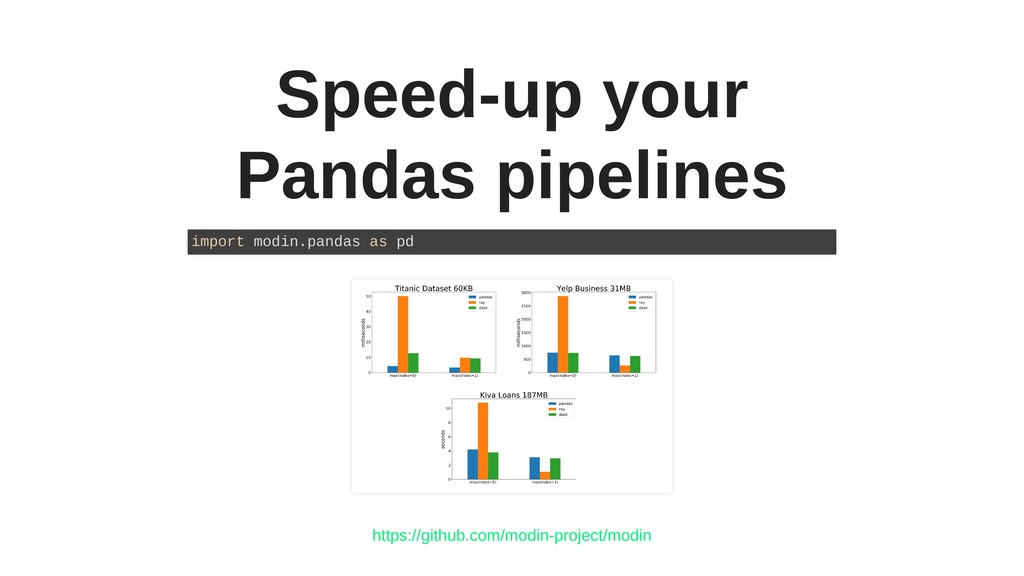
Come for a while and learn how to execute your Python computations in parallel, to seamlessly scale the training of your machine learning models from a single machine to a cluster, find the right hyper-parameters, or accelerate your Pandas pipelines with large dataframes.
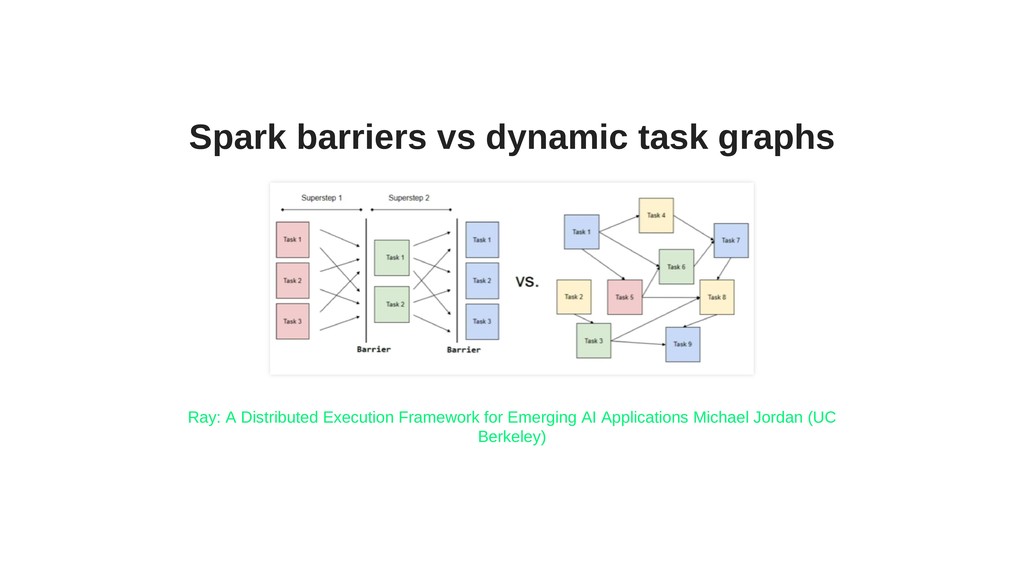
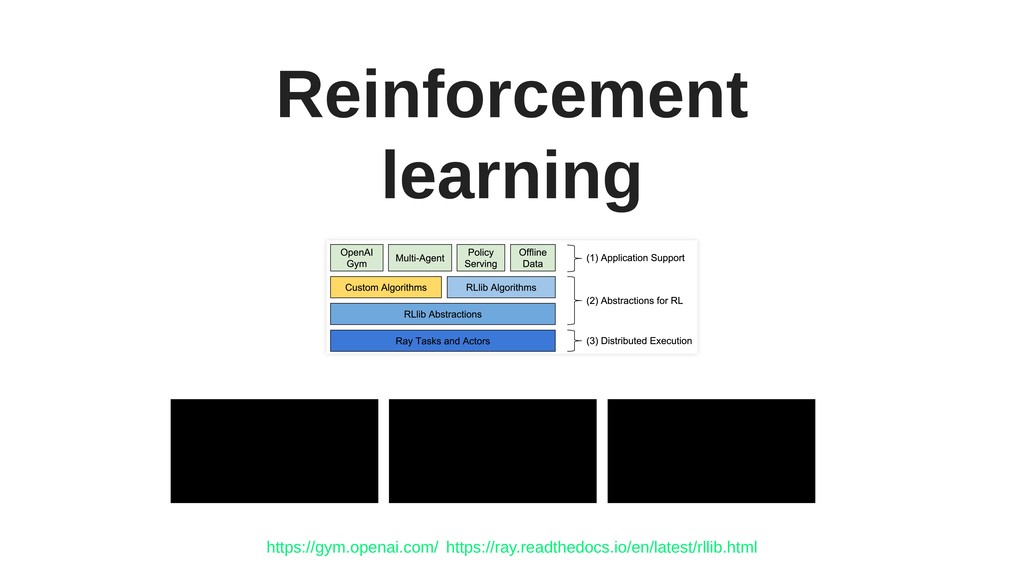
In this talk, we will cover Ray in action with plenty of examples. Ray is a flexible, high-performance distributed execution framework. Ray is well suited to deep learning workflows but its utility goes far beyond that.
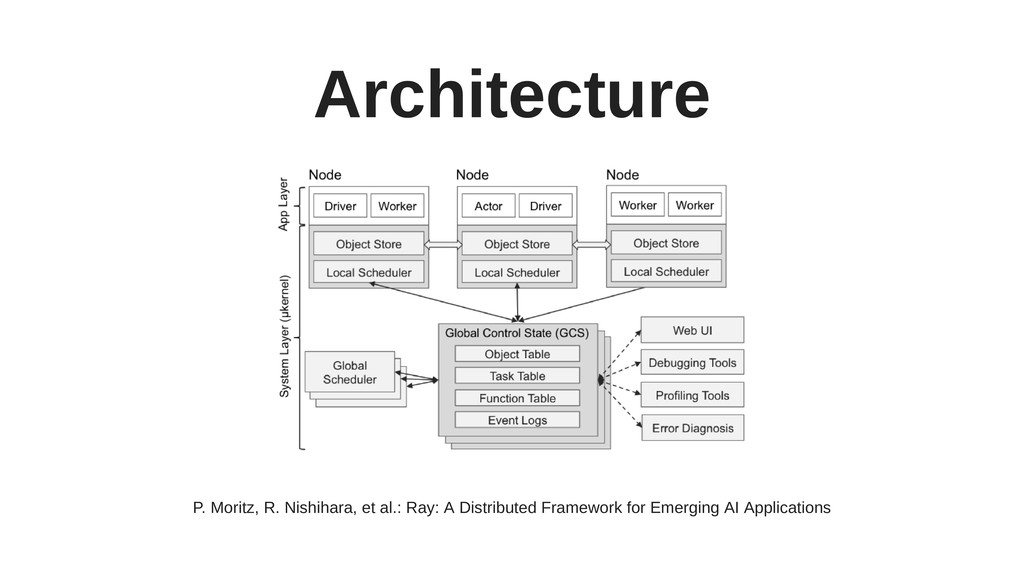
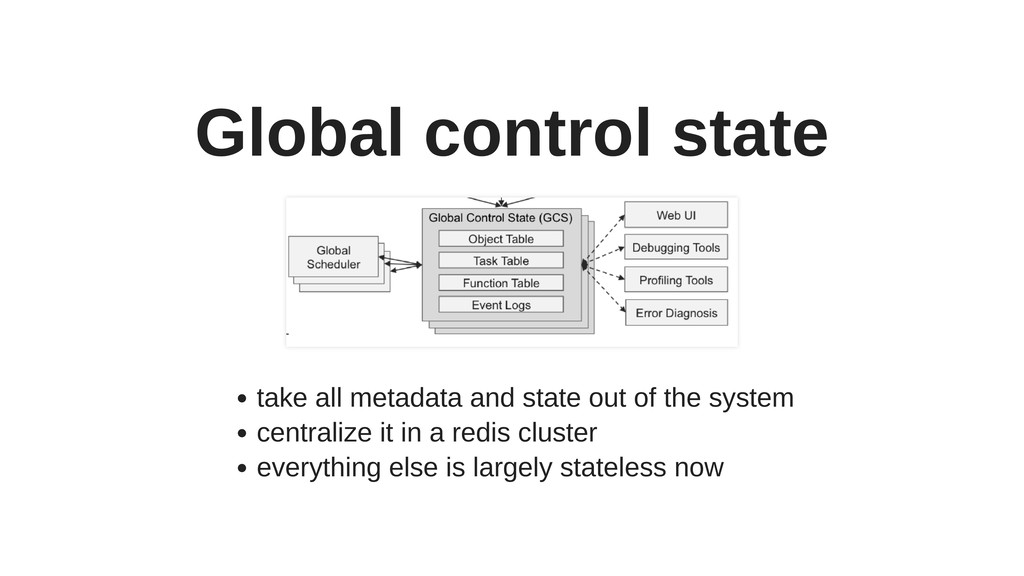
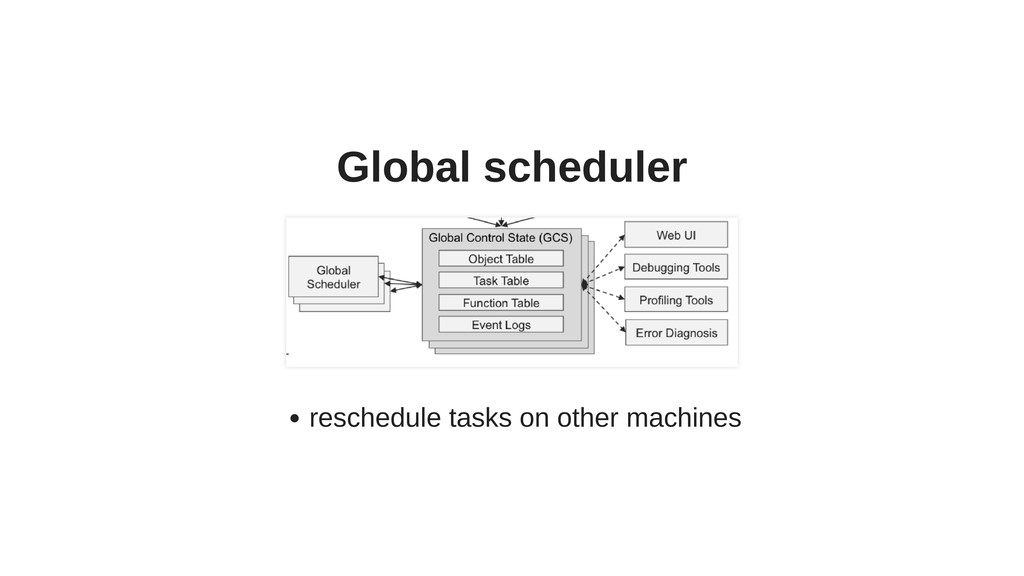
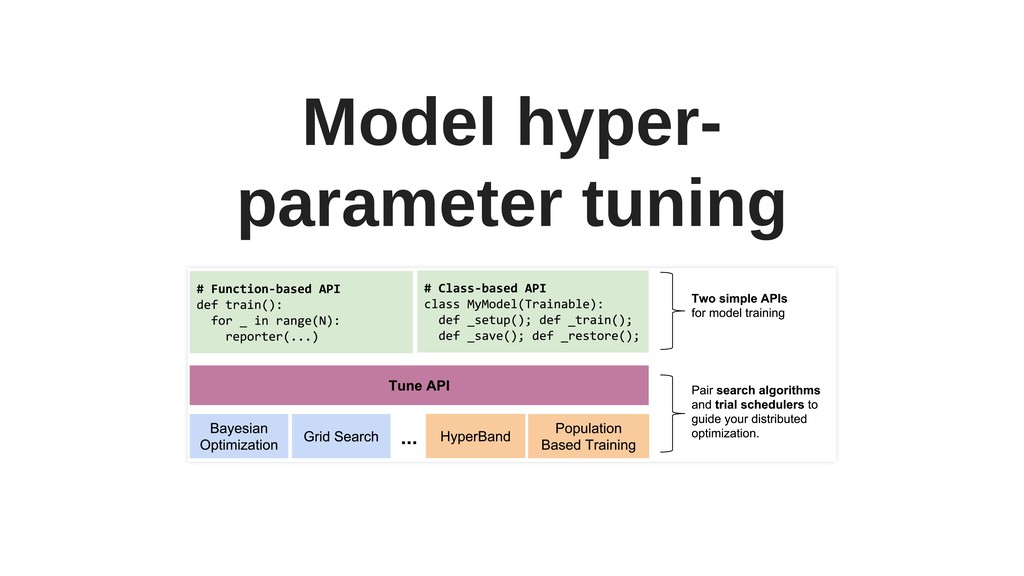
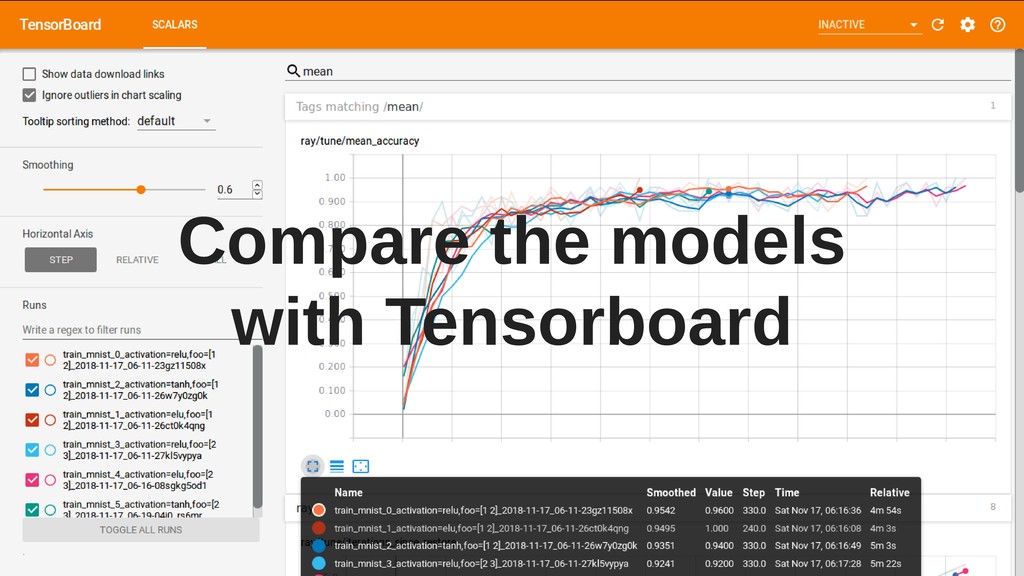
Ray has several interesting and unique components, such as actors, or Plasma - an in-memory object store with zero-copy reads (particularly useful for working on large objects), and includes powerful hyper-parameter tuning tools.
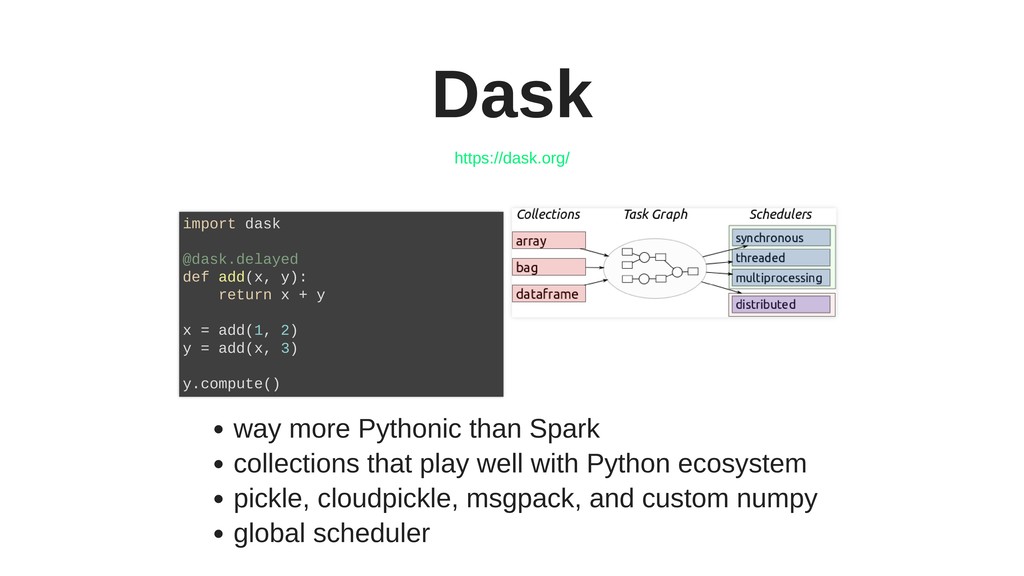
We will compare Ray with its alternatives such as Dask or Celery, and see when it is more convenient or where it might even completely replace them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}