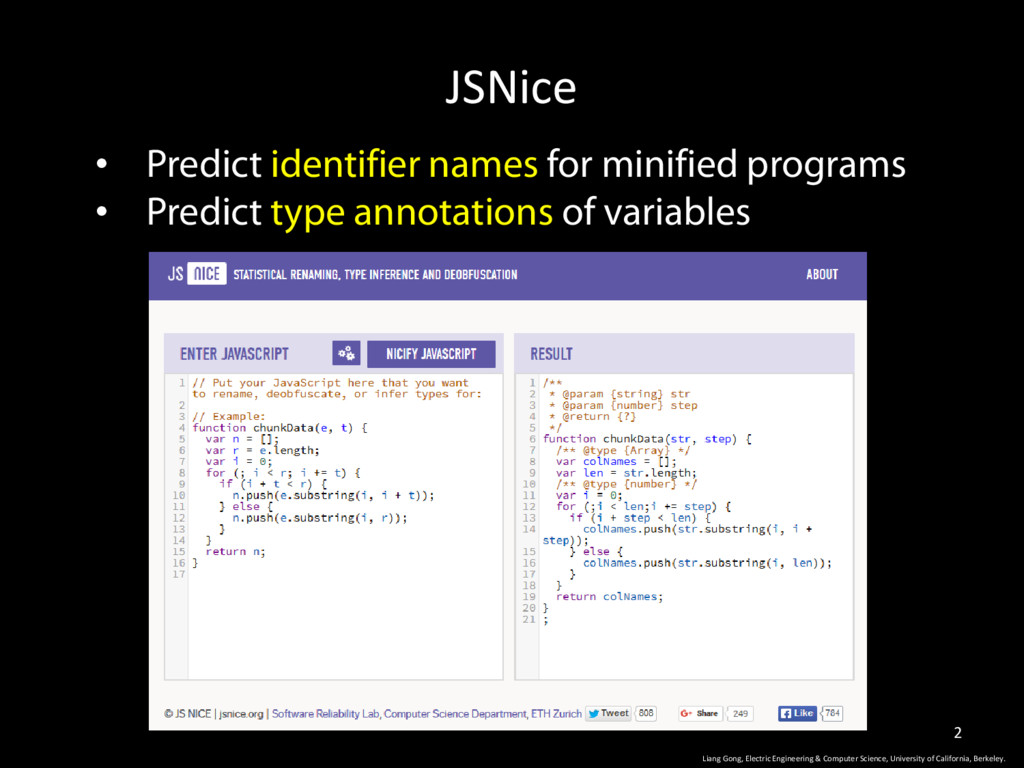
by: Liang Gong Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 1 Veselin Raychev, Martin Vechev, and Andreas Krause
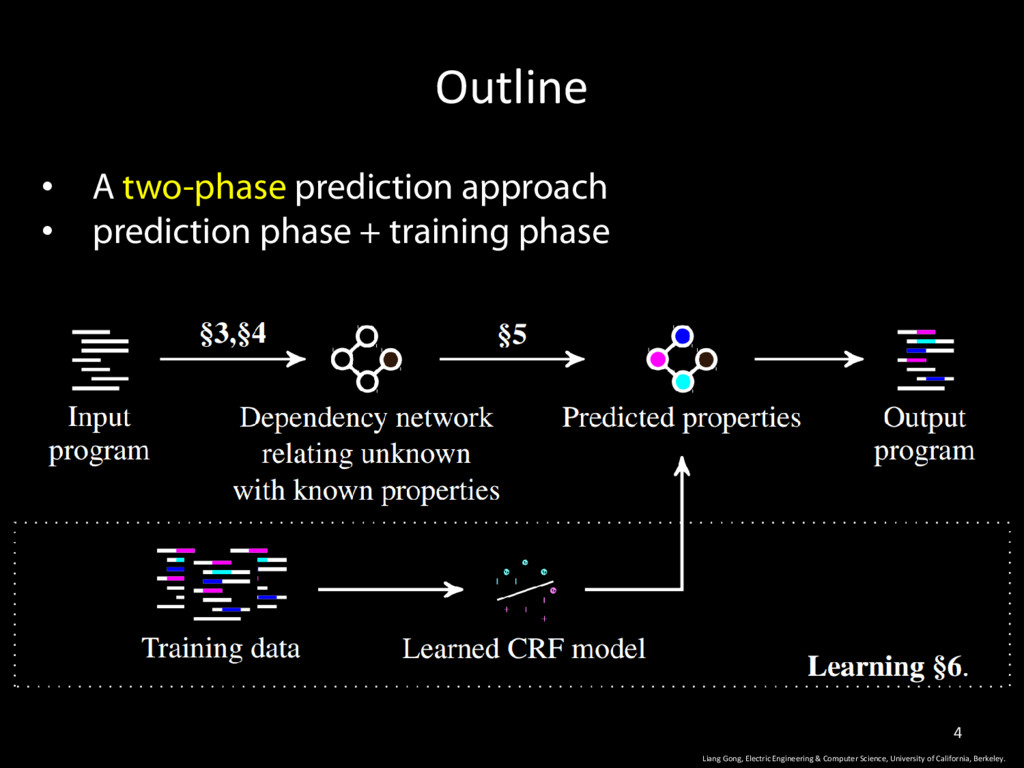
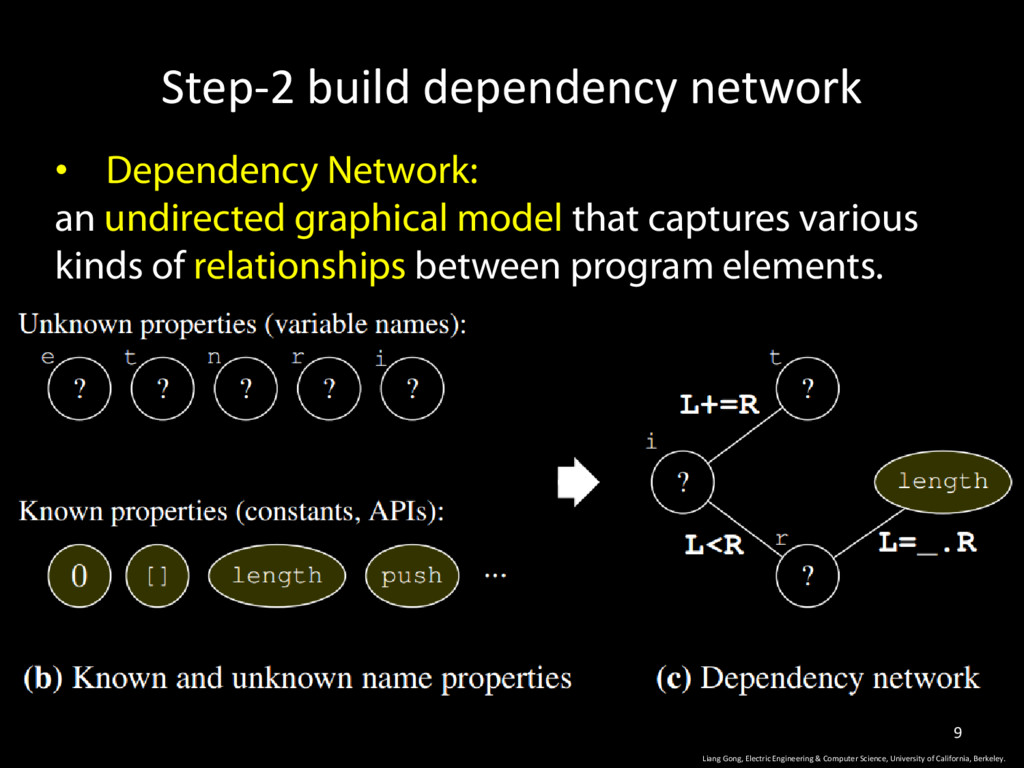
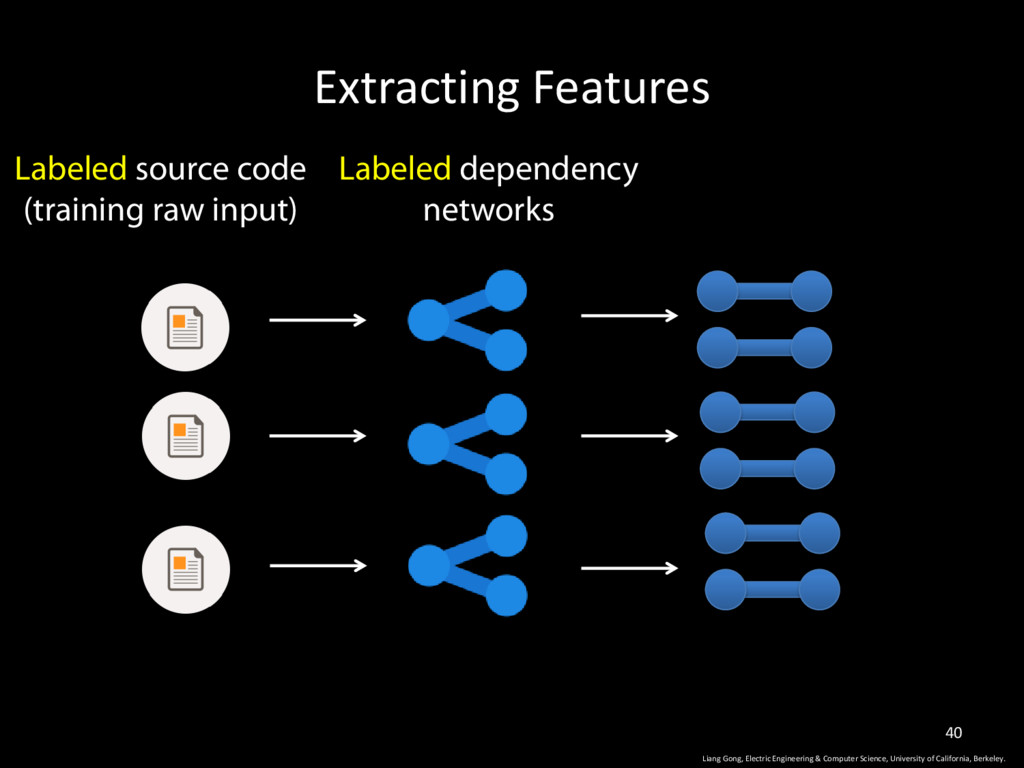
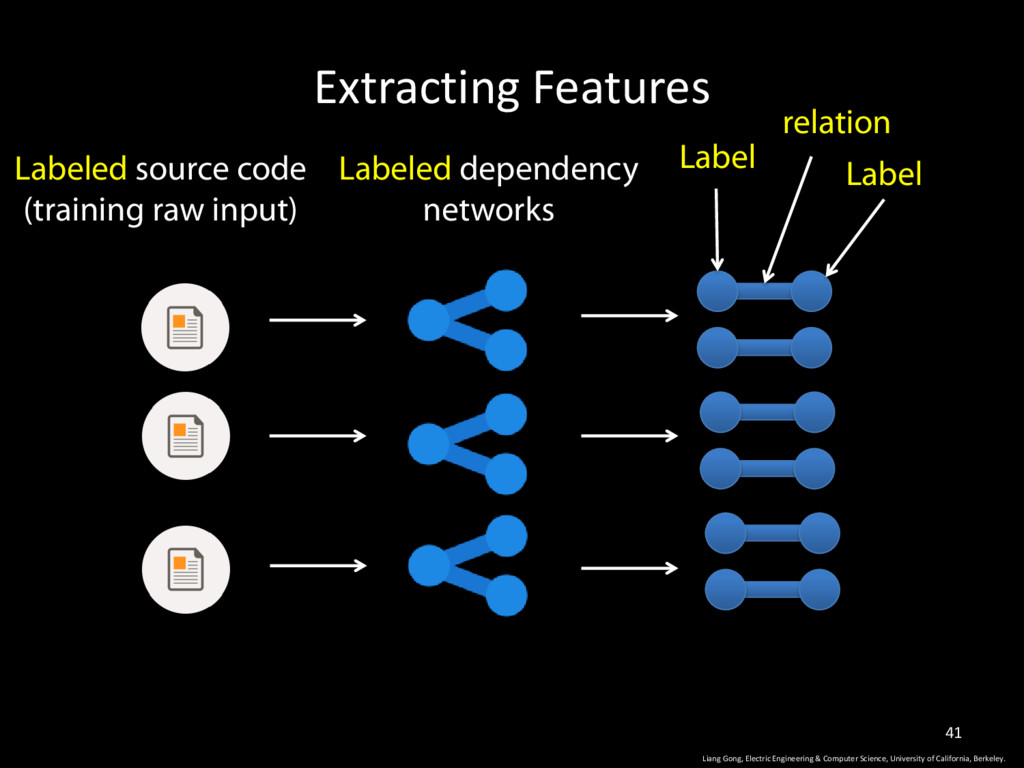
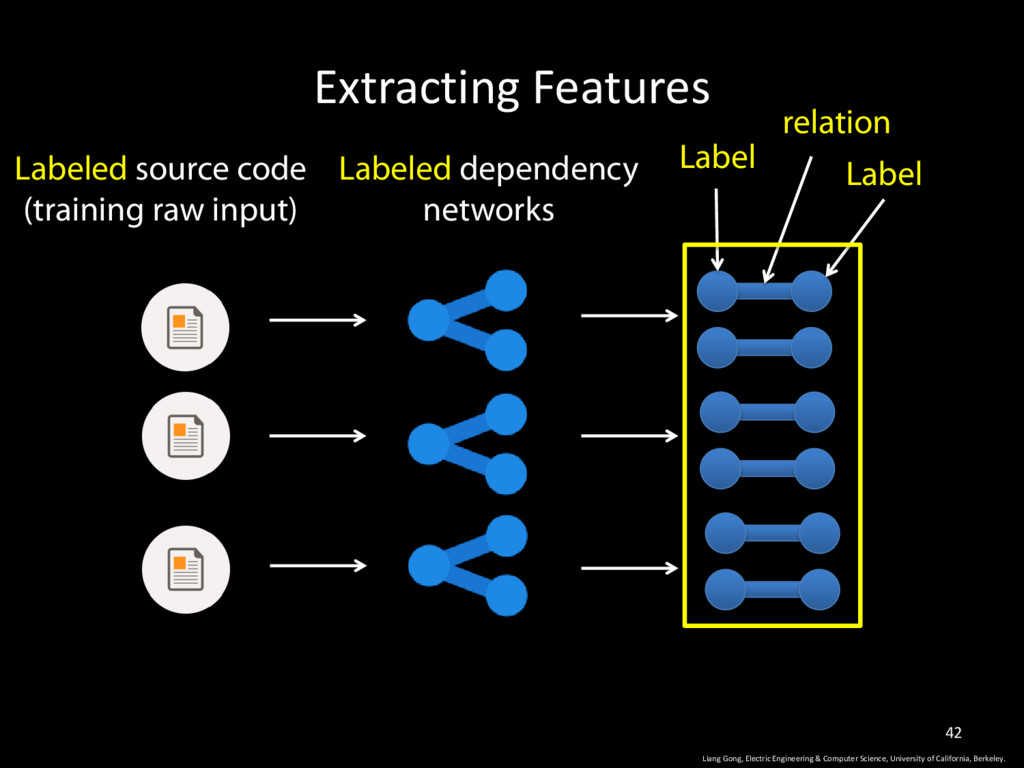
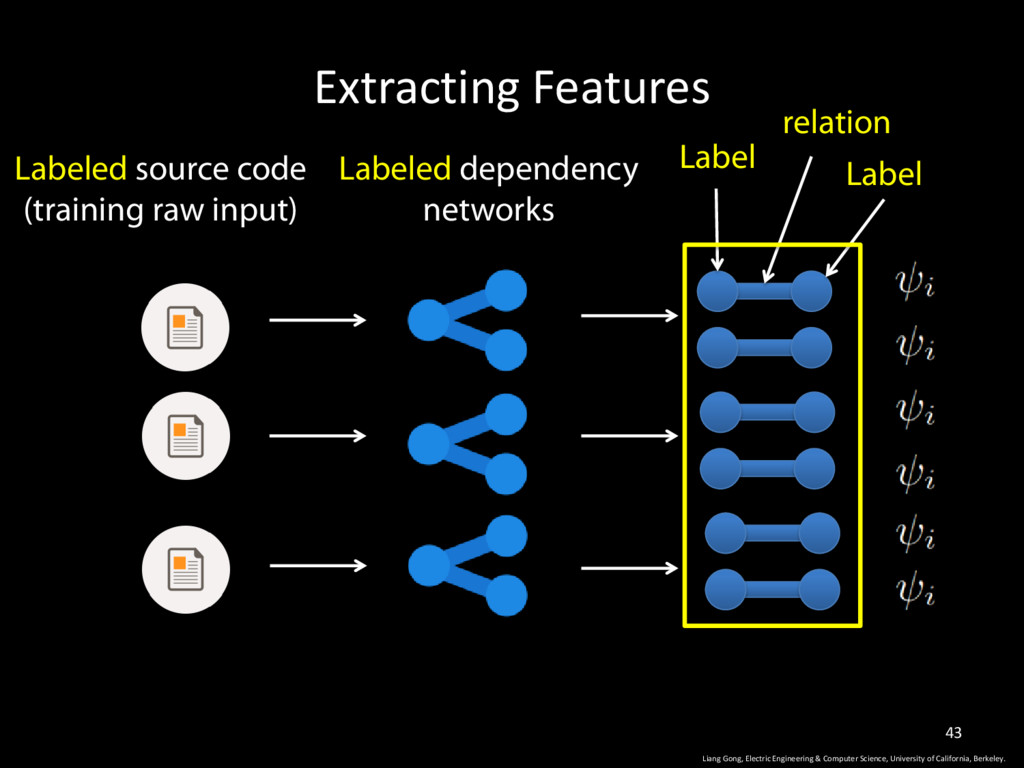
Science, University of California, Berkeley. 9 • Dependency Network: an undirected graphical model that captures various kinds of relationships between program elements.
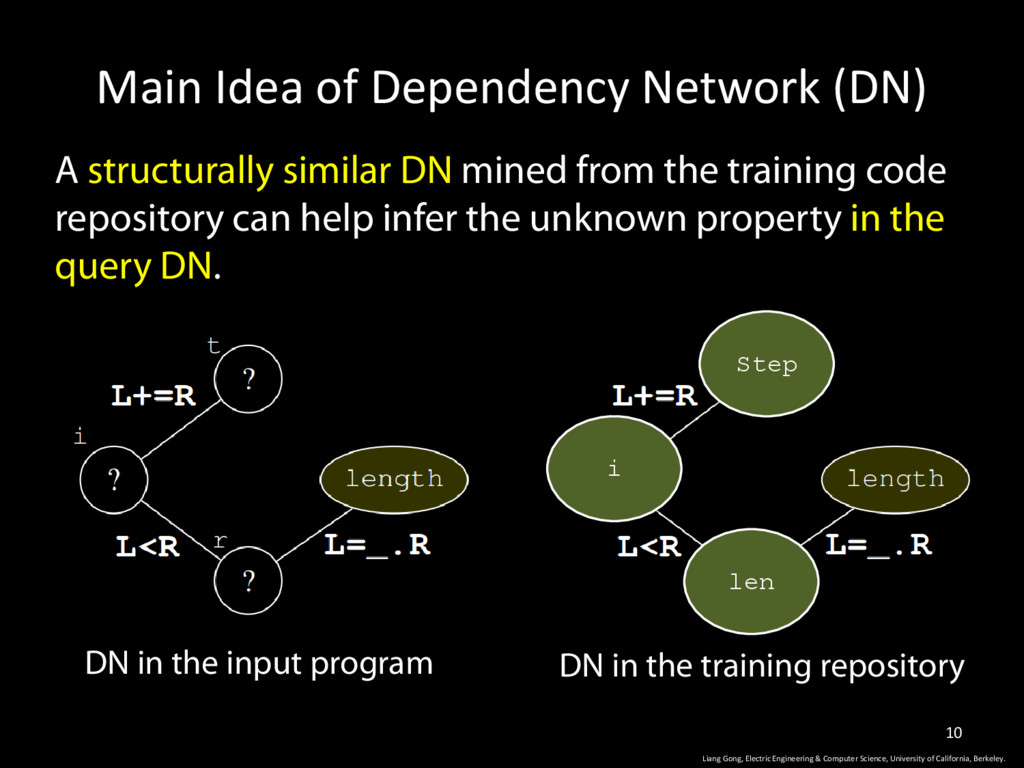
& Computer Science, University of California, Berkeley. 10 A structurally similar DN mined from the training code repository can help infer the unknown property in the query DN. DN in the input program DN in the training repository Step i len
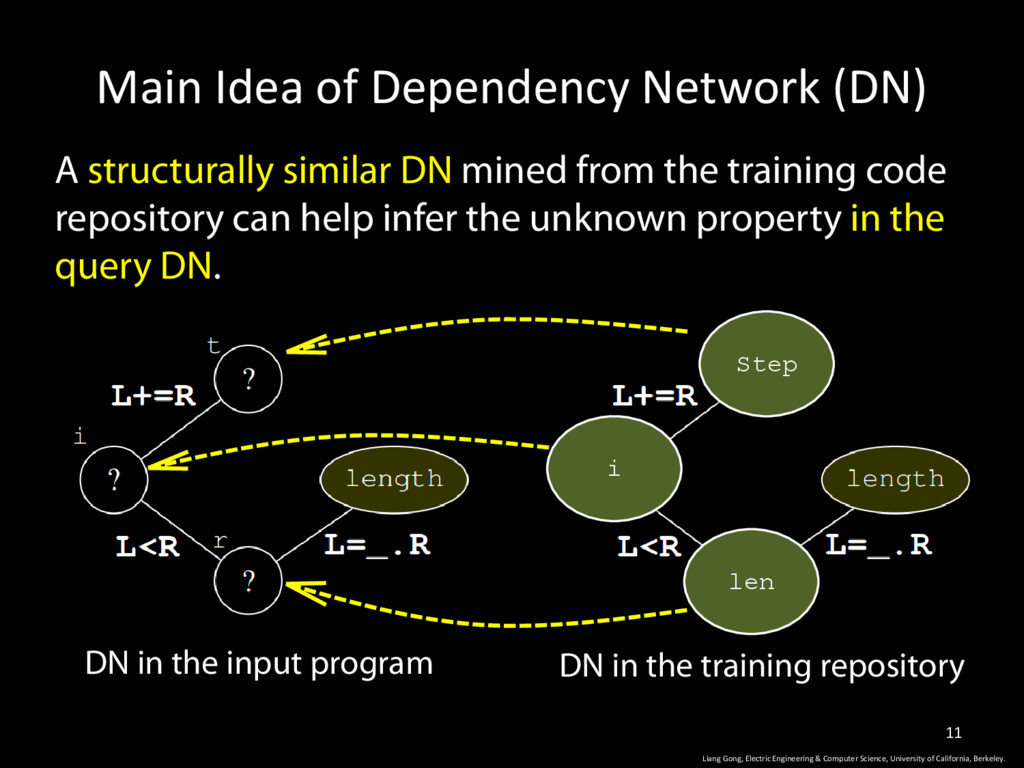
& Computer Science, University of California, Berkeley. 11 A structurally similar DN mined from the training code repository can help infer the unknown property in the query DN. DN in the input program DN in the training repository Step i len
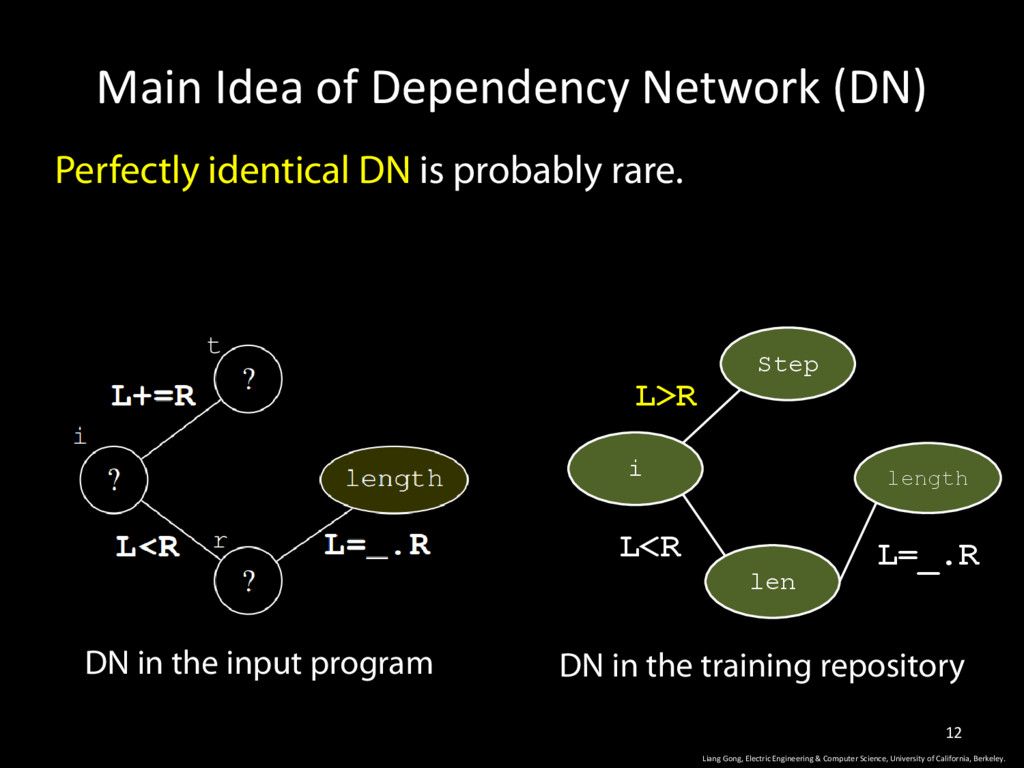
& Computer Science, University of California, Berkeley. 12 Perfectly identical DN is probably rare. DN in the input program DN in the training repository Step i len length L>R L<R L=_.R
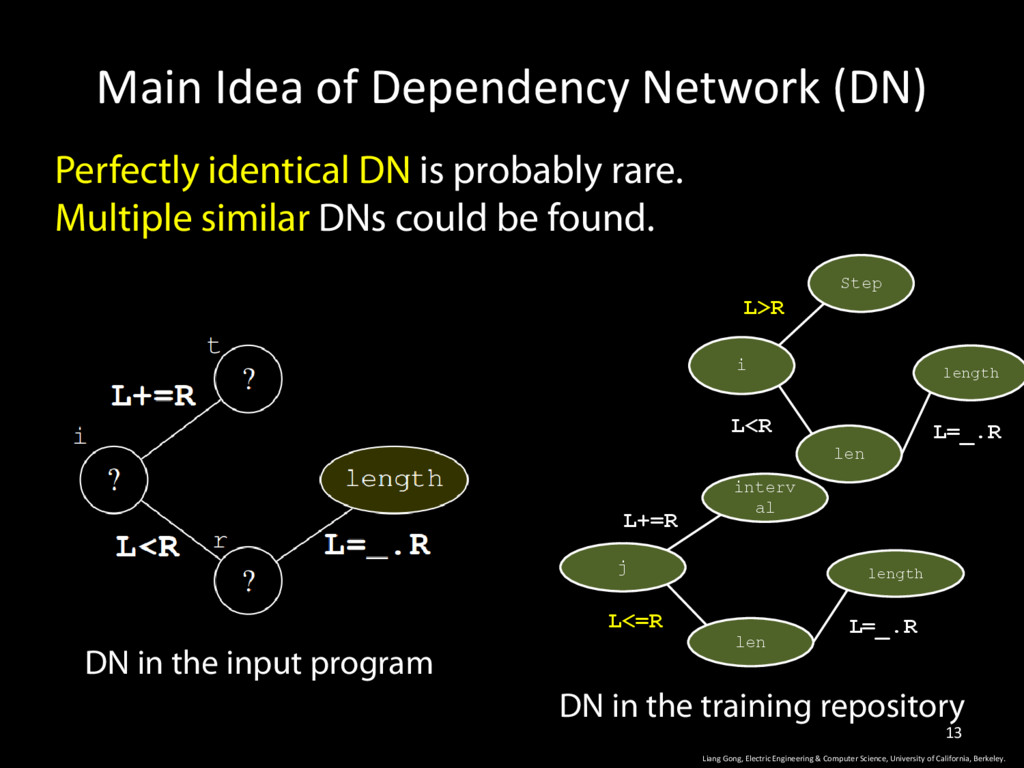
& Computer Science, University of California, Berkeley. 13 Perfectly identical DN is probably rare. Multiple similar DNs could be found. DN in the input program DN in the training repository Step i len length L>R L<R L=_.R interv al j len length L+=R L<=R L=_.R
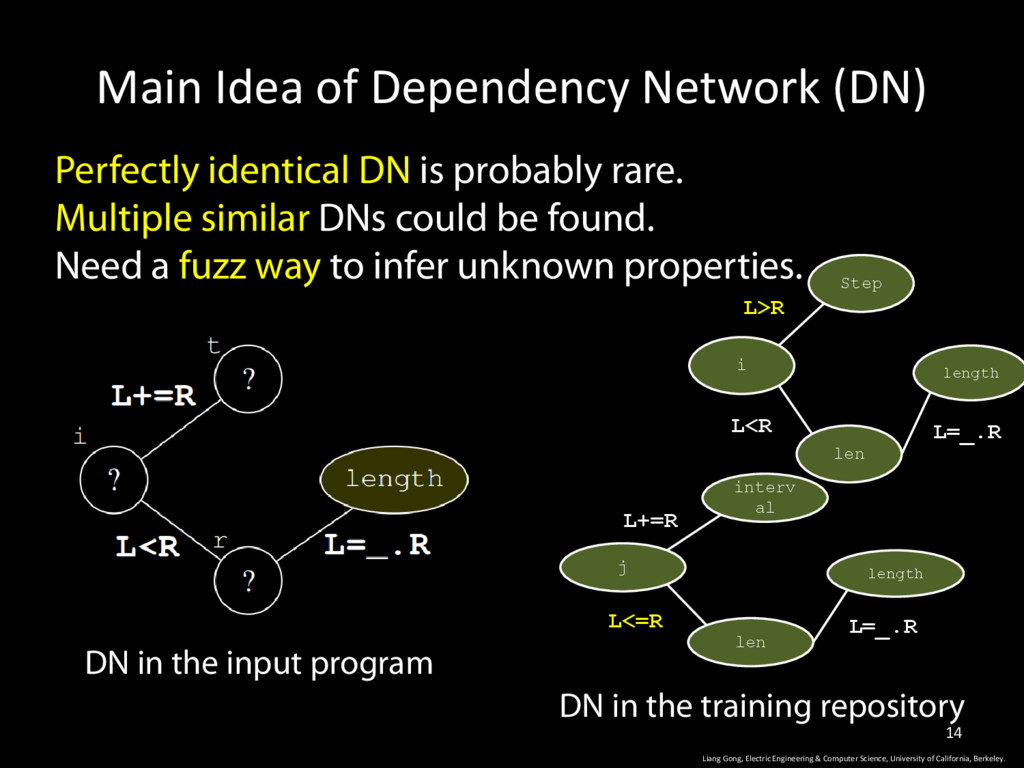
& Computer Science, University of California, Berkeley. 14 Perfectly identical DN is probably rare. Multiple similar DNs could be found. Need a fuzz way to infer unknown properties. DN in the input program DN in the training repository Step i len length L>R L<R L=_.R interv al j len length L+=R L<=R L=_.R
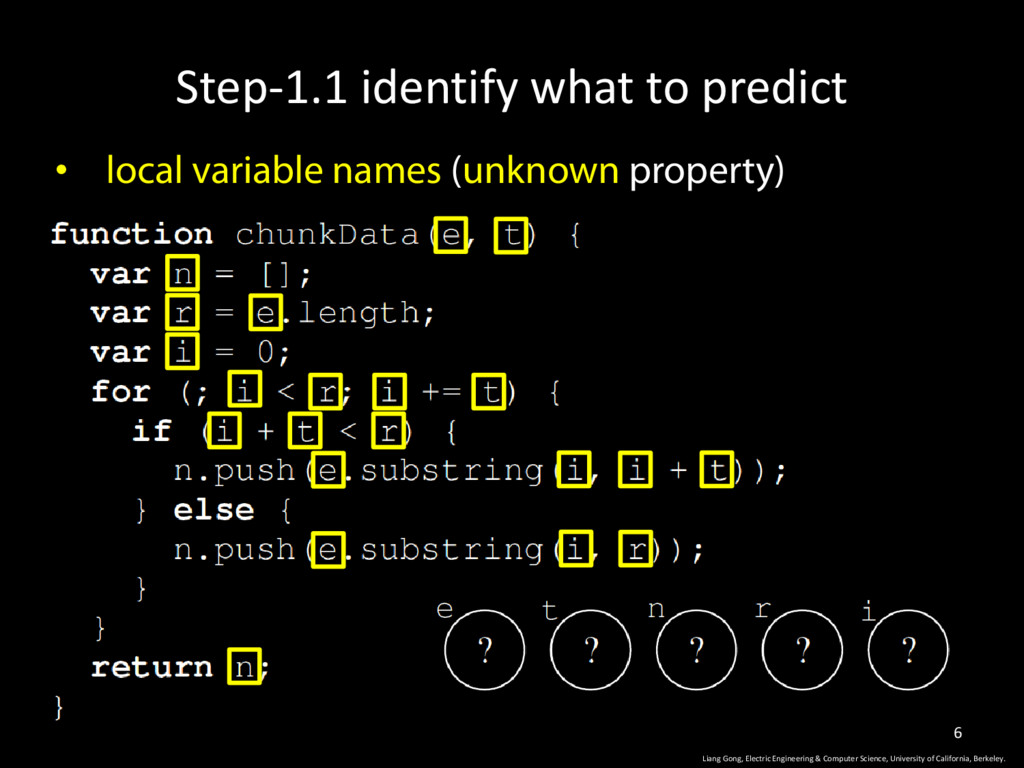
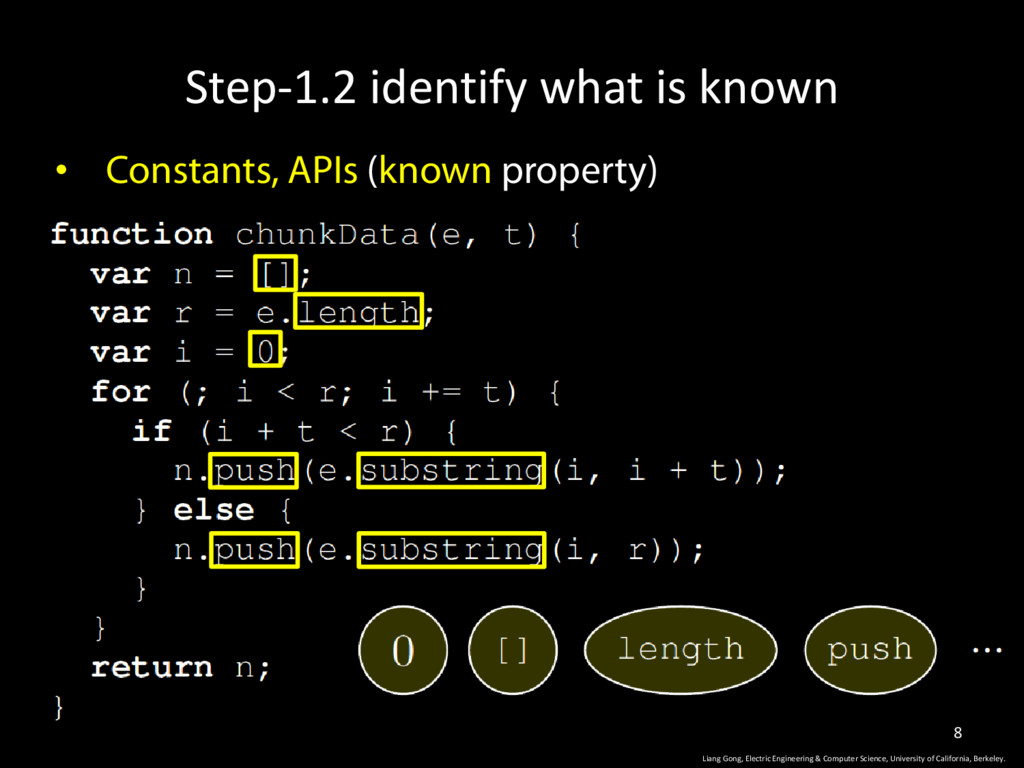
of California, Berkeley. 16 The entire training set D contains t programs. Each program x(j) has a vector of labels y Given a program x to be predicted, return a label vector with the maximal probability. n(x): # of unknown properties
University of California, Berkeley. 23 The score of label y, based on feature fi The score of label vector y all possible labels in x Learnt through gradient descent
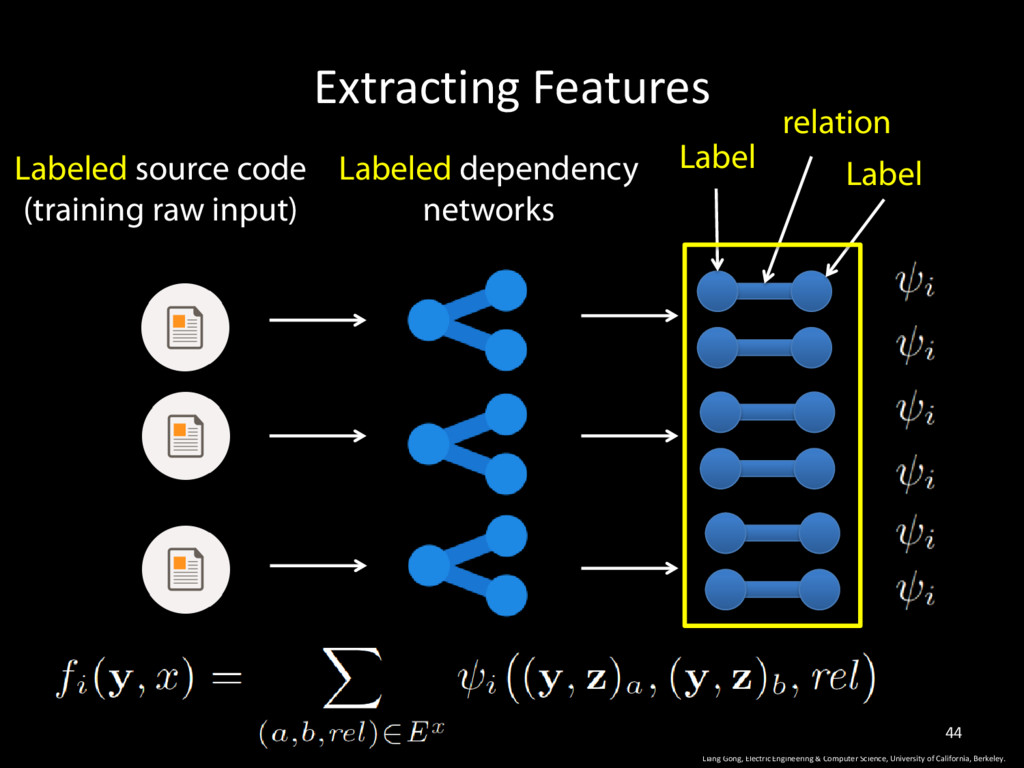
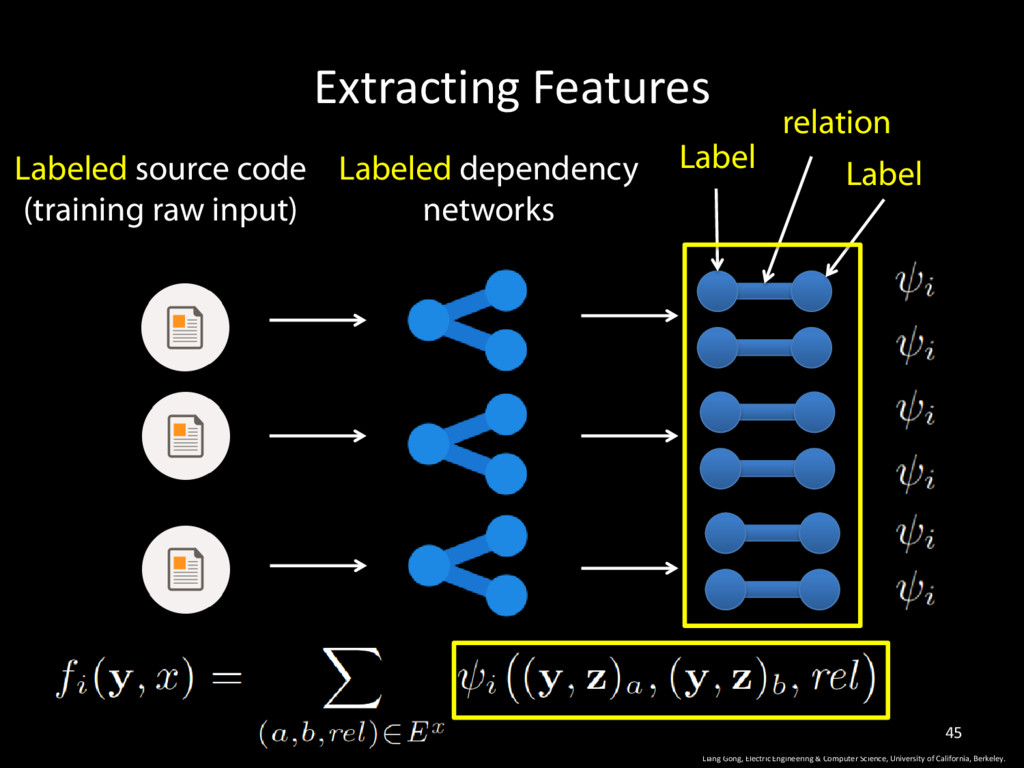
University of California, Berkeley. 34 feature score of label vector y in program x The set of all edges in the dependency network of program x This function returns 1 if this pair appears in the training set, otherwise return 0
University of California, Berkeley. 35 feature score of label vector y in program x The set of all edges in the dependency network of program x Unknown label vector y This function returns 1 if this pair appears in the training set, otherwise return 0
University of California, Berkeley. 36 feature score of label vector y in program x The set of all edges in the dependency network of program x Known property vector Unknown label vector y This function returns 1 if this pair appears in the training set, otherwise return 0
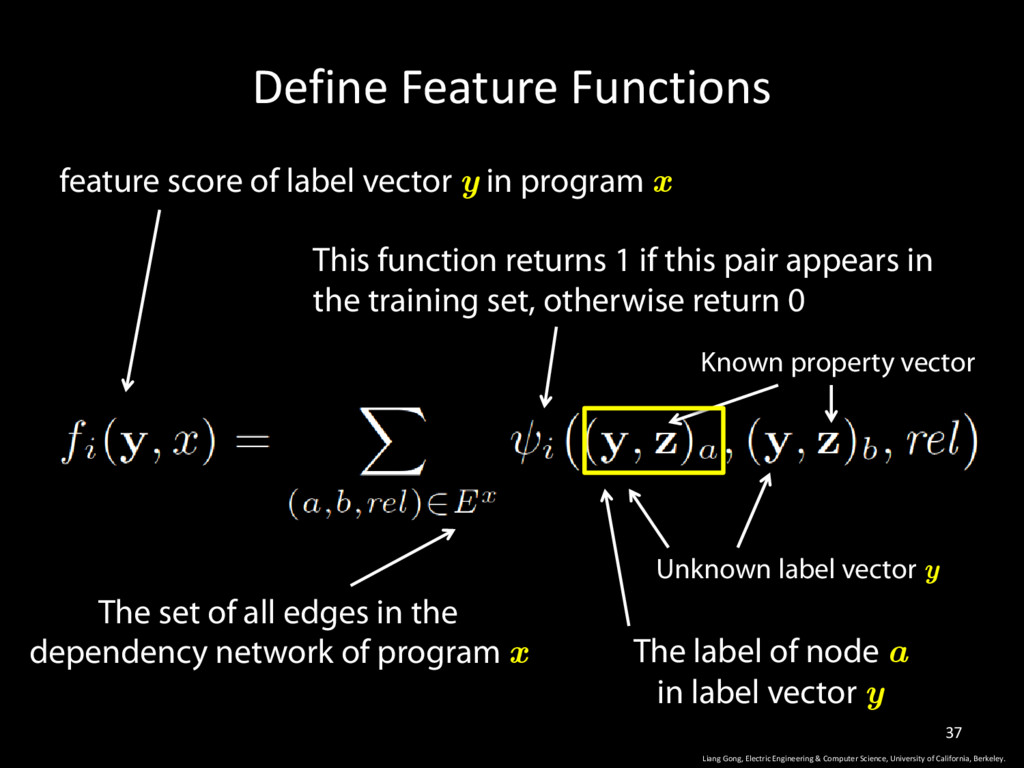
University of California, Berkeley. 37 feature score of label vector y in program x The set of all edges in the dependency network of program x Known property vector Unknown label vector y This function returns 1 if this pair appears in the training set, otherwise return 0 The label of node a in label vector y
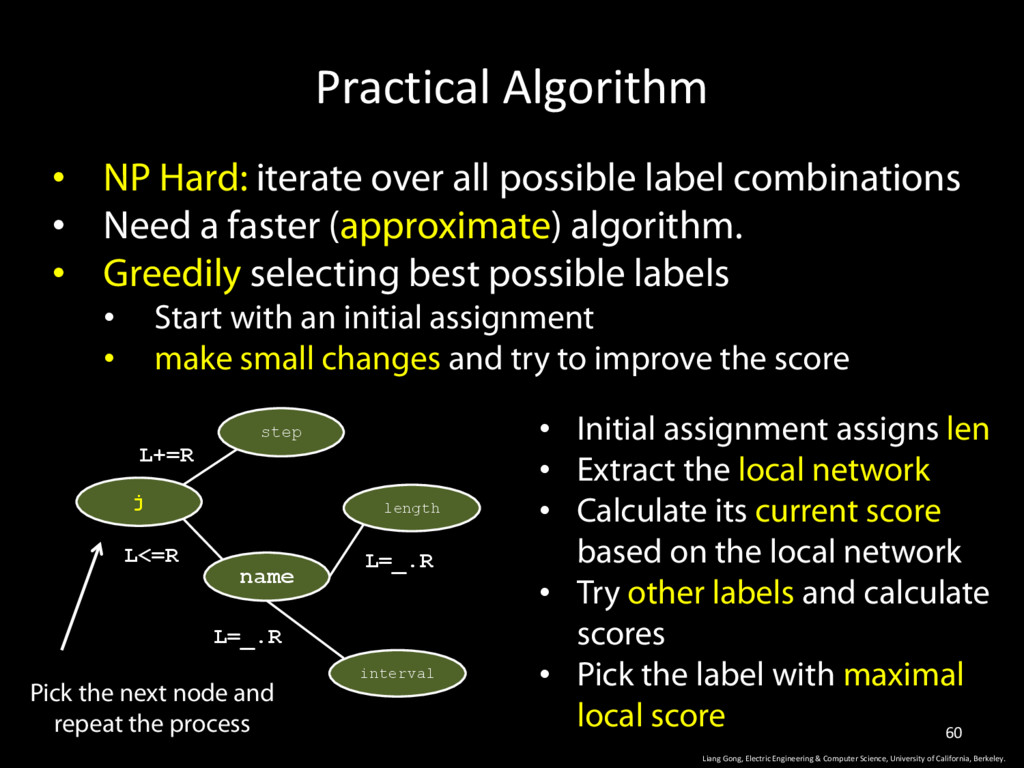
of California, Berkeley. 53 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score
of California, Berkeley. 54 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score step j len length L+=R L<=R L=_.R interval L=_.R
of California, Berkeley. 55 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score step j len length L+=R L<=R L=_.R interval L=_.R • Initial assignment assigns len
of California, Berkeley. 56 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score j len length L<=R L=_.R • Initial assignment assigns len • Extract the local network interval L=_.R
of California, Berkeley. 57 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score j len length L<=R L=_.R • Initial assignment assigns len • Extract the local network • Calculate its current score based on the local network interval L=_.R
of California, Berkeley. 58 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score j len length L<=R L=_.R • Initial assignment assigns len • Extract the local network • Calculate its current score based on the local network • Try other labels and calculate scores interval L=_.R name input
of California, Berkeley. 59 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score j name length L<=R L=_.R • Initial assignment assigns len • Extract the local network • Calculate its current score based on the local network • Try other labels and calculate scores • Pick the label with maximal local score interval L=_.R
of California, Berkeley. 60 • NP Hard: iterate over all possible label combinations • Need a faster (approximate) algorithm. • Greedily selecting best possible labels • Start with an initial assignment • make small changes and try to improve the score • Initial assignment assigns len • Extract the local network • Calculate its current score based on the local network • Try other labels and calculate scores • Pick the label with maximal local score step j name length L+=R L<=R L=_.R interval L=_.R Pick the next node and repeat the process
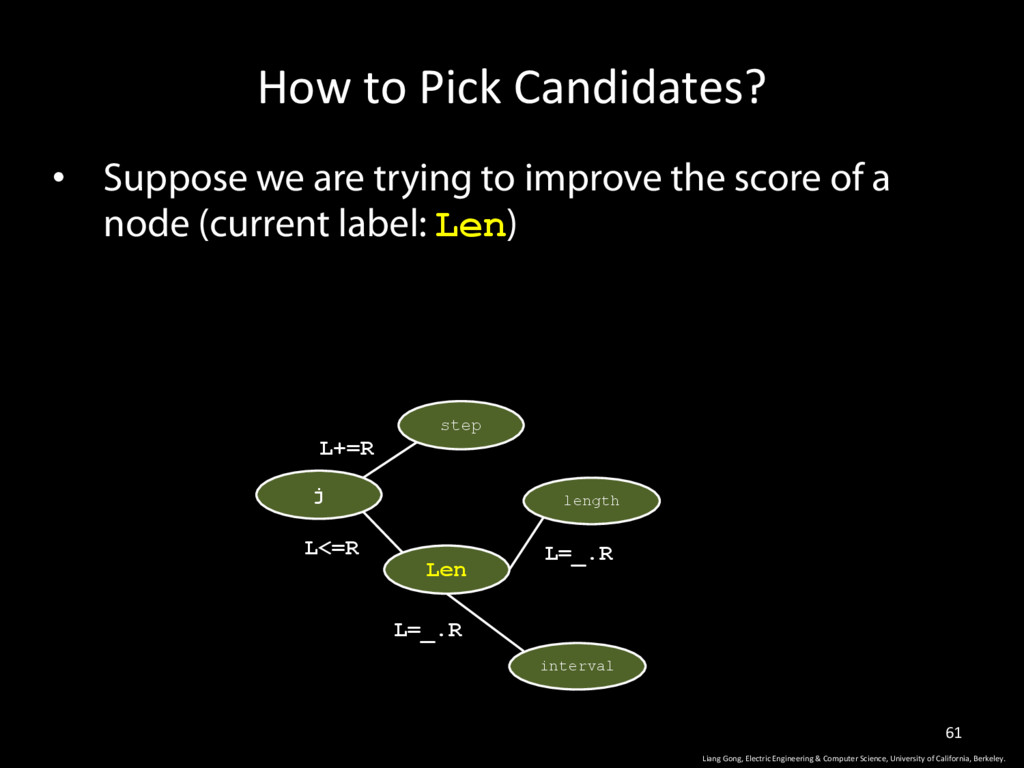
Science, University of California, Berkeley. 61 • Suppose we are trying to improve the score of a node (current label: Len) step j Len length L+=R L<=R L=_.R interval L=_.R
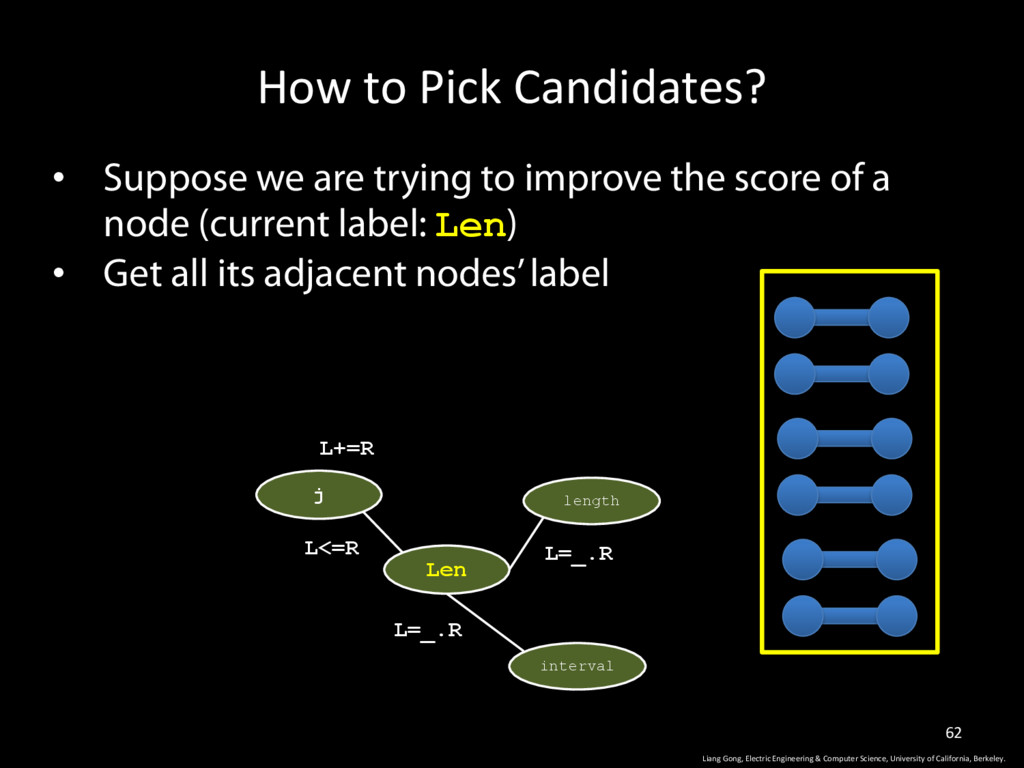
Science, University of California, Berkeley. 62 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R
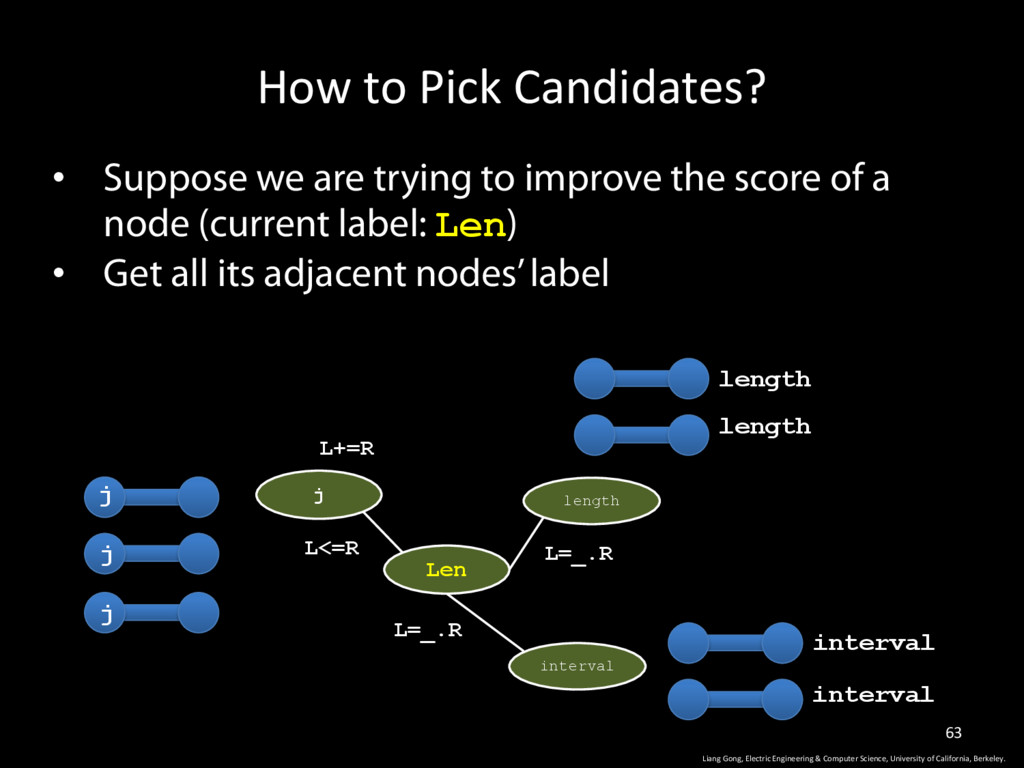
Science, University of California, Berkeley. 63 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R j j j length length interval interval
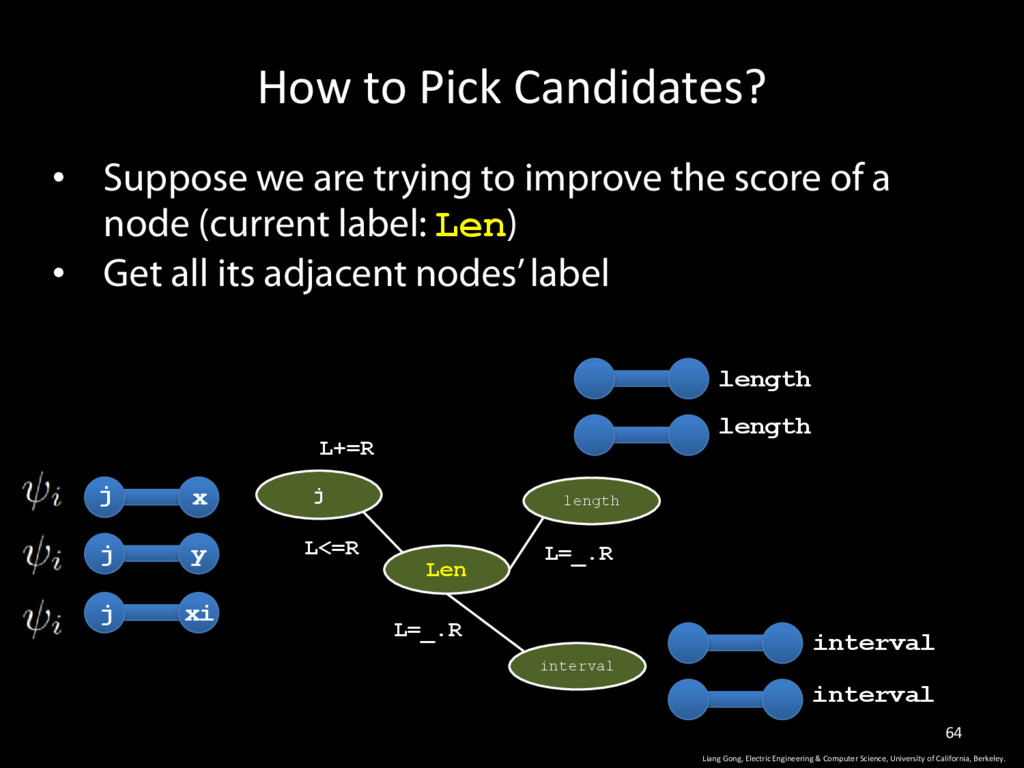
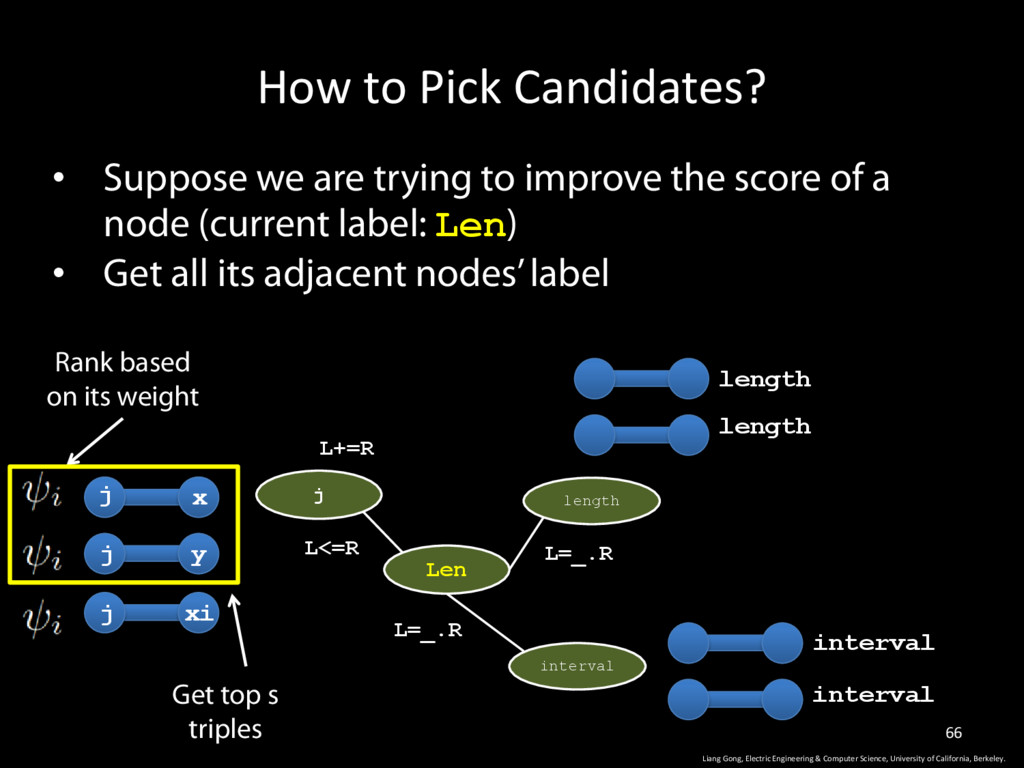
Science, University of California, Berkeley. 64 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R j j j length length interval interval x y xi
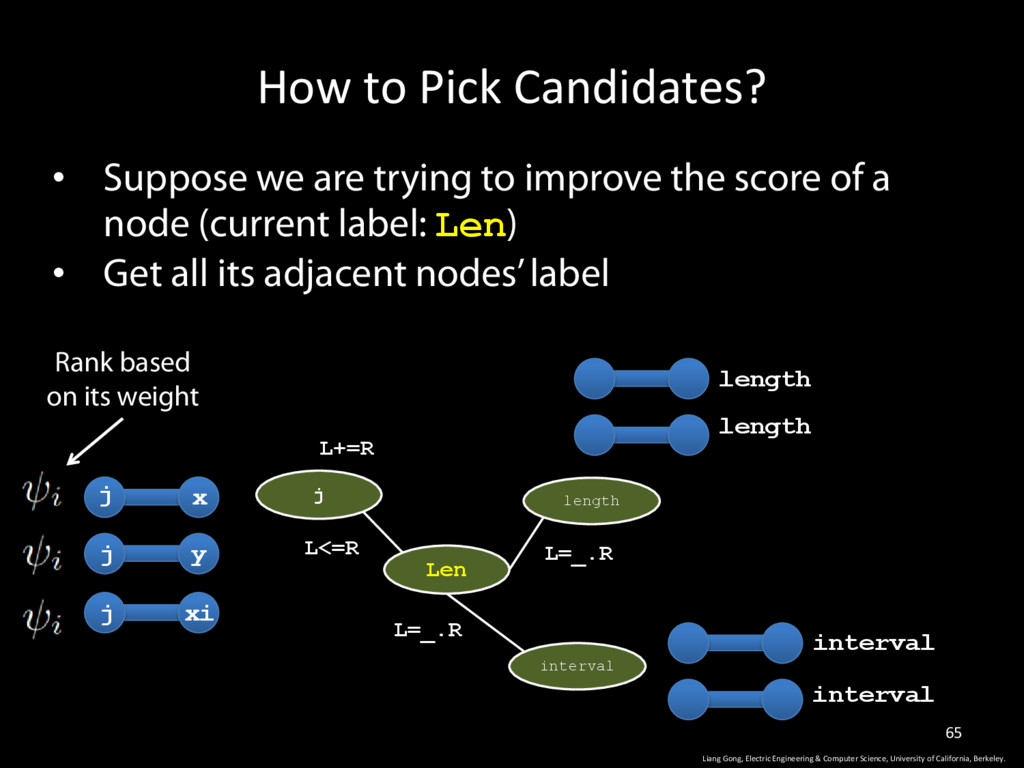
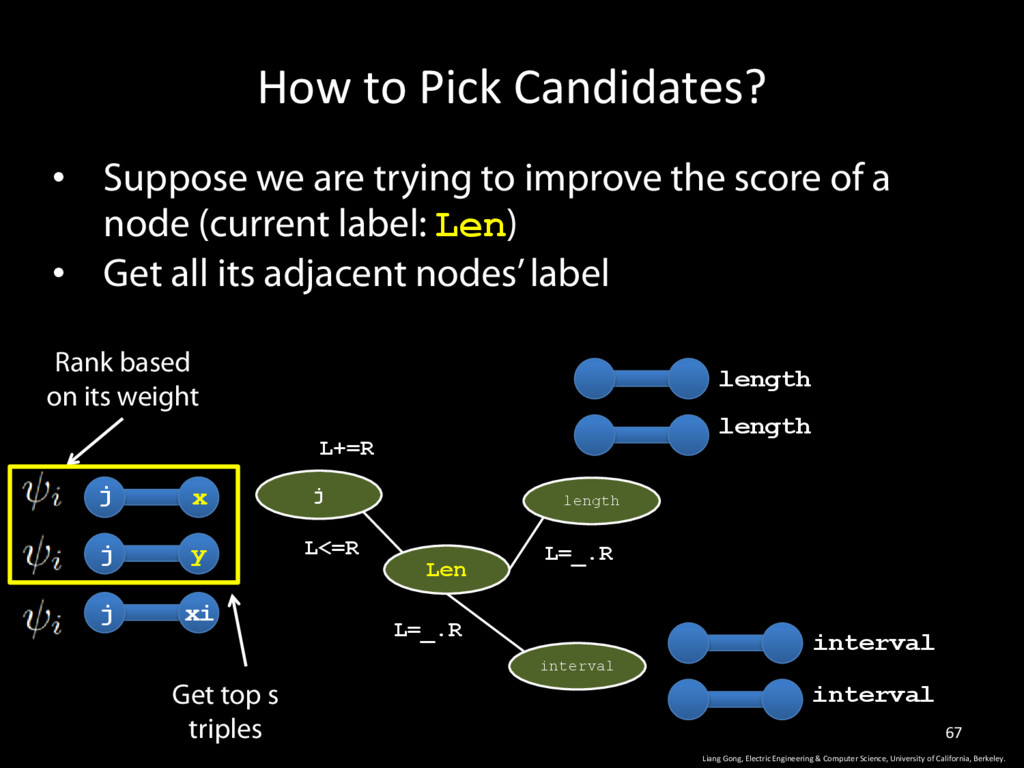
Science, University of California, Berkeley. 65 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R j j j length length interval interval x y xi Rank based on its weight
Science, University of California, Berkeley. 66 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R j j j length length interval interval x y xi Rank based on its weight Get top s triples
Science, University of California, Berkeley. 67 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R j j j length length interval interval x y xi Rank based on its weight Get top s triples
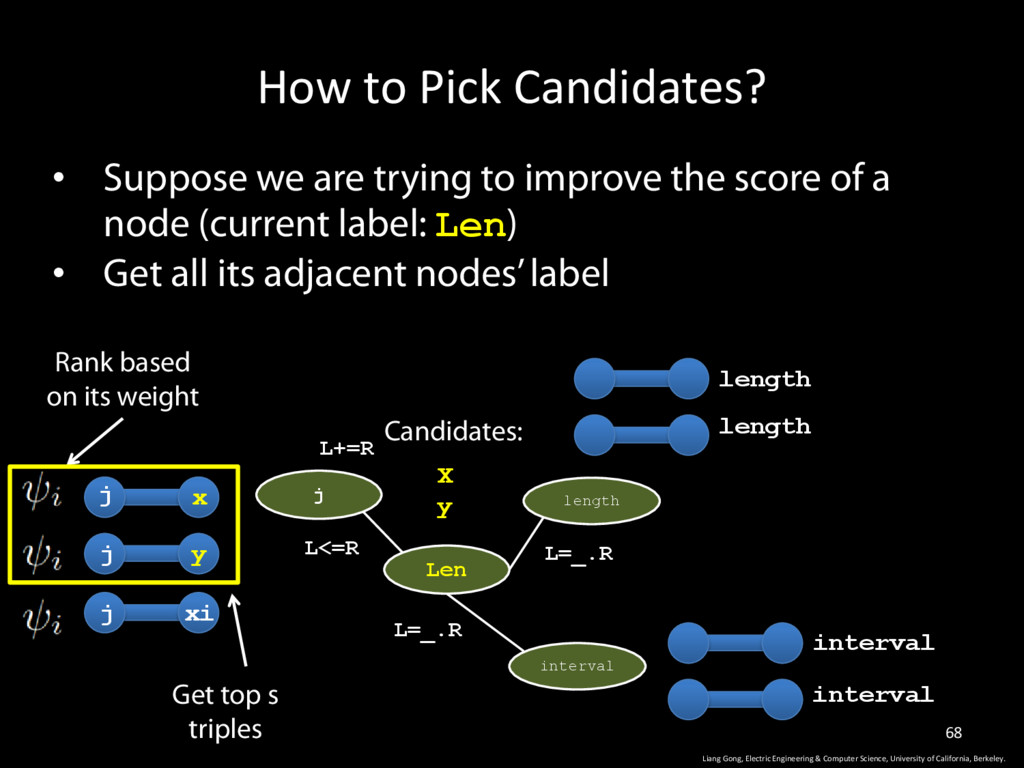
Science, University of California, Berkeley. 68 • Suppose we are trying to improve the score of a node (current label: Len) • Get all its adjacent nodes’ label j Len length L+=R L<=R L=_.R interval L=_.R j j j length length interval interval x y xi Rank based on its weight Get top s triples X y Candidates:
Computer Science, University of California, Berkeley. 73 • Each feature function has a corresponding weight • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments:
Computer Science, University of California, Berkeley. 74 • Each feature function has a corresponding weight • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments:
Computer Science, University of California, Berkeley. 75 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Score of correct assignment Score of wrong assignment A distance function • Ideally:
Computer Science, University of California, Berkeley. 76 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Score of wrong assignment Score of correct assignment
Computer Science, University of California, Berkeley. 77 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Score of wrong assignment Score of correct assignment Negative value
Computer Science, University of California, Berkeley. 78 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Score of wrong assignment Score of correct assignment Negative value Pick the wrong assignment with minimal margin
Computer Science, University of California, Berkeley. 79 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Score of wrong assignment Score of correct assignment Negative value Pick the wrong assignment with minimal margin Negative value
Computer Science, University of California, Berkeley. 80 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Score of wrong assignment Score of correct assignment Negative value Pick the wrong assignment with minimal margin Negative value maximize the distance between correct assignment and the closest wrong assignment
Computer Science, University of California, Berkeley. 81 • How do we obtain the weights? • Maximize the margin between correct assignment and wrong assignments: Based on this reward function, do stochastic gradient descent to update the weights
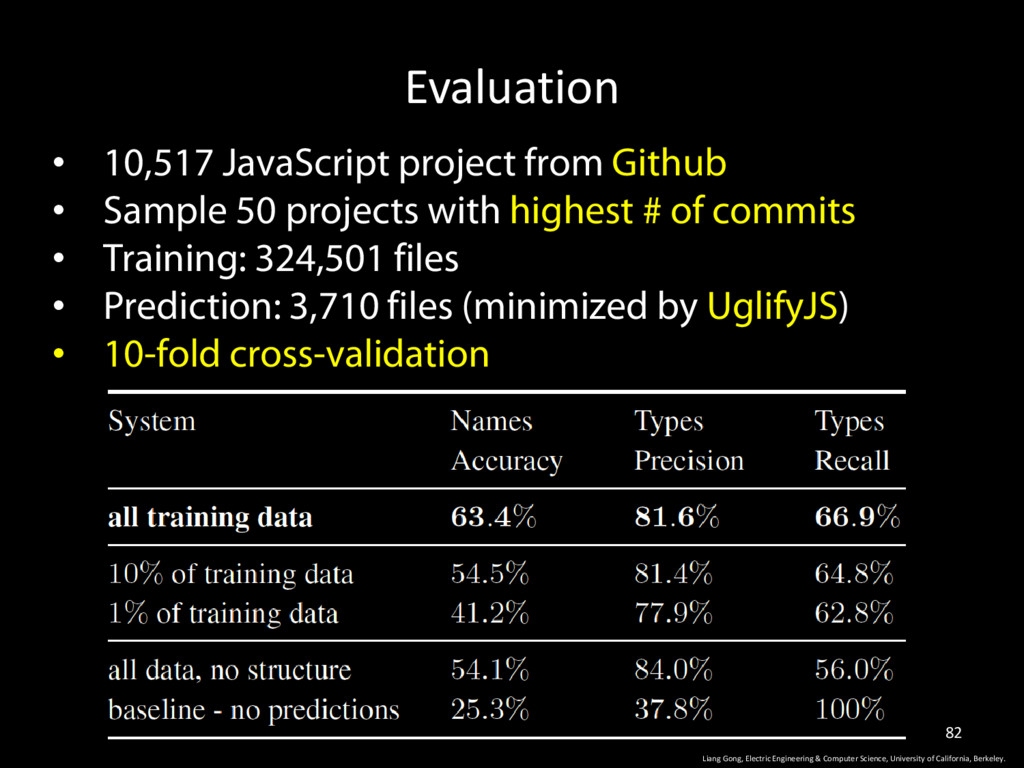
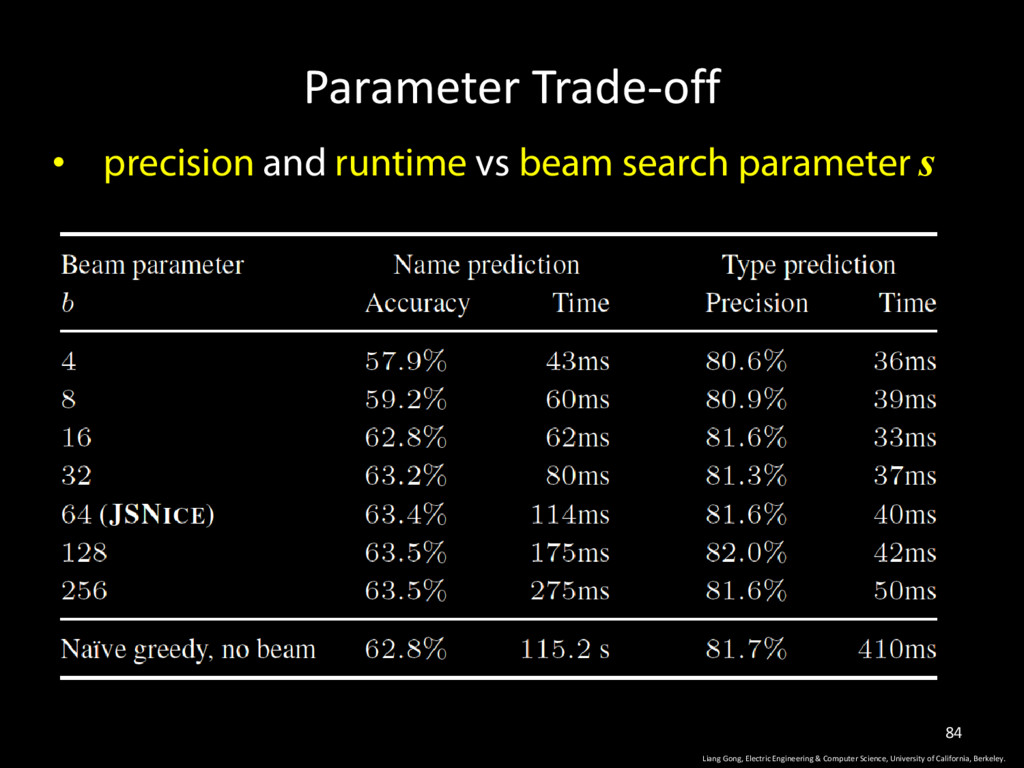
& Computer Science, University of California, Berkeley. 83 • JS Developer typically do not type check their annotations (miss spell, missing or conflicting annotations)
University of California, Berkeley. 86 Normalize the score to get the probability: The score of label y, based on feature fi The score of label y The set of all possible labels in x
• What is Markov Networks? • https://www.youtube.com/watch?v=2BXoj778YU8 • CRF is a probabilistic framework for labeling and segmenting sequential data. • CRF can be viewed as an undirected graphical model Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 88
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
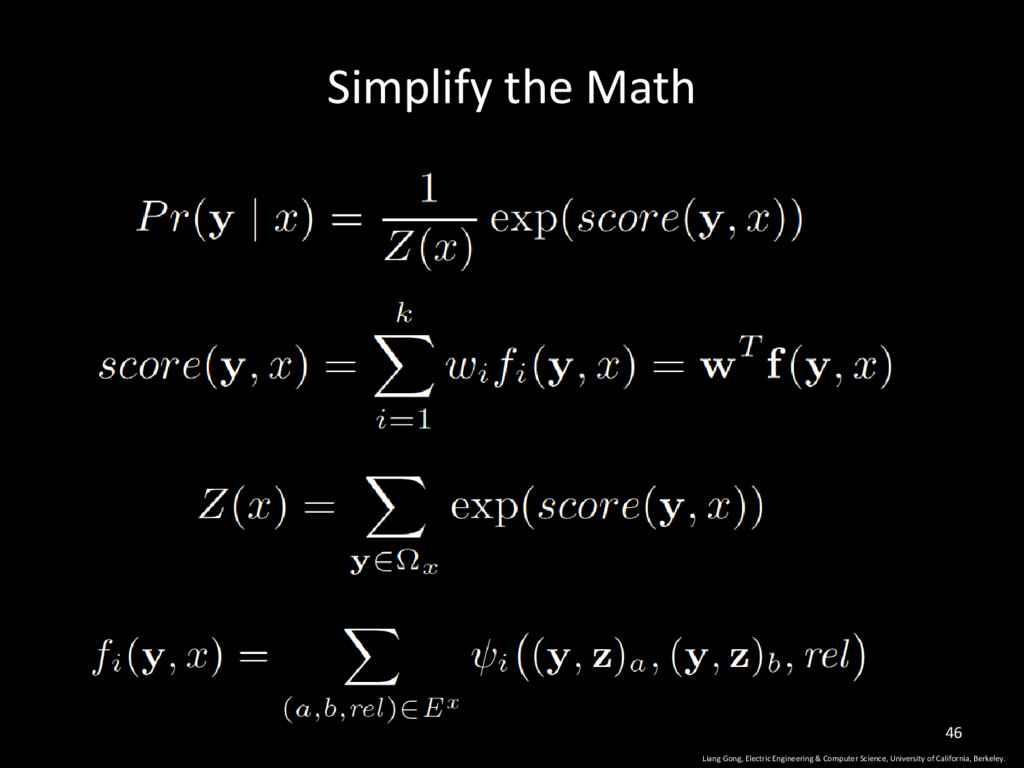{kind=link}
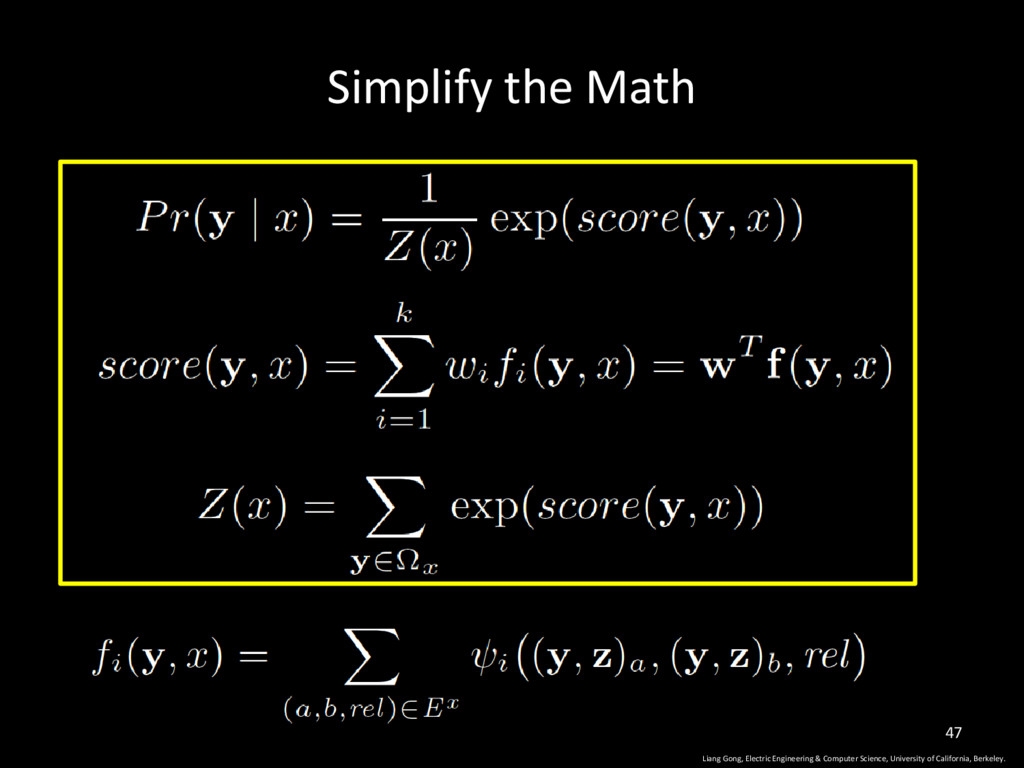{kind=link}
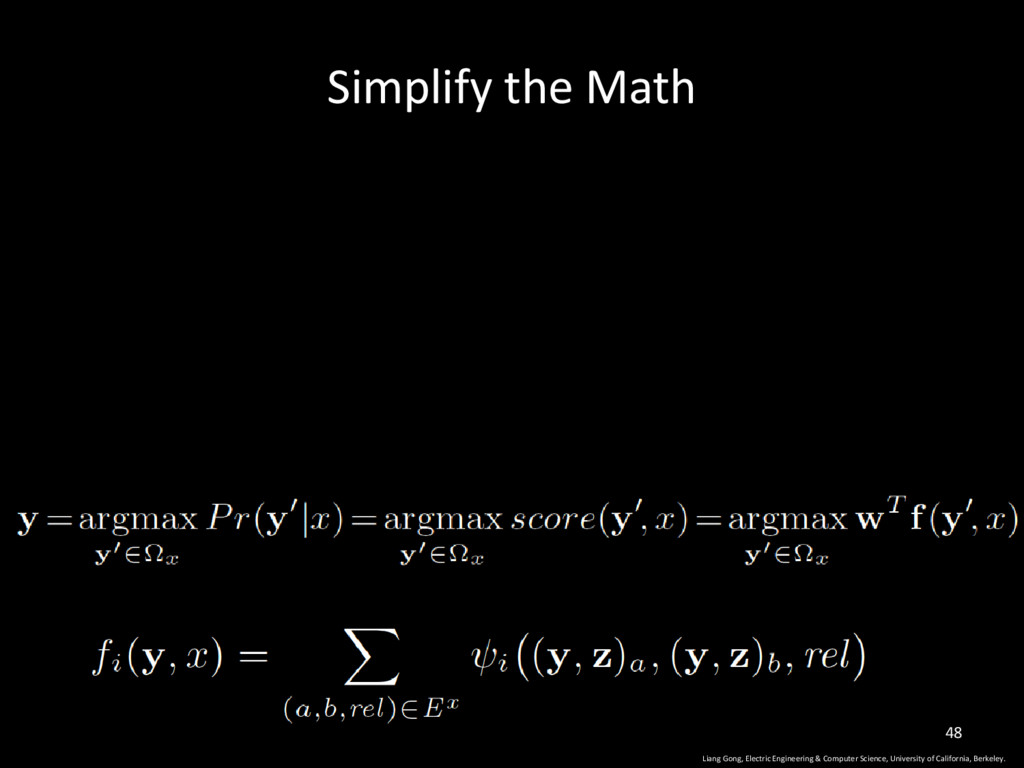{kind=link}
{kind=link}
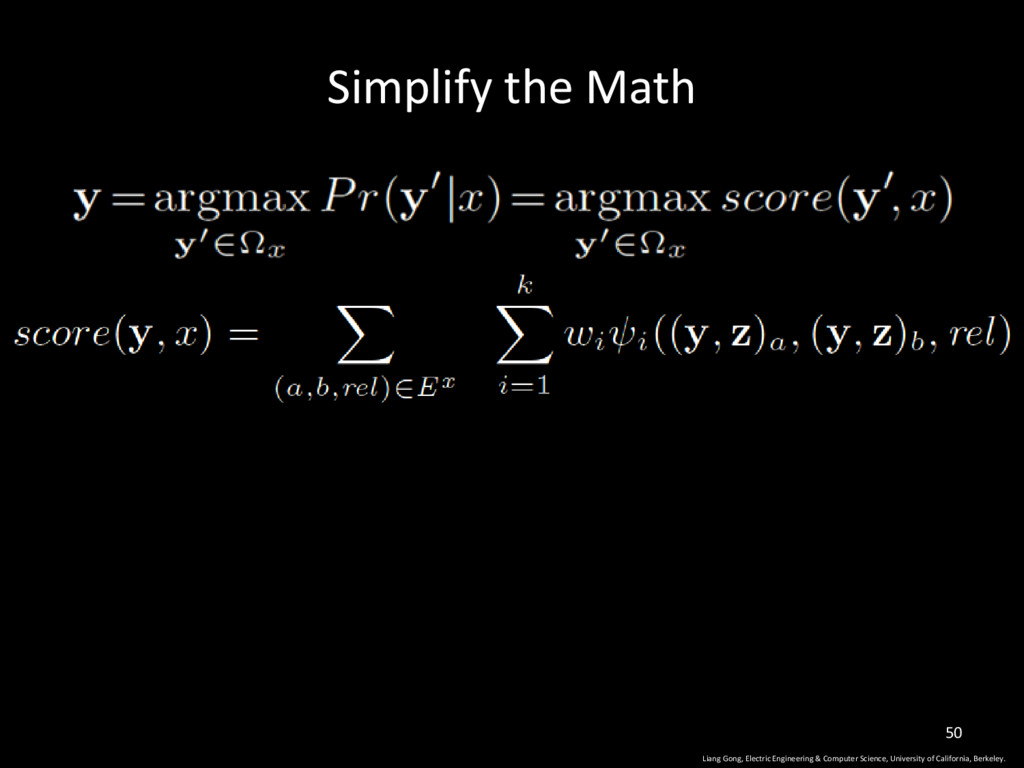{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}