This talk explores how writing machine learning models can become simpler and more fun with dynamic code execution. The "deep learning" paradigm is rapidly becoming "differentiable programming".
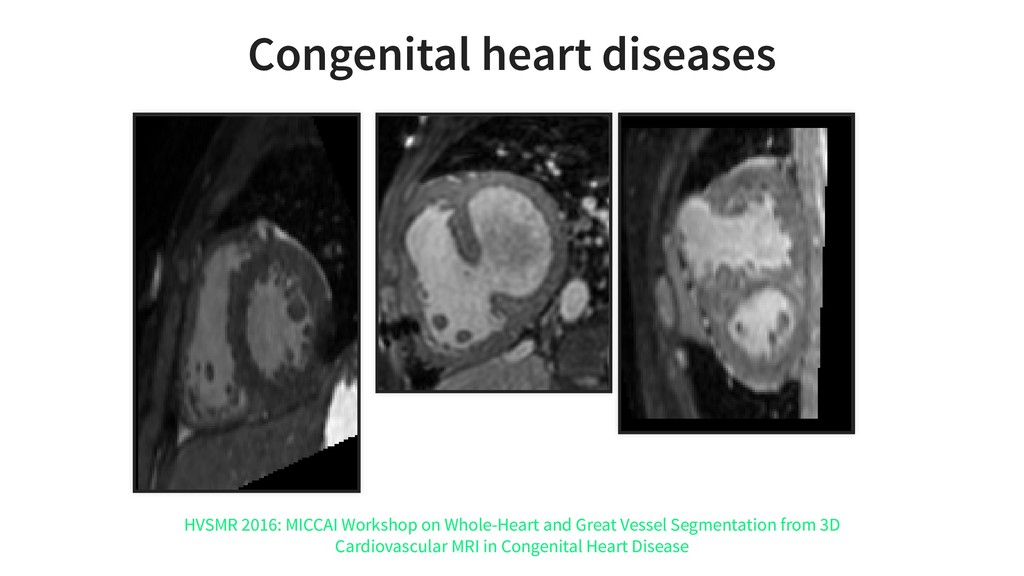
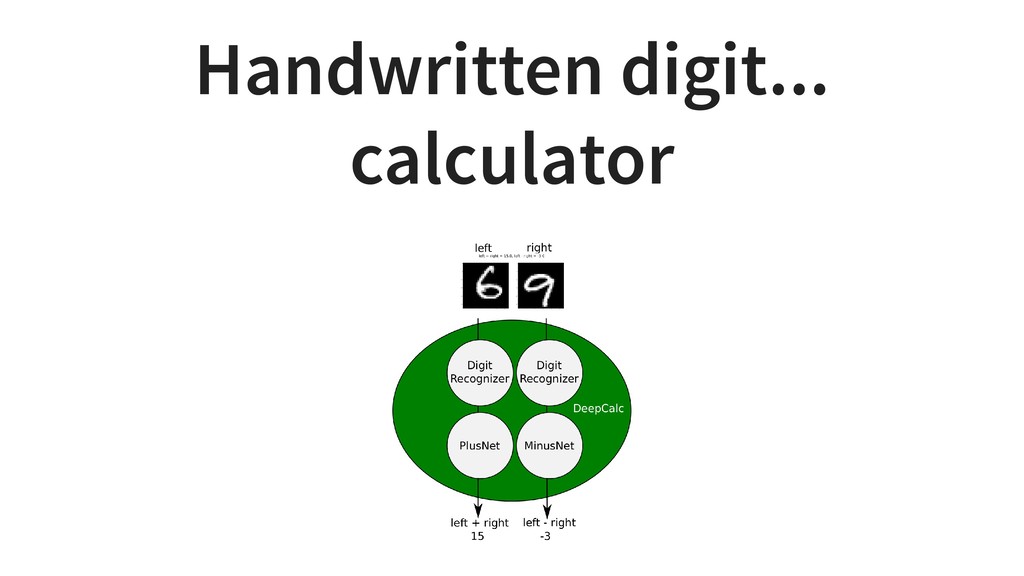
And we will see it applied to cardiac medical images and images from industrial inspection.
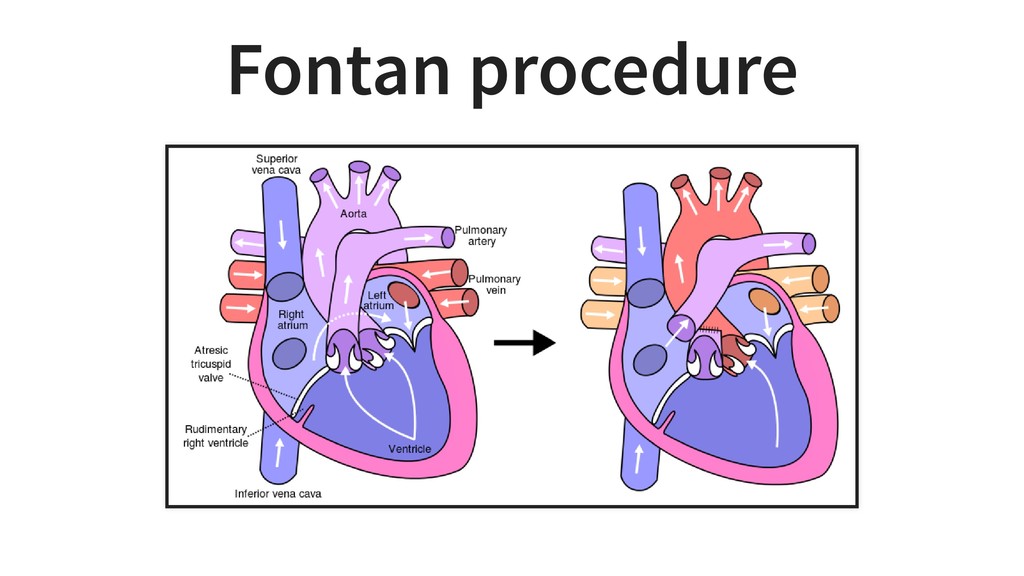
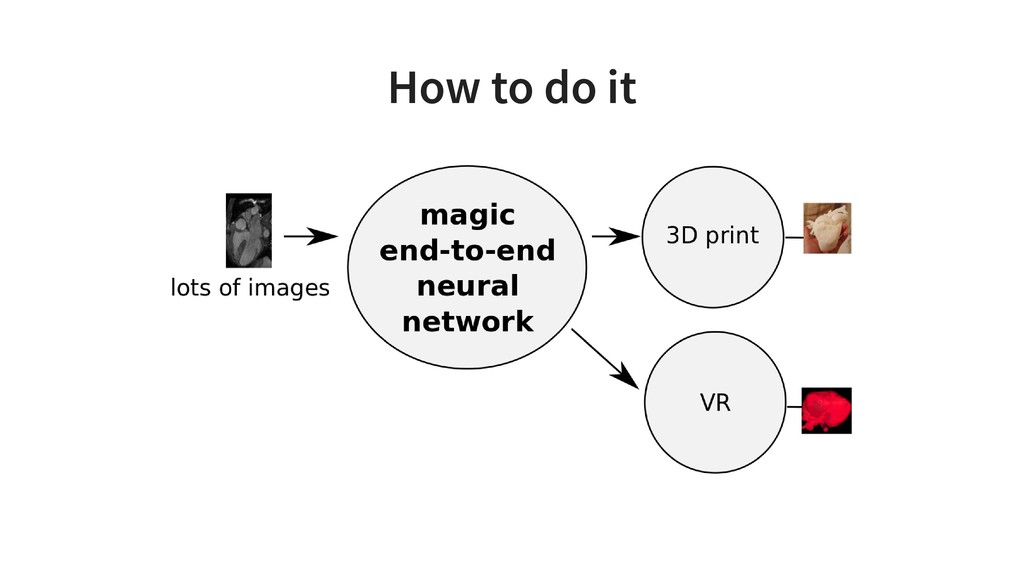
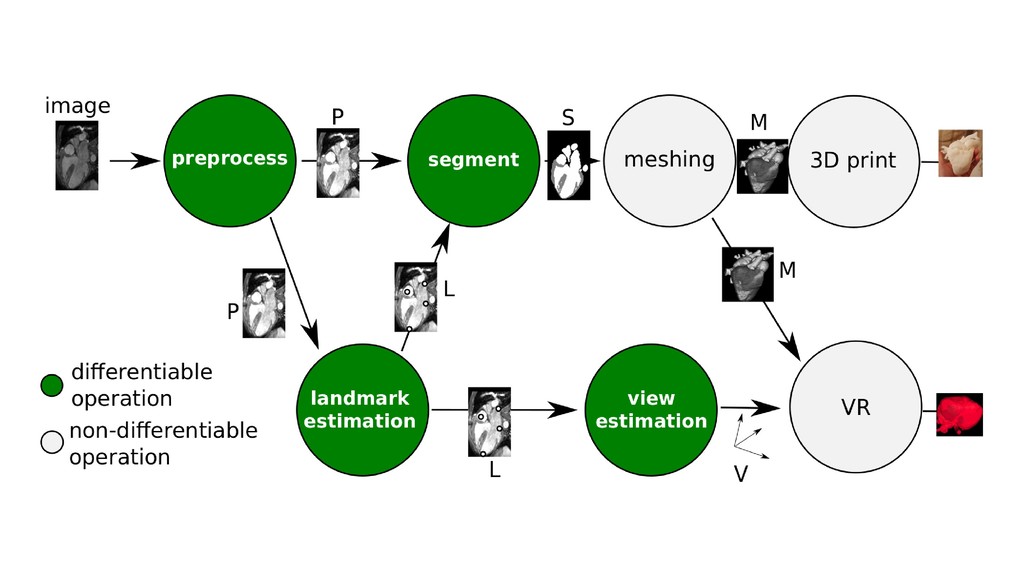
It is based on our experiences at KardioMe in making of machine learning apps for healthcare and optical inspection in manufacturing. We will have a peek into python pipelines for data preparation for creation of anatomical models for virtual reality and 3d printing.
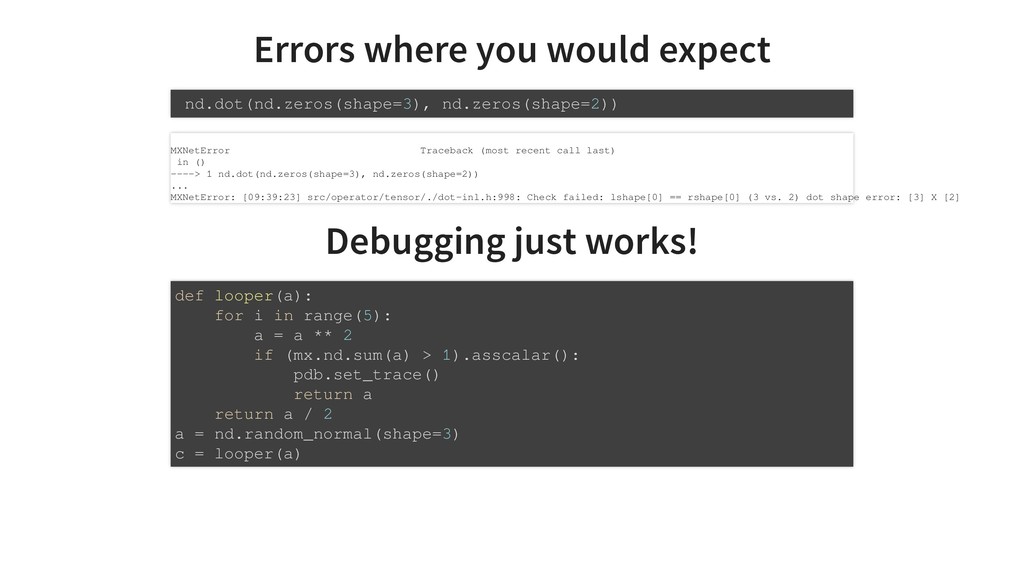
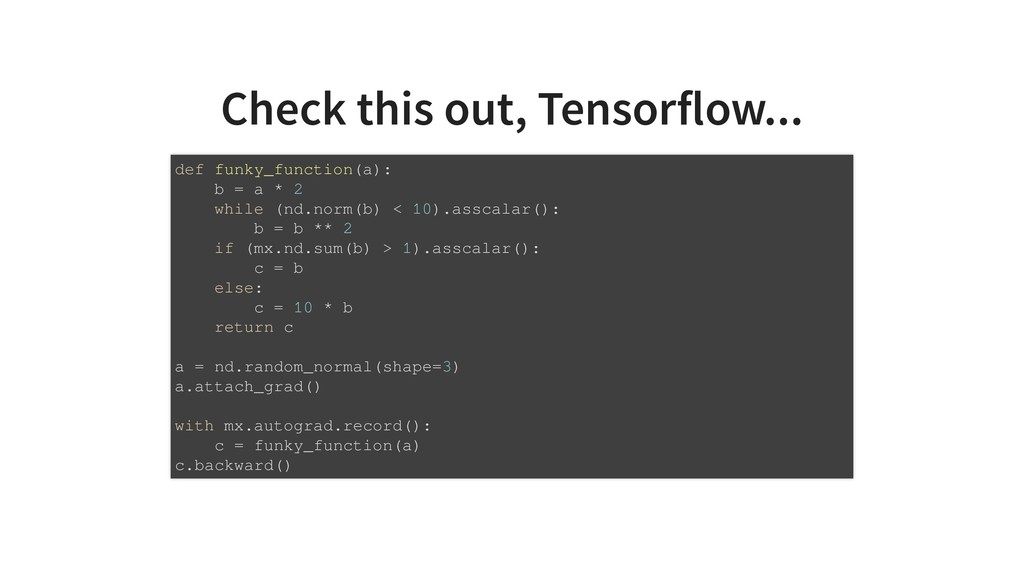
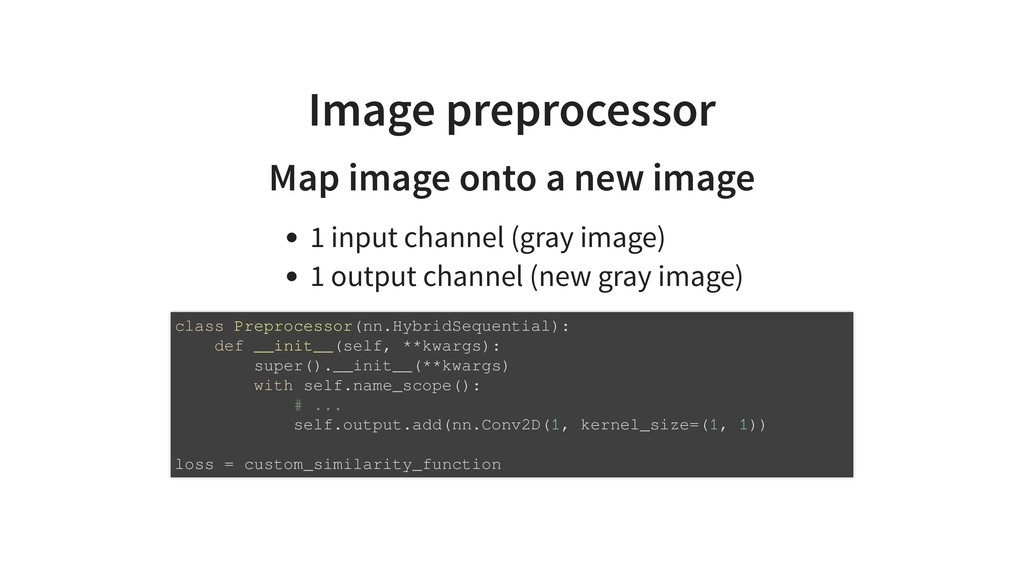
Traditional development and deployment of deep learning models often feels like stepping away from programming and what we love about Python. Simple loops and branches get replaced with special operations. Programs are written as static computation graphs which need to are compiled to optimize runtime and resource usage. Seeing intermediate results and debugging can be a pain, even with specialized tool. Tensorflow, Keras, Theano, MxNet, CNTK, they all do that.
Machine learning is all teaching computers how to solve the problems for us with data instead of explicitely telling them how to do so. It is undoubtedly a different way of thinking about programming.
Yet, it does not need to become unnecessarily complex and you certainly do not need a PhD for that.
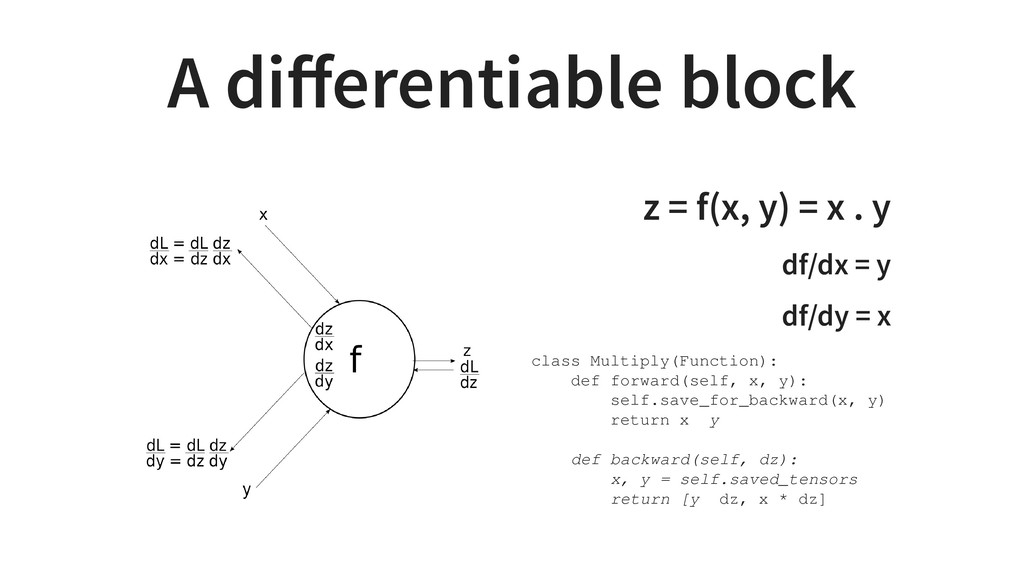
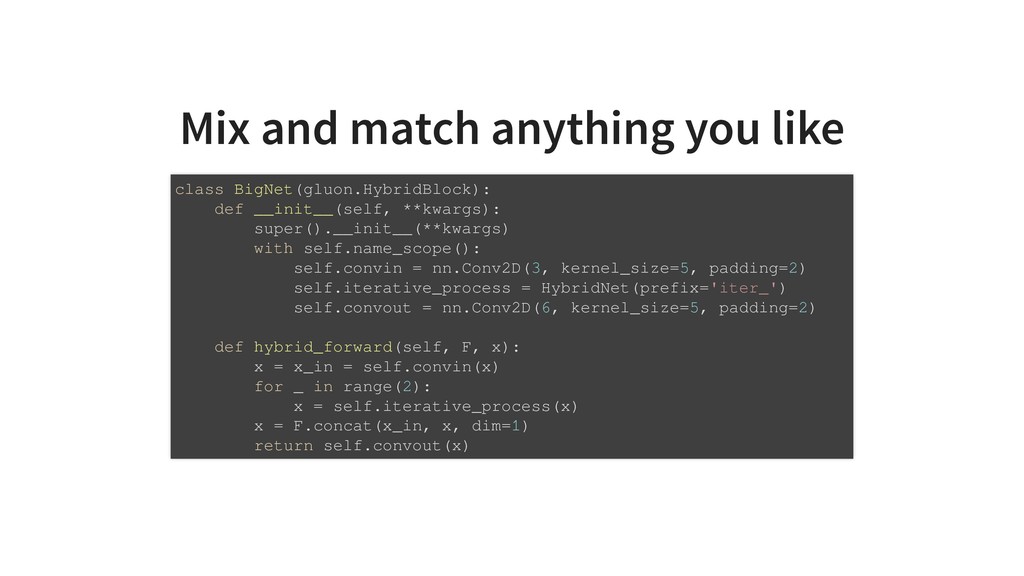
Gluon, is a new dynamic interface to MxNet and is a fenomenal tool to develop models that improve with data. The network can be written like a regular program with ifs or loops. Everything is dynamically executed and even allows step by step debugging with pdb. The program parameters are, however, trainable so that the execution output gets better with more data.
These together are massive helpers in faster experimentation and more fun. In addition to that, Gluon has a large zoo of pretrained models ready for your next app and MxNet as its backend is fast and resource efficient, and can be deployed to embedded devices too.
Notebooks:
https://github.com/jmargeta/PyConSK2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [Differentiable Programming]) ( ) Neural Networks, Types, and Functional](https://files.speakerdeck.com/presentations/5f324c2125d140cd91b8f213a44b846d/slide_46.jpg){kind=link}