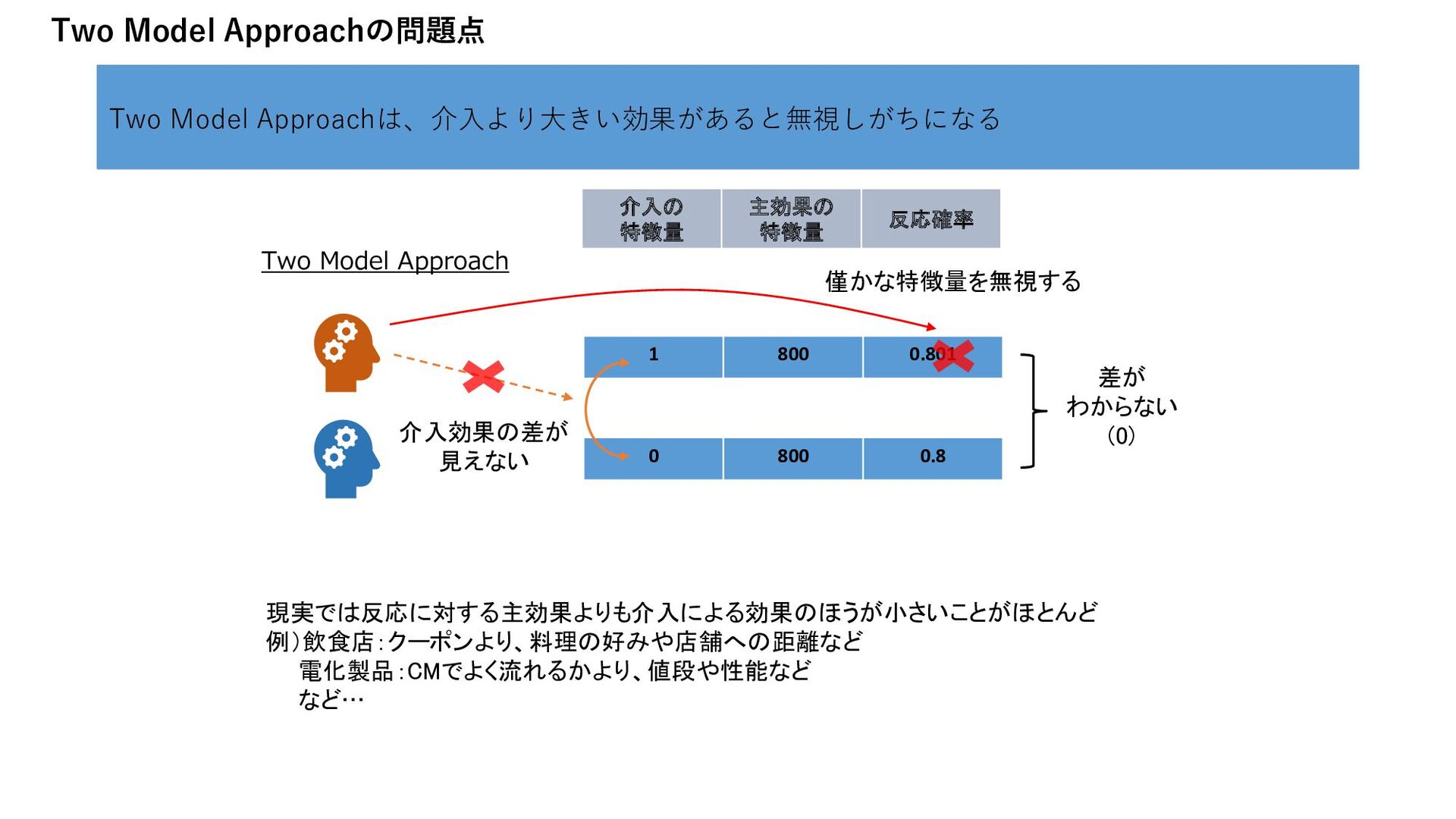
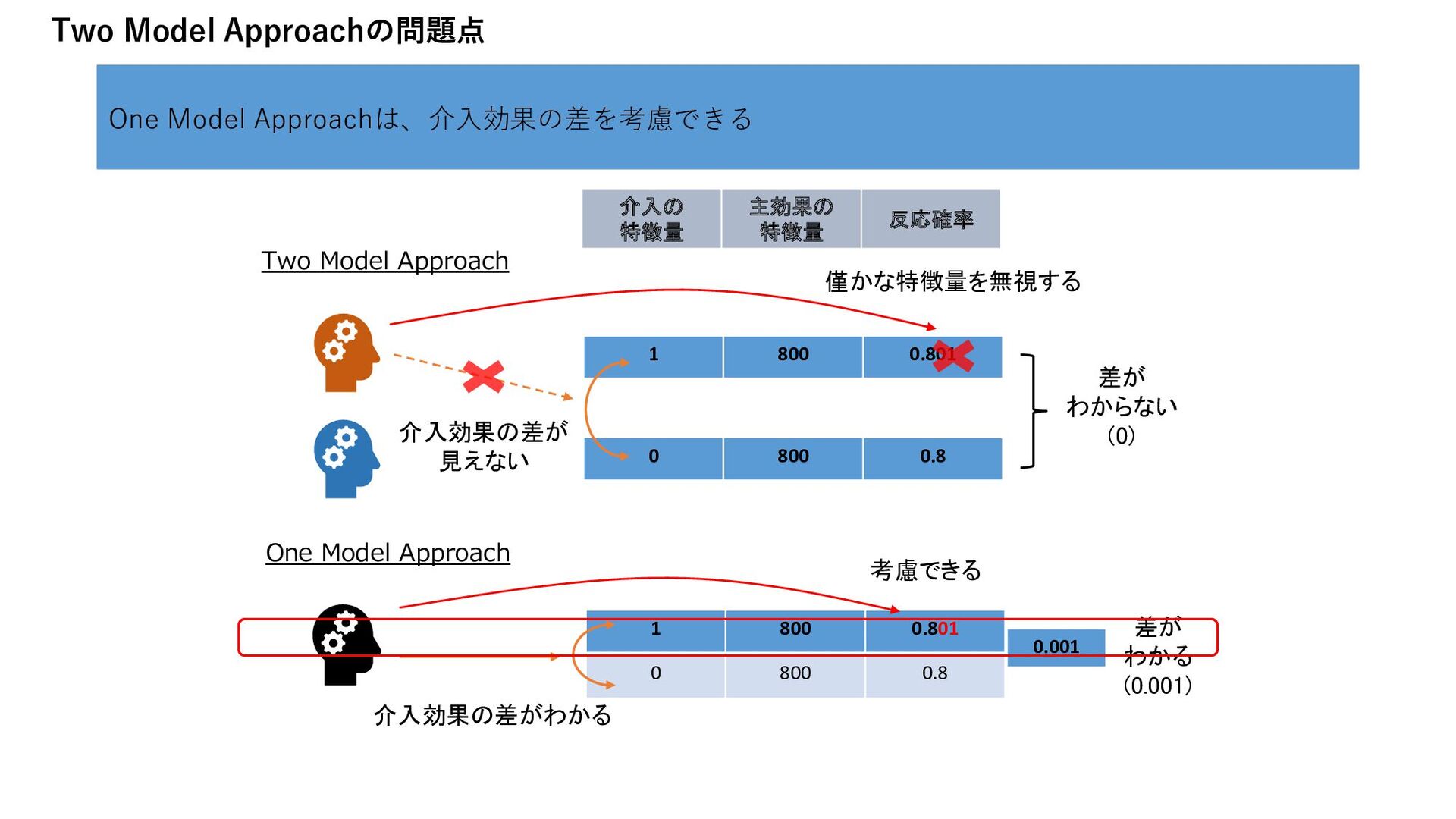
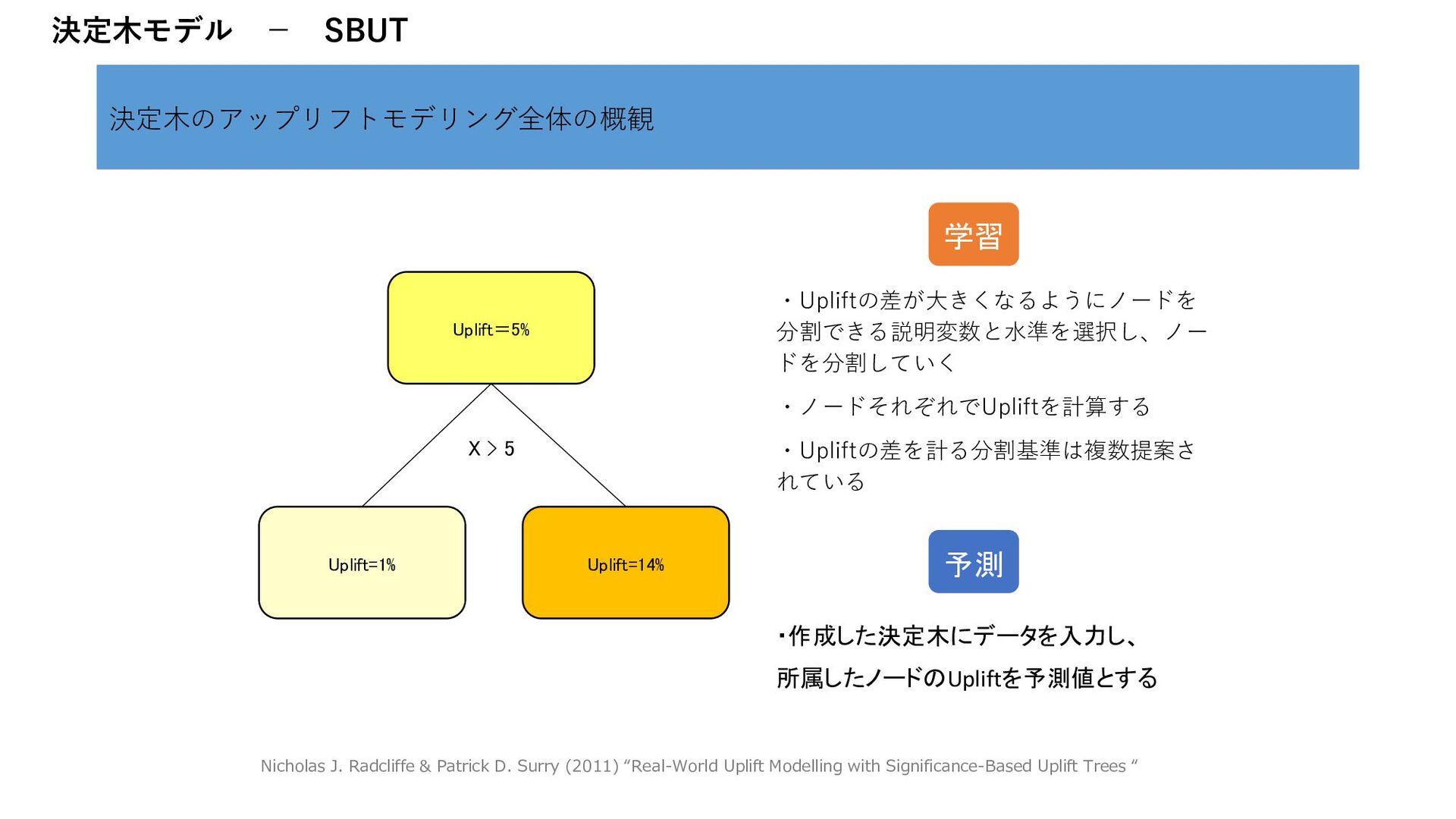
この場合、反応の予測がアップリフトの予測につながらない つまり、介入の効果を無視しがちなモデルになる そして、実は現実の問題はほとんどそうである Nicholas J. Radcliffe & Patrick D. Surry (2011) “Real-World Uplift Modelling with Significance-Based Uplift Trees“, p16-17
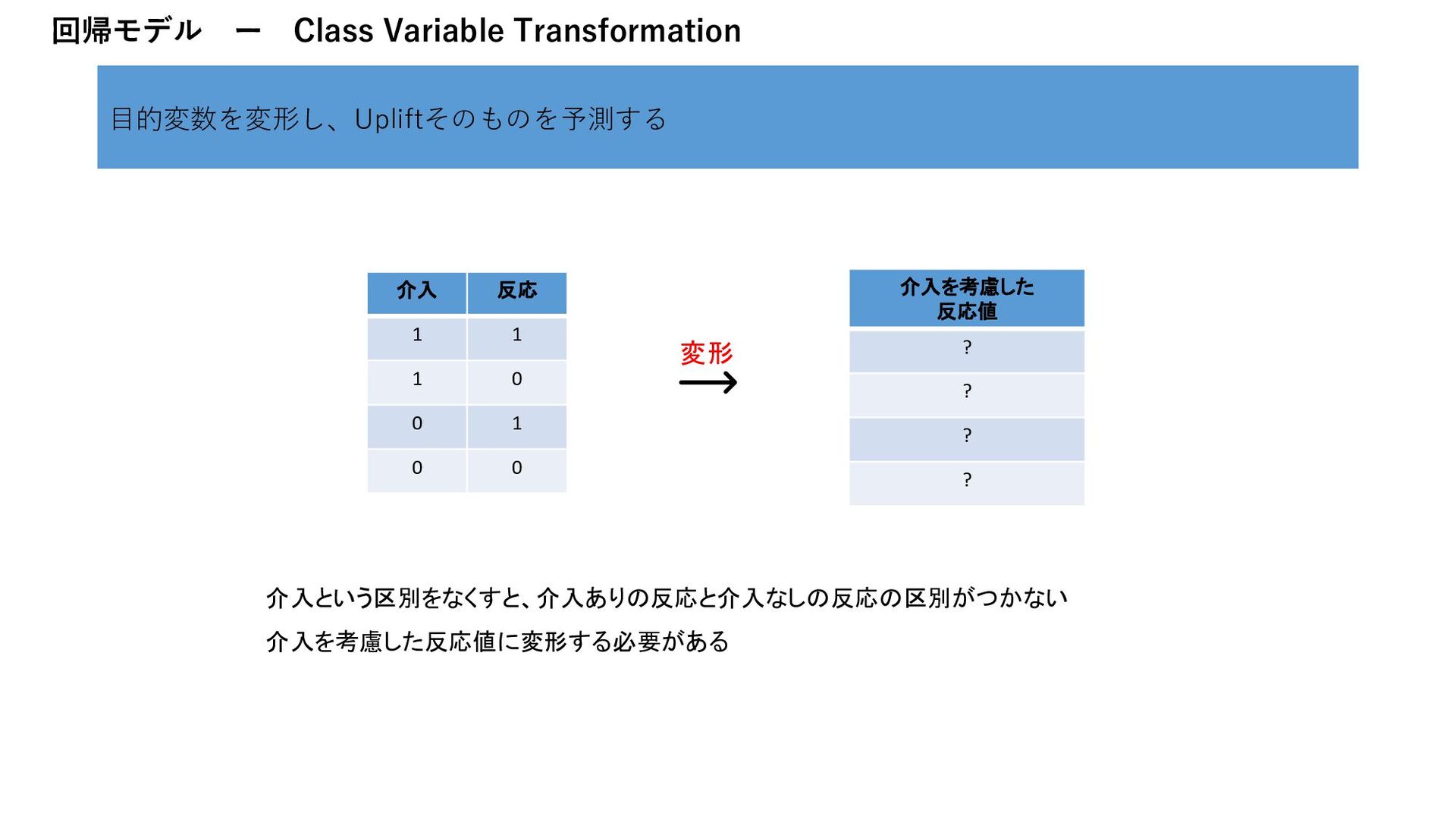
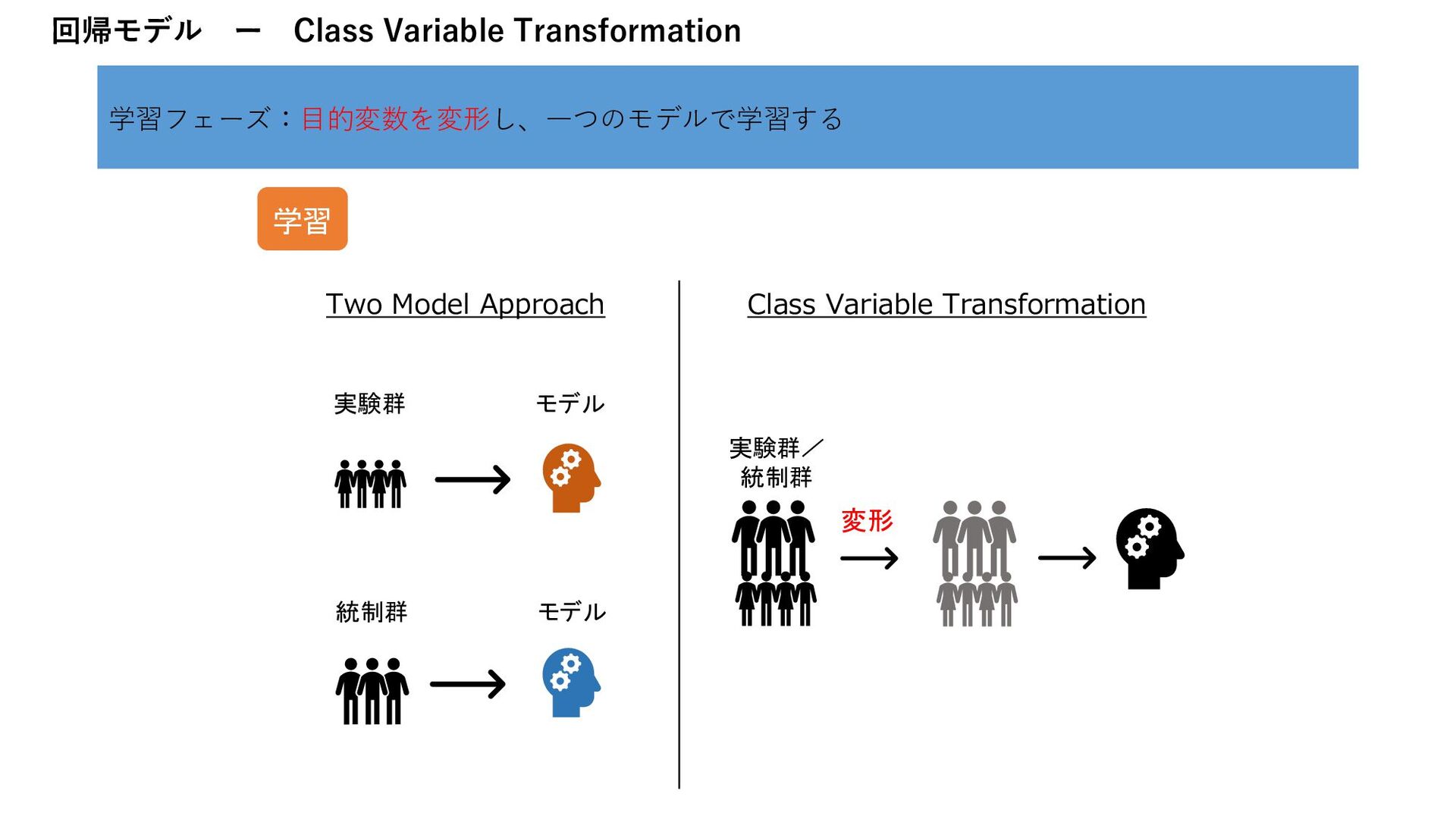
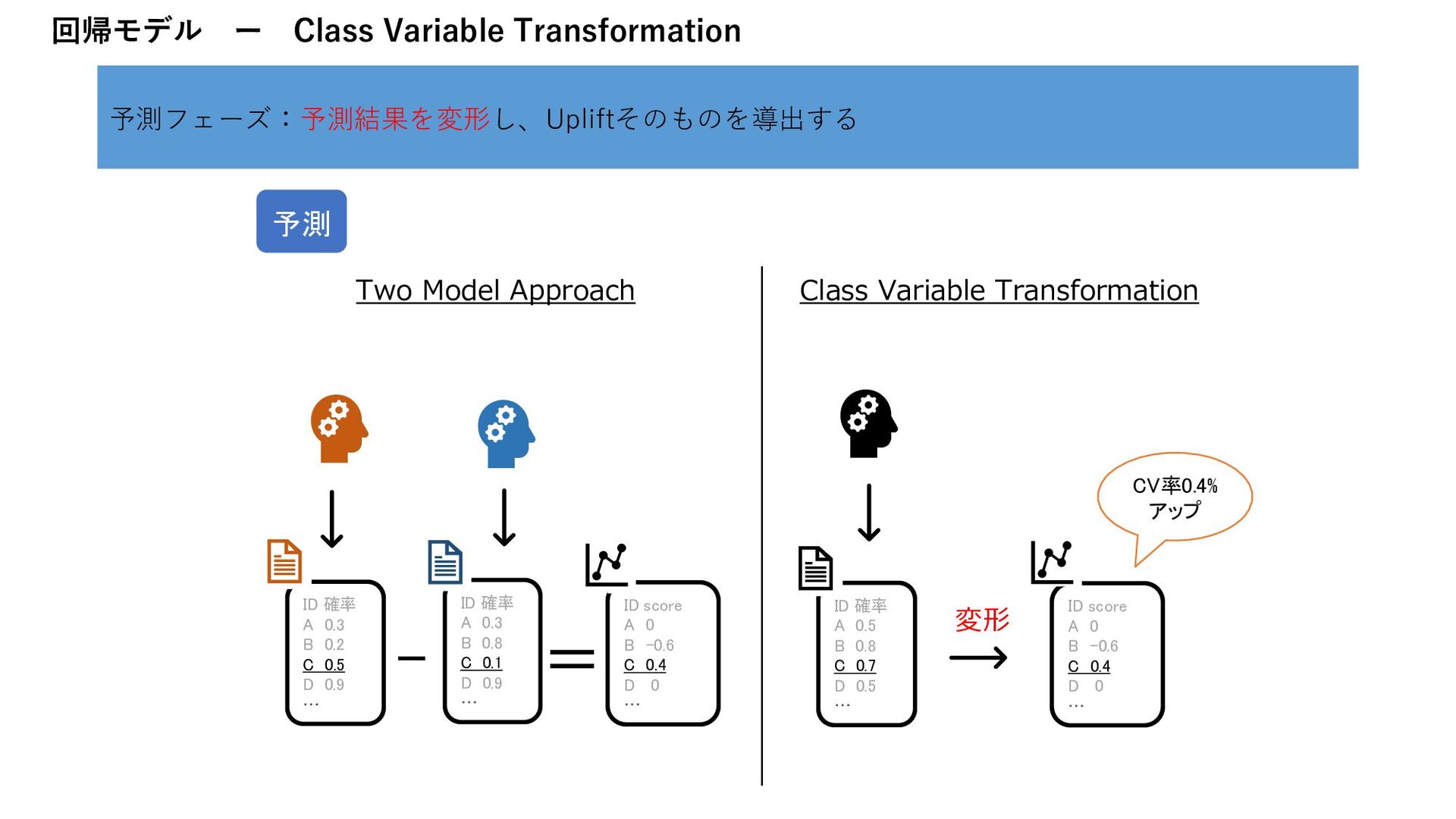
B 0.2 C 0.5 D 0.9 … ID 確率 A 0.3 B 0.8 C 0.1 D 0.9 … ID score A 0 B -0.6 C 0.4 D 0 … - = Two Model Approach Class Variable Transformation ID 確率 A 0.5 B 0.8 C 0.7 D 0.5 … ID score A 0 B -0.6 C 0.4 D 0 … 変形 予測 CV率0.4% アップ
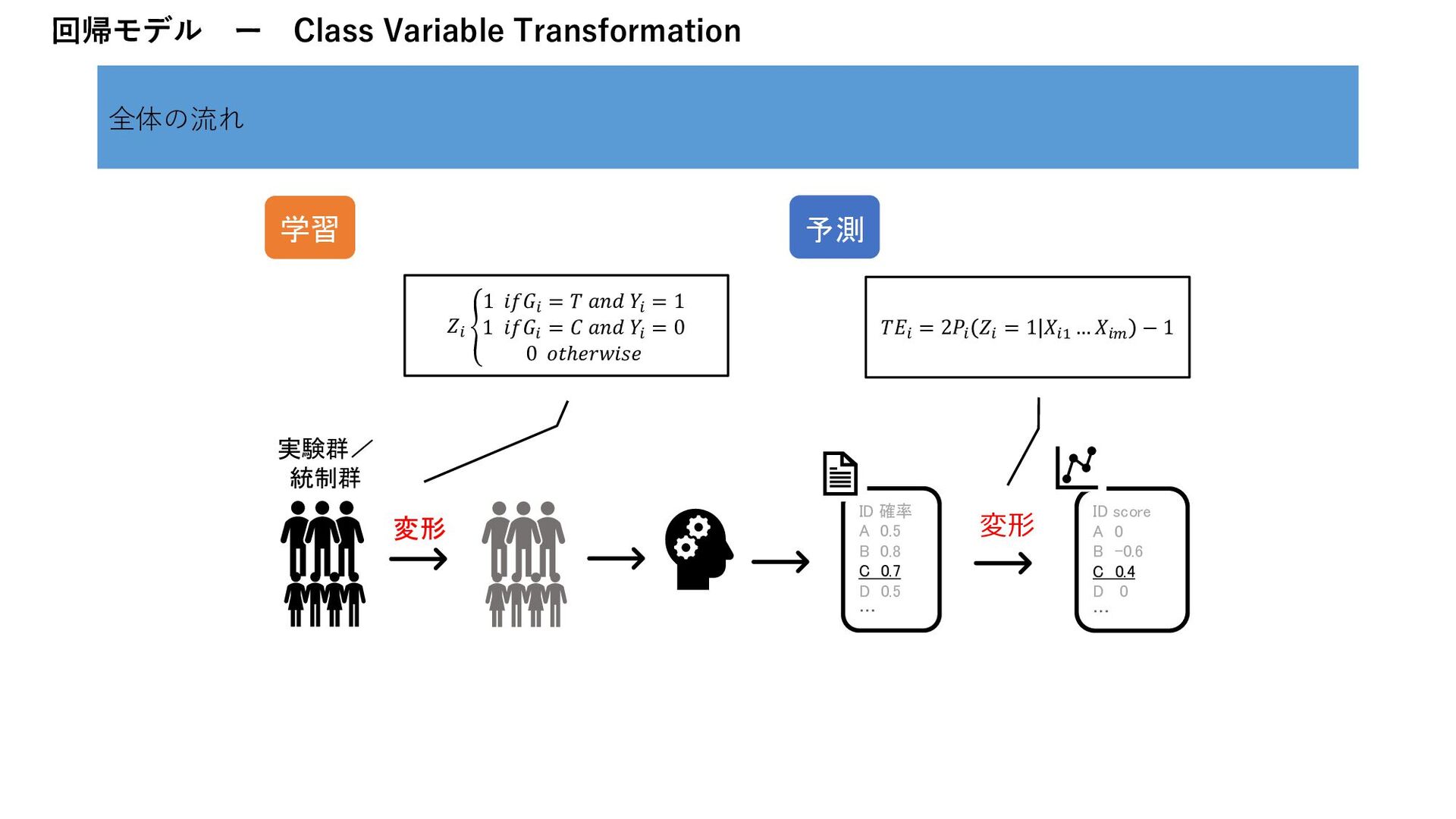
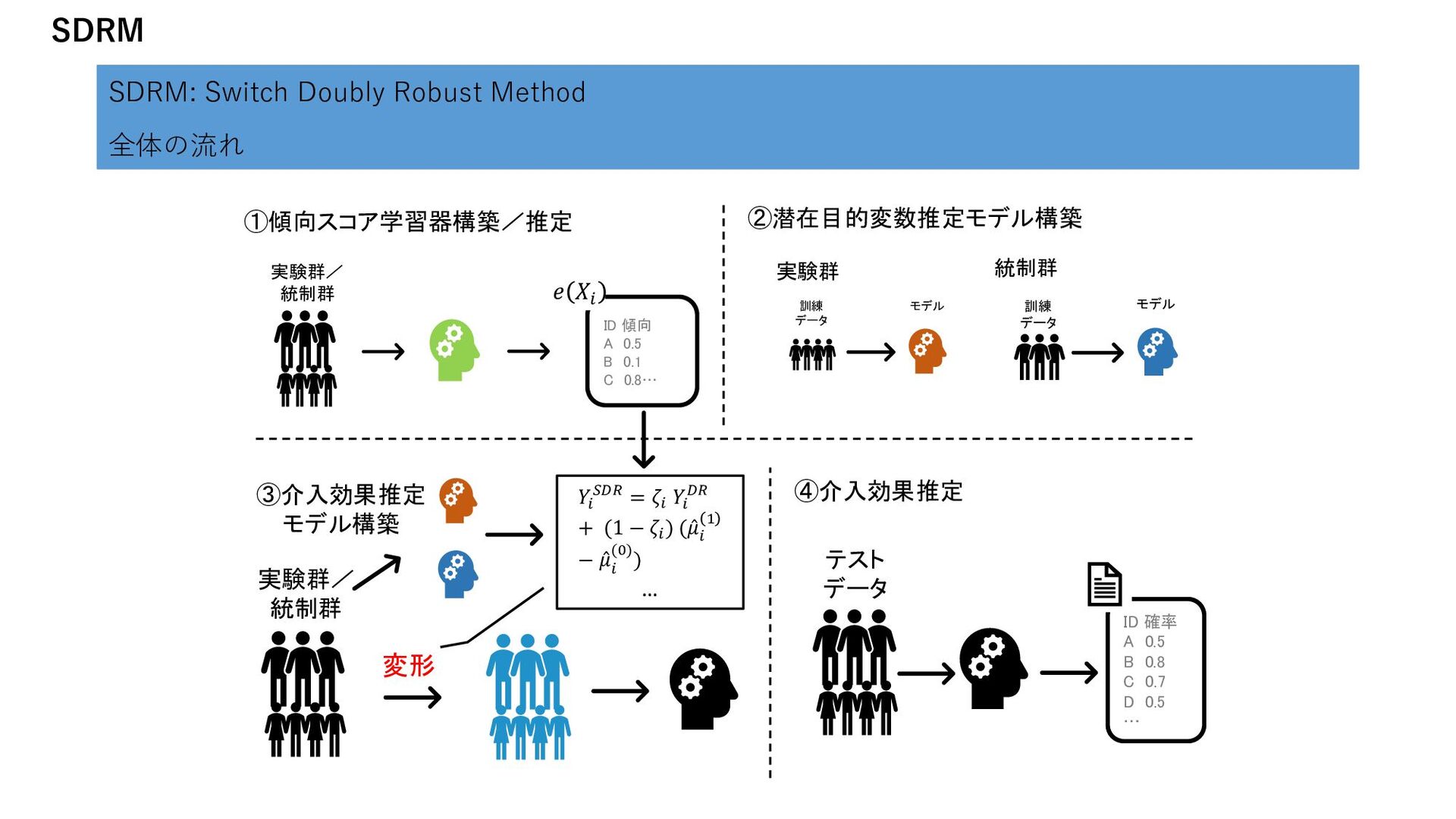
1 𝑍𝑖 ቐ 1 𝑖𝑓𝐺𝑖 = 𝑇 𝑎𝑛𝑑 𝑌𝑖 = 1 1 𝑖𝑓𝐺𝑖 = 𝐶 𝑎𝑛𝑑 𝑌𝑖 = 0 0 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 回帰モデル ー Class Variable Transformation 全体の流れ 実験群/ 統制群 変形 学習 予測 ID 確率 A 0.5 B 0.8 C 0.7 D 0.5 … ID score A 0 B -0.6 C 0.4 D 0 … 変形
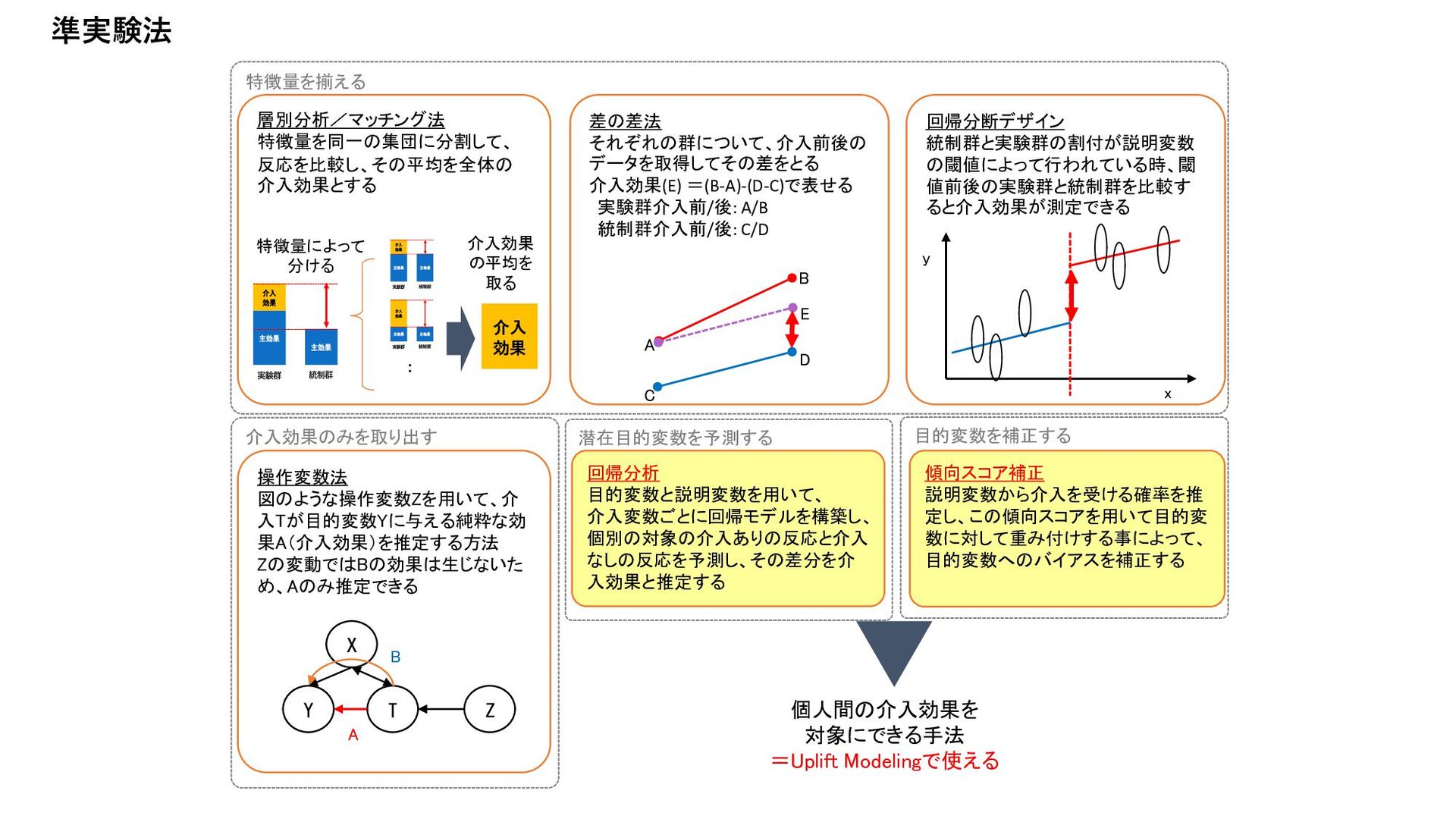
入効果と推定する 回帰分断デザイン 統制群と実験群の割付が説明変数 の閾値によって行われている時、閾 値前後の実験群と統制群を比較す ると介入効果が測定できる 差の差法 それぞれの群について、介入前後の データを取得してその差をとる 介入効果(E) =(B-A)-(D-C)で表せる 実験群介入前/後: A/B 統制群介入前/後: C/D B E C A D x y 層別分析/マッチング法 特徴量を同一の集団に分割して、 反応を比較し、その平均を全体の 介入効果とする 介入 効果 介入効果 の平均を 取る 特徴量によって 分ける ・ ・ 傾向スコア補正 説明変数から介入を受ける確率を推 定し、この傾向スコアを用いて目的変 数に対して重み付けする事によって、 目的変数へのバイアスを補正する 操作変数法 図のような操作変数Zを用いて、介 入Tが目的変数Yに与える純粋な効 果A(介入効果)を推定する方法 Zの変動ではBの効果は生じないた め、Aのみ推定できる Y T Z X A B 個人間の介入効果を 対象にできる手法 =Uplift Modelingで使える
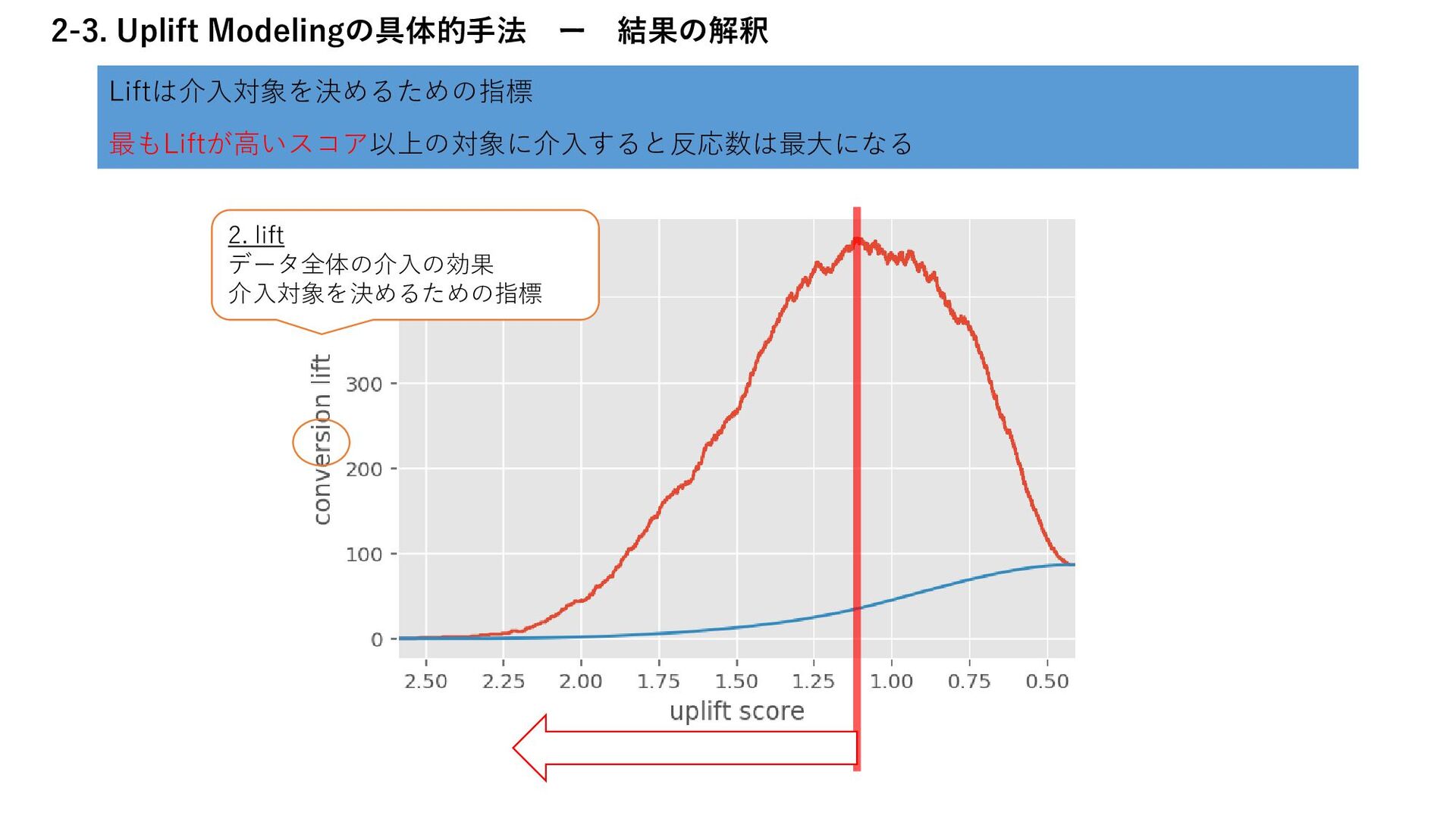
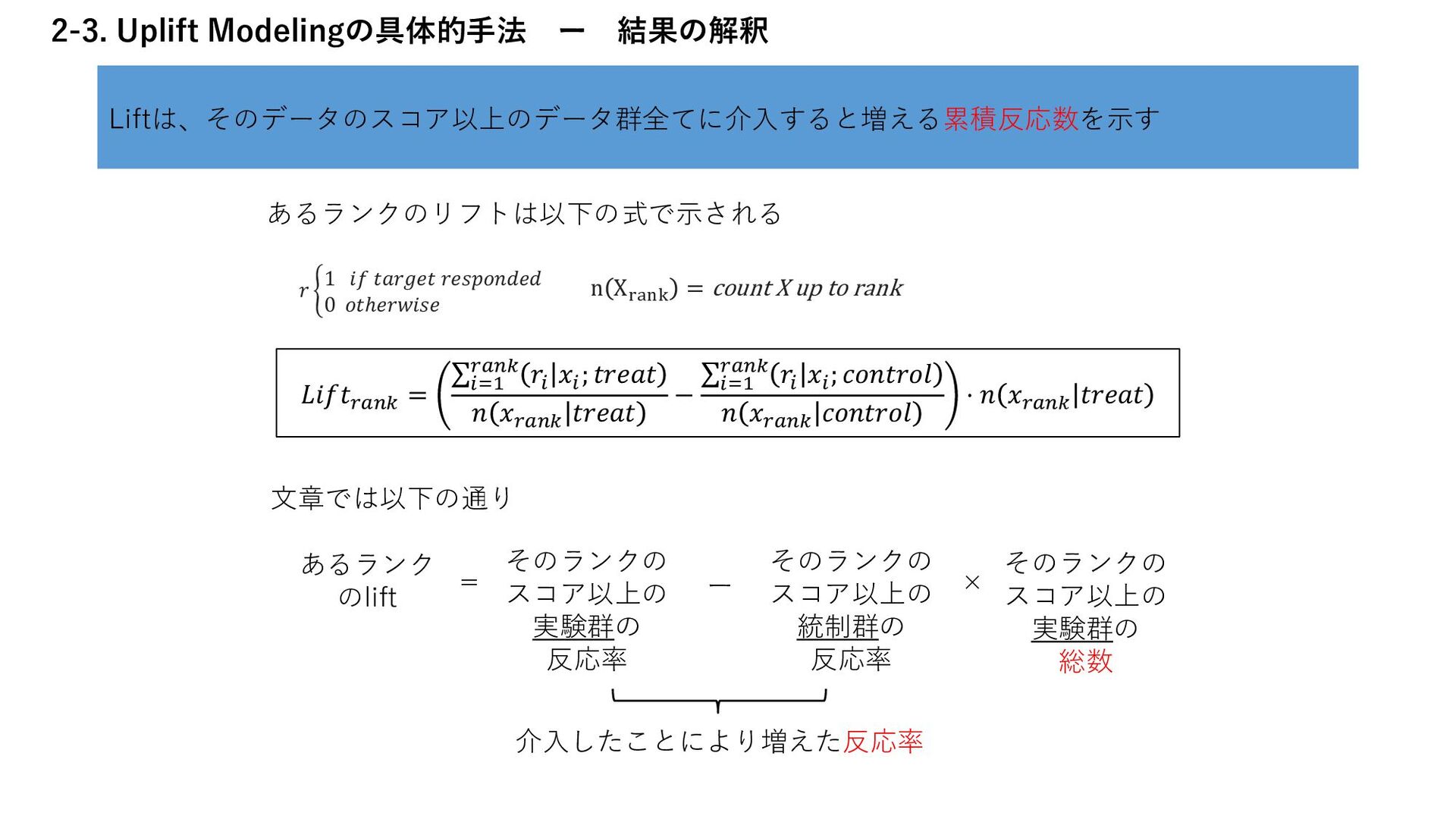
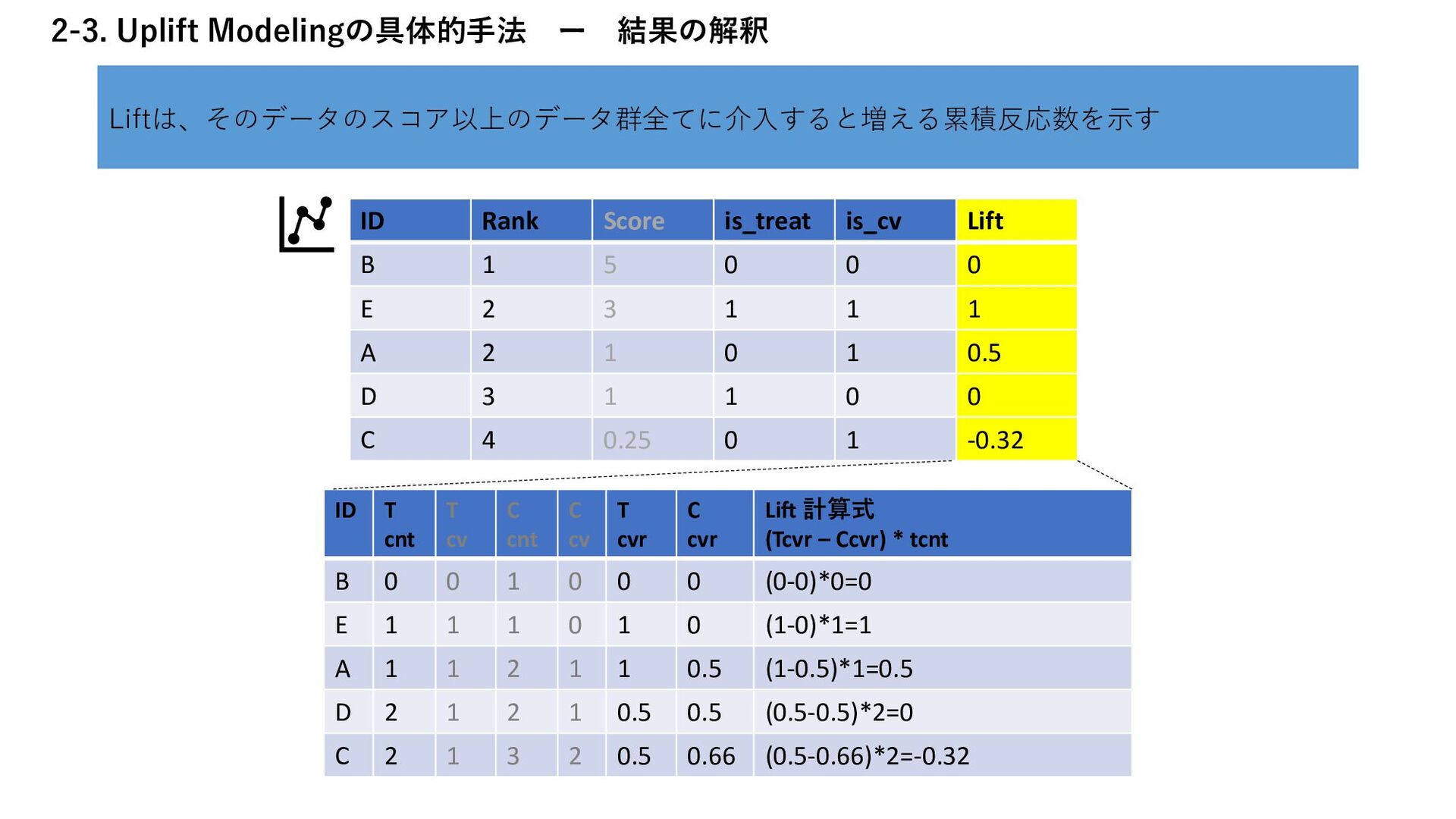
実験群の反応率:𝑅𝑡 統制群の反応率:𝑅𝑐 実験群の総数:𝑁𝑡 統制群の総数:𝑁𝑐 実験群の反応数ー実験群の総数に合わせて補正した統制群の反応数 変形すると、「仕事ではじめる機械学習 9章」と同じ形の式になる 𝐿𝑖𝑓𝑡 𝑁𝑡 = 𝑅𝑡 𝑁𝑡 − 𝑅𝑐 𝑁𝑐 Lift = 𝑅𝑡 𝑁𝑡 − 𝑅𝑐 𝑁𝑐 ⋅ Nt (実験群の反応率ー統制群の反応率)×実験群の総数 なぜ実験群の数を軸にするのかについては、原論文にも言及がないが、 Liftの意味がそもそも、介入に対して反応率がどれだけ上がるかという、実験群を軸にした基準であるた めではないかと考える Nicholas J. Radcliffe (2007) “Using control groups to target on predicted lift: Building and assessing uplift model”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}