Share
井手上 雅迪, 山本 和英, 内山 将夫, 隅田 英一郎. フレーズテーブルを用いた教師なし用語対訳抽出手法の比較. 言語処理学会第17回年次大会, pp.178-181 (2011.3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
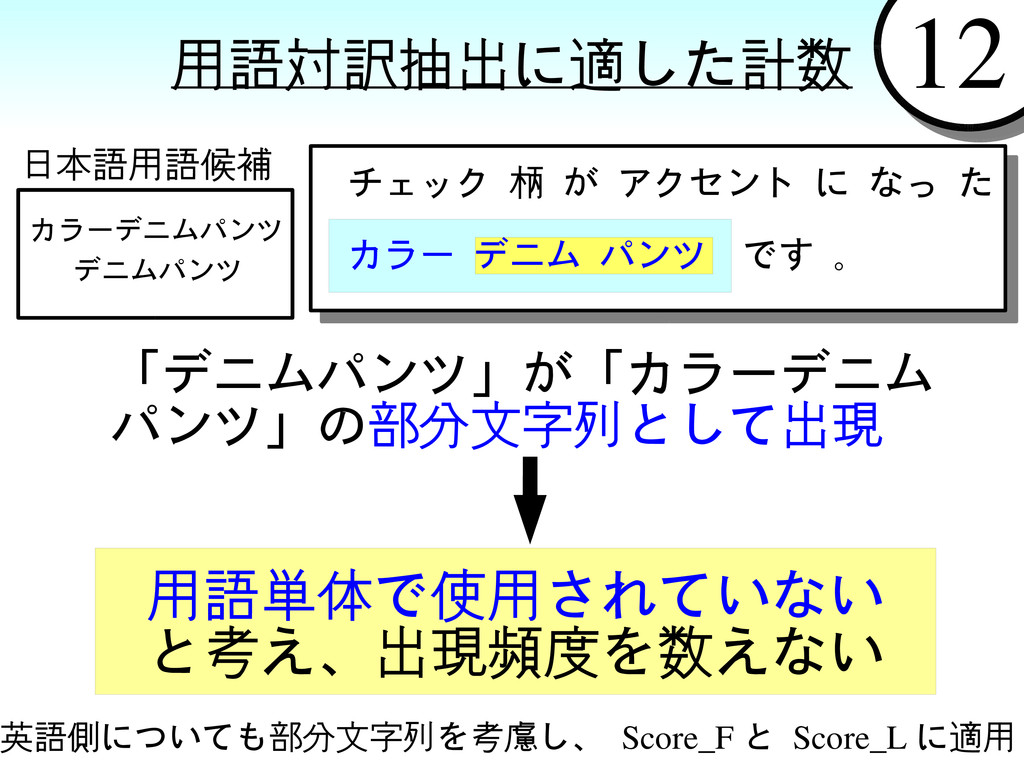{kind=link}
{kind=link}
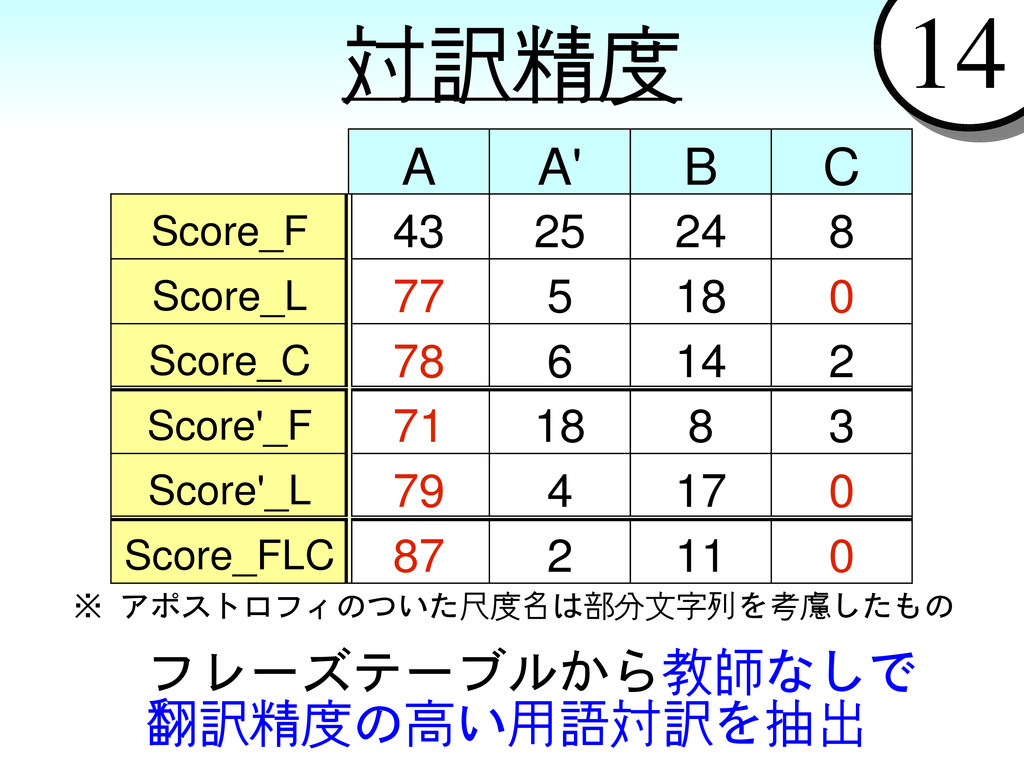{kind=link}
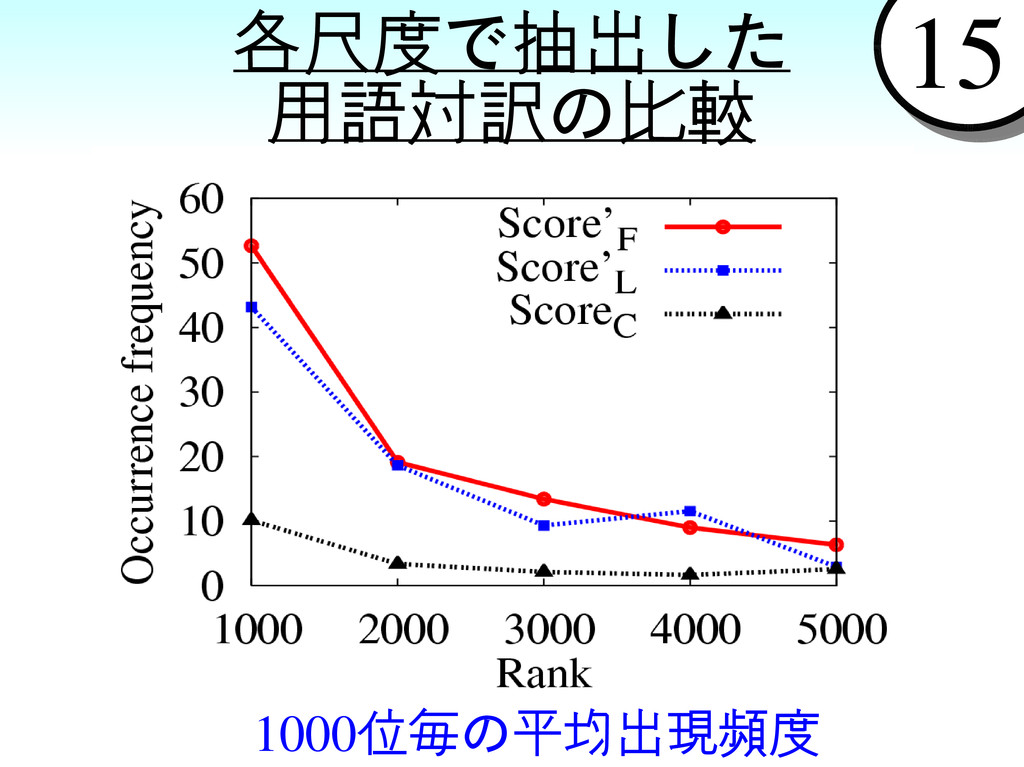{kind=link}
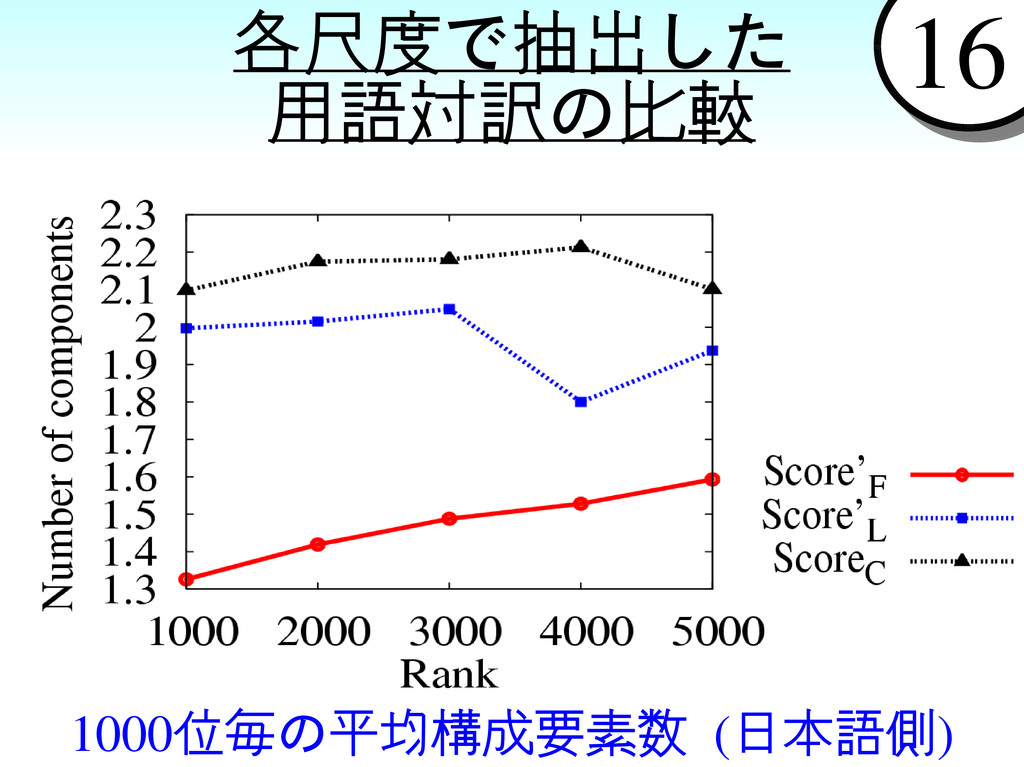{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}