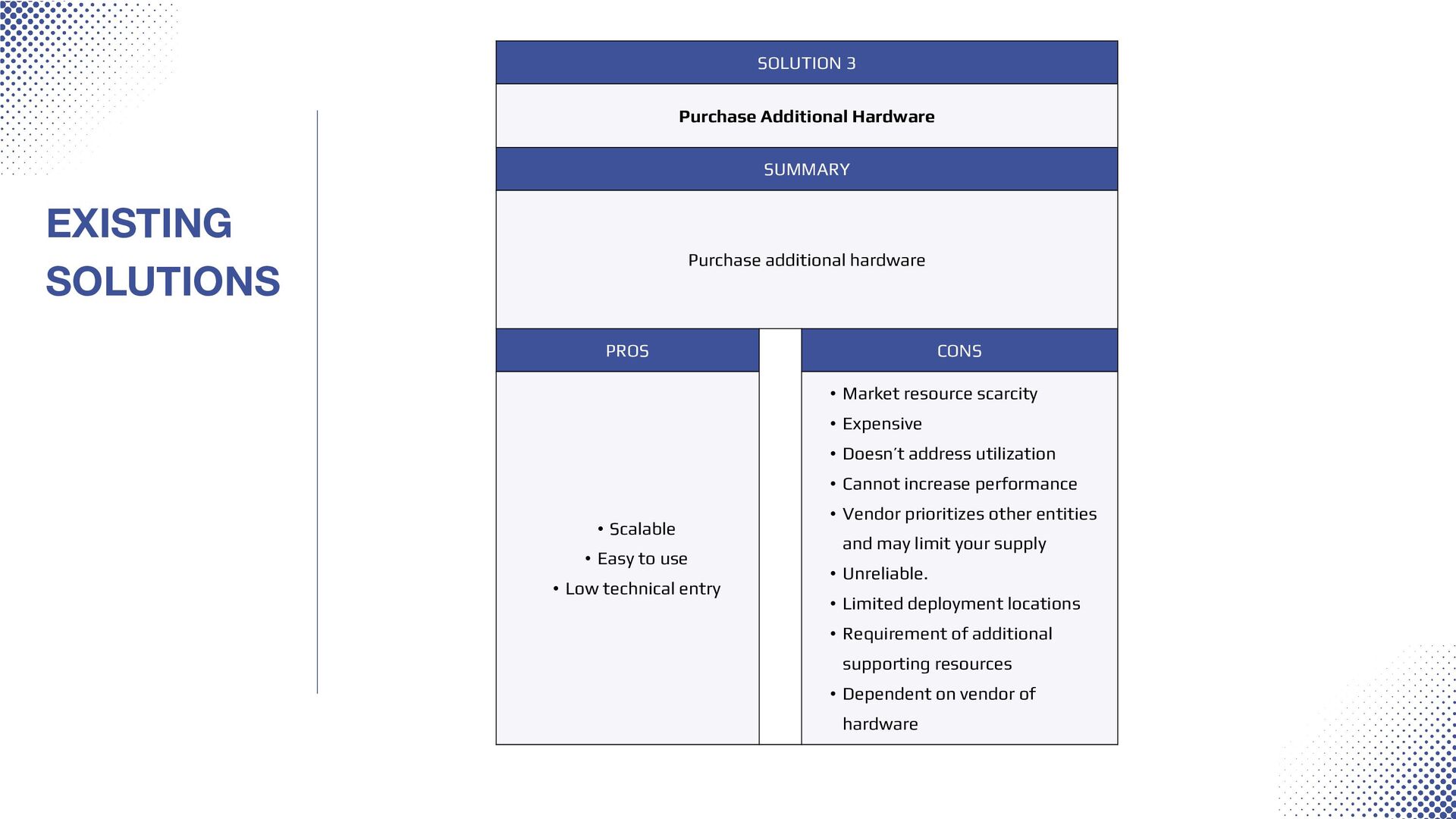
and reduce environmental impact. Pains and challenges Arc Compute SOLUTION 1 Ignore SUMMARY No method or solution to address the scarcity of hardware nor increase utilization PROS CONS • None • Not feasible for business continuity EXISTING SOLUTIONS
using de facto solutions such as job schedulers and fractional GPU software PROS CONS • Increase user density • Easy to use • Readily available • Scalable • Cannot address low-level utilization points such as memory access latencies where additional arithmetic operations could occur • Can lead to performance degradations • Cannot address fine-tuning of GPU environments for optimal task deployment for performance • Cannot set or prioritize performance for business objective alignment; missing user governance policy setting for performance EXISTING SOLUTIONS
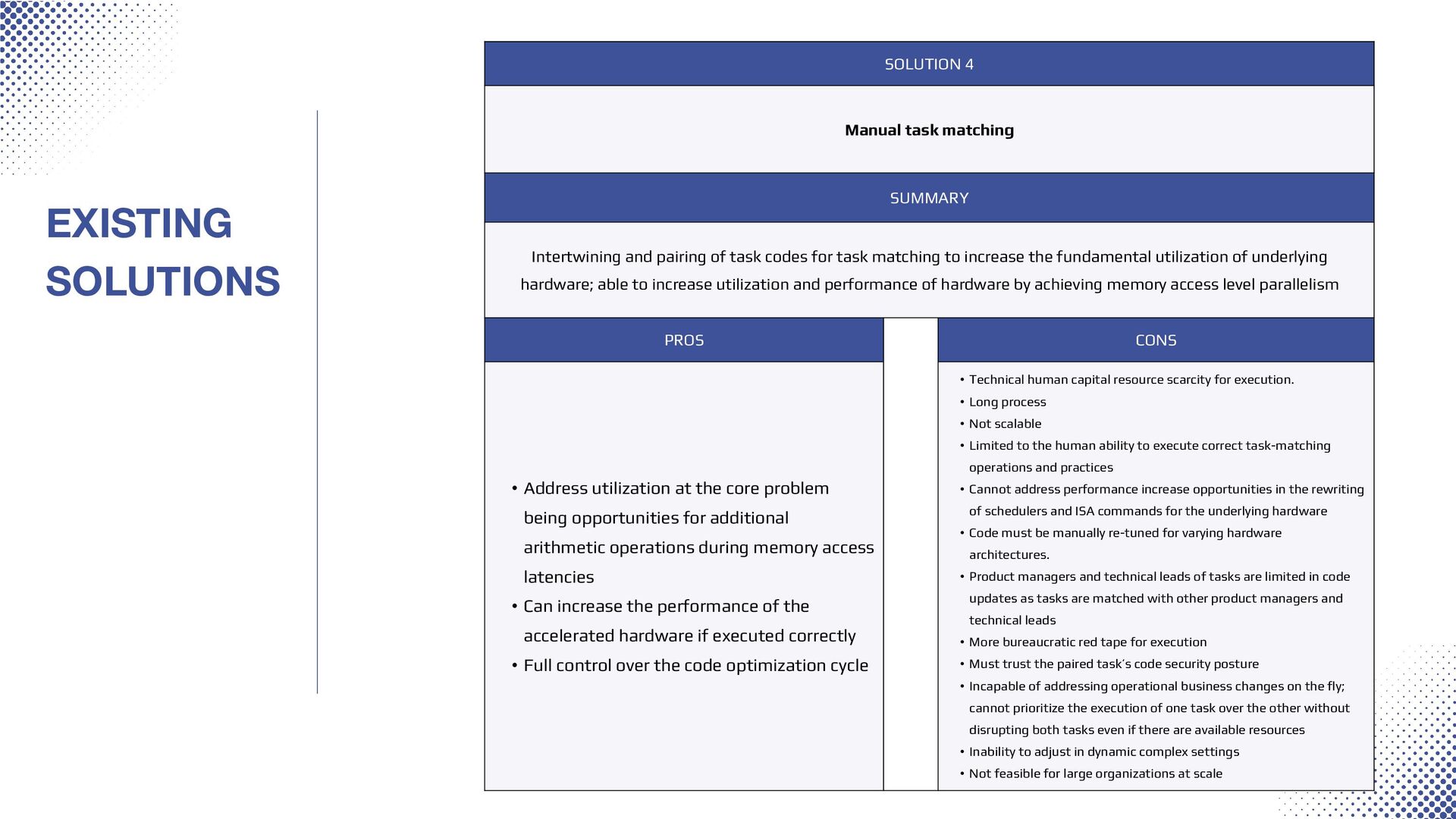
task codes for task matching to increase the fundamental utilization of underlying hardware; able to increase utilization and performance of hardware by achieving memory access level parallelism PROS CONS • Address utilization at the core problem being opportunities for additional arithmetic operations during memory access latencies • Can increase the performance of the accelerated hardware if executed correctly • Full control over the code optimization cycle • Technical human capital resource scarcity for execution. • Long process • Not scalable • Limited to the human ability to execute correct task-matching operations and practices • Cannot address performance increase opportunities in the rewriting of schedulers and ISA commands for the underlying hardware • Code must be manually re-tuned for varying hardware architectures. • Product managers and technical leads of tasks are limited in code updates as tasks are matched with other product managers and technical leads • More bureaucratic red tape for execution • Must trust the paired task’s code security posture • Incapable of addressing operational business changes on the fly; cannot prioritize the execution of one task over the other without disrupting both tasks even if there are available resources • Inability to adjust in dynamic complex settings • Not feasible for large organizations at scale EXISTING SOLUTIONS
and other accelerated hardware • This software allows users to maximize user/task density and GPU performance. • It achieves this by increasing throughputs to compute resources while granularly tuning compute environments for task execution and providing recommendations for further improvements. Nexus
maximization of utilization and performance for GPUs can occur. ⚬ ArcHPC Nexus provides management protocols that remove limitations and performance degradation pitfalls found in other solutions that attempt to maximize utilization but can’t address performance at the same time. Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies.
with integration into prominent job schedulers such as SLURM, used by Meta, exascale large institutions and universities, for scalable management of HPC environments along with tools for granular understanding of operational health of HPC environments and tasks running, with enterprise governance capabilities and control. HPC Environment Management Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies.
the ability to increase utilization and performance. Increased Throughput for Increased User and Task Density Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies.
generations in an HPC environment enabling users to mix and match various compute resources to remain agile. Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies. Simultaneous Management of Multiple Accelerator Types
it's scalable, streamlined and instantly applicable in dynamic environments. ⚬ Manual task matching is a gruelling, daunting cumbersome operation that is currently being performed by some large companies to maximize utilization of their underlying HPC investments the best a human can. ⚬ Manual matching - humans can't manage the operation as slight code changes require a rework of the entire operation. Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies. Automated Task Matching and Task Deployment
the execution of their instructions. This enables users to achieve the highest performance increases possible at scale during intervals and vectors that are not addressable due to human limitations. Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies. Granular Instruction Execution Management
governance so large entities can maintain granular control of operations to align with business objectives. Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies. Enterprise Scalability and Control
tasks running. • Selects hardware which will maximize the throughput for the average task running in the datacenter. • Provides datacenter owners information to help scale their datacenters to adhere to new growing workloads.
National Lab. • Very hard to optimize due to high occupancy/pipeline saturation in the code. • Still benefits from Multi GPU setups. • Serious deadtime when running the lmp component in just moving the data to and from the gpu. • We ran a few tests to show how Nexus can speed this up.
an initial baseline on what to expect on A100s (4484.309 tau/day) • We ran 5 experiments of the system just running on our machine in a virtualized state, no magic tricks to make our system better. • We used CUDA 11.2.1 (available at the time that Sandia made their benchmark). • To ensure there are no driver speedups playing a role in our systems. • We still got a 2% performance increase consistently.
memory size, we lowered the in.lj.txt value by a bit. Line 7 the 20 was changed to a 10. • With our virtual machines we did a mapping of sharing our GPU between 2 identical LAMMP processes. • The wide varity is due to CPUs haphazardly sending the info to the GPU. However with our system in place behind the scenes we still see massive improvements. Once we control the CPU component even more, we expect the varity to stablize around 12k Tau/day.
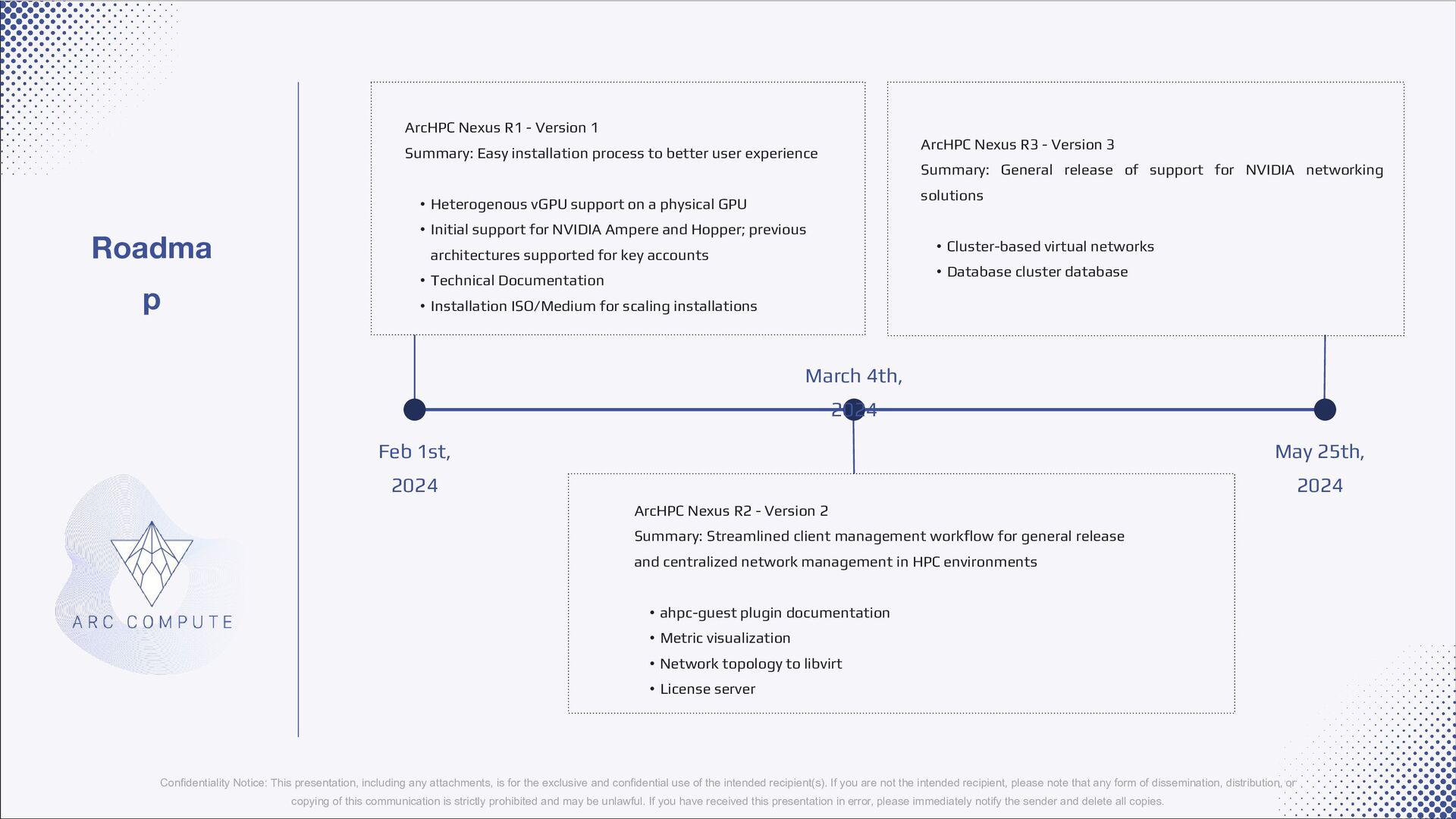
2024 ArcHPC Nexus R1 - Version 1 Summary: Easy installation process to better user experience • Heterogenous vGPU support on a physical GPU • Initial support for NVIDIA Ampere and Hopper; previous architectures supported for key accounts • Technical Documentation • Installation ISO/Medium for scaling installations ArcHPC Nexus R2 - Version 2 Summary: Streamlined client management workflow for general release and centralized network management in HPC environments • ahpc-guest plugin documentation • Metric visualization • Network topology to libvirt • License server ArcHPC Nexus R3 - Version 3 Summary: General release of support for NVIDIA networking solutions • Cluster-based virtual networks • Database cluster database Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies.
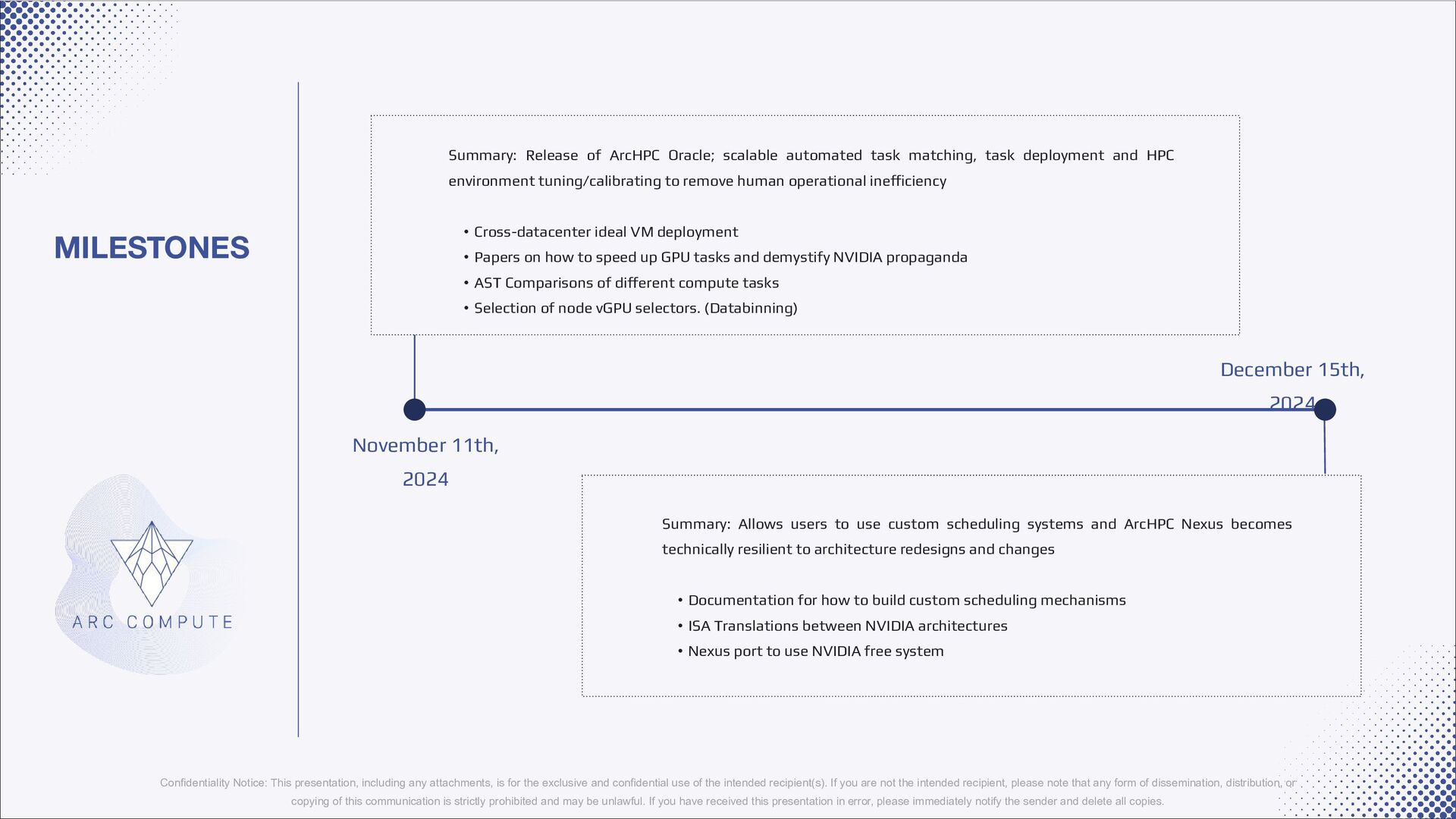
ArcHPC Oracle; scalable automated task matching, task deployment and HPC environment tuning/calibrating to remove human operational inefficiency • Cross-datacenter ideal VM deployment • Papers on how to speed up GPU tasks and demystify NVIDIA propaganda • AST Comparisons of different compute tasks • Selection of node vGPU selectors. (Databinning) Summary: Allows users to use custom scheduling systems and ArcHPC Nexus becomes technically resilient to architecture redesigns and changes • Documentation for how to build custom scheduling mechanisms • ISA Translations between NVIDIA architectures • Nexus port to use NVIDIA free system Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}