} DDL 検索基盤スキーマ(json) ES Index Mysqlへ Elasticsearchへ PUT _mapping API PUT _settings API Rolling restart ALTER TABLE indexするか|storeだけするか 文字列型ならアナライザを決める 検索対象なのか格納するだけなのか 追加するフィールドの型を決める boolean, integer, long, float, date, string 社内製アナライザ(kuromoji移行中?) 前提として ◦ フィールド追加時に決めること
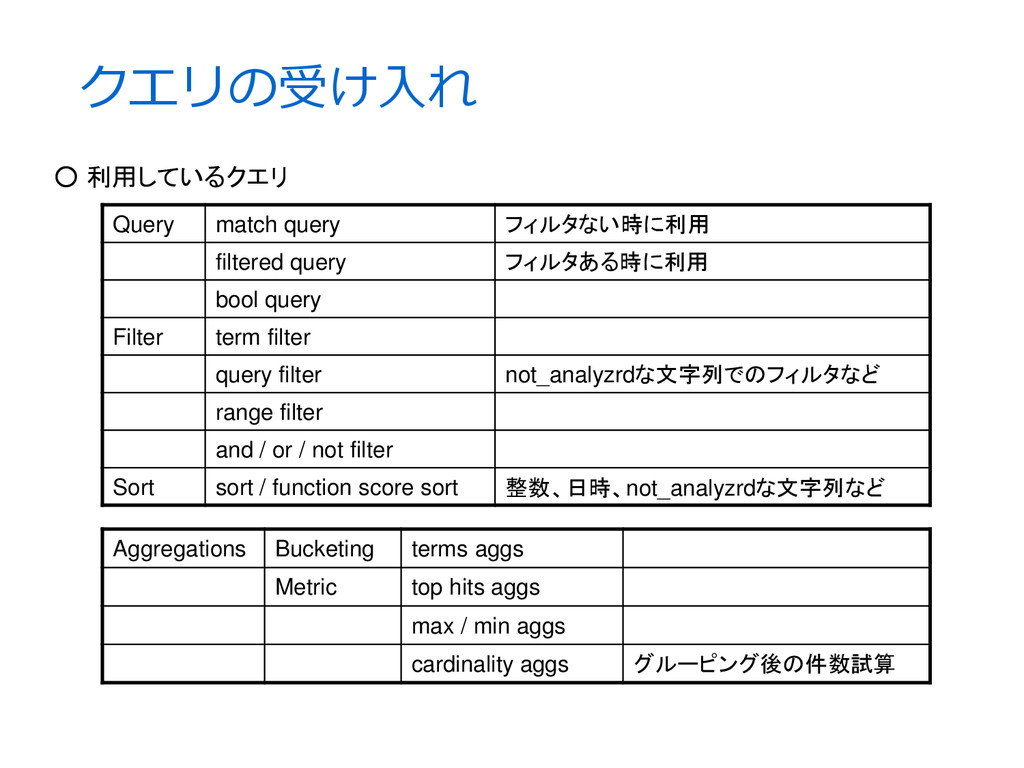
bool query Filter term filter query filter not_analyzrdな文字列でのフィルタなど range filter and / or / not filter Sort sort / function score sort 整数、日時、not_analyzrdな文字列など Aggregations Bucketing terms aggs Metric top hits aggs max / min aggs cardinality aggs グルーピング後の件数試算
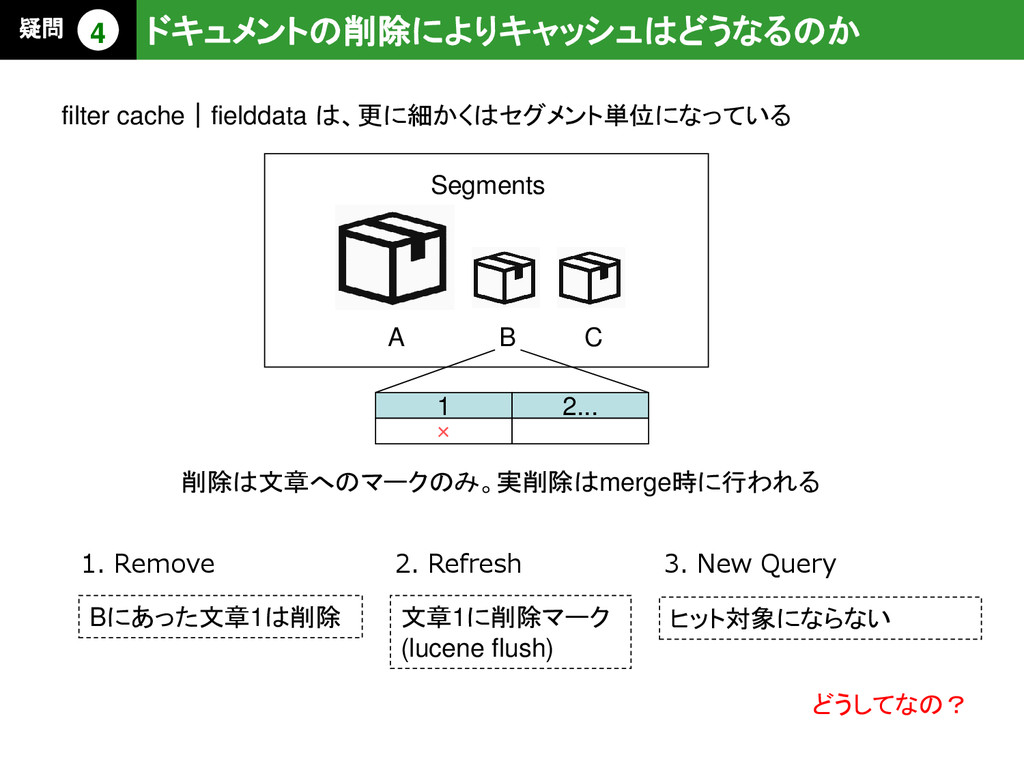
– 転置インデックスは単語からdoc idを探すのは得意だけど、逆にdoc idから単語 を取得するのが苦手なので、キャッシュに持つ • field valuesやシャードを跨いだGlobal ordinalsという序数を持つ – 容量は大きく、文字列フィールドだと1フィールドで500MBを超えることもある • デフォルトのフォーマットでは問い合わせ時にメモリ上に作成される – メモリに置かずかつ高速なdoc valueというフォーマットもあるが、まだデフォ ルトにはなってない – こちらはLUCENE 4.0で追加されたDocValuesを利用しているとのこと – デフォルトと違いIndex時に作成されるらしい なぜfilterやsortは、二回目の方が早いのか 疑問 2 f i e l d d a t a と は
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
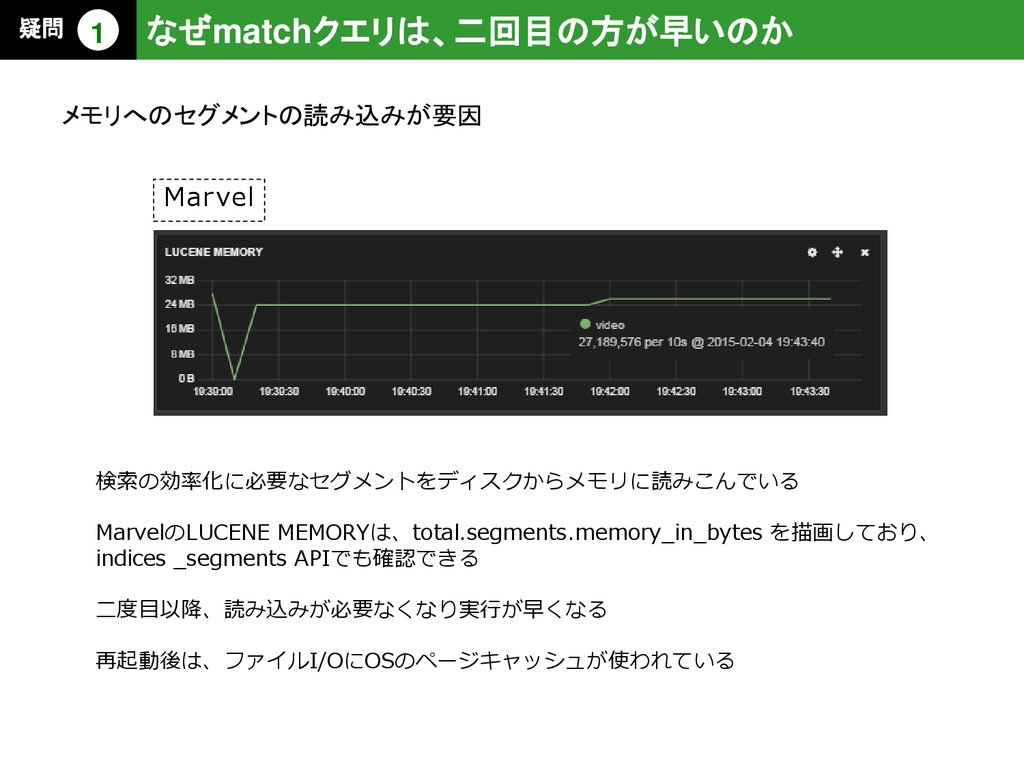{kind=link}
{kind=link}
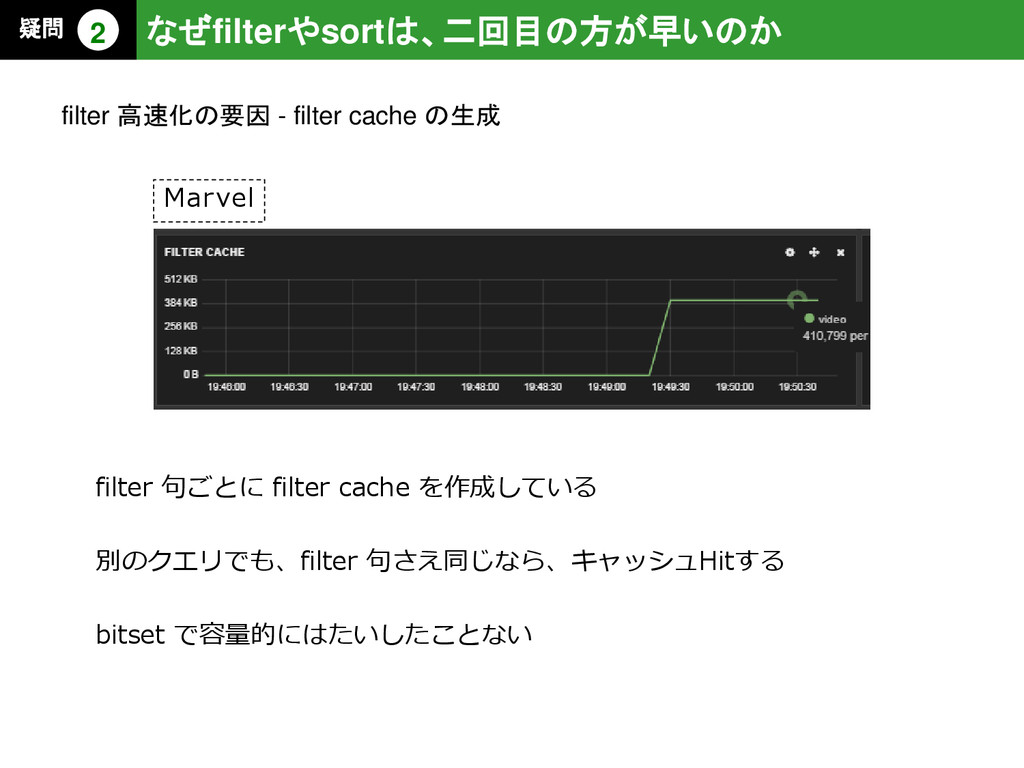{kind=link}
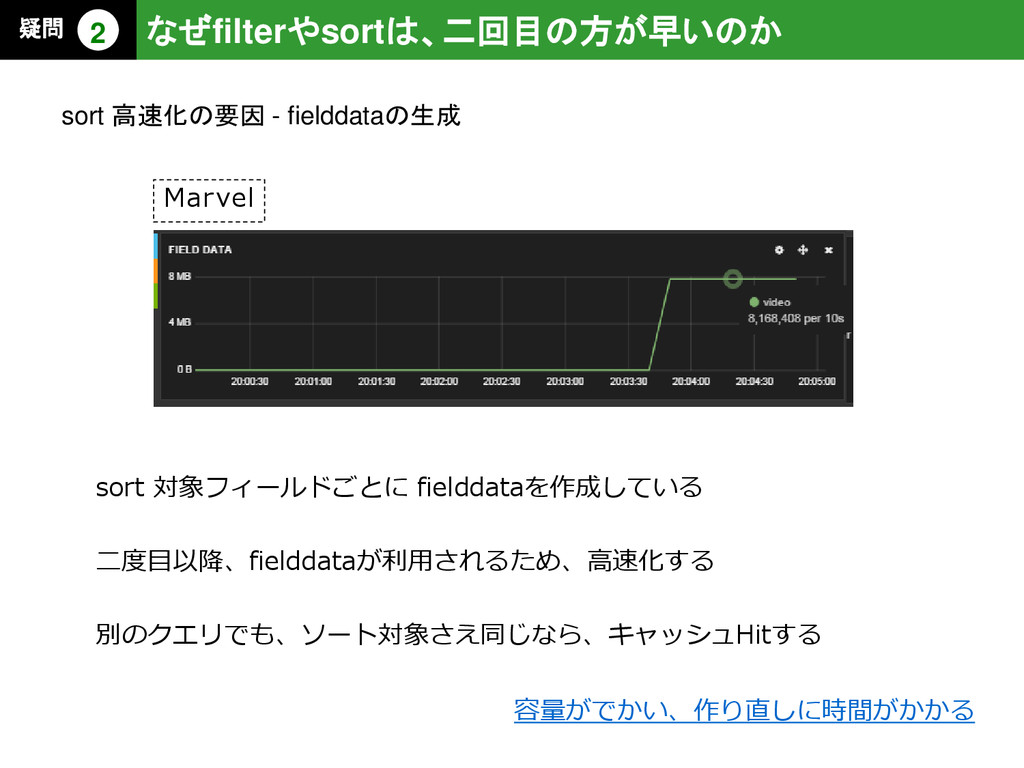{kind=link}
{kind=link}
{kind=link}
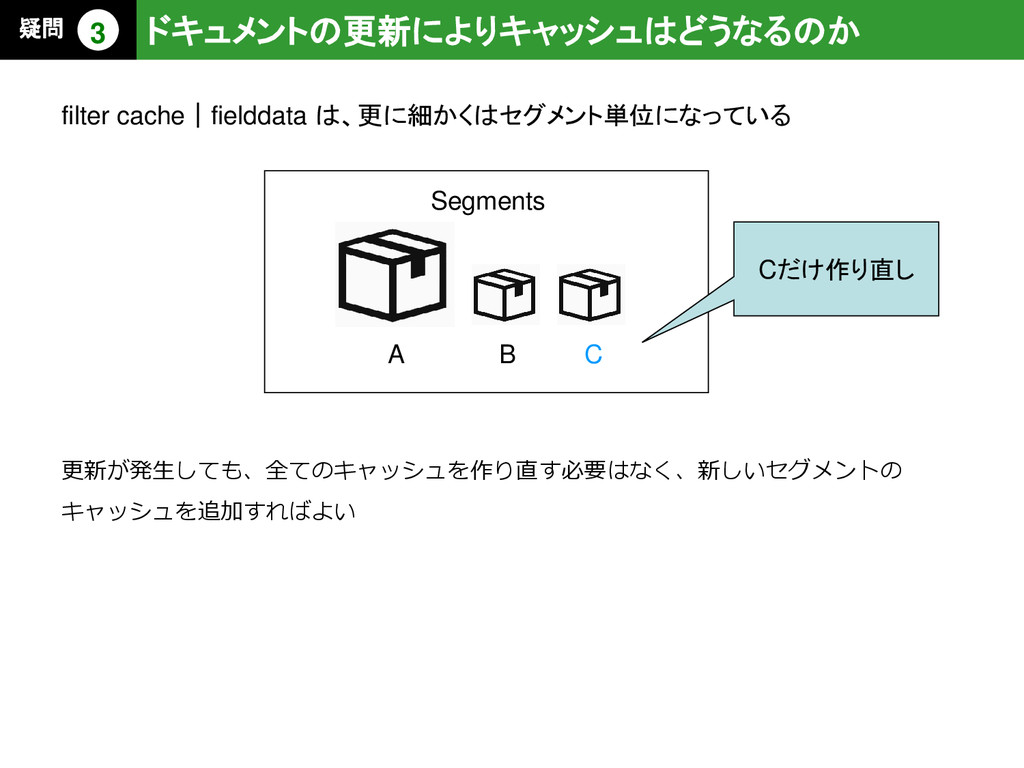{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}