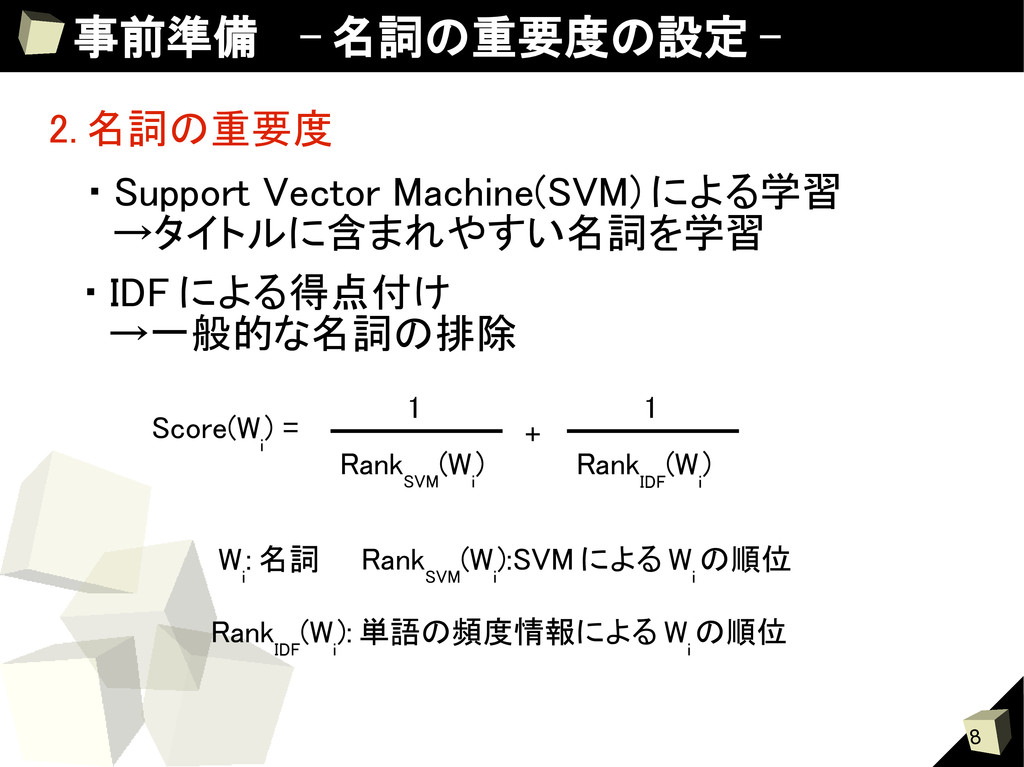
Machine(SVM) による学習 →タイトルに含まれやすい名詞を学習 ・ IDF による得点付け →一般的な名詞の排除 Score(W i ) = Rank SVM (W i ) 1 Rank IDF (W i ) 1 + W i : 名詞 Rank SVM (W i ):SVM による W i の順位 Rank IDF (W i ): 単語の頻度情報による W i の順位
Vector Machine(SVM) による学習 →タイトルに含まれやすい名詞を学習 ・大規模テキストからの頻度情報 (IDF) →一般的な名詞の排除 Score(W i ) = Rank SVM (W i ) 1 Rank IDF (W i ) 1 + Wi: 名詞 Rank SVM (W i ):SVM による W i の順位 Rank IDF (W i ): 単語の頻度情報による W i の順位
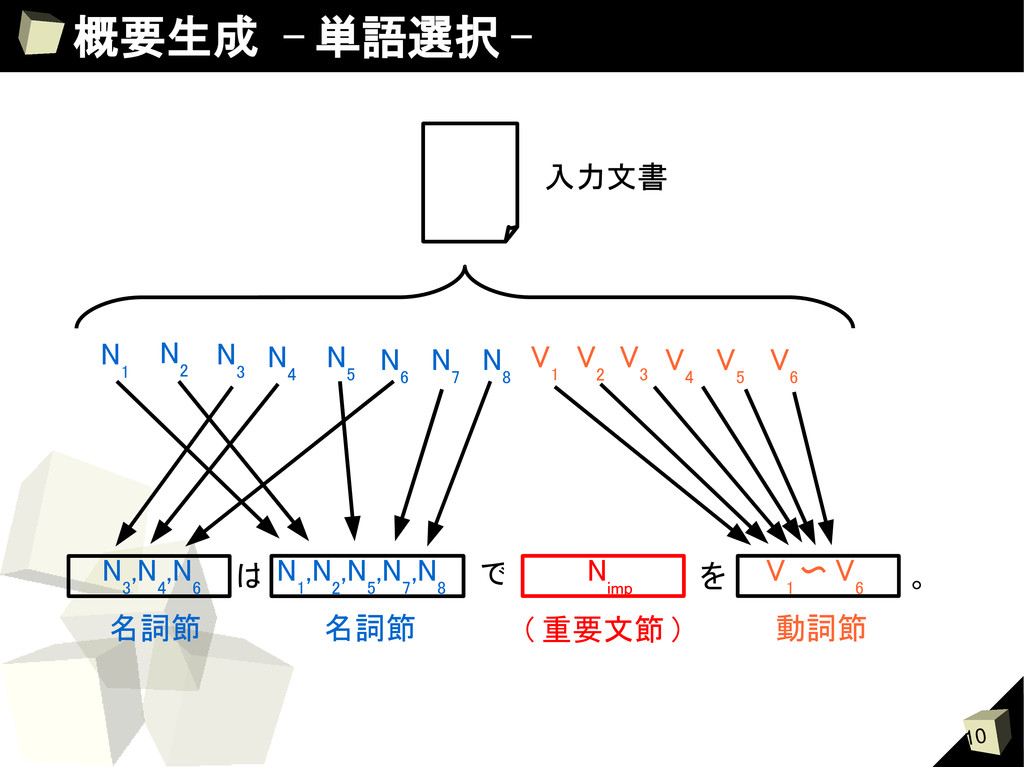
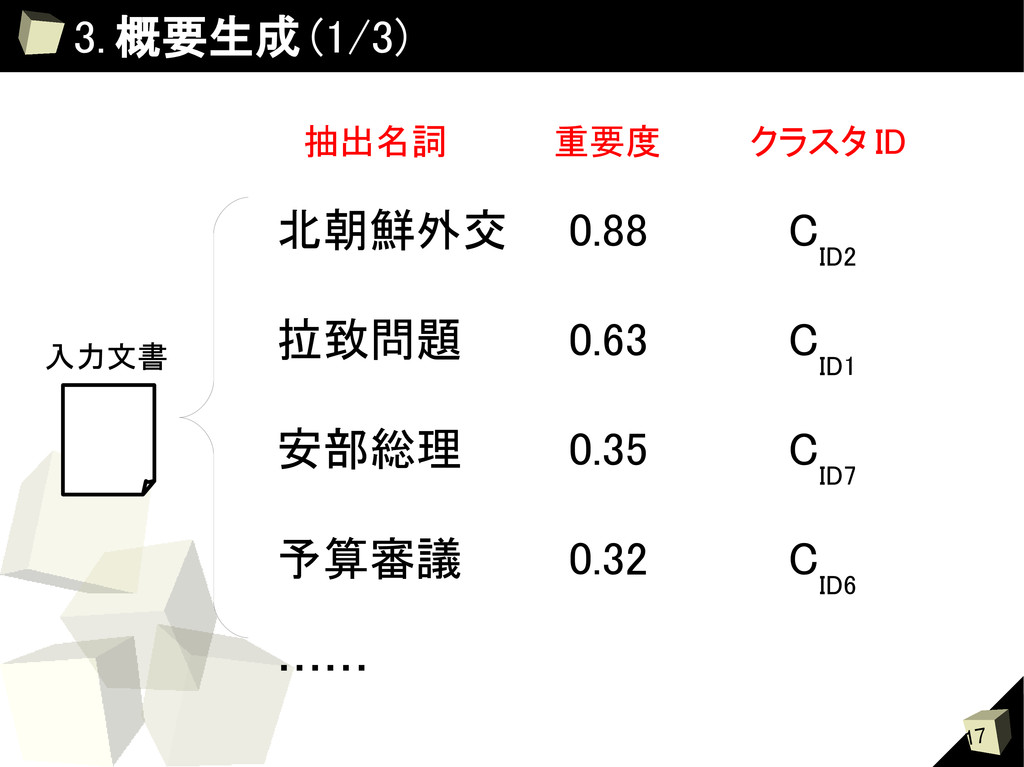
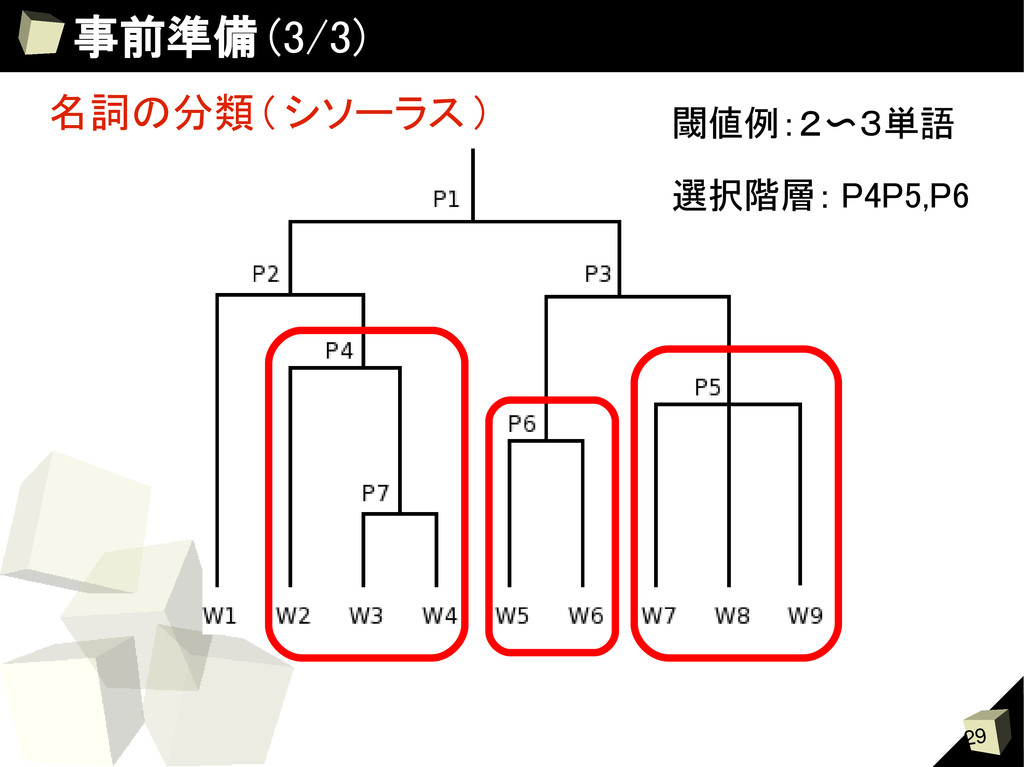
SVM と名詞の頻度情報から求める Score(W i ) = Rank SVM (W i ) 1 Rank IDF (W i ) 1 + Wi: 名詞 Rank SVM (W i ):SVM による W i の順位 Rank IDF (W i ): 単語の頻度情報による W i の順位 2. 単語の分類 クラスタリングの結果から名詞にクラスタ ID を付与する
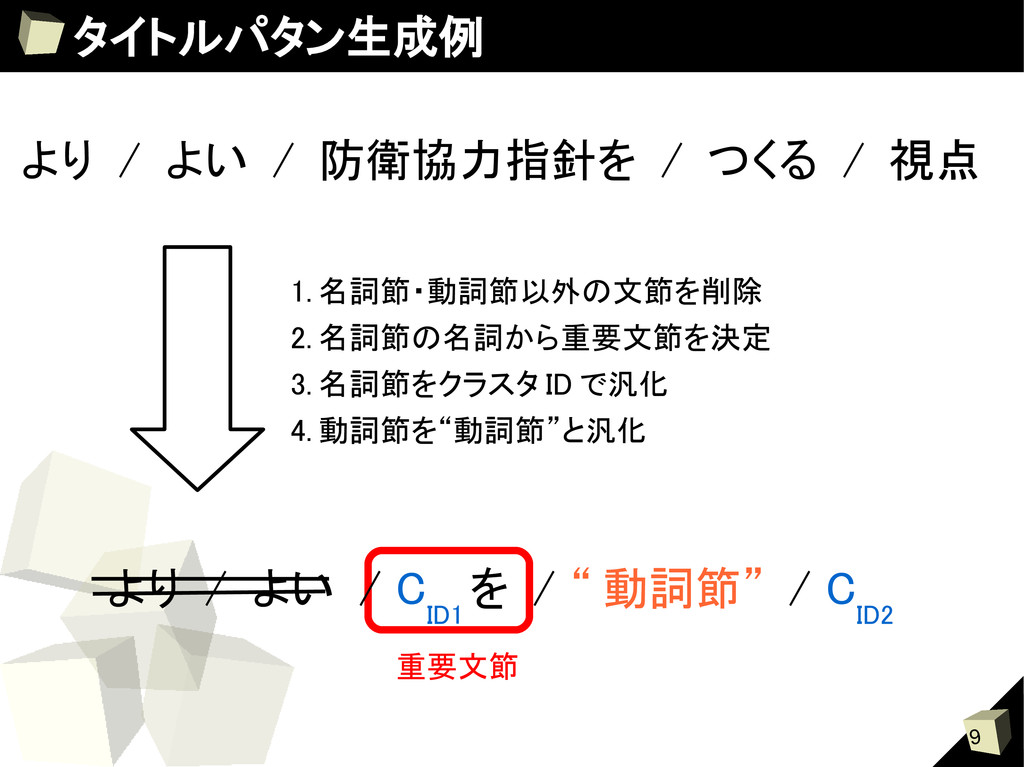
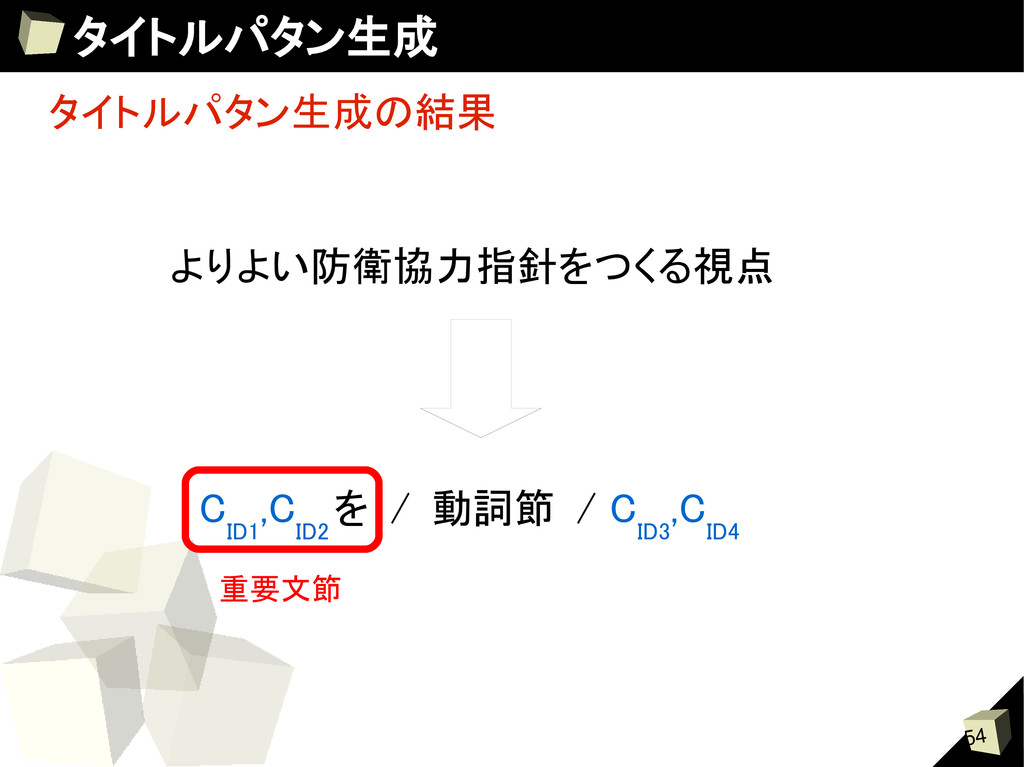
Score 2-gram ) (2) 動詞を中心とした連接確率 =大局的スコア( Score Verb ) Score(S i ) = S i : 生成された文 スコア計算時は複合名詞の長さに依存させないために 複合名詞は主辞のみを見る 例:防衛協力指針をつくる視点 → 指針をつくる視点 argmaxScore Verb (S i ) Score Verb (S i ) argmaxScore 2-gram (S i ) Score 2-gram (S i ) +
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}