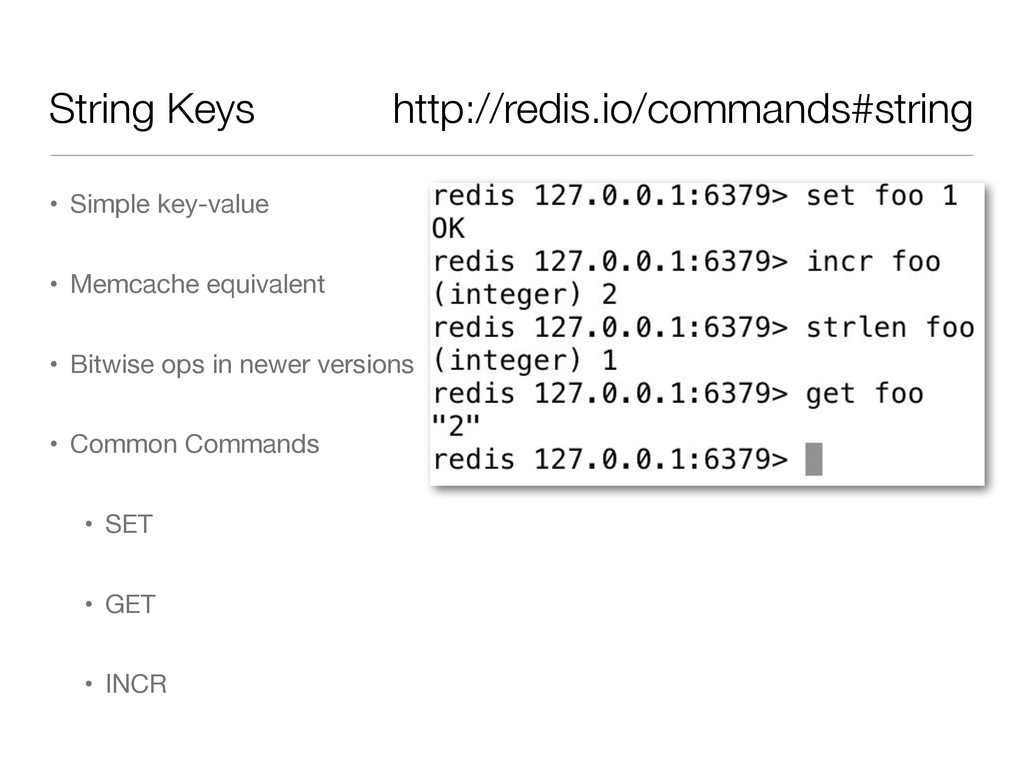
database • Backed by VMWare • Redis works like memcached, but better: • Atomic commands & transactions • Server-side data structures • Comparable speed
RAM as you have data • Disk persistence is exactly that • Customize disk writes interval to suit your pain threshold • Something interesting happens when you run out of memory
like node, nginx • It can peg one CPU core but that’s it • Redis Cluster can solve this with automatic sharding • Below Redis 3.0, it’s easier to get a bigger server than fix your code (In my opinion)
on Windows • Has virtually no compile dependencies • apt-get, homebrew, yum, etc • Amazon ElastiCache • No reason not to run the latest and greatest • but at get at least 2.6
• use one database per application • Within a database, namespace your keys • Ex: classname:uid:datafield • Keep them concise but useful. Keys take memory too!
user-provided score value • Extremely fast access by score or range of scores, because it’s sorted in storage • Common commands • ZADD • ZRANGE • ZREVRANGE
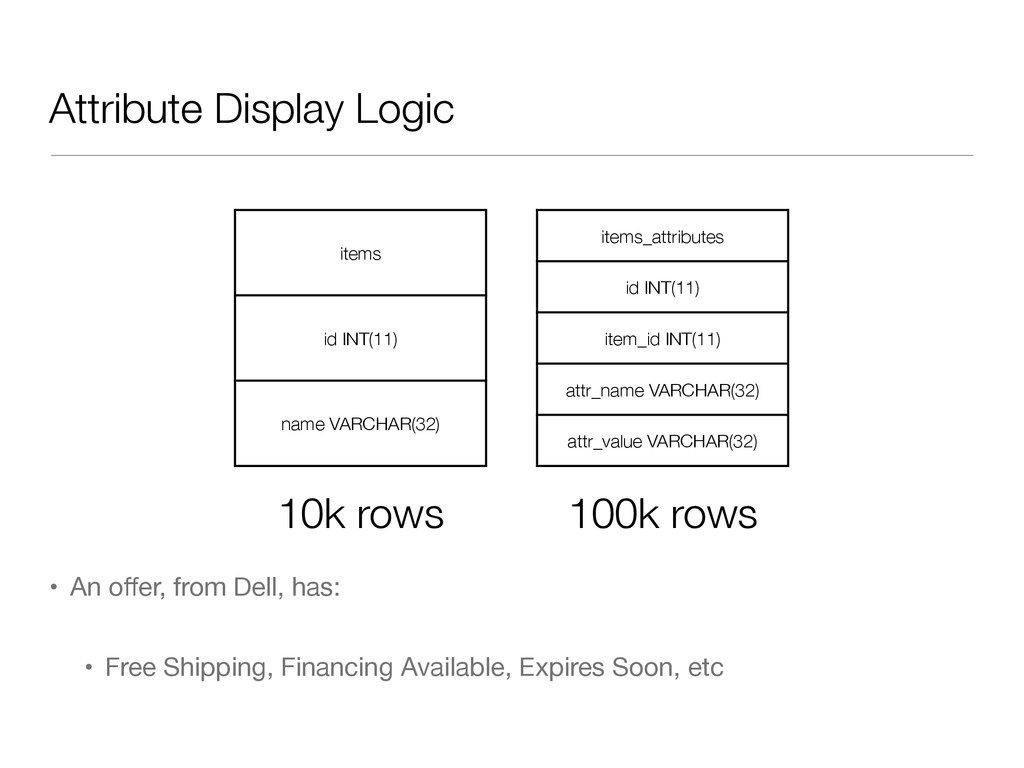
• Define a consistent way to name a relational object in Redis • I prefer [object class]:[object id]:[attribute] • ex: product:13445:num_comments • This prevents data collisions, and makes it easy to work with data on the command line
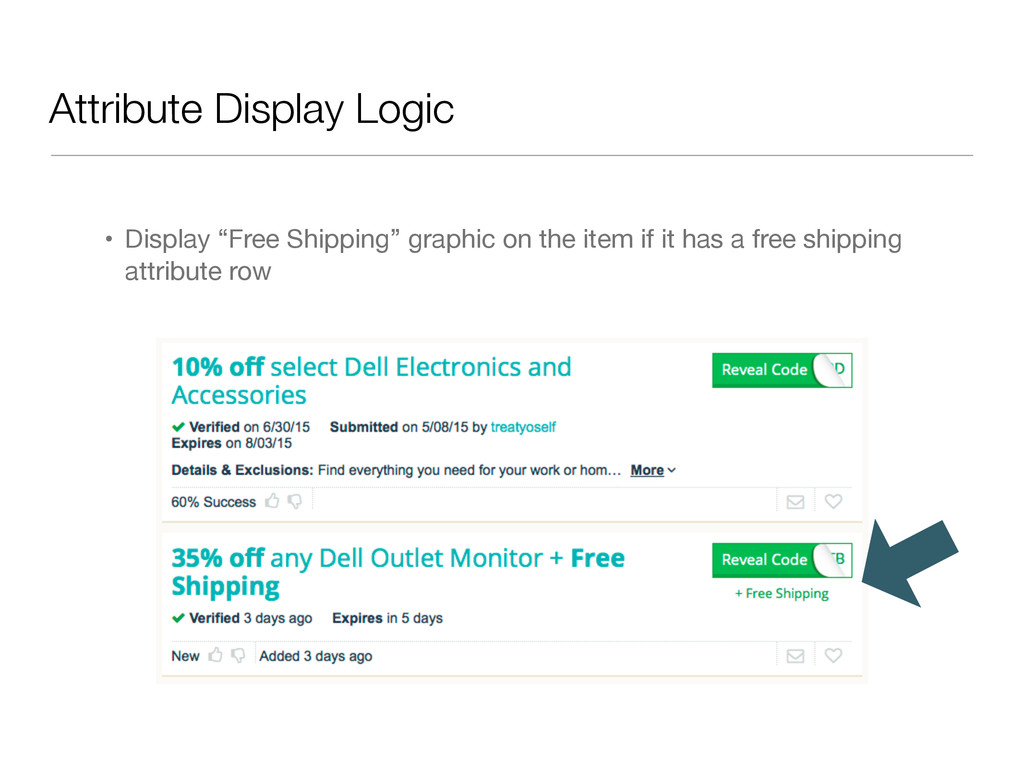
{ return $this->redis->sismember(“item:$this->id:attributes”, $name); } public function addAttribute($name, $value) { //traditional mysql stuff here still $this->redis->sadd('item:$this->id:attributes', $name); } public function deleteAttribute($name) { //traditional mysql stuff here $this->redis->srem(‘item:$this->id:attributes’, $name); } }
will scale this solution for you on it’s own • Frequently updating your items kills the MySQL query cache • Checking existence of a set member is O(1) time • On a mid-range laptop, I can check roughly 10,000 attributes per second
a user do something N number of times • This becomes more complex when you add a time window to that constraint • We can use key expirations in Redis to help with this
on things • Facebook like? • You probably want to store this 2 ways • in MySQL for reporting, long term aggregation, etc • something faster so your website will actually work
Offload your intensive workloads to some other process • Blocking I/O allows you to easily build long-running daemons • Be aware of scale tradeoffs vs. data availability
really cool here // throw an exception on error } // process all pending jobs $q = new Queue(‘email_confirmations’); while ($job = $q->pop()) { try { processJob($job); } catch (Exception $e) { echo “error processing job”; $q = new Queue(‘errors’); $q->push($job); } }
really cool here // throw an exception on error } // keep processing jobs as they become available $q = new Queue(‘test_queue’); while ($job = $q->pop(true)) { try { processJob($job); } catch (Exception $e) { echo “error processing job”; $q = new Queue(‘errors’); $q->push($job); } }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
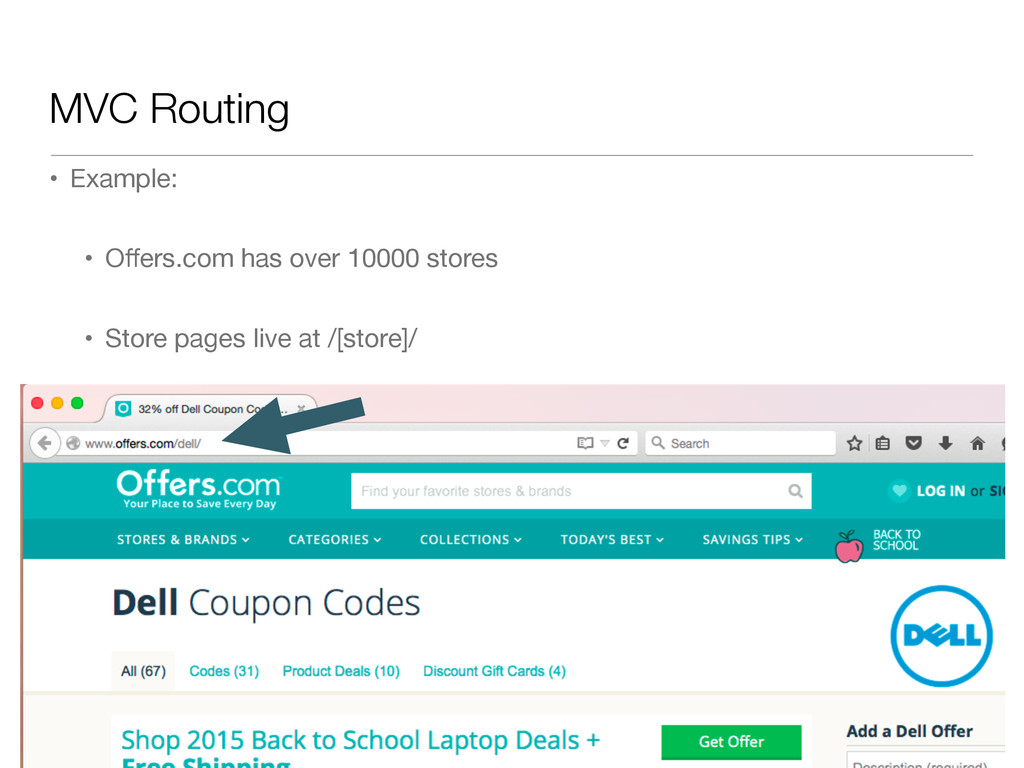
![Advantages • I can now create offers.com/[anything]/ and route it](https://files.speakerdeck.com/presentations/b10cbb11b4534c8685978be1adc3f0f6/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Most Popular [insert widget here] • Everyone likes to vote](https://files.speakerdeck.com/presentations/b10cbb11b4534c8685978be1adc3f0f6/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}