This talk is part use-case and part intro into BigQuery.
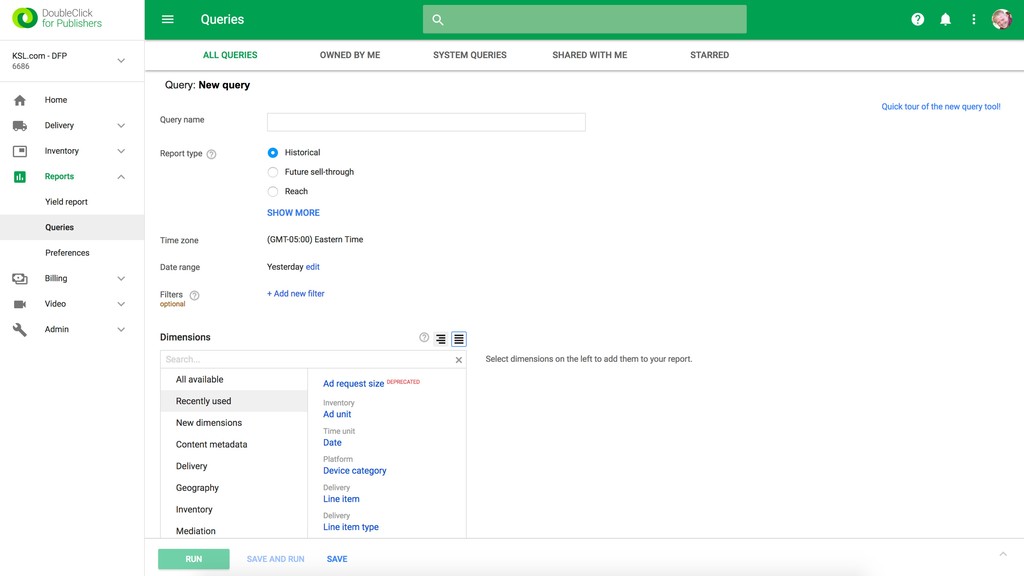
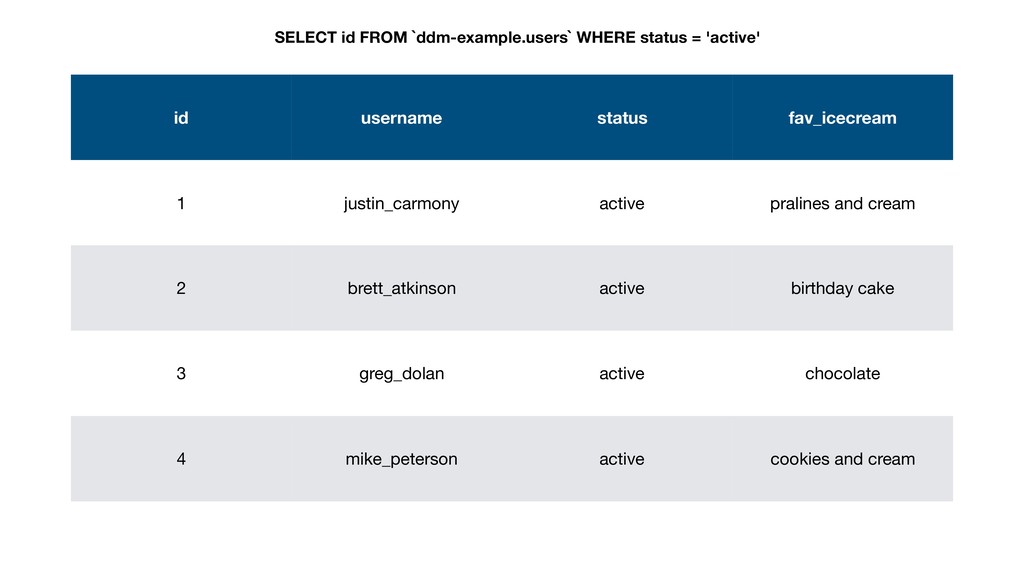
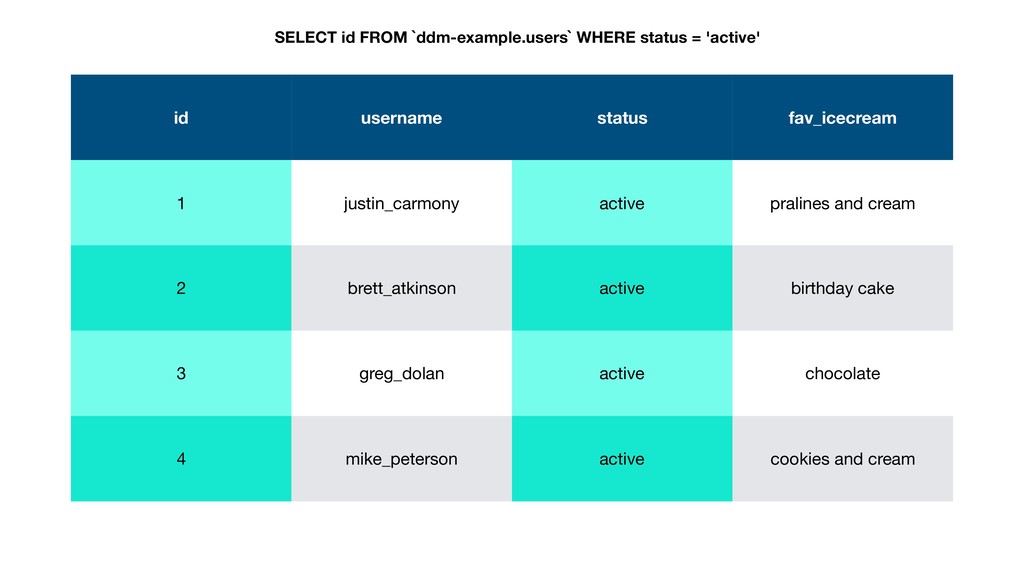
Three years ago Deseret Digital Media had a serious problem: it had a lot of data in Google Analytics and Google Ad Manager (then called DFP), but couldn't run the in-depth analysis needed because of limitations with their reporting tools. They had crucial questions they couldn't answer, so they did what everyone else was doing: just guessing and hoping for the best.
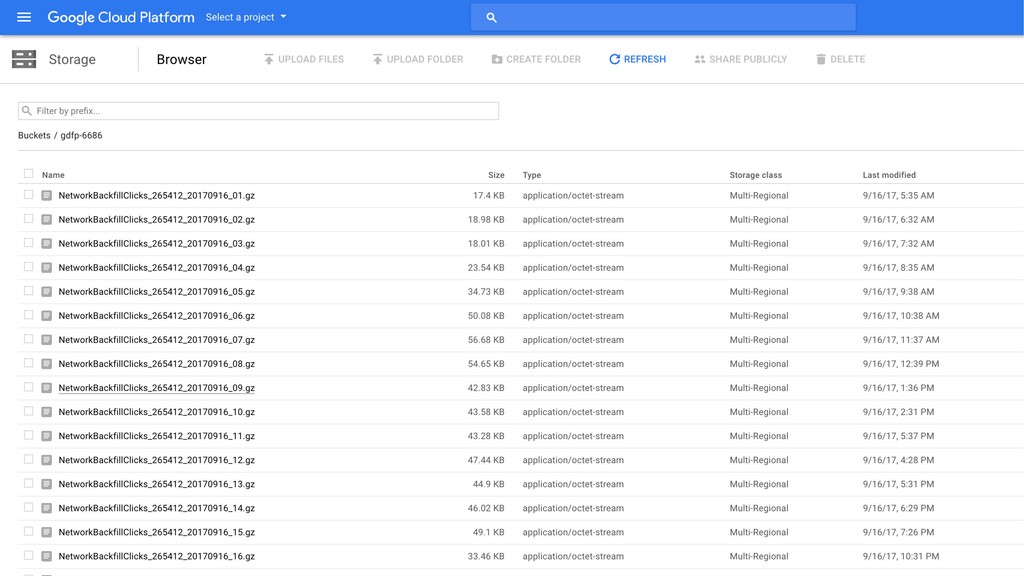
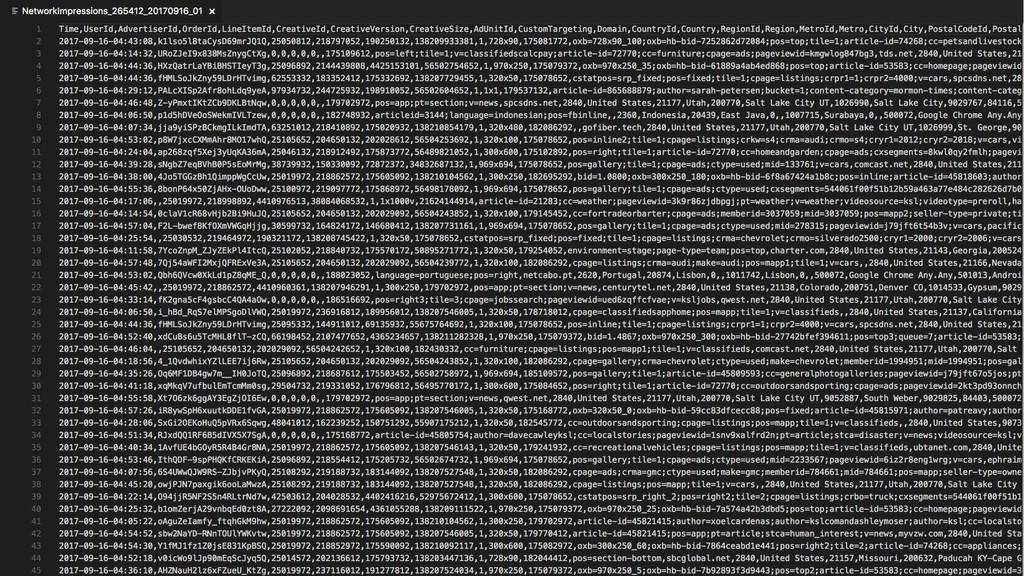
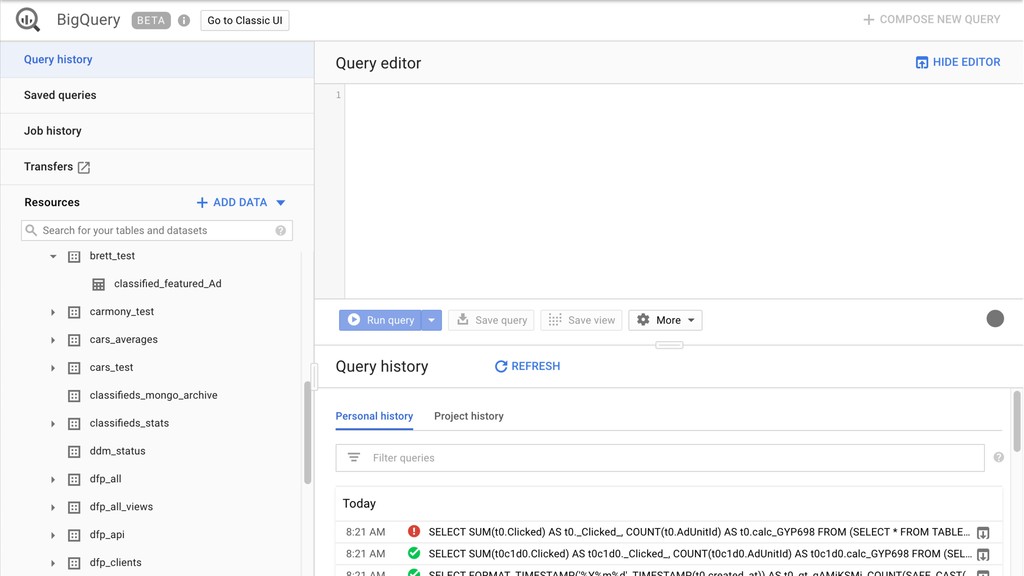
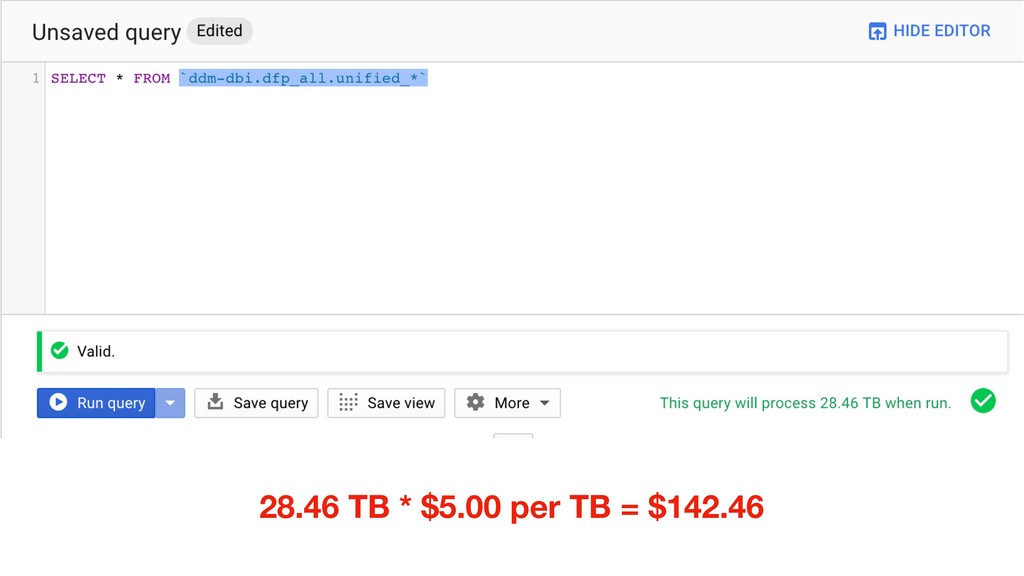
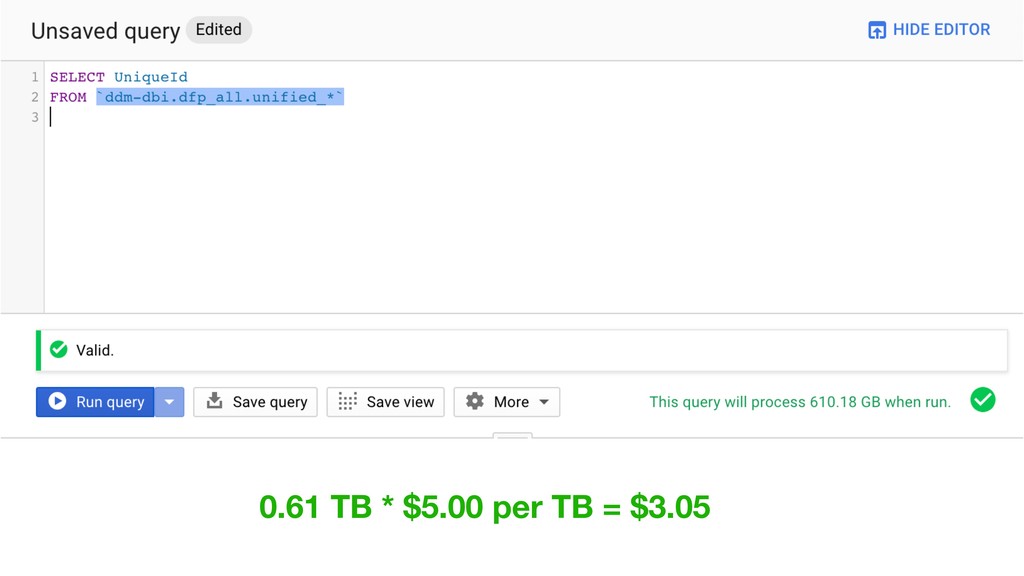
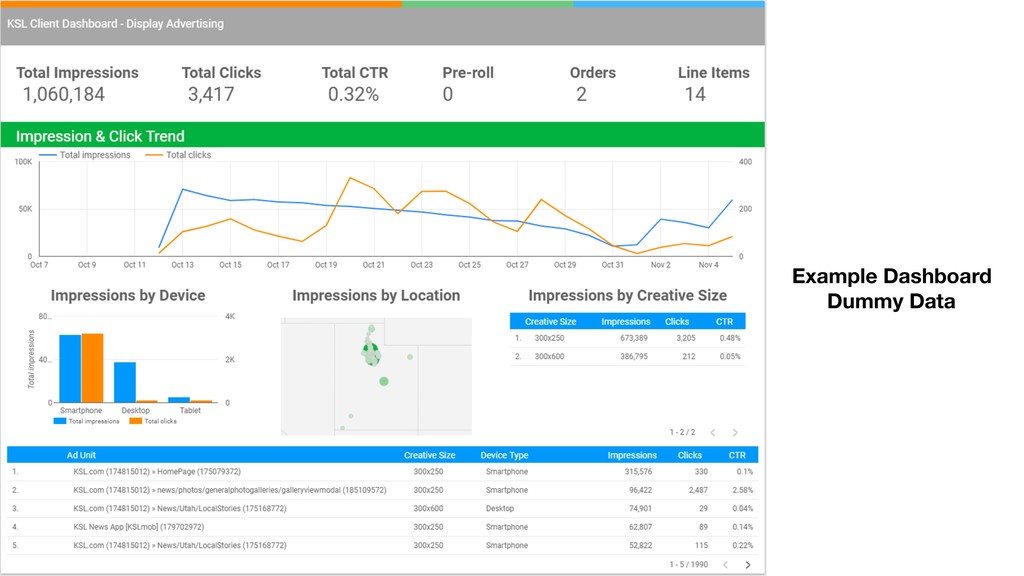
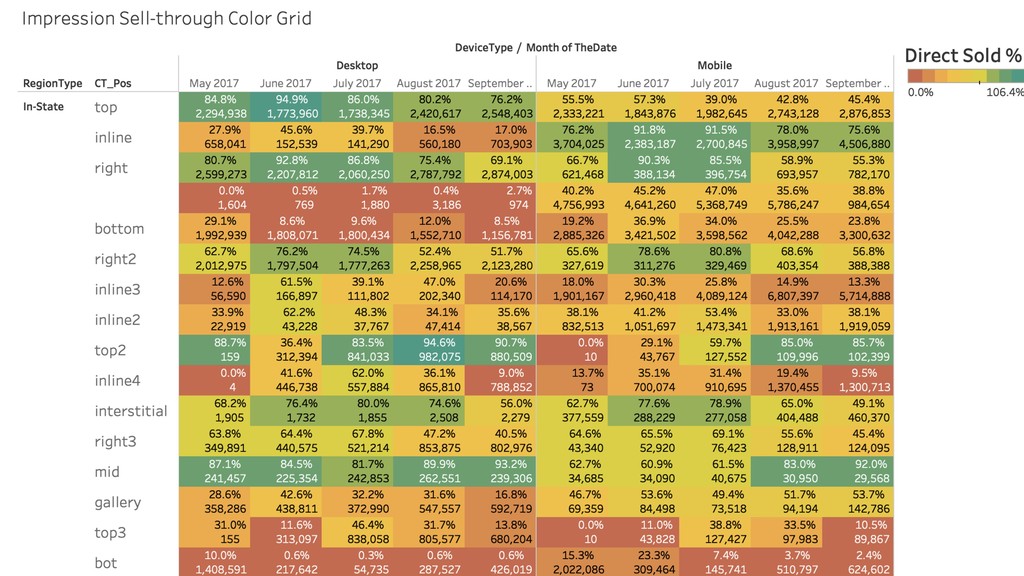
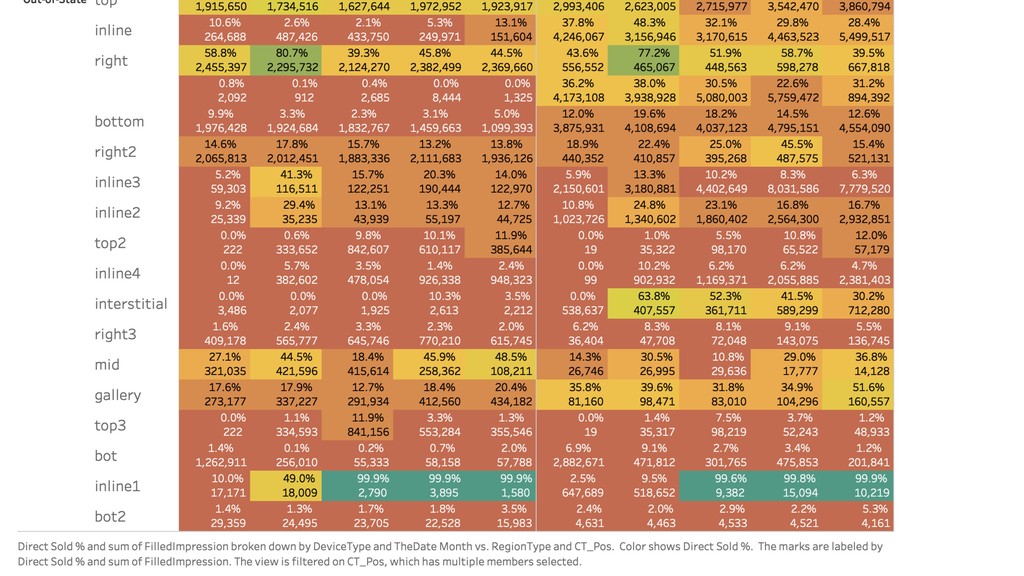
Then one day Justin discovered BigQuery and the rest is history. Without having to create an entire data warehousing team, Justin was able to ingest 30 GB of data a day into BigQuery easily. They went from vague reports to perfectly precise queries. Not only that, but DDM's reports ran incredibly fast. They soon hooked up BigQuery data with Data Studio and provided insights to the entire company.
Justin will cover the basics of BigQuery and talk about the best strategies of how to get started with it. BigQuery is fast, simple, and affordable, and you're going to love learning more about it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}