Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【ClickHouseMeetup】JSON データ型はクラウド時代の可変フィールドにと...
Search
Hisashi Hibino
March 12, 2025
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【ClickHouseMeetup】JSON データ型はクラウド時代の可変フィールドにどこまで対応できるのか
ClickHouse Meetup 2025/03
Hisashi Hibino
March 12, 2025
More Decks by Hisashi Hibino
See All by Hisashi Hibino
【Cyber-sec+】経営層を"動かす"ための考え方
hssh2_bin
0
220
【ClickHouseMeetup】LibreChat × ClickHouse プロンプトキャッシュ機能の効果とその仕組み
hssh2_bin
0
110
【ClickHouseMeetup】ClickHouseを活用したセキュリティログ解析AIエージェント『LogEater』とは
hssh2_bin
0
480
【インフラエンジニアbooks】30分でわかる「AWS継続的セキュリティ実践ガイド」
hssh2_bin
10
2.6k
【ログ分析勉強会】EDR ログで内部不正を検出できるのか、Copilot に聞いてみた
hssh2_bin
2
1.5k
【OpsJAWS】踏み台サーバーって何がうれしいんだっけ?
hssh2_bin
14
6.2k
【Cyber-sec+】ログの森で出会った CloudTrail との奇妙な旅
hssh2_bin
1
780
【OpsJAWS】EC2 のセキュリティの運用と監視について考えてみた件
hssh2_bin
7
1.4k
【SecurityJAWS】時間切れで書き切れなかったOCSFの行く末とは
hssh2_bin
2
2.5k
Other Decks in Technology
See All in Technology
Network Firewallやっていき!
news_it_enj
0
170
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
1
580
世界、断片、モデル。そして理解
ardbeg1958
1
130
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
410
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
280
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
0
200
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
220
公式ドキュメントの歩き方etc
coco_se
1
120
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
290
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
420
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Statistics for Hackers
jakevdp
799
230k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
The Curse of the Amulet
leimatthew05
2
13k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
The Curious Case for Waylosing
cassininazir
1
430
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
320
Large-scale JavaScript Application Architecture
addyosmani
515
110k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Speed Design
sergeychernyshev
33
1.9k
Transcript
JSON データ型はクラウド時代の可変フィールドに どこまで対応できるのか? Hisashi Hibino / 日比野 恒 ログスペクト株式会社
本日のテーマ • Beta Feature である JSON Data Type の機能検証で得られた知見を共有します。 2
【参考】JSON Data Type: https://clickhouse.com/docs/sql-reference/data-types/newjson
1. 背景と目的 2. 検証内容 3. 総括 アジェンダ 3
自己紹介 日比野 恒 - Hisashi Hibino ログスペクト株式会社 Security Architect CISSP,
CCSP, CISA, PMP, 情報処理安全確保支援士(000999) [書籍] ➢ Elastic Stack 実践ガイド [Logstash/Beats 編](インプレス刊) ➢ AWS 継続的セキュリティ実践ガイド (翔泳社刊) [略歴] ⚫ 2018 年まで 10 年間 フューチャーアーキテクト株式会社に在籍 ⚫ 2019 年より株式会社リクルートのセキュリティ組織に所属 ログ基盤やクラウドセキュリティに関するプロジェクトを推進 ⚫ 2024 年にログスペクト株式会社を設立し、現在に至る 4
01 背景と目的
わたしのログにまつわるこれまでの歴史 6 3. 総括 2. 検証内容 1. 背景と目的 ❶ ログ黎明期
(2015 - 2018 年) ❷ ログ幻滅期 (2019 - 2021 年) ❸ ログ啓蒙活動期 (2022 - 2024 年) • 2015 年に Elastic Stack にハマるも Splunk をかじりつつ、次第に DWH 系サービスに魅了されていきました。 (各サービスにそれぞれの良さがあり、一方ではビジネス的な課題もあったため、常により良いものを求め続けて今に至ります)
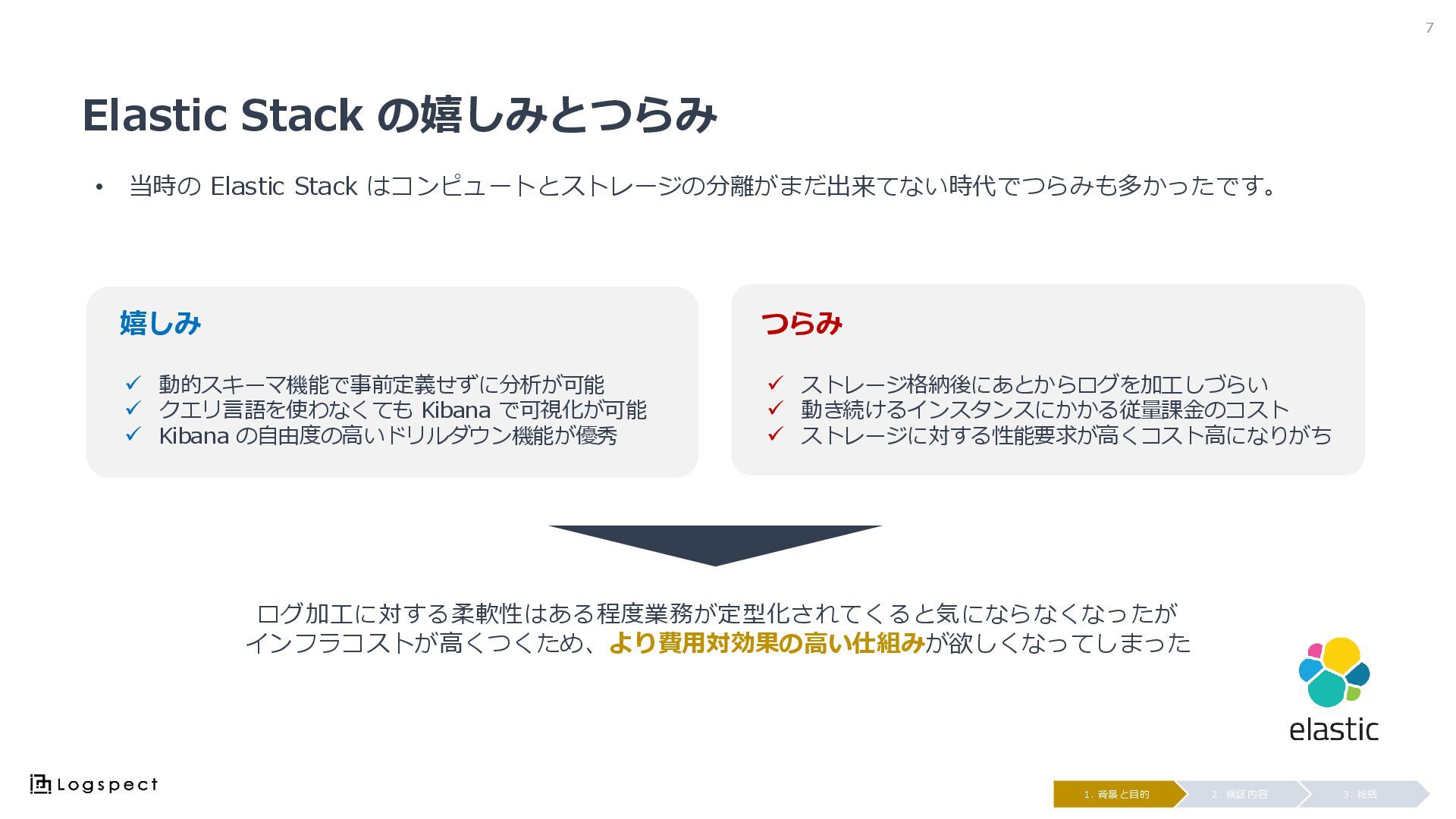
Elastic Stack の嬉しみとつらみ • 当時の Elastic Stack はコンピュートとストレージの分離がまだ出来てない時代でつらみも多かったです。 7 3.
総括 2. 検証内容 1. 背景と目的 ✓ 動的スキーマ機能で事前定義せずに分析が可能 ✓ クエリ言語を使わなくても Kibana で可視化が可能 ✓ Kibana の自由度の高いドリルダウン機能が優秀 ✓ ストレージ格納後にあとからログを加工しづらい ✓ 動き続けるインスタンスにかかる従量課金のコスト ✓ ストレージに対する性能要求が高くコスト高になりがち 嬉しみ つらみ ログ加工に対する柔軟性はある程度業務が定型化されてくると気にならなくなったが インフラコストが高くつくため、より費用対効果の高い仕組みが欲しくなってしまった
Splunk の嬉しみとつらみ • 若干、寄り道的な出会いでしたが、Elastic Stack とのアーキテクチャ的な違いを学ぶ良い機会となりました。 8 3. 総括 2.
検証内容 1. 背景と目的 ✓ 完全スキーマレスなため、ログ取り込み負荷が低い ✓ クエリ言語(SPL)が強力で大抵の処理は実装可能 ✓ クエリ時点であとからログを加工できる柔軟性が高い ✓ 前処理によるフィルタが弱く不要なログにライセンス料 がかかり高コストになりがち ✓ クエリ言語が Splunk 独自なために習得コストが高い ログの処理に特化したクエリ言語である SPL が優秀で、あとからでも多くの処理が可能で 使いこなせると生産性は高まるが、使いこなせる人を揃えることがボトルネックとなってしまう 嬉しみ つらみ
BigQuery & Looker の嬉しみとつらみ • 汎用性の高い SQL とクエリ課金によるコスト抑制を期待し、Google Cloud のソリューションを試してみました。
9 3. 総括 2. 検証内容 1. 背景と目的 ✓ SQL は SPL に比べて人口が多く人材は確保しやすい ✓ 列指向型ストレージのため、クエリ性能が期待できる ✓ クエリ課金のため、無駄なコストの抑制が効きやすい ✓ スキーマを事前定義する必要がありアドホックしづらい ✓ ログフォーマットの変更に追随しづらく保守負荷が高い ✓ 利用者が無邪気にクエリしまくると課金爆発が起こる 嬉しみ つらみ 特にアプリケーションの機能追加によるログのフィールド追加に対応するために DWH のテーブルを作り直し、古いバージョンのテーブルと縦結合する修正が必要となった
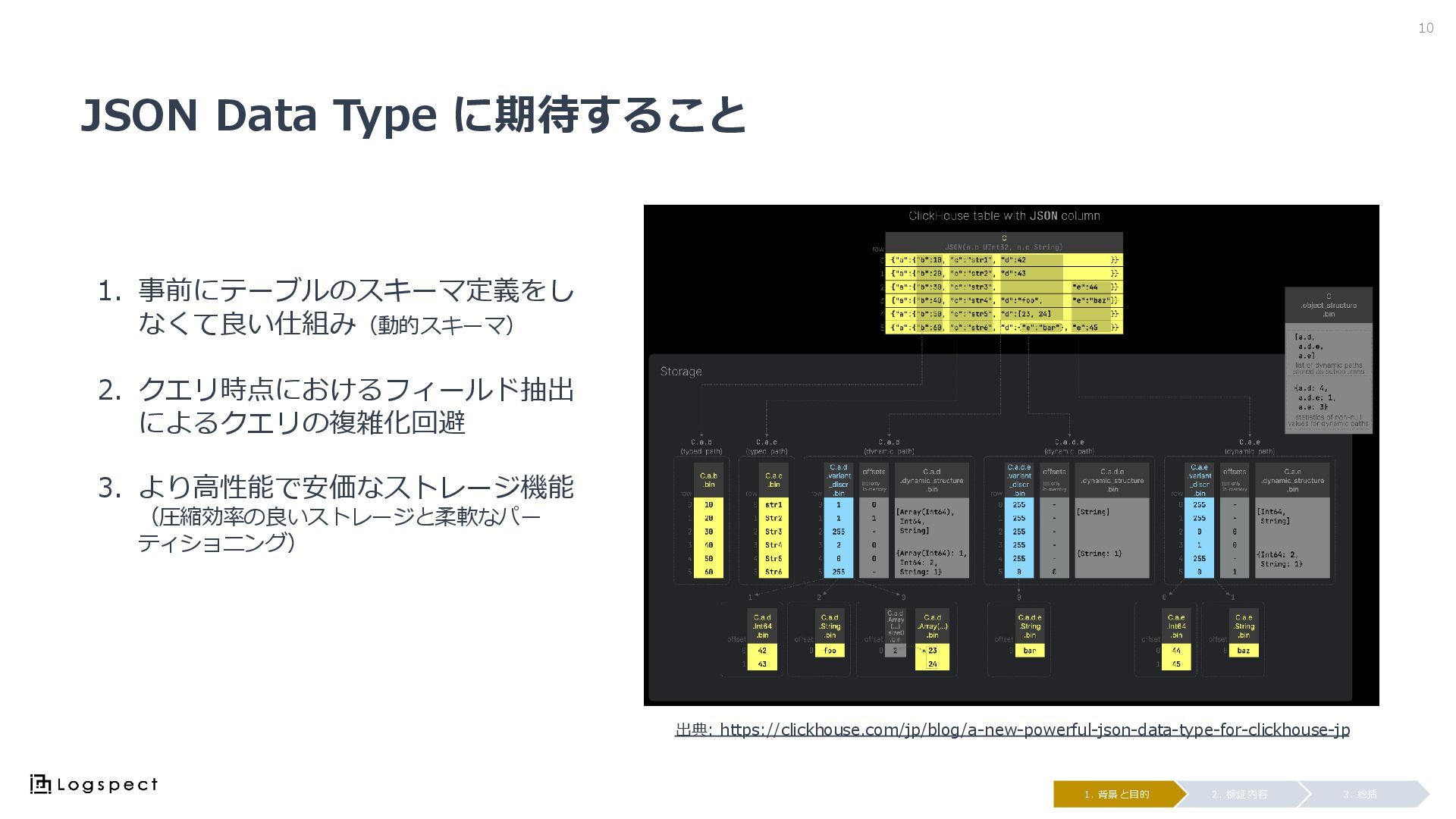
JSON Data Type に期待すること 10 3. 総括 2. 検証内容 1.
背景と目的 1. 事前にテーブルのスキーマ定義をし なくて良い仕組み(動的スキーマ) 2. クエリ時点におけるフィールド抽出 によるクエリの複雑化回避 3. より高性能で安価なストレージ機能 (圧縮効率の良いストレージと柔軟なパー ティショニング) 出典: https://clickhouse.com/jp/blog/a-new-powerful-json-data-type-for-clickhouse-jp
他製品との差で期待するのはクエリ性能になってくる 11 3. 総括 2. 検証内容 1. 背景と目的 【Snowflake】半構造化データのクエリ https://docs.snowflake.com/ja/user-guide/querying-semistructured
【databricks】JSON 文字列のクエリ https://docs.databricks.com/aws/ja/semi-structured/json 【Google BigQuery】Google SQL での JSON データの操作 https://cloud.google.com/bigquery/docs/json-data?hl=ja 【AWS RedShift】半構造化データのクエリ https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/query-super.html 【PostgreSQL】JSON データ型 https://www.postgresql.jp/docs/12/datatype-json.html 【MySQL】The JSON Data Type https://dev.mysql.com/doc/refman/8.4/en/json.html
02 検証内容
実施内容 • 以下の内容で ClickHouse の機能検証を実施しました。 13 3. 総括 2. 検証内容
1. 背景と目的 1. JSON Data Type に対するクエリをテストするため、ndjson 形式のログを取り込む 2. 継続的にログの取り込みをおこなうため、ClickPipes でパイプラインを作成する 3. サンプルログとして AWS CloudTrail の監査ログを利用する
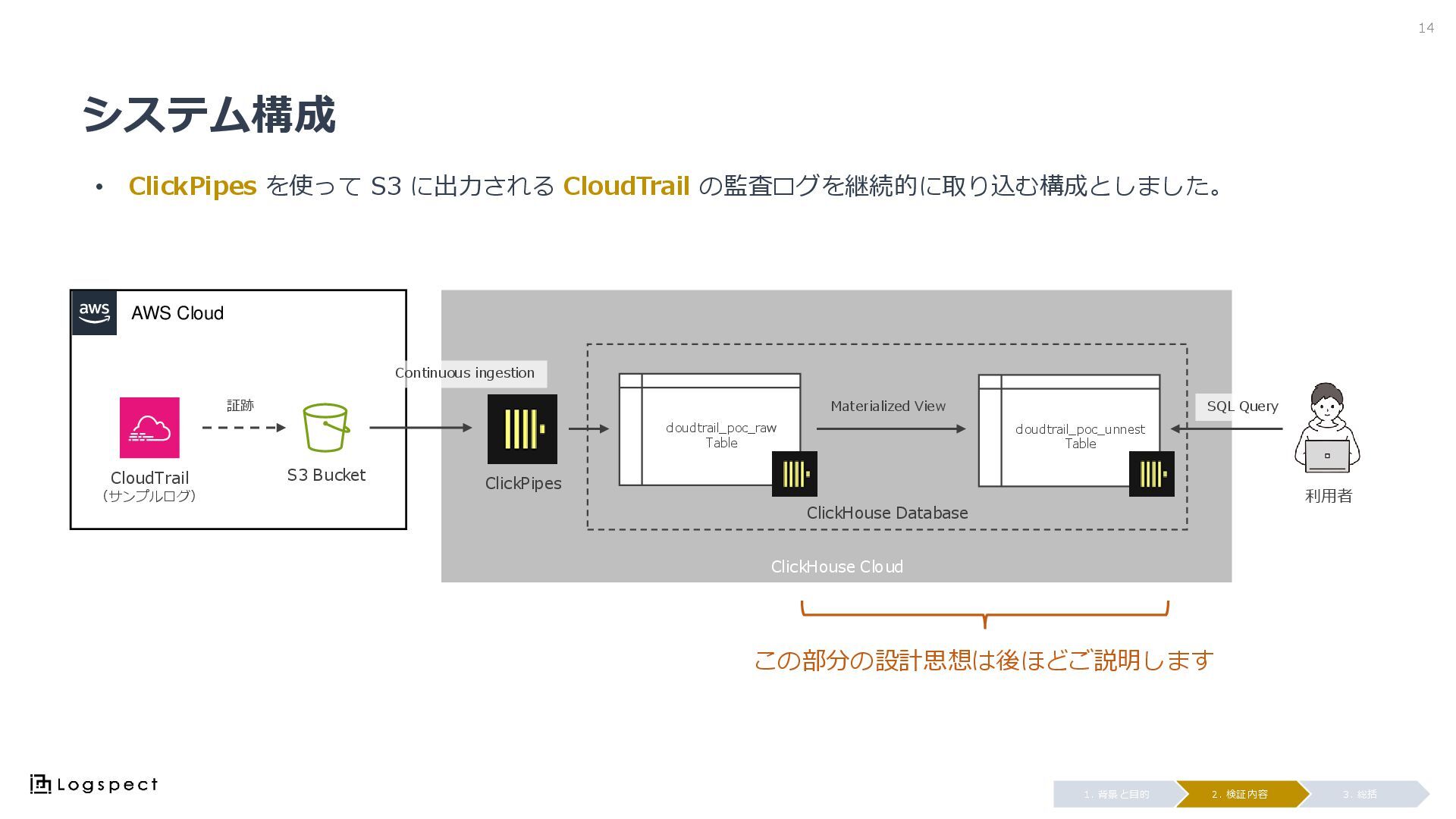
システム構成 • ClickPipes を使って S3 に出力される CloudTrail の監査ログを継続的に取り込む構成としました。 14 3.
総括 2. 検証内容 1. 背景と目的 AWS Cloud CloudTrail (サンプルログ) S3 Bucket 証跡 ClickHouse Cloud ClickPipes cloudtrail_poc_raw Table cloudtrail_poc_unnest Table ClickHouse Database Materialized View SQL Query 利用者 この部分の設計思想は後ほどご説明します Continuous ingestion
【参考】 S3 に出力される CloudTrail 監査ログは 15 3. 総括 2. 検証内容
1. 背景と目的 • イベント名によってフィールド構造の異なる ndjson(1 行に複数イベントが格納されることがあります)です。 イベント 1 イベント 2 , Field Name: [ ] イベント 3 , 【主な特徴】 • ndjson (配列オブジェクト) • ネスト構造のフィールドあり • フィールドは可変する • 値に配列あり
テーブル作成 • S3 から CloudTrail の監査ログを取り込むための生ログ用テーブルを作成します。 16 3. 総括 2.
検証内容 1. 背景と目的 -- S3 からログを取り込むための生ログ用テーブルの作成 CREATE TABLE default.cloudtrail_poc_raw ( `Records` Array(JSON) ) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192 SETTINGS allow_experimental_json_type = 1; # JSON Data Type の有効化 # JSON の配列型で Records フィールドの定義 # cloudtrail_poc_raw テーブルの作成
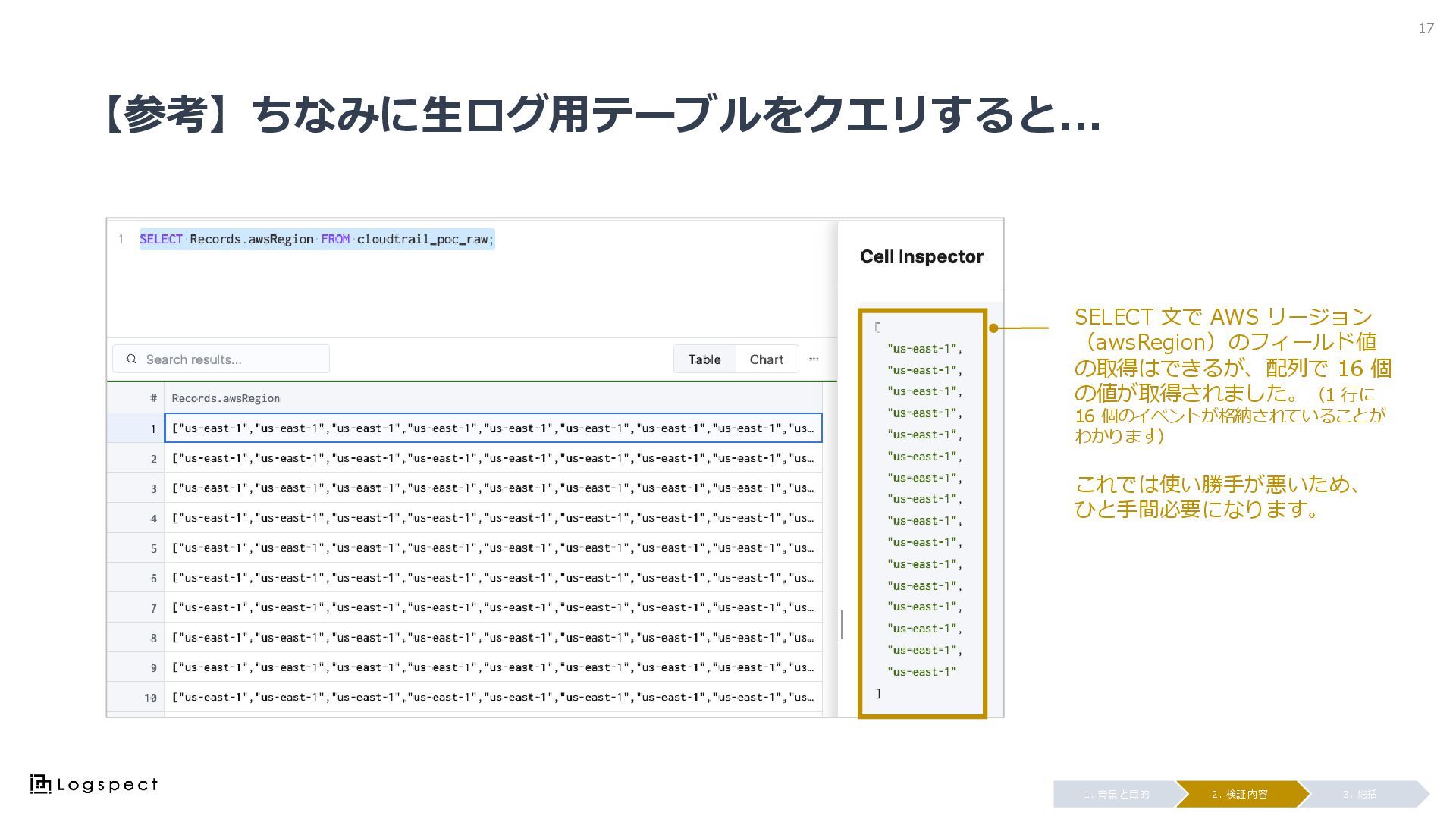
【参考】ちなみに生ログ用テーブルをクエリすると... 17 3. 総括 2. 検証内容 1. 背景と目的 SELECT 文で
AWS リージョン (awsRegion)のフィールド値 の取得はできるが、配列で 16 個 の値が取得されました。(1 行に 16 個のイベントが格納されていることが わかります) これでは使い勝手が悪いため、 ひと手間必要になります。
マテリアライズドビューの作成 • マテリアライズドビューで生ログ用テーブルに格納された JSON イベントの配列構造を分解します。 18 3. 総括 2. 検証内容
1. 背景と目的 -- 分割したレコードを格納するテーブルの作成 CREATE TABLE default.cloudtrail_poc_unnest ( `Records` JSON ) ORDER BY tuple(); SETTINGS allow_experimental_json_type = 1; -- マテリアライズドビューによるレコードの分割 CREATE MATERIALIZED VIEW cloudtrail_poc_mv TO cloudtrail_poc_unnest AS SELECT arrayJoin(Records) AS Records FROM cloudtrail_poc_raw; # 今回は配列ではないため、単なる JSON 型で定義 # JSON Data Type の有効化 # cloudtrail_poc_unnest テーブルの作成 # 生ログ用テーブルの Records フィールドを UNNEST 化
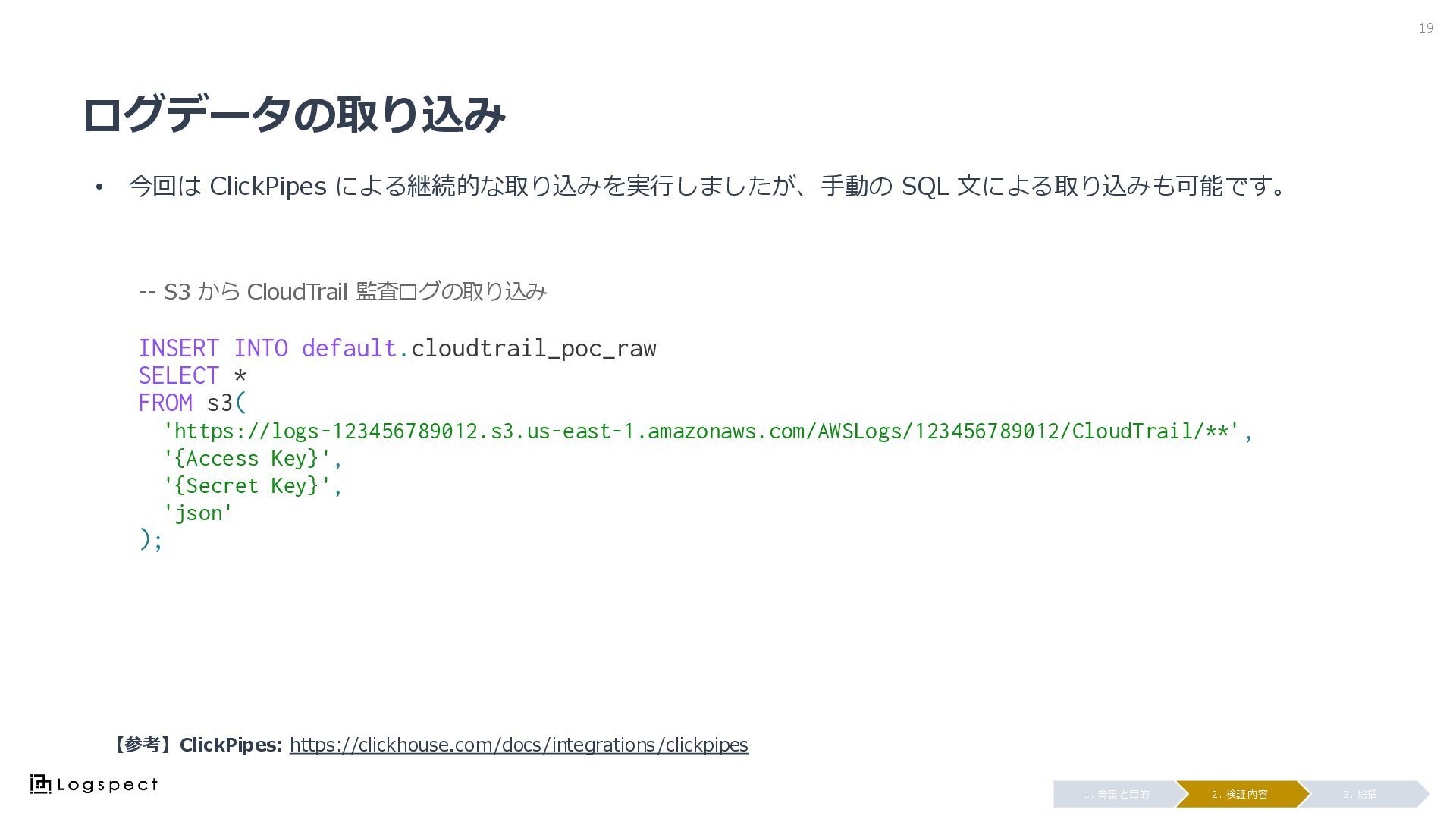
ログデータの取り込み • 今回は ClickPipes による継続的な取り込みを実行しましたが、手動の SQL 文による取り込みも可能です。 19 3. 総括
2. 検証内容 1. 背景と目的 -- S3 から CloudTrail 監査ログの取り込み INSERT INTO default.cloudtrail_poc_raw SELECT * FROM s3( 'https://logs-123456789012.s3.us-east-1.amazonaws.com/AWSLogs/123456789012/CloudTrail/**', '{Access Key}', '{Secret Key}', 'json' ); 【参考】ClickPipes: https://clickhouse.com/docs/integrations/clickpipes
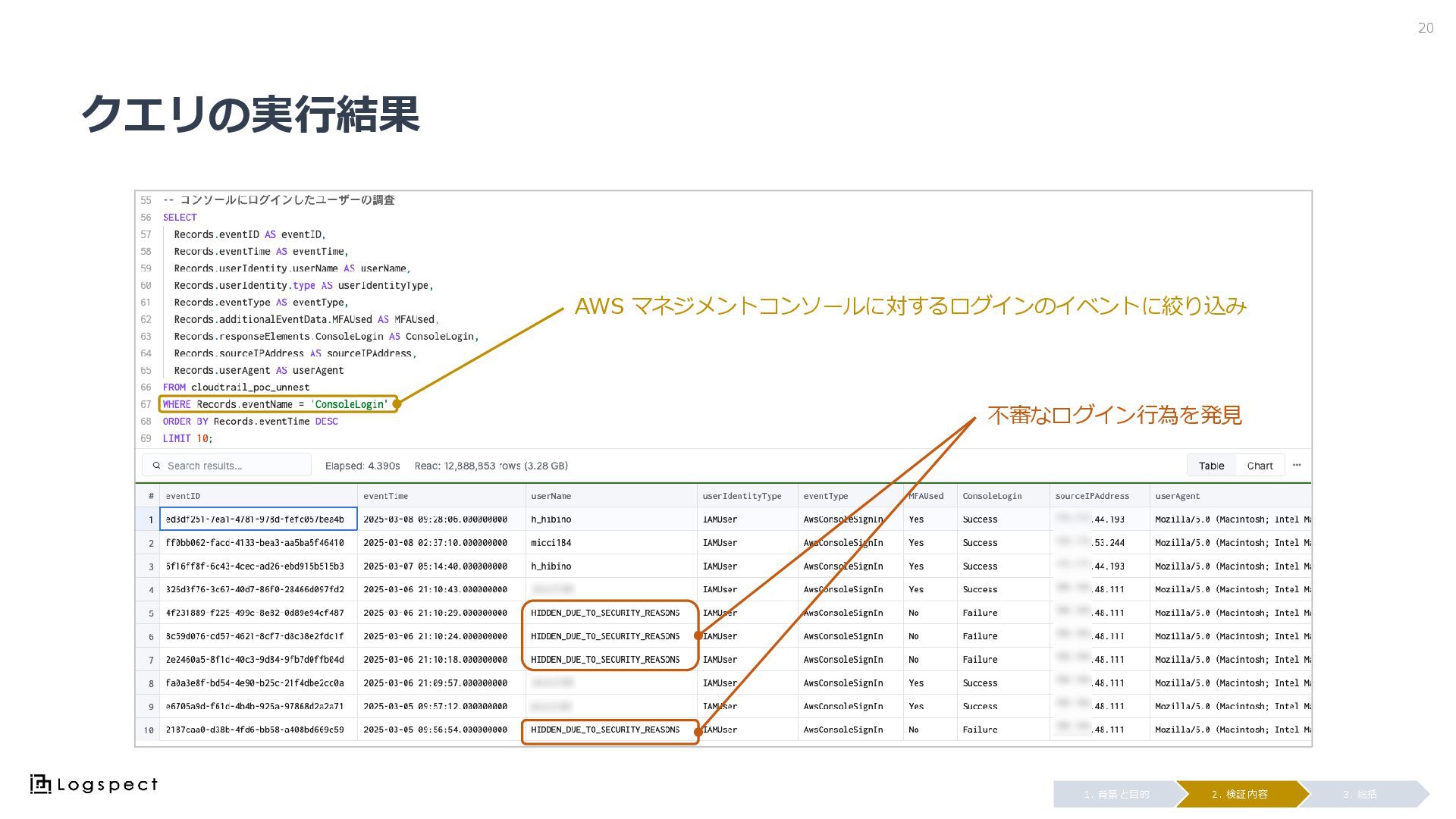
クエリの実行結果 20 3. 総括 2. 検証内容 1. 背景と目的 AWS マネジメントコンソールに対するログインのイベントに絞り込み
不審なログイン行為を発見
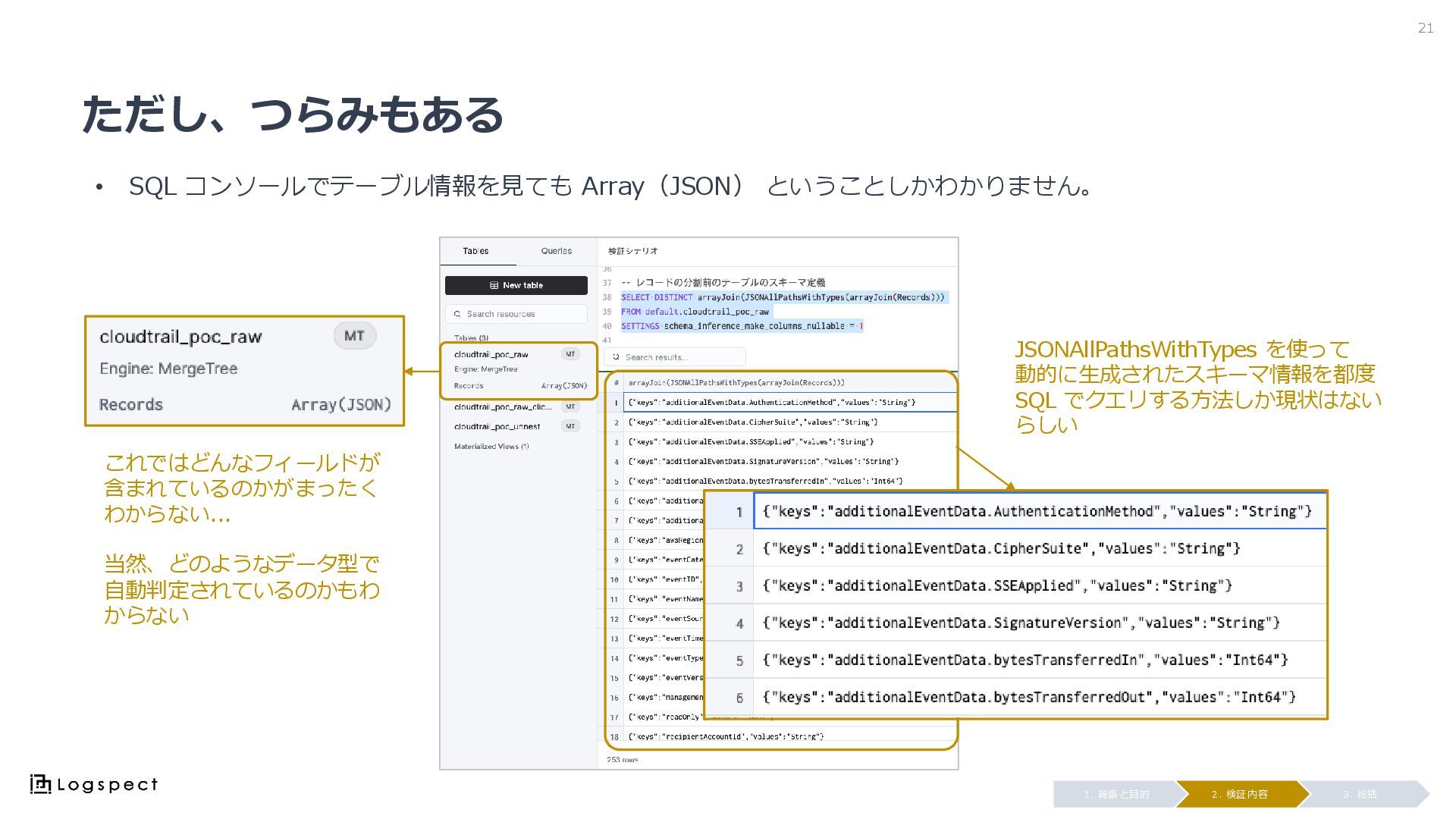
ただし、つらみもある 21 3. 総括 2. 検証内容 1. 背景と目的 JSONAllPathsWithTypes を使って
動的に生成されたスキーマ情報を都度 SQL でクエリする方法しか現状はない らしい これではどんなフィールドが 含まれているのかがまったく わからない... 当然、どのようなデータ型で 自動判定されているのかもわ からない • SQL コンソールでテーブル情報を見ても Array(JSON) ということしかわかりません。
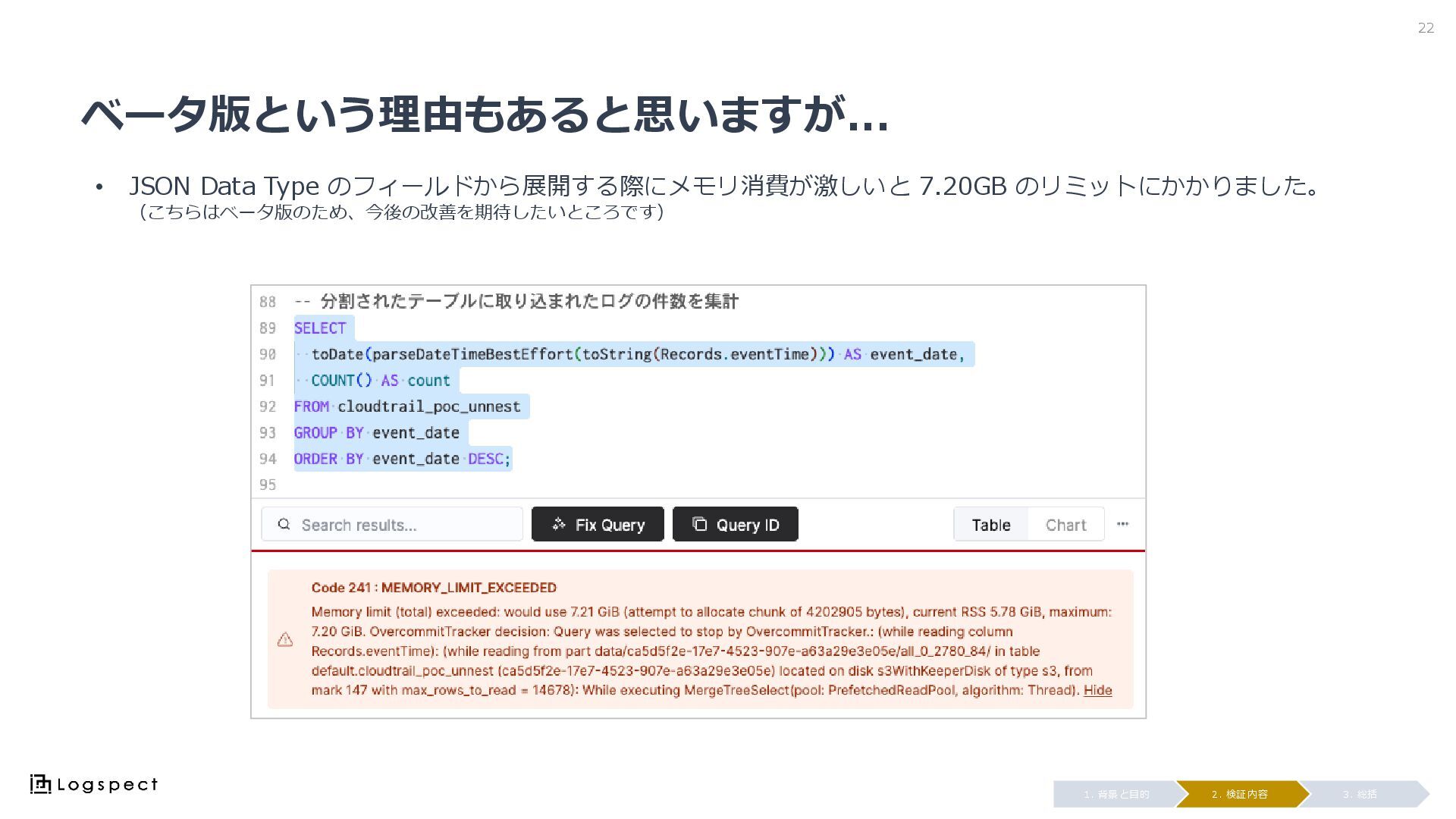
ベータ版という理由もあると思いますが... 22 3. 総括 2. 検証内容 1. 背景と目的 • JSON
Data Type のフィールドから展開する際にメモリ消費が激しいと 7.20GB のリミットにかかりました。 (こちらはベータ版のため、今後の改善を期待したいところです)
03 総括
検証結果のまとめ 3. 総括 2. 検証内容 1. 背景と目的 24 ✓ 確認できたこと
✓ JSON Parse 処理をせずとも ndjson 形式のログに対する SQL クエリが実行できた ✓ ClickPipes を利用することで継続的に S3 からログの取り込みができた ✓ 改善してほしいこと ✓ JSON Data Type を利用するとテーブル情報(スキーマ定義など)が把握しづらい (やはり Kibana はアドホック分析をする上で非常に優れたツールだった) ✓ JSON Data Type を利用すると Null Table を有効化できないため、データの重複持ちになってしまう (マテリアライズドビューを利用した場合の元テーブルの書き込みを無効化できないため) ✓ 今後検証したいこと ✓ Terraform を利用した IaC 化によるコード化・オペレーションの自動化 ✓ 大量のログに対するクエリ性能テストと性能チューニング ✓ IP アドレスに GEO 情報(特に国名情報)を付加して日本以外からのアクセスの可視化
ご清聴ありがとうございました
26 Appendix
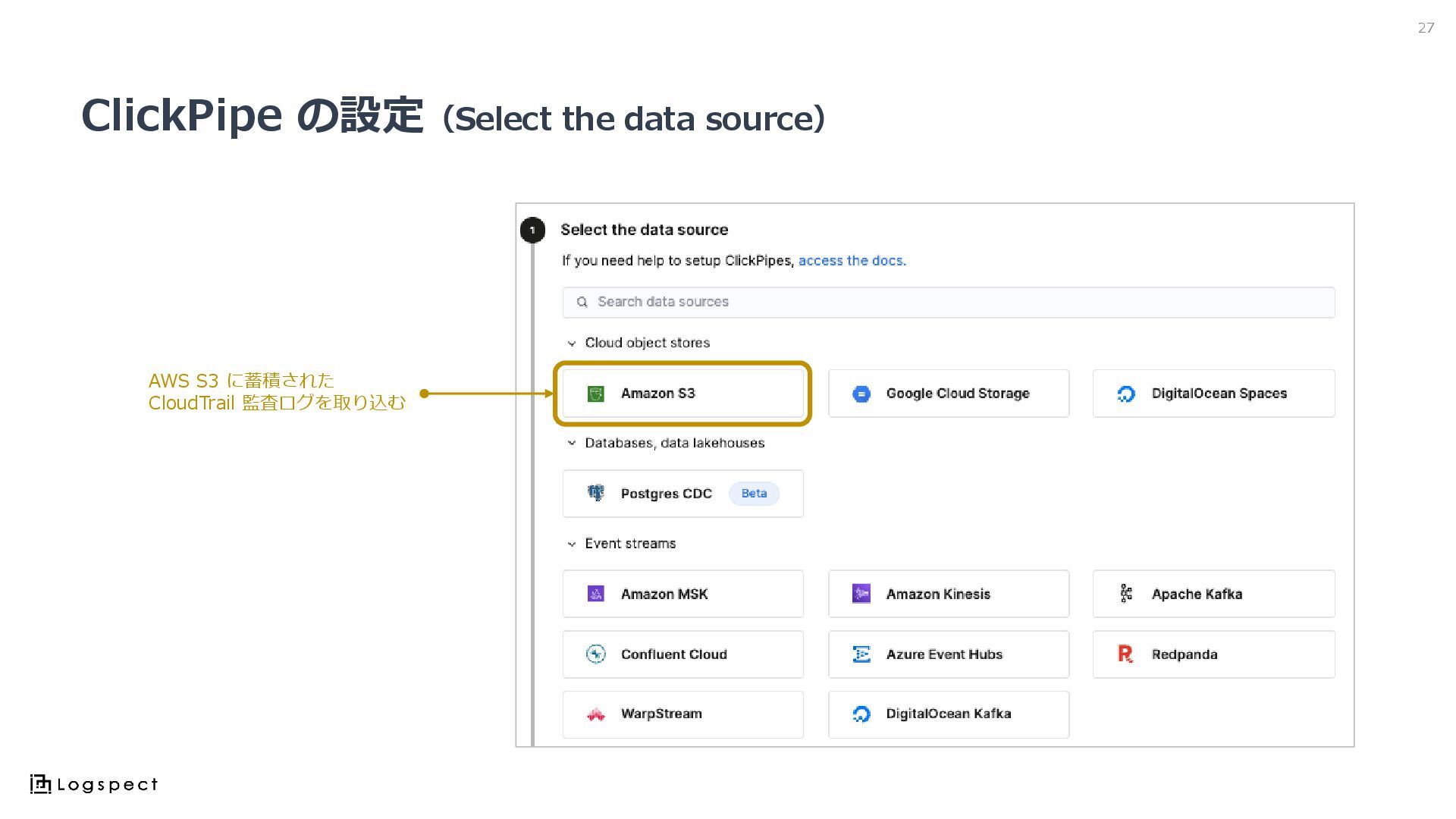
ClickPipe の設定(Select the data source) 27 AWS S3 に蓄積された CloudTrail
監査ログを取り込む
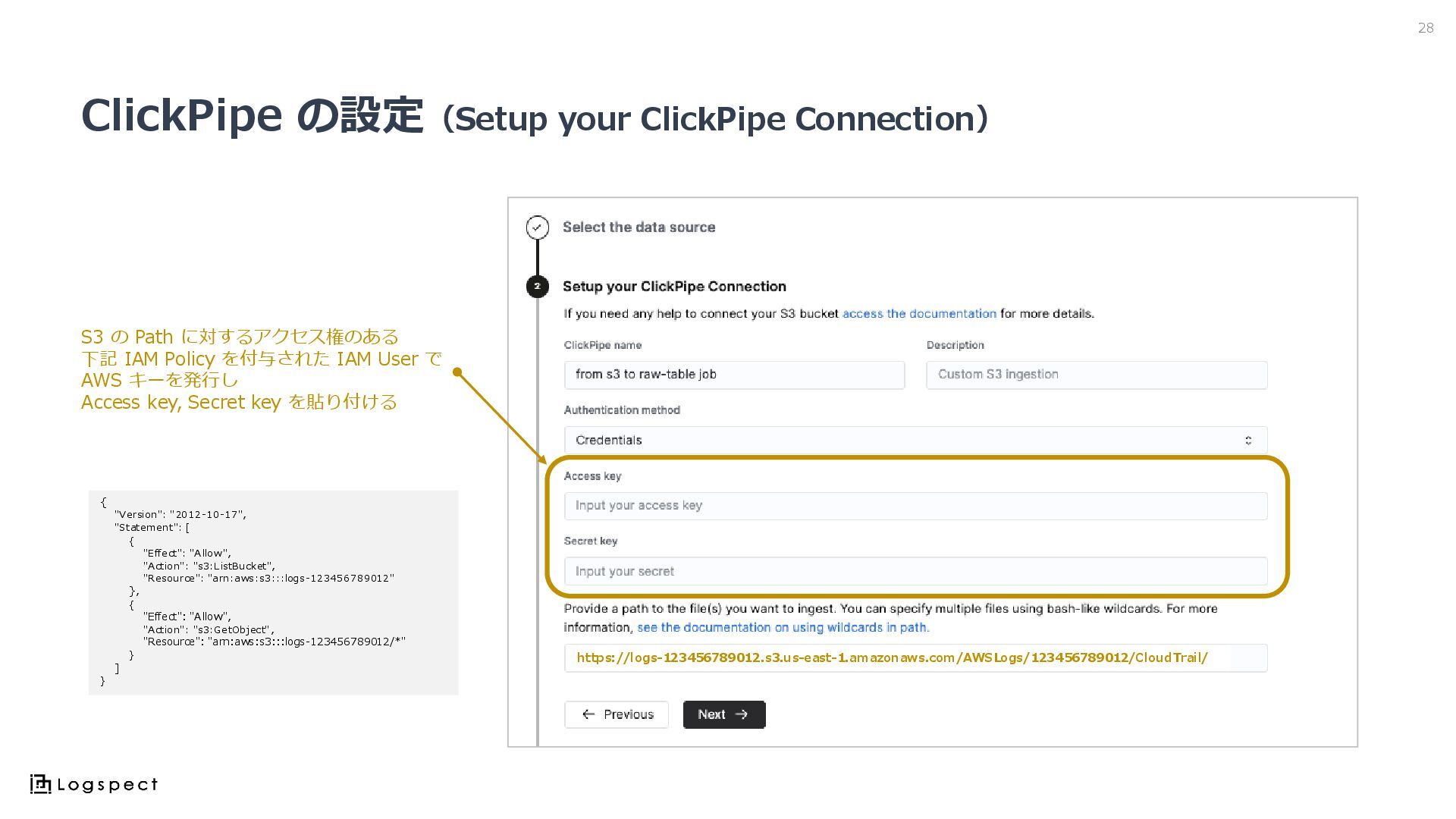
ClickPipe の設定(Setup your ClickPipe Connection) 28 { "Version": "2012-10-17", "Statement":
[ { "Effect": "Allow", "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::logs-123456789012" }, { "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::logs-123456789012/*" } ] } S3 の Path に対するアクセス権のある 下記 IAM Policy を付与された IAM User で AWS キーを発行し Access key, Secret key を貼り付ける https://logs-123456789012.s3.us-east-1.amazonaws.com/AWSLogs/123456789012/CloudTrail/
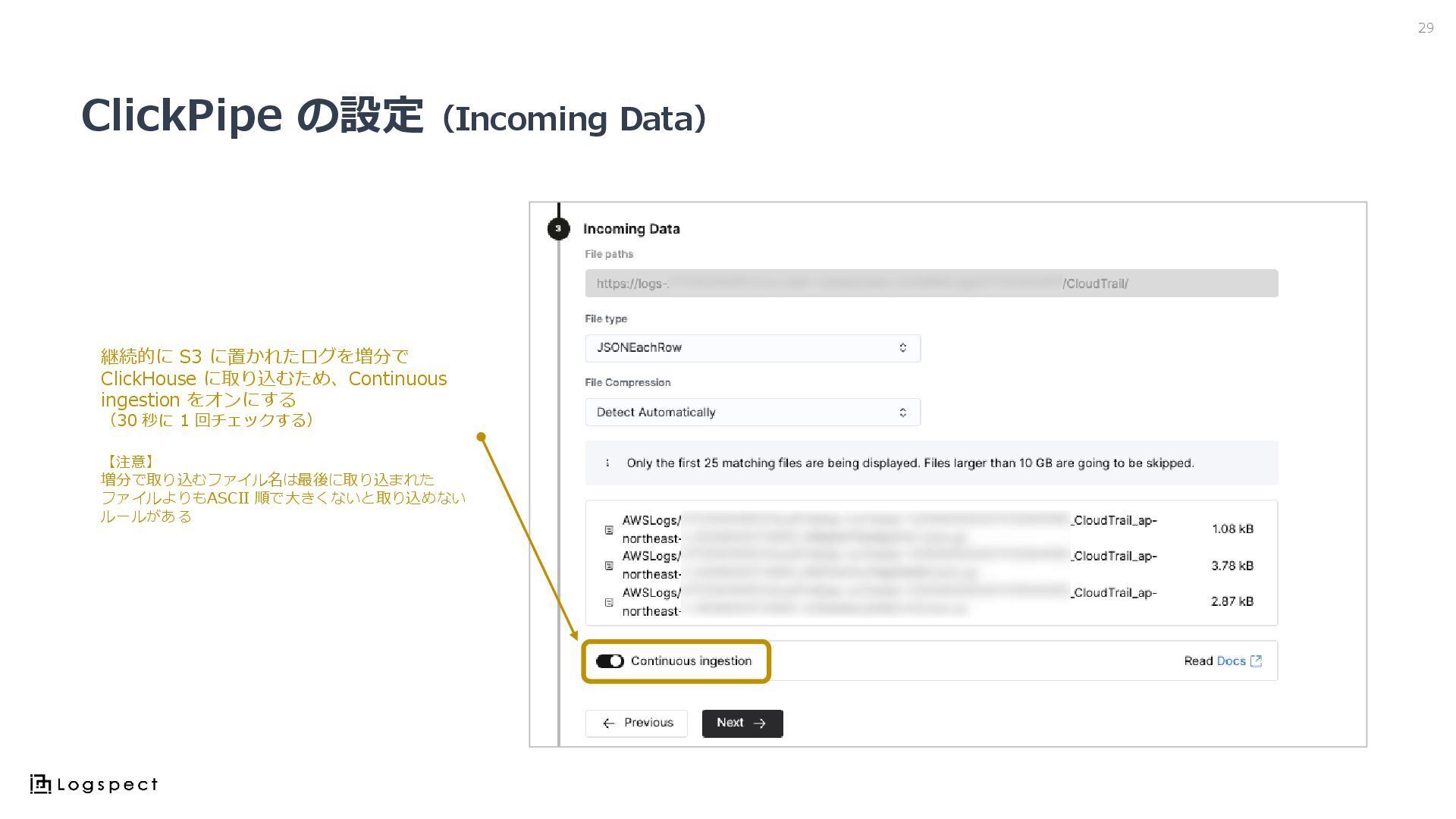
ClickPipe の設定(Incoming Data) 29 継続的に S3 に置かれたログを増分で ClickHouse に取り込むため、Continuous ingestion
をオンにする (30 秒に 1 回チェックする) 【注意】 増分で取り込むファイル名は最後に取り込まれた ファイルよりもASCII 順で大きくないと取り込めない ルールがある
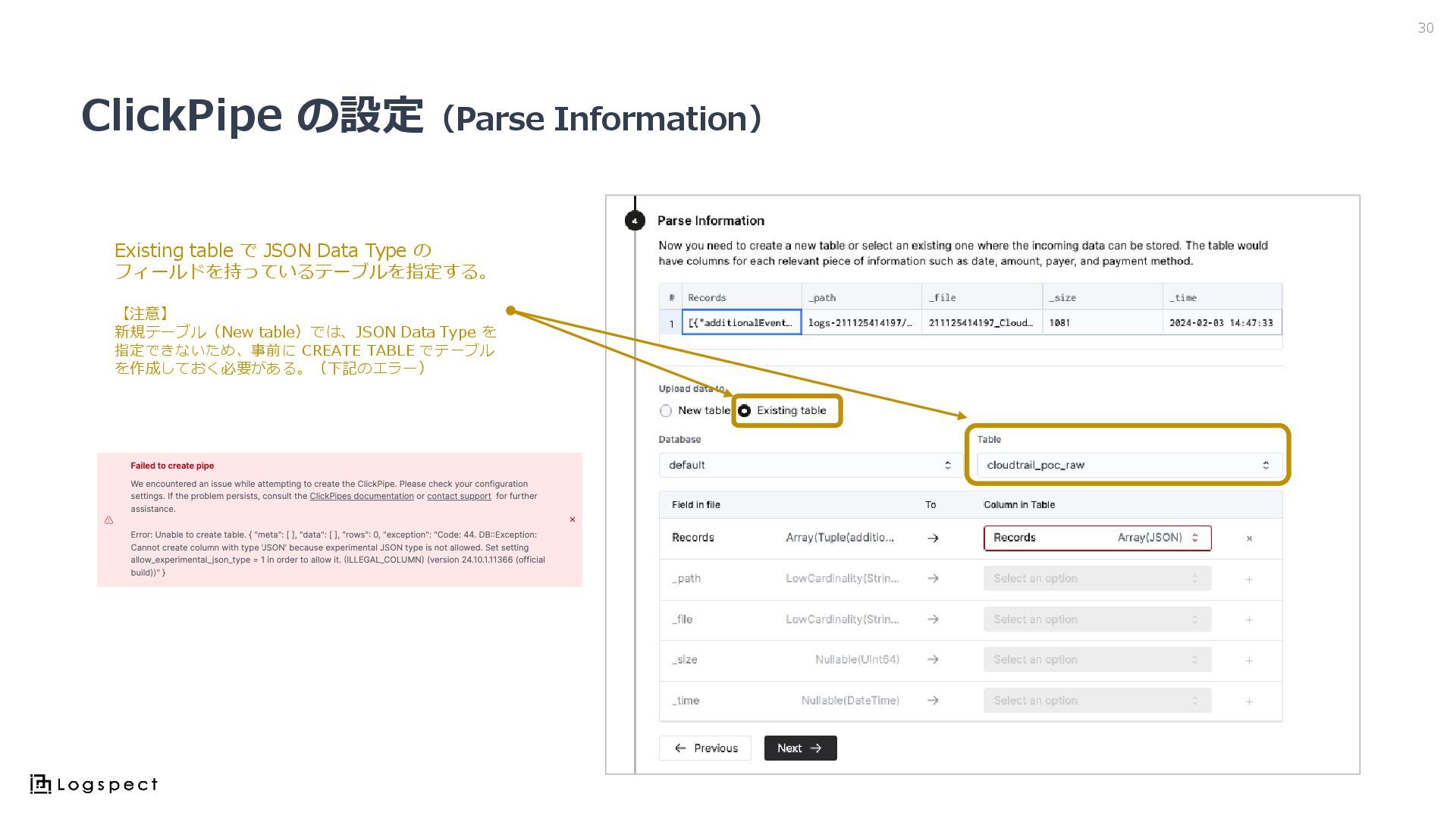
ClickPipe の設定(Parse Information) 30 Existing table で JSON Data Type
の フィールドを持っているテーブルを指定する。 【注意】 新規テーブル(New table)では、JSON Data Type を 指定できないため、事前に CREATE TABLE でテーブル を作成しておく必要がある。(下記のエラー)
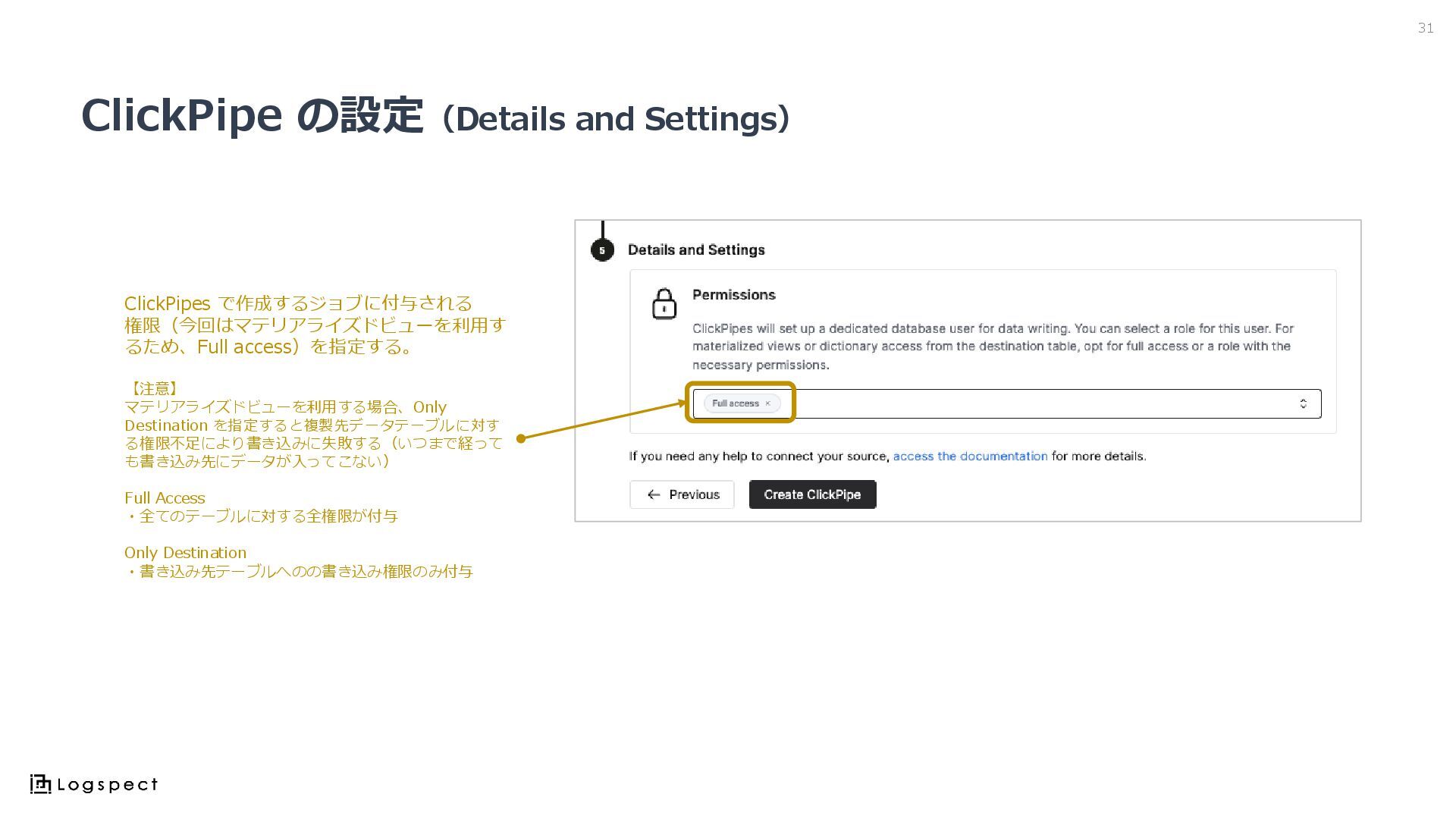
ClickPipe の設定(Details and Settings) 31 ClickPipes で作成するジョブに付与される 権限(今回はマテリアライズドビューを利用す るため、Full access)を指定する。
【注意】 マテリアライズドビューを利用する場合、Only Destination を指定すると複製先データテーブルに対す る権限不足により書き込みに失敗する(いつまで経って も書き込み先にデータが入ってこない) Full Access ・全てのテーブルに対する全権限が付与 Only Destination ・書き込み先テーブルへのの書き込み権限のみ付与
ClickPipe の設定(Metrix) 32
参考 URL 33 JSON Data Type https://clickhouse.com/docs/sql-reference/data-types/newjson ClickHouse の新たな強力な JSON
データ型の開発プロセス https://clickhouse.com/jp/blog/a-new-powerful-json-data-type-for-clickhouse-jp The billion docs JSON Challenge: ClickHouse vs. MongoDB, Elasticsearch, and more https://clickhouse.com/blog/json-bench-clickhouse-vs-mongodb-elasticsearch-duckdb-postgresql Null Table Engine https://clickhouse.com/docs/engines/table-engines/special/null Incremental Materialized Views https://clickhouse.com/docs/materialized-view/incremental-materialized-view ClickPipes https://clickhouse.com/docs/integrations/clickpipes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}