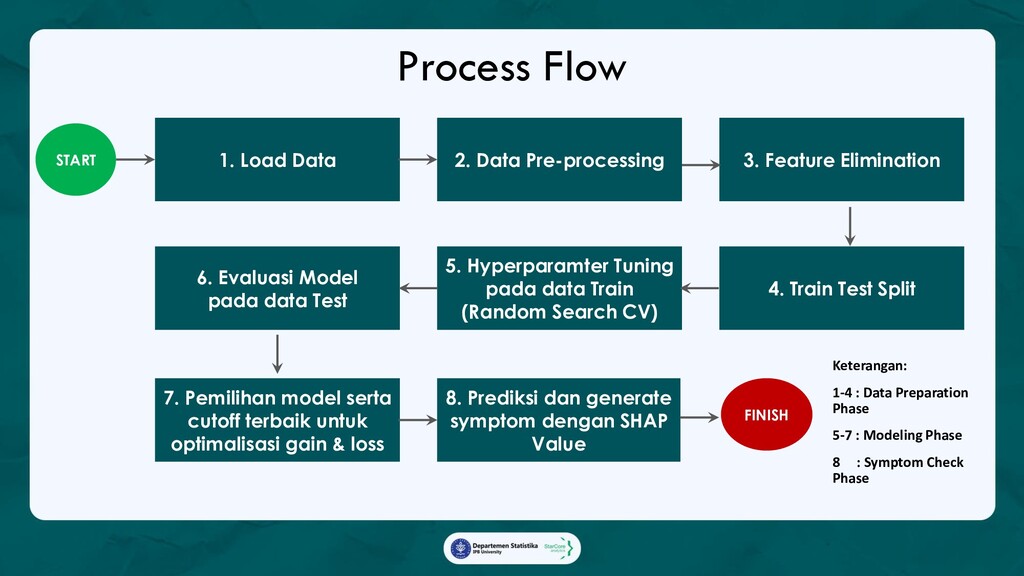
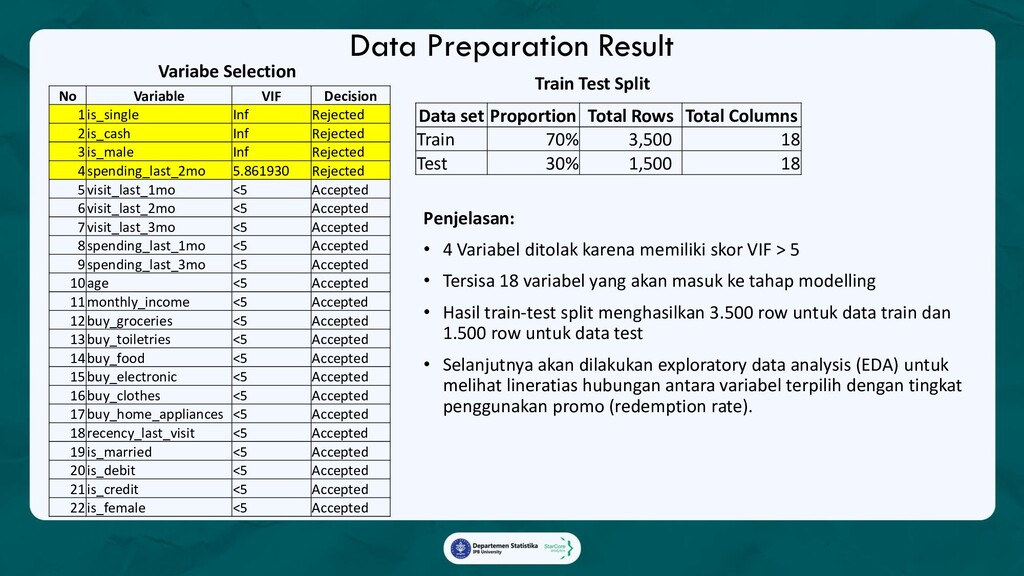
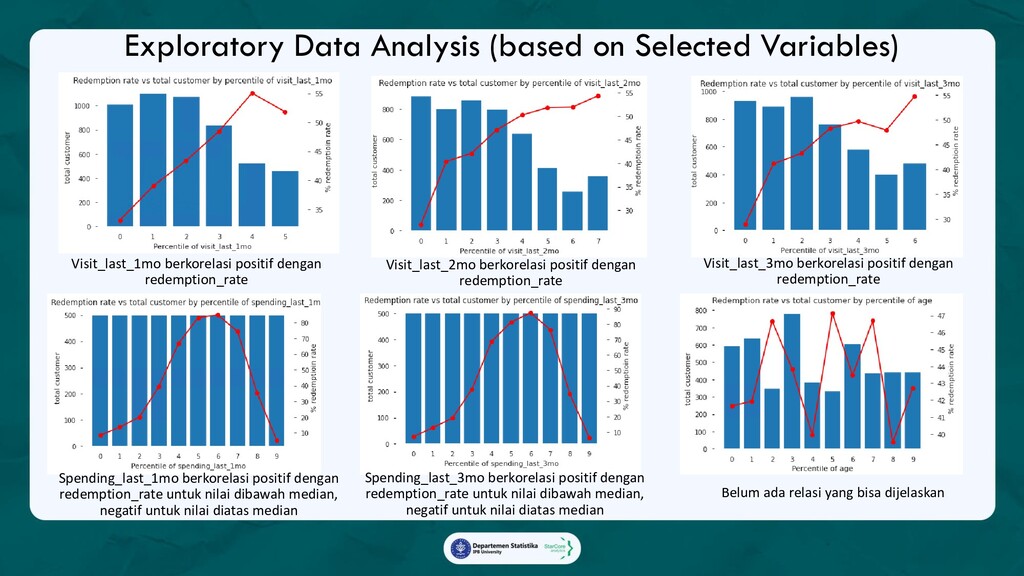
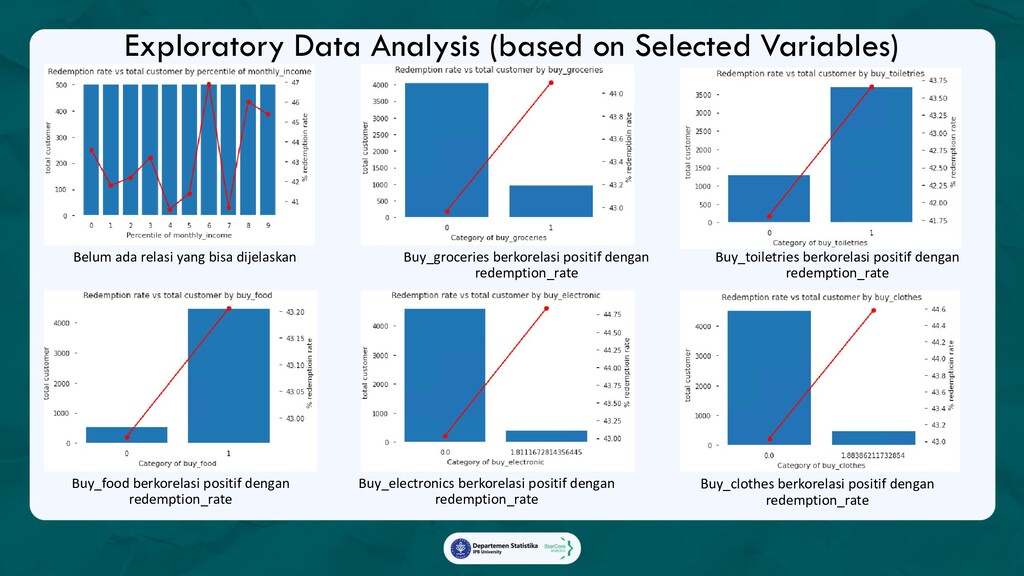
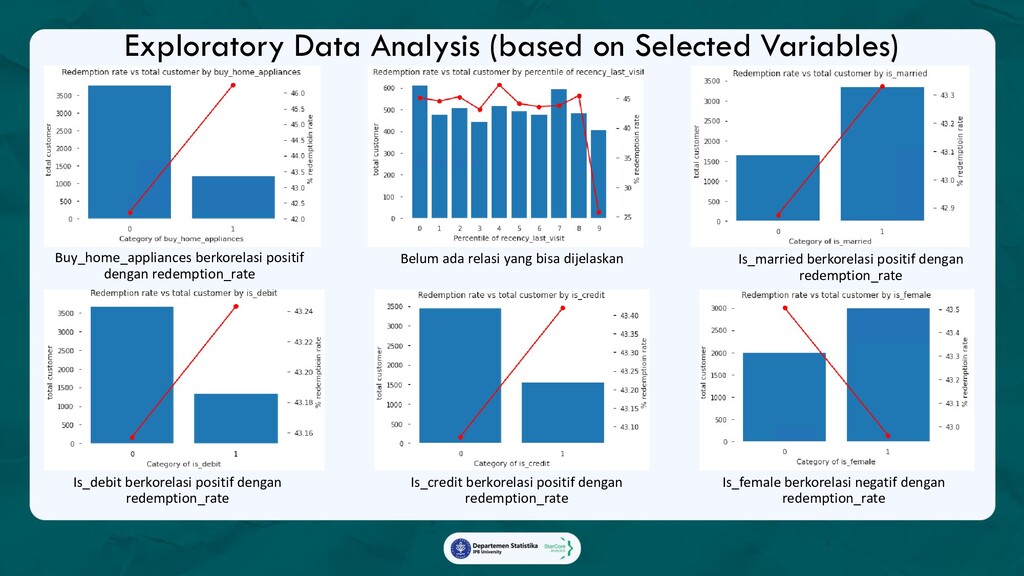
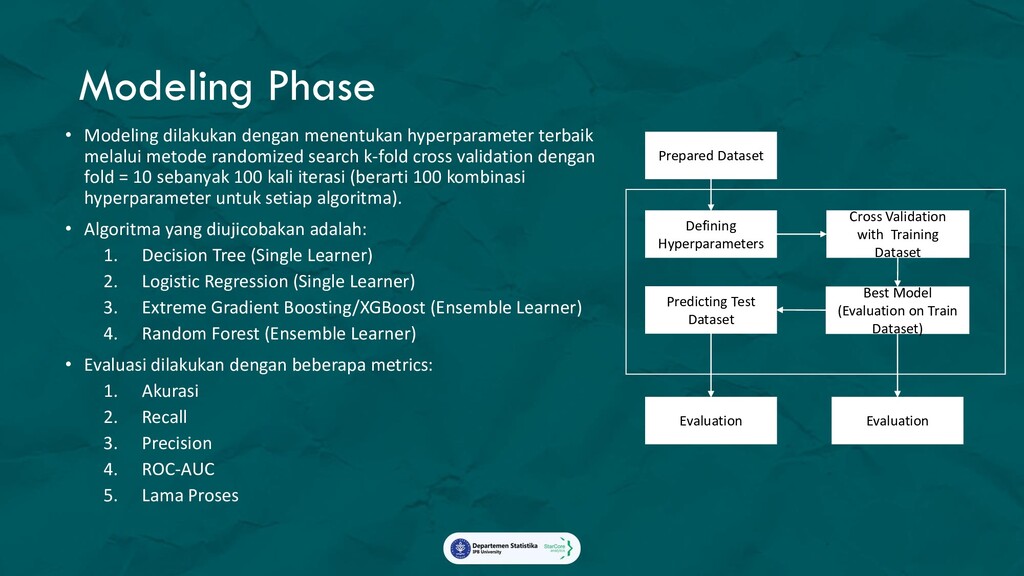
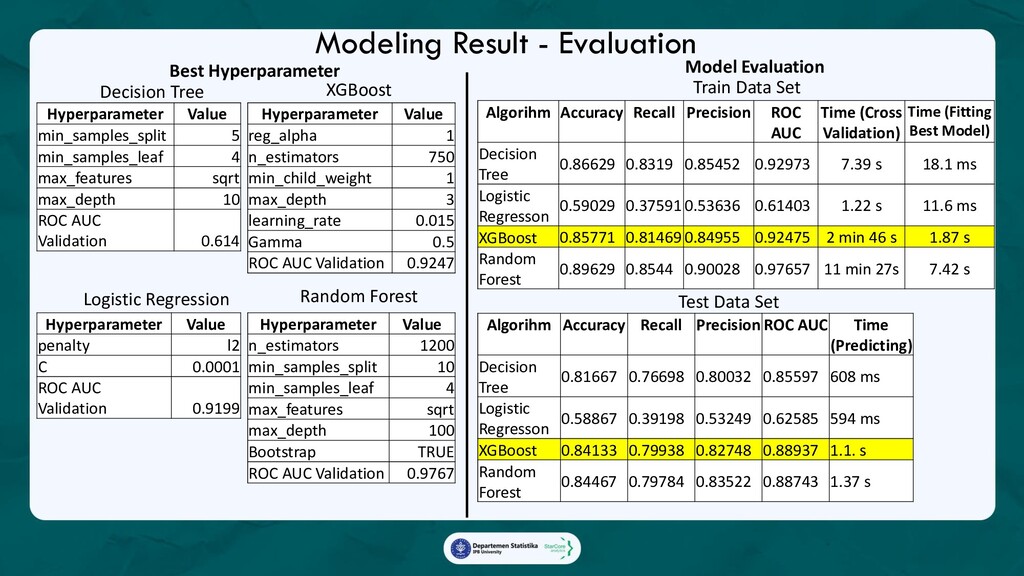
Ada 3 analytics yang diterapkan dalam marketing campaign:
1. Promo Redemption Model with SHAP value,
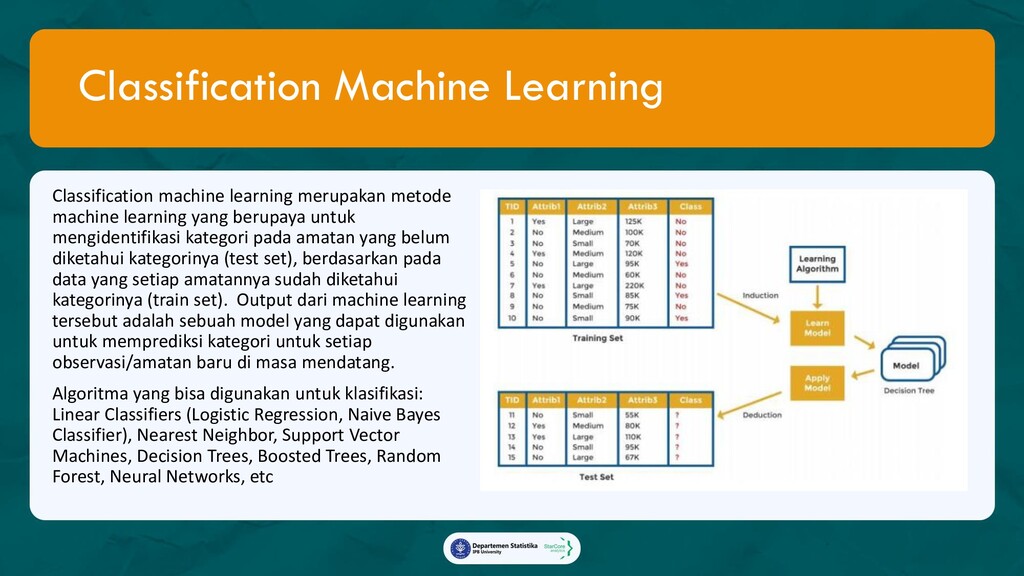
Model yang akan memprediksi apakah seorang pelanggan akan menggunakan promo yang diberikan,
beserta faktor-faktor yang mempengaruhi keputusan tersebut
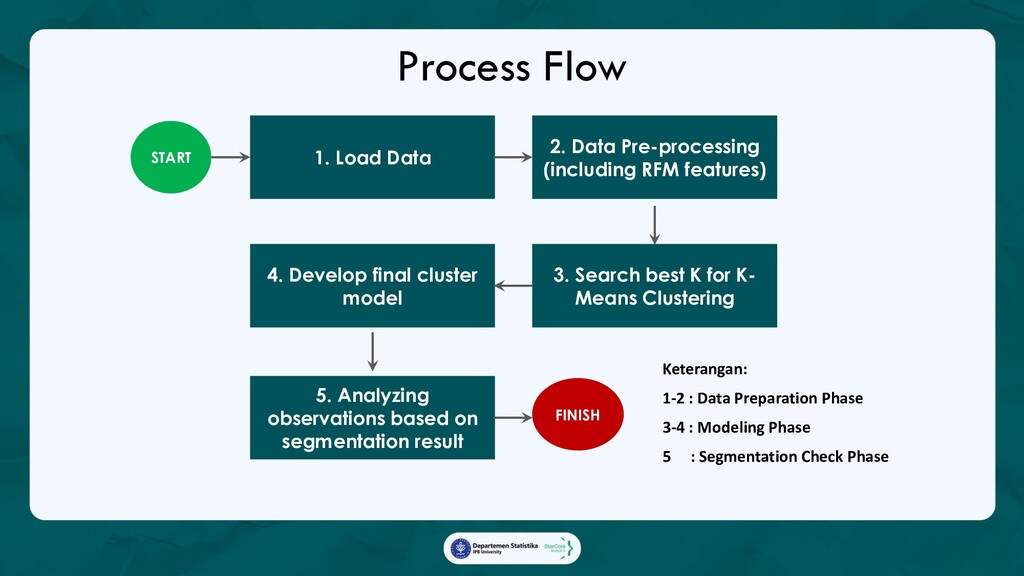
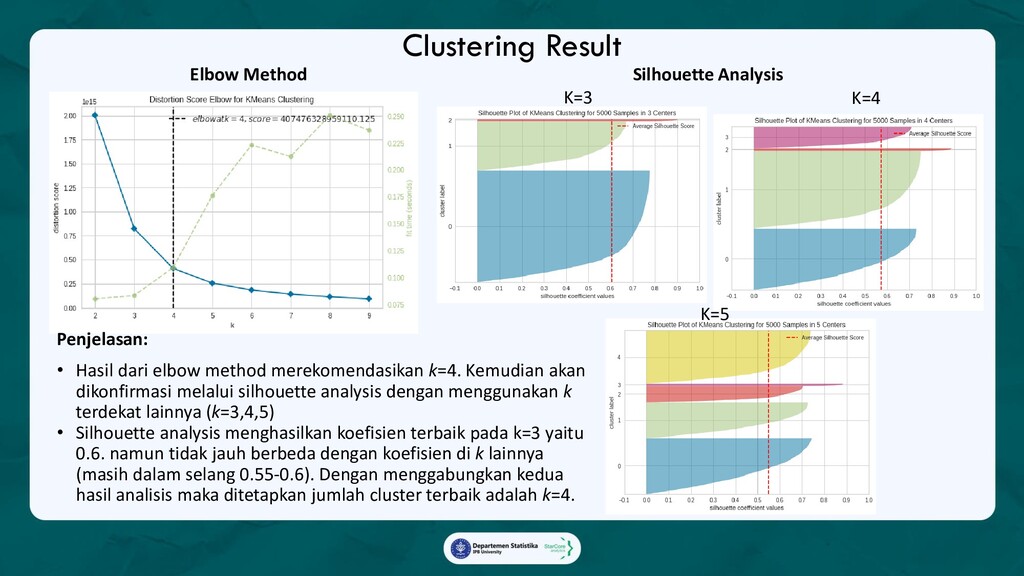
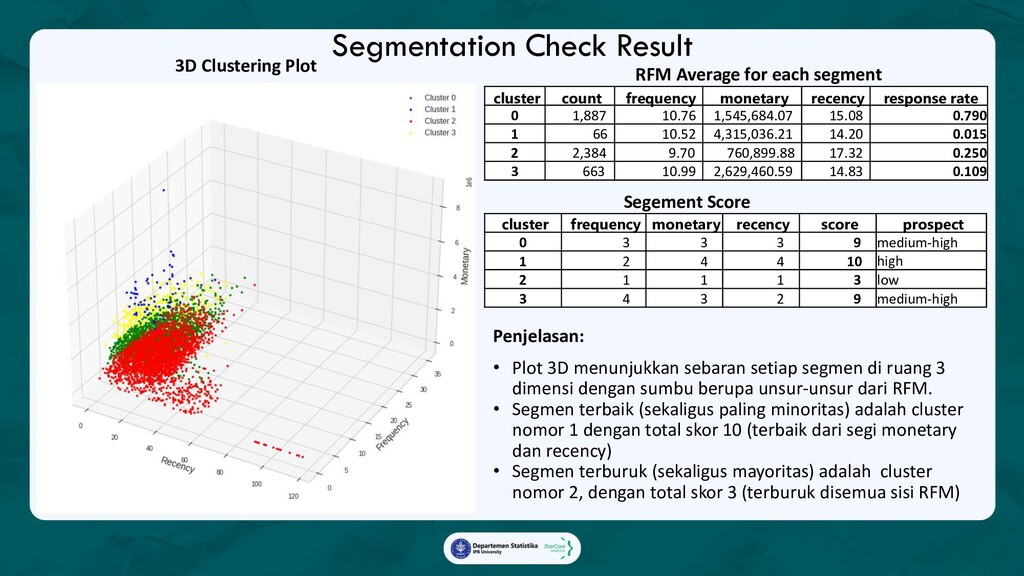
2. Customer Segmentation with RFM,
Membagi pelanggan yang mengikuti campaign ke dalam beberapa segmen, kemudian menilai prospek
dari masing-masing segmen, dan memberikan rekomendasi segmen manakah yang berpotensi
meningkatkan pendapatan SAS-MART.
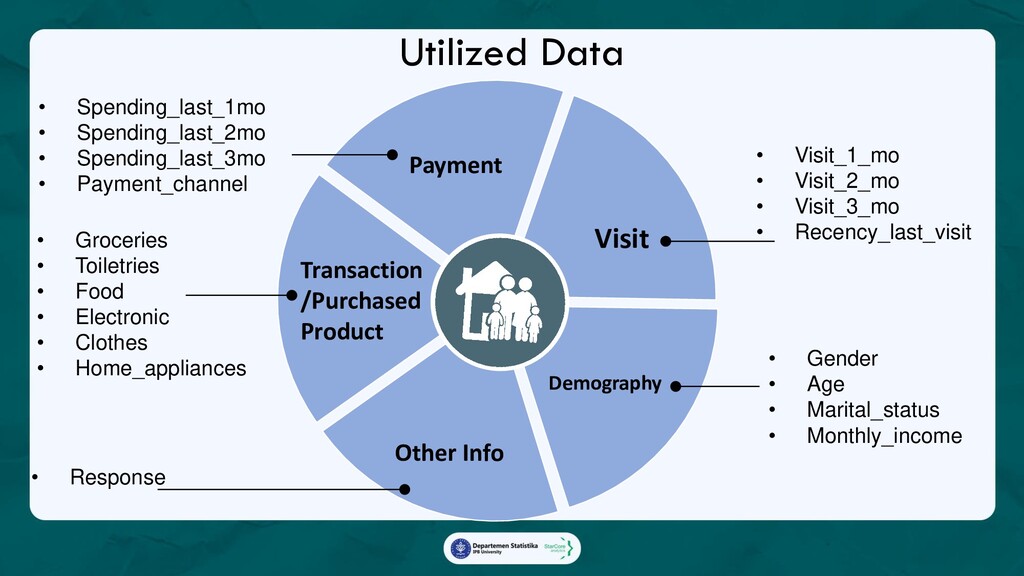
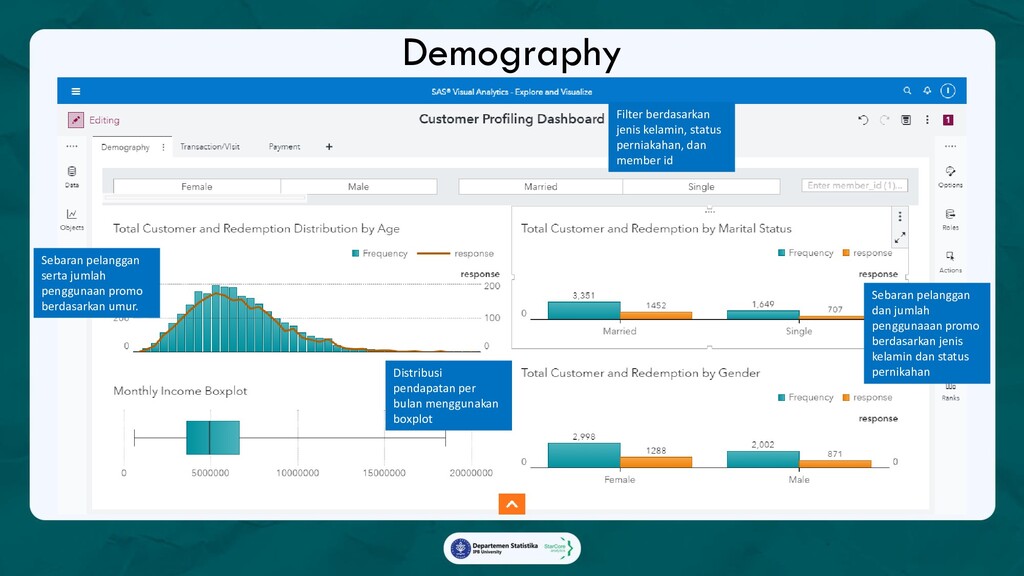
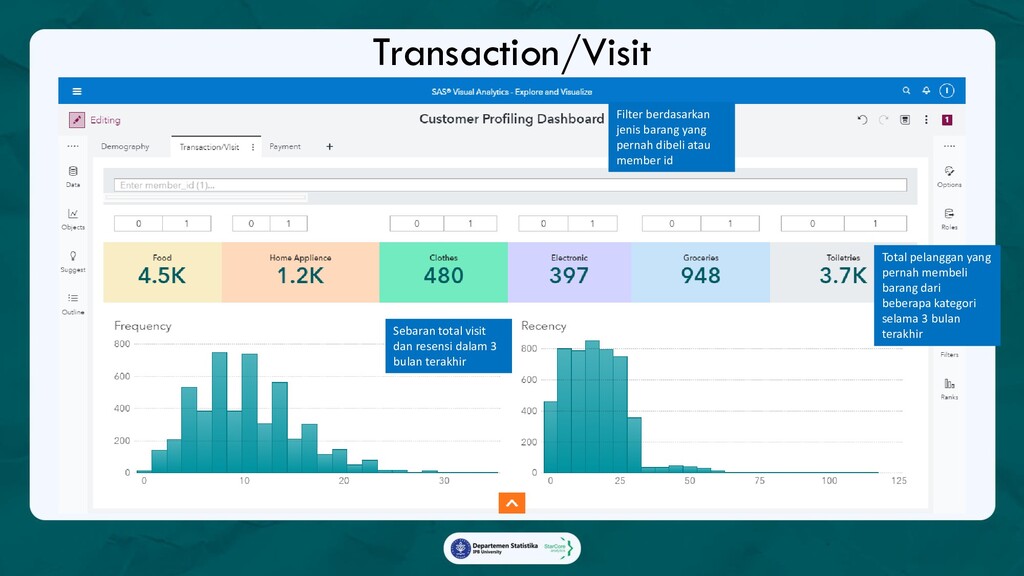
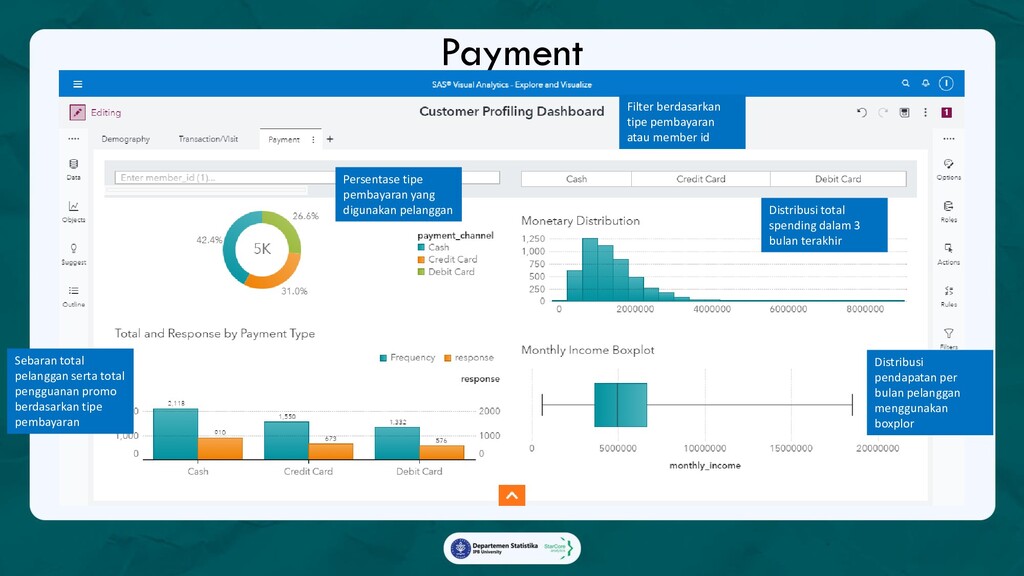
3. Customer Profiling Dashboard, Dashboard yang memberikan profil lengkap pelanggan yang mengikuti campaign, sebagai referensi
dalam membangun gimmick campaign yang lebih menarik dan personalized sehingga memiliki tingkat
keberhasilan yang lebih tinggi.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}