Share
MySQL クラウド向け InnoDB チューニング。仮想サーバーで使う場合のチューニングのポイントを解説しました。DB TECH SHOWCASE SAPPORO 2015 での発表資料です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
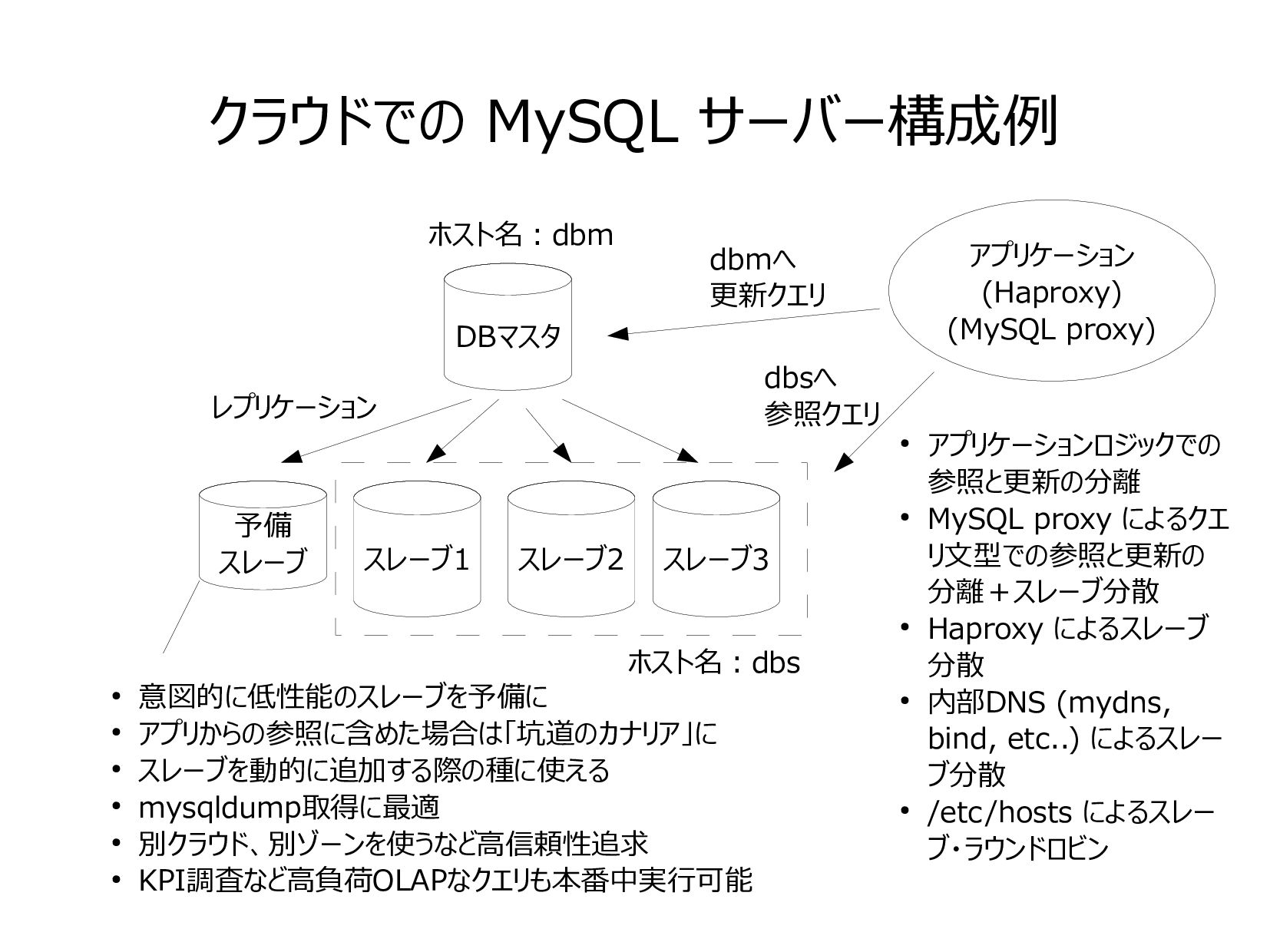{kind=link}
{kind=link}
{kind=link}
{kind=link}
![オープン数 /proc/[pid]/limits • ulimit や /etc/security/limits.conf は PAM経由でのログイン処理で適用 • デーモンプロセスは起動スクリプトで](https://files.speakerdeck.com/presentations/3ab82a1525cb441282949e73485624ed/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
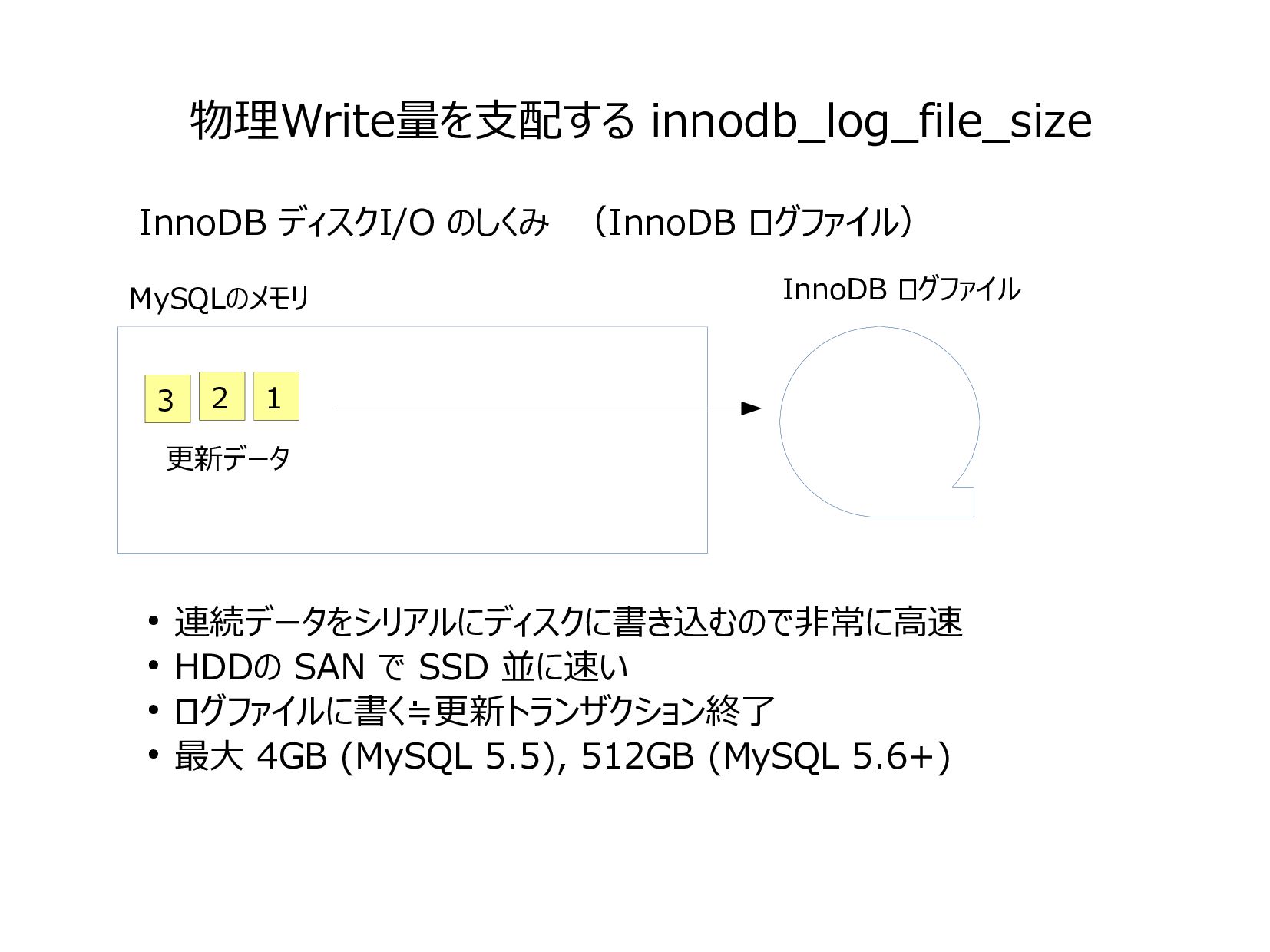{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
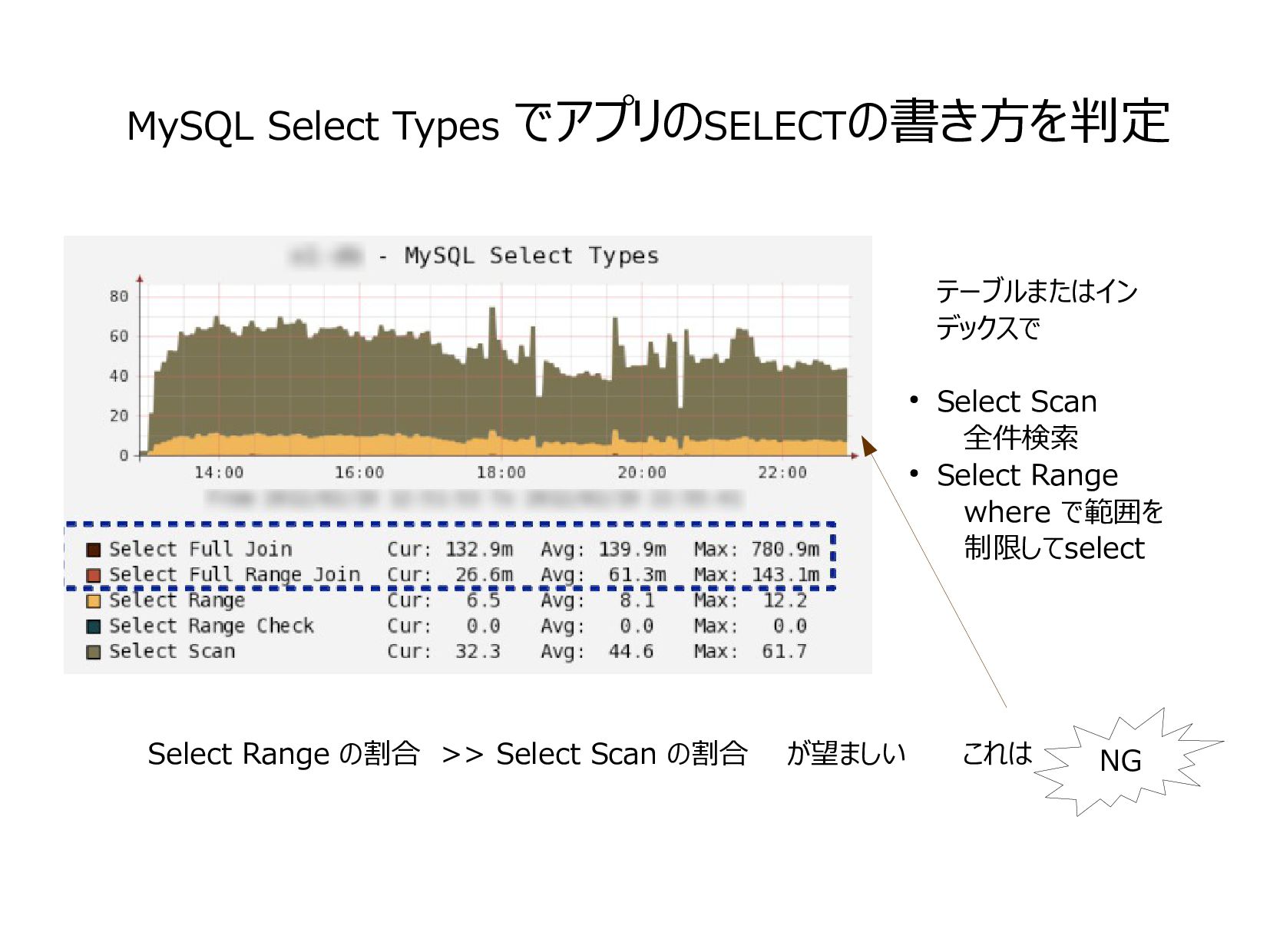{kind=link}
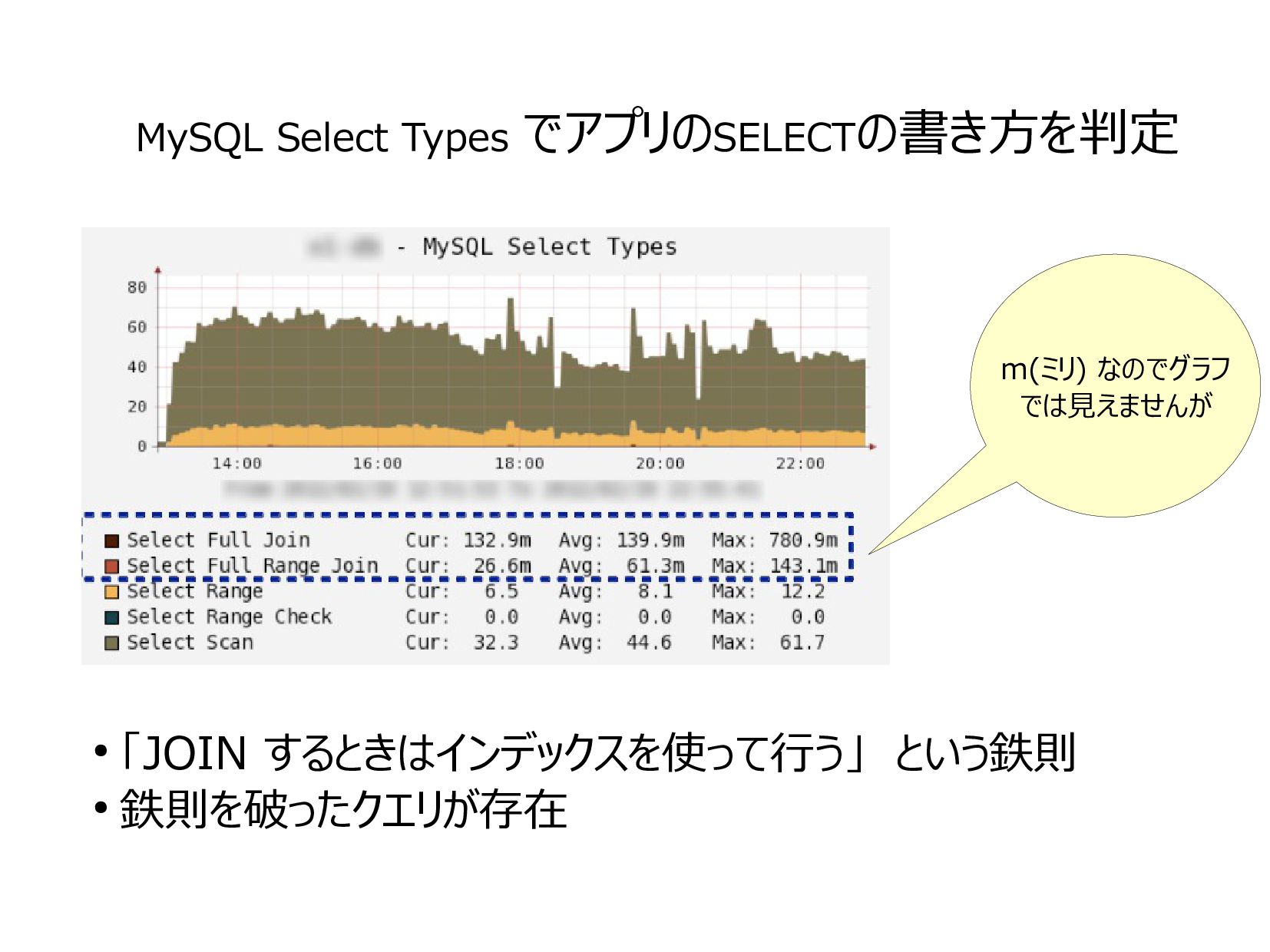{kind=link}
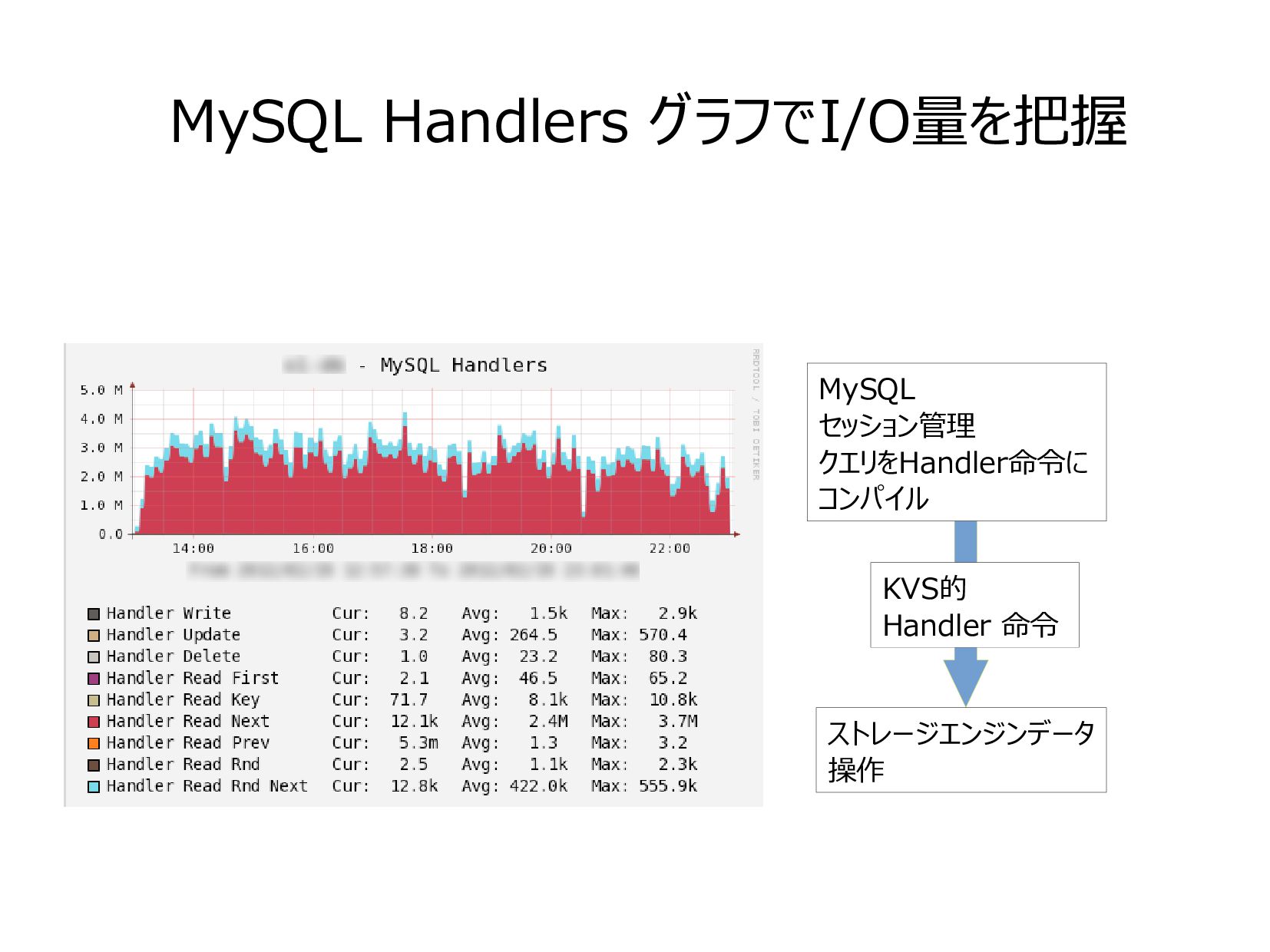{kind=link}
{kind=link}
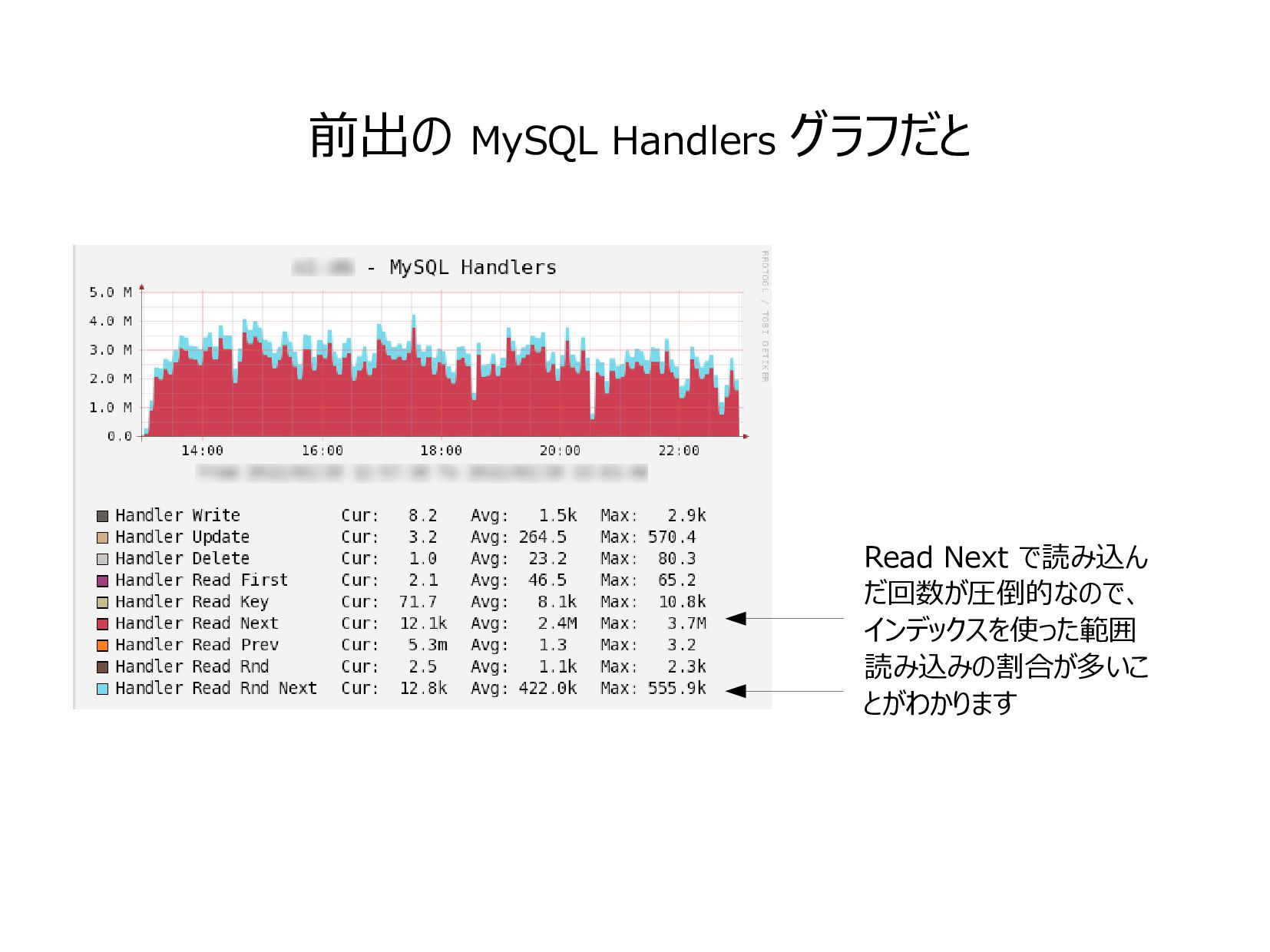{kind=link}
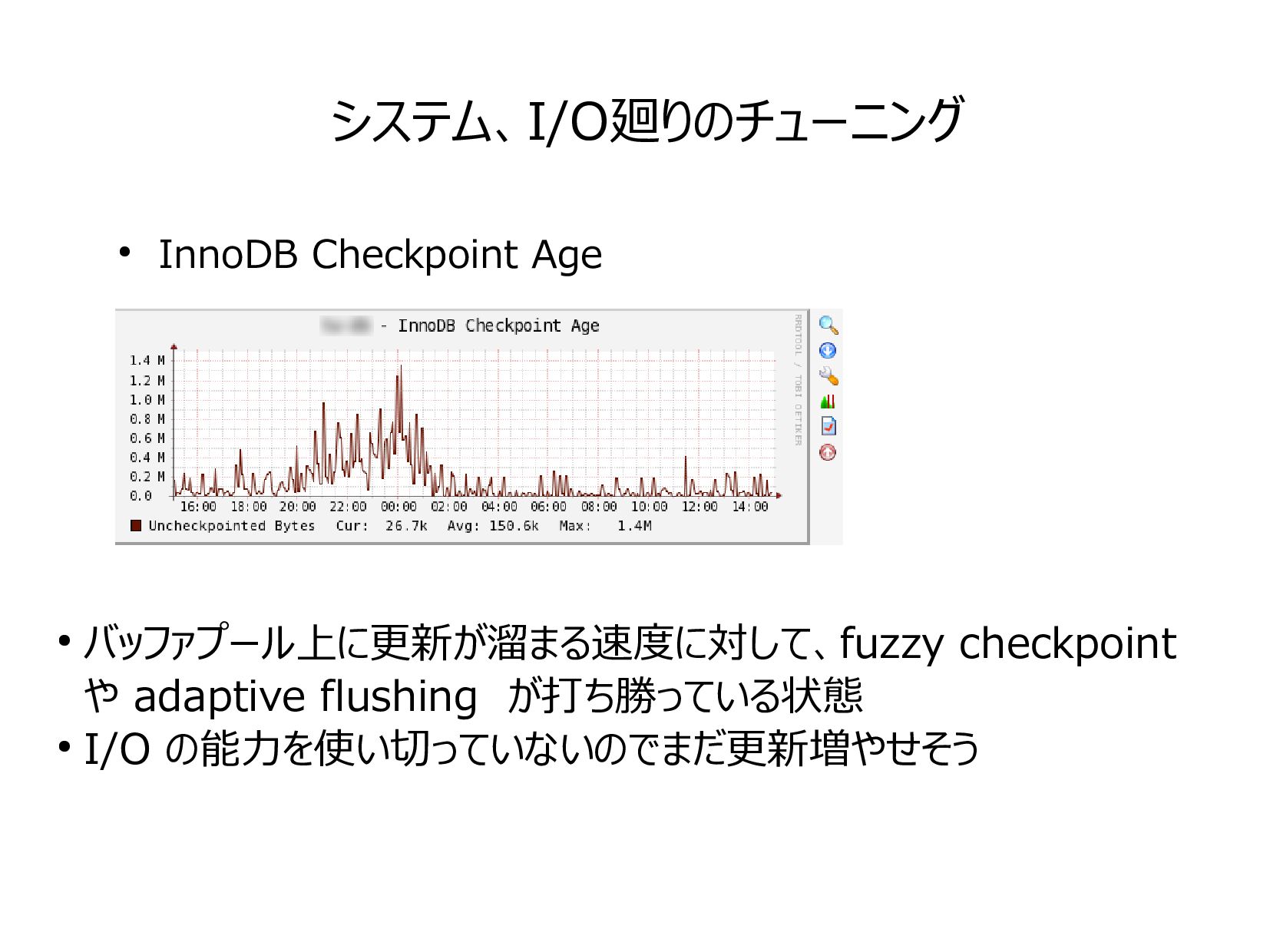{kind=link}
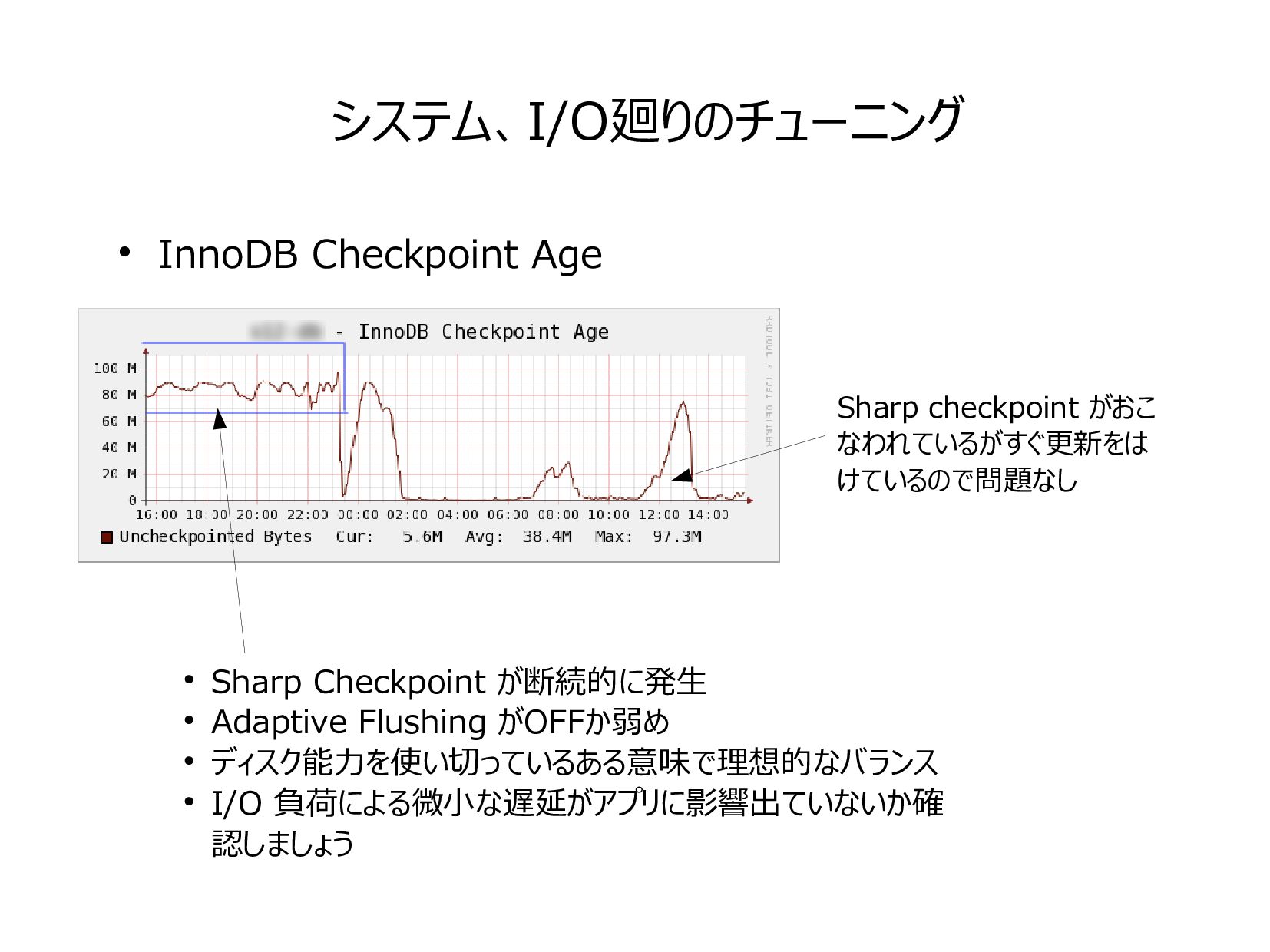{kind=link}
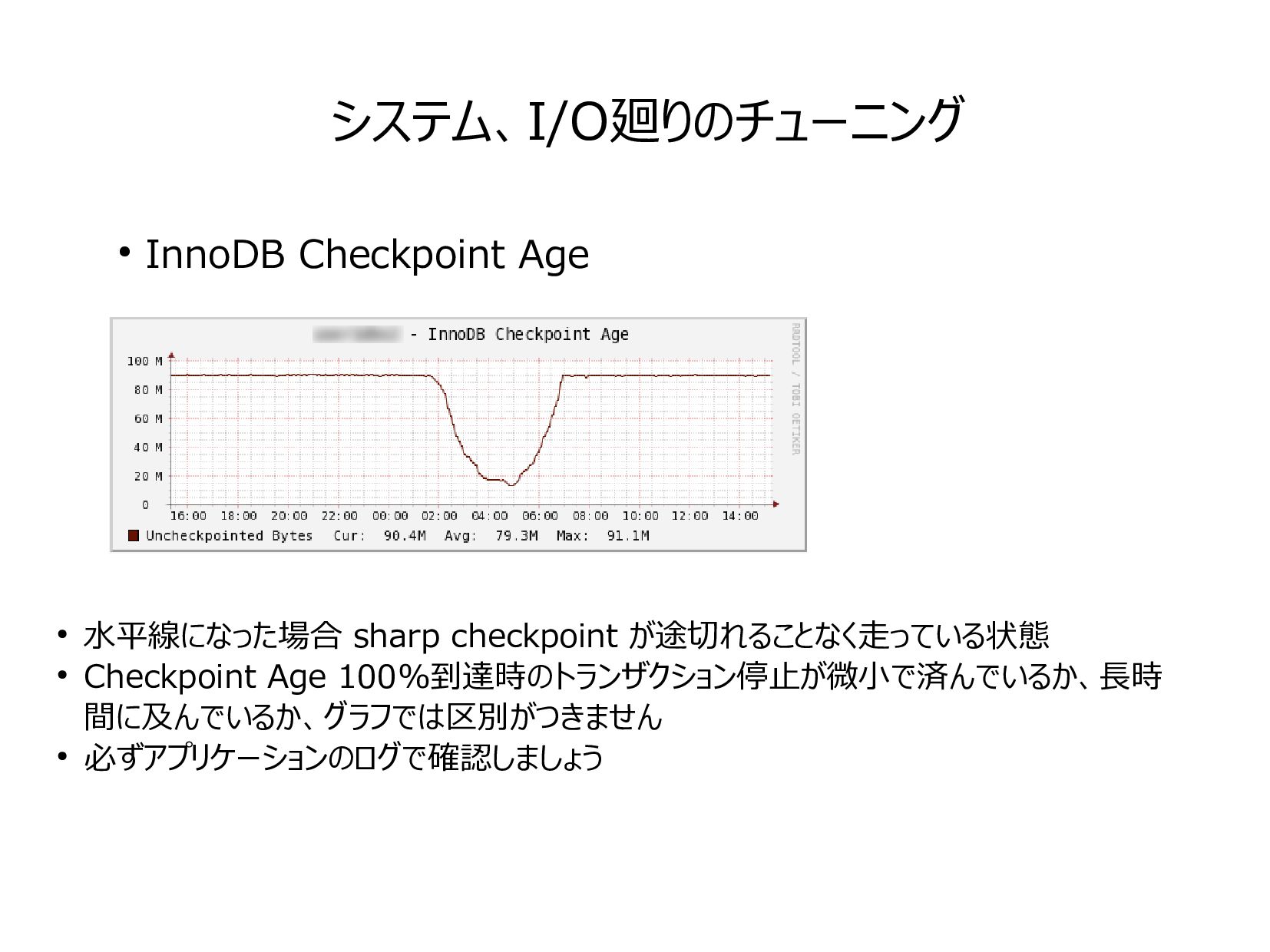{kind=link}
{kind=link}