Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第65回コンピュータビジョン勉強会
Search
TSUKAMOTO Kenji
November 14, 2025
Technology
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第65回コンピュータビジョン勉強会
TSUKAMOTO Kenji
November 14, 2025
More Decks by TSUKAMOTO Kenji
See All by TSUKAMOTO Kenji
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
130
第64回コンピュータビジョン勉強会@関東(後編)
tsukamotokenji
0
340
DynIBaR (第60回CV勉強会@関東)
tsukamotokenji
0
270
DeepSFM: Structure from Motion Via Deep Bundle Adjustment
tsukamotokenji
2
650
第三回 全日本コンピュータビジョン勉強会(後編)
tsukamotokenji
1
1k
Other Decks in Technology
See All in Technology
はじめてのWDM
miyukichi_ospf
1
140
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.2k
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
13
2.1k
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
230
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.8k
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3k
公式ドキュメントの歩き方etc
coco_se
0
110
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
210
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
740
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
220
Featured
See All Featured
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
The SEO Collaboration Effect
kristinabergwall1
1
500
Design in an AI World
tapps
1
260
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
The Limits of Empathy - UXLibs8
cassininazir
1
470
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Mind Mapping
helmedeiros
PRO
1
280
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Transcript
第65回コンピュータビジョン勉強会@関東 ICCV2025読み会 2025/11/16 1
紹介論文 Vision-Language-Actionにおいて4つのアフォーダンスによる推論とstep-by-stepでの 画像・言語の中間出力を元に動作生成を行う。 2
Robot Armでのタスク実施方法 Robot Armは人が設定した動作(Teaching)を繰り返し行う • 特定の動作・作業を行わせるよう設定するため、 人側の作業負荷が大きい • 環境が変わらない状態で動作 →VLA(Vision
Language Action Model)を使って言語で指示・動作生成を自動で行う 3
Vision-Language-Action Model Vision-Language-Action Model(VLA)は、視覚と言語の多モーダル入力を処理し、ロボットの行動を制御す るための基盤モデル 1. 視覚処理(Vision):カメラ・センサーなどの視覚情報から物体認識・空間認識・シーン理解を行う。 2. 言語理解(Language):自然言語による指示や説明を理解し、意味を解釈する。 3.
行動生成(Action):視覚情報と言語指示に基づいて、適切な物理的行動を計画し実行する。 これらの要素が統合され、 End2Endで学習・実行されることで適応性の高い制御が可能 π0 AutoRT 例: 4
Pick&Placeをする上で重要なこと タスク目標達成のために、ロボットが環境を理解すること 1. Object:相互作用の対象となる物体とその視野内での位置を特定 2. Grasp:物体の最適な把持点や表面を評価し、確実かつ安定した把持を実現 3. Spatial:配置のための空きスペースなどを満たす座標系の特定 4. Movement:現実世界において致命的な損傷を回避するには、衝突せずにロボットが移動する経路を
予測 タスクを完了するためには安全性を確保した軌跡に沿って実行することが求められる。 5
Affordance Affordance:心理学において物体や環境が人に提示する行為の可能性 対象物体によって把持(持ち方)、動作が生成される ロボットにAffordanceを取り入れるという研究はこれまでにもある ポット→水を注ぐ ハンマー→くぎを打つ 6
関連研究 RobotにおけるAffordance • 典型的な例ではアフォーダンスは対象物の機能として定義され、対象物の本質、操作方法、目標物と の空間的関係を含み、観察と行動を直接的に関連付ける。 ◦ セグメンテーション、キーポイント、画像特徴量から 6DOF把持推定 ◦ Robopoint:画像+指示文からVLMで動作(掴む・置く場所)を出力
◦ RT-Affordance:ロボットのPoseを事前に推定し、VLMに用いる ◦ TraceVLA:視覚的な軌跡(トレース)を画像上に追加入力として取り込む 言語と制御 • 中間ステップを出力する LLMをロボット制御(サブタスクへの分解・動作生成)に活用 ◦ Chain-of-Thougt:いくつかの「途中式 (step-by-stepの思考過程)」を例示してモデルに与える ◦ Embodied CoT:動作生成前に複数ステップの思考過程を階層的テキストで生成。「掴む物体の 座標はどこか」などを言語で明示 7
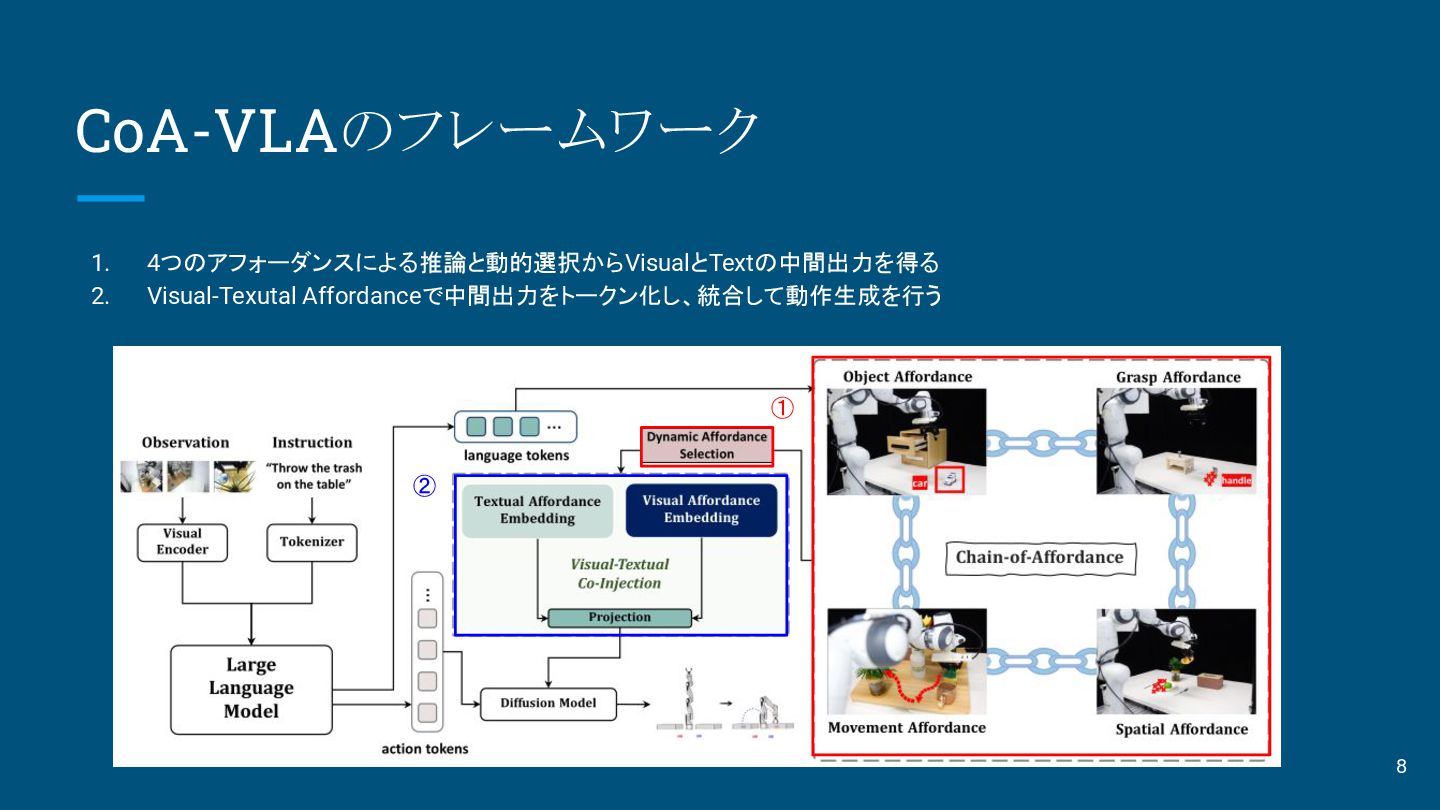
1. 4つのアフォーダンスによる推論と動的選択からVisualとTextの中間出力を得る 2. Visual-Texutal Affordanceで中間出力をトークン化し、統合して動作生成を行う CoA-VLAのフレームワーク ① ② 8
Chain-of-Affordance VLMとPick&PlaceにおいてAffordanceを統合 1. Object Affordance:2つの機能を統合 意味的識別:Text Tokenからオブジェクト名解決(お茶を注ぐ→ポット) 空間的グラウンディング:画像中のオブジェクト位置 2. Grasp
Affordance:物体が操作可能な機能や方法を包括する概念で、物体の 把持点を表す 3. Spatial Affordance:ロボットが3D環境内の空間的関係を解釈・推論する能力 で、物体配置やナビゲーションのための衝突フリー領域の特定などを実現 4. Movement Affordance:タスク遂行中の軌道を定義、障害物などの環境変化 に動的に対応してタスクを完了させる Dynamic Affordance selection:objectとgraspは状況に応じて推論しない アフォーダンスをTextとVisualの組み合わせで中間出力する 9
Visual-Textual Affordance VisualとText情報の中間出力の例 Text Visual 10
Visual-Textual Affordance • Textual Affordance:物体の情報、把持位置、空きスペース座標等の情報を自然言語記述子にマッピ ング • Visual Affordance:座標マーカーや運動軌跡を過去の観測フレーム上に重ねて符号化 •
Visual-Textual Co-injection:各affordanceをトークン化してDiffusionModelの入力とする ◦ Text:VLMモデルの最終埋め込みを用い、 MLP層を追加してトークン化 ◦ Visual:ViTでパッチトークン化 11
学習データ生成 各シナリオシーンをモデル化 • 物体情報 • 空間データとそれに対応するコンテキスト • グリッパの軌跡をデータ化 データ生成パイプライン 1.
LLM(GPT-4o)で言語指示からシーンの詳細なコンテキストを作成 2. Grounding DINOv2とSAMでObjectのbounding boxを作成、グリッパ位置もデータ化 3. RoboPointで空間アフォーダンスの作成。 4. 空間アフォーダンスとシーンコンテキストのラベル対応をつけ、外れ値は除去 5. グリッパ位置をCoTrackerで追跡して軌跡データとする 12
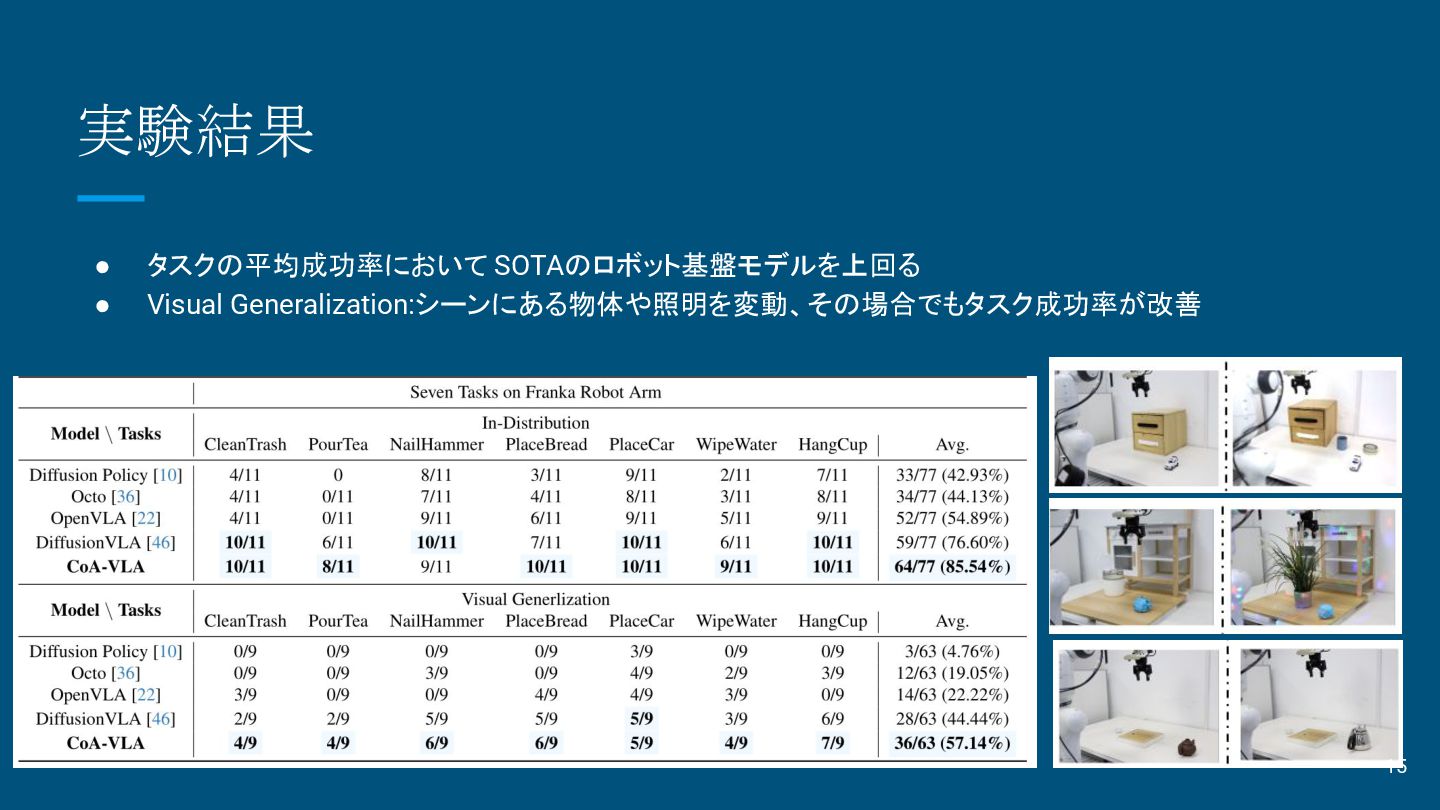
実験 • 実験環境:Franka6自由度アーム、ステレオカメラ (ZED)2台、手首カメラ(D435i)1台 • 学習データ:Droid Dataset(39Kセットの軌跡データ)と CoA用の軌跡データ692セット • アルゴリズム:Diffusion
VLAをベース • 比較:Diffusion Policy, Octo, OpenVLA, TinyVLA, Diffusion VLA ◦ 全モデルは同一データセットで Fine-Tuning アームとステレオカメラ(赤と青)と手首カメラ 13
実験タスク7種 1. PlaceCar:車を引き出しにいれ、引き出しを閉める 2. PlaceBread:パンを皿の空きスペースに置く 3. CleanTrash:ゴミをゴミ箱に捨てる。植木鉢の有無 の2シナリオ 4. NailHammer:ハンマーで釘を打つ。
5. PlaceCup:コップをラックにかける。 6. PourTea:ティーカップをトレイに置き、ティーポット を持ち上げてティーカップにお茶を注ぐ。 7. WipeWater:スポンジを使用し、多数の障害物を 回避しながらテーブルを拭く。 14 Video
実験結果 • タスクの平均成功率において SOTAのロボット基盤モデルを上回る • Visual Generalization:シーンにある物体や照明を変動、その場合でもタスク成功率が改善 15
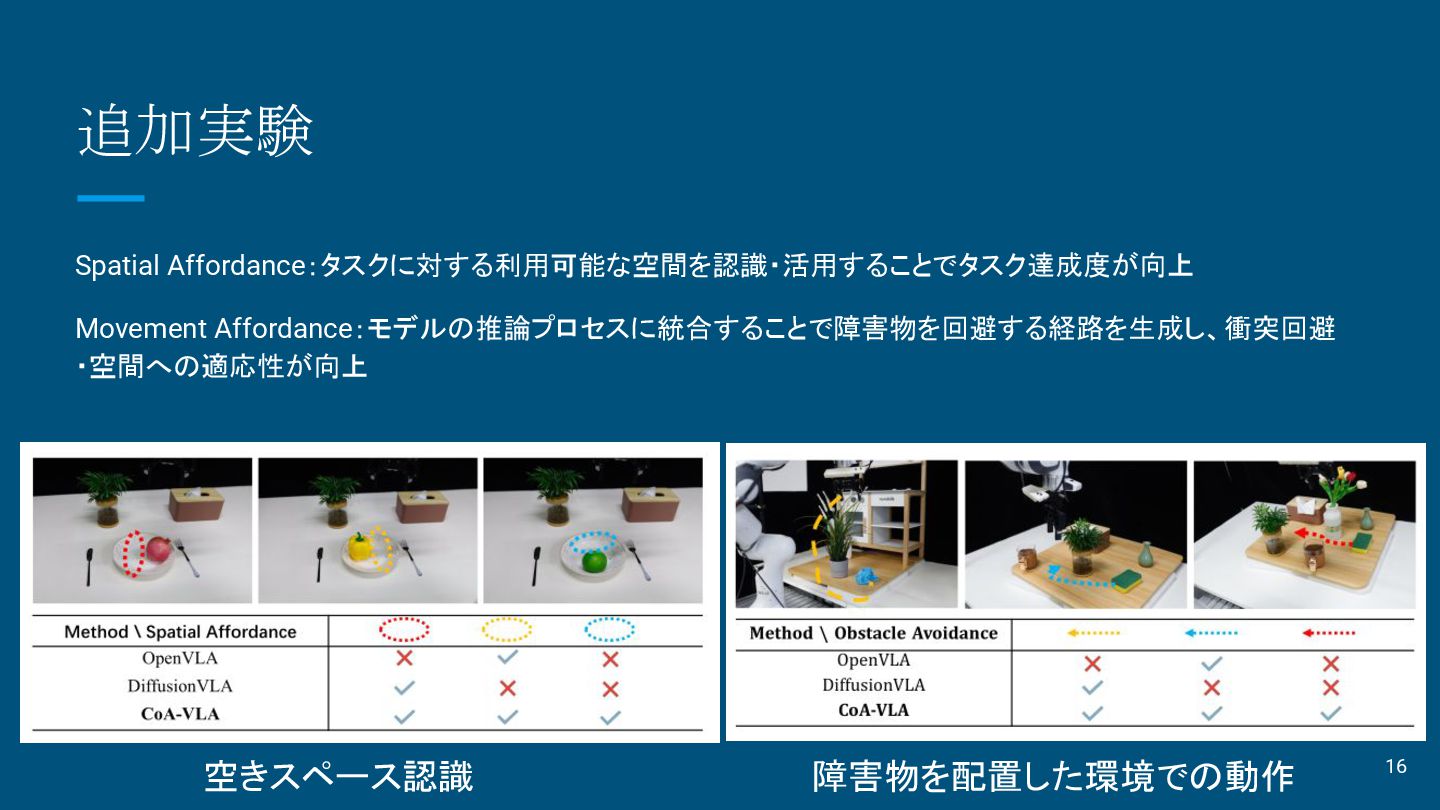
追加実験 Spatial Affordance:タスクに対する利用可能な空間を認識・活用することでタスク達成度が向上 Movement Affordance:モデルの推論プロセスに統合することで障害物を回避する経路を生成し、衝突回避 ・空間への適応性が向上 空きスペース認識 障害物を配置した環境での動作 16
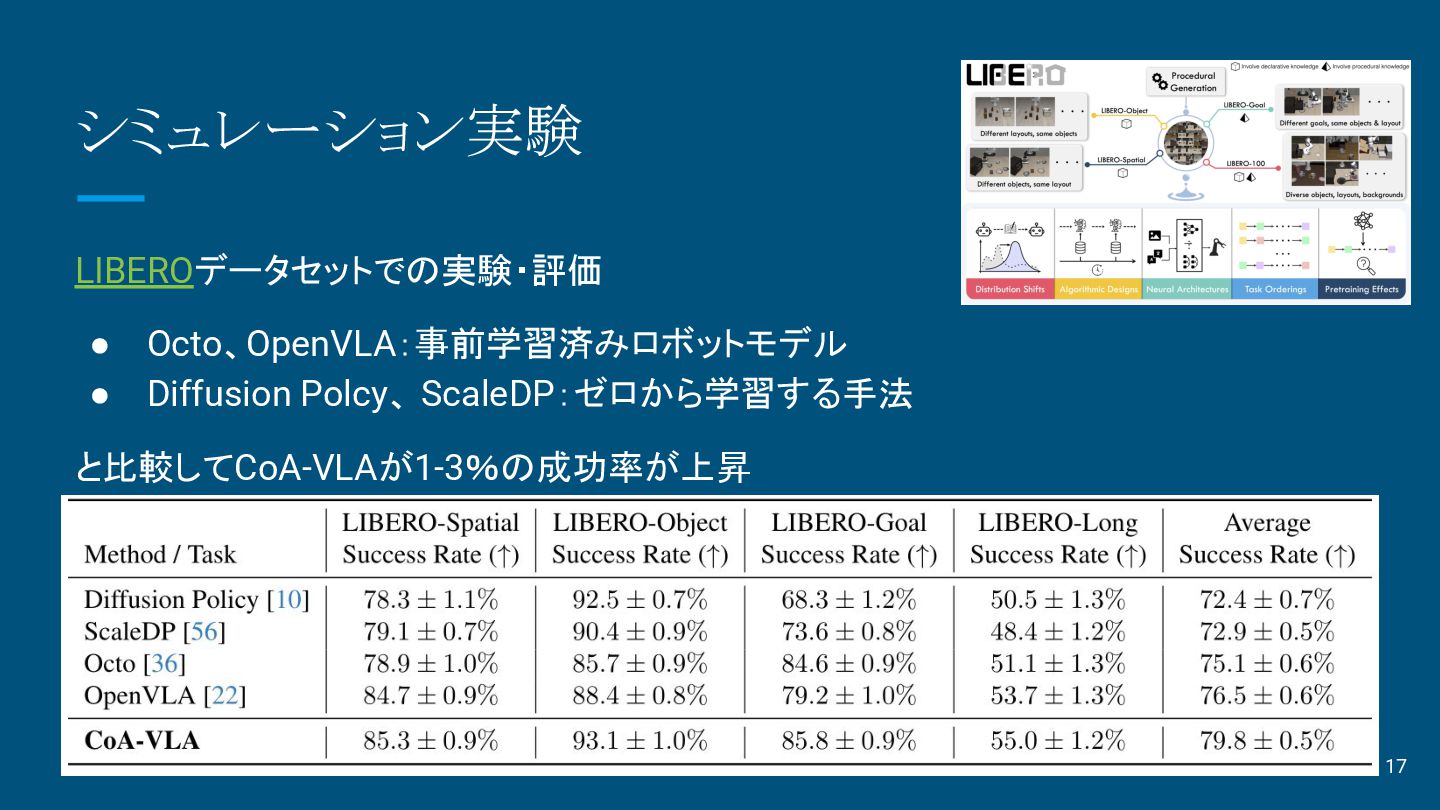
シミュレーション実験 LIBEROデータセットでの実験・評価 • Octo、OpenVLA:事前学習済みロボットモデル • Diffusion Polcy、 ScaleDP:ゼロから学習する手法 と比較してCoA-VLAが1-3%の成功率が上昇 17
まとめ 論文の内容 • CoA-VLAはアフォーダンスによる推論・VisualとText情報を中間出力し、それらを用いて動作 生成を行う ◦ シーンへの汎化性があり、把持・障害物回避などの改善もできる 感想 • step-by-stepで推論・動作生成をした方ががよくなるのはわかる
• Affordanceと言ってるが事前知識を取り入れているのと変わらない ◦ Affordanceや中間出力に引きずられる可能性がありそう(トレードオフ?) • 学習データが複雑化・多様化するのが懸念点 ◦ BBox、空間データ、コンテキストが必要になっている 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}