Data Science – Big Data “El Cuarto Paradigma de la Ciencia está basado en computación intensiva sobre grandes colecciones de datos”. MicrosoC Research, 2009 hGp://research.microsoC.com/en-‐us/collabora9on/fourthparadigm/ "... mankind created 150 exabytes (billion gigabytes) of data in 2005... ...This year, it will create 1,200 exabytes... ...Analysing it, to spot paRerns and extract useful informa,on, is harder s,ll... ...data deluge is already star,ng to transform business, government, science and everyday life. ...” "The Data Deluge", The Economist, Feb 25th 2010 “Inicia,va para Big Data I+D” para mejorar la capacidad del país para extraer conocimiento y visiones de colecciones de datos grandes y complejas, para contribuir a resolver algunos de los retos más acuciantes de la nación The Obama Ini9a9ve, Mar 2012
¿Qué es Big Data? de contenidos compar,dos en Facebook por mes 30 billones millones de llamadas al día en Colombia 200 millones en EEUU ,enen más datos por empresa que la Biblioteca del Congreso (250 Terabytes) 15/17 sectores industriales de imágenes en los herbarios de Colombia 1 millón crecimiento global proyectado de datos generados por año 40% un secuenciador Illumina 1 TB/día por año generados por el LHC 15 petabytes 40 TB/día generados por el LSST, Chile
Big Data • manejo de datasets de tamaño >> capacidad de las herramientas tradicionales de bases de datos • según la tecnología avanza con el 9empo, el tamaño de los conjuntos de datos a los que denomina el término también crecerán, si cabe, a un aún ritmo mayo • Requiere nuevo modelo (no sirven BBDD tradicionales, paquetes estadís9cos/visualización desktop) • Obje9vo à Escalabilidad «trivial»
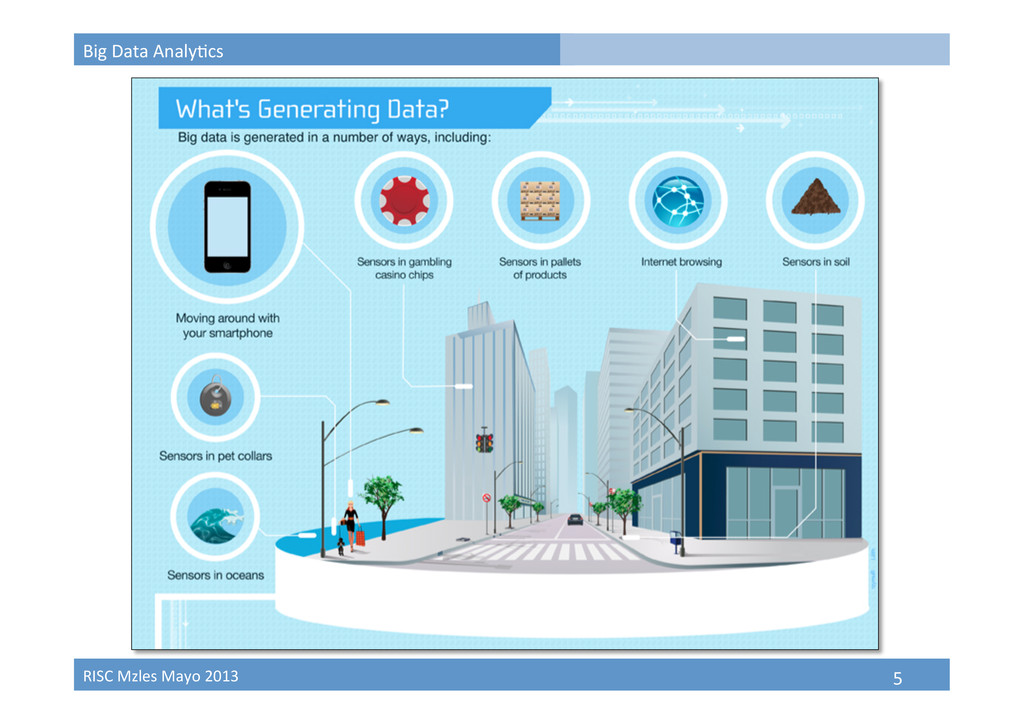
Fuentes de Big Data simulaciones históricos de consumo redes sociales bancos de documentos web logs sensores medioambientales, electrónicos, … datos biológicos adquisición de imágenes ciencia industria mobile devices transacciones financieras registros de pacientes ¿cuántas transacciones ,ene su compañía al año? gobierno
Tipos de Big Data imágenes video texto audio mul,modal real ,me data kilo 103 1.000 (mil) 1795 mega 106 1.000.000 (un millón) 1960 giga 109 1.000.000.000 (un billón) 1960 tera 1012 1.000.000.000.000 (un trillón) 1960 peta 1015 1.000.000.000.000.000 (un cuatrillón) 1975 exa 1018 1.000.000.000.000.000.000 (un quin,llón) 1975 registros, datos estructurados datos no estructurados
Límites del acceso de datos tradicional grep 1MB en 1 seg grep 1GB en 1 min grep 1TB en 1 día grep 1PB en 1 año Cp 1MB en 1 seg Cp 1GB en 1 min, 1 USD Cp 1TB en 1 día, 1K USD Cp 1PB en 1 año, 1M USD necesitas desarrollar índices, procesamiento en paralelo, etc.
• DBA à aprende a tratar con datos no estructurados • Estadís9co à aprende a tratar con información que no cabe en memoria • Ingeniero sw à aprente modelado estadís9co y a comunicar los resultados a los expertos del dominio • Experto de un dominio à aprende algoritmos y los compromisos según aumenta la escala de tu problema El camino hacia big data
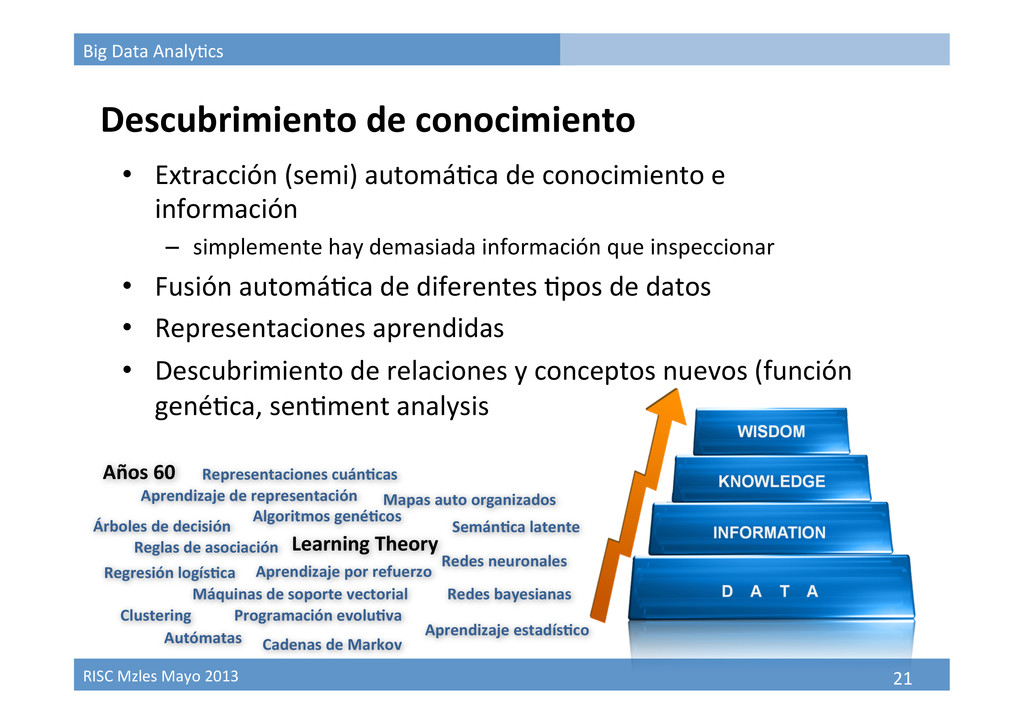
Descubrimiento de conocimiento • Extracción (semi) automá9ca de conocimiento e información – simplemente hay demasiada información que inspeccionar • Fusión automá9ca de diferentes 9pos de datos • Representaciones aprendidas • Descubrimiento de relaciones y conceptos nuevos (función gené9ca, sen9ment analysis) • Tres Vs: – Volumen – Variedad – Velocidad
• Extracción (semi) automá9ca de conocimiento e información – simplemente hay demasiada información que inspeccionar • Fusión automá9ca de diferentes 9pos de datos • Representaciones aprendidas • Descubrimiento de relaciones y conceptos nuevos (función gené9ca, sen9ment analysis) • Tres Vs: – Volumen – Variedad – Velocidad Descubrimiento de conocimiento
Descubrimiento de conocimiento Árboles de decisión Reglas de asociación Redes neuronales Algoritmos gené,cos Programación evolu,va Máquinas de soporte vectorial Clustering Aprendizaje por refuerzo Aprendizaje de representación Semán,ca latente Autómatas Regresión logís,ca Aprendizaje estadís,co Redes bayesianas Cadenas de Markov Mapas auto organizados Representaciones cuán,cas Learning Theory Años 60 • Extracción (semi) automá9ca de conocimiento e información – simplemente hay demasiada información que inspeccionar • Fusión automá9ca de diferentes 9pos de datos • Representaciones aprendidas • Descubrimiento de relaciones y conceptos nuevos (función gené9ca, sen9ment analysis
Más de 2.5 millones de suscriptores Datos históricos de consumos mensuales de más de 5 años Problema: proceso de detección de anomalías con alto número de falsos posi,vos y falsos nega,vos costos adicionales por inspecciones innecesarias, pérdidas por consumos no facturados! Pregunta: Cómo determinar con alta fiabilidad si un consumo par9cular es anómalo o no. Solución: construcción de un modelo predic9vo para determinación de anomalías basado en técnicas de big data analy9cs Resultados: Un modelo predic9vo para la detección de anomalías, reducción sustancial de falsos posi9vos y nega9vos Una metodología para comparar obje9vamente diferentes modelos de detección de anomalías Proyecto reciente, empresa de servicios Colombia
Tecnologías YA disponibles cassandra hadoop hbase virtual box kvm google apps amazon cloud ms azure hyper-‐v open nebula map-‐reduce machine learning noSQL tag cloud history flow clustergrams spa,al/map info clouds privadas servicios modelos y teorías aplicaciones y frameworks visualización high speed networks mul,cores GPUs large storage hardware eucalyptus mongo db BIGS mahout Big Table
Bases de datos NoSQL • Expresividad SQL vs. Escalabilidad • Tablas: filas de keys + lista no fija de columnas/valores • Operaciones simples: Scan por key Acceso directo por key Transacciones mínimas (check&put) No joins, no SQL language • Big table, Hbase, DynamoDB, Azure, Cassandra, etc.
oportunidades par,cipar en los nuevos modelos de negocio nuevas capacidades para desarrollar productos nueva forma de organizaciones las decisiones se basarán cada vez más en predicciones analí,cas explotar el valor de los datos personales nuevas relaciones con el cliente capturar datos y productos personalizados dirigidas por los datos
oportunidades par,cipar en los nuevos modelos de negocio nuevas capacidades para desarrollar productos nueva forma de organizaciones las decisiones se basarán cada vez más en predicciones analí,cas explotar el valor de los datos personales riesgos pérdida de compe,,vidad incapacidad de descubrir patrones, conceptos, comportamientos de nuestro propio dominio inaccesibilidad a nuevas reglas de mercado nuevas relaciones con el cliente capturar datos y productos personalizados dirigidas por los datos fundamento básico para las organizaciones
modelos de proyectos procesos de decisión y análisis formación de equipos mu,disciplinares arquitecturas de TI retos diseñar / adaptar nuevas subestructuras organizacionales modelos predic,vos, múl,ples fuentes de datos expertos del dominio/negocio, ingenieros, estadís,cos gran escala, escalabilidad trivial, nubes privadas, públicas, …
está empezando a parecerse a la ciencia adquisición de muchos datos necesidad de modelos predic,vos necesitan Data Scien-sts en la industra facebook, google, transacciones, etc. detección de fraude, customer paRerns, etc. data munging + estadís,ca + sistemas ….
Formación mul,disciplinar Conclusión 1: El mundo de la computación es plano, cualquiera puede acceder. Lo que nos dis,nguirá del resto del mundo es nuestra habilidad para hacerlo mejor y explotar las nuevas arquitecturas que desarrollamos antes de que dichas arquitecturas sean universalmente usadas. Conclusión 2: La educación y formación inadecuadas de la siguiente generación de cienoficos computacionales amenaza el crecimiento global de la Ciencia e Ingeniería Basadas en Simulación. Esto es par,cularmente urgente [...]; a no ser que preparemos a los inves,gadores para desarrollar y usar la próxima generación de algoritmos y arquitecturas de computadores, no seremos capaces de explotar sus capacidades para cambiar las reglas del juego. hGp://www.wtec.org/sbes/
más información MicrosoC Research, 2009 The Fourth Paradigm: Data-‐Intensive Scien,fic Discovery hGp://research.microsoC.com/en-‐us/collabora9on/fourthparadigm/ NSF, NASA, DOE, NIH, NIST and DOD, 2009 Interna,onal Assessment of Research and Development in Simula,on Based Engineering and Science hGp://www.wtec.org/sbes European Commission, 2012 ICT infrastructures for e-‐Science hGp://europa.eu/legisla9on_summaries/informa9on_society/internet/si0006_en.htm US Office of Science and Technology, 2012 The Big Data Research and Development Ini,a,ve hGp://www.whitehouse.gov/blog/2012/03/29/big-‐data-‐big-‐deal McKinsey Global Ins9tute, 2011. Big data: The next fron,er for innova,on, compe,,on and produc,vity. hGp://www.mckinsey.com/insights/business_technology/big_data_the_next_fron9er_for_innova9on Oracle, 2012. IBM, 2012 Mee,ng the challenge of Big Data Harness the power of Big Data hGp://www.oracle.com/us/technologies/big-‐data/index.html hGp://www.ibm.com/soCware/data/bigdata/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}