Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
誹謗中傷を表す文の自動検出
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2010
Research
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
誹謗中傷を表す文の自動検出
石坂 達也, 山本 和英. 誹謗中傷を表す文の自動検出. NLP若手の会 第5回シンポジウム, (発表14) (2010.9)
自然言語処理研究室
March 31, 2010
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
560
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
660
typst の使い方:言語学を研究する学生のために
gitomochang
0
510
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
230
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.7k
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
210
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
360
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.4k
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Featured
See All Featured
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Building the Perfect Custom Keyboard
takai
2
810
Between Models and Reality
mayunak
4
370
Transcript
誹謗中傷を表す文の自動検出 長岡技術科学大学 石坂 達也, 山本 和英
1 Web上には他者を誹謗中傷する書き込みがある ネットいじめと呼ばれる社会問題となっている 最悪の場合, 自殺を引き起こしている 背景と目的 Web上の誹謗中傷の自動検出
目的 現状 人手による巡回 負担が大きい
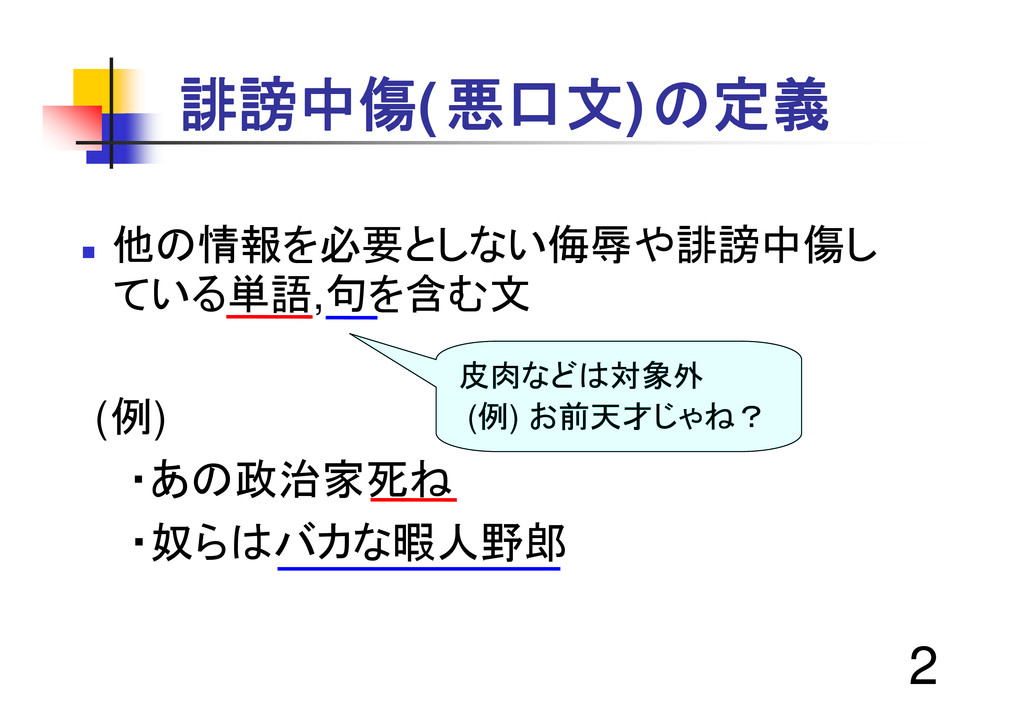
2 他の情報を必要としない侮辱や誹謗中傷し ている単語,句を含む文 (例) ・あの政治家死ね ・奴らはバカな暇人野郎 誹謗中傷(悪口文)の定義 皮肉などは対象外 (例)
お前天才じゃね?
3 手法の方針 評価情報を分析するための手法を引用する ある単語が好評表現/不評表現かの判定する手法 単語が悪口単語/非悪口単語かを判定して文分類 引 用 誹謗中傷文は悪口単語の影響が大きい
誹謗中傷は人への評価ともいえる
4 SO-PMI Algorithmを使用 単語の悪口度計算 ) ( ] [ log
) ( ) ( ) ( log * ) ( ) ( ) , ( ) ( ) , ( ) ( 2 2 α α α f C w SO negative hits positive hits f positive hits negative w hits negative hits positive w hits w C + = = ∗ ∗ = [Wang and Araki, 2007] negativeの 検索ヒット数 positiveの 検索ヒット数 単語wとpositiveの 検索ヒット数 重み
5 共起情報を利用して単語 の極性を判定 positiveと共起しやすいなら悪口単語 negativeと共起しやすいなら非悪口単語 検索ヒット数の差を補正するための
¾ WangらはSO-PMIを用いて好評文/不評文に分類 好評文が78%, 不評文が72%の精度で分類できた w ) ( SO-PMIの概要 α f
6 positive,negative単語の選択 評価表現を対象とする場合 positive=素晴らしい, 好き, 楽しい, 満足
negative=不良, 悪い, 欠点, 最悪 悪口単語を対象とする場合 positive=悪口単語(ウザい, 死ね, キモい) negative=悪口単語と極性が逆の単語 極性が逆の単語を使用(好評⇔不評) 悪口単語の逆とは…? 褒め言葉?非悪口単語?
7 単語の極性計算 褒め言葉を使用 可愛い, 素敵, イケメン 愚民 -3.688
派閥 -3.413 売ら -3.250 兆 -3.190 廃止 -3.162 非悪口単語を使用 机, チューリップ 消えろ -6.697 失せろ -6.667 ジャニヲタ -6.371 死ねよ -6.370 メンヘラー -6.364 悪口単語にはウザいを使用 negativeには非悪口単語を使用する 今回はとりあえず「机」で行う。
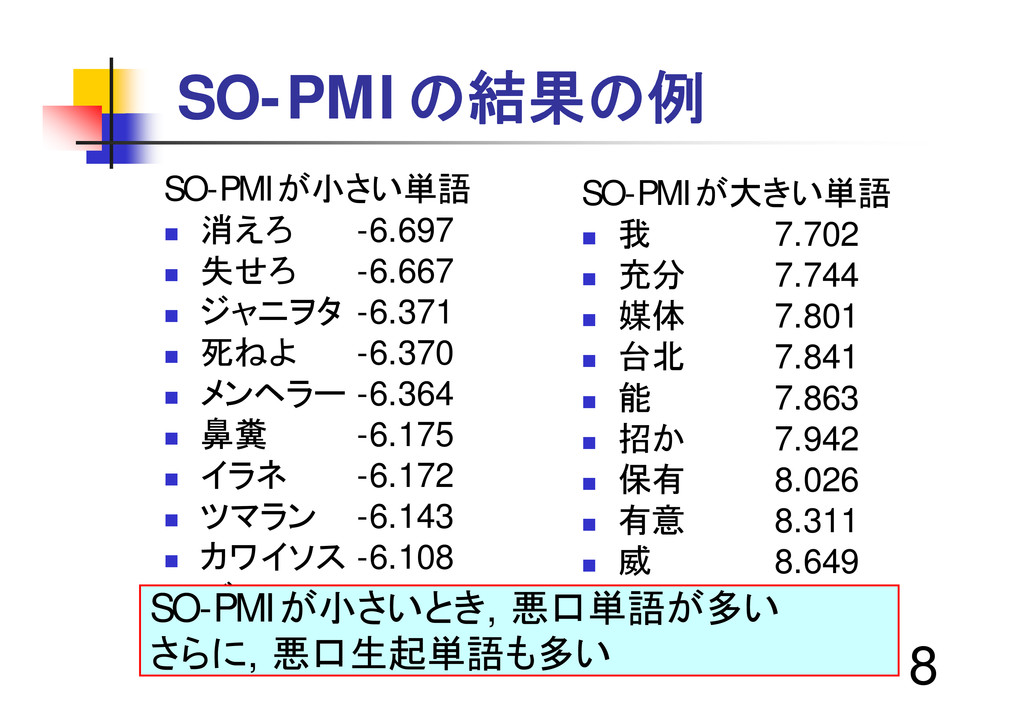
8 SO-PMIの結果の例 SO-PMIが小さい単語 消えろ -6.697 失せろ -6.667
ジャニヲタ -6.371 死ねよ -6.370 メンヘラー -6.364 鼻糞 -6.175 イラネ -6.172 ツマラン -6.143 カワイソス -6.108 バロス -6.075 SO-PMIが大きい単語 我 7.702 充分 7.744 媒体 7.801 台北 7.841 能 7.863 招か 7.942 保有 8.026 有意 8.311 威 8.649 以上 9.755 SO-PMIが小さいとき, 悪口単語が多い さらに, 悪口生起単語も多い
9 SVMを用いた分類実験 入力文が悪口文/非悪口文を判定 TinySVMを使用 学習データ&評価データ 「2ちゃんねる」から収集
被験者3人により作成 2人以上一致した評価を使用 5分割交差検定 悪口文1400文, 非悪口文1400文 ¾ 各380文は評価データとして使用
10 素性と特徴量とα 素性 文に含まれる形態素(記号除く) 特徴量 各単語のSO-PMI
α SO-PMIに使われるαによって精度が変動 αは0~1.0(0.1刻み)
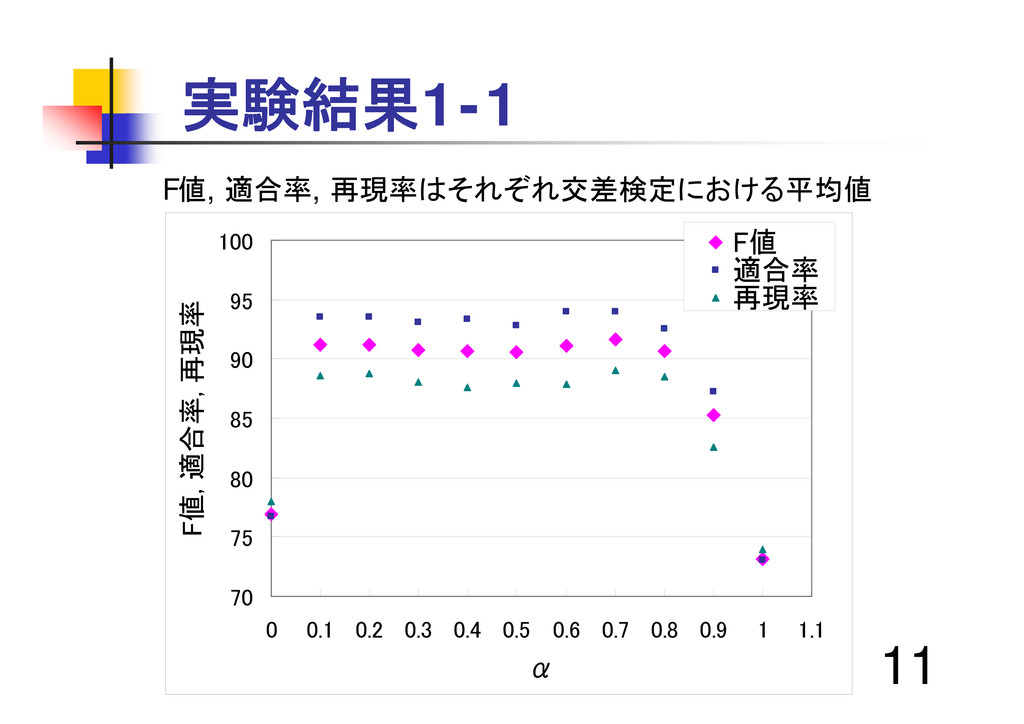
11 実験結果1-1 70 75 80 85 90 95 100 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 α F値, 適合率, 再現率 F値 適合率 再現率 F値, 適合率, 再現率はそれぞれ交差検定における平均値
12 実験結果1-2 αが0.7の時、F値が91.64で最高 悪口単語を含む文は分類精度 高 (例)お前みたいな認識の馬鹿は死ねば良いと思う。
悪口単語が悪口として使われない文は… 状況によって分類精度が異なる (例)糞かっこいいー (例)あのパンはバカうまいな 比喩のような表現の悪口文は分類精度 低 (例)お前はサル以下の脳みその持ち主だな
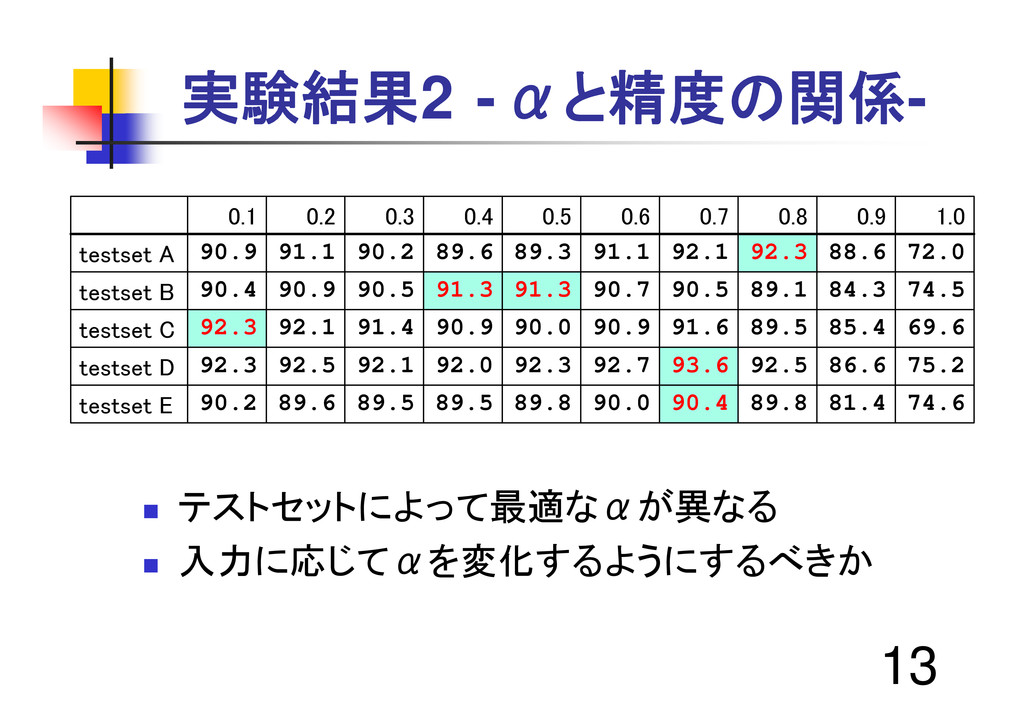
13 実験結果2 -αと精度の関係- テストセットによって最適なαが異なる 入力に応じてαを変化するようにするべきか 0.1 0.2 0.3
0.4 0.5 0.6 0.7 0.8 0.9 1.0 testset A 90.9 91.1 90.2 89.6 89.3 91.1 92.1 92.3 88.6 72.0 testset B 90.4 90.9 90.5 91.3 91.3 90.7 90.5 89.1 84.3 74.5 testset C 92.3 92.1 91.4 90.9 90.0 90.9 91.6 89.5 85.4 69.6 testset D 92.3 92.5 92.1 92.0 92.3 92.7 93.6 92.5 86.6 75.2 testset E 90.2 89.6 89.5 89.5 89.8 90.0 90.4 89.8 81.4 74.6
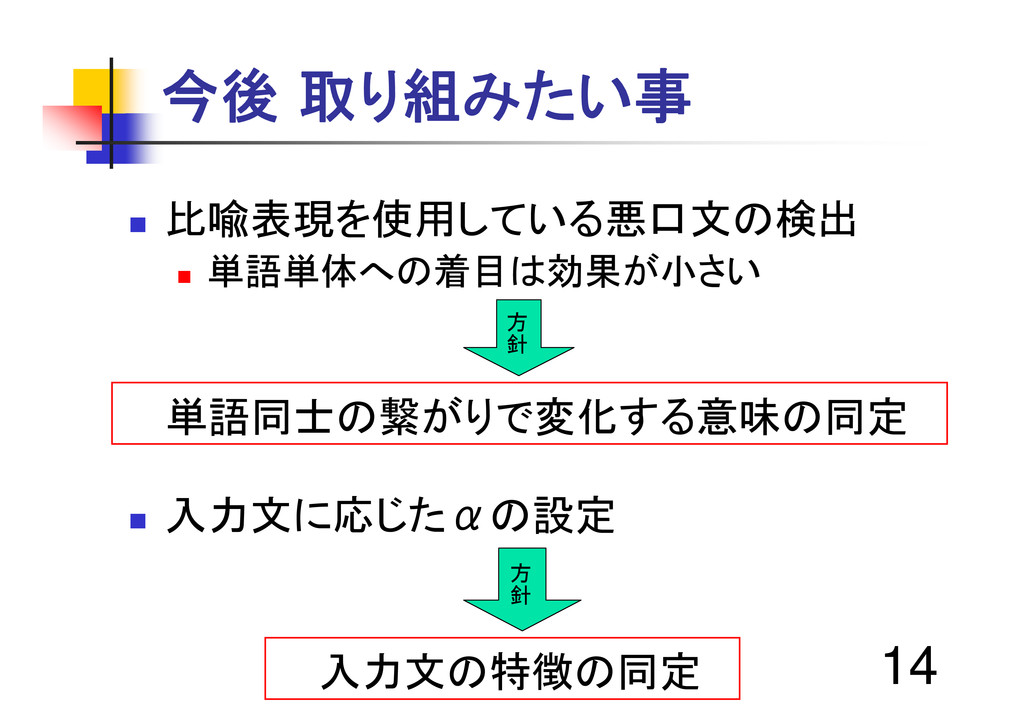
14 今後 取り組みたい事 比喩表現を使用している悪口文の検出 単語単体への着目は効果が小さい 方 針 単語同士の繋がりで変化する意味の同定
入力文に応じたαの設定 方 針 入力文の特徴の同定
15 まとめ 誹謗中傷を表す文の検出することが目的 今回は評価表現分類の手法を使用 単語が悪口単語かどうかを計算した SVMの分類結果は最高でF値91.64
比喩を使う悪口文は抽出できない 単語の繋がりによる意味の変化を同定したい
16 なぜ 「2ちゃんねる」なのか z 2ちゃんねるは多くの人が利用している z さらに, 悪口書き込みが多い z 仮説
z Web全体と2ちゃんねるでは悪口表現の種 類数 に大きな差はない
17 悪口文の収集 z 種辞書の登録表現を含む文(悪口文)を収集 z 毎日 約2000スレッドを解析 z 約20万文を収集できた (例)
z つか,官僚死ねや z 泥棒ゴミクズ団体はさっさと吊ってこい! z こんなんでイチイチ騒ぐなボケカス。
18 類似研究 有害サイトのフィルタリング Goez et al. 2003, Grilheres
et al. 2004, Lee et al. 2004 有害サイトの単語を学習させて分類器で分類 学校非公式サイトから有害となる単語の検出 松葉ら 2009,2010 規則と分類器で分類 単語ではなくn-gramで有害(悪口)となる句をもとに抽出 本手法は…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![4 SO-PMI Algorithmを使用 単語の悪口度計算 ) ( ] [ log](https://files.speakerdeck.com/presentations/df12ec00c60301306b9516ef2e465d1f/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}