Slides from talks given at SF Bay Area Machine Learning Meetup and OpenLate @ OpenDNS:
Talk excerpt:
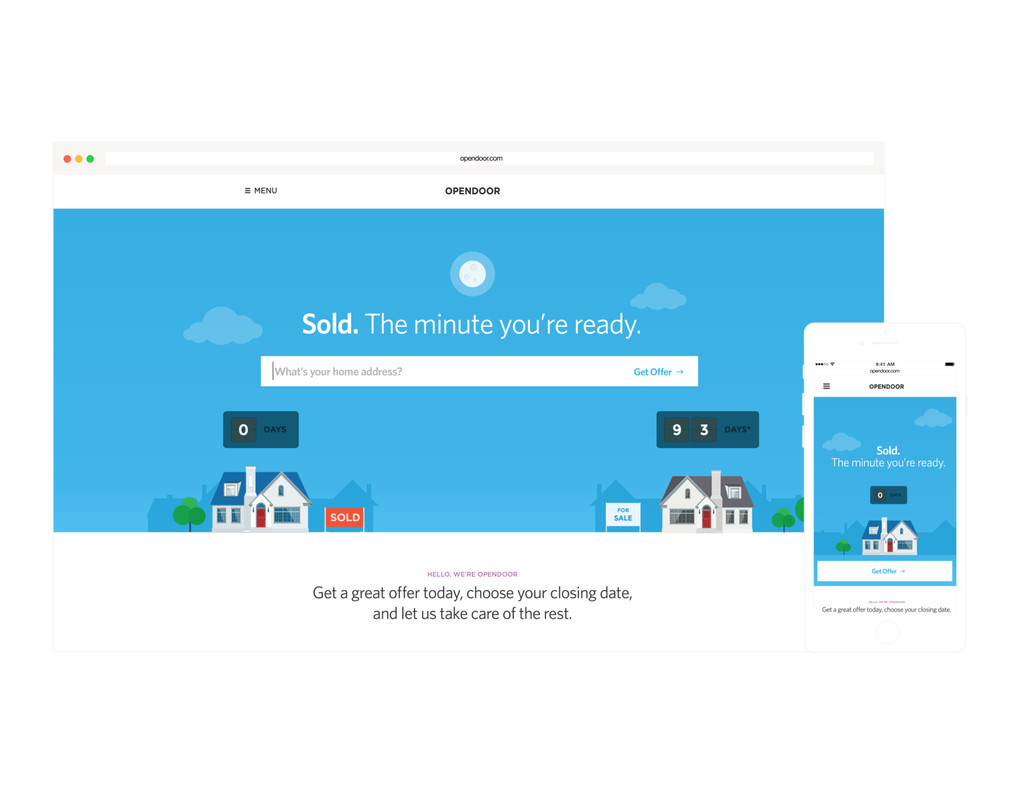
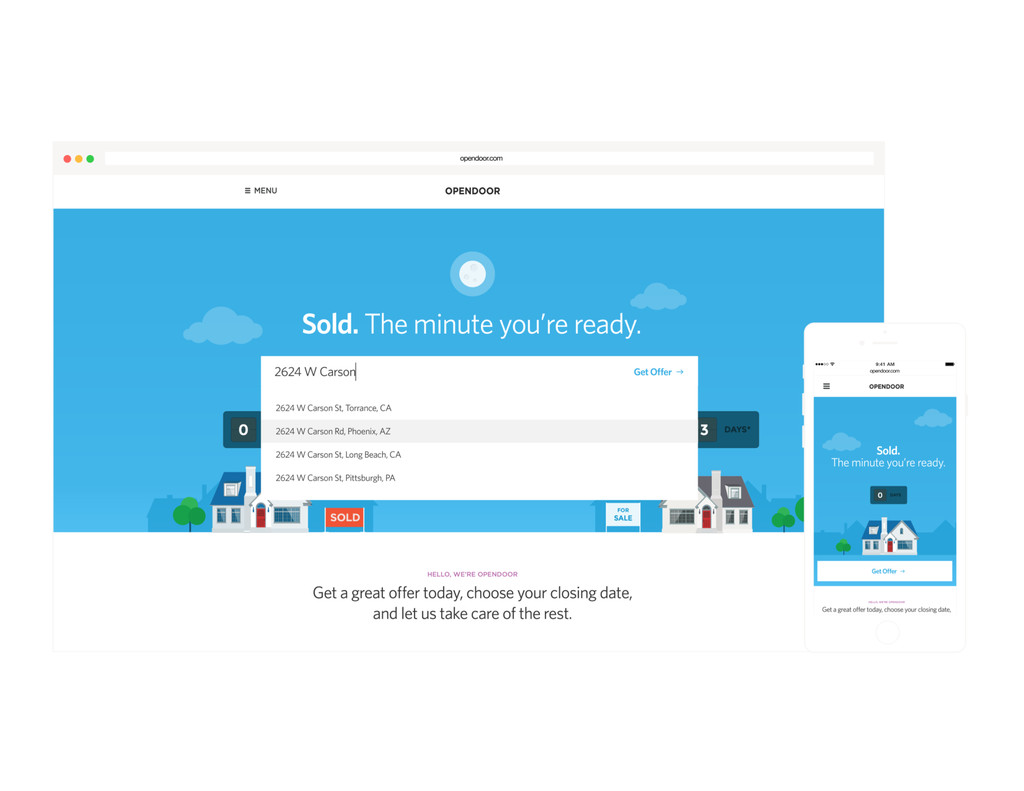
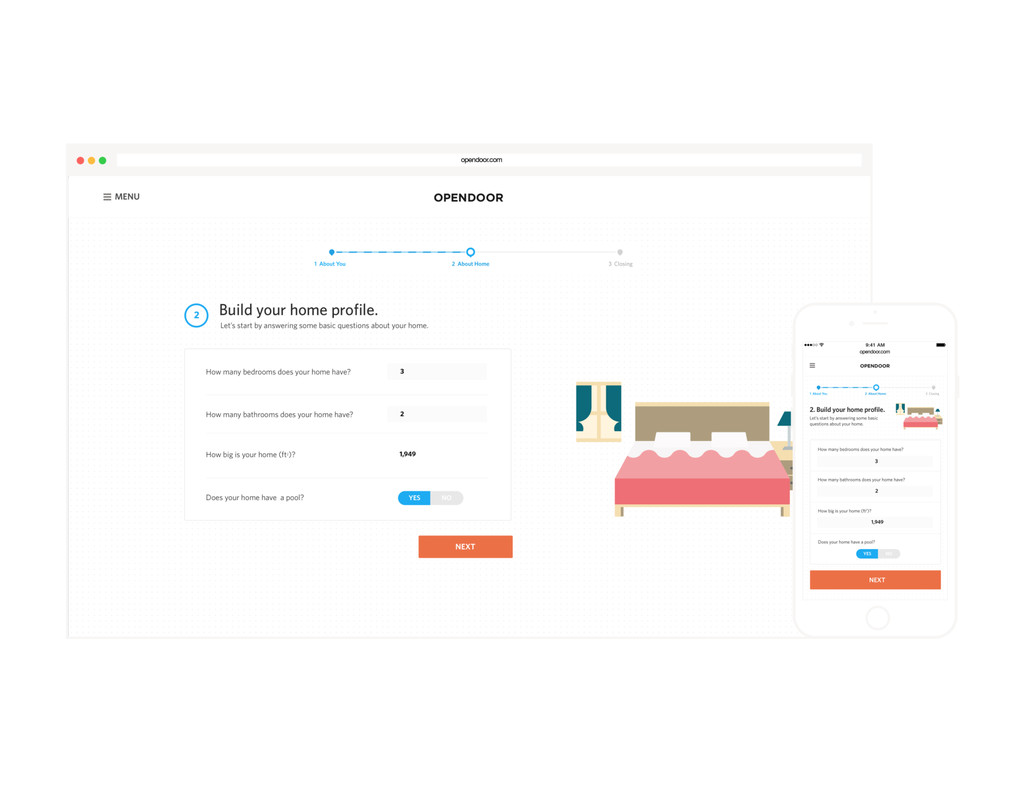
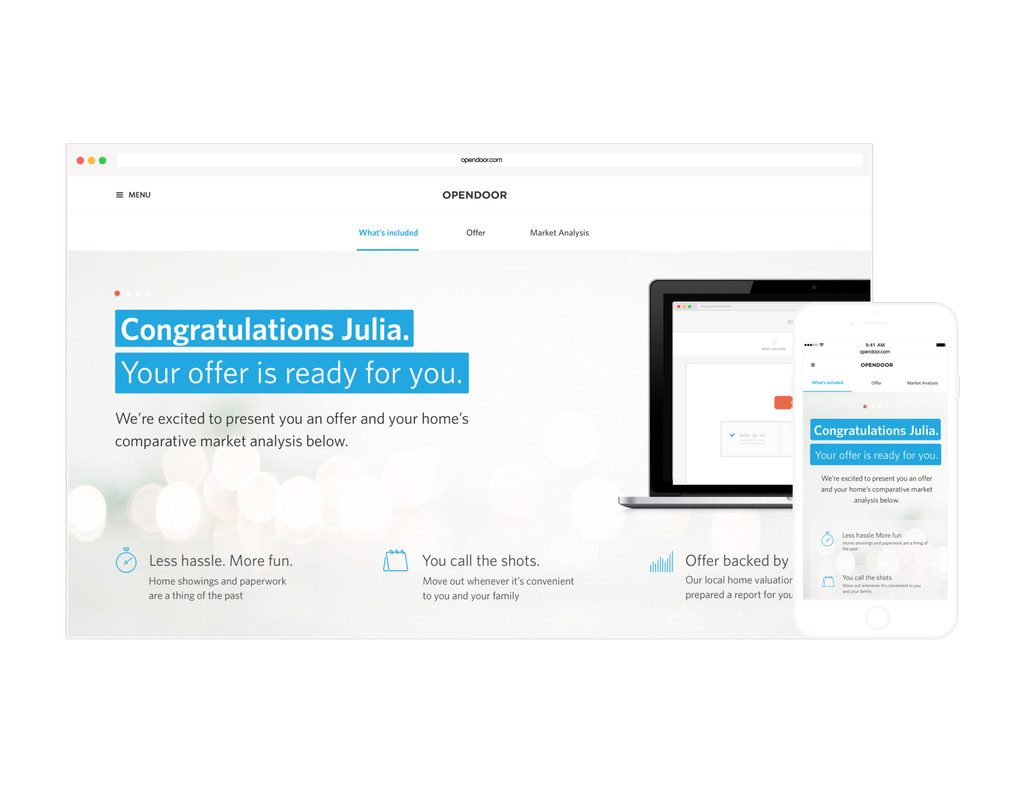
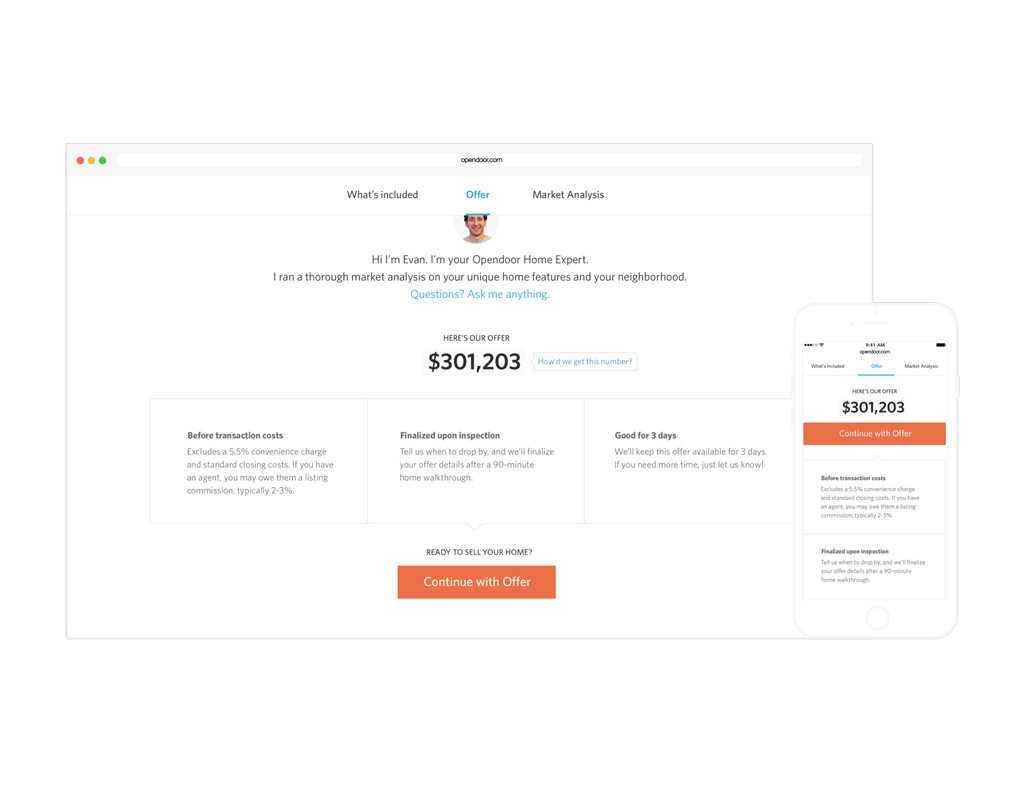
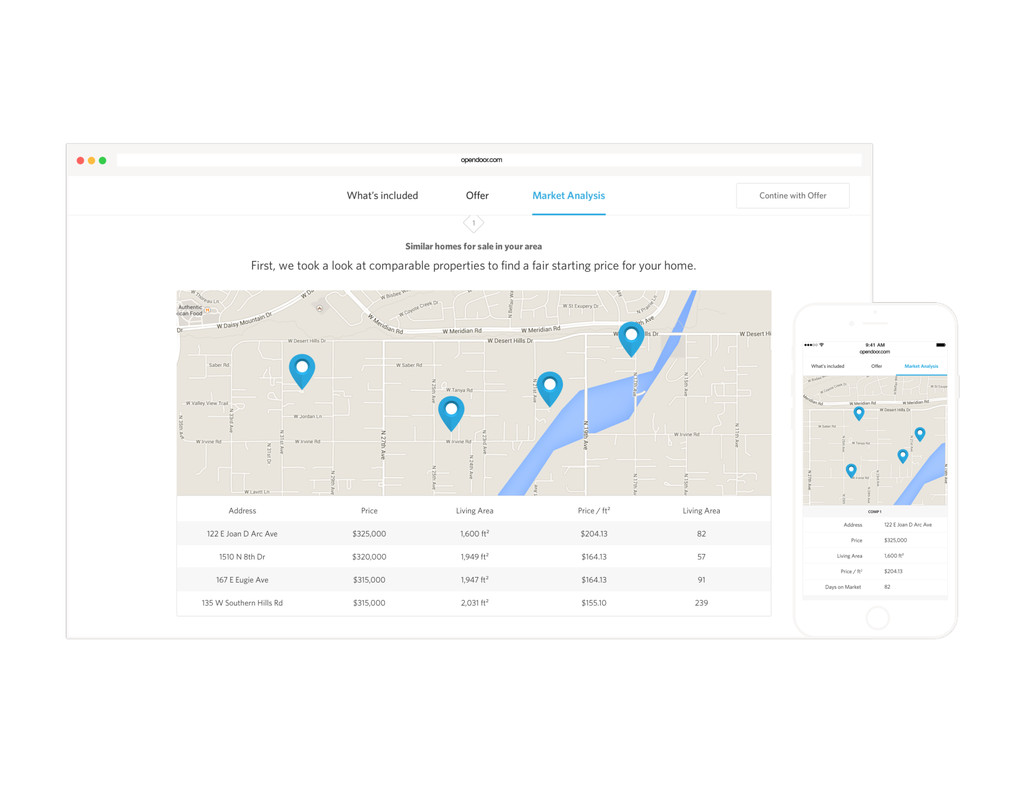
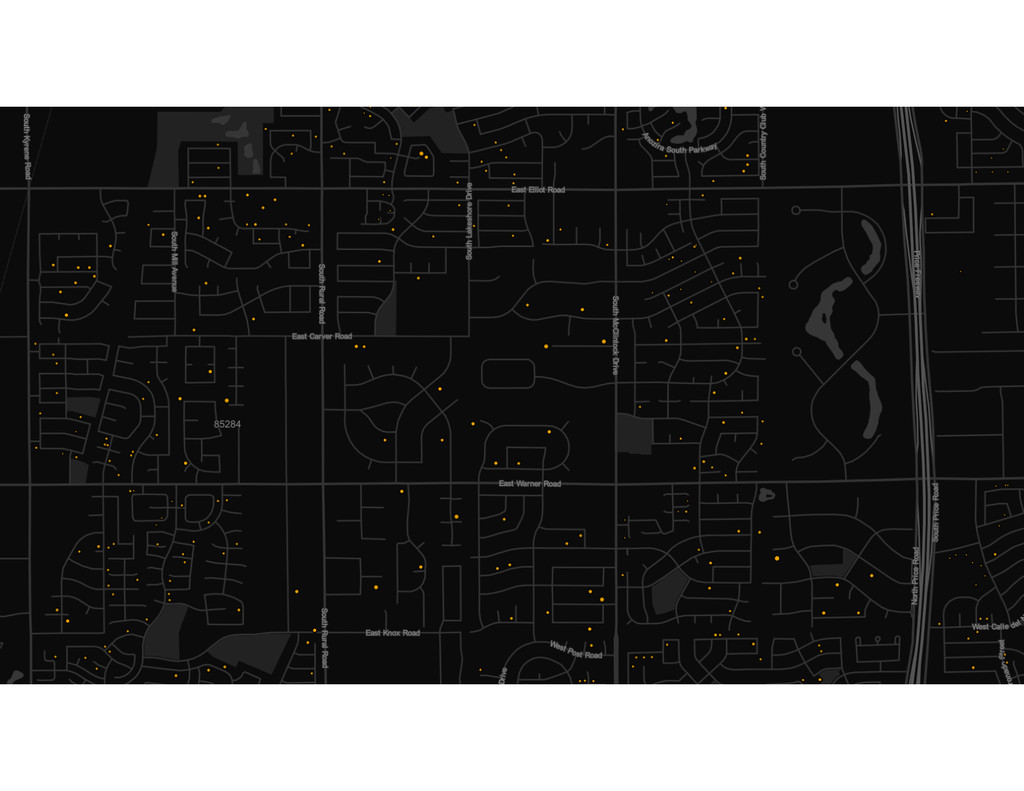
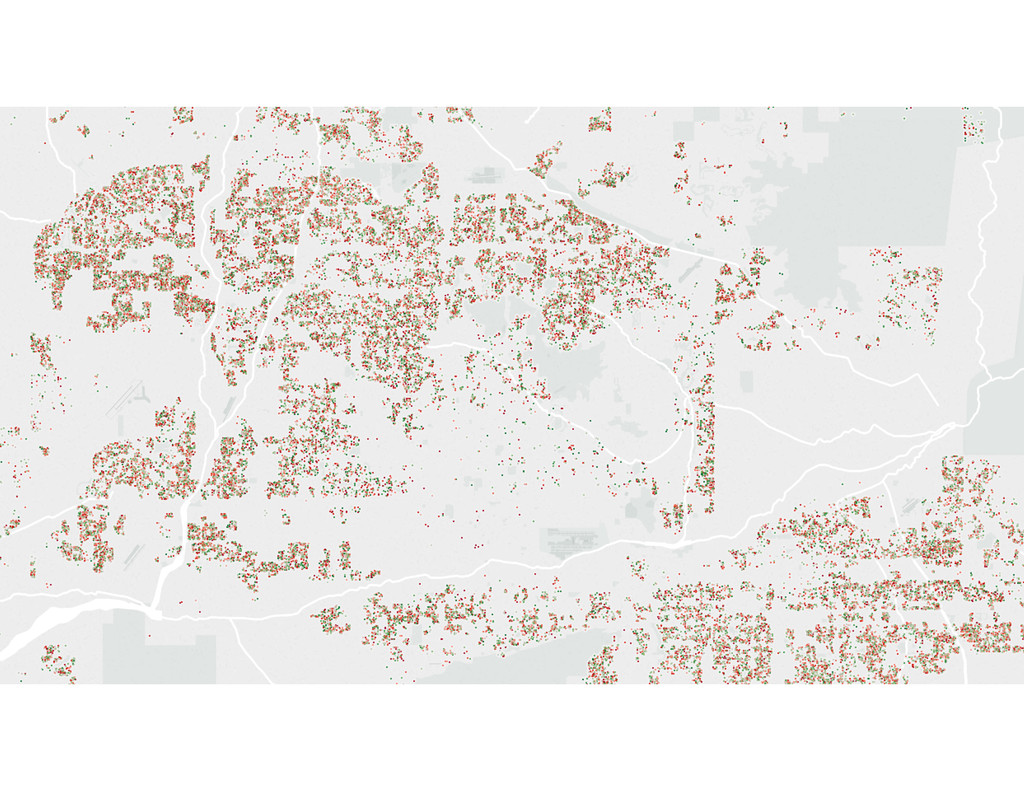
Homes are Americans' most valuable yet least liquid asset. Selling a home on the market takes months of hassle and uncertainty. Founded in 2014, Opendoor removes all the friction from the transaction by providing homeowners with instant offers to buy their homes. Sellers can choose when they want to move out, and close the sale through a streamlined experience online.
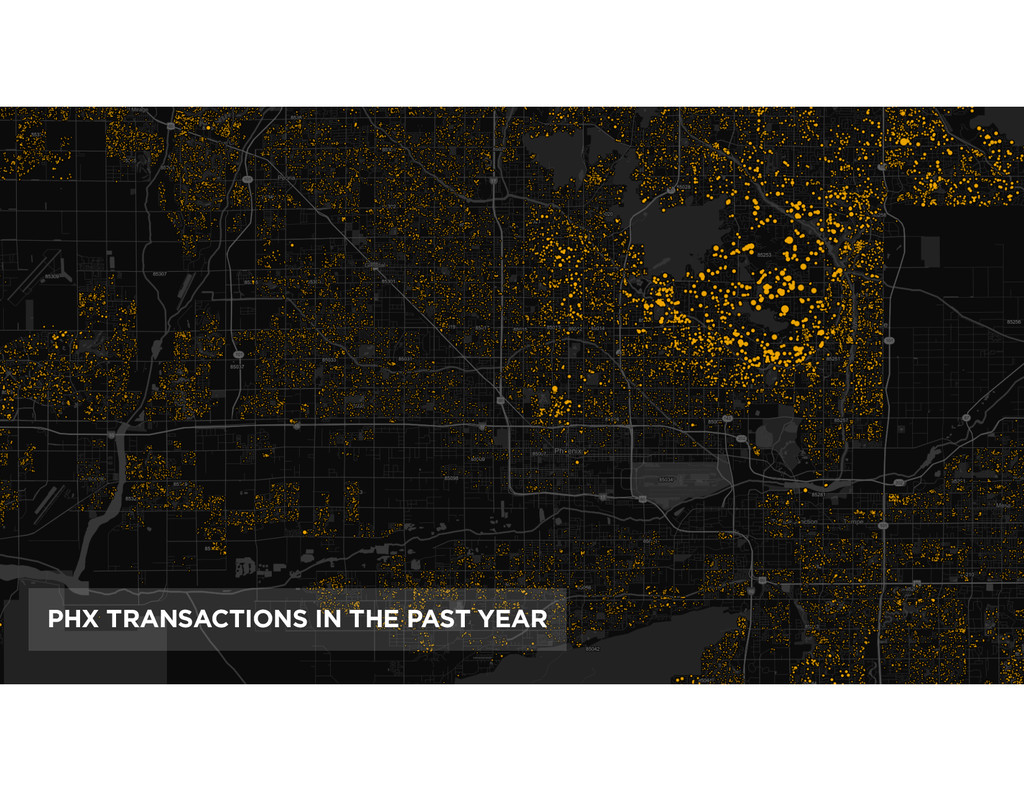
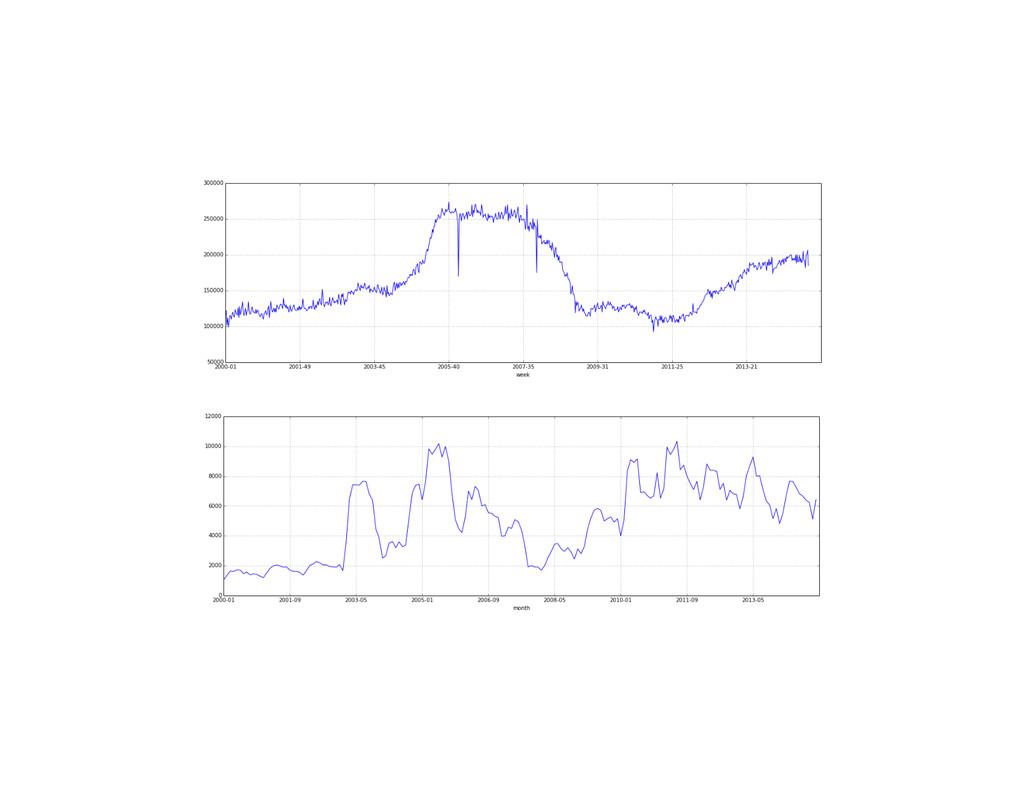
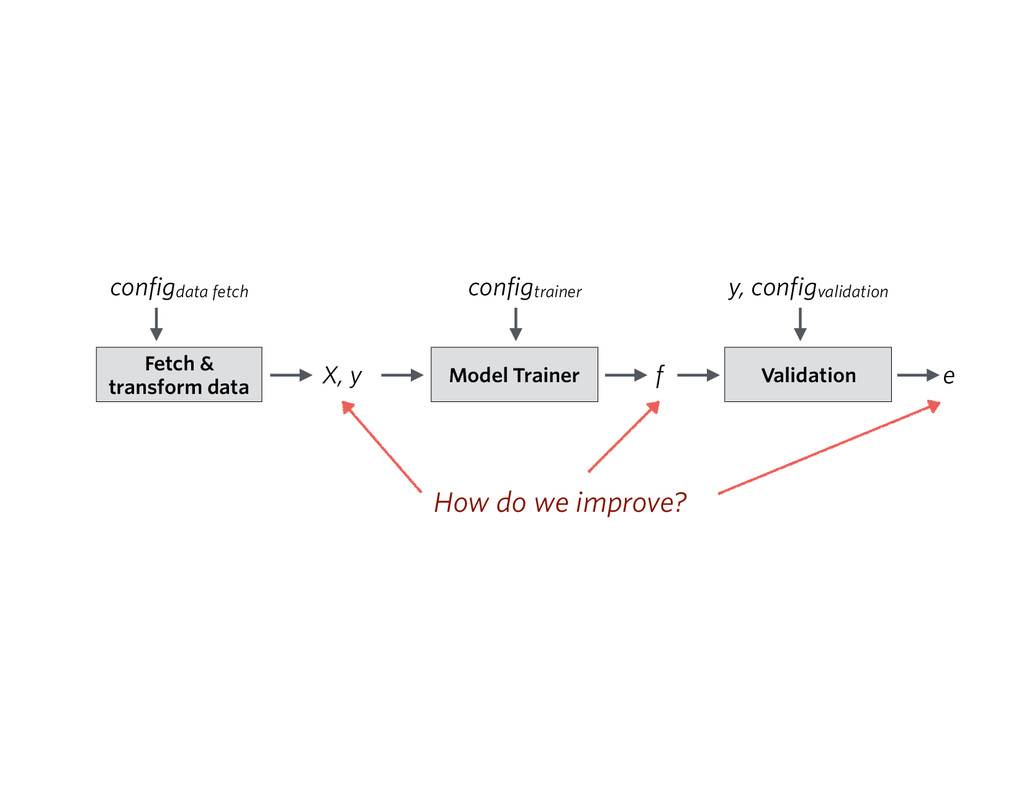
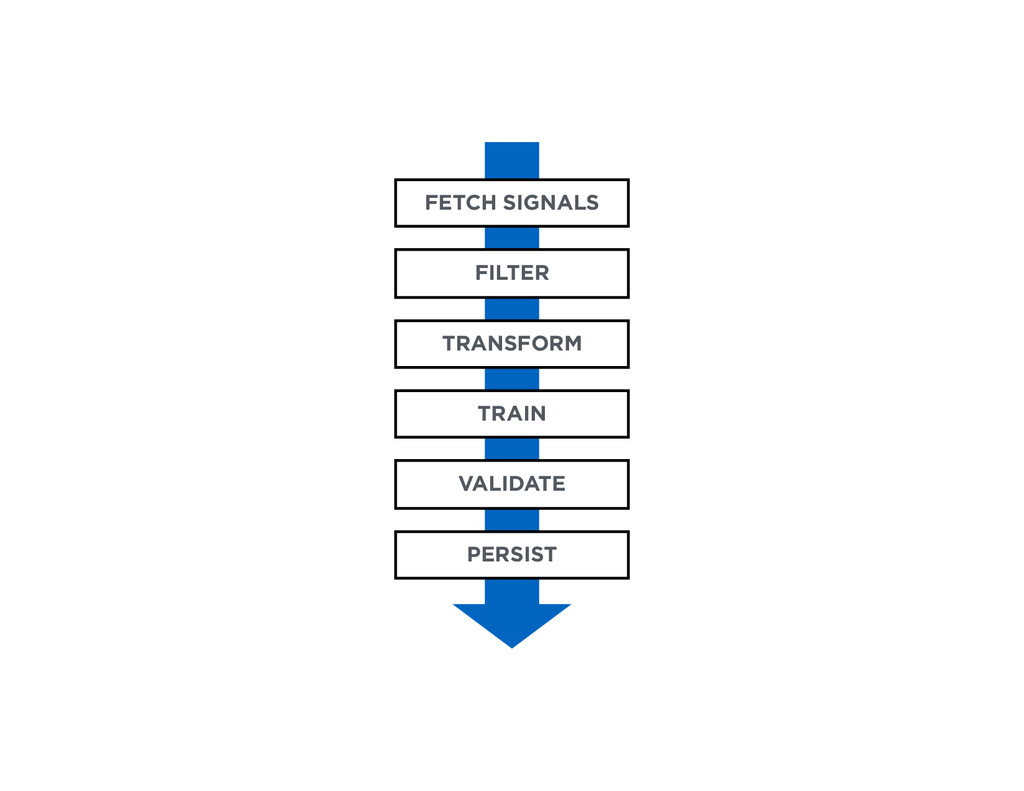
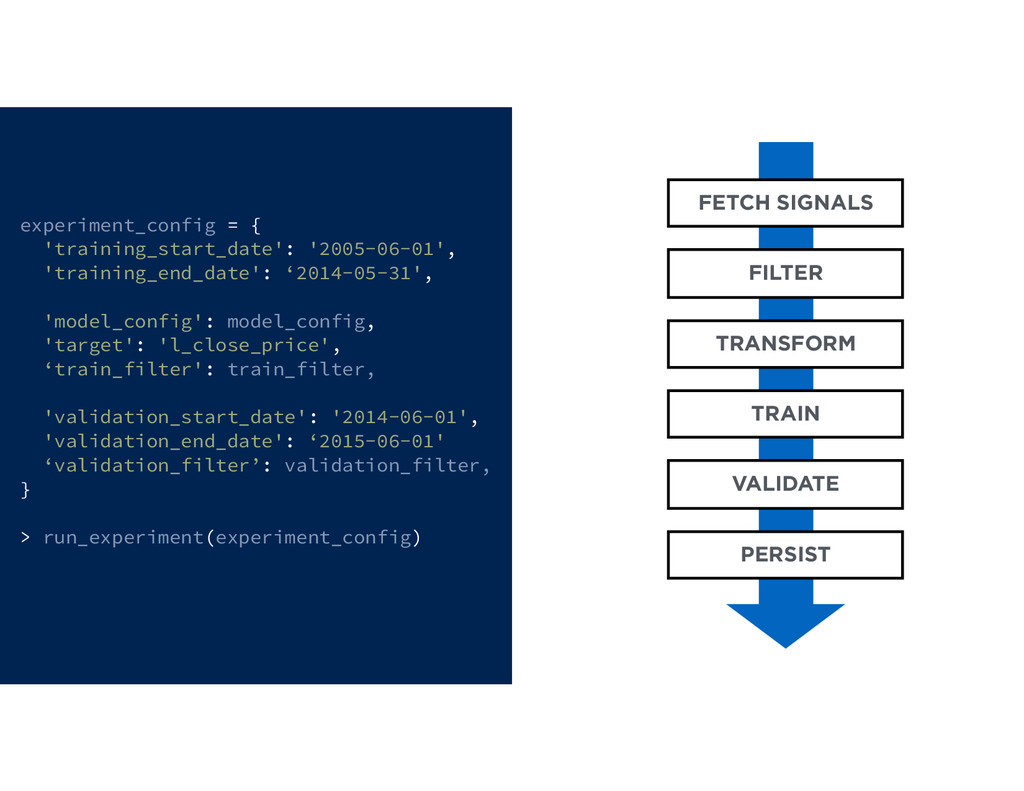
At the core of the service is a collection of pricing algorithms that infer the fair market value for houses. In this talk, we’ll explore some of the challenges in dealing with real-estate data, and ways to address them. We’ll dive into aspects of putting together modular and declarative data pipelines for model training and feature generation, as well as recipes for reproducible model research.
![OPENDOOR August 5th 2015 Ian Wong (@ihat) [email protected] Making real-estate](https://files.speakerdeck.com/presentations/afc6afe53e474b7eb6203b330999c996/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
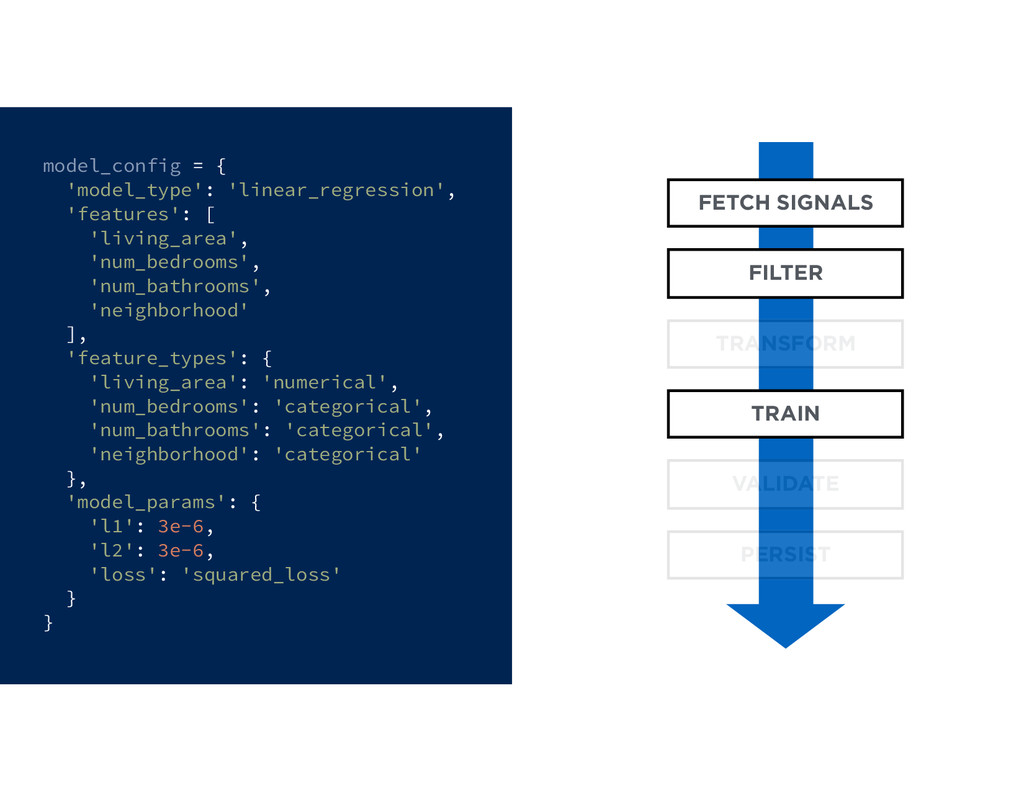{kind=link}
![filter_config = { 'not_null': ['living_area'], 'value': { 'max' : {](https://files.speakerdeck.com/presentations/afc6afe53e474b7eb6203b330999c996/slide_39.jpg){kind=link}
{kind=link}
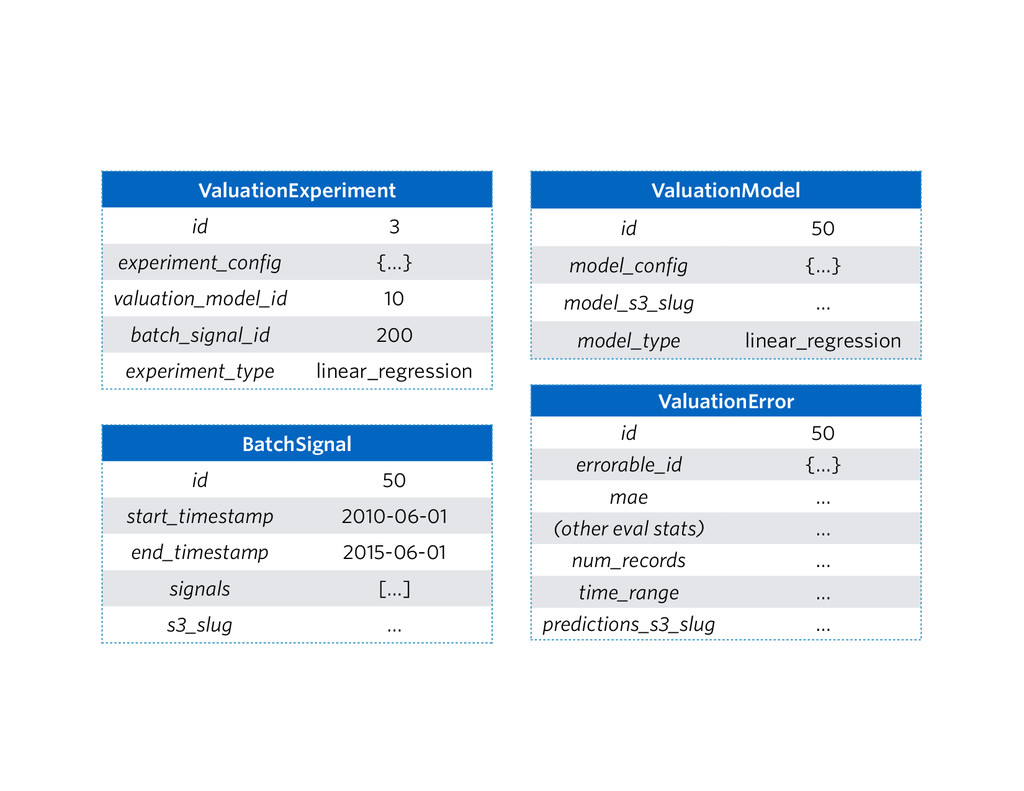{kind=link}
{kind=link}
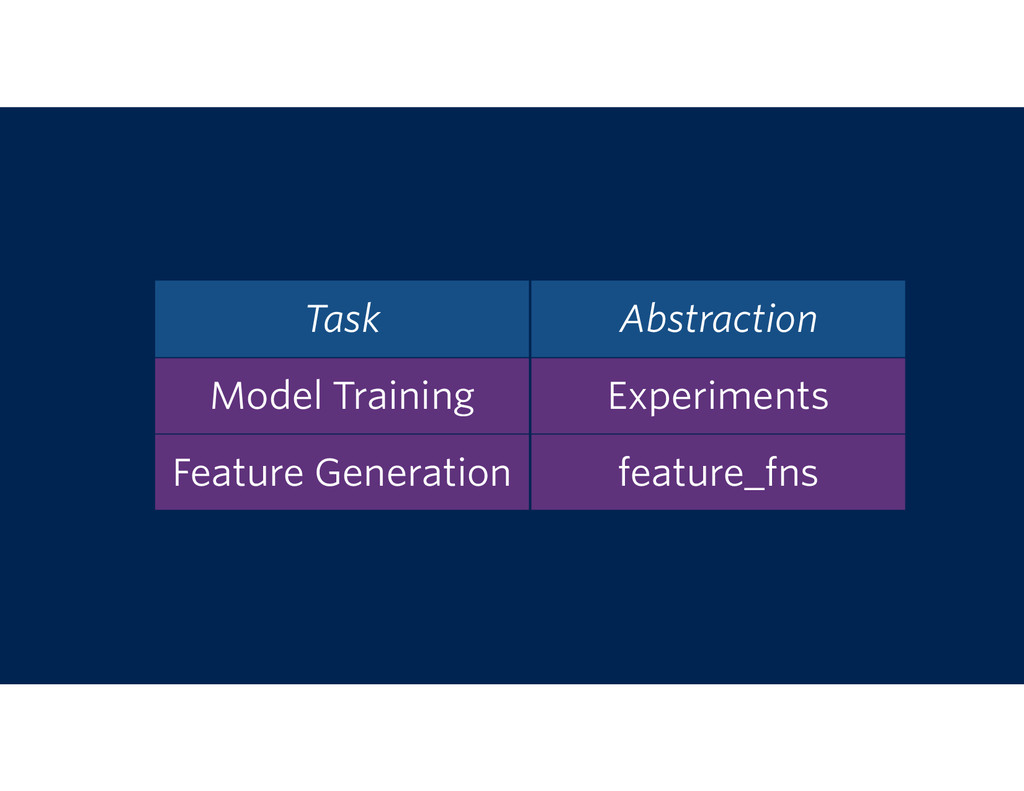{kind=link}
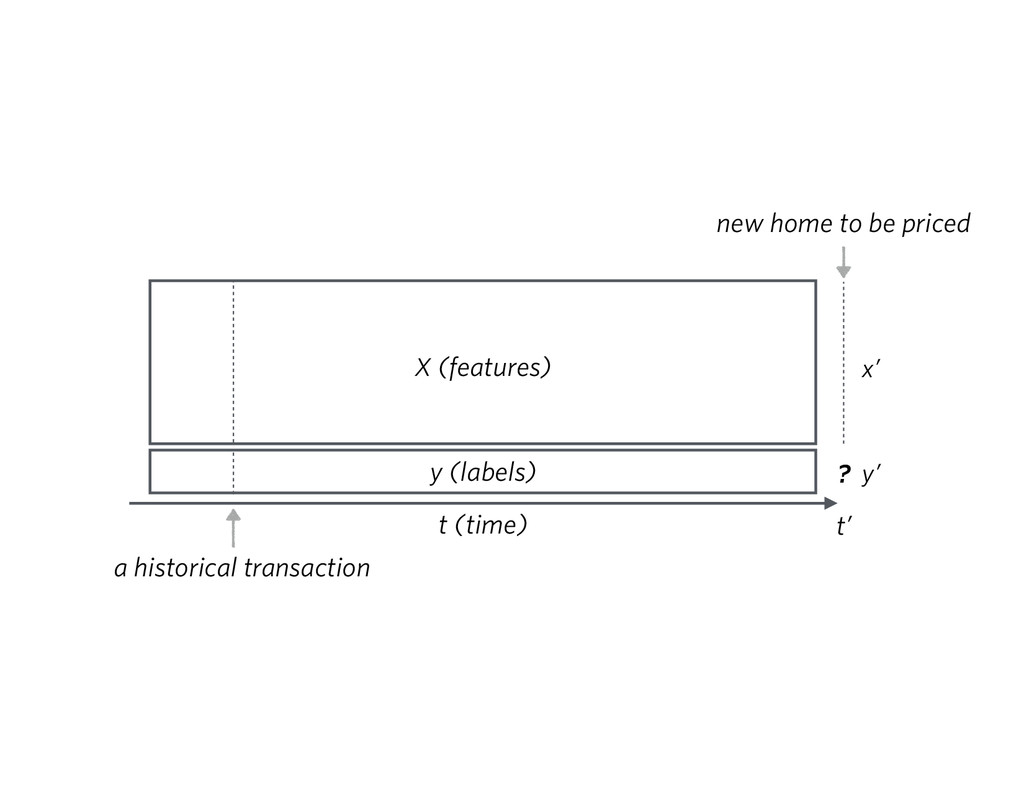{kind=link}
![Declarative Feature Generation compute for at features [f] entities [e]](https://files.speakerdeck.com/presentations/afc6afe53e474b7eb6203b330999c996/slide_45.jpg){kind=link}
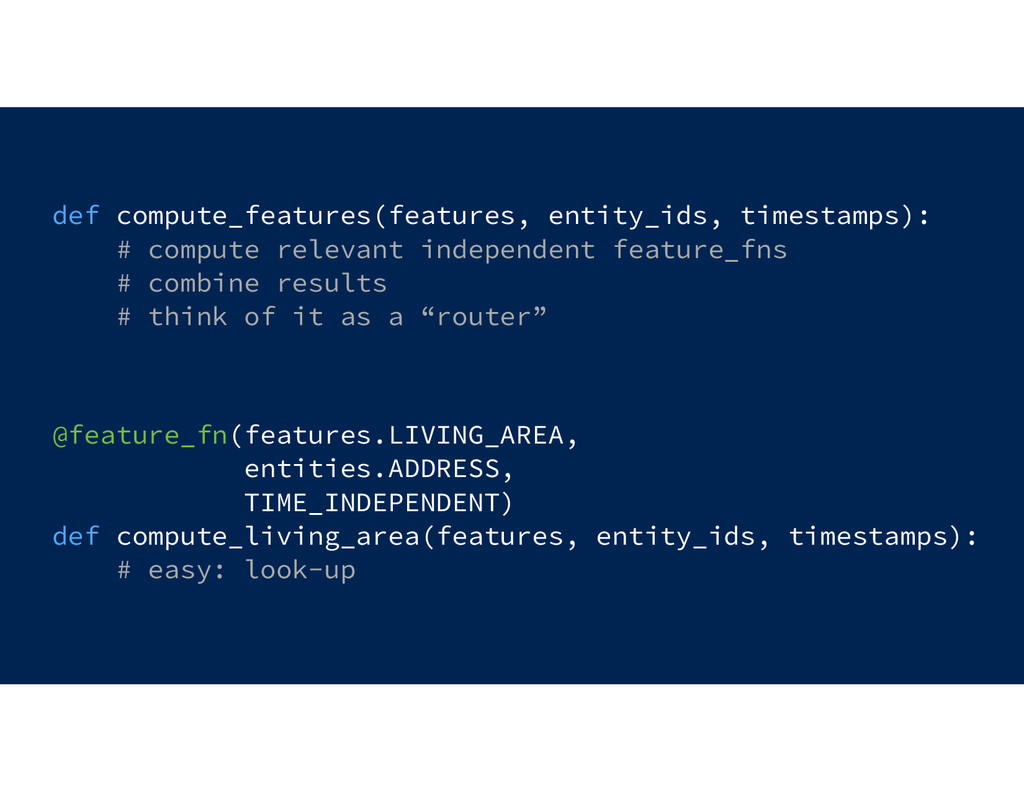{kind=link}
![@feature_fn(features :- [feature], entities :- [entity], timestamp :- {TIME_INDEPENDENT, TIME_DEPENDENT}])](https://files.speakerdeck.com/presentations/afc6afe53e474b7eb6203b330999c996/slide_47.jpg){kind=link}
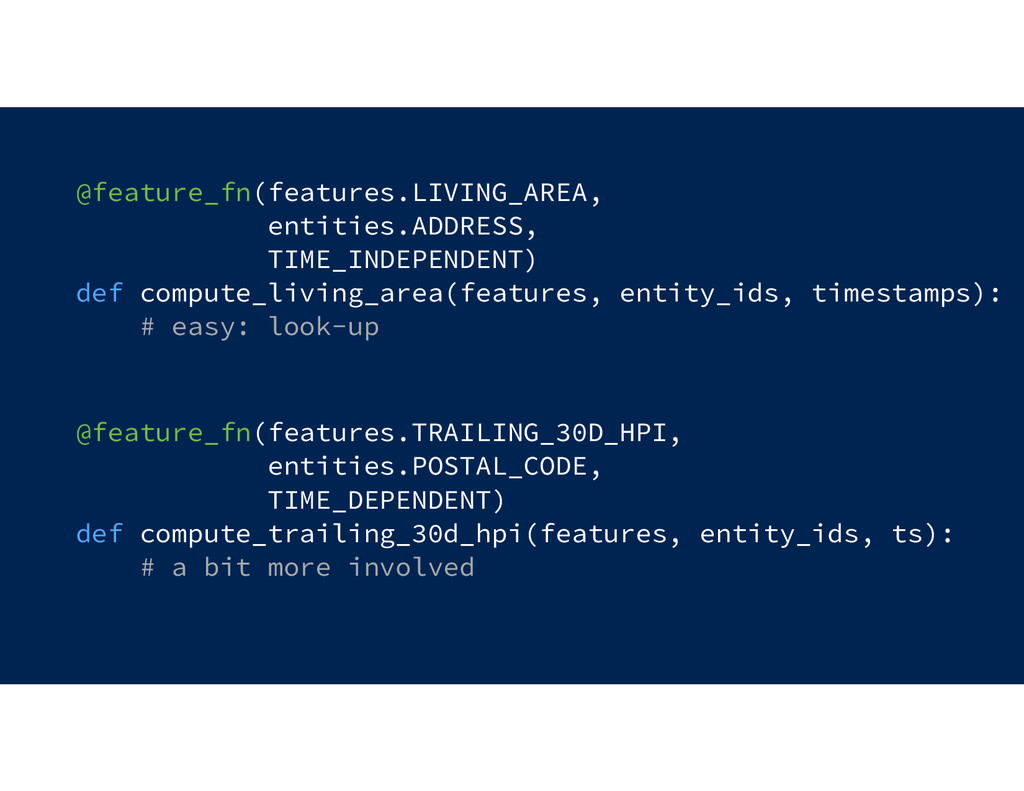{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Q & A Ian Wong (@ihat) [email protected]](https://files.speakerdeck.com/presentations/afc6afe53e474b7eb6203b330999c996/slide_59.jpg){kind=link}