Mein Vortrag am Global Azure Bootcamp 2015 in Linz.
Das Apache Spark Projekt hat 2014 einen enormen Aufschwung erfahren und stark an Popularität zugelegt. Besonders in der Machine Learning & Data Science Szene wird Spark als "besseres Hadoop" gehandelt und gilt derzeit als unverzichtbarer Bestandteil zur Umsetzung iterativer und interaktiver Analyseszenarien in Cluster bzw. Cloud Umgebungen. In dieser Session wird gezeigt, welche Vorteile Apache Spark bietet und wie man durch Customization mit Script Actions einen Spark Cluster in Azure auf Basis von HDInsight erstellen kann, um verteilte Datenanalysen verschiedenster Art in Microsoft Azure damit durchführen zu können.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
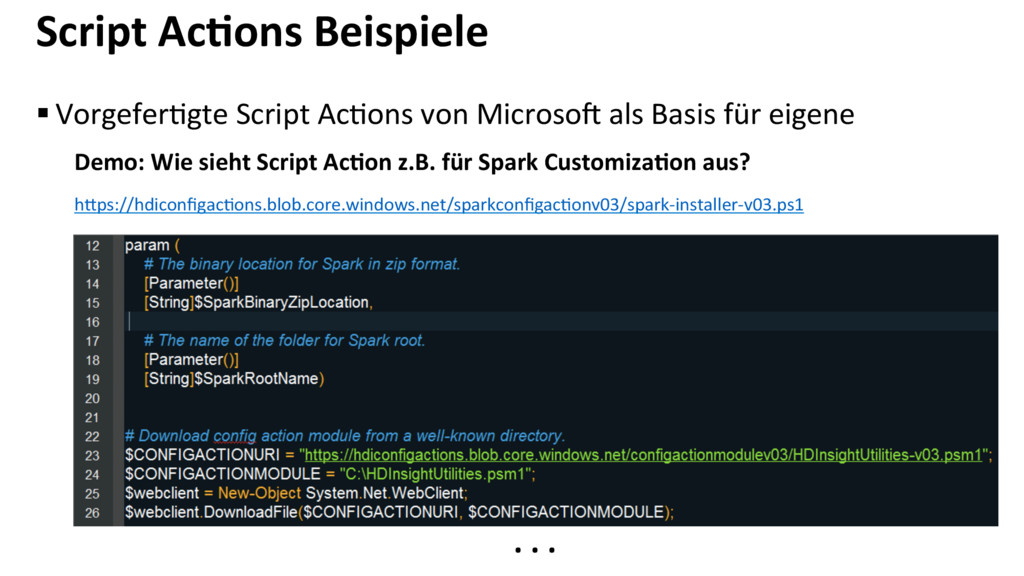{kind=link}
{kind=link}
{kind=link}
{kind=link}
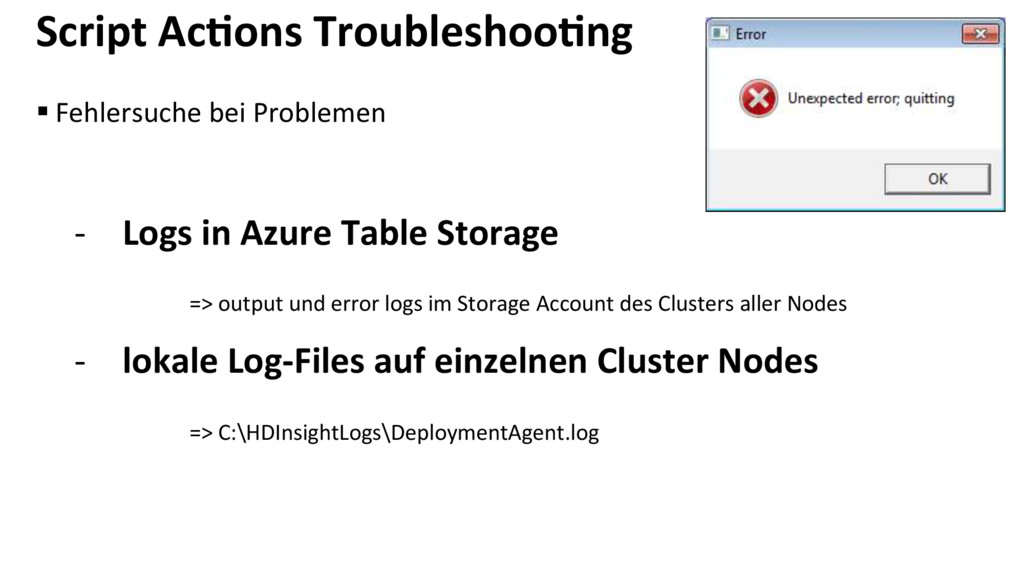{kind=link}
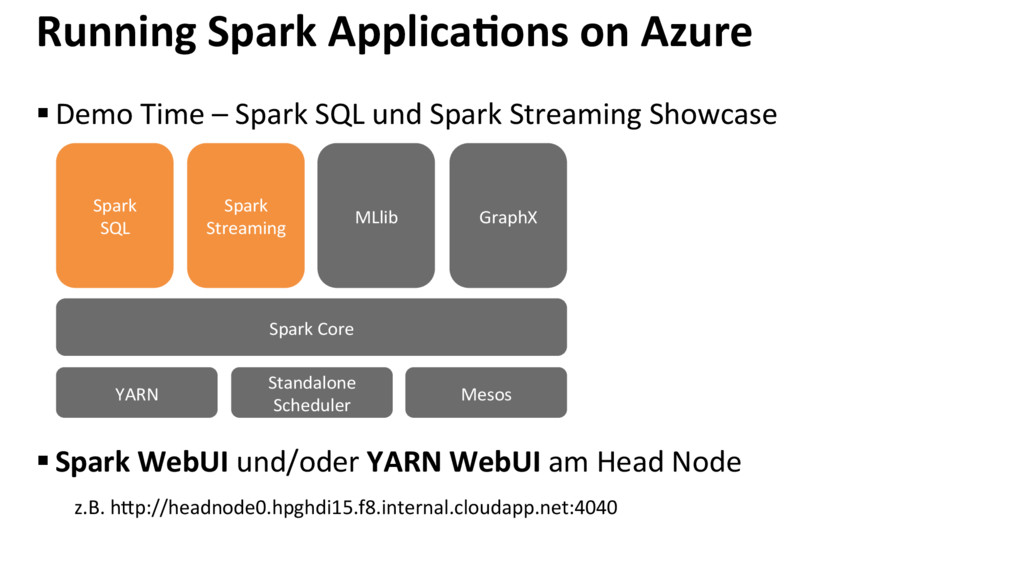{kind=link}
{kind=link}
{kind=link}
![Kontakt Hans-‐Peter Grahsl [email protected] +43 650](https://files.speakerdeck.com/presentations/f4471488a20147b3a2a90ae15816eb05/slide_24.jpg){kind=link}