BY DEFAULT AS IDENTITY PRIMARY KEY, category_id int REFERENCES category (id) NOT NULL, title text NOT NULL, describe text NOT NULL, location geometry(point, 4326) NOT NULL, prefecture text NOT NULL, municipality text NOT NULL, pref_muni text GENERATED ALWAYS AS (prefecture || municipality) STORED, created_at timestamp with time zone DEFAULT timezone('utc'::text, now()) NOT NULL, updated_at timestamp with time zone DEFAULT timezone('utc'::text, now()) NOT NULL ); CREATE INDEX spot_location_idx ON spot_opendata USING GIST (location); CREATE INDEX spot_pref_idx ON spot_opendata (prefecture); CREATE INDEX spot_muni_idx ON spot_opendata (municipality); CREATE INDEX spot_pref_muni_idx ON spot_opendata (pref_muni); 18
ALTER TABLE spot_opendata ADD COLUMN ft_text text GENERATED ALWAYS AS (title || ',' || describe || ',' || prefecture || municipality) STORED; CREATE INDEX pgroonga_content_index ON spot_opendata USING pgroonga (ft_text) WITH (tokenizer='TokenMecab'); 19
dist_limit = -1 AND keywords = '' THEN false ELSE true END) AND (CASE WHEN dist_limit = -1 THEN true ELSE (ST_POINT(point_longitude, point_latitude)::geography <-> spot_opendata.location::geography) <= dist_limit END) AND (CASE WHEN category_id_number = -1 THEN true ELSE category.id = category_id_number END) AND (CASE WHEN keywords = '' THEN true ELSE ft_text &@~ keywords END) ORDER BY distance; END; $$ LANGUAGE plpgsql; 22
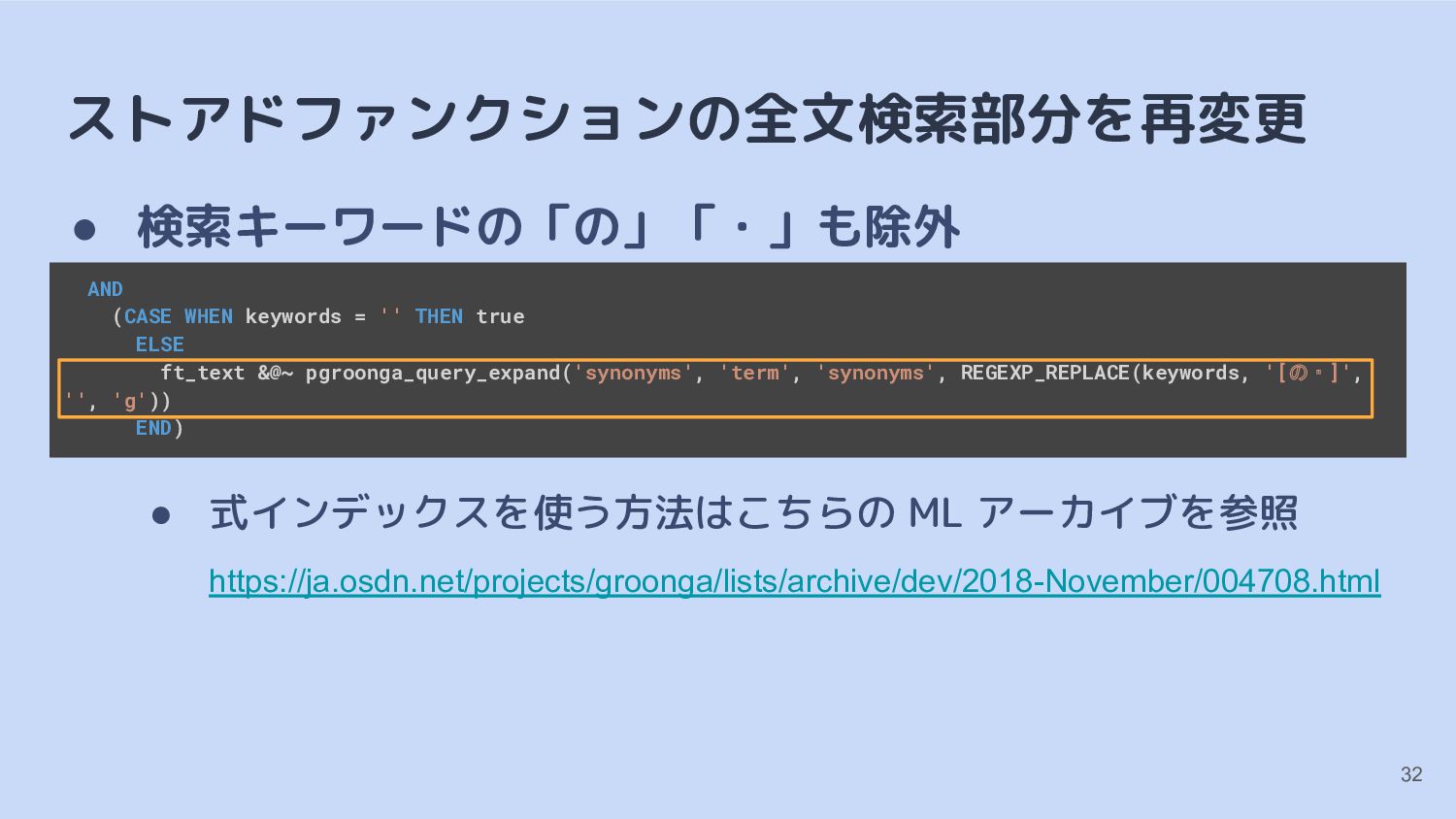
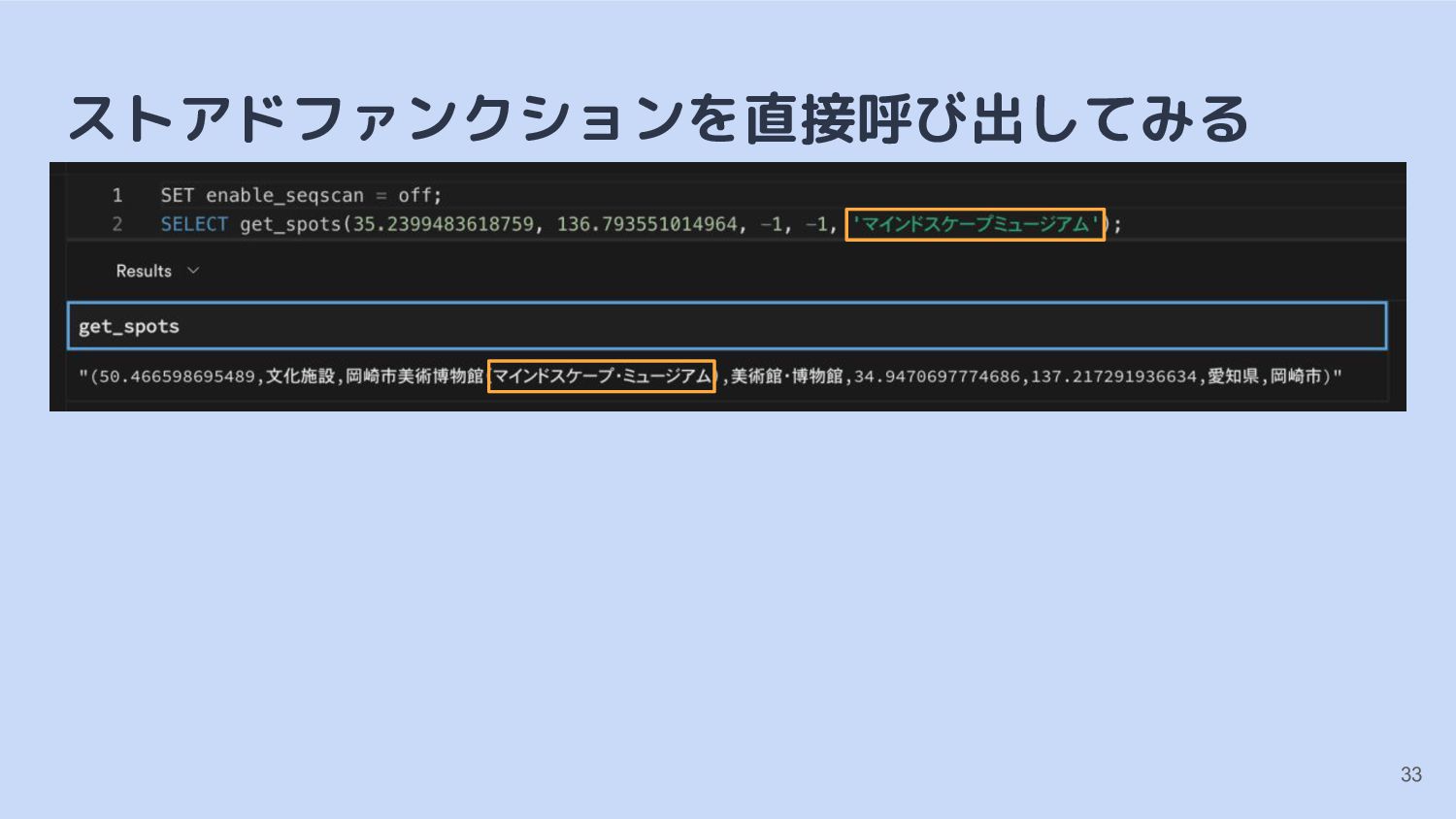
INDEX pgroonga_content_index; ALTER TABLE spot_opendata DROP COLUMN ft_text, ADD COLUMN ft_text text GENERATED ALWAYS AS (REGEXP_REPLACE((title || ',' || describe || ',' || prefecture || municipality), '[の・]', '', 'g')) STORED; CREATE INDEX pgroonga_content_index ON spot_opendata USING pgroonga (ft_text) WITH (tokenizer='TokenMecab'); 31
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
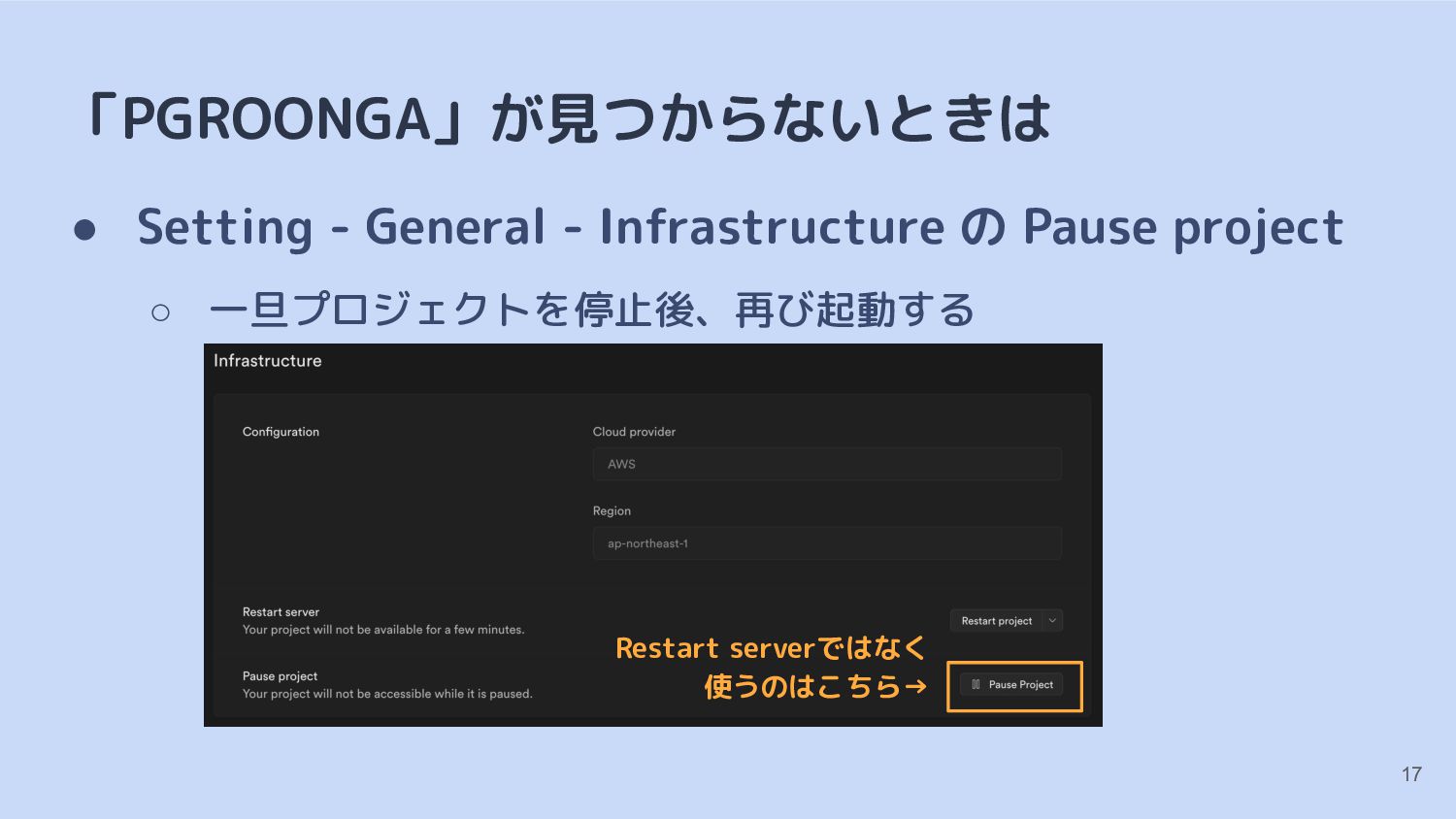{kind=link}
{kind=link}
{kind=link}
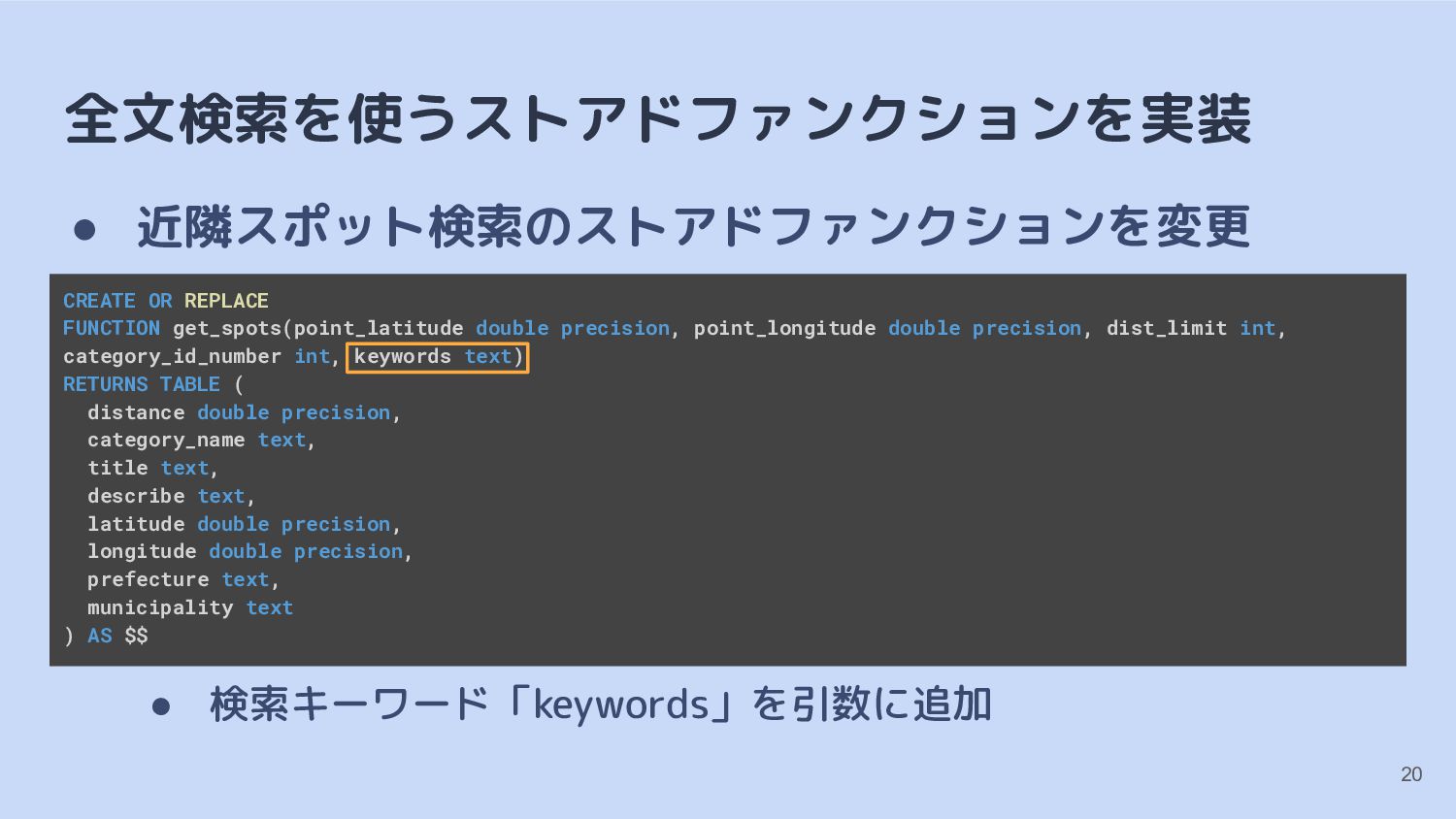{kind=link}
{kind=link}
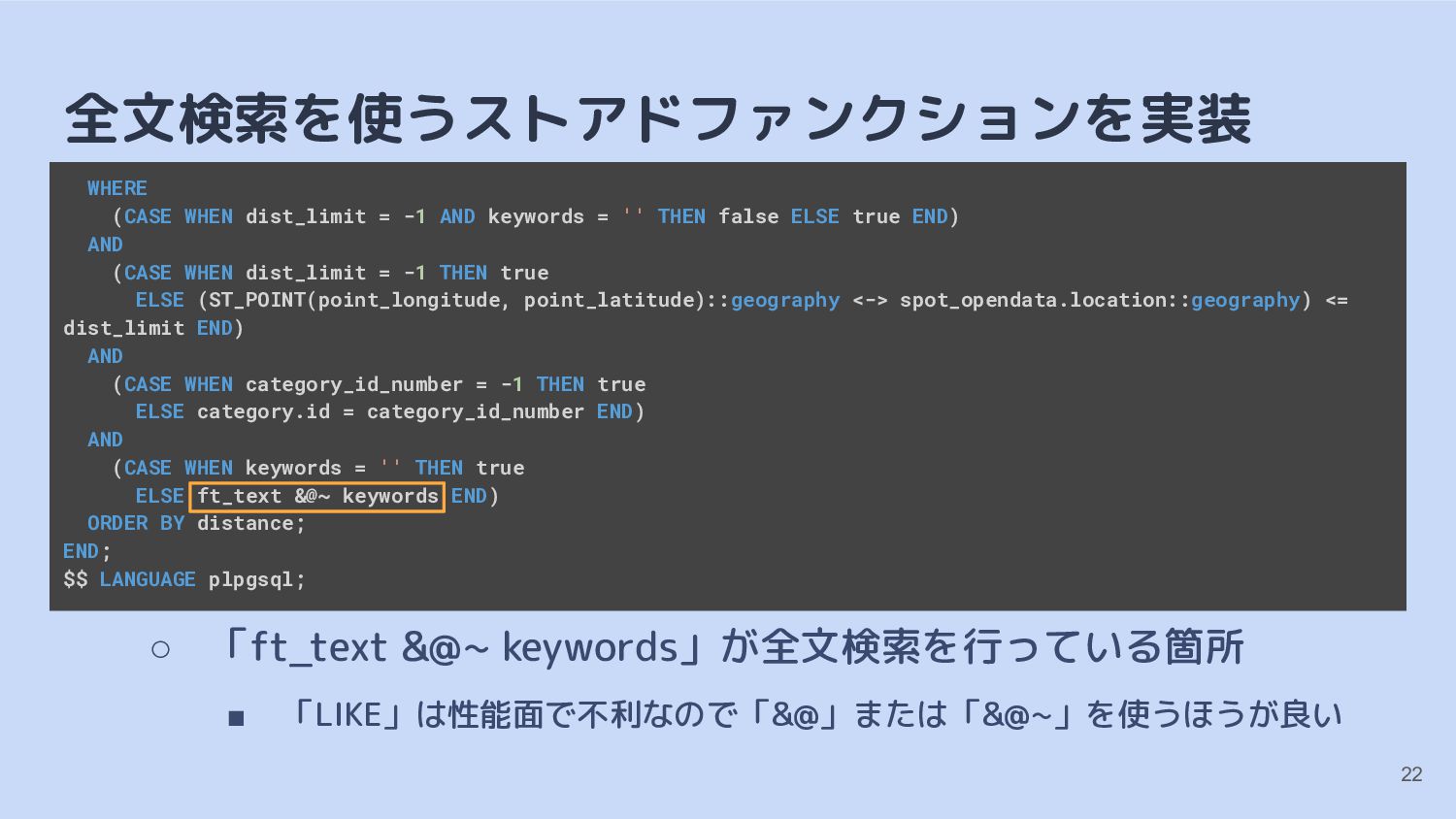{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}