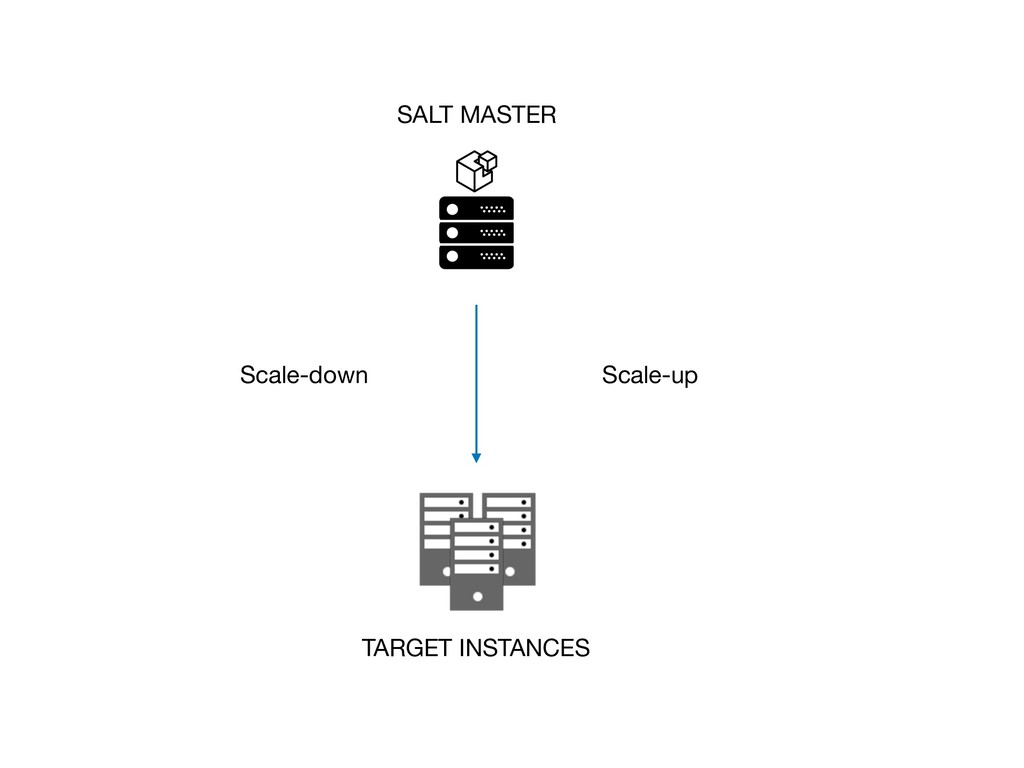
Autoscaling 是藉由監控服務流量來調整機器數量的一種機制,
可以盡量的用最低的成本來維持穩定的服務。
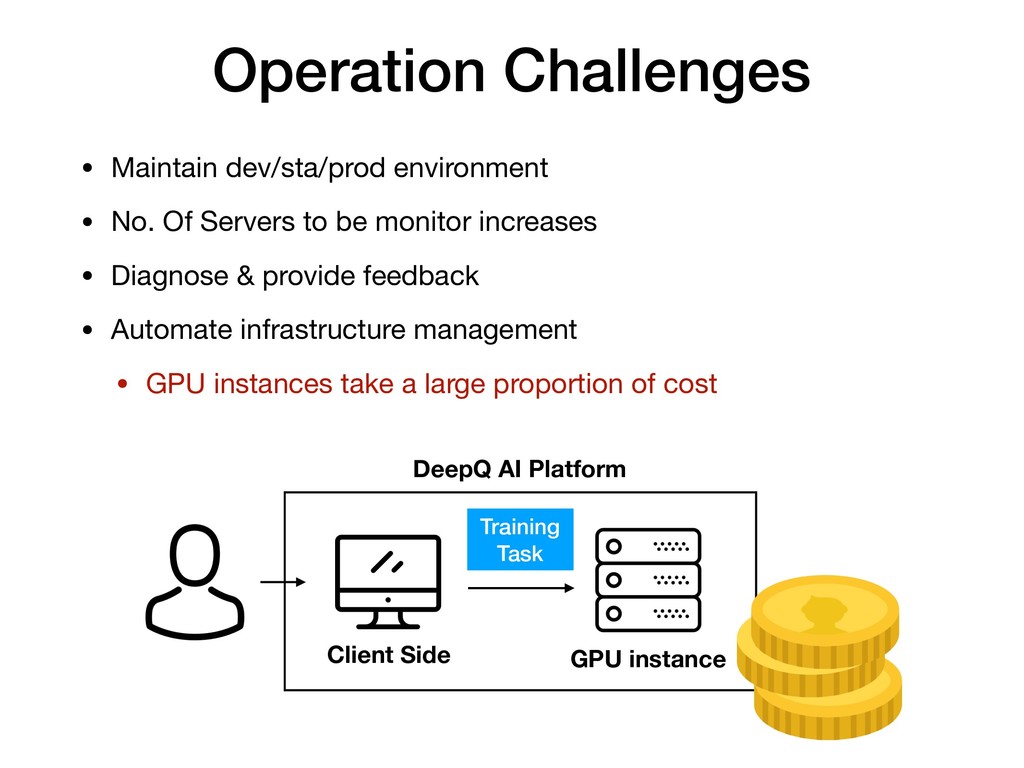
現有的cloud service, 例如AWS 對於自家的運算執行個體(EC2),
也有提供 Autoscaling 的機制,
但此機制對執行個體的增長刪減操作,不滿足我們的需求。
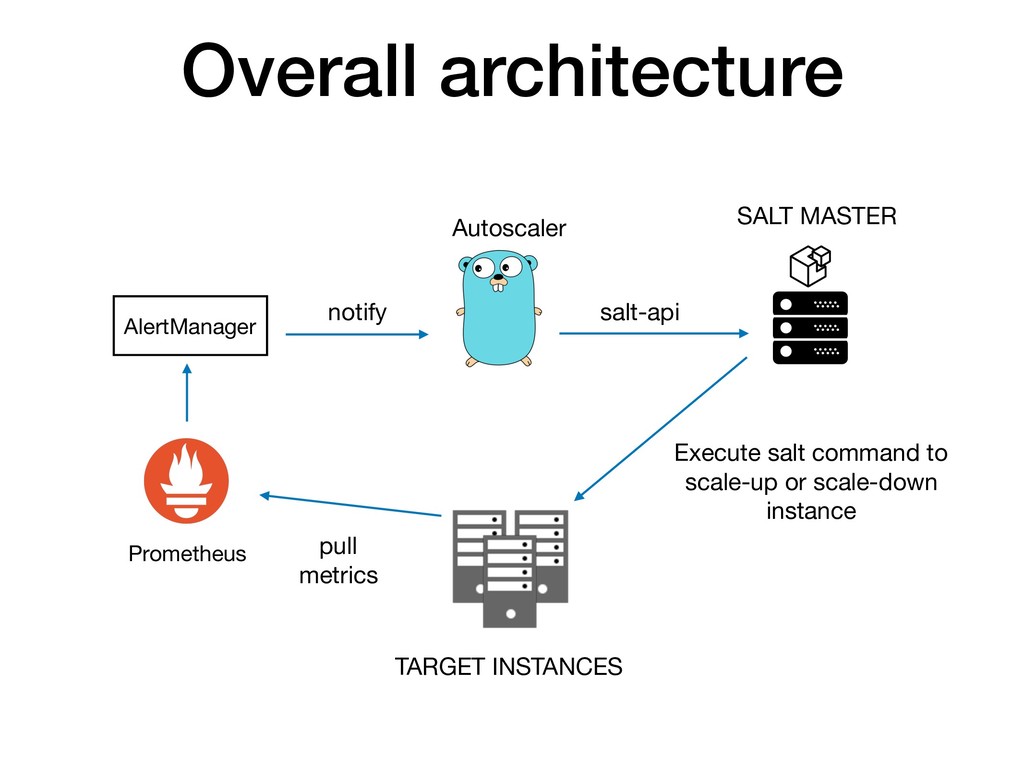
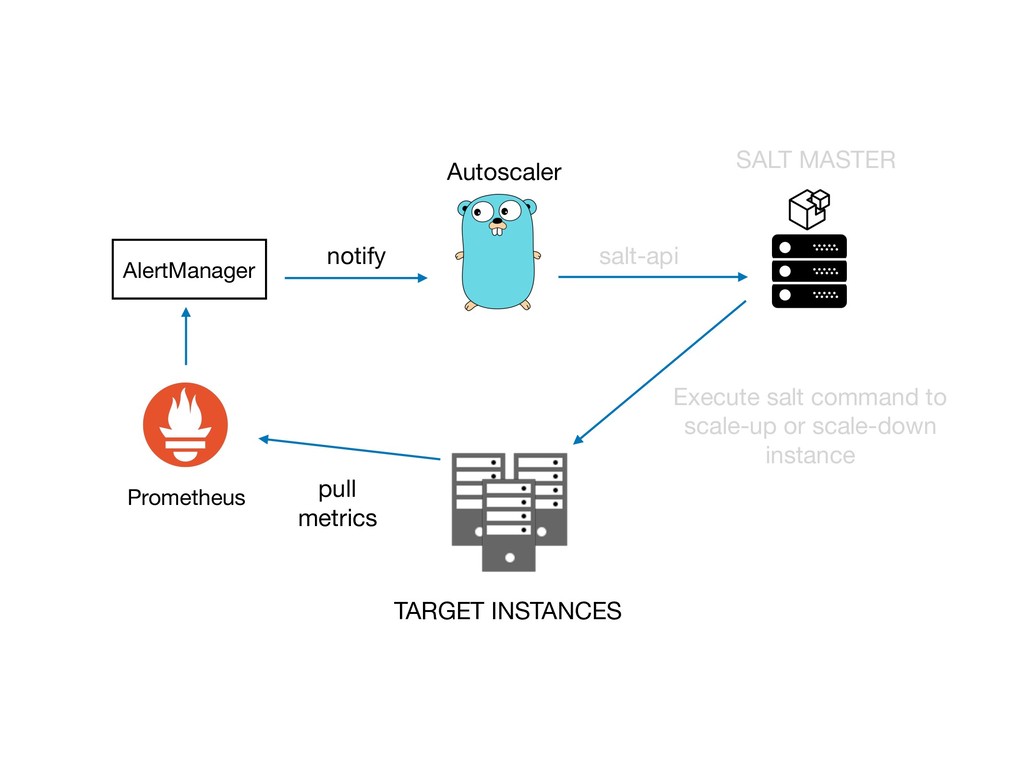
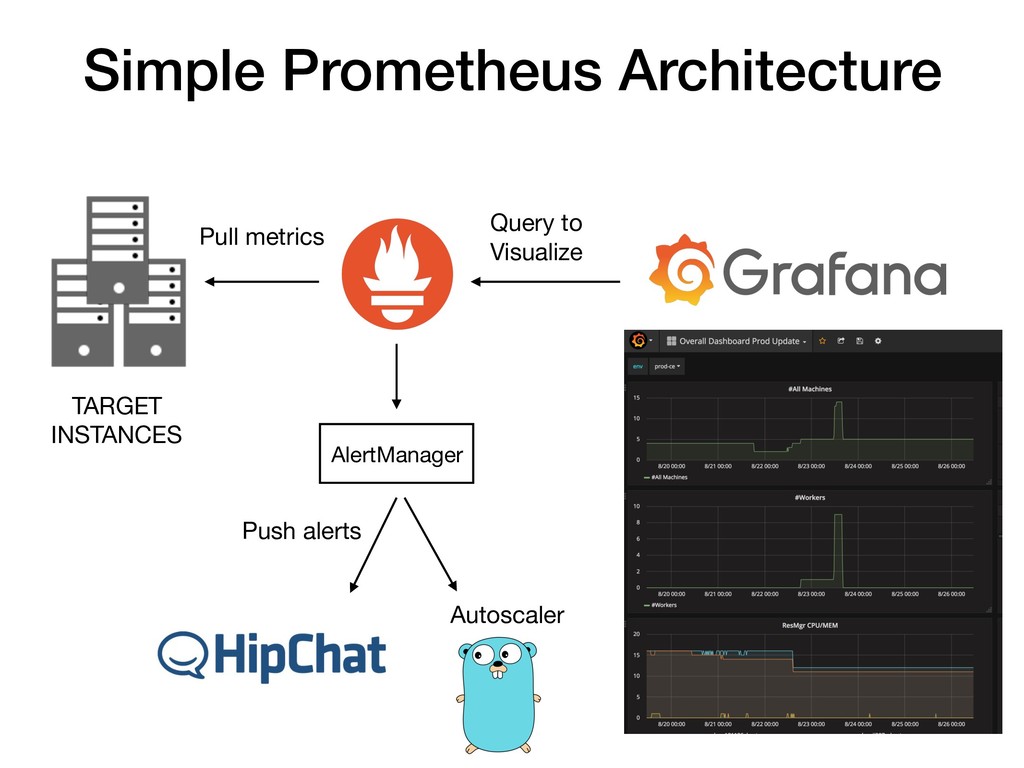
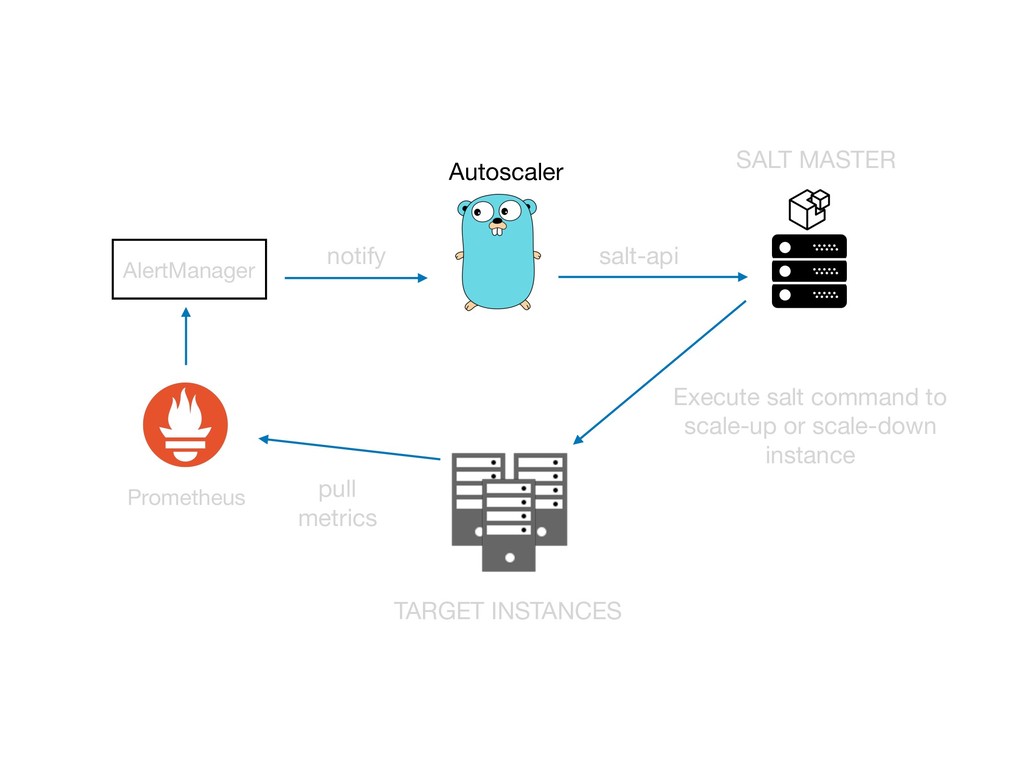
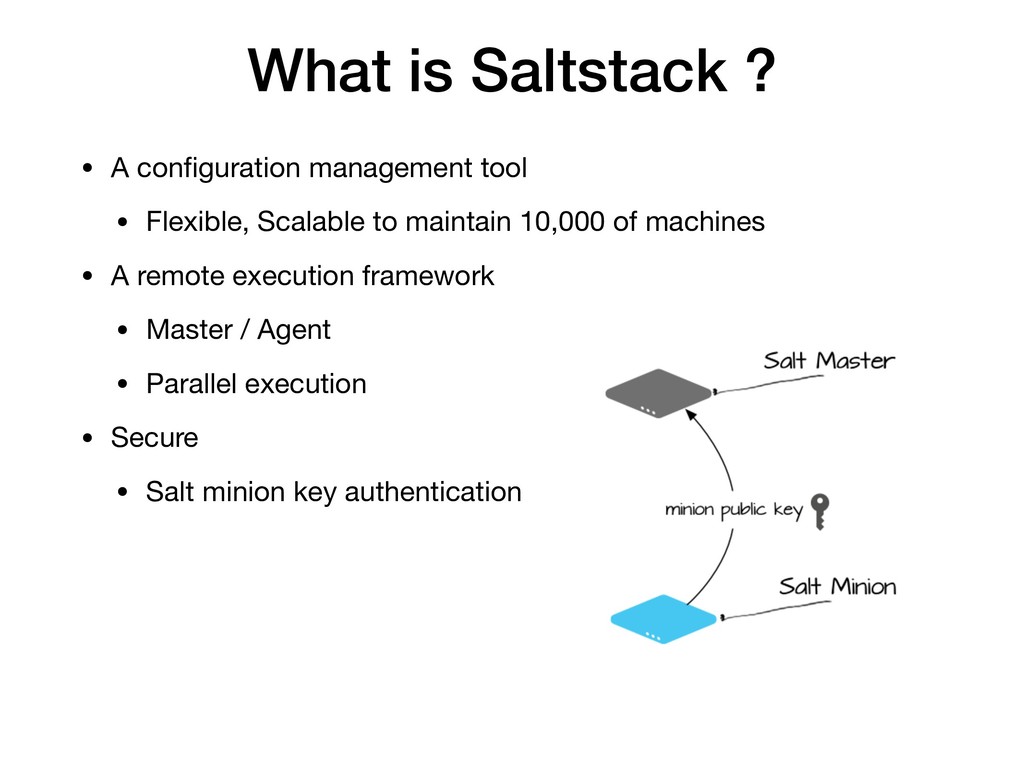
如何藉由 Prometheus (監控服務流量) 與 Saltstack (組態管理工具) 來實踐Autoscaling ?
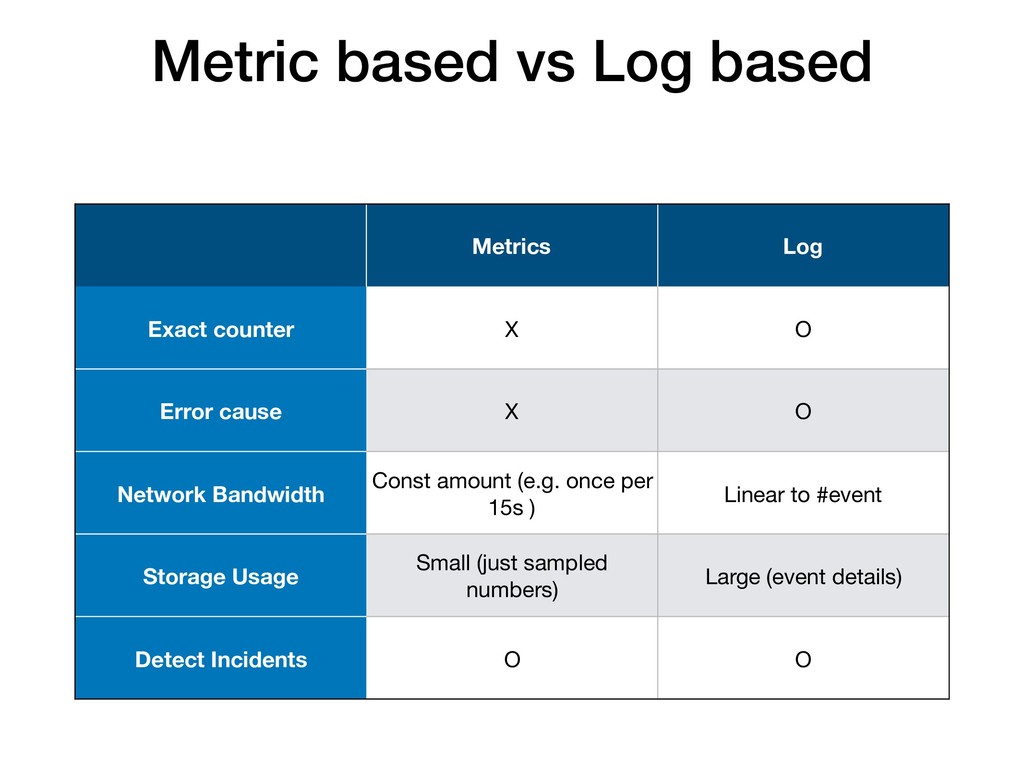
為什麼會選擇 Prometheus 來作為監控服務流量的工具?
以及為什麼會選擇 Saltstack?
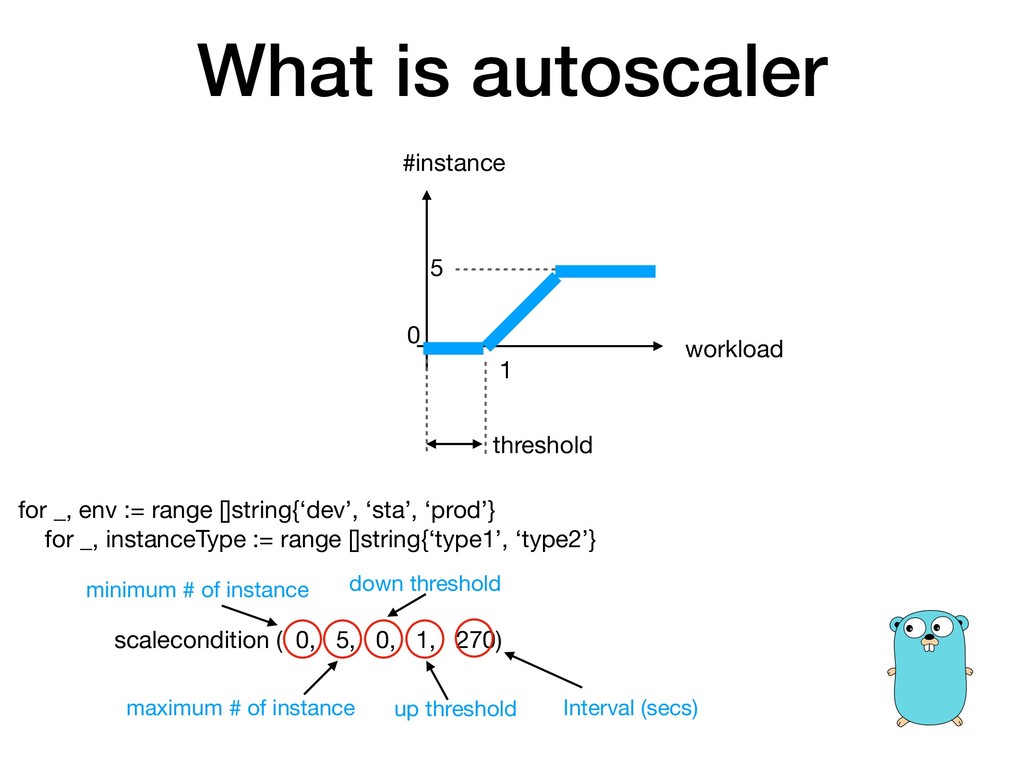
在設計 Autoscaling 的觸發條件上有什麼需要注意的?
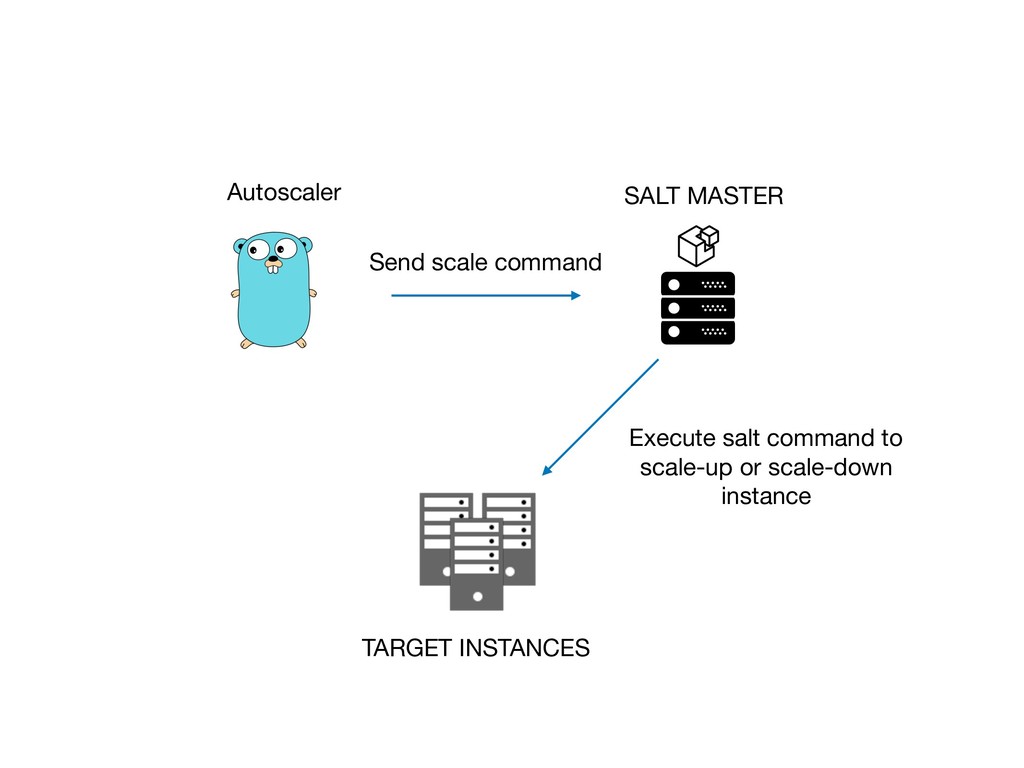
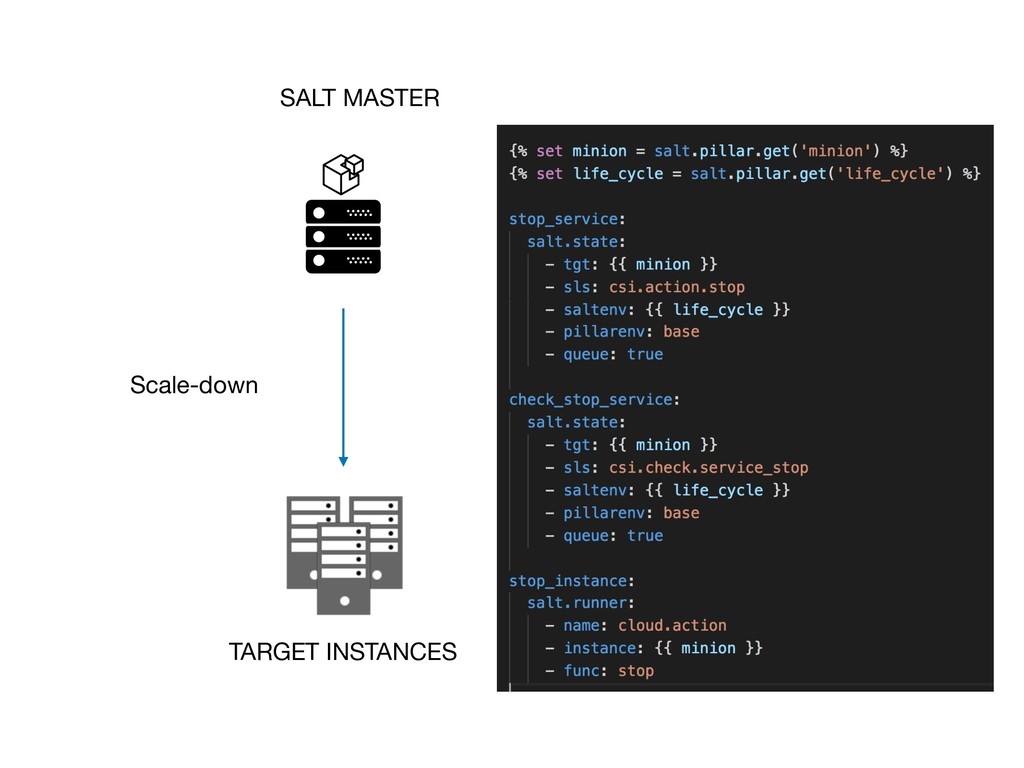
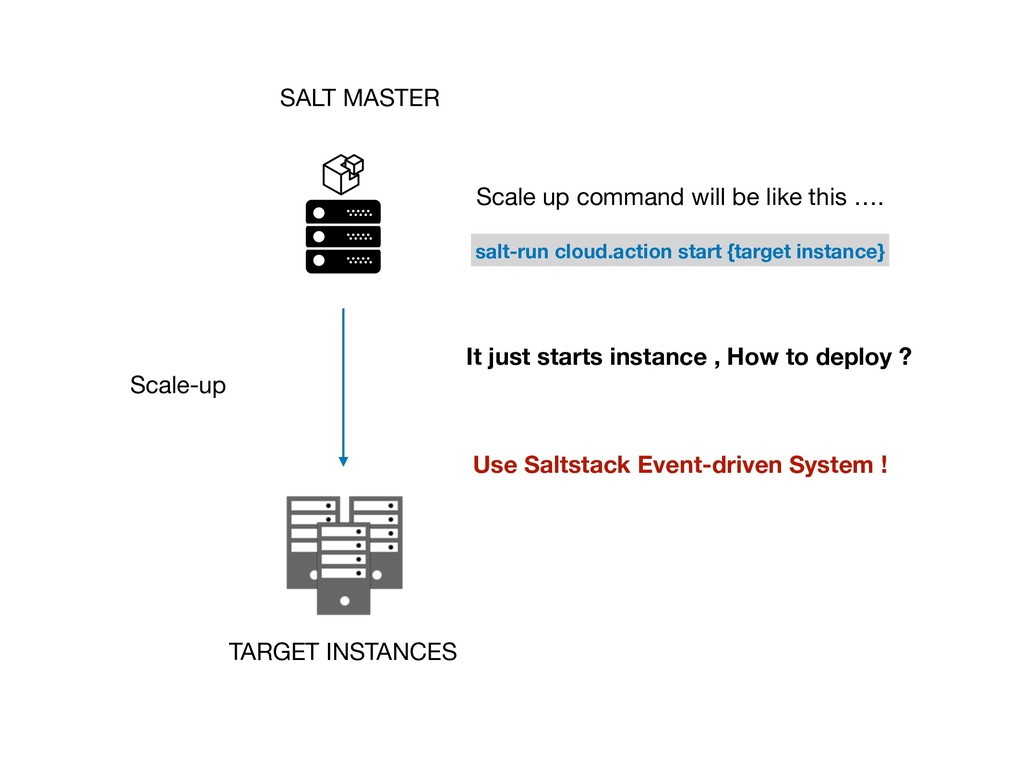
還有如何搭起 Prmoetheus 與 Saltstack 之間的橋樑。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
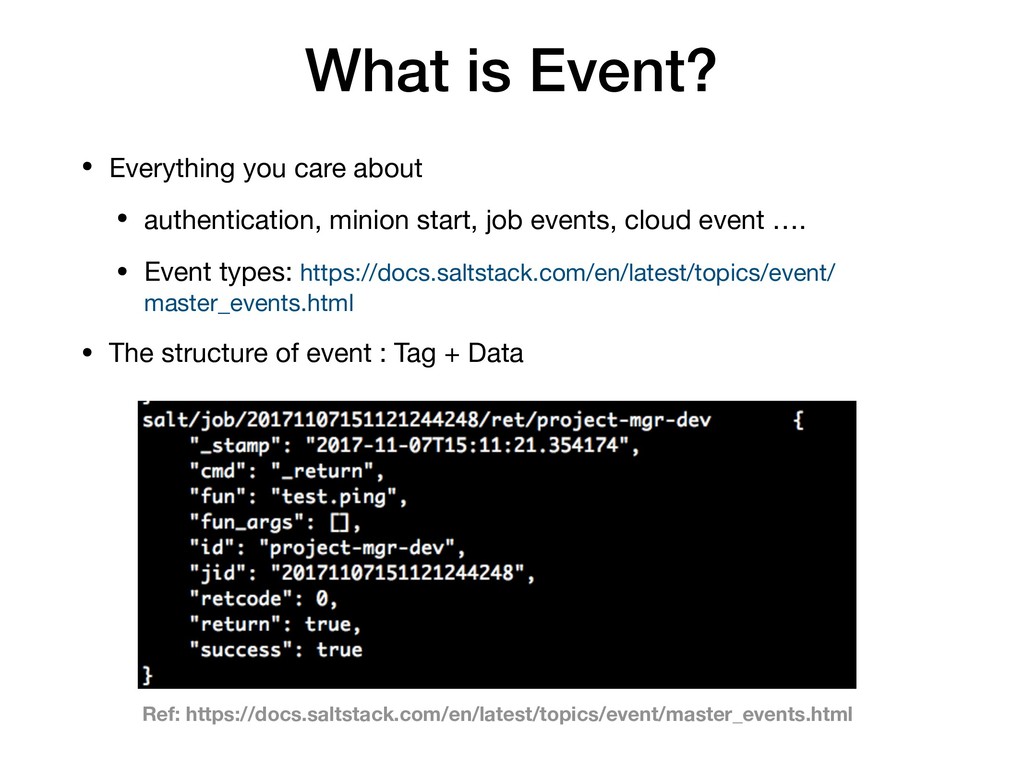{kind=link}
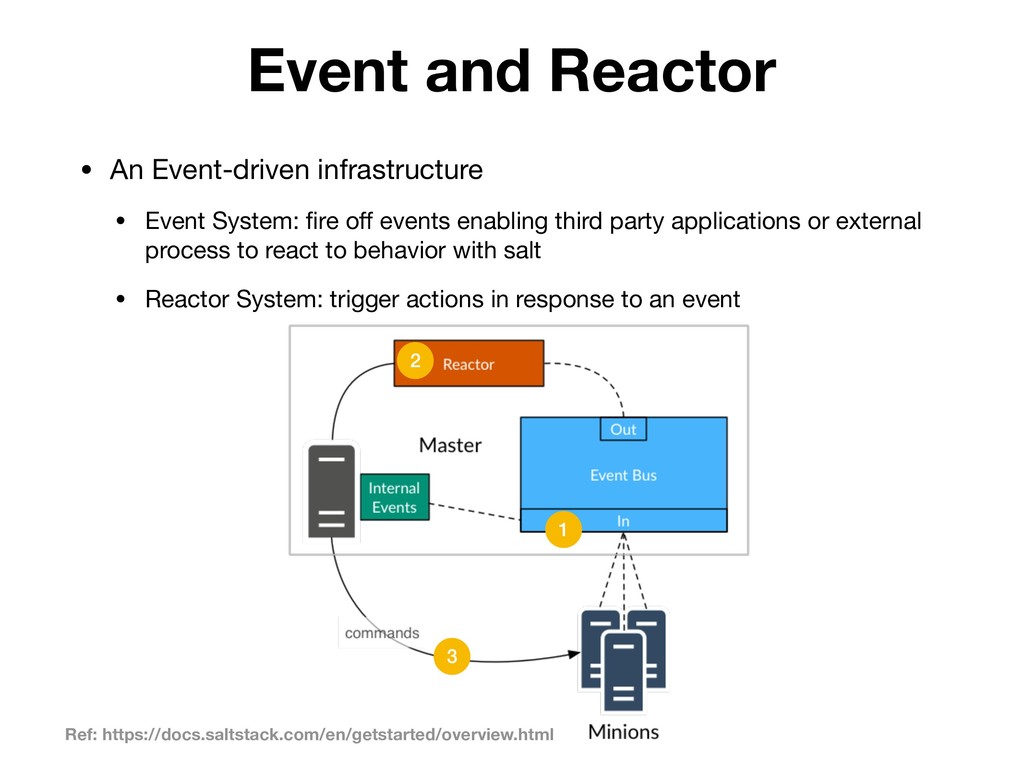{kind=link}
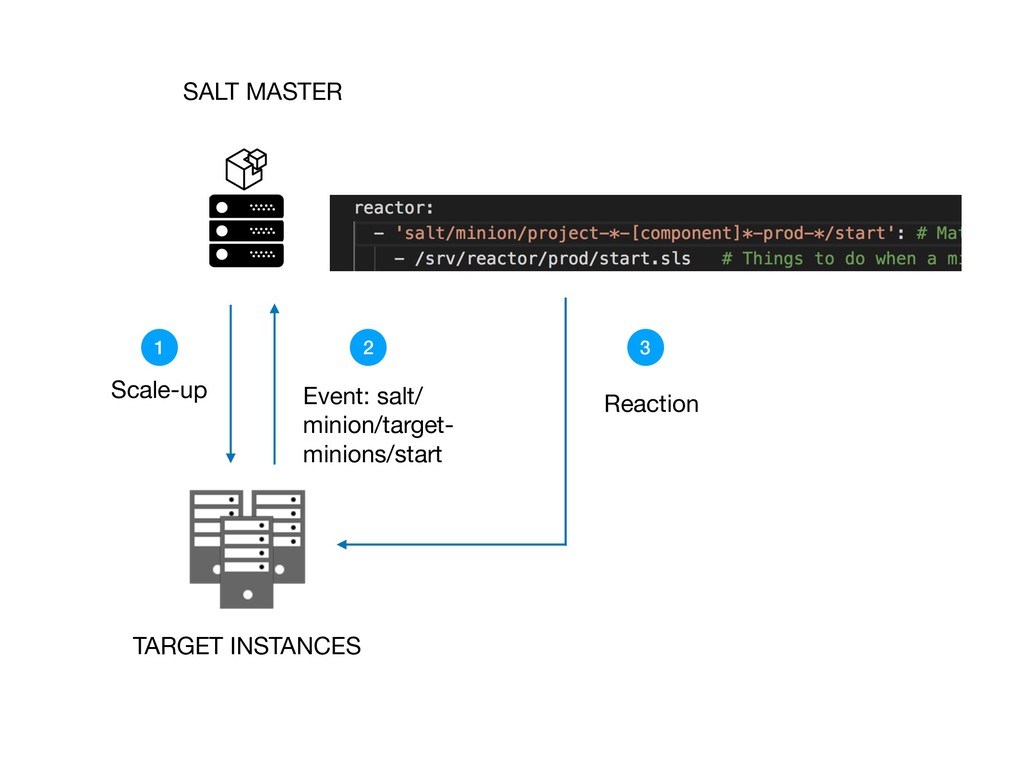{kind=link}
{kind=link}
{kind=link}