Database just in US, app servers all around world • Network latency ◦ If you don’t account for machines not being next to each other • Caching • Load Balancing • Regional outages • Config management
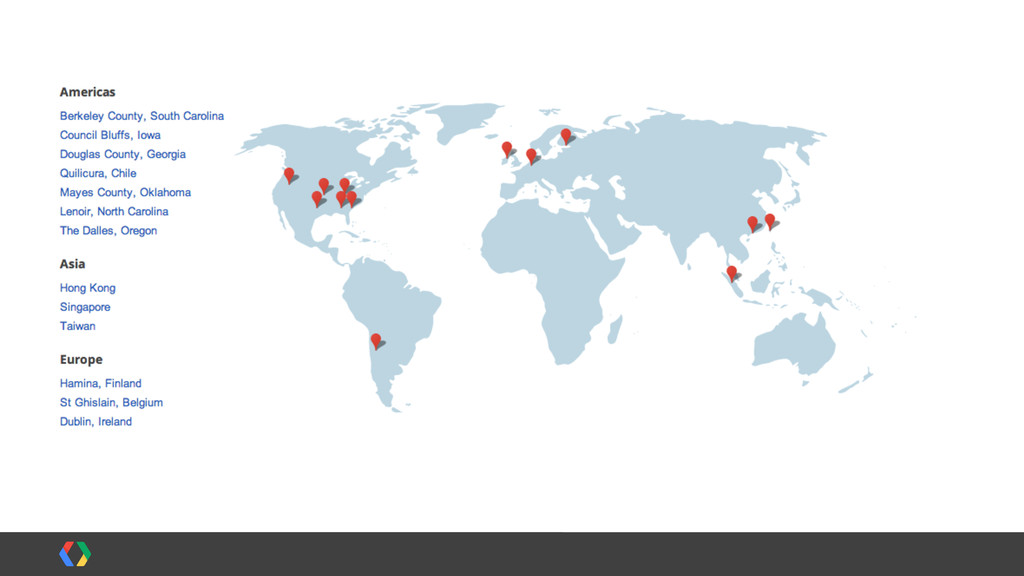
in capital expenditures in the third quarter of 2013 [...]. The spending is driven by a massive expansion of Google’s global data center network, which represents perhaps the largest construction effort in the history of the data center industry.” - Rich Miller Data Center Knowledge, 2013
sorts of dramatic ways, and you're not going to foresee all of them. What you can do, however, is make use of what you do know about what happens in your real world on a regular basis.” - John Allspaw High Scalability Blog, 2009
50% Engineering • Use exactly the same tools and processes as Developers ◦ Unit tests, Peer review, Coding standards ◦ Configuration treated as code ◦ Develop, test, release, iterate ◦ Write documentation • Learn lessons, continually improve ◦ Formal 'post mortems' after service-impacting incidents • But different ◦ Typically not feature-driven workload. ◦ Typically not front-end related development. ◦ Typically greater choice in what you work on day-to-day.
Failure Modes • As your service grows, what will start to fail and how will that show itself? • What failure modes can you prevent before they start? • How can you keep serving and growing your service in spite of failures? Limiting Factors • What will limit your ability to grow your application? • Which resource constraints are important to pay attention to? • How can you design to push past these limits?
has a MTBF of 3 years, and you have 10,000 such drives, expect 9 to fail every day. • All our software is designed to cater to small or large component failures. (e.g. server failure, DC failure). • Monitor Everything. Always.
a Service • “Here’s my code. Scale it, maybe?” • Google App Engine, Heroku, others IAAS • Infrastructure as a Service • “Linux Servers, IN THE CLOUD!” • Google Compute Engine, Amazon Elastic Compute Cloud, OpenStack Nova
than a PAAS • Free tiers usually provide inconsistent performance • A lot more expensive than using your own hardware if you don’t have a dynamic workload and large scale Pros • Run anything in any way you want • Easier to migrate to and off of • Cheaper at larger scale
requires you to trust provider • Restrictions on what you can host and/or build Pros • Low maintenance • Great developer communities • Scaling is just a slider
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google Confidential and Proprietary “Google [recorded] a whopping $2.29 billion](https://files.speakerdeck.com/presentations/3332769038930131bfa67ef76df448c9/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}