Storage Ø Typically 10x faster, at down to 1/10th the cost Ø Scales to supercomputing levels of performance How? Ø Client-side rather than Server-side storage technology Ø Leverages our 40+ man-years of IP creating high perf client-side virtual filesystems Ø Allows us to disentangle and predict application access patterns Ø Exploits Object Storage for scalability and cost Ø Solved POSIX<->Object compatibility problems thought to be impossible before Ø Innovative encoding and compression of POSIX metadata 2
of genomics data files Resulting in files 60-91% smaller Transparent, random access, just-in-time decompression User-mode library streams compressed data to analysis tools as native files Compress and move data to local or cloud object storage in one step Accelerated transparent access to files in object storage as local file systems FIPS 140-2 Encryption Fine-grained access control, redaction Transaction control Full Audit PetaGene quick intro 4 2016 2018 2019
of genomics data files Resulting in files 60-91% smaller Transparent, random access, just-in-time decompression User-mode library streams compressed data to analysis tools as native files Compress and move data to local or cloud object storage in one step Accelerated transparent access to files in object storage as local file systems FIPS 140-2 Encryption Fine-grained access control, redaction Transaction control Full Audit PetaGene quick intro 5 2016 2018 2019
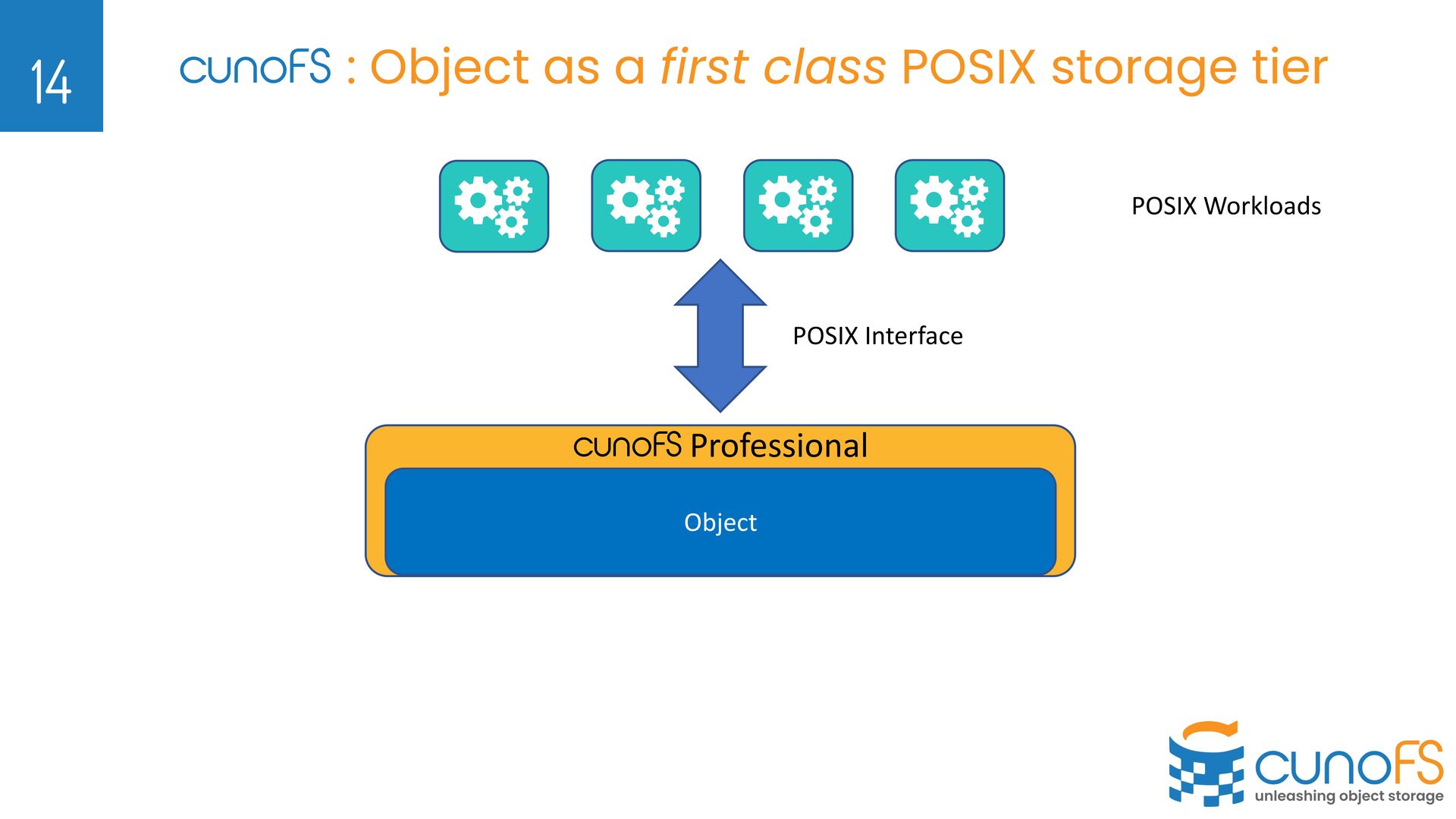
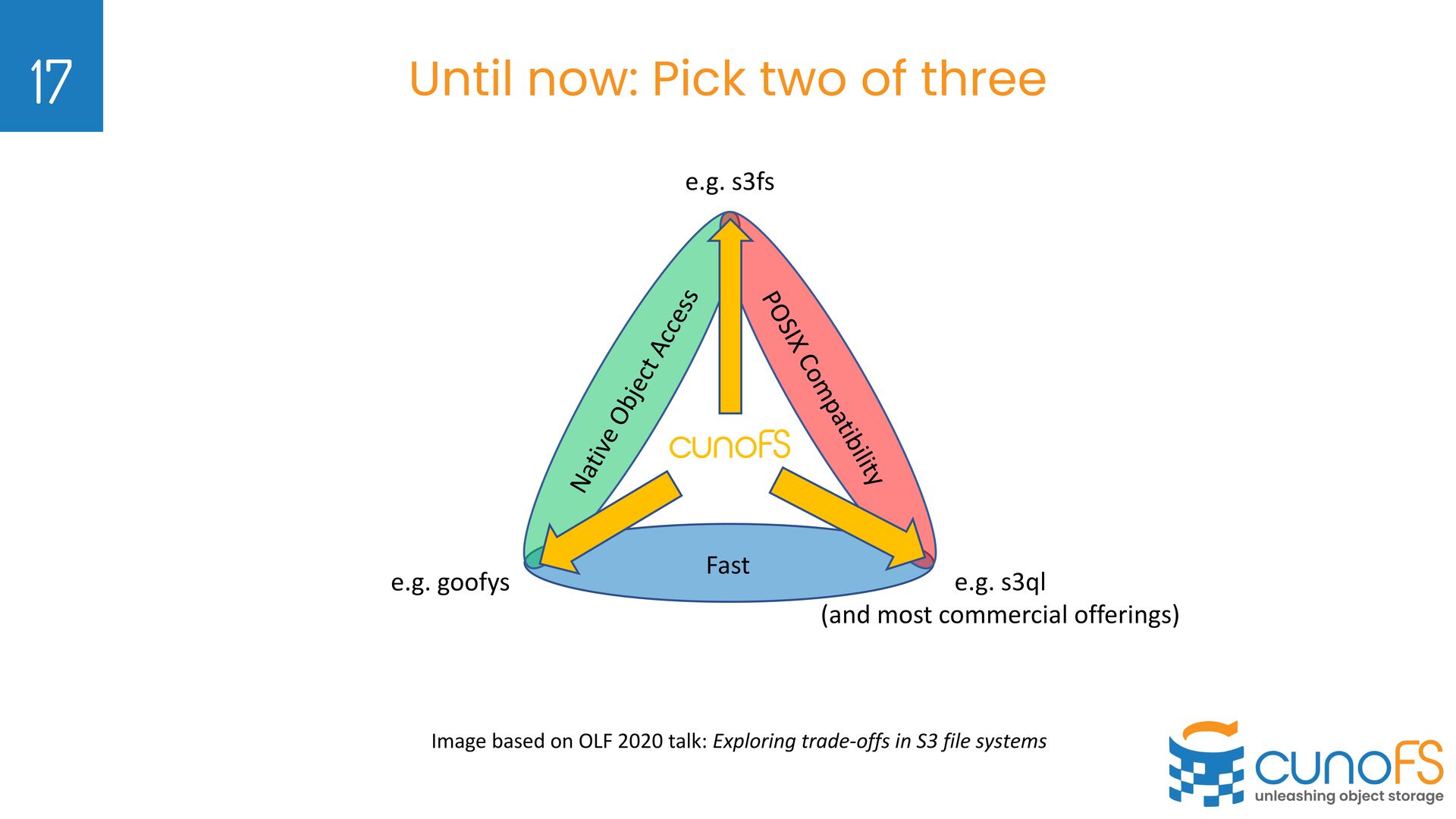
was built for large genomics workloads BUT was being used by customers for all sorts of non-genomics data Ø Not intended use-case, but PetaSuite Cloud Edition was being compared to general file-on-object competitors: Ø We won by 10x on fast large file access (what we built it for) Ø Lost on small files Ø Lost on POSIX compatibility Ø What if we intentionally design for these use cases? Ø cunoFS solved above problems and further boosted performance Ø cunoFS re-brand to expand outside Life Sciences and Genomics 7
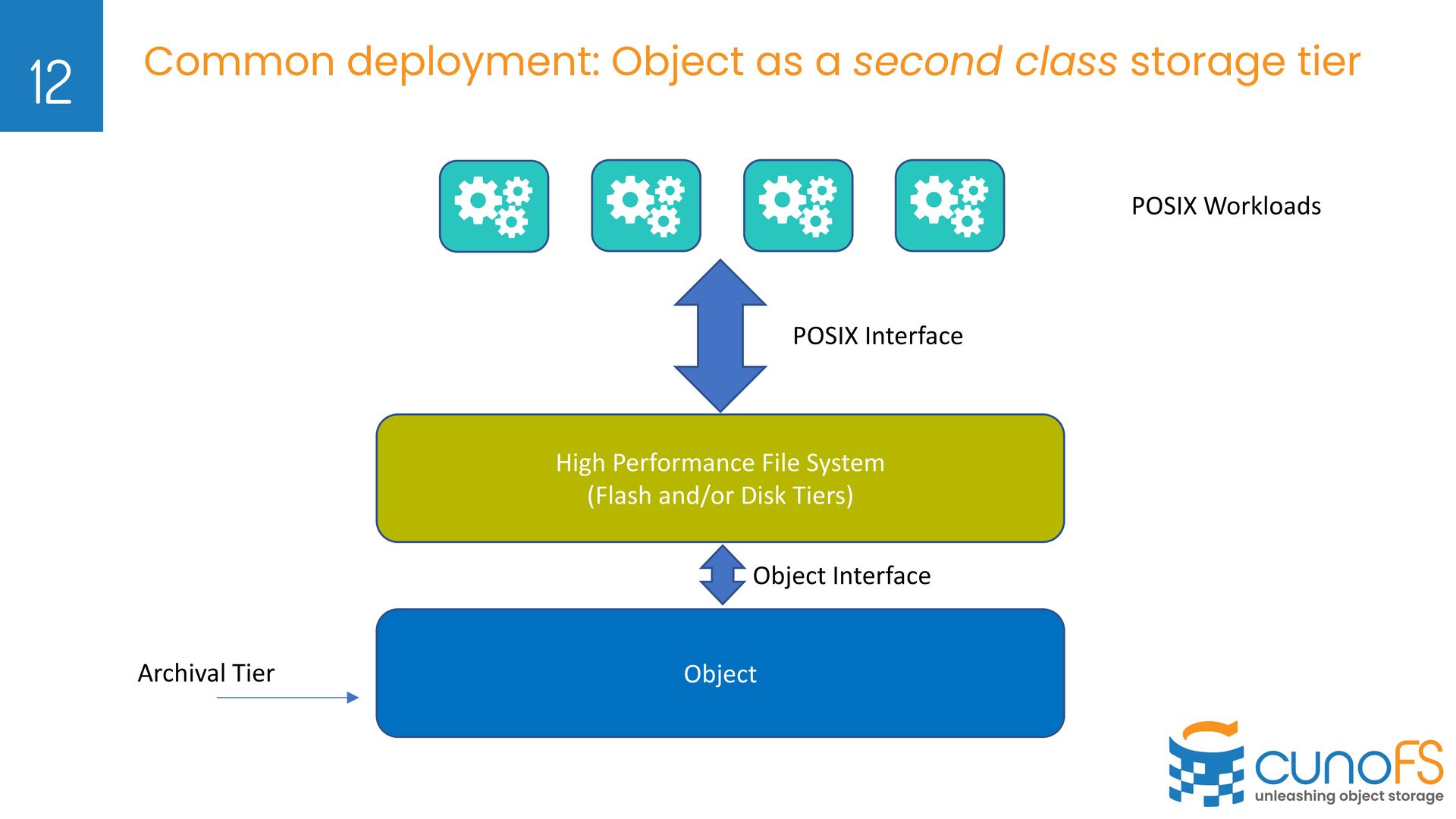
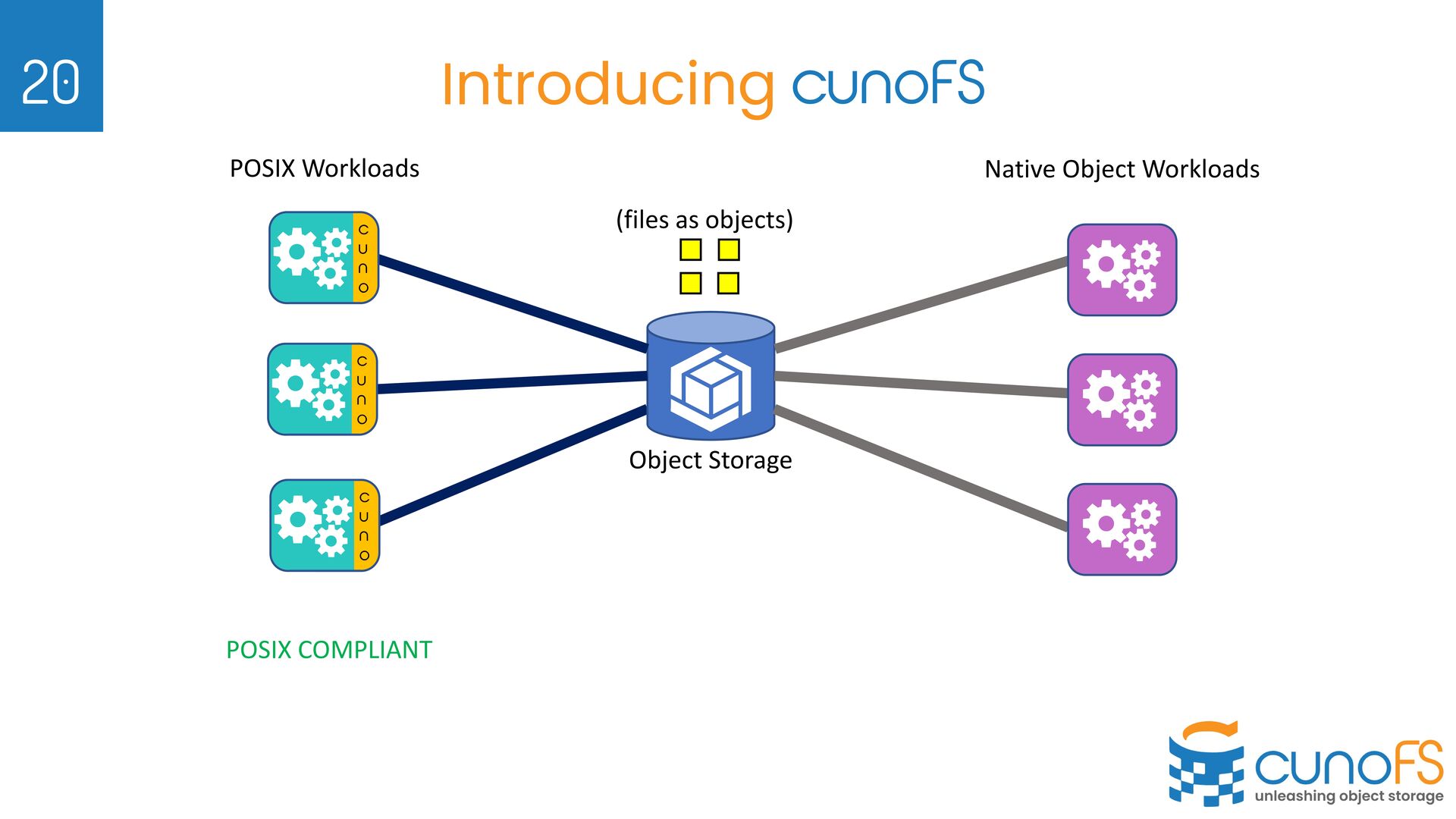
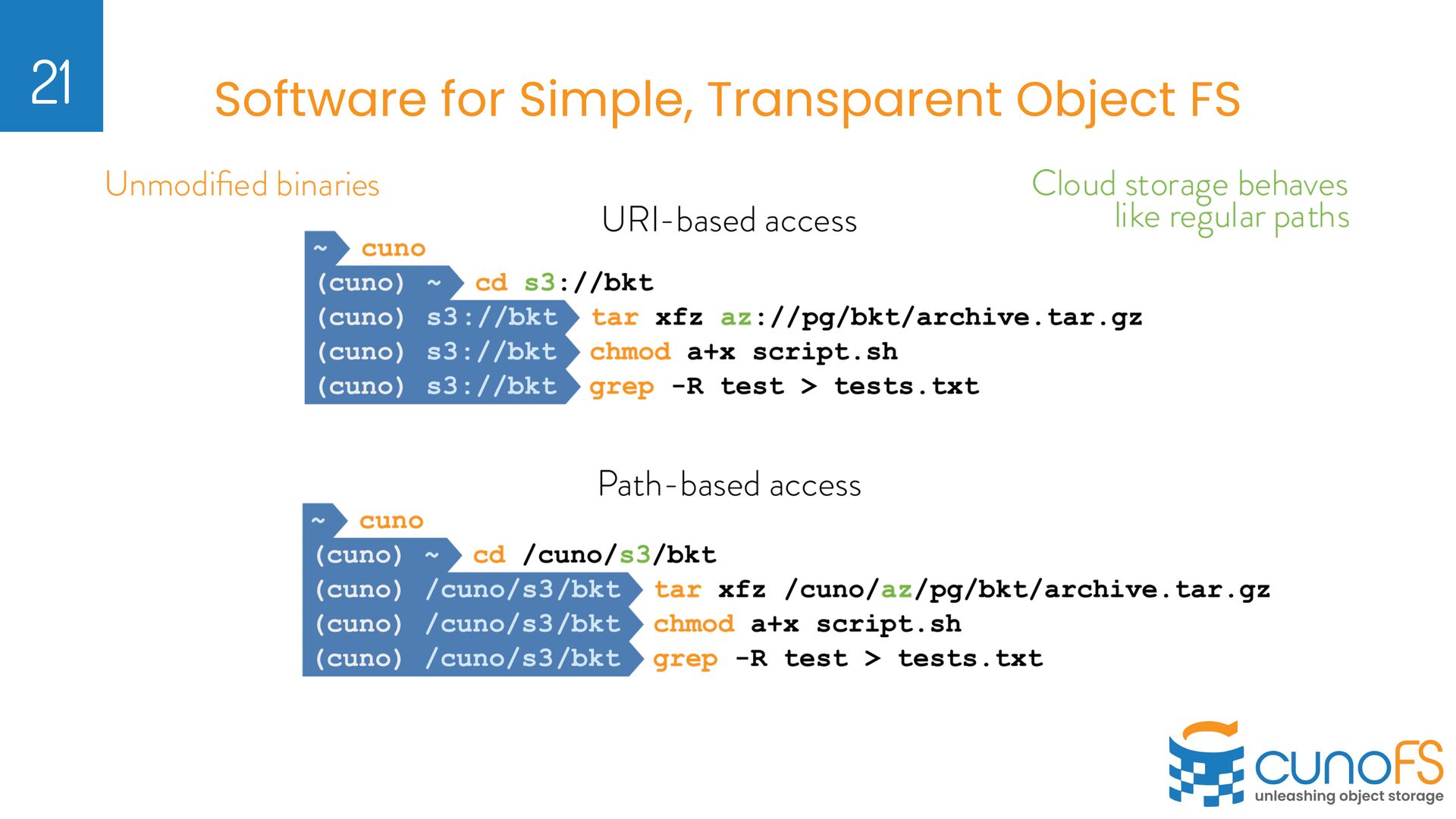
We do not sell software for building your own Object Storage Ø We sell software that enables Object Storage (cloud / on-prem) to be used as fast, POSIX File Storage 8
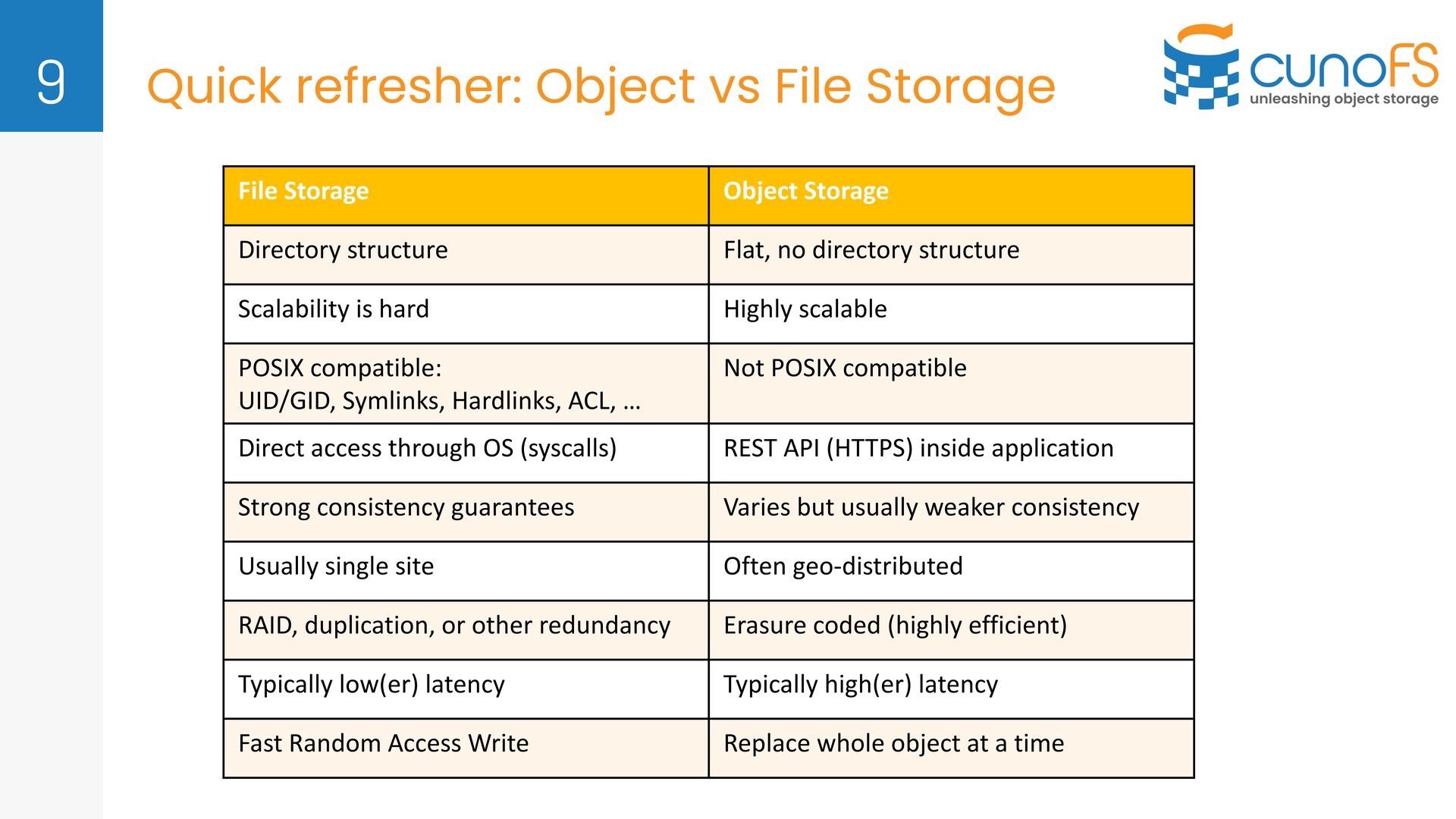
Storage Directory structure Flat, no directory structure Scalability is hard Highly scalable POSIX compatible: UID/GID, Symlinks, Hardlinks, ACL, … Not POSIX compatible Direct access through OS (syscalls) REST API (HTTPS) inside application Strong consistency guarantees Varies but usually weaker consistency Usually single site Often geo-distributed RAID, duplication, or other redundancy Erasure coded (highly efficient) Typically low(er) latency Typically high(er) latency Fast Random Access Write Replace whole object at a time
be an order of magnitude less expensive than file storage Ø Cost example on AWS: Ø 1TB on FSx Lustre = $1,680-$7,200 pa (scratch to high perf File storage) Ø 1TB of EFS (standard storage) = $3,600 pa Ø 1TB on S3 = $276 pa Ø 1TB of EFS (20% standard, 80% infrequent) = $960 pa (AWS EFS pricing example 2) Ø 1TB on S3 (20% standard, 80% infrequent) = $175 pa Ø 1TB EFS Machine Learning workload = $6792 pa (AWS EFS pricing example 6) Ø 1TB on S3 with this workload = $340 pa 10
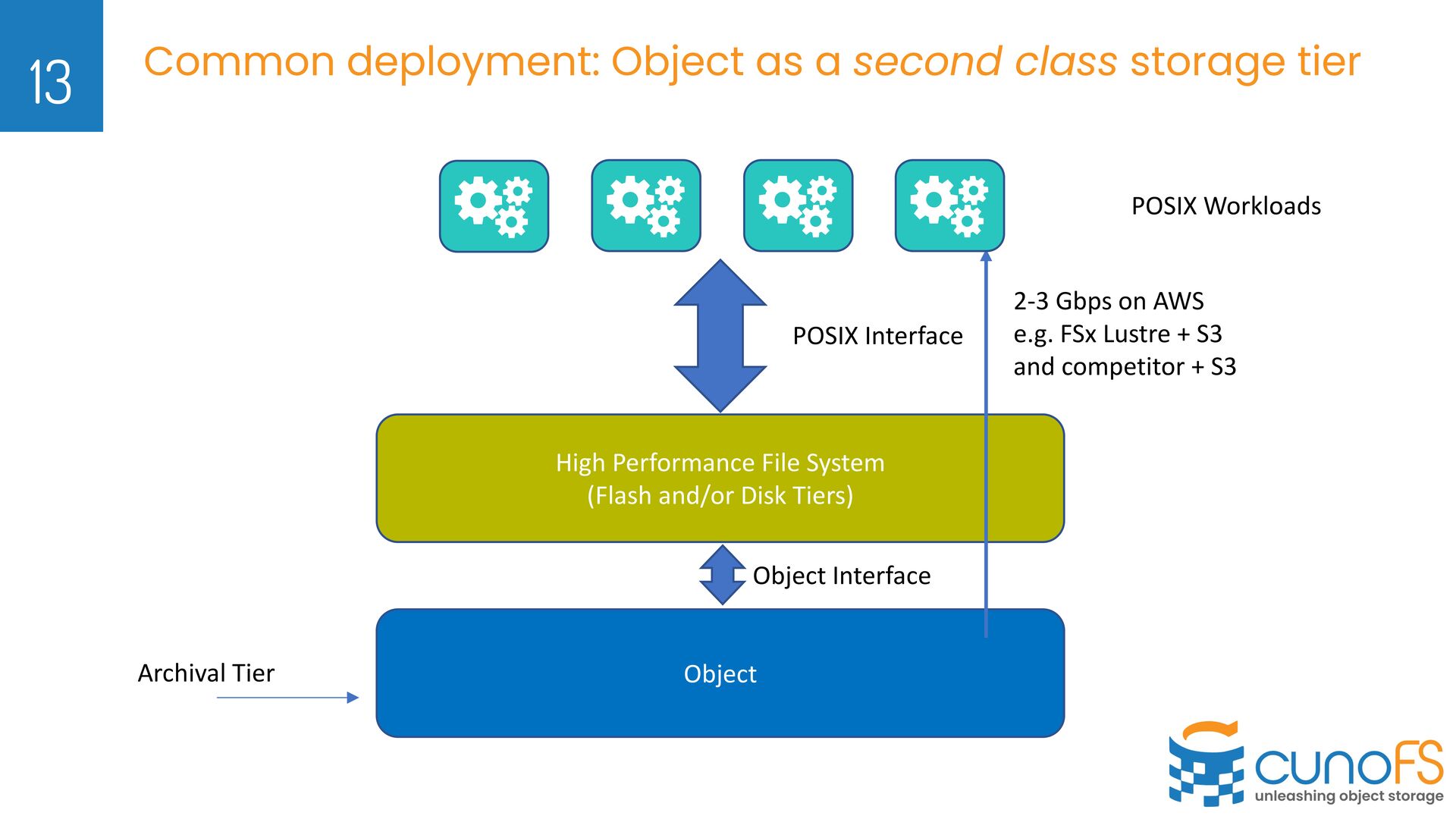
POSIX Interface Archival Tier Object Interface 2-3 Gbps on AWS e.g. FSx Lustre + S3 and competitor + S3 POSIX Workloads Common deployment: Object as a second class storage tier
Gateway Usual competing approach: Object+DB gateway Native Object Workloads Object Gateway (bottlenecks in red) POSIX COMPLIANT scrambled file data: N F S N F S N F S (bottlenecks in red) POSIX Workloads
Gateway Usual competing approach: Object+DB gateway Native Object Workloads Object Gateway (bottlenecks in red) POSIX COMPLIANT scrambled file data: N F S N F S N F S (bottlenecks in red) POSIX Workloads
file storage (faster + cheaper) Ø e.g. AWS EFS, FSx Lustre and similar on Azure and Google Cloud Ø Many customers already use a lot of object storage BUT apps unable to directly use it Ø Eliminate staging to/from block storage (e.g. AWS EBS) Ø Convenient, fast access to object storage repositories Ø On prem Ø Replacing expensive file storage with on-prem object storage Ø Eliminates staging Ø Fast File-system Backups and Disaster Recovery Ø Hybrid Ø Bursting workloads with datasets from on-prem object store TO cloud compute Ø Access in-cloud object stores from on-prem
IOPS and to be very large in size Ø GPUs are throughput-hungry and need to be fed randomly shuffled datasets over and over again Ø In the past IT budget holders saw two classes: small but fast storage (expensive per TB), large but slower storage (inexpensive per TB) Ø Now they are alarmed by ML as needing BOTH large and fast storage (many PB of expensive high-IOPS flash storage such as NVMe) Ø However, what is actually needed is high throughput storage
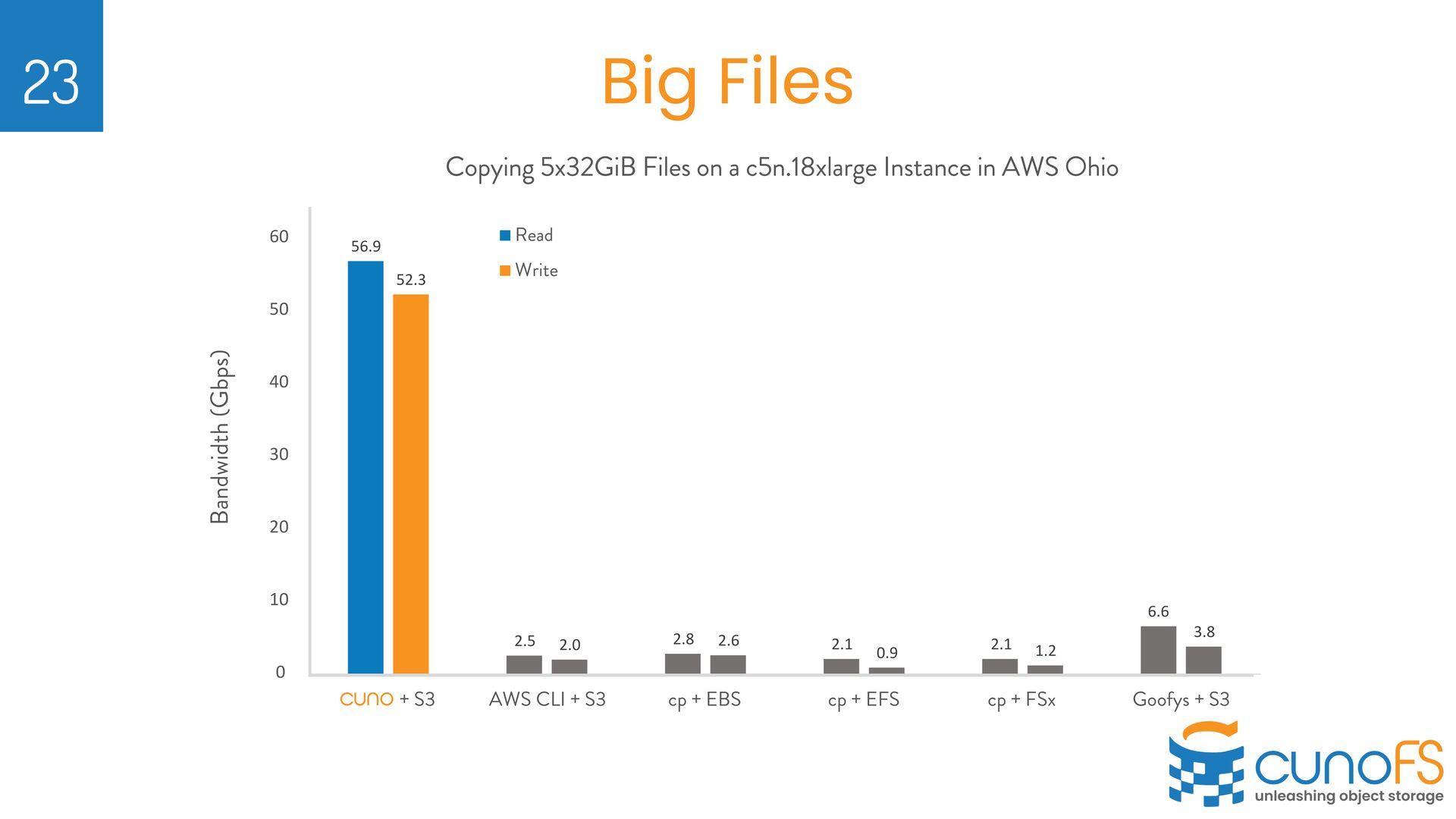
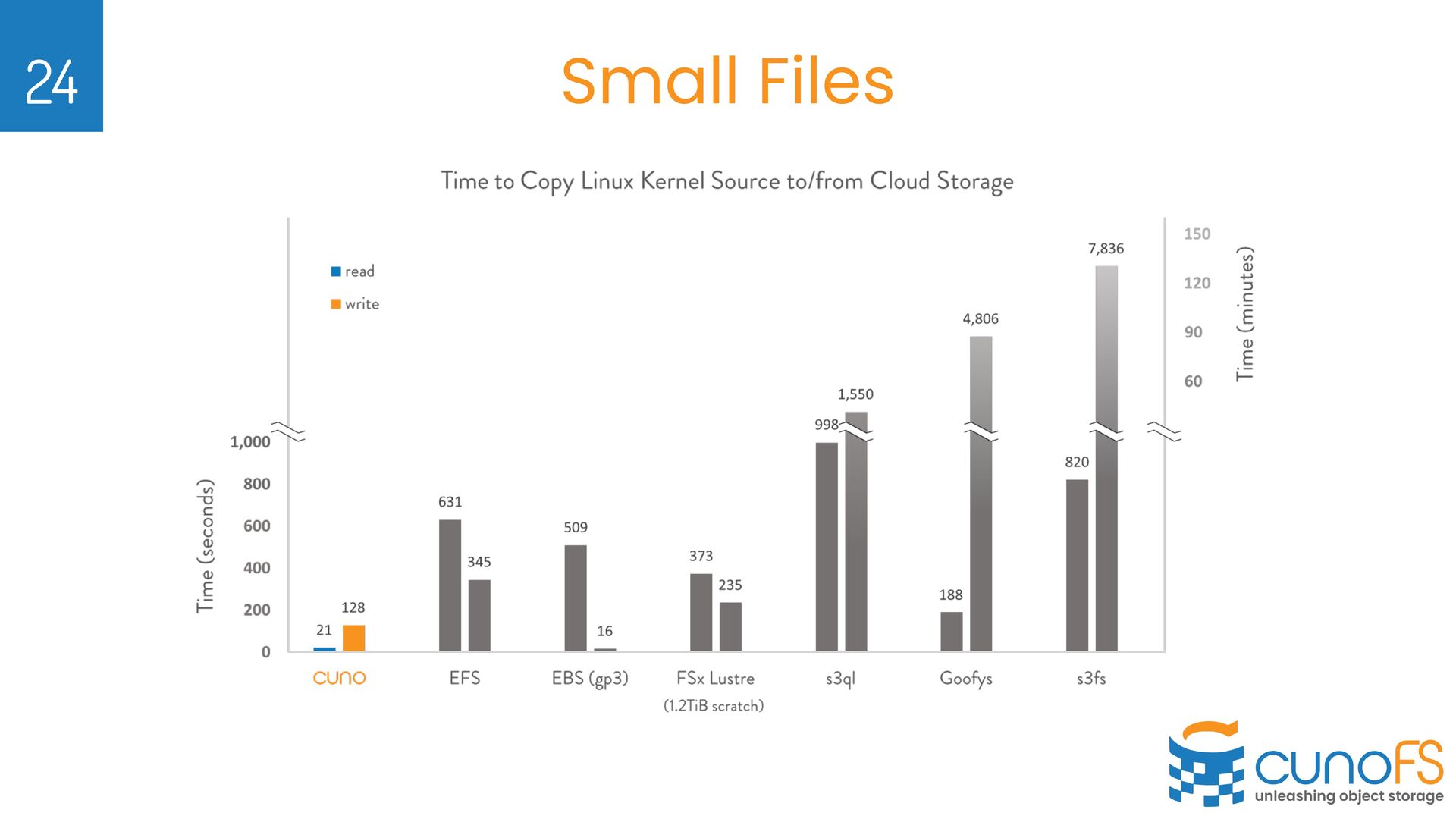
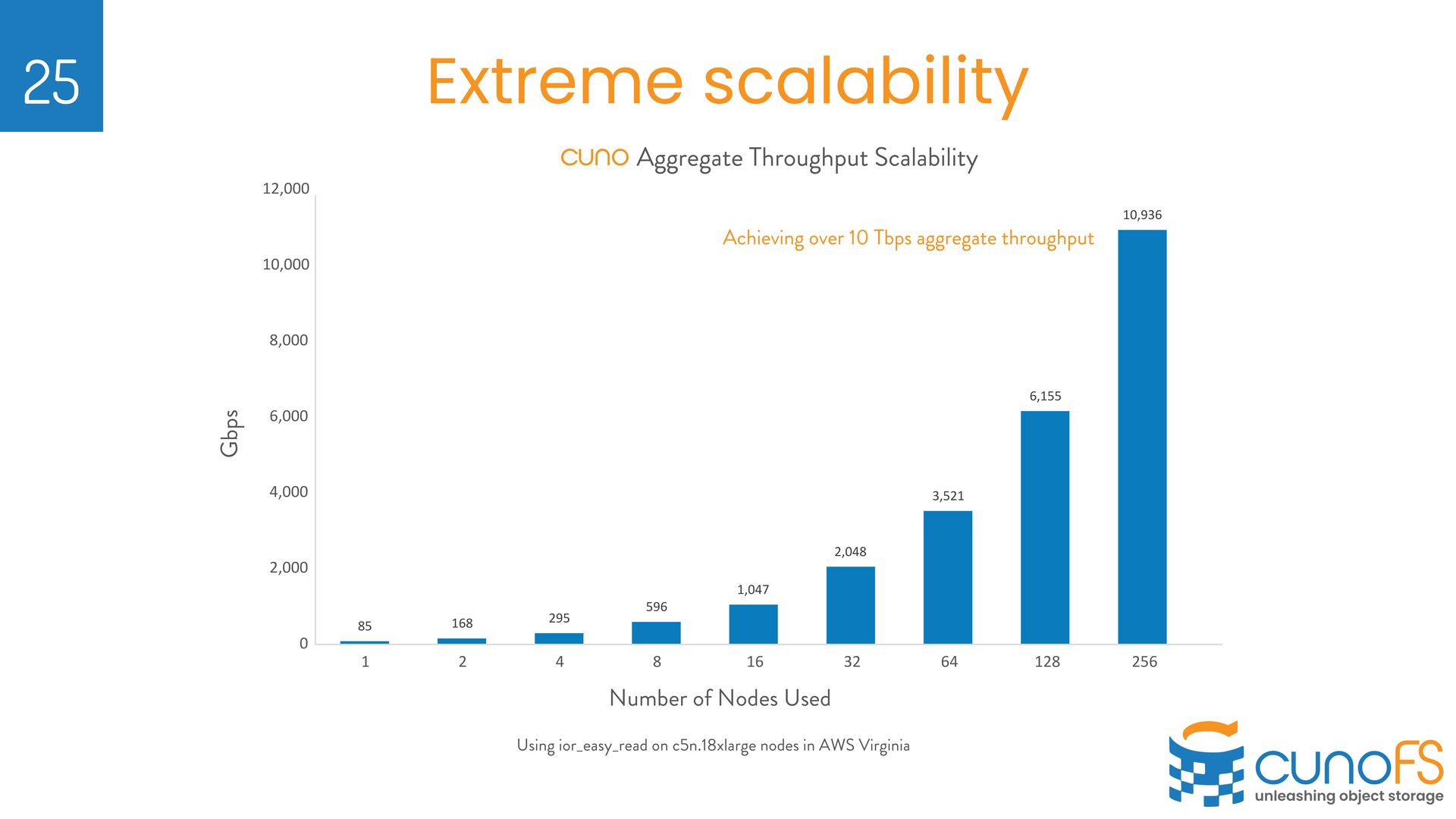
on their own Object Storage Ø Validated performance metrics seen on AWS Ø https://infohub.delltechnologies. com/t/cuno-s3-performance- and-validation-testing
random pieces of data tend to be IOPS- limited Ø Truly random I/O is not suitable for Object Storage Ø This includes most database workloads Ø However we argue that most applications are throughput-limited rather than IOPS limited. Most workloads are not really random I/O. Workloads are quite deterministic.
globally distributed, wants to speed up analysis while reducing costs. Using cunoFS to replace AWS FSx Lustre and EFS. Ø Pharma companies – scientific compute (e.g. omics analyses) and ML workloads on lots of images. One pharma would eventually like to place all their users’ home directories on cunoFS with Object Storage. Ø Media organisation – testing cunoFS with media workloads Ø Large supercomputing centre – HPC workloads Ø Space agencies – one commenced, another upcoming
support but not Azure or Google Cloud Ø cunoFS intercepts applications and can override built-in S3 support, and add Azure & GCP support Ø Download is 4.8x faster Ø Upload is 30x faster cuno enables organisations to quickly and easily broaden theusage ofobject storagewithout theneed for code changes or updates to existing mission critical applications. 0 100 200 300 400 500 600 cuno + samtools samtools cuno + samtools samtools Time (seconds) Download Upload Real-world Benchmarks: Samtools
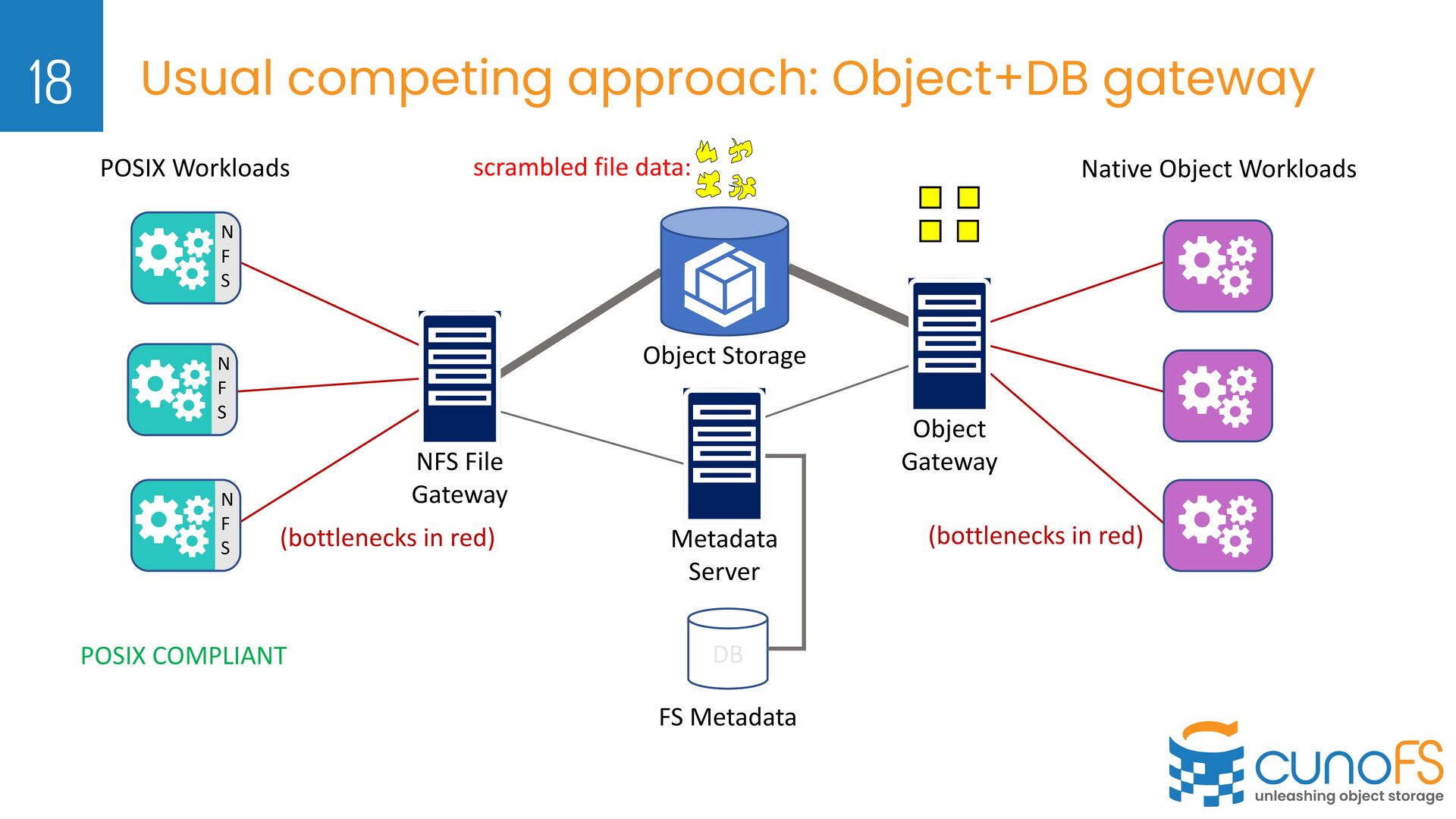
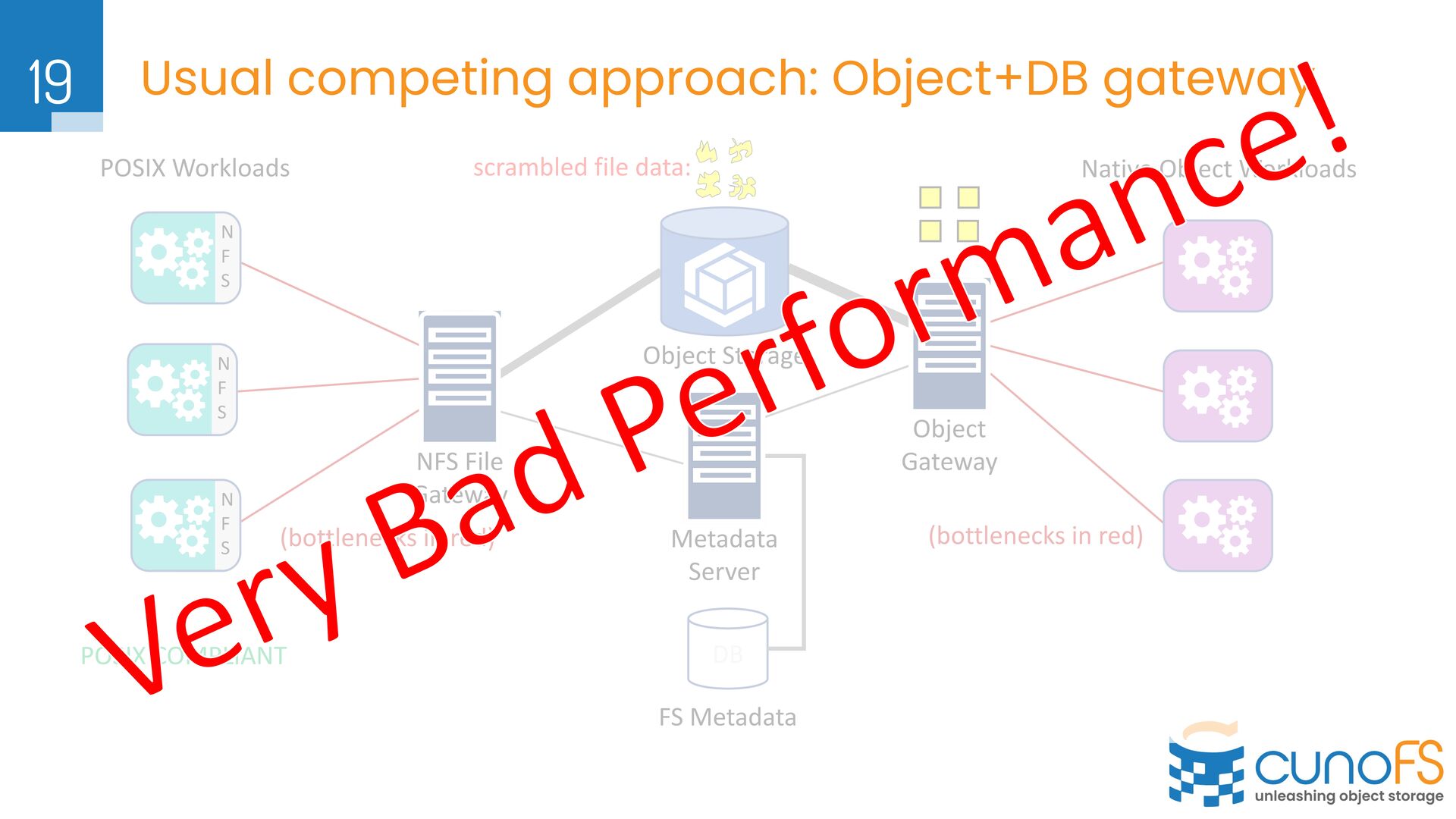
object storage for data chunks, separate DB for metadata Ø Separate DB servers, scalability issues, consistency issues in backup/restore with object store Ø Data is scrambled and inaccessible via native API Ø Store POSIX metadata inside per-object metadata (very slow and immutable) Ø Per-object overhead of retrieving metadata (e.g. dirlisting 1000 files => 1000+ API calls) Ø Changing metadata (e.g. access permissions) involves overwriting whole object Ø Our approach: Ø POSIX metadata tends to be highly compressible, and slow changing Ø Novel composable encoding for POSIX metadata Ø Encode POSIX metadata as hidden, long filenames Ø LIST API operation retrieves both list of files and encoded metadata
can be vague in places and misinterpreted Ø Ultimately AWS S3 behaviour is the “real” spec, and what SDKs are written against Ø Unlike POSIX which is more easily defined and tested, S3 compatibility is very mixed Ø We’ve had to build cunoFS to be resilient to S3 backend bugs and missing APIs Ø Some vendors only support a subset of S3 APIs, this is not what we mean by bugs Ø We’ve dealt with very many different backend S3 API bugs and behaviours so our customers don’t have to, including from major vendors Ø Even Google Cloud with considerable resources have bugs we’ve had to work around Ø Worse – we’ve detected some bugs that only appear at high load! Ø cunoFS detects backends so it adapts accordingly Ø cunoFS can also run conformance testing when pairing buckets, and cunoFS adapts according to what it detects
Ø Early engagement with some Object Storage partners Ø Engaging with regional resellers Ø Publicly downloadable free trial to be launched (in July) Ø Currently there’s a waiting list for PoCs Ø Pricing Ø Volume under management - Enterprise Pricing Ø Price per PB continuously decreases as volume grows Ø Small volume per TB pricing coming soon
open source products but they are just too slow, unscalable, not POSIX compatible, or simply not practical Ø There are Object Storage vendors which promise POSIX access as a feature, but all organisations we’ve spoken to say these were unworkable Ø Many organisations we’ve spoken to say their Object Storage is poorly utilised because either it lacks POSIX, or POSIX access is cripplingly slow Ø We see ourselves as complementing rather than competing Ø Azure offers a File gateway to object storage, and even they don’t recommend their File gateway be used for anything other than navigating the directory tree
ourselves as competing more with: Ø AWS EFS, FSx Lustre, Azure Files, Azure Lustre, Google Cloud Filestore Ø On-prem equivalent general file storage, scalable file storage Ø For throughput-workloads, we are faster, more scalable and less expensive Ø To some extent we are also competing with: Ø AWS EBS, Azure Disk Storage, Google Persistent Disk Ø cunoFS doesn’t need to be pre-provisioned Ø For throughput-workloads, we are faster, more scalable and less expensive Ø We are not competing with high IOPS file storage e.g. Weka Ø We see ourselves as complementing rather than competing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}