High Performance Computing (HPC) systems generate massive amounts of data and logs. In addition, the retention requirements are only increasing to ensure data remains available for incident response, audits, and other business needs. Ingesting and making sense of all the data takes a correspondingly large amount of computing power and storage. With El Capitan, a 2 Exaflop computer arriving and being deployed at LLNL in 2023, we’ll have even larger processing needs in the future. Therefore over the past year, Livermore Computing at LLNL has been migrating our current logging infrastructure to Elasticsearch and Kibana in an effort to handle the increasing amount of data even faster than before. This talk will focus on the changes we’ve made, why we decided to go with Elastic, and address some of the bumps we’ve hit along the way.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
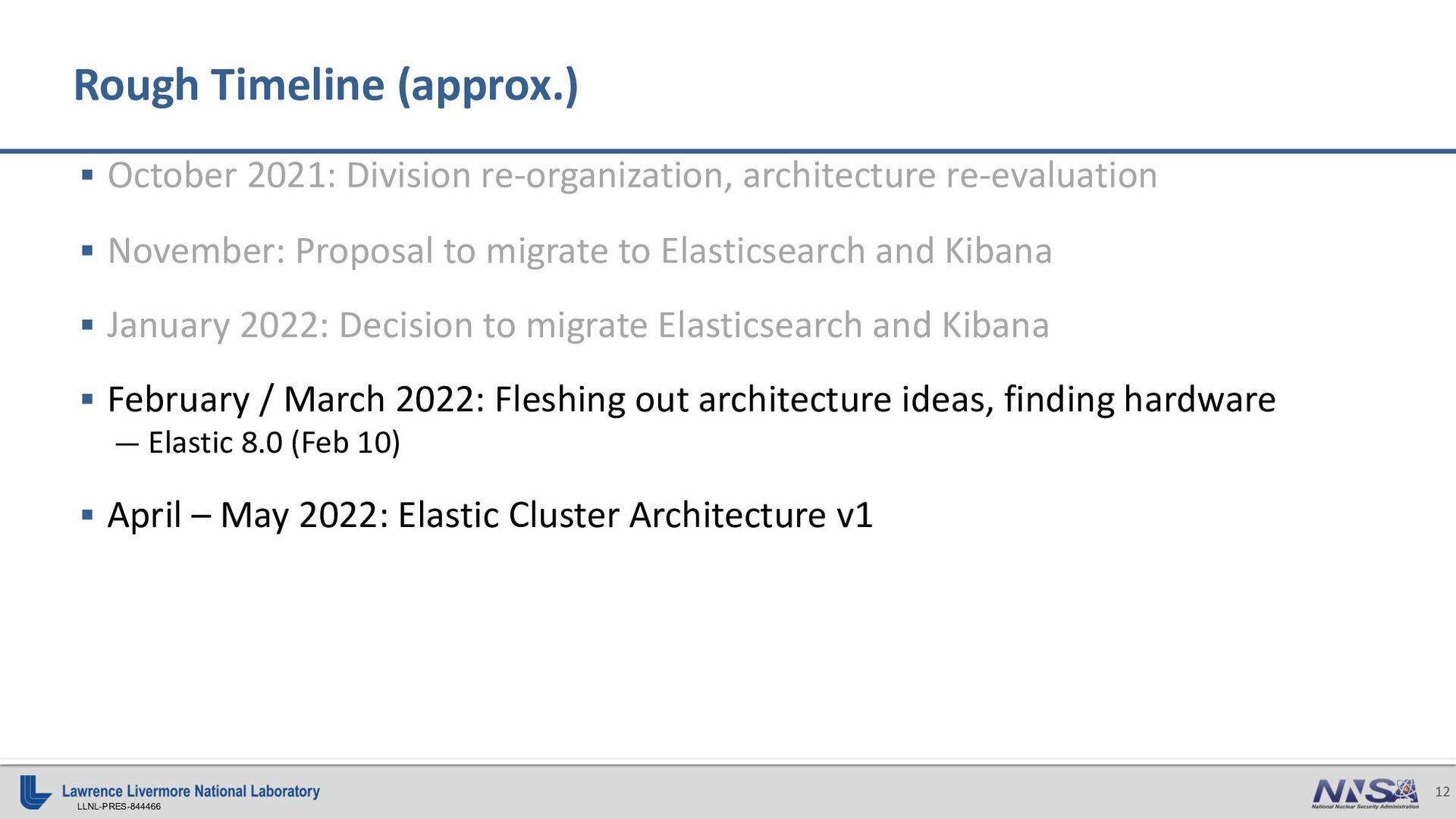{kind=link}
{kind=link}
{kind=link}
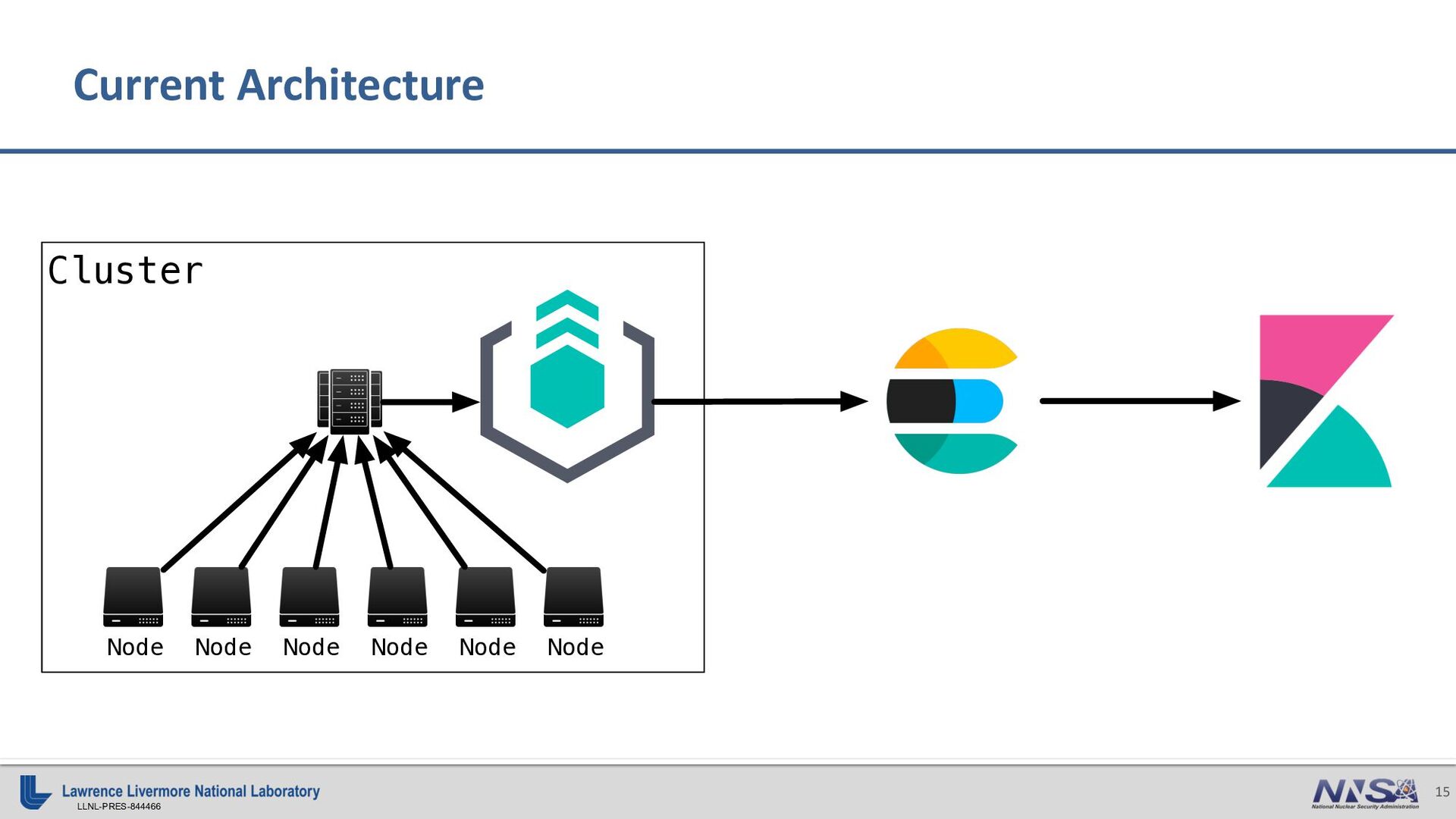{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
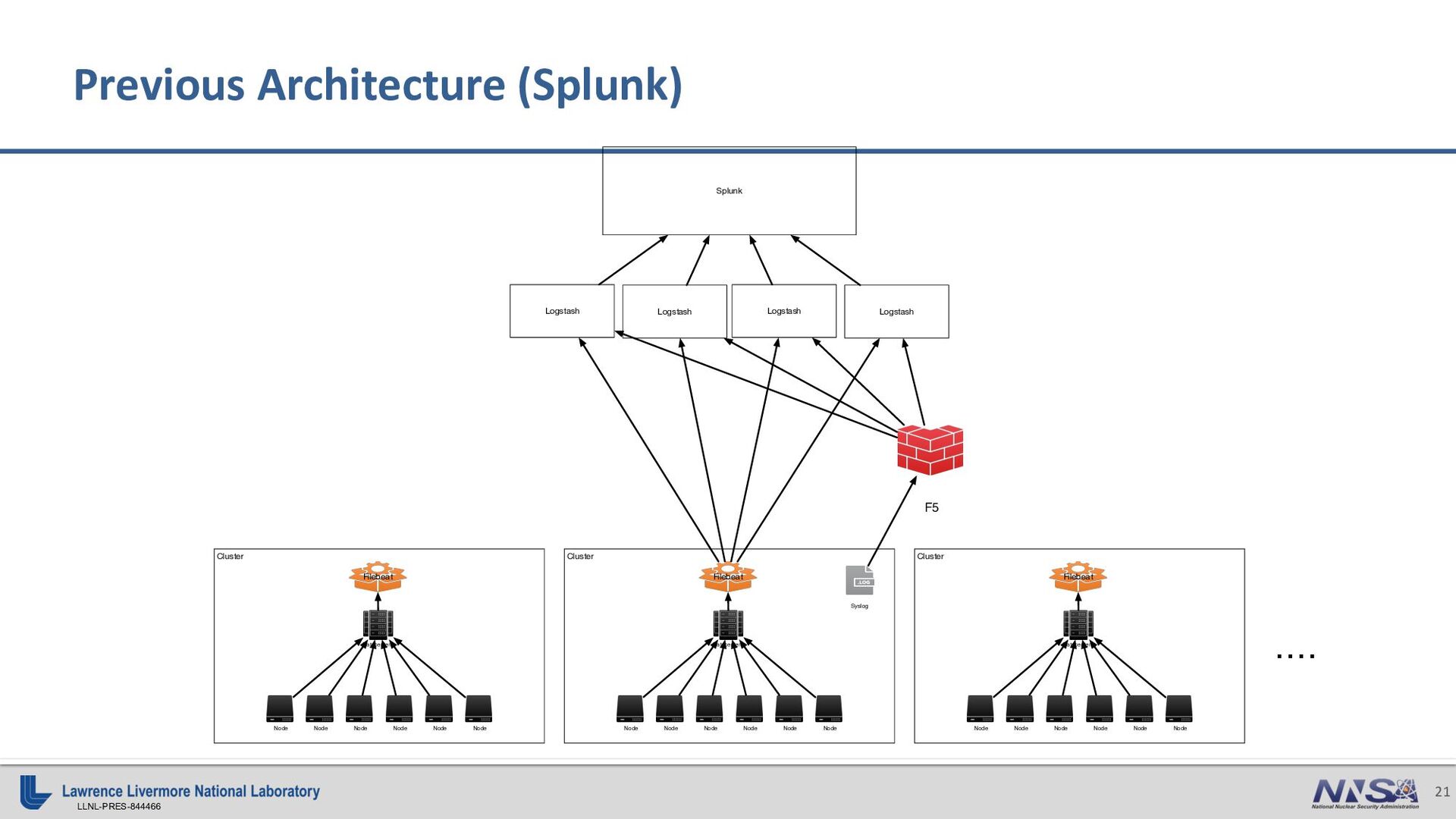{kind=link}
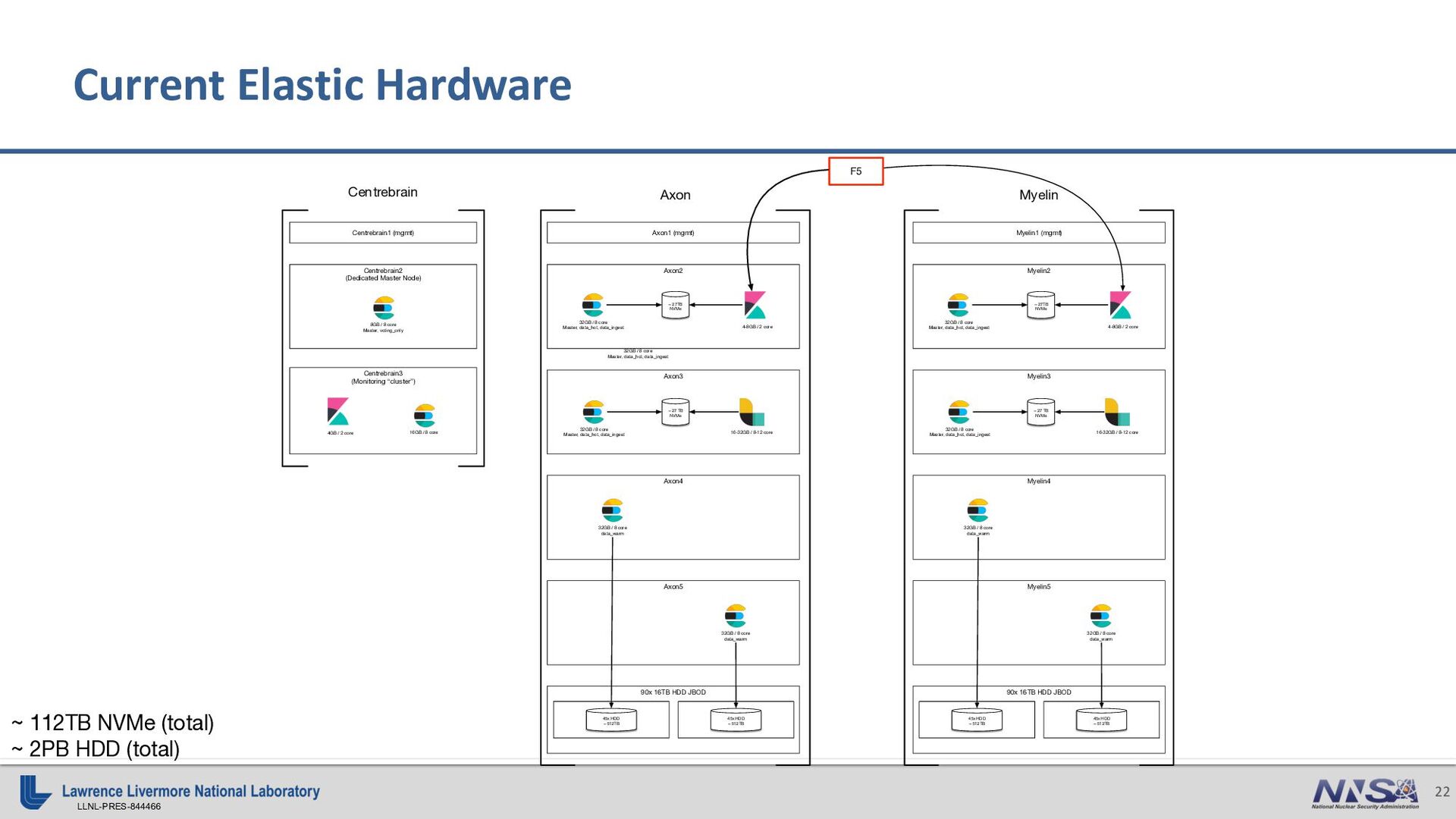{kind=link}
{kind=link}