前回の達成目標
今回の達成目標
実験回数を少なくしたい!
実験計画法
実験計画法のイメージ 1/3
実験計画法のイメージ 2/3
実験計画法のイメージ 3/3
実験パラメータの候補をどのように選択するか?
D 最適基準が大きくなるように選択する
[補足] D 最適基準以外の最適基準の例
例題をどうするか?
実際に最初に実験する候補を選択してみる
標準化 (オートスケーリング)
最小二乗法による線形重回帰分析
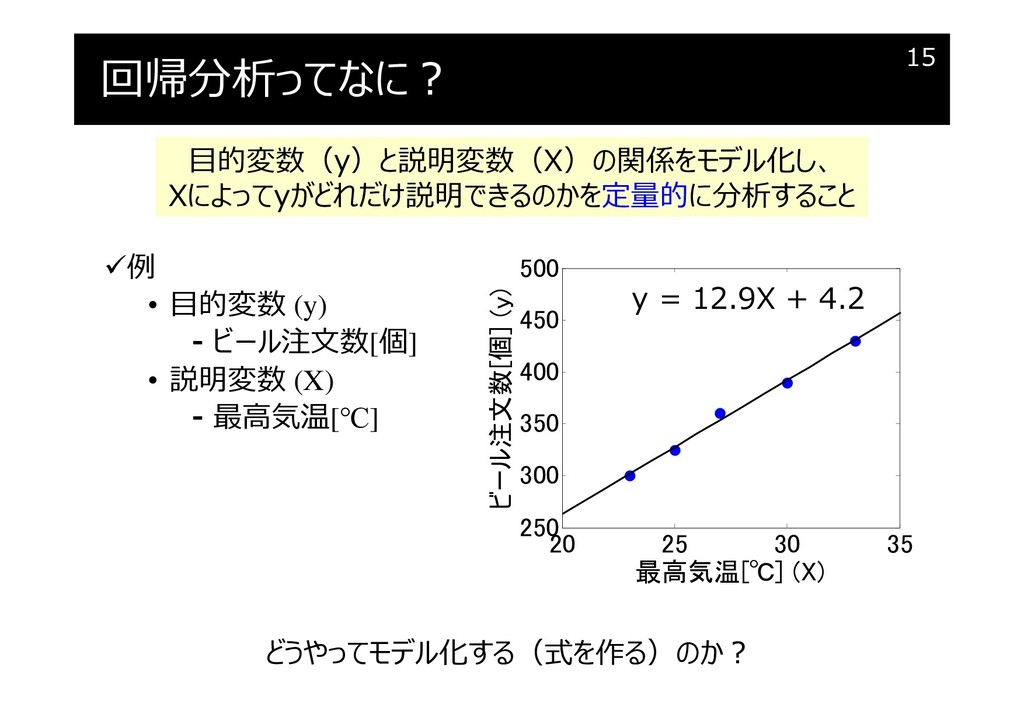
回帰分析ってなに?
説明変数が2つのときの線形重回帰分析
オートスケーリング(標準化)のメリット
サンプルが n 個のとき
行列で表す
回帰係数を求めたい
最小二乗法
誤差の二乗和を回帰係数で偏微分して 0
回帰係数、ついに求まる
回帰モデルの精度の指標 r2
回帰モデルの精度の指標 RMSE
回帰モデルの精度の指標 MAE
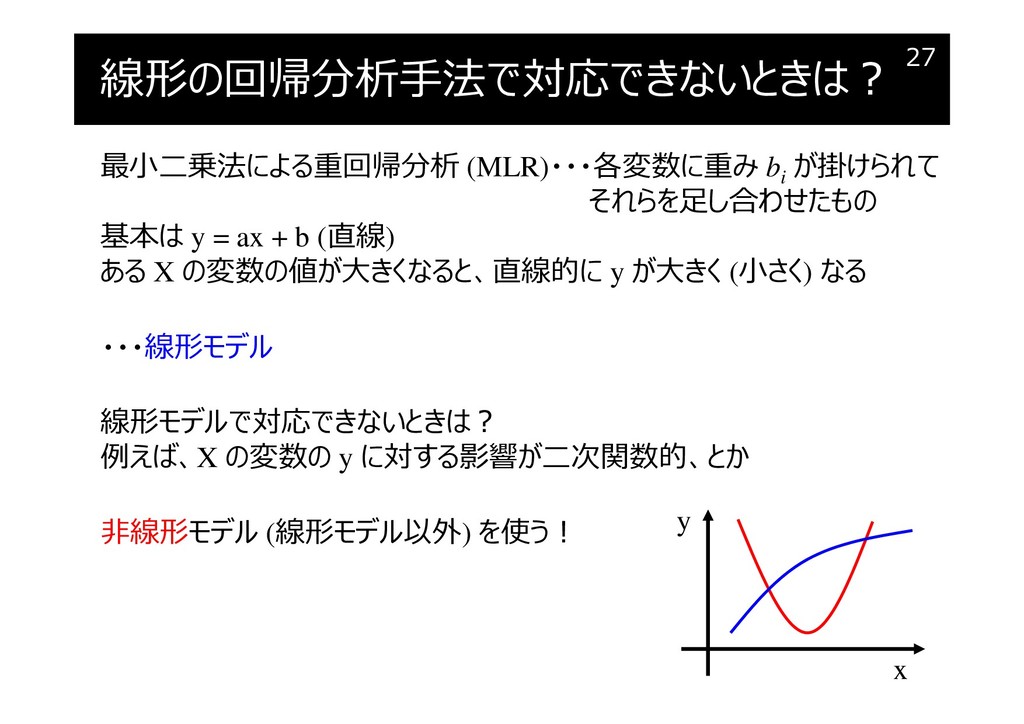
線形の回帰分析手法で対応できないときは?
簡単に非線形モデルを作る方法
今後のお話の概要
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] D 最適基準以外の最適基準の例 A 最適基準︓XTX の逆⾏列の対角成分の和を最⼩化 E 最適基準︓XTX の固有値の最⼩値を最⼤化 I](https://files.speakerdeck.com/presentations/8331bf2ead534e01a1d509f2d58d114d/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![簡単に非線形モデルを作る方法 28 X の変数をそれぞれ二乗した変数 (x1 2, x2 2, …) [二乗項]](https://files.speakerdeck.com/presentations/8331bf2ead534e01a1d509f2d58d114d/slide_28.jpg){kind=link}
{kind=link}
{kind=link}