opinions • There are many different ways to do things • If I trash your favorite, we can still be friends • Why am I even qualified to talk about this? 4
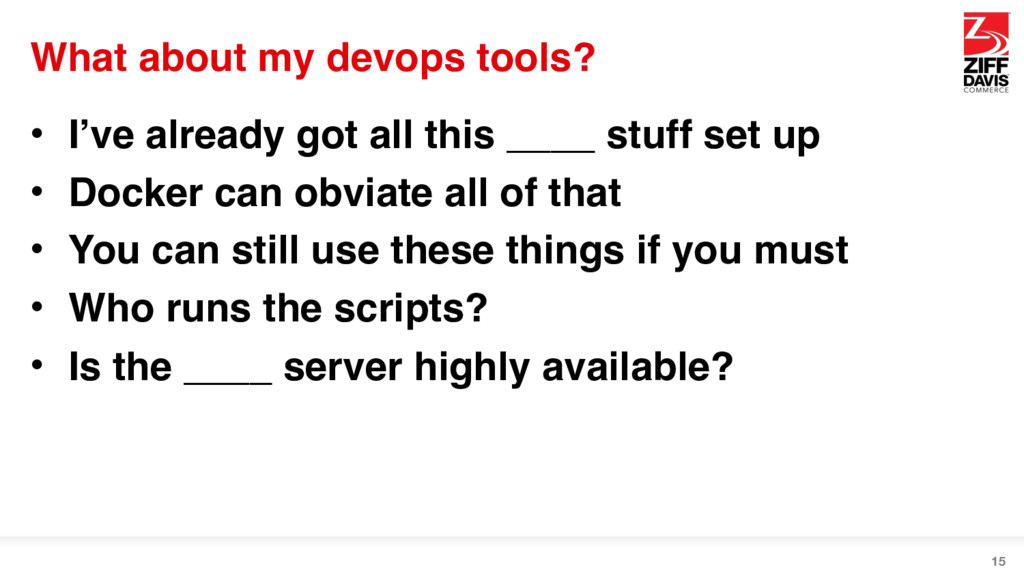
this ____ stuff set up • Docker can obviate all of that • You can still use these things if you must • Who runs the scripts? • Is the ____ server highly available? 15
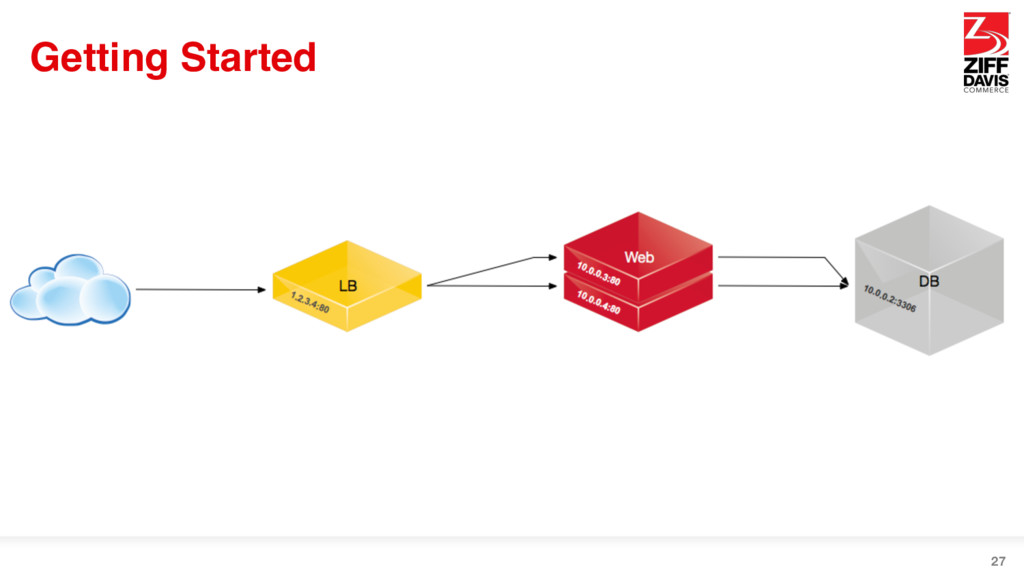
This is not a Docker talk, I promise • Containers breed immutable, repeatable infrastructure • Immutable infrastructure is disposable and replaceable • Containers breed 12-factor apps • 12-factor apps are modular enough to facilitate true HA 22
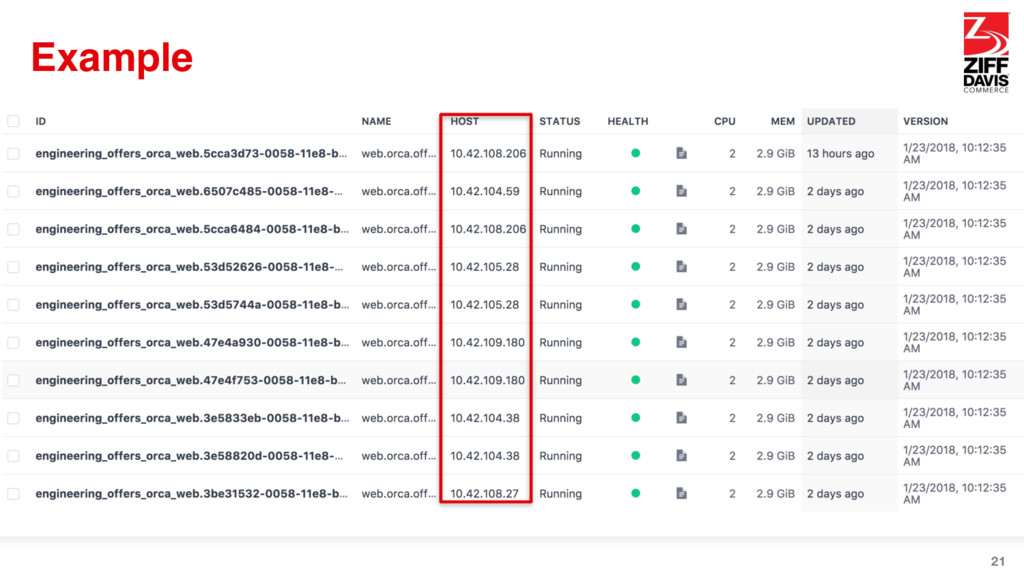
registry of what servers are where • Your code connects to these instead of using a config file • Even if you had to update it manually, it’d be faster than deploying 38
takes approximately 10ms • If you have to look up DB, Cache, ElasticSearch, SMTP, etc, it adds up • Try to organize services by logical application, so you can query for a whole namespace at once 41
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Now IP addresses are broken 28 $clientIp = $_SERVER['REMOTE_ADDR']; //](https://files.speakerdeck.com/presentations/8cad3acfe9854691867795a6d3e3c0ff/slide_27.jpg){kind=link}
![Lets fix IPs 29 $clientIp = 0; if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) {](https://files.speakerdeck.com/presentations/8cad3acfe9854691867795a6d3e3c0ff/slide_28.jpg){kind=link}
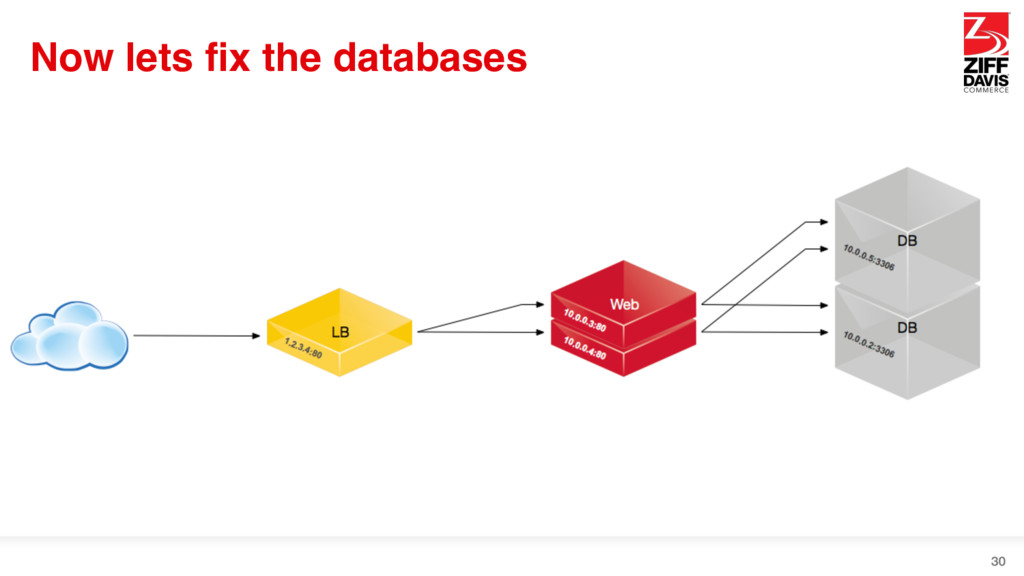{kind=link}
![App Considerations 31 $dbs = ["db1.site.com", "db2.site.com", "db3.site.com"]; $slaveNum =](https://files.speakerdeck.com/presentations/8cad3acfe9854691867795a6d3e3c0ff/slide_30.jpg){kind=link}
![Better Version 32 $dbs = ["db1.site.com", "db2.site.com", "db3.site.com"]; $slaveNum =](https://files.speakerdeck.com/presentations/8cad3acfe9854691867795a6d3e3c0ff/slide_31.jpg){kind=link}
{kind=link}
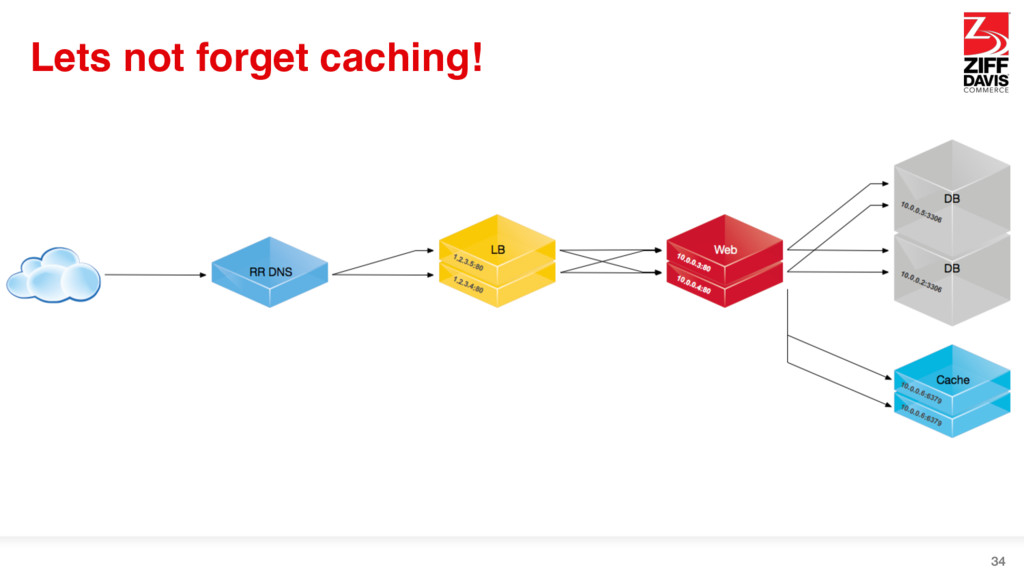{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
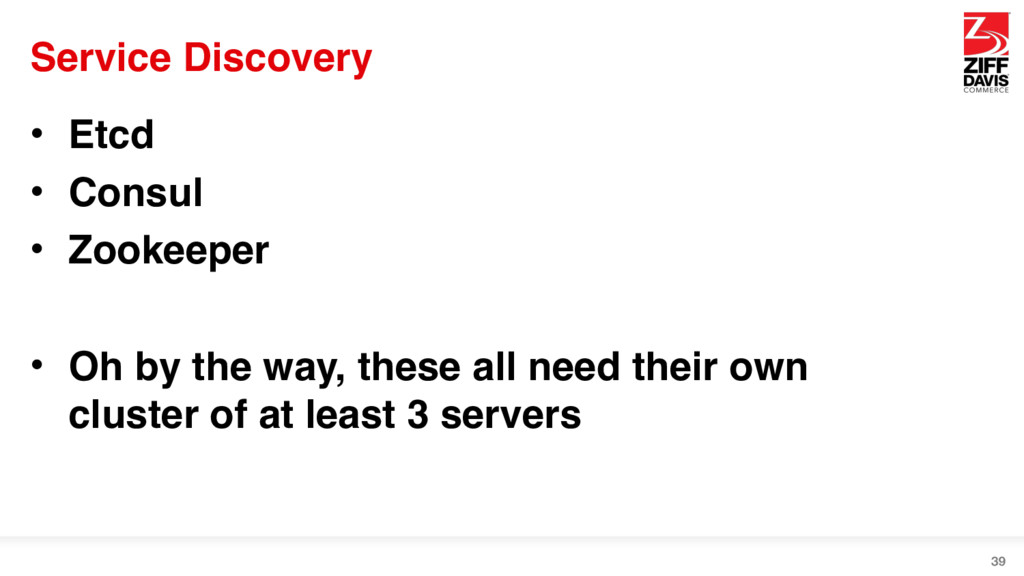{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}