Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【AWS Lambda(SAM)でつくるクローラー】Crawler Night 2020 Wi...
Search
Hironori Tanaka
December 03, 2019
Technology
3.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【AWS Lambda(SAM)でつくるクローラー】Crawler Night 2020 Winter
Lambda(SAM) x Layer でリアルタイムクローリングした知見を発表してきました。
#crawler_night
Hironori Tanaka
December 03, 2019
More Decks by Hironori Tanaka
See All by Hironori Tanaka
ビジネスサイドと共創し、チーム連動性を高める「Tech2Biz」
hirontan
0
190
【ちょっとしたカスタマイズが大事なエンジニア採用】CTO・CPOが語る!エンジニア採用を成功させる採用オペレーション【LAPRASxHERP】
hirontan
1
940
【自己流 Lambda(SAM)活用のTips】スタートアップ×AWS オンラインLT大会 Coral Developers Night
hirontan
1
630
【僕はこれでハードシングスを乗り越えた。 ~空のコアバリュー「LiveDirect」の正体~】「10名、50名、100名規模それぞれのB2B SaaS技術組織に聞く、フェーズ別ハードシングス」 〜組織拡大中の3社が向き合うエンジニア組織デザイン〜
hirontan
0
1.6k
株式会社空紹介_SIer脱出を語る_SIerで働くU30エンジニア限定イベント_kiitokMeetUp___配布用_.pdf
hirontan
0
260
【「不足している箇所はないか」 を考えてきた結果】プロダクトマネージャーがキャリアを語る。U35のPdM志望エンジニア限定【kiitokMeetup】
hirontan
1
1.1k
【プロダクトから顧客や様々な職種へ】CTO of the year 2018【株式会社空】
hirontan
0
480
Other Decks in Technology
See All in Technology
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
370
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
890
PLaMoを毎日の開発で使い育てていく
pfn
PRO
0
170
Pavlokで始める電撃駆動開発
sgrsn
0
140
ガバメントクラウドでのランサムウェア対策
techniczna
1
480
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
AI時代の強いチームの作り方
yuukiyo
23
12k
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
2k
データ組織の転換期 一足飛びしない段階的戦略
leveragestech
PRO
0
140
AIエージェントの知識表現と推論に なぜグラフが使われるのか - 記号的AIの復権とニューラルAIとの統合
yohei1126
1
250
Amazon Bedrock Managed Knowledge Base Dive Deep
ren8k
0
320
Atlassian Cloudサポート業務でのAIエージェント活用事例
smt7174
0
210
Featured
See All Featured
How to train your dragon (web standard)
notwaldorf
97
6.7k
ラッコキーワード サービス紹介資料
rakko
1
4.1M
The SEO Collaboration Effect
kristinabergwall1
1
510
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Paper Plane
katiecoart
PRO
2
52k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
How to Ace a Technical Interview
jacobian
281
24k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Un-Boring Meetings
codingconduct
0
350
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Transcript
AWS Lambda(SAM) でつくるクローラー 株式会社空 ⽥仲 紘典
⾃⼰紹介 2 2012年〜2016年 ヤフー アドテクのインフラエンジニアや社内システムの開 発・保守を主に担当。 その他に、新卒研修のメンター・次世代リーダー育成 Yahoo!アカデミアにも参加をし、育成⼒とリーダーシ ップ⼒を向上させる。 2013年頃から副業も⾏い、AWSや開発などの技術サ
ポートを初めて経験。 2016年〜 空 ホテル向け料⾦設定サービス「MagicPrice」の⽴ち上 げ期からエンジニアとして携り、2016年6⽉取締役兼 エンジニアとして参画。現在はプロダクト責任者 (Chief Production Officer)。
会社紹介 3
4 社名︓株式会社空 代表者︓松村⼤貴 設⽴︓2015年 従業員︓30名(⾮正規社員含む) URL︓https://www.sora.flights/
Vision 5 ⾰新的なサービスをつくりながら、幸せな働き⽅を世界に広めます
6 世界中の価格を最適化し、売り⼿も買い⼿も嬉しい世界を作る Mission
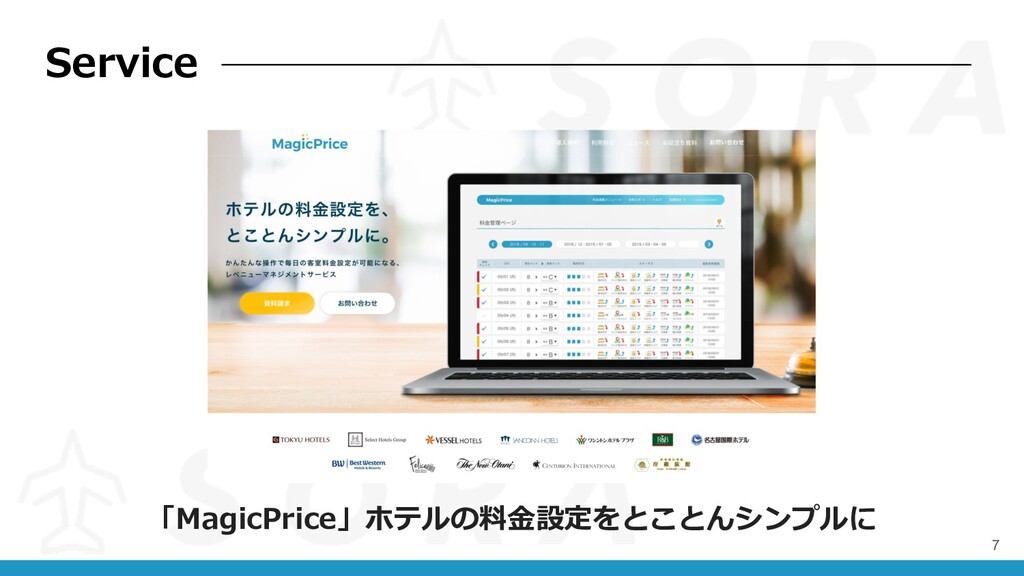
7 「MagicPrice」ホテルの料⾦設定をとことんシンプルに Service
精度=料⾦設定のムラ ノウハウが属⼈化しており、担当者が変わると やり⽅が変わる。 経験とカンに頼る部分が⼤きく、 上⼿くいく⽉といかない⽉が出てしまう。 ⼿間=料⾦設定のムダ 調査や分析にかかる時間は1⽇1〜3時間。 ⽉に60時間も、経営や戦略を担う従業員の 時間を使っている。 Issues
8
クローリングをどこで利⽤しているのか 9
Research 10 予約 状況 ⾃ホテル︓⾃ホテルの予約データを連携 競合ホテル︓マーケット情報を収集 予約 プラン 予約 金額
・・・ 掲載 状況 掲載 プラン 掲載 金額 ・・・ クローリング
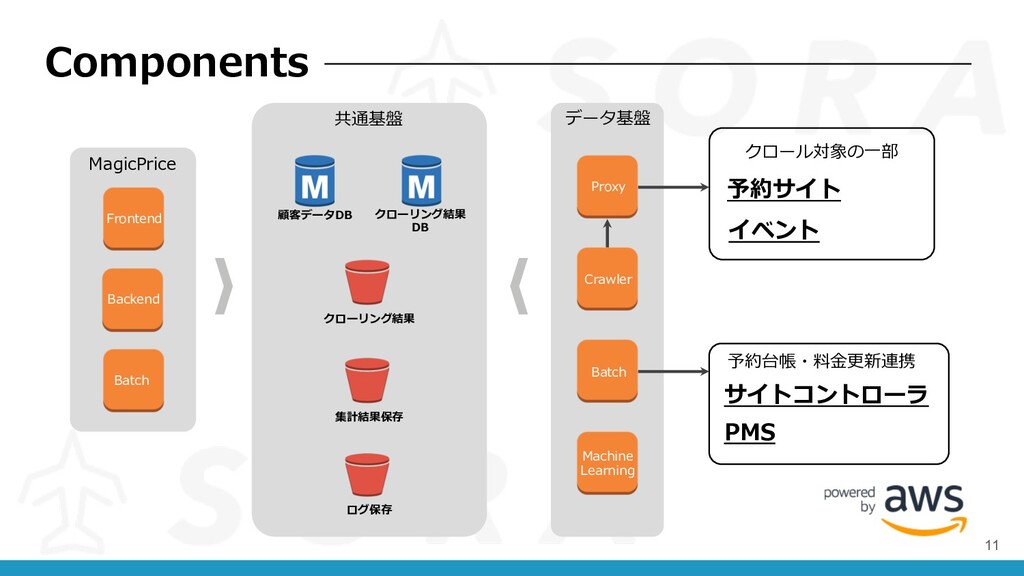
Components Frontend クローリング結果 Backend 顧客データDB クローリング結果 DB Proxy Crawler Batch
クロール対象の⼀部 ログ保存 集計結果保存 MagicPrice 共通基盤 Machine Learning データ基盤 予約サイト イベント 予約台帳・料⾦更新連携 サイトコントローラ PMS Batch 11
リアルタイムクローリングに Lambda(SAM)を選択 12
クローリング・スクレイピング 13 ウェブサイトからHTMLを取得 HTMLから任意の情報を抽出
クローリング︓2種類のパターン • バッチ ◦ 情報差分の更新やデータ分析に時系列情報としての取り扱いなど 特に即時性は求めないが、一定間隔でデータ取得をしておくパターン • リアルタイム ◦ ホテルで言えば、価格や在庫の情報など現在情報を知るために、
即時にデータ取得を行うパターン 14
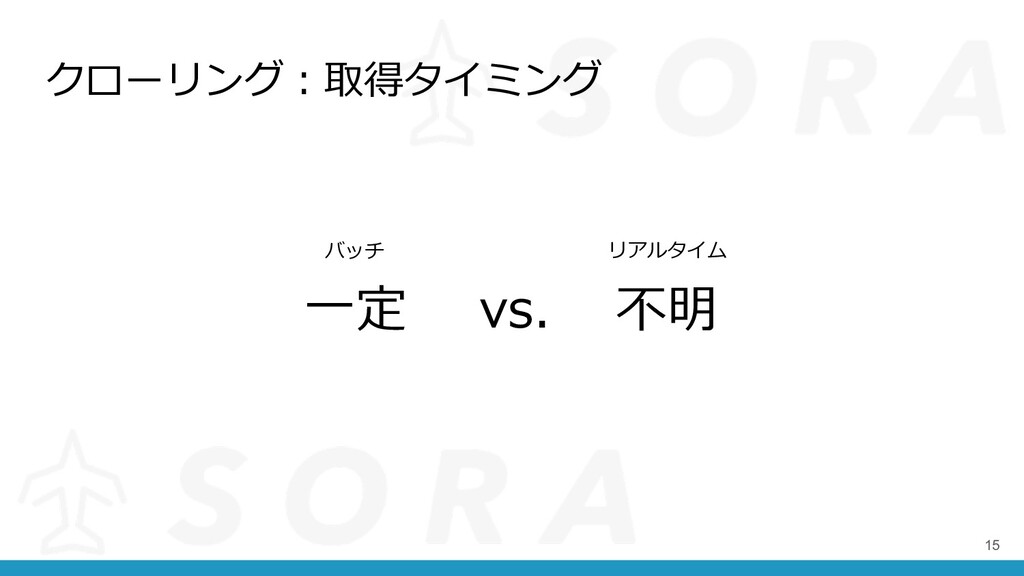
クローリング︓取得タイミング 15 ⼀定 vs. 不明 バッチ リアルタイム
クローリング︓取得の速さ 16 求められ 「ない」 vs. 求められ 「る」 バッチ リアルタイム
クローリング︓わがままなリアルタイム︕ • バッチ ◦ 情報差分の更新やデータ分析に時系列情報としての取り扱いなど 特に即時性は求めないが、一定間隔でデータ取得をしておくパターン • リアルタイム ◦ ホテルで言えば、価格や在庫の情報など現在情報を知るために、
即時にデータ取得を行うパターン 17 制約が強いところを解決したい︕
ぼんやりイメージしていたこと • 取得タイミング不明の解消・取得速度 ◦ キューやAPIなどをフックにイベントを受け付ける ◦ 起動を早める。AutoScalingでは起動に時間がかかる ◦ EC2などサーバの常時稼働はコストが嵩む。サーバレス?Lambda? •
ローカルからリリース ◦ CloudFormation?serverless framework? • ローカルで本番とほぼ同⼀環境構築 18
【個⼈的に】インフラの前提として、気にしていること • ローコストで本番稼働できる ◦ 一度開発したら、なかなか修正できないから設計段階で考える • ローカルで単体テスト + 周辺の結合テストまで実⾏できる ◦
クラウド環境でできるだけ動かさない ◦ 周辺の結合テストはできる限り • 可能な限りデフォルトを利⽤する ◦ あれこれライブラリ入れない ◦ 小難しいことしない 19
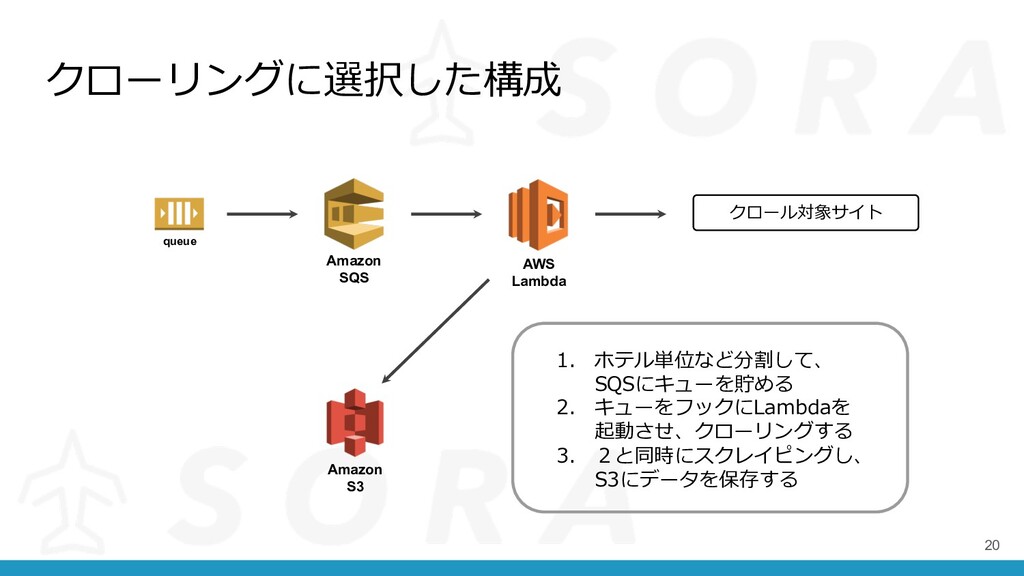
クローリングに選択した構成 20 AWS Lambda Amazon S3 Amazon SQS queue クロール対象サイト
1. ホテル単位など分割して、 SQSにキューを貯める 2. キューをフックにLambdaを 起動させ、クローリングする 3. 2と同時にスクレイピングし、 S3にデータを保存する
ローカル開発︓SAM(サーバーレスアプリケーションモデル) 21
ローカル開発︓SAM(サーバーレスアプリケーションモデル) 22
Lambda(SAM)でクローリング 23
実⾏環境 • ランタイム︓Ruby 2.5 • ライブラリ ◦ nokogiri:HTMLやXML、SAXのパーサー。XPath または CSS
セレクタを利用して要素抽出 ◦ robotex:robot.txt からクローラーの判定可否 ◦ aws-sdk-xxxxx(AWSは個別のサービス):AWSのサービスを操作 24
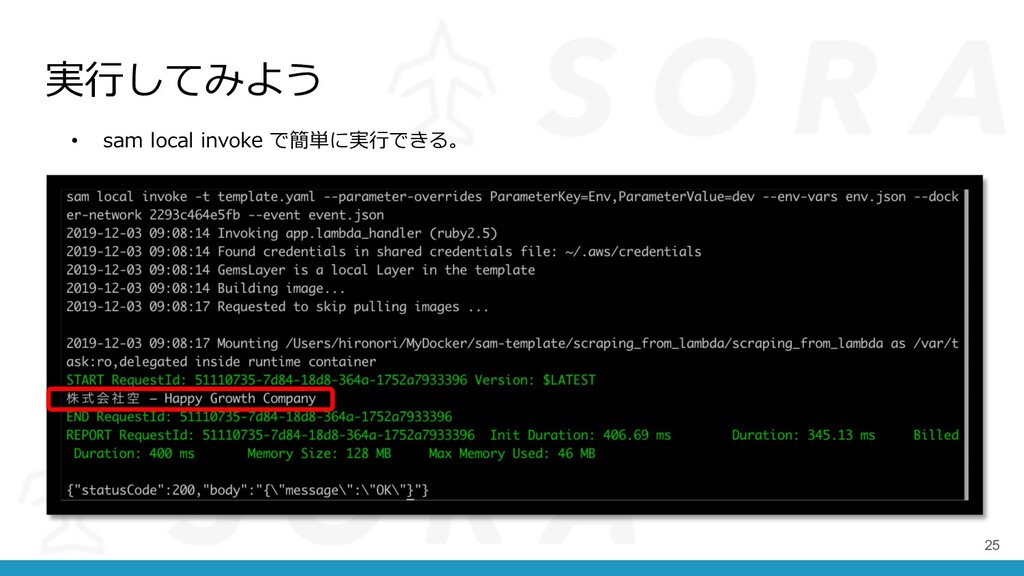
実⾏してみよう 25 • sam local invoke で簡単に実⾏できる。
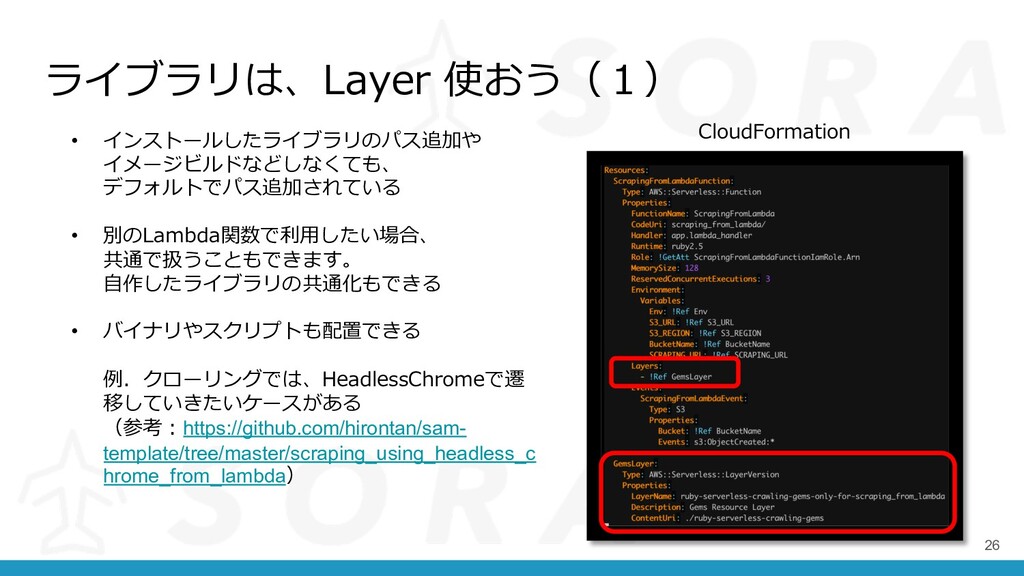
ライブラリは、Layer 使おう(1) 26 • インストールしたライブラリのパス追加や イメージビルドなどしなくても、 デフォルトでパス追加されている • 別のLambda関数で利⽤したい場合、 共通で扱うこともできます。
⾃作したライブラリの共通化もできる • バイナリやスクリプトも配置できる 例.クローリングでは、HeadlessChromeで遷 移していきたいケースがある (参考︓https://github.com/hirontan/sam- template/tree/master/scraping_using_headless_c hrome_from_lambda) CloudFormation
ライブラリは、Layer 使おう(2) 27 • ライブラリの配置先は決まっている(/opt 配下に)
⼀つだけ、Layer のハマりポイント 28 • Rubyのバージョンが揃っていないとライブラリの読み込みされない可能性がある。 • イメージ「 lambci/lambda:build-ruby2.5 」を利⽤して、ビルドした結果をローカルに配置 し直した結果を利⽤する
• スクリプト⽤意しているので参考にしてください layers/ ├── builds │ └── build_ruby-serverless-crawling-gems.sh ├── docker │ └── Dockerfile_ruby-serverless-crawling-gems └── gemfiles ├── Gemfile_ruby-serverless-crawling-gems └── Gemfile_ruby-serverless-crawling-gems.lock https://github.com/hirontan/sam-template/tree/master/scraping_from_lambda/layers
イベント︓⾮同期的に呼び出す(1) 29 • リアルタイムに実⾏できる • S3 / SQS / CloudWatch
Events など 扱えるイベントはデフォルトで備わっている • ローカルでは、jsonファイルで擬似的に実⾏できる sam local generate-event でイベント作成 • 本番環境では、プロパティに Events を書いて、 デプロイする。CloudFormationの yaml ファイル に記述するだけ CloudFormation
イベント︓⾮同期的に呼び出す(2) 30 • キューの受け取りは event[ʻRecordsʼ] 簡単に受け取れる • ⼀度にキューを複数受け取り できる設定も、SQS・Kinesis などでも、
プロパティに BatchSize と記述すると 設定できる ソースコード
同時実⾏数 31 • クローリング対象サイトにダメージを与えない ように同時アクセス数は気にしなければいけない。 そのコントロールとして、同時実⾏数の制御を⾏う (もちろんソースコード内でもスリープも考える) • プロパティ ReservedConcurrentExecutions
で 同時実⾏の予約数を制御することを忘れない • もしRDSも接続するなら、データベースへの 同時接続数制御にも。 情報があまり変わらないのであれば、 DataPipelineなどでデータベースのテーブルを CSV化して、CSVにアクセスする⽅法もあります。 CloudFormation
コスト⾯での注意(CloudWatch PutLogEvents) 32 • S3 / SQS / CloudWatch Events
/ Lambda など、⼀つ⼀つは、正直積み重ならない。 しかし、無闇にログをCloudWatchに履き続けると PutLogEventsが発⽣し、料⾦が嵩む。 正常系はログに出さないなど、障害に備えられるログ出しにしてください
時間あったら本当に実⾏してみる︕ 33 https://github.com/hirontan/sam- template/tree/master/scraping_fr om_lambda
わかったこと・まとめ • Lambda(SAM) x Layer でクローリングできる • リアルタイムな実⾏に適してそう(実⾏した分だけなので安価なことから) • CloudFormation・AWSサービスを理解していれば、
組み合わせだけで簡単に仕組みが作れる • CloudWatch PutLogEventsは気を付けろ︕ 34
35
参考⽂献 • AWS サーバーレスアプリケーションモデル https://aws.amazon.com/jp/serverless/sam/ • AWS Lambda レイヤー https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-
layers.html • AWS CloudFormation https://aws.amazon.com/jp/cloudformation/ • AWS::Lambda::EventSourceMapping https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/User Guide/aws-resource-lambda-eventsourcemapping.html 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![イベント︓⾮同期的に呼び出す(2) 30 • キューの受け取りは event[ʻRecordsʼ] 簡単に受け取れる • ⼀度にキューを複数受け取り できる設定も、SQS・Kinesis などでも、](https://files.speakerdeck.com/presentations/b221196e88e9404d8abbe0d1090ffec0/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}