This talk is a brief presentation of what is Tuenti, from the company history and structure to some fun-facts about how big we are and how much Spanish youth is using us to live their online social experience. At the end, I focus on the Backend Engineering in Tuenti and explain some general scalability aspects about how to build and evolve a web-app to sustain rapid growth.
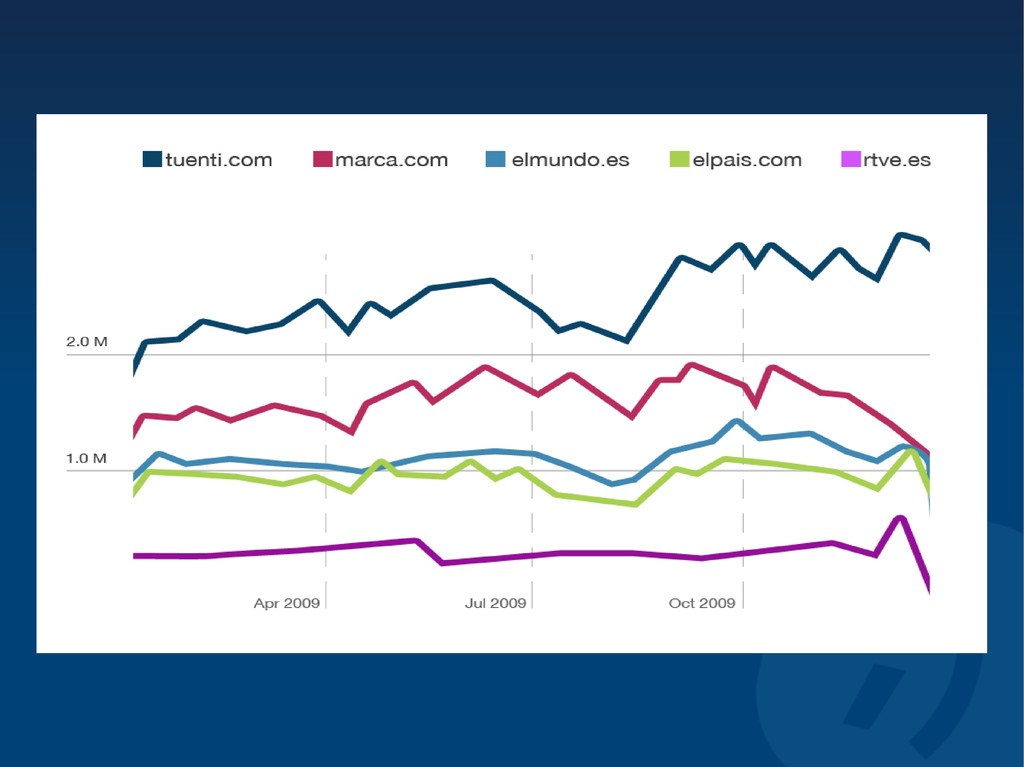
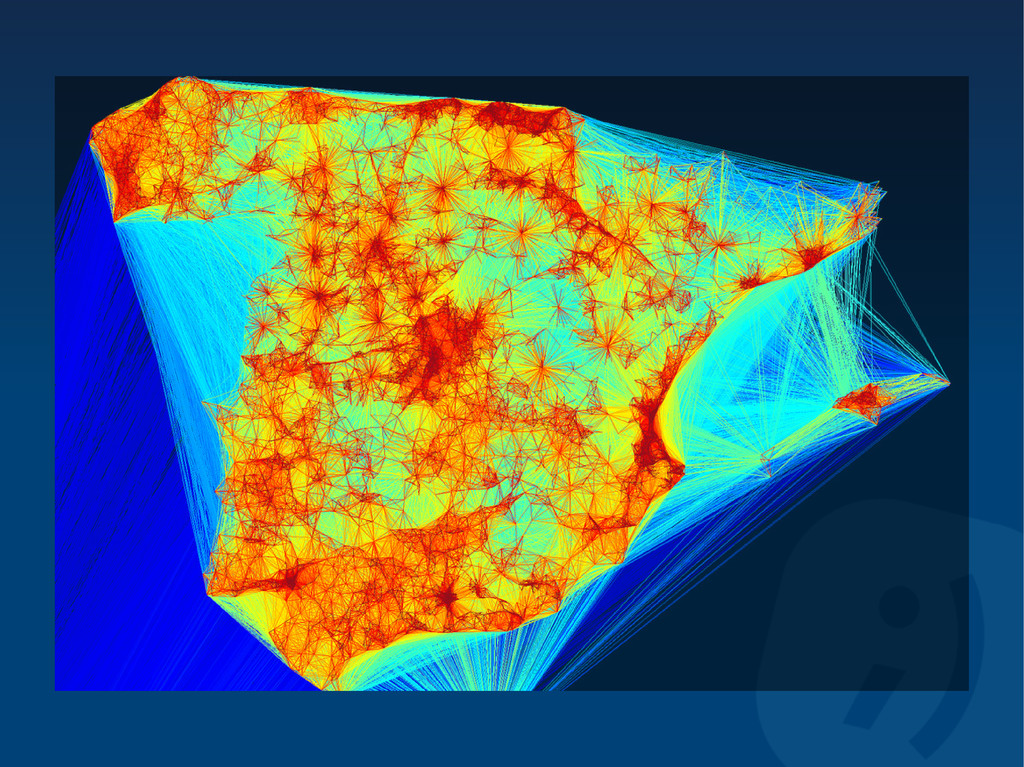
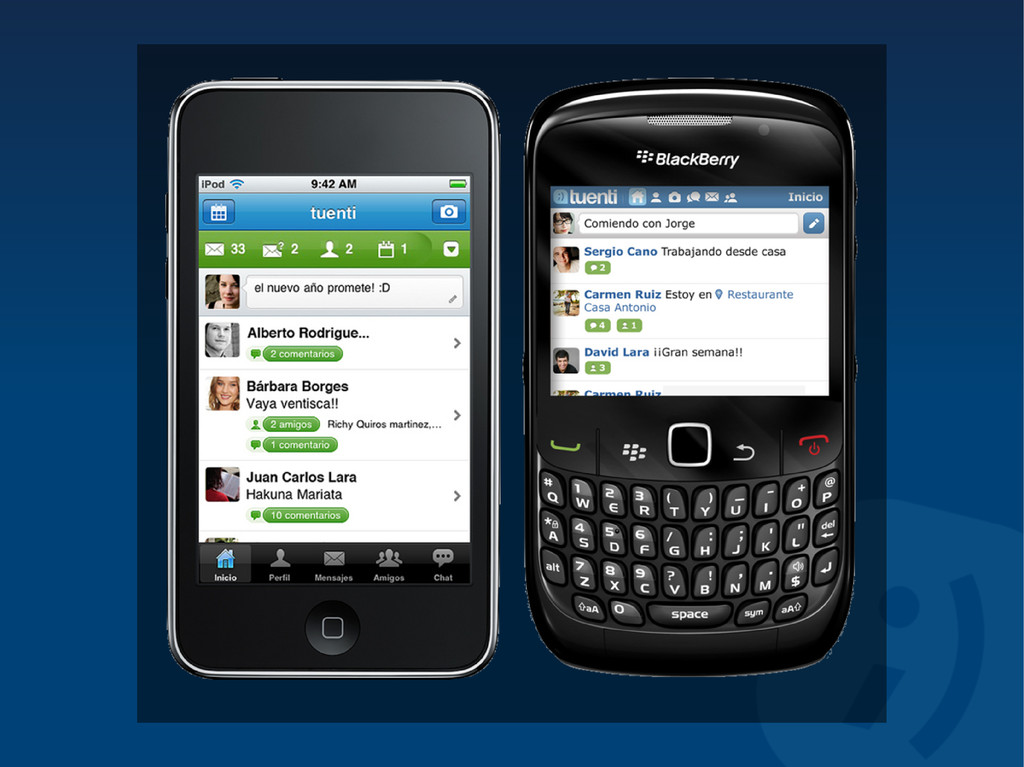
Tuenti is the leading spanish invitation-only private social networking website that has been referred to as the "Spanish Facebook". According to ComScore, it is the most trafficked website in the country, having more monthly page views in Spain than Facebook and Google combined.
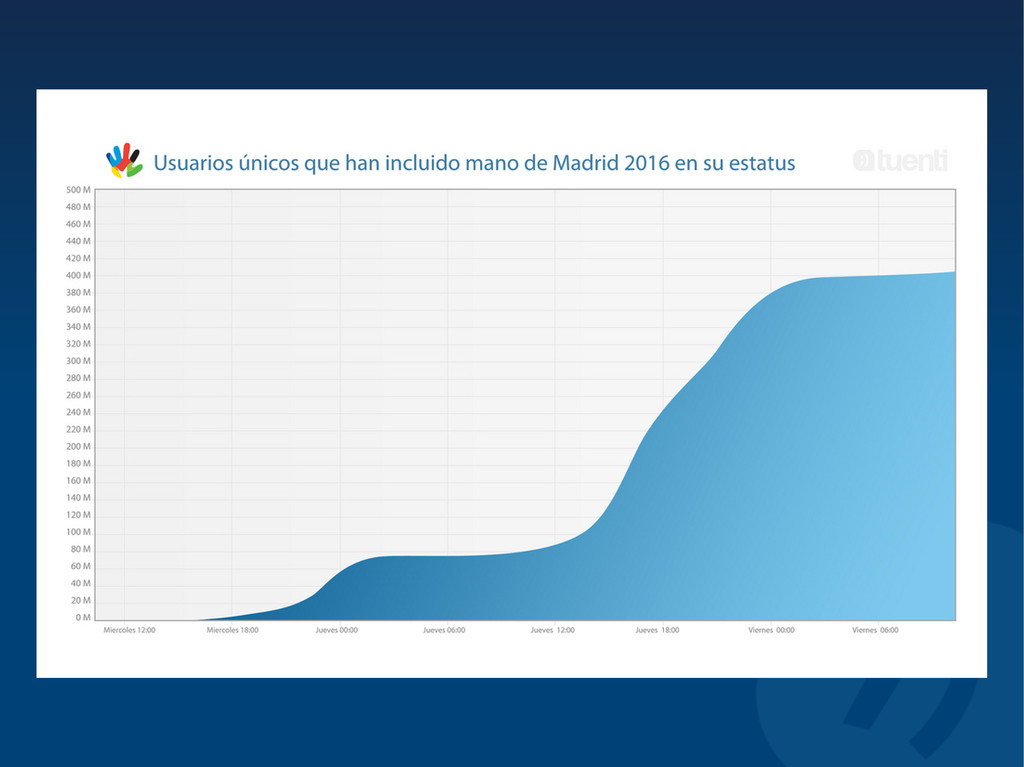
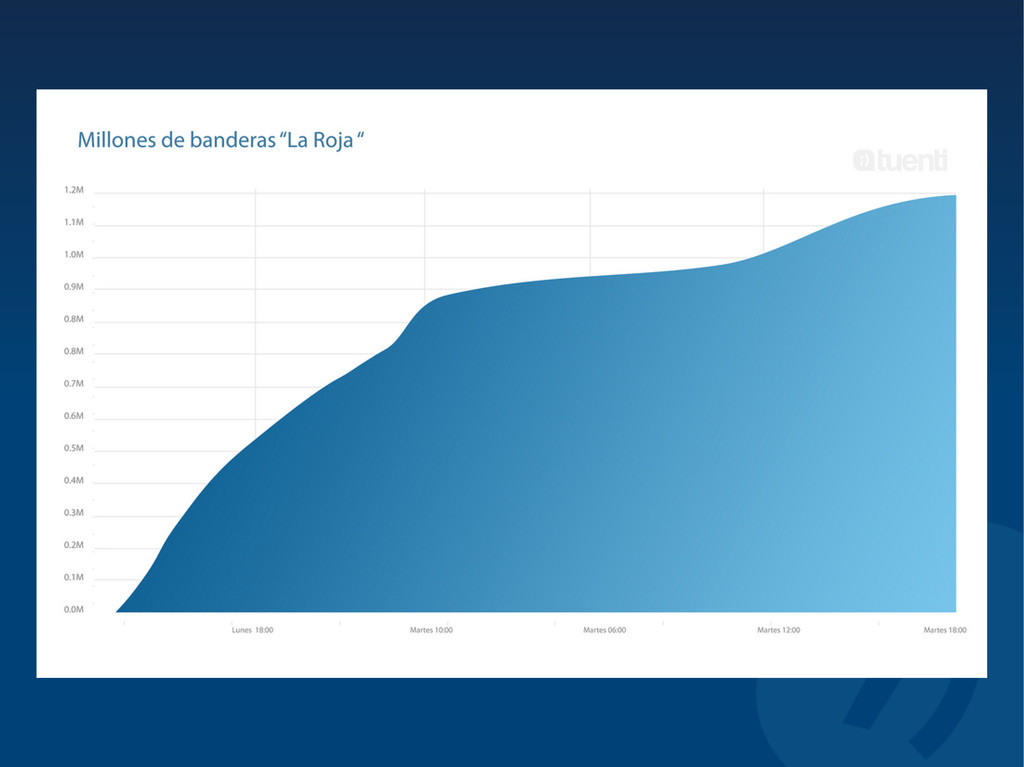
The site has rapidly grown in four years with millions of active daily users and was one of the most searched terms in Google's 2008 and 2009 Zeitgeists. We currently have more than 25 billion monthly page views and we are processing, storing and serving more than 2.5 million new photos every day (with peaks up to 5 million), with over 6 Gbps of image traffic at peak.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected] [email protected]](https://files.speakerdeck.com/presentations/4e80e0605cc0ec0063001f23/slide_70.jpg){kind=link}