examining dev set examples that your algorithm misclassified. • Will help you understand the cause of the problem. • This will give you a better insight on what to do next.
dev set examples. • Look at these examples manually, and count what fraction of them are dog images. OUTPUT: • 5 % of images are dogs. • 50 % of images are dogs.
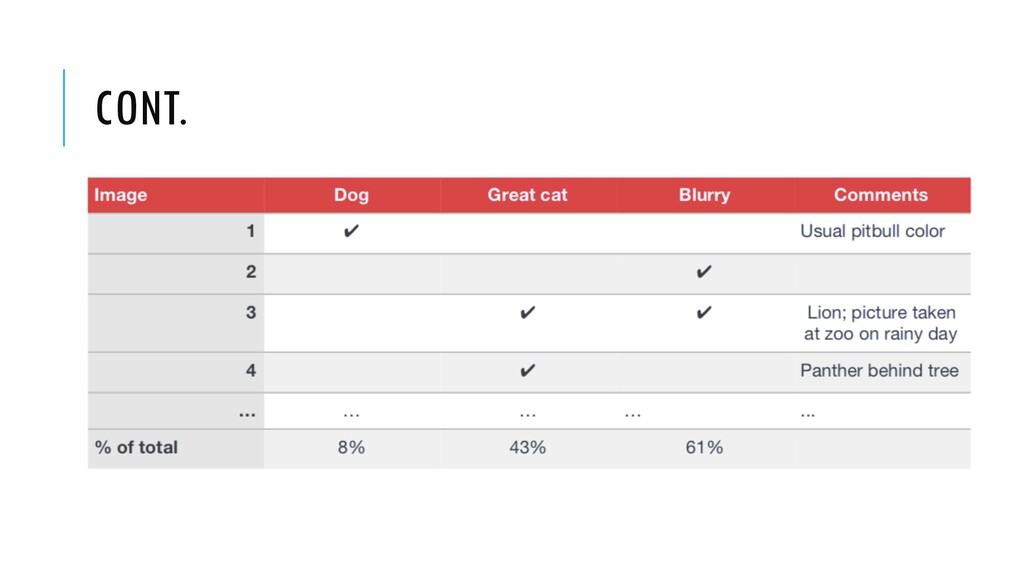
several ideas for improving the cat detector: • Fix picture of dogs being recognized as cats • Fix great cats (lion, Panther, etc. . . ) being misrecognized • Improve performance on blurry images
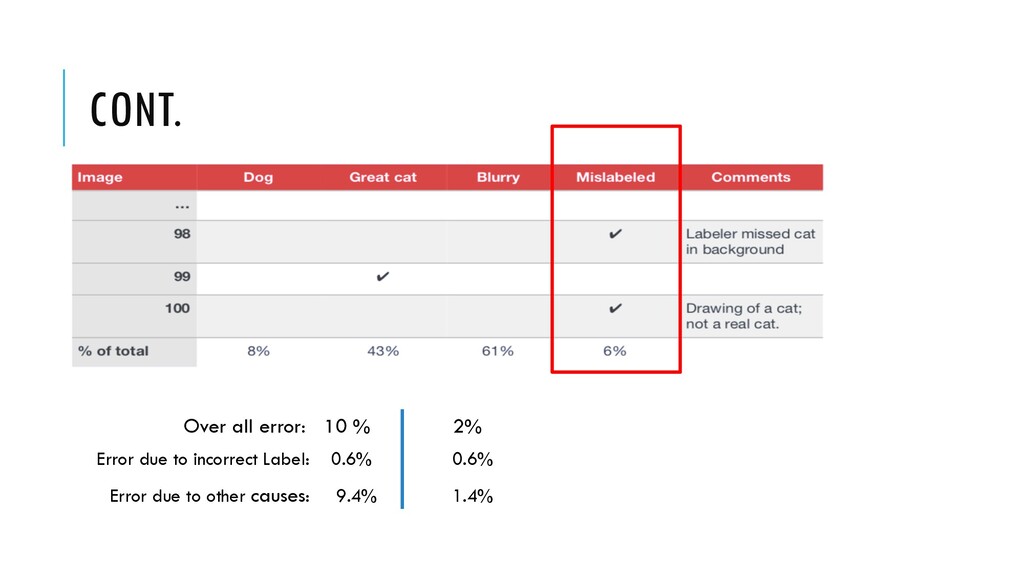
notice that some examples in your dev set are mislabeled ( the pictures were already mislabeled by a human ). • Should you correct the labels in your dev set ?
are tackling a brand Machine learning problem, it is advised that to build your first system quickly and then iterate. • Speech recognition example. • Noisy background (Café noise, car noise) •Accented speech •Far from microphone •Stuttering, etc.
shuffle them and divide to train, dev and test • Advantage is all your sets come from the same distribution. • Disadvantage is most of your dev set images come from the web data Train 205,000 images dev 2.5k test 2.5k
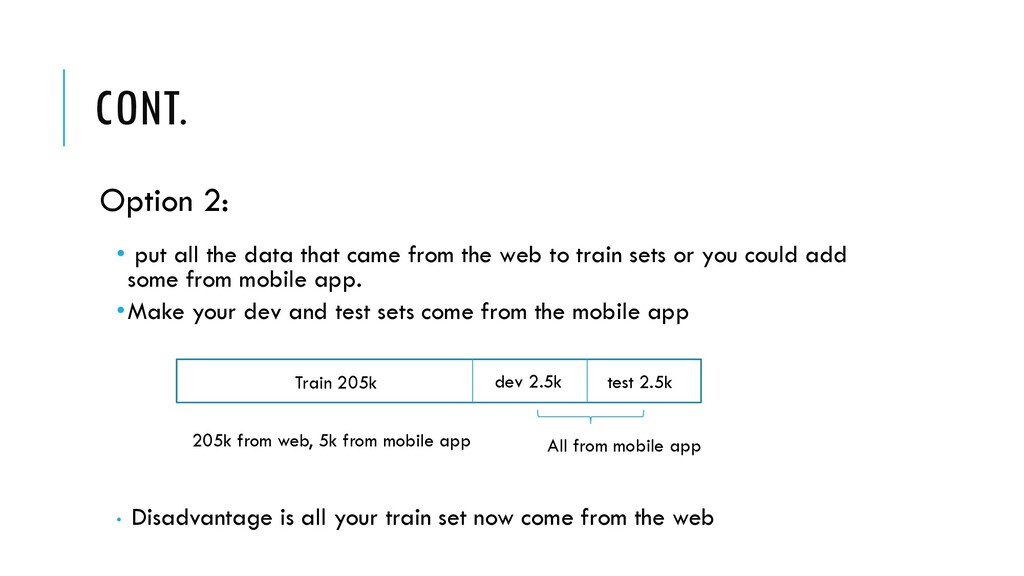
from the web to train sets or you could add some from mobile app. •Make your dev and test sets come from the mobile app • Disadvantage is all your train set now come from the web Train 205k dev 2.5k test 2.5k 205k from web, 5k from mobile app All from mobile app
and variance of your learning algorithm will also help you prioritize on what to next. • Analyzing bias and variance change when your training sets comes from different distribution than dev/test sets will help you identify your error. • Cat classifier App Example •Training error – 1% •Dev error – 10%
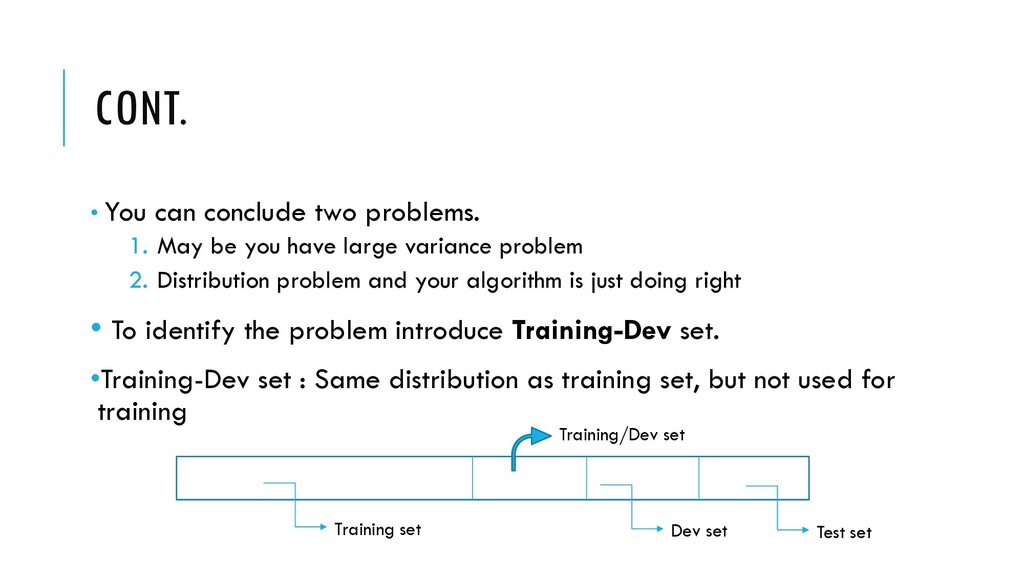
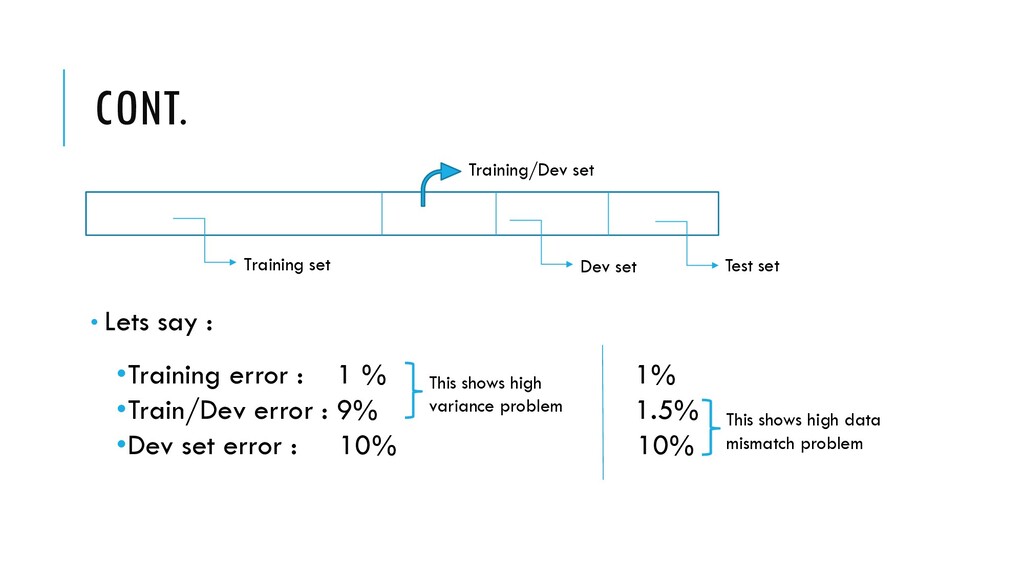
you have large variance problem 2. Distribution problem and your algorithm is just doing right • To identify the problem introduce Training-Dev set. •Training-Dev set : Same distribution as training set, but not used for training Test set Dev set Training/Dev set Training set
1% •Train/Dev error : 9% 1.5% •Dev set error : 10% 10% Dev set Training/Dev set Training set This shows high variance problem This shows high data mismatch problem Test set
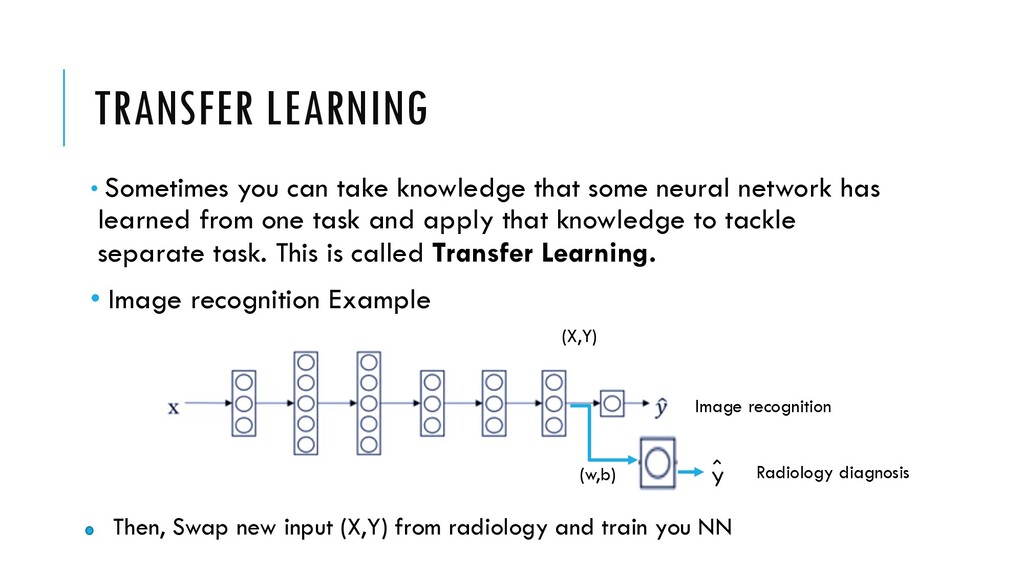
neural network has learned from one task and apply that knowledge to tackle separate task. This is called Transfer Learning. • Image recognition Example (X,Y) Y ˆ (w,b) Radiology diagnosis Image recognition Then, Swap new input (X,Y) from radiology and train you NN
network to do several things simultaneously at the same time. • Autonomous driving Example •Features you need to identify: •Pedestrian •Cars •Stop sign •Traffic Lights
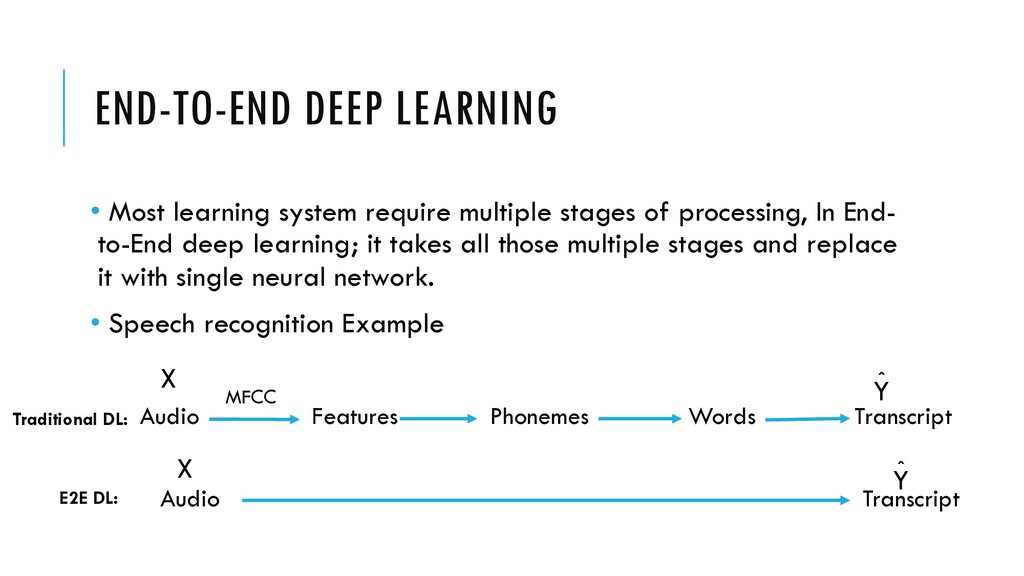
of processing, In End- to-End deep learning; it takes all those multiple stages and replace it with single neural network. • Speech recognition Example Audio Features Phonemes Words Transcript X Y MFCC ˆ Traditional DL: Audio Transcript Y ˆ X E2E DL:
before it works well. If you have smaller data traditional pipelines works better. • If your data is not big enough, you could take some stages to your E2E DL pipeline. (i.e. audio > features > transcript) ADV: • Less hand designing components required
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}