Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
チャットボット奮闘記
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
fuzyco
April 25, 2017
Technology
140
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
チャットボット奮闘記
RNNを用いてチャットボットを作った奮闘記です。
fuzyco
April 25, 2017
More Decks by fuzyco
See All by fuzyco
Functional Error&Retry Handling
hiroki6
2
630
Extensible Effects: beyond the Monad Transformers
hiroki6
1
880
High Performance Scala/high_performance_scala
hiroki6
4
4.4k
並行四方山話/tales_of_concurrency
hiroki6
0
140
Scalaでの並行・並列処理戦略/strategy-for-concurrency-and-parallel-by-scala
hiroki6
9
3.3k
Monad Error with Cats/monad-error-with-cats
hiroki6
0
650
scala_multi_thread.pdf
hiroki6
0
380
GAEを用いたBQ Load戦略/gae_bq_load_strategy
hiroki6
2
1.9k
Extensible Effects with Scala/eff-with-scala
hiroki6
0
1.1k
Other Decks in Technology
See All in Technology
reFACToring
moznion
1
1.1k
LangfuseによるLLMOps基盤の構築と活用事例
zozotech
PRO
1
200
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
480
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
2k
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.4k
plamo-3-translateの開発
pfn
PRO
0
220
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
AIエージェントの知識表現と推論に なぜグラフが使われるのか - 記号的AIの復権とニューラルAIとの統合
yohei1126
1
240
システム監視入門
grimoh
5
770
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
5
810
AIQAのナレッジ構築について
qatonchan
1
130
Featured
See All Featured
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
920
New Earth Scene 8
popppiees
3
2.4k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Become a Pro
speakerdeck
PRO
31
6k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.7k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
410
Are puppies a ranking factor?
jonoalderson
1
3.7k
Transcript
チャットボット奮闘記 1
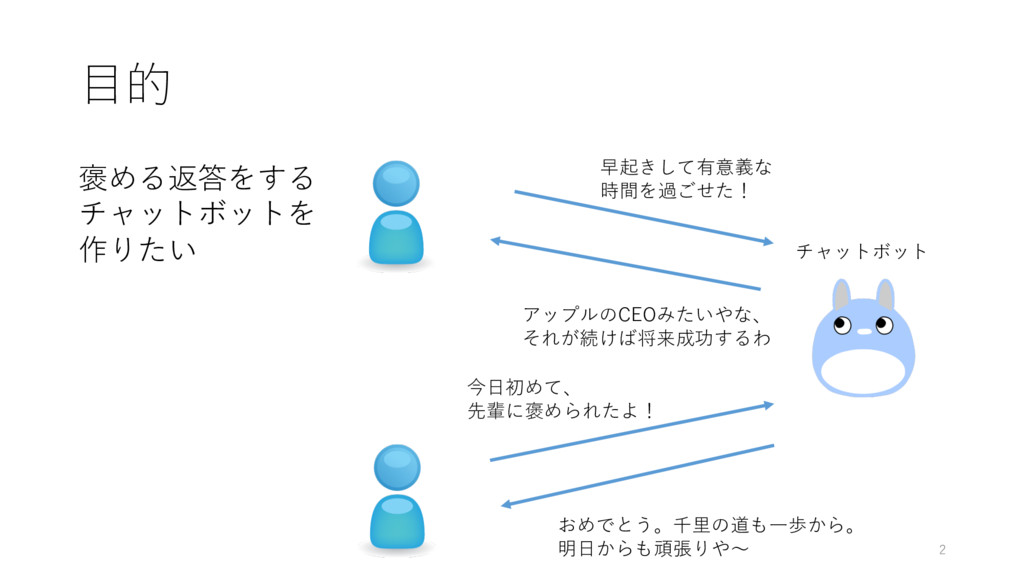
⽬的 2 早起きして有意義な 時間を過ごせた! アップルのCEOみたいやな、 それが続けば将来成功するわ 今⽇初めて、 先輩に褒められたよ! おめでとう。千⾥の道も⼀歩から。 明⽇からも頑張りや〜
褒める返答をする チャットボットを 作りたい チャットボット
実現⽅法 3 2. 褒める返答を学習して、⼈⼯知能が⼊⼒に対して返答を⾏う 1. ⼀般的な対話を学習して、それに対する返答と 褒める⽂章のベクトルを組み合わせて褒める⽂章を⽣成する (画像⽣成のGANみたいなイメージ) 難しすぎる(研究レベル) 学習データがあれば今まで研究されてきた
対話モデルとか使えばなんとかなりそう 参考サイト: http://qiita.com/sergeant-wizard/items/0a57485bc90a35efcf26
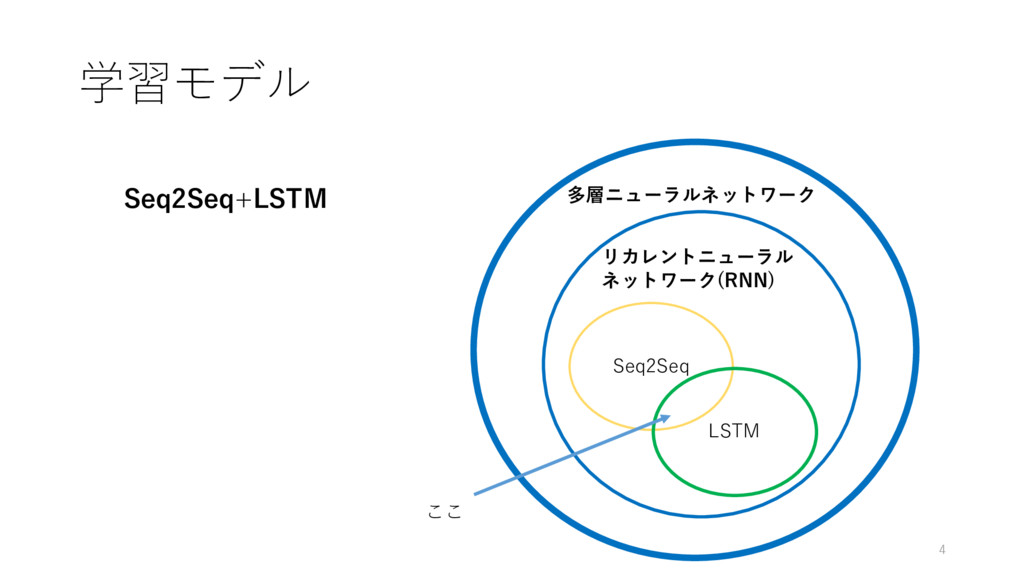
学習モデル 4 Seq2Seq 多層ニューラルネットワーク LSTM リカレントニューラル ネットワーク(RNN) ここ Seq2Seq+LSTM
RNNの例 語彙: [h, e, l, o] トレーニング⽂章: “hello” 1 0
0 0 0 1 0 0 0 0 1 0 0 0 0 1 “h” “e” “l” “l” ⼊⼒データ t 1 2 3 4 ⼊⼒層: X 5
RNNの例 語彙: [h, e, l, o] トレーニング⽂章: “hello” 1 0
0 0 0 1 0 0 0 0 1 0 0 0 0 1 0.3 -0.1 0.9 1.0 0.3 0.1 0.1 -0.5 -0.3 -0.3 0.9 0.7 “h” “e” “l” “l” ⼊⼒データ W W(in) zt = tanh(W(in)xt +Wzt−1) t 1 2 3 4 隠れ層: Z ⼊⼒層: X 6
RNNの例 語彙: [h, e, l, o] トレーニング⽂章: “hello” 出⼒層: Y
隠れ層: Z ⼊⼒層: X 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0.3 -0.1 0.9 1.0 0.3 0.1 0.1 -0.5 -0.3 -0.3 0.9 0.7 1.0 2.2 -3.0 4.1 0.5 0.3 -1.0 1.2 0.1 0.5 1.9 -1.1 0.2 -1.5 -0.1 2.2 “h” “e” “l” “l” 教師データ “e” “l” “l” “o” ⼊⼒データ W(out) W W(in) 学習 t 1 2 3 4 7
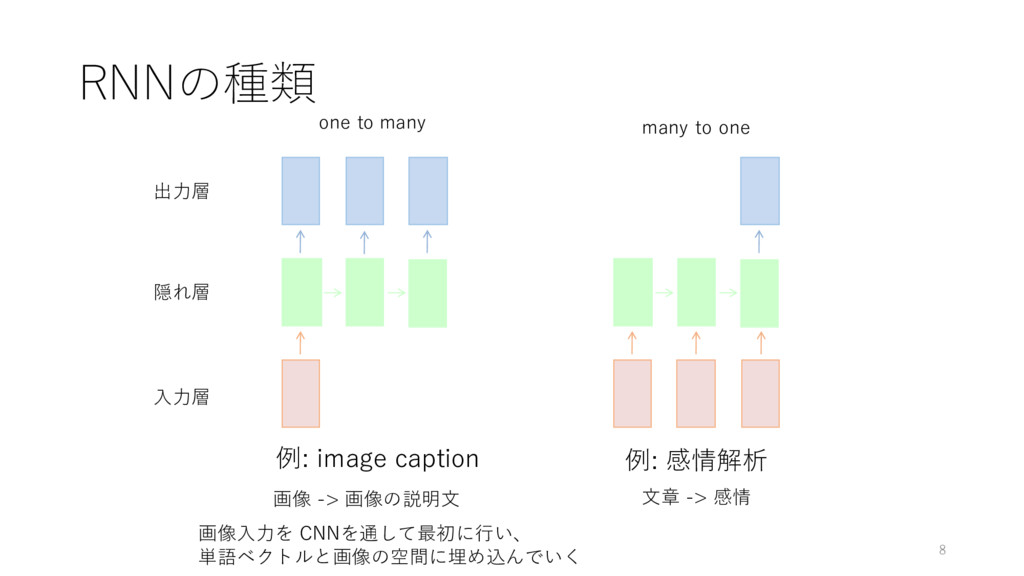
one to many many to one RNNの種類 例: image caption
出⼒層 隠れ層 ⼊⼒層 画像⼊⼒を CNNを通して最初に⾏い、 単語ベクトルと画像の空間に埋め込んでいく 例: 感情解析 ⽂章 -> 感情 画像 -> 画像の説明⽂ 8
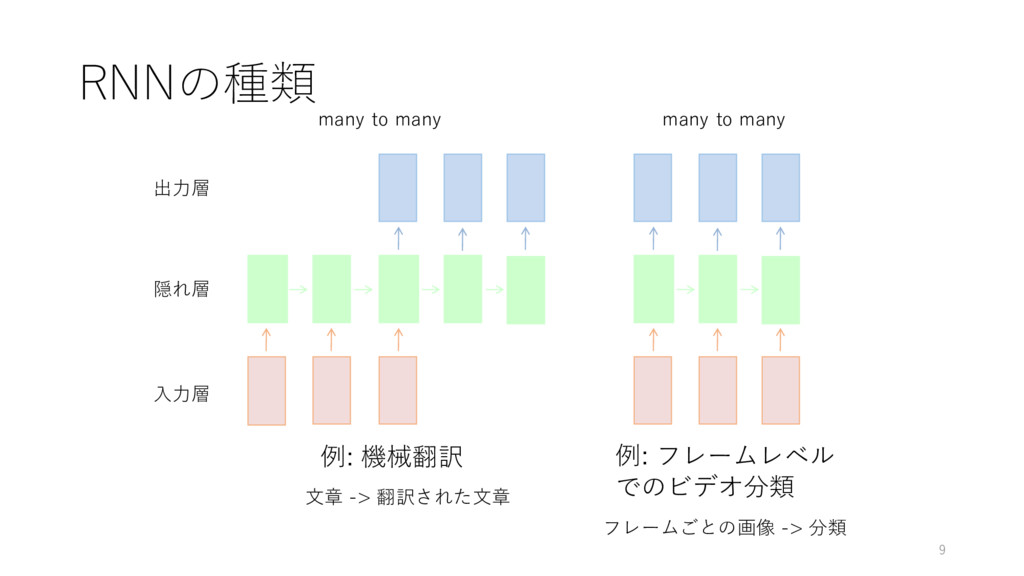
RNNの種類 many to many many to many 出⼒層 隠れ層 ⼊⼒層
例: 機械翻訳 ⽂章 -> 翻訳された⽂章 例: フレームレベル でのビデオ分類 フレームごとの画像 -> 分類 9
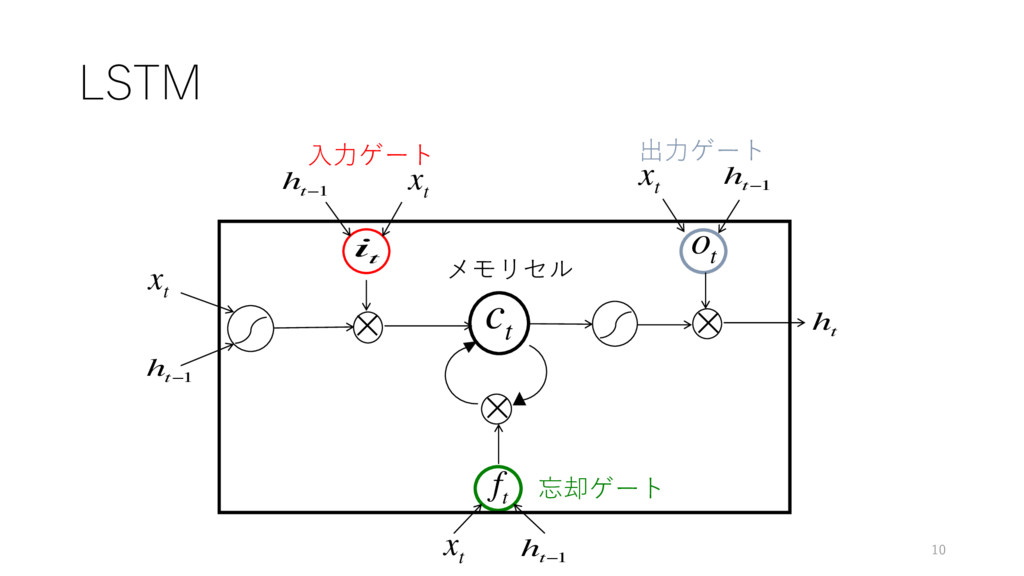
LSTM × × × i t o t c t
f t x t x t x t x t h t h t−1 h t−1 h t−1 h t−1 ⼊⼒ゲート 出⼒ゲート 忘却ゲート メモリセル 10
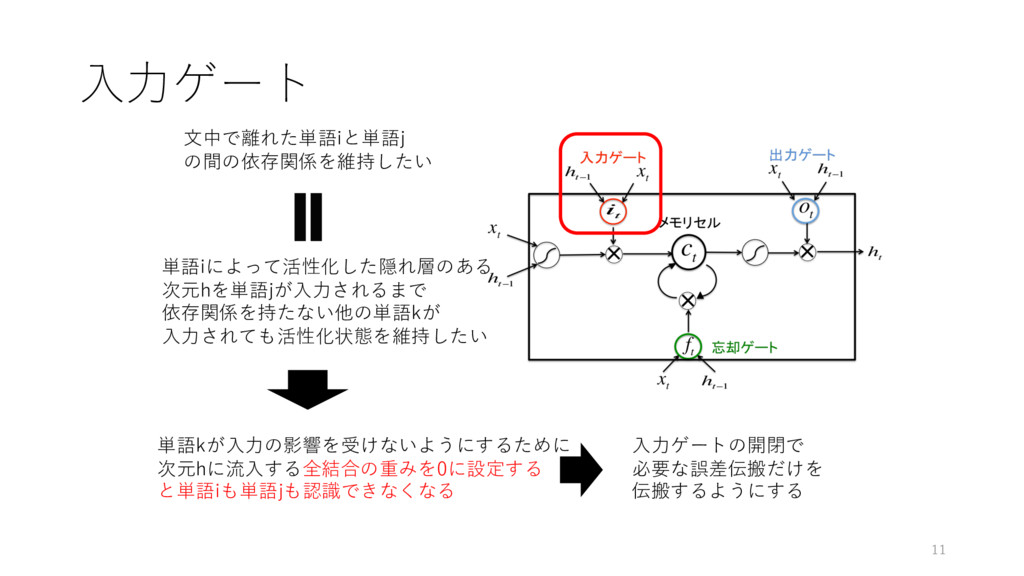
⼊⼒ゲート ⽂中で離れた単語iと単語j の間の依存関係を維持したい 単語iによって活性化した隠れ層のある 次元hを単語jが⼊⼒されるまで 依存関係を持たない他の単語kが ⼊⼒されても活性化状態を維持したい 単語kが⼊⼒の影響を受けないようにするために 次元hに流⼊する全結合の重みを0に設定する と単語iも単語jも認識できなくなる
⼊⼒ゲートの開閉で 必要な誤差伝搬だけを 伝搬するようにする 11
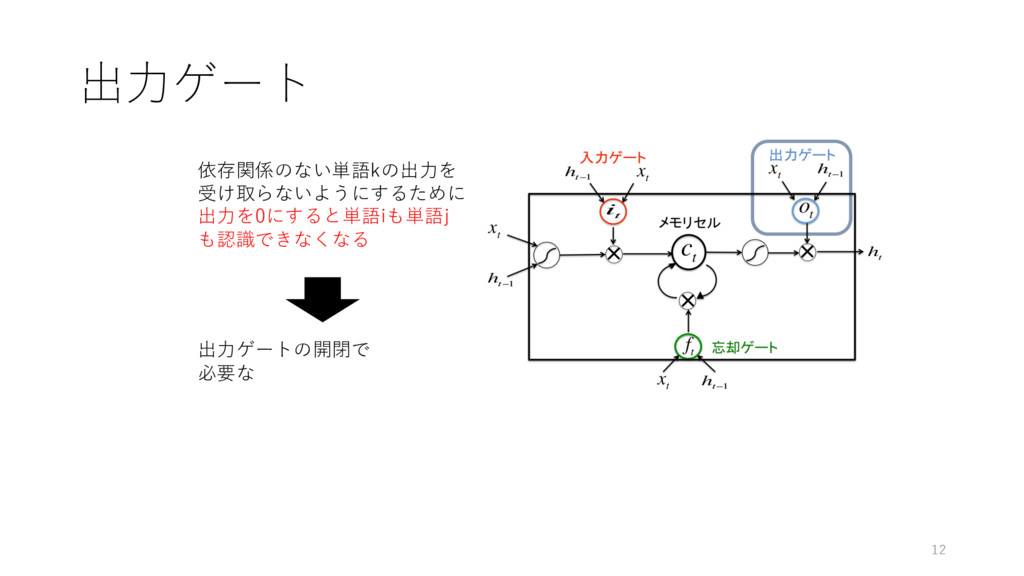
出⼒ゲート 依存関係のない単語kの出⼒を 受け取らないようにするために 出⼒を0にすると単語iも単語j も認識できなくなる 出⼒ゲートの開閉で 必要な 12
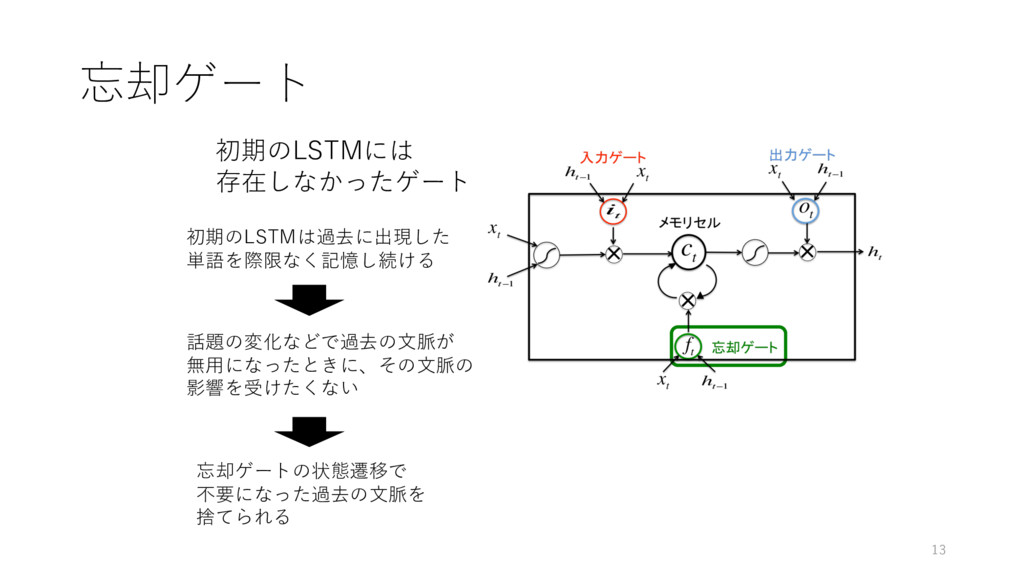
忘却ゲート 初期のLSTMには 存在しなかったゲート 話題の変化などで過去の⽂脈が 無⽤になったときに、その⽂脈の 影響を受けたくない 初期のLSTMは過去に出現した 単語を際限なく記憶し続ける 忘却ゲートの状態遷移で 不要になった過去の⽂脈を
捨てられる 13
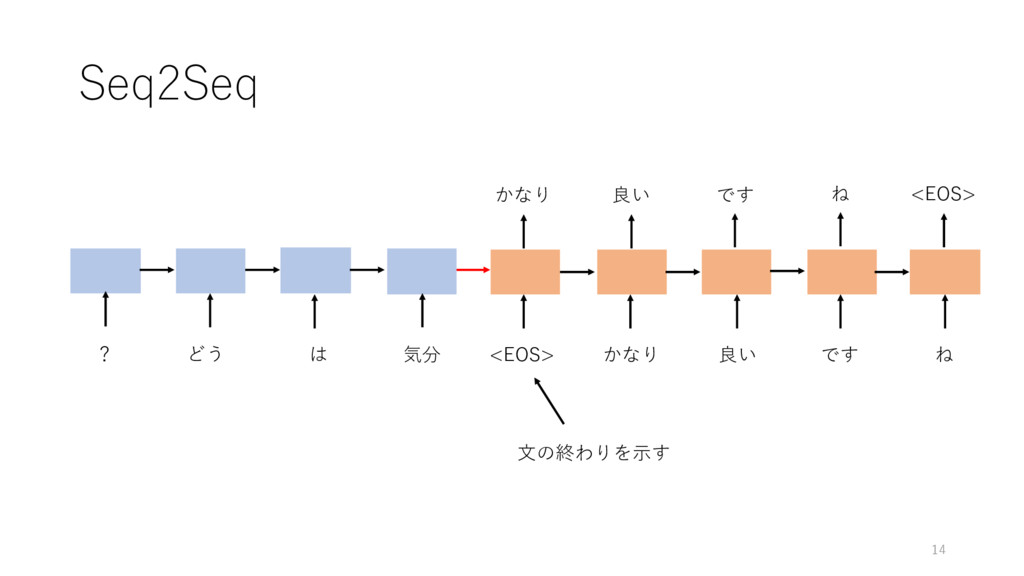
Seq2Seq ? どう は <EOS> かなり 良い です ね かなり
良い です ね <EOS> 14 気分 ⽂の終わりを⽰す
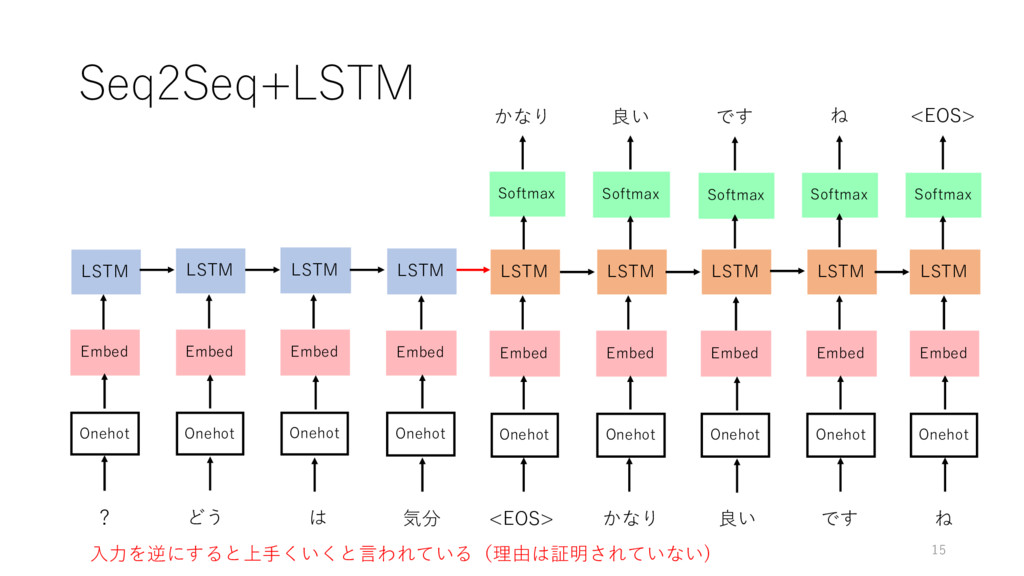
15 LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM ?
どう は <EOS> かなり 良い です ね かなり 良い です ね <EOS> LSTM 気分 Embed Embed Embed Embed Embed Embed Embed Embed Embed Seq2Seq+LSTM Onehot Onehot Onehot Onehot Onehot Onehot Onehot Onehot Onehot Softmax Softmax Softmax Softmax Softmax ⼊⼒を逆にすると上⼿くいくと⾔われている(理由は証明されていない)
実装 16 l Chainerで実装 l ⼆つのモデルを作って試してみた 1. Embed(単語の分散表現)もrnn上で学習 2. Embed(単語の分散表現)を事前にword2vecで学習したものを使⽤
参考⽂献 ソースコード: https://github.com/Hiroki6/homey_api 実装したモデル
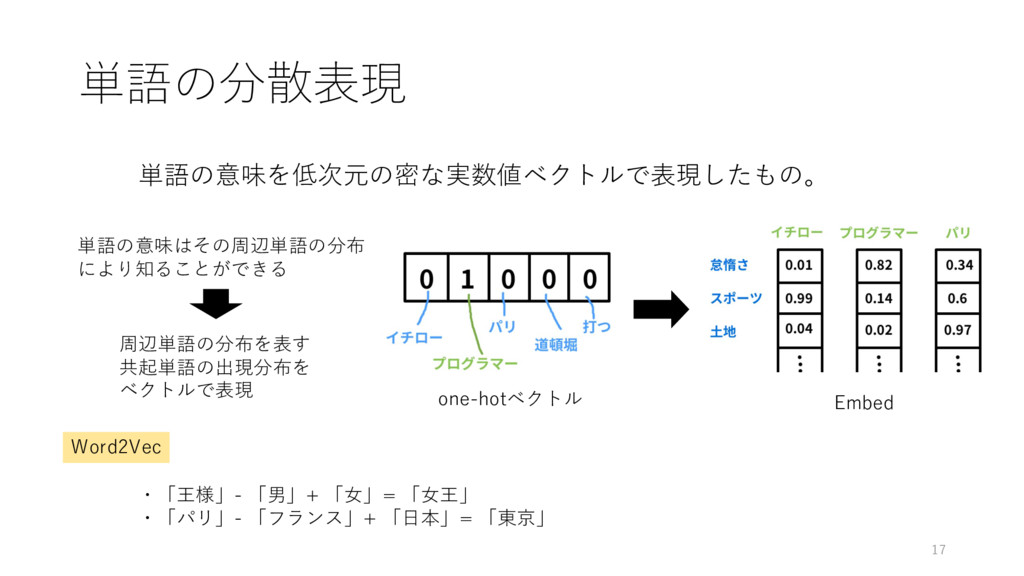
単語の分散表現 17 単語の意味を低次元の密な実数値ベクトルで表現したもの。 Word2Vec ・「王様」- 「男」+ 「⼥」= 「⼥王」 ・「パリ」- 「フランス」+
「⽇本」= 「東京」 one-hotベクトル Embed 単語の意味はその周辺単語の分布 により知ることができる 周辺単語の分布を表す 共起単語の出現分布を ベクトルで表現
Word2Vec 18 from gensim.models.word2vec import Word2Vec model = Word2Vec.load(w2v_model_path) #
モデルの読み込み # 王+⼥-男 results = w2v.most_similar(positive=[u"王", u"⼥"], negative=[u"男"], topn=20) 聖王, 0.809992 君主, 0.802966 皇帝, 0.801212 ⼥帝, 0.787127 先王, 0.782204 王⼦, 0.772441 王シ, 0.771339 ⼤王, 0.763460 公, 0.762177 ローマ皇帝, 0.760930 ⼥王, 0.759142 ⽩ヤギコーポレーションが公開している学習済みword2vecのモデルを使⽤ http://aial.shiroyagi.co.jp/2017/02/japanese-word2vec-model-builder/ gensimで簡単に読み込んで使⽤できる
学習 19 chainerは簡単にgpu環境で動かせる関数を⽤意している import numpy as np from chainer import
cuda xp = cuda.cupy # npの代わりにxpを使⽤ cuda.get_device(0).use() # 使⽤するGPUを指定 model.to_gpu() # modelを学習するまえにgpu⽤に変換 Ø GPUを使⽤(Tesla) この3⾏を加えるだけ 環境 時間 褒める会話を多く含む11,000対話を100epoch学習 約1週間
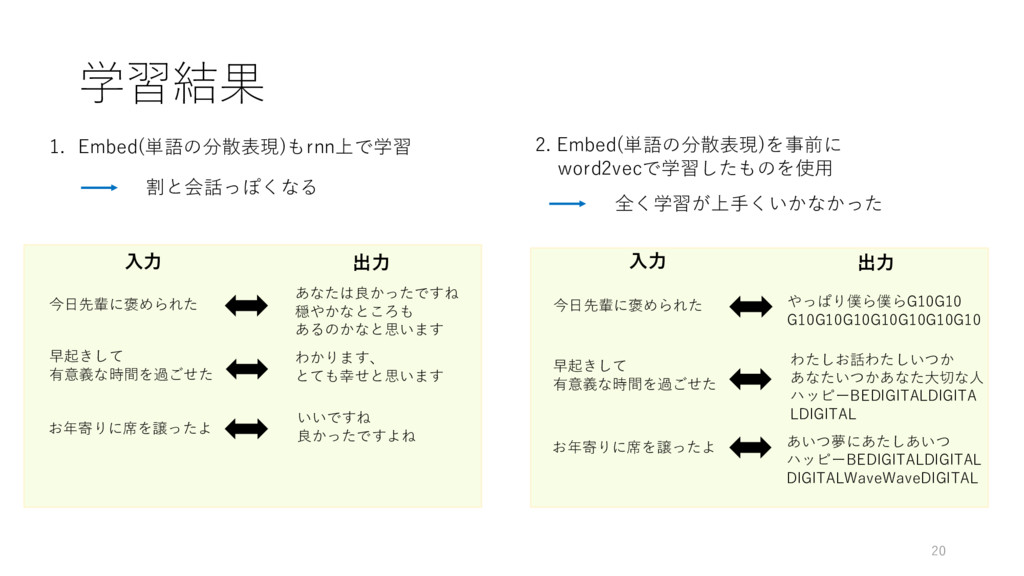
学習結果 20 1. Embed(単語の分散表現)もrnn上で学習 割と会話っぽくなる 全く学習が上⼿くいかなかった ⼊⼒ 出⼒ ⼊⼒ 出⼒
2. Embed(単語の分散表現)を事前に word2vecで学習したものを使⽤ 今⽇先輩に褒められた あなたは良かったですね 穏やかなところも あるのかなと思います やっぱり僕ら僕らG10G10 G10G10G10G10G10G10G10 今⽇先輩に褒められた わかります、 とても幸せと思います 早起きして 有意義な時間を過ごせた 早起きして 有意義な時間を過ごせた わたしお話わたしいつか あなたいつかあなた⼤切な⼈ ハッピーBEDIGITALDIGITA LDIGITAL いいですね 良かったですよね お年寄りに席を譲ったよ お年寄りに席を譲ったよ あいつ夢にあたしあいつ ハッピーBEDIGITALDIGITAL DIGITALWaveWaveDIGITAL
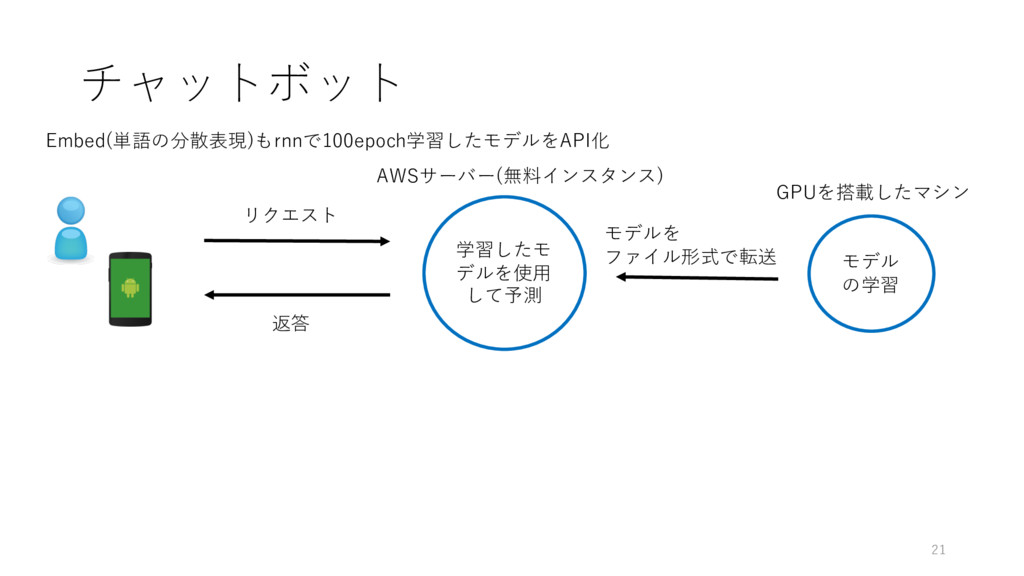
チャットボット 21 GPUを搭載したマシン モデル の学習 AWSサーバー(無料インスタンス) 学習したモ デルを使⽤ して予測 リクエスト
返答 モデルを ファイル形式で転送 Embed(単語の分散表現)もrnnで100epoch学習したモデルをAPI化
まとめ 22 l ディープラーニングはコストが⾼い l ⼤量の学習データ l 計算機(GPUなど) l 研究レベルと実⽤レベルは違う
l 研究だと⽂章っぽくなってても感動する l 実⽤だとちゃんとした⽂章が求められる l ディープラーニングは難しい l 細かいチューニング l パラメータが多い l 計算コスト l どの部分が有効かがわかりにくい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RNNの例 語彙: [h, e, l, o] トレーニング⽂章: “hello” 1 0](https://files.speakerdeck.com/presentations/4667f076800a4c31855f58d7d13533ea/slide_4.jpg){kind=link}
![RNNの例 語彙: [h, e, l, o] トレーニング⽂章: “hello” 1 0](https://files.speakerdeck.com/presentations/4667f076800a4c31855f58d7d13533ea/slide_5.jpg){kind=link}
![RNNの例 語彙: [h, e, l, o] トレーニング⽂章: “hello” 出⼒層: Y](https://files.speakerdeck.com/presentations/4667f076800a4c31855f58d7d13533ea/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}