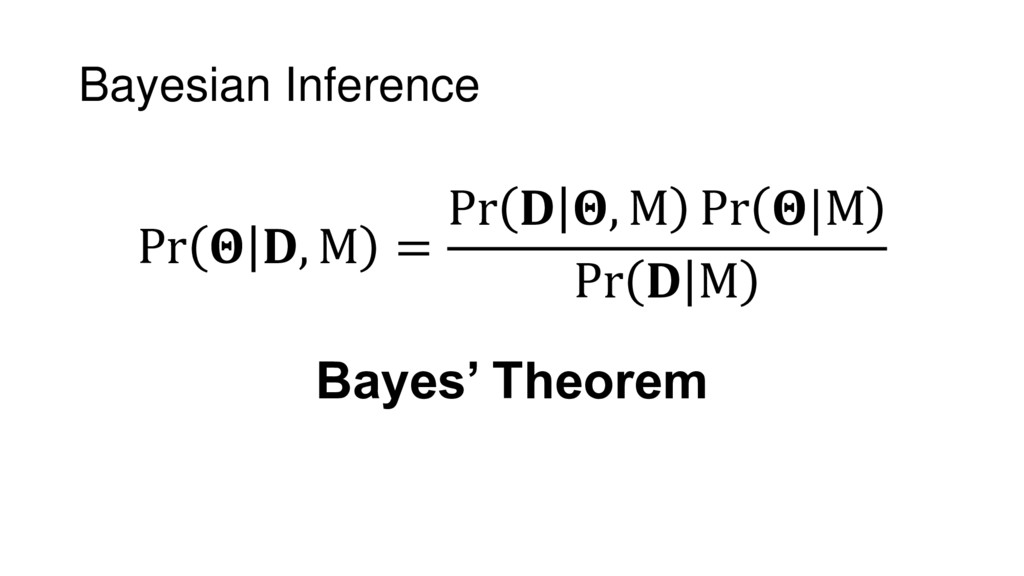
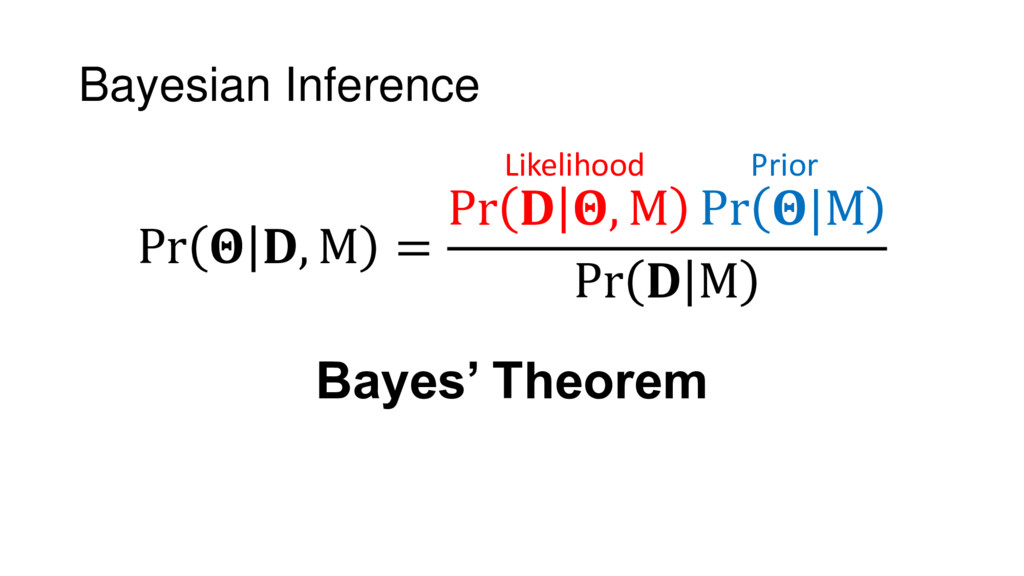
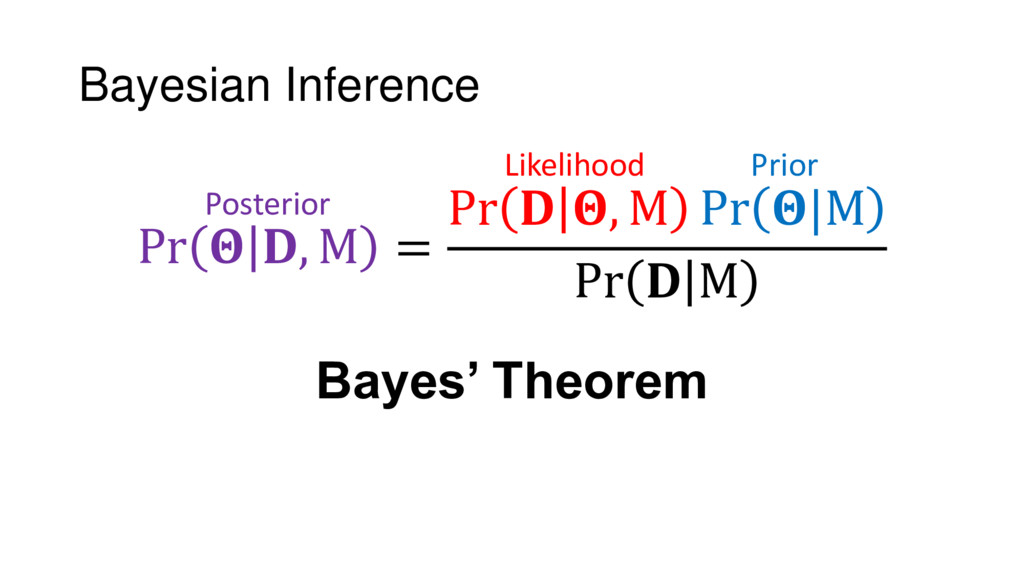
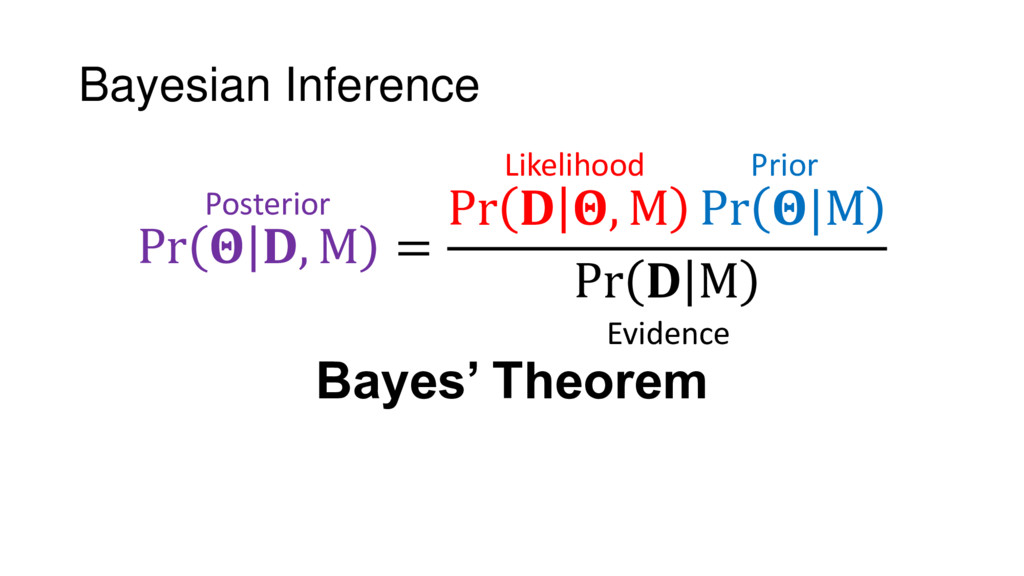
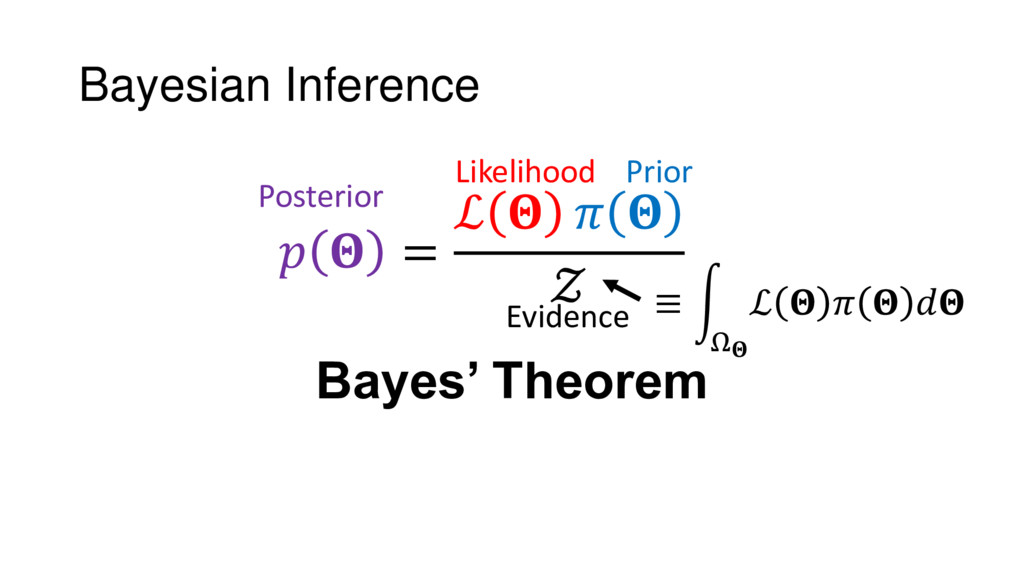
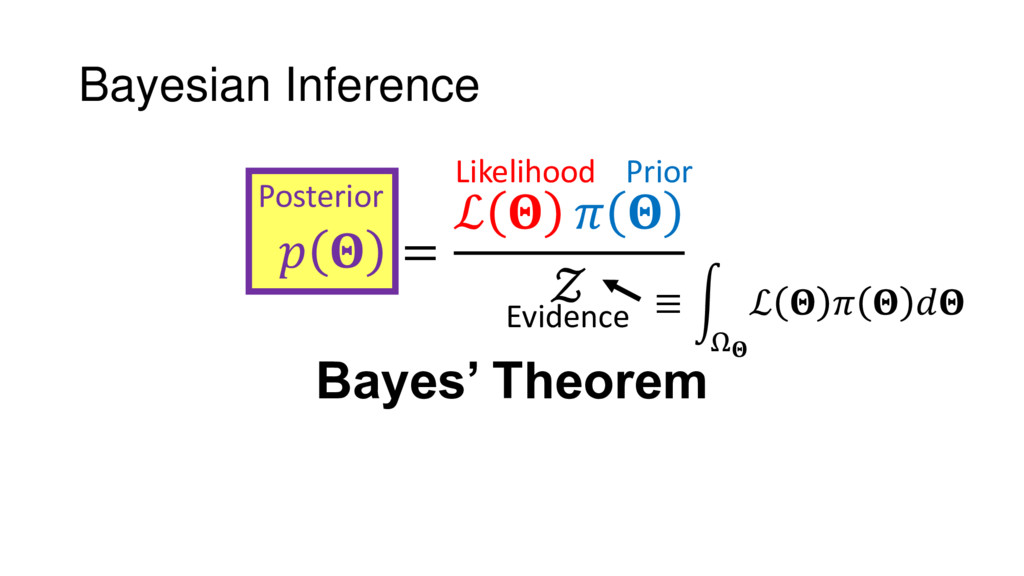
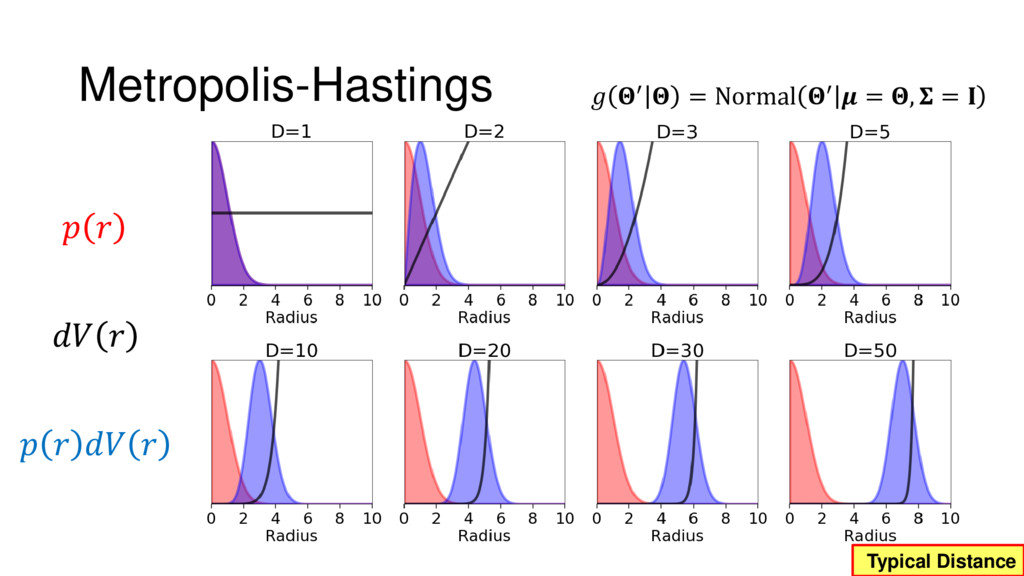
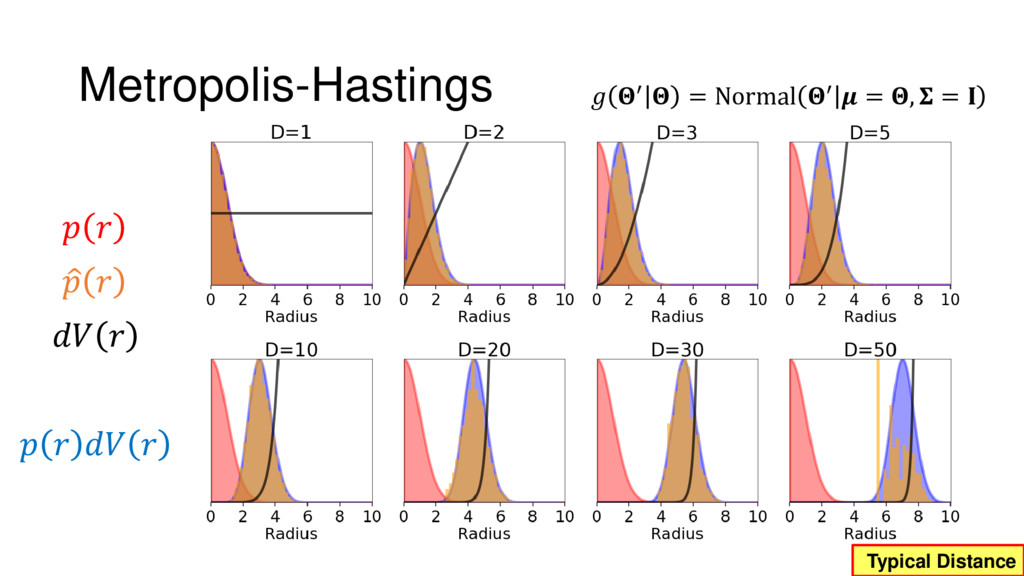
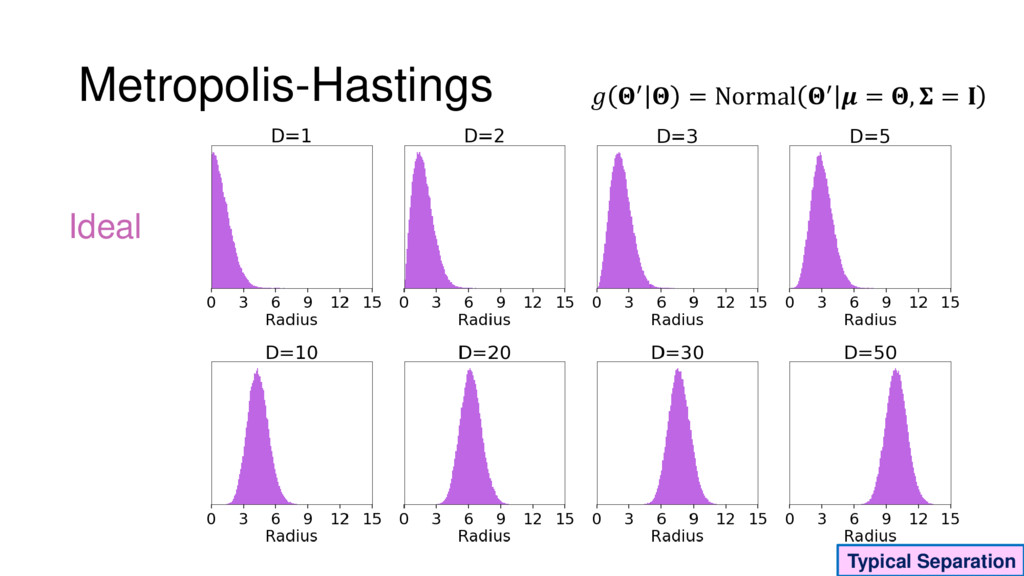
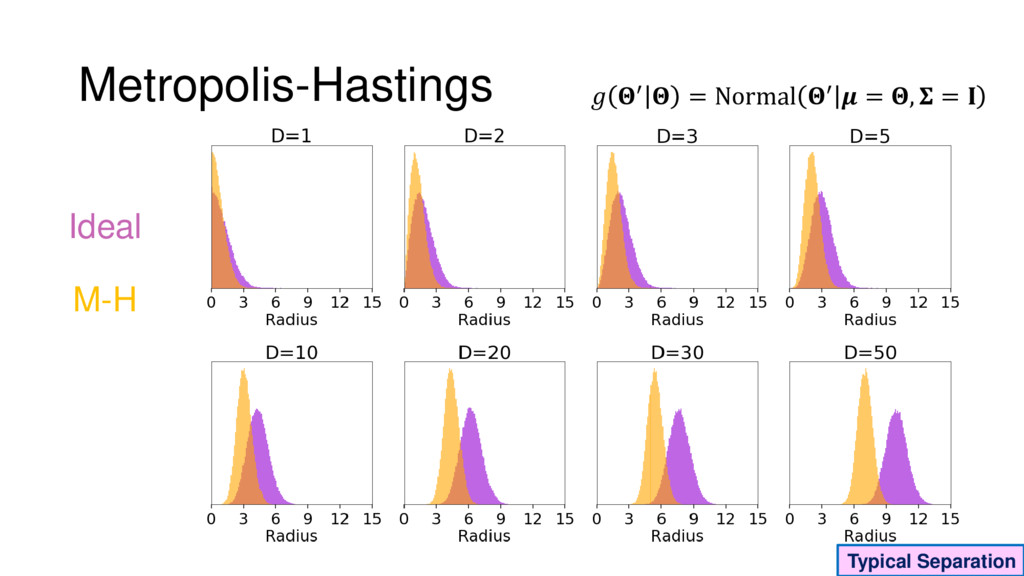
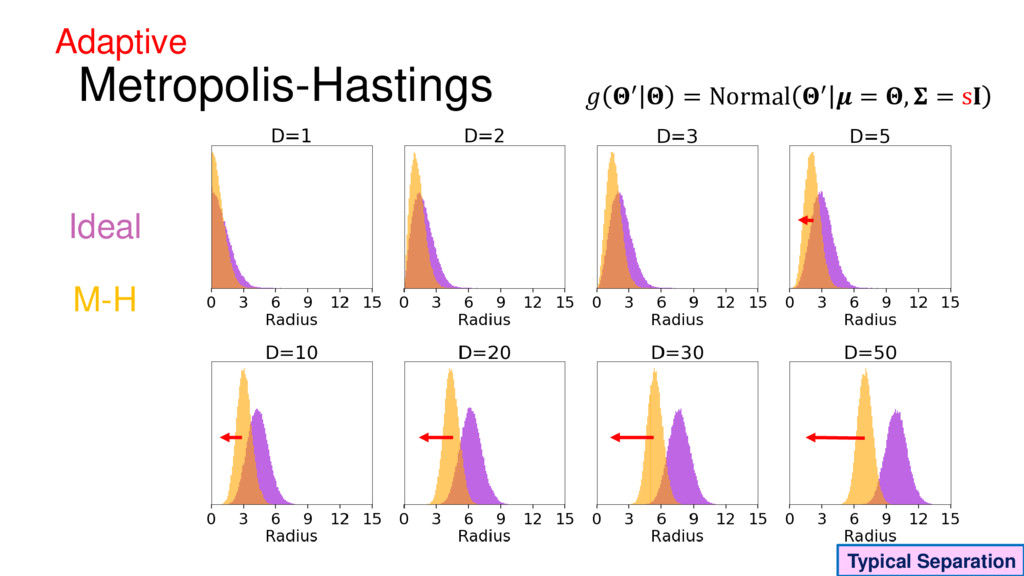
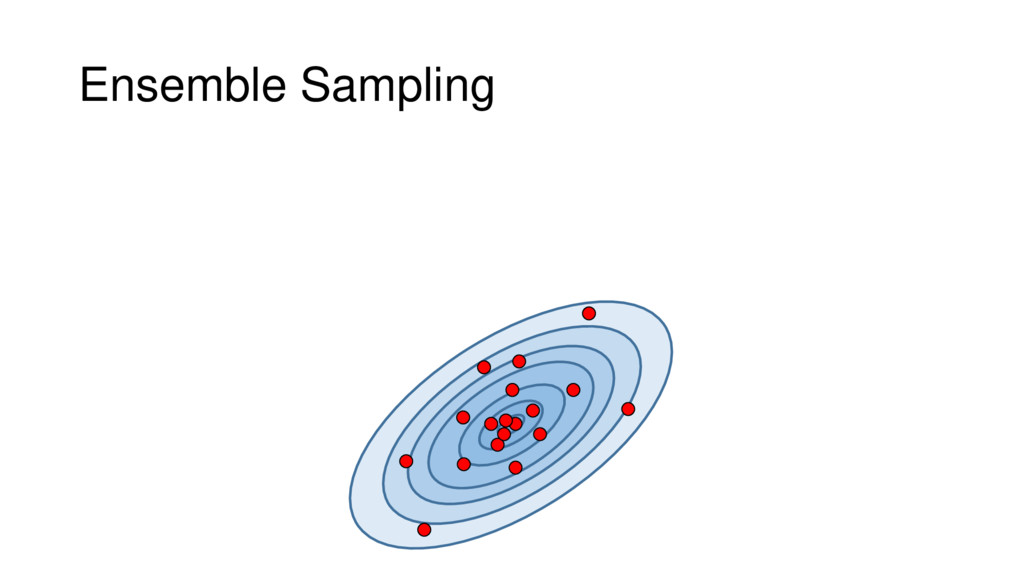
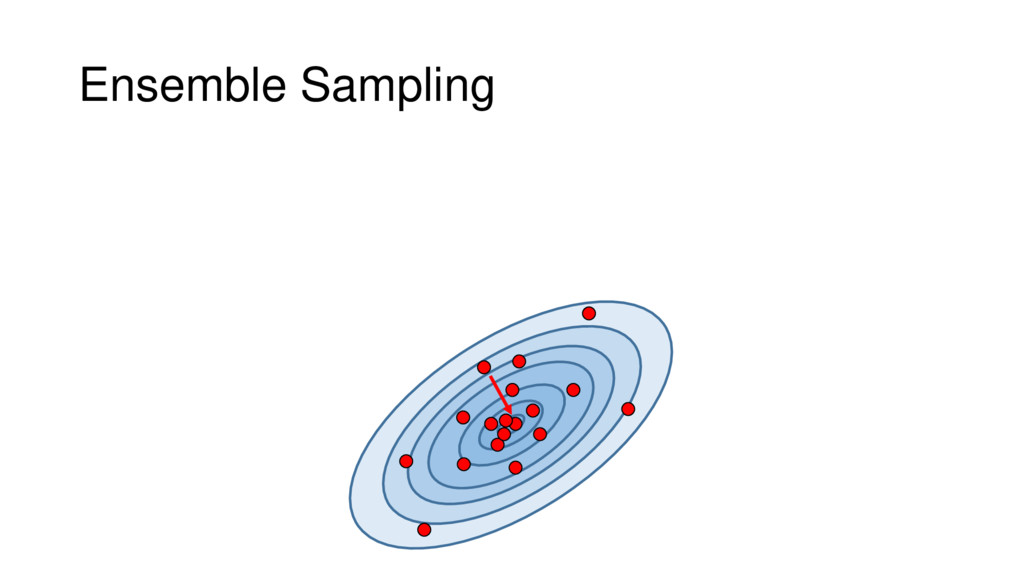
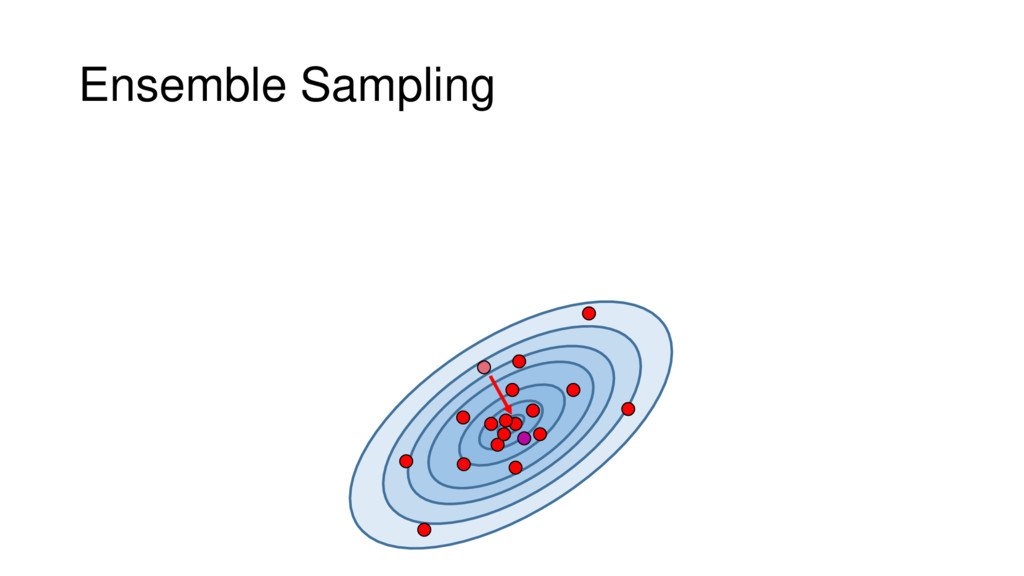
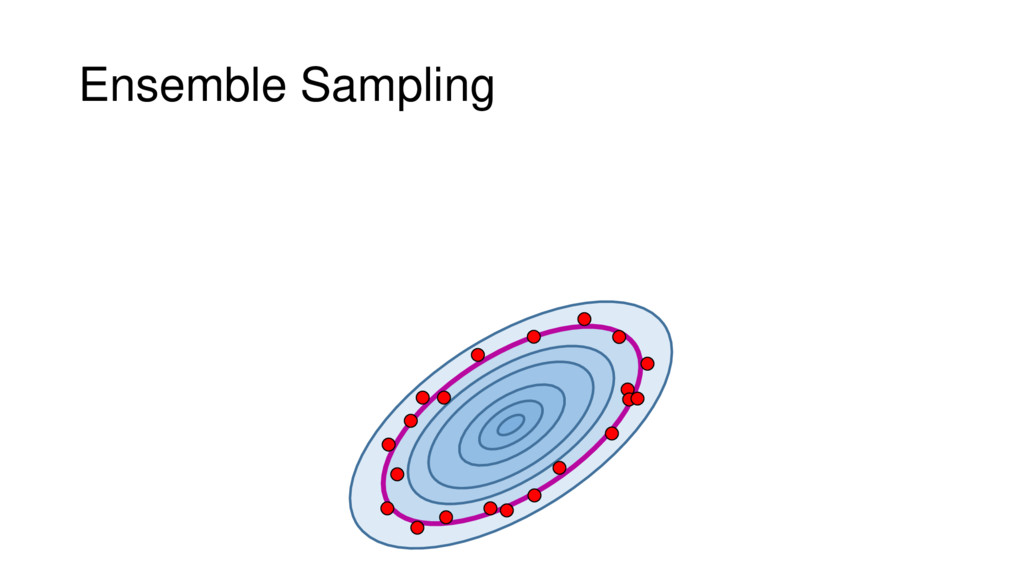
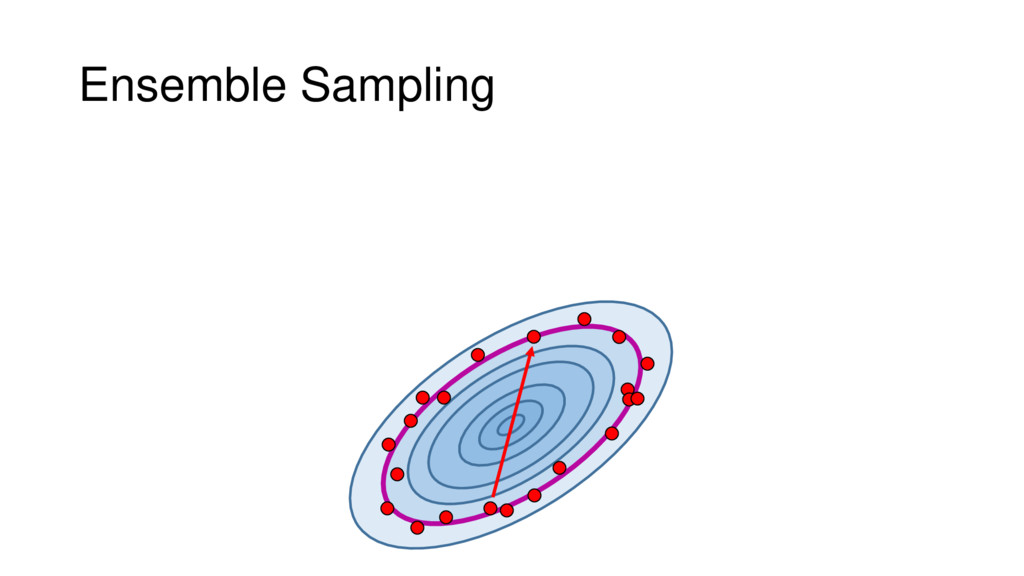
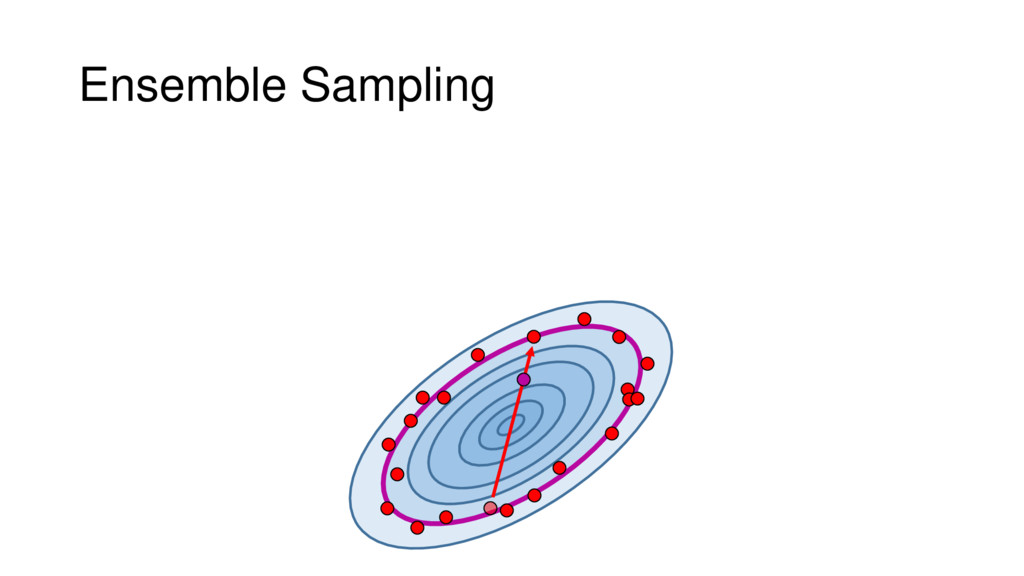
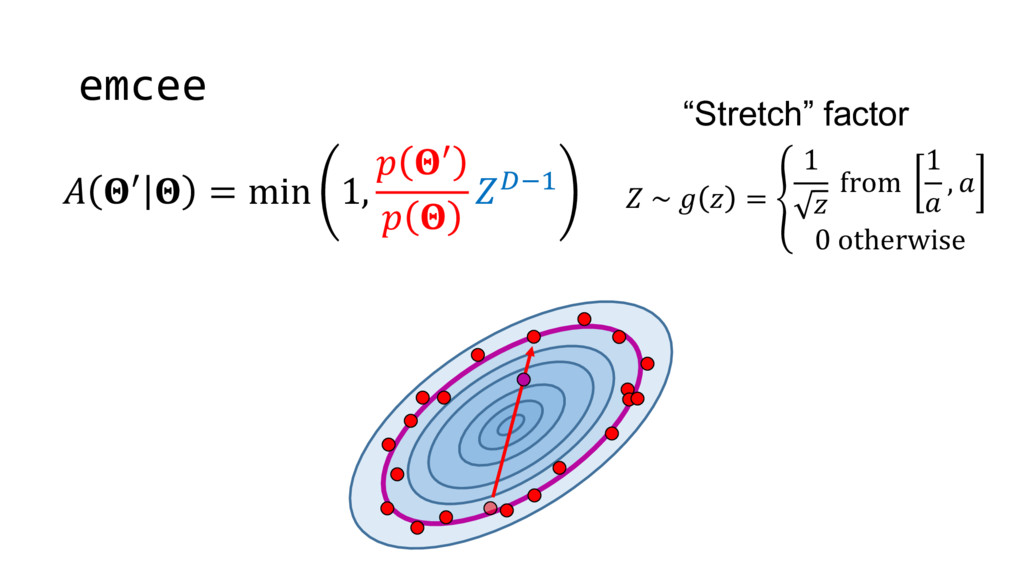
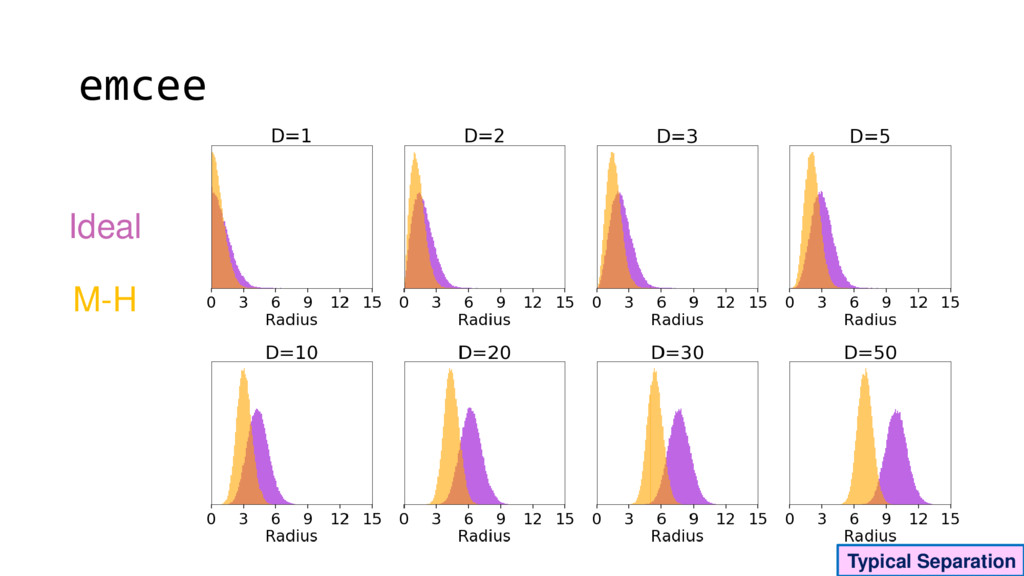
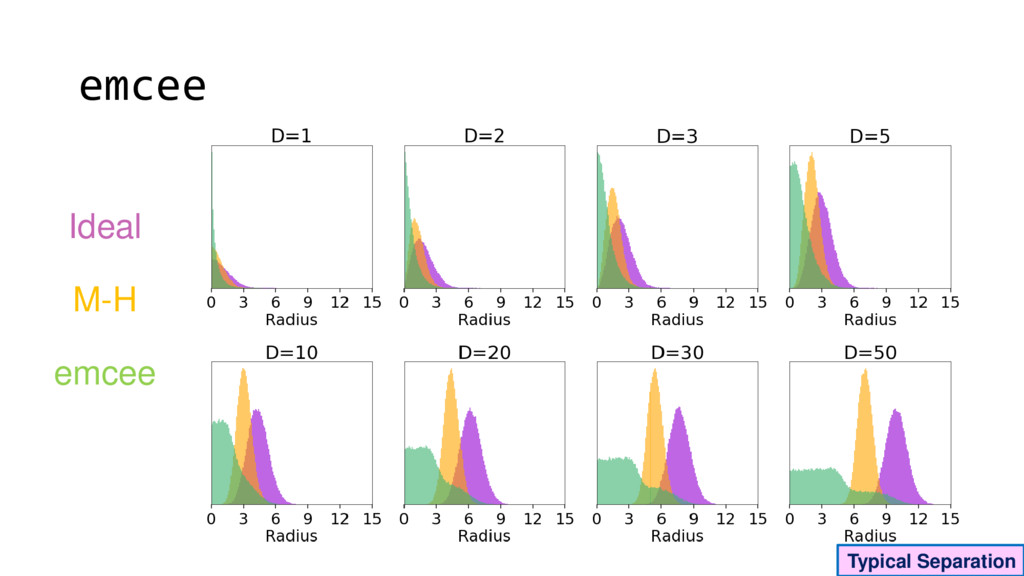
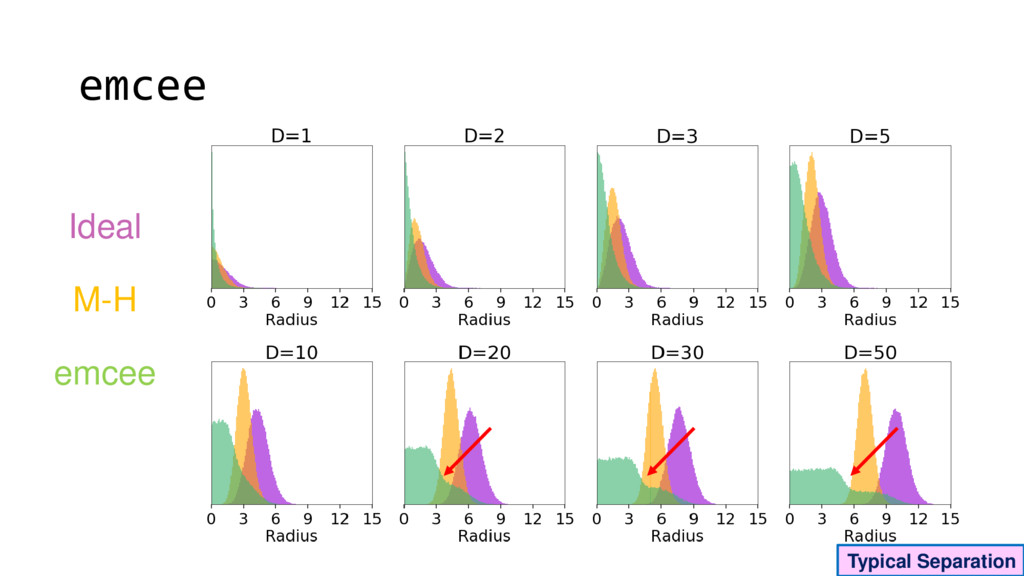
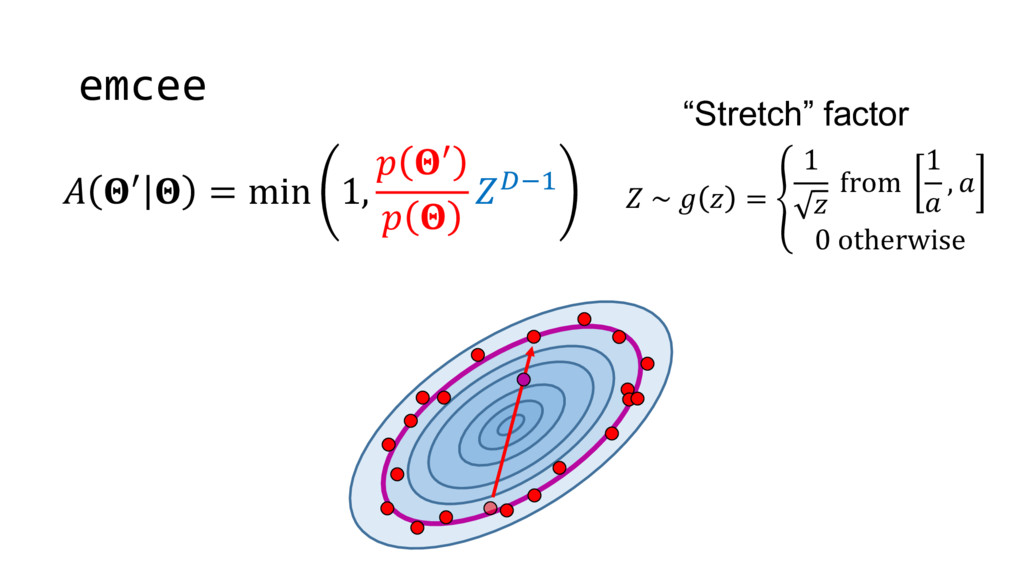
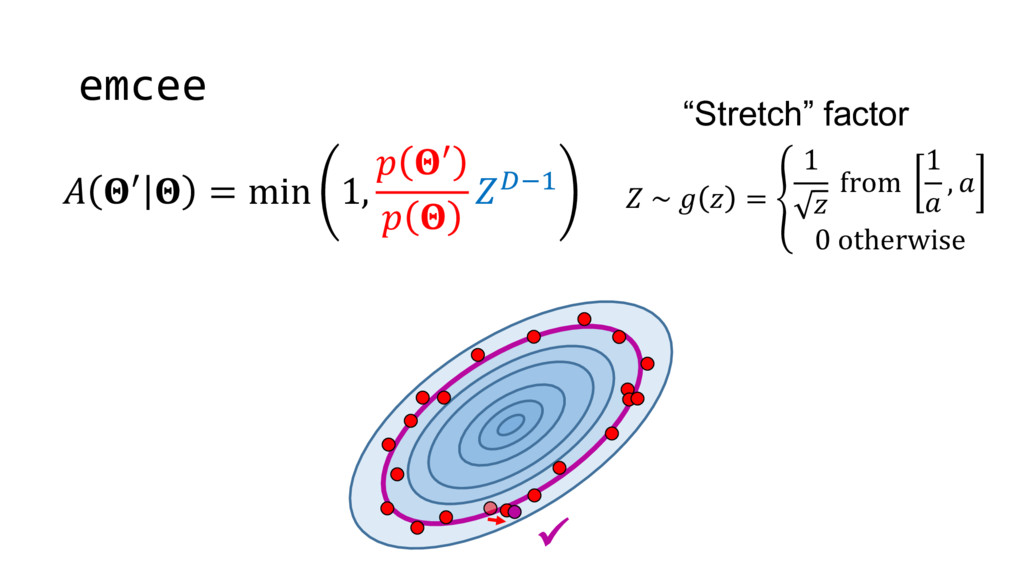
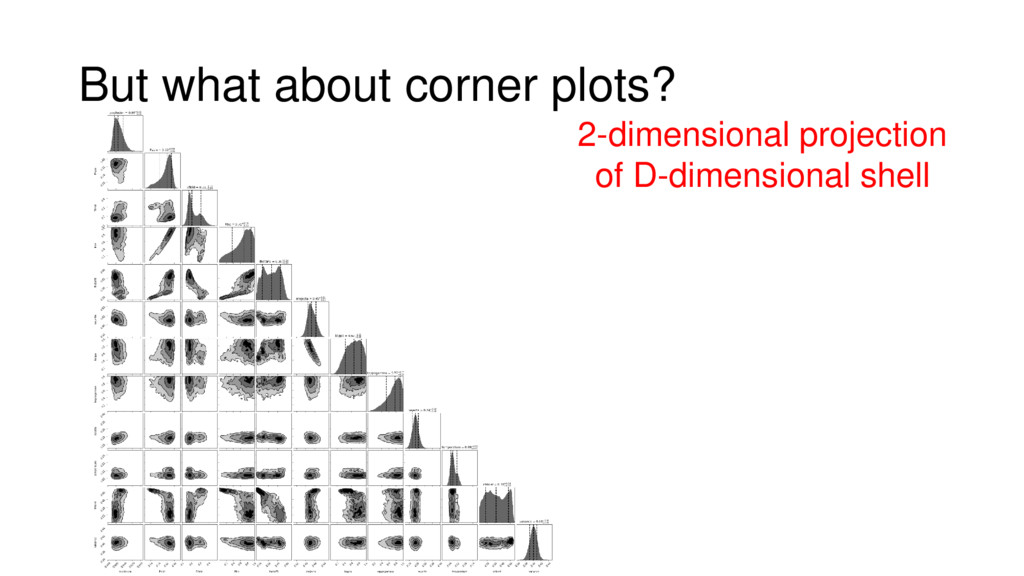
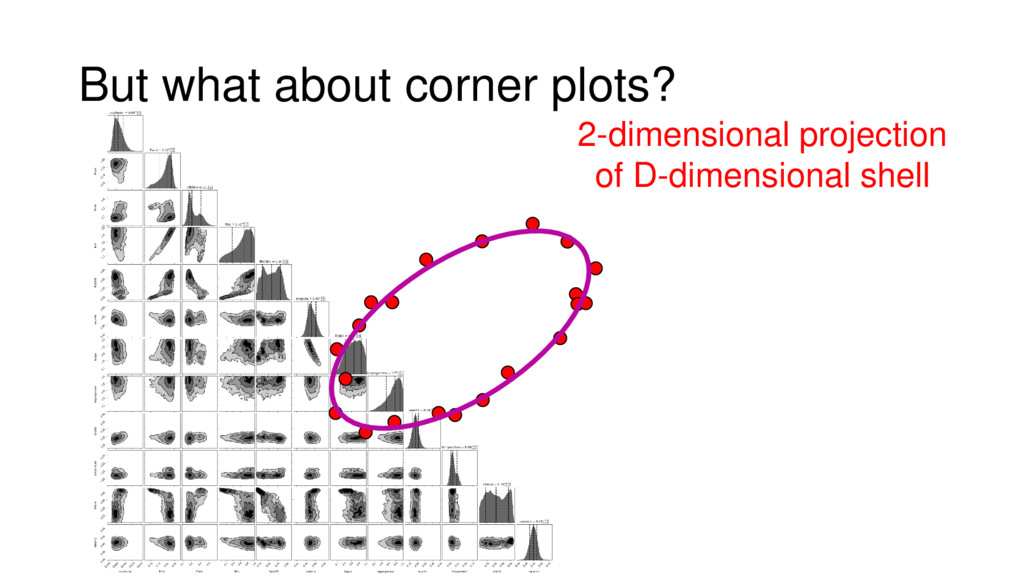
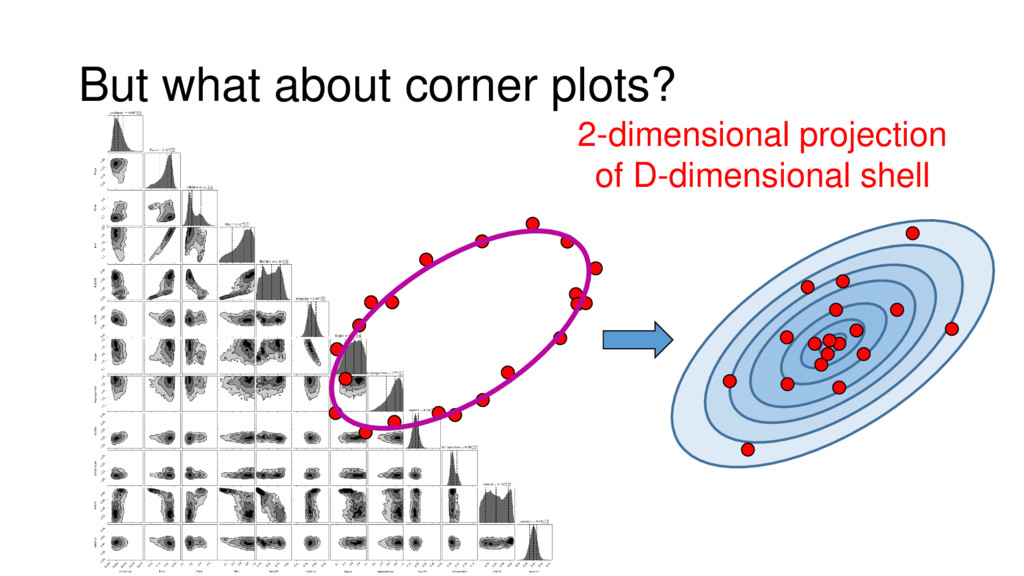
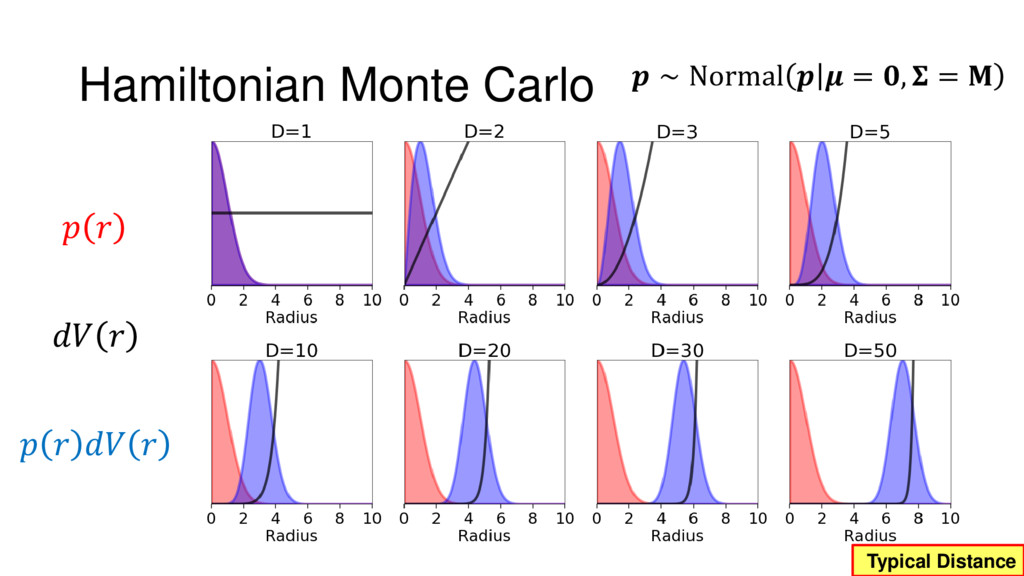
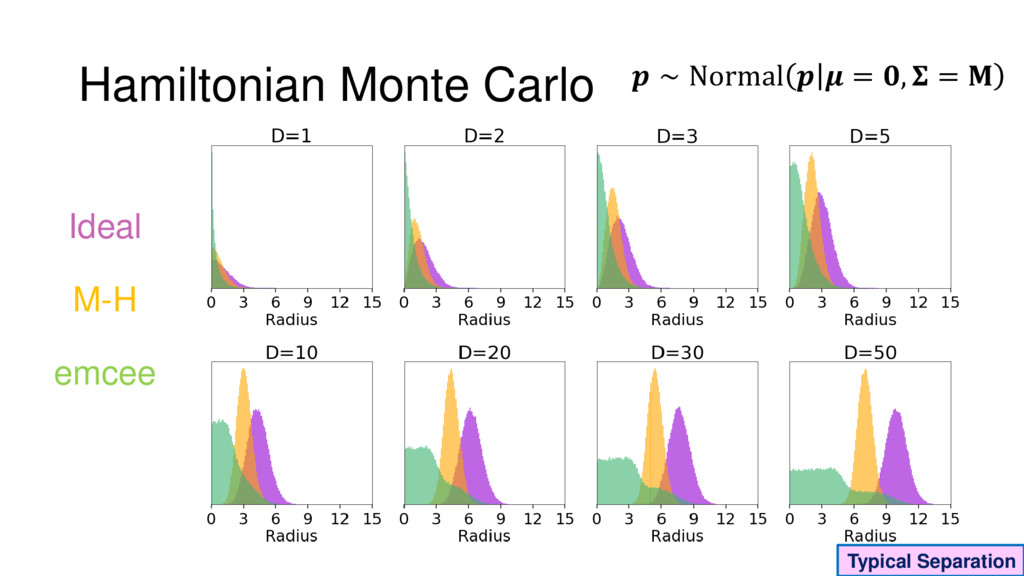
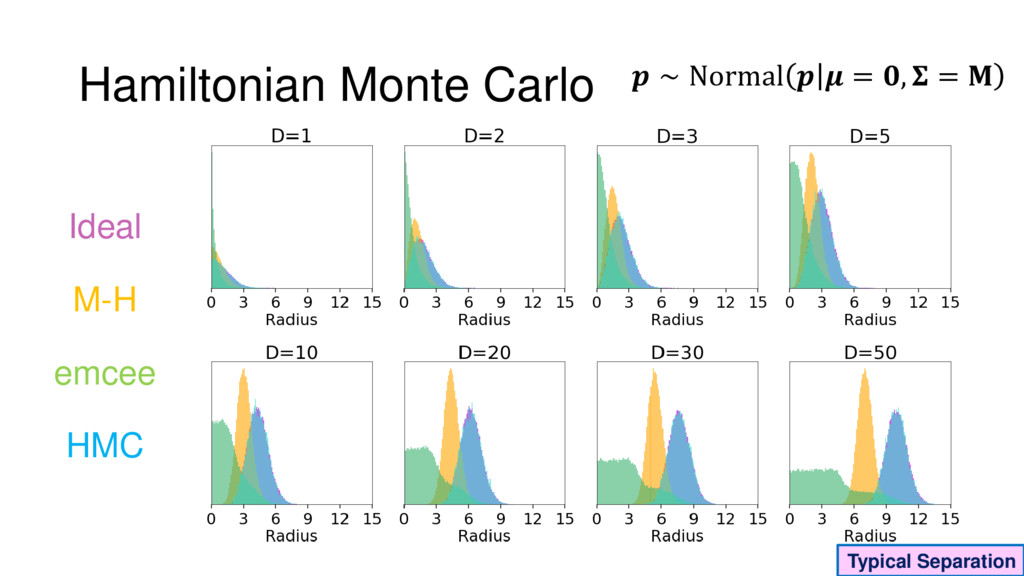
Although typical sets are important in understanding how/why sampling algorithms (do not) work, they are rarely taught when most astronomers are introduced to sampling methods such as Markov Chain Monte Carlo (MCMC). I introduce the idea of typical sets using some basic examples and show why they make sampling difficult in higher dimensions. I then outline how their behavior shapes various MCMC algorithms such as (Adaptive) Metropolis-Hastings, ensemble sampling, and Hamiltonian Monte Carlo. See https://github.com/joshspeagle/typical_sets for additional resources.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
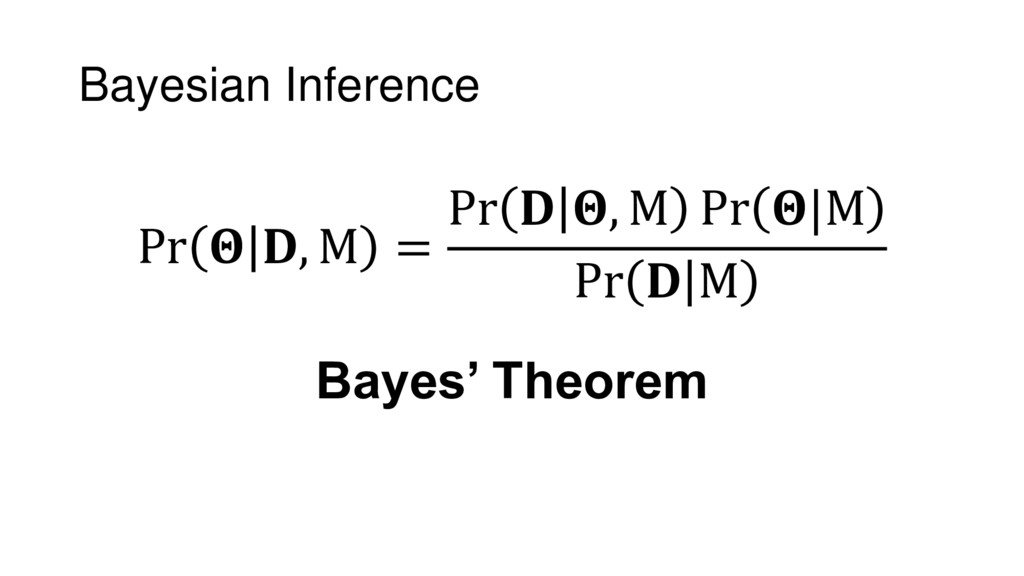{kind=link}
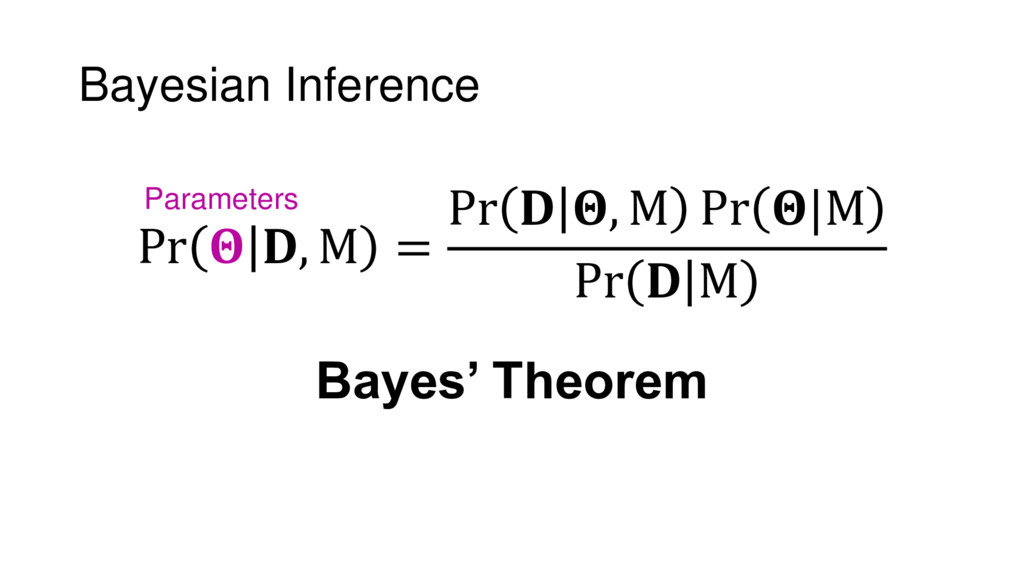{kind=link}
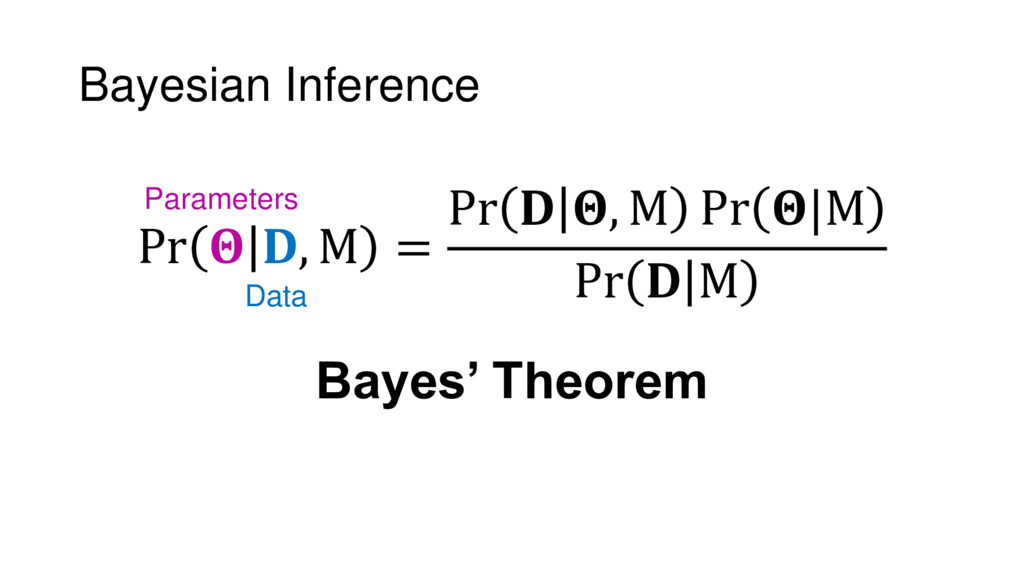{kind=link}
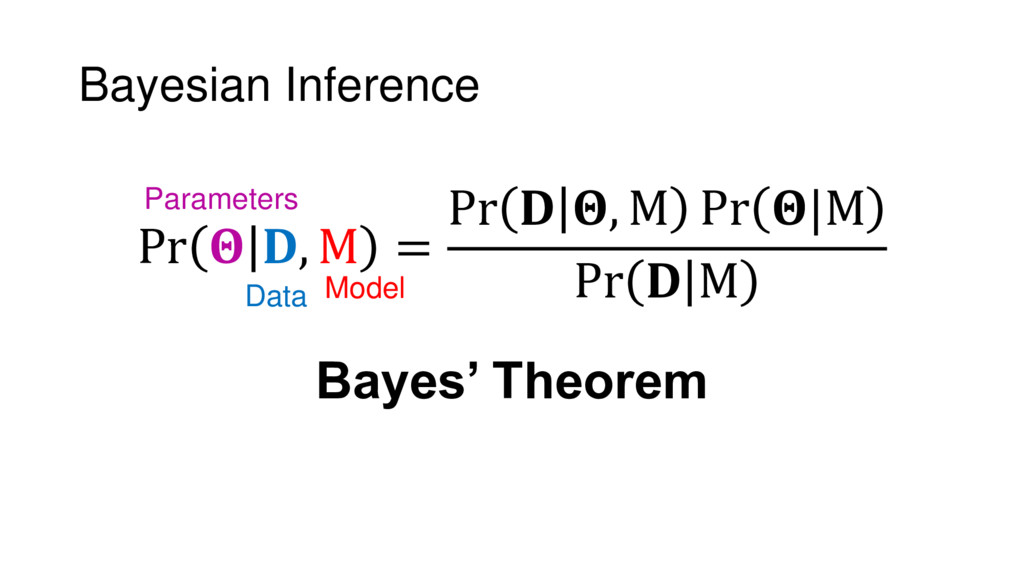{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
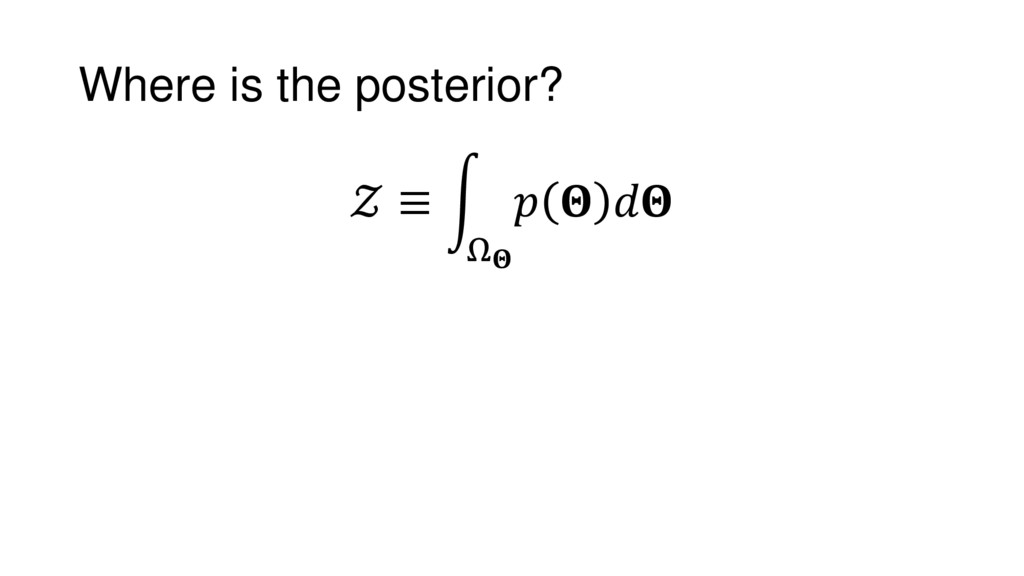{kind=link}
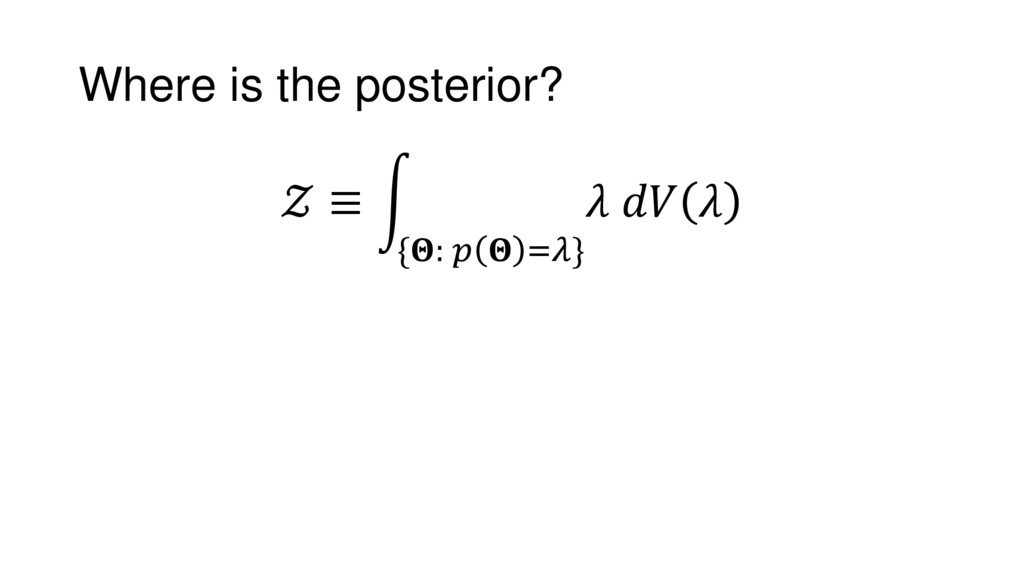{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}