Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Spark 簡單教學
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Kyle Bai
June 18, 2015
Technology
65
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Spark 簡單教學
Kyle Bai
June 18, 2015
More Decks by Kyle Bai
See All by Kyle Bai
讓 Jenkins 老爺爺掌舵帶領開發者航向美好新世界
kairen
1
270
AWS Startup 2020 - AMIS
kairen
0
94
學習 Kubernetes 不是為了成為 YAML Engineer
kairen
0
370
How to make your container:Kubernetes is a bit more secure
kairen
0
230
Vishwakarma: Terraform modules for deploying EKS and Self-hosting Kubernetes(AWS))
kairen
0
110
Vishwakarma: Terraform modules for deploying EKS and Self-hosting Kubernetes
kairen
0
130
Chatbot as a Service on Container(Kubernetes)
kairen
0
1k
IT IRONMAN 2020
kairen
0
110
Advanced Kubernetes For UMC
kairen
0
190
Other Decks in Technology
See All in Technology
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
540
GoでCコンパイラを作った話
repunit
0
150
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
460
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
230
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
940
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
620
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
170
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
Power Automateアップデート情報
miyakemito
0
100
Featured
See All Featured
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Un-Boring Meetings
codingconduct
0
350
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
410
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Transcript
SPEAKER: KYLE.BAI 連 胖子 也想泡 唷 乾 偶腰回夾了了拉
什什麼是Spark ? !2 Apache Spark是⼀一個開源叢集運算框架,最初是由加州⼤大學柏克萊分校AMPLab所開發。相對於 Hadoop的MapReduce會在執⾏行行完⼯工作後將中介資料存放到磁碟中,Spark使⽤用了了記憶體內運算技 術,能在資料尚未寫入硬碟時即在記憶體內分析運算。
巨量量資料處理理架構 • 重複⼯工作:許多專有系統在解決同樣問題,如分散式作業以及容錯。 舉例例,⼀一個分散式的 SQL 引擎或⼀一個機器學習系統都需要實現平⾏行行聚 合。這些問題在每個專有系統中會重複地被解決。 • 組合問題:在不同系統之間進⾏行行組合計算是費⼒力力⼜又不討好的事情。對 於特定的⼤大數據應⽤用程式⽽而且,中間資料集是非常⼤大的,⽽而且移動的
本也非常⾼高,⽬目前環境中採⽤用副本機制,將資料複製到穩定儲存系統 (HDFS),以便便在不同引擎進⾏行行分享。但這樣往往比運算花費代價要 ⼤大許多。 !3
巨量量資料處理理架構 • 適⽤用範圍的限制:如果⼀一個應⽤用不適合⼀一個專有的計算系統,那麼使 ⽤用者只能換⼀一個系統,或重新定義⼀一個新的計算系統。 • 資源設定:在不同計算引擎之間進⾏行行資源的動態共⽤用是比較困難的。 因為⼤大多數計算引擎都會假設它們在程式執⾏行行結束之前擁有相同的機 器節點的資源。 • 管理理問題:對於多個專有系統,需要花費更更多時間與精⼒力力來來管理理與部
署。我們終端使⽤用者,要學習多種API與系統模型。 !4
Hadoop 問題點 !5 • 我們都知道 Google 的 MapReduce,他是⼀一個簡單通⽤用與⾃自動容錯的批次處 理理計算模型。http://static.googleusercontent.com/media/research.google.com/ zh-TW//archive/mapreduce-osdi04.pdf
• 由於 Hadoop 很多⼦子專案都繼承 MR 模型,對於其他類型計算,諸如互動式 與串串流式計算,並不適合被拿來來使⽤用。導致⼤大量量不同於 MR 的專有資料處理理 模型出現,Ex:Storm、Impala與GraphLab。 • 然⽽而隨著新模型的不斷出現,似乎對於巨量量資料處理理⽽而⾔言,不同類型的作業 應該需要⼀一系列列不同的處理理架構才可以極佳地完成。但是這些專有系統也有 ⼀一些不⾜足之處。
Spark 巨量量資料處理理架構 !6 • Spark 採⽤用⼀一個 RDD 概念念(⼀一種新的抽象的彈性資料集),在某種程度上 Spark 是對
MapReduce 模型的⼀一種擴充。 • 主要是把 MR 不擅長的計算⼯工作(反覆運算、互動式與串串流式)進⾏行行改善,並提 出⼀一個統⼀一的引擎。 • 因為 MR 缺乏⼀一種特性,就是在平⾏行行計算的各個階段劑型有效的資料共⽤用,這種 共⽤用就是 RDD 的本質。利利⽤用這種本質來來達到這些運算模式。 • 在叢集處理理的容錯⽅方式,不像Hadoop與 Dryad將計算建置成⼀一個無環圖的⼯工作 集。
RDD 表達能⼒力力 !7 • 反覆運算演算法:這是⽬目前專有系統實現比較普遍的應⽤用 場景,⽤用於圖型處理理與機器學習。RDD 能夠極佳的實現這 些模型,包含Pregel、HaLoop、GraphLab等模型。 • 關連式查詢:對
MR 來來說非常重要的需求就是SQL查詢, 包含長期執⾏行行、數⼩小時的批次處理理作業與互動式查詢。在 MR 上有其內在缺點,如其容錯的模型⽽而導致速度很慢。利利 ⽤用RDD實現許多通⽤用的資料庫引擎特性,使效能提升。
RDD 表達能⼒力力 !8 • MapReduce 批次處理理:RDD提供的介⾯面是 MR 的超集合,所以 RDD 可以
有效地執⾏行行與利利⽤用 MR 實現應⽤用程式,另外 RDD 還適合更更加抽象的以 DAG 為基礎的應⽤用程式,如 DryadLINQ。 • 串串流式處理理:⽬目前串串流式系統只提供有限容錯處理理,需要消耗系統非常⼤大的 複製代價與非常長的容錯時間。然⽽而 RDD 實現⼀一個新的模型—離散資料流程 (D-Stream),D-Stream 將串串流計算當作⼀一系列列的短⼩小的批次處理理操作,⽽而 非常駐有狀狀態的操作,將兩兩個離散串串流之間的狀狀態存在RDD中。並允許 RDD 的繼承關係圖(Lineage)進⾏行行平⾏行行性的恢復,⽽而不需要進⾏行行資料複製。
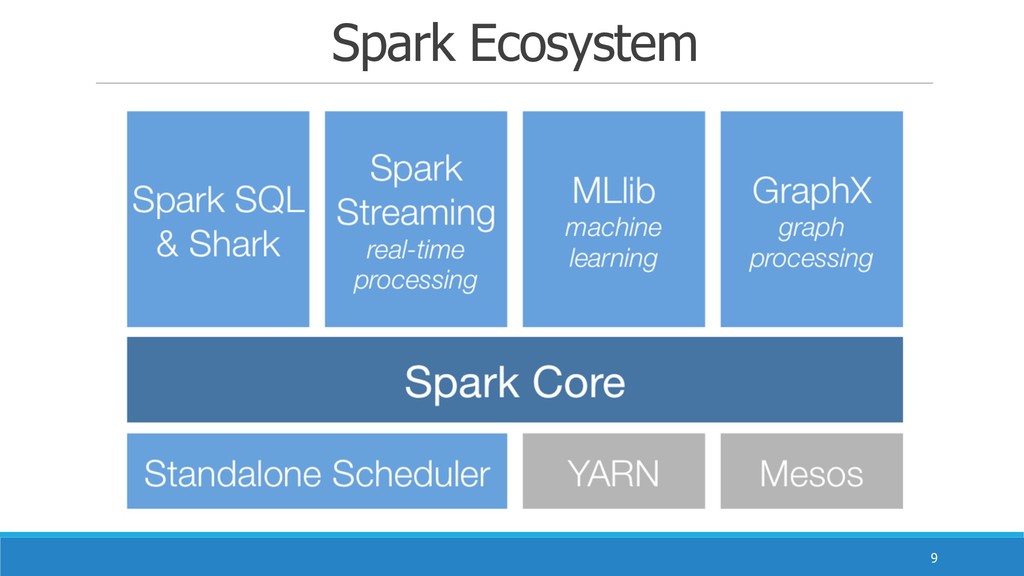
Spark Ecosystem !9
處理理的基本情況 !10 我們可以將巨量量資料處理理分為以下三種情況: • 複雜的批次資料處理理(batch data processing):時間長,跨度為 10min - N
hr。 • 以歷史資料為基礎的互動查詢(interactive query):時間通常為 10 sec - N min。 • 以即時資料流為基礎的資料處理理(streaming data processing):時間 通常為 N ms - N sec。
Spark ⼦子專案對應 !11 • Spark Core:以 RDD 提供了了豐富的基礎操作介⾯面,利利⽤用 DAG 進⾏行行統⼀一
⼯工作規劃,使 Spark 能夠靈活地處理理類似 MR 的批次作業。 • Spark SQL:相容 Hive 介⾯面 HQL,提供比 Hive 更更好查詢速度(10 - 100 x)的分散式 SQL 引擎。 • Spark Streaming:將串串流式計算分解成⼀一系列列短⼩小的批次處理理作業,利利 ⽤用 Spark 輕量量級與低延遲時間的排程架構,來來⽀支援串串流處理理。⽬目前已⽀支援 資料源套件,Kafka、Flume、ELK、Twitter 與 TCP sockets等。
Spark ⼦子專案對應 !12 • GraphX:已 Spark 為基礎的圖形計算架構,相容 Pregel 與 GraphLab
介⾯面,增強圖型建置與圖的 轉換功能。 • MLlib:因為 Spark Core 非常適合於 反覆式運算,MLlib就是作為Spark的機器學習演算法函式 庫。已⽀支援分類、分群、關聯聯與推薦演算法。如以下: • 匯總統計、相關性、分層抽樣、假設檢定、隨機資料⽣生成 • 分類與回歸:⽀支援向量量機、回歸、線性回歸、決策樹、樸素⾙貝葉斯 • 協同過濾:ALS • 分群:k-平均演算法(k-mean) • 維度縮減:奇異異值分解(SVD),主成分分析(PCA) • 特徵提取和轉換:TF-IDF、Word2Vec、StandardScaler • 最佳化:隨機梯度下降法(SGD)、L-BFGS
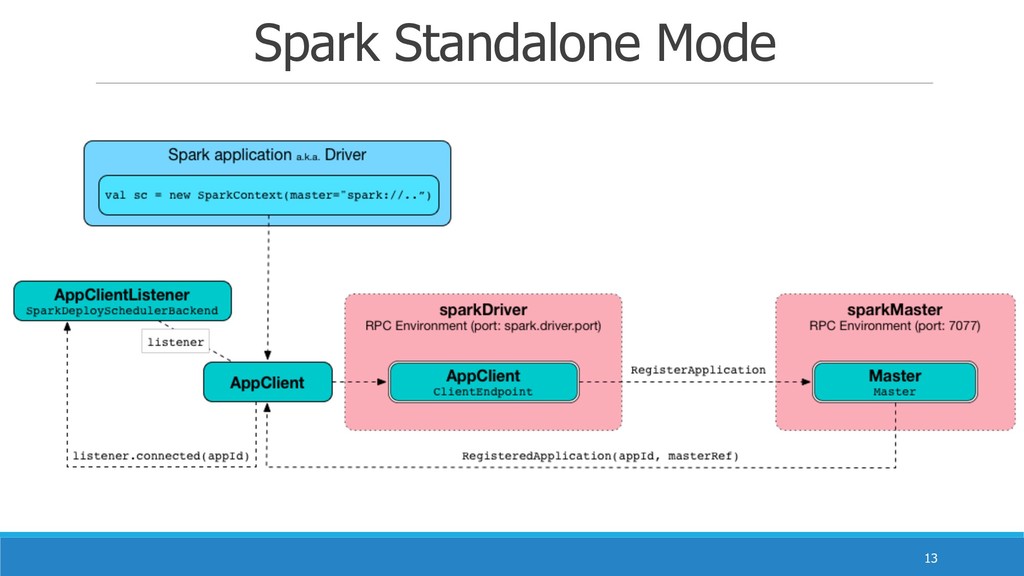
Spark Standalone Mode !13
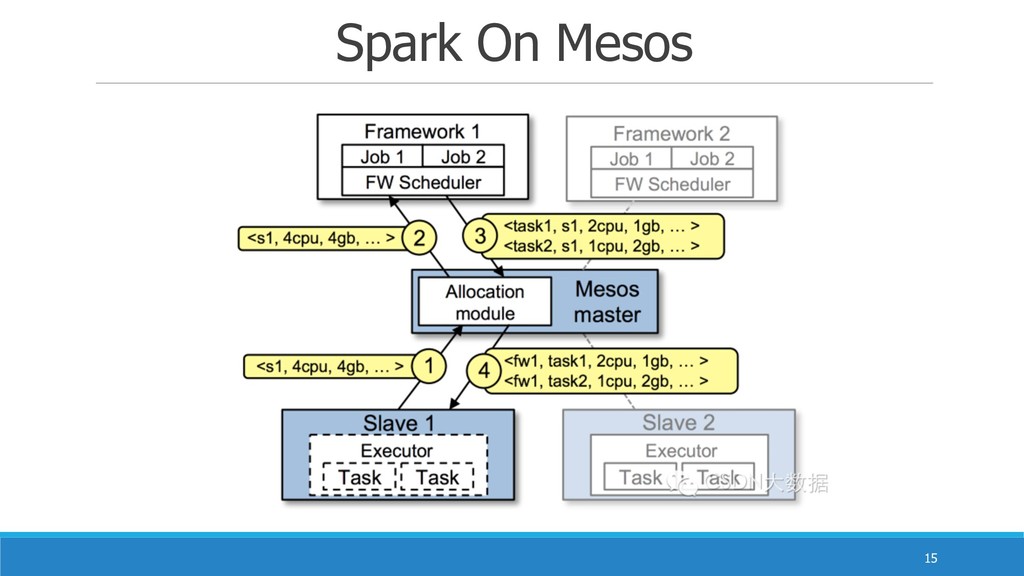
Spark On Mesos !14 是很多公司採⽤用的模式,官⽅方推薦這種模式(當然,原因之 ⼀一是⾎血緣關係)。正是由於Spark開發之初就考慮到⽀支持 Mesos,因此,⽬目前⽽而⾔言,Spark運⾏行行在Mesos上會比運⾏行行在 YARN上更更加靈活,更更加⾃自然。⽬目前在Spark On Mesos環境
中,⽤用⼾戶可選擇兩兩種調度模式之⼀一運⾏行行⾃自⼰己的應⽤用程序。 • 粗粒度模式(Coarse-grained Mode) • 細粒度模式(Fine-grained Mode)
Spark On Mesos !15
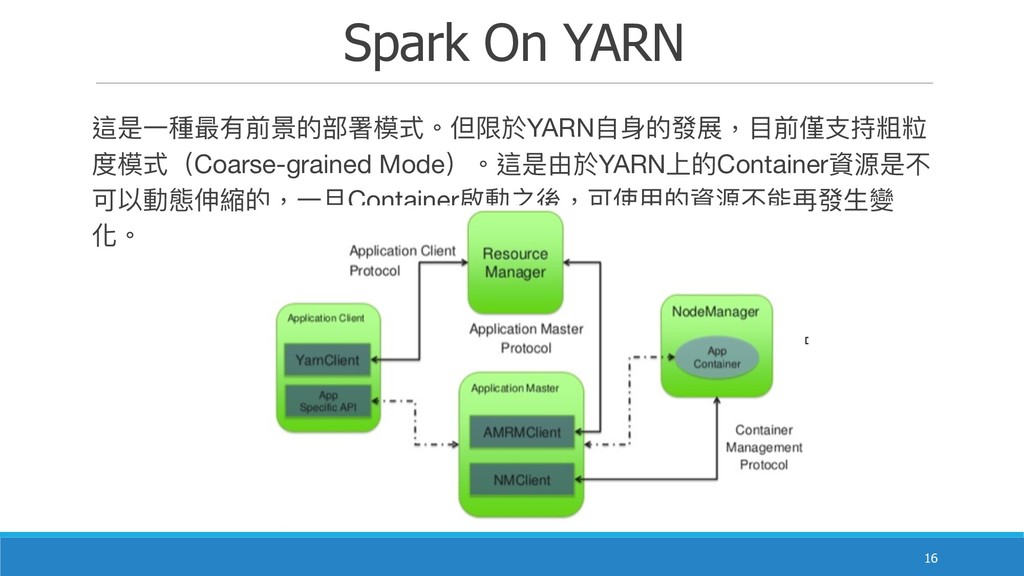
Spark On YARN !16 這是⼀一種最有前景的部署模式。但限於YARN⾃自⾝身的發展,⽬目前僅⽀支持粗粒 度模式(Coarse-grained Mode)。這是由於YARN上的Container資源是不 可以動態伸縮的,⼀一旦Container啟動之後,可使⽤用的資源不能再發⽣生變 化。
⽤用Spark做什什麼? !17 對⼯工程師⽽而⾔言,Spark提供了了⼀一個簡單的⽅方式在集群之間並⾏行行化這 些應⽤用,隱藏了了分佈式系統、網絡通信和容錯處理理的複雜性。系 統使得⼯工程師在實現任務的同時,有充⾜足的權限監控、檢查和調 整應⽤用。 API的模塊特性使得重⽤用已有⼯工作和本地測試變得簡單。 Spark⽤用⼾戶使⽤用Spark作為其數據處理理應⽤用,因為他提供了了豐富的 功能,易易於學習和使⽤用,⽽而且成熟可靠。
⽤用Spark有哪些好處? !18 • Java、Scala、Python 和 R APIs。 • 可擴展⾄至超過 8000
個結點。 • 能夠在記憶體內緩存資料集以進⾏行行互動式資料分析。 • Scala 或 Python 中的互動式命令列列介⾯面可降低橫向擴展資料探索 的反應時間。 • Spark Streaming 對即時資料串串流的處理理具有可擴充性、⾼高吞吐 量量、可容錯性等特點。 • Spark SQL ⽀支援結構化和和關聯聯式查詢處理理(SQL)。 • MLlib 機器學習演算法和 Graphx 圖形處理理演算法的⾼高階函式庫。
!19 基本操作
安裝Spark !20 $ wget http://files.imaclouds.com/scripts/hadoop-spark-installer.sh OR https://hub.docker.com/r/kairen/yarn-spark/
下載 Spark Library !21 http://files.imaclouds.com/packages/hadoop-spark/ spark-assembly-1.5.2-hadoop2.6.0.jar 並 Import 到 Project
裡
執⾏行行指令 !22 $ spark-submit --class <package> --master local[2] <jar path>
<input path> <output path>
在 HDFS 新增資料 !23 $ vim test.txt a,123,456,789,11344,2142,123 b,1234,124,1234,123,123 c,123,4123,5435,1231,5345
d,123,456,789,113,2142,143 e,123,446,789,14,2142,113 f,123,446,789,14,2142,1113,323 $ hadoop fs -mkdir /spark/homework $ hadoop fs -put test.txt /spark/homework
Spark 操作概念念 !24 Spark 共有以下幾個概念念: •Resilient Distributed Datasets •Creation operation
•Transformation operation •Control operation •Action operation
SparkConf & JavaSparkContext !25 // 建立 Configuration 且定義 Job 名稱
SparkConf conf = new SparkConf(); conf.setAppName(“JavaWordCount”); conf.setMaster("yarn-cluster") // 建立 JavaSparkContext 來來接收資料來來源 JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> file = sc.textFile(inputPath);
map !26 Input : String Output : 任⼀一定義 JavaRDD<String> map
=file.map(new Function<String, String>() { public String call(String arg0) throws Exception { return arg0; } }); {1,2,3} => {1,2,3}
map 練習 !27 找出測試資料所有英⽂文字⺟母,並存⾄至/spark/ homework/map。結果如下: a b c d e
f
flatmap !28 Input : String Output : Iterable<v> // v
型態任⼀一定義 JavaRDD<String> map =file .flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String arg0) throws Exception { return Arrays.asList(arg0.split(",")); } }); {1,2,3} => {1 2 3}
flatmap 練習 !29 找出測試資料所有以”,”切割的資料,並存⾄至/spark/homework/flatMap。結 果如下: a 123 456 789 11344
2142 123 b 1234 ….
filter !30 Input : String Output : Boolean JavaRDD<String> filter
=map.filter(new Function<String, Boolean>() { public Boolean call(String arg0) throws Exception { if(arg0.contains("2")){ return true; } return false; } }); {1,2,3} => {2}
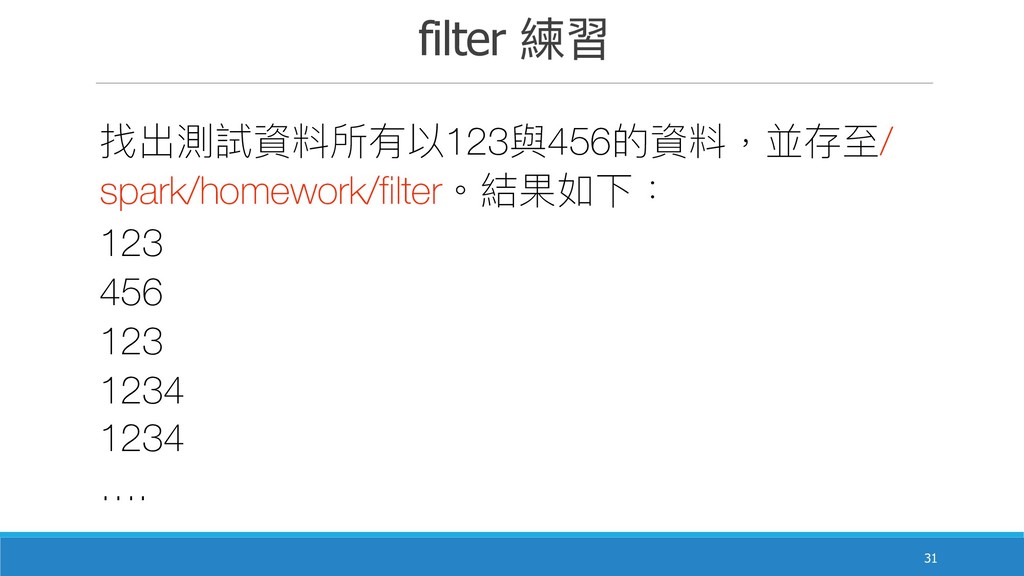
filter 練習 !31 找出測試資料所有以123與456的資料,並存⾄至/ spark/homework/filter。結果如下: 123 456 123 1234 1234
….
mapToPair !32 Input : String Output : Tuple2<K, V> //
K、V型態任⼀一定義 JavaPairRDD<String, Integer> pairRDD =file .mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String arg0) throws Exception { return new Tuple2<String, Integer>(arg0, 1); } }); {1,2,3} => {(1,1),(2,1),(3,1)}
mapToPair 練習 !33 將測試資料轉換成(str, 1),並存⾄至/spark/homework/mapPair。 結果如下: (a,1) (123,1) (456,1) (789,1)
(11344,1) (2142,1) (123,1) ….
flatMapToPair !34 Input : String Output : Iterable<Tuple2<K, V>> //
K、V型態任⼀一定義 JavaPairRDD<String, Integer> pairRDD =file .flatMapToPair(new PairFlatMapFunction<String, String, Integer>() { public Iterable<Tuple2<String, Integer>> call(String arg0) throws Exception { ArrayList<Tuple2<String,Integer>> arrayList =new ArrayList<Tuple2<String,Integer>>(); arrayList.add(new Tuple2<String, Integer>(arg0, 123)); return arrayList ; } }); {1,2,3} => {(1,123),(2,123),(3,123)}
flatMapToPair 練習 !35 將測試資料轉換成(字⺟母, 所有後⾯面數字的sum),並存⾄至/ spark/homework/filter_output。結果如下: (a,14977) (b,2838) (c,16257) (d,3766)
(e,3627) (f,4950) ….
groupBy !36 Input : String Output : V // V
型態任⼀一定義 JavaPairRDD<String, Iterable<String>> groupBy =file .groupBy(new Function<String, String>() { public String call(String arg0) throws Exception { return (arg0.contains("2")?"A":"B"); } }); {1,2,3} => {(A,{2}) , (B,{1,3})}
groupBy 練習 !37 找出測試資料中⼤大於500的資料,若若無法辨識分 到”None”,並存⾄至/spark/homework/groupBy。結果如 下: (None,[a, b, c, d,
e, f]) (⼩小於 500,[123, 456, 123, 124, 123, 123, 123, 123, 456, 113, 143, 123, 446, 14, 113, 123, 446, 14, 323]) (⼤大於 500,[789, 11344, 2142, 1234, 1234, 4123, 5435, 1231, 5345, 789, 2142, 789, 2142, 789, 2142, 1113]) ….
reduce !38 Input : String Output : String String string
= flatmap.reduce(new Function2<String, String, String>() { public String call(String arg0, String arg1) throws Exception { return arg0+arg1+"~~"; } }); {1,2,3} => {1~~2~~3}
reduce 練習 !39 找出測試資料所有英⽂文字⺟母,並⽤用reduce將之 append成⼀一個字串串,並存⾄至/spark/homework/ reduce。結果如下: abcdef
reduceByKey !40 Input : String Output : Integer JavaPairRDD<String, Integer>
reduceByKey =flatmap .reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer arg0, Integer arg1) throws Exception { return arg0+arg1; } }); {(1,1),(1,2),(3,3)} => {(1,3),(3,3)}
reduceByKey 練習 !41 找出以”,”切割的所有wordcount,並存⾄至/spark/ homework/reduceByKey。結果如下: (d,1) (1113,1) (1231,1) (e,1) (14,2)
(113,2) ….
mapValues !42 Input : String Output : Integer reduceByKey.mapValues(new Function<Integer,
Integer>() { public Integer call(Integer arg0) throws Exception { return arg0*100; } }); {(1,1),(2,2),(3,3)} => {(1,100),(2,200),(3,300)}
sortByKey & distinct !43 //以 Key 為主進⾏行行⼤大到⼩小排序,反之true⼩小到⼤大 JavaPairRDD<String, Integer> sort
= reduceByKey.sortByKey(false); //去除重覆 JavaPairRDD<String, Integer> sort = reduceByKey.distinct(); {1,2,3} => {(1,123),(2,123),(3,123)}
打鐵趁熱(⼀一) !44 找出Datasets中,銷售前⼆二⼗十名的商品。結果為以 下: 01,0006584093 02,0000143511 03,0007082051 04,0005772981 05,0014252066 ….
打鐵趁熱(⼆二) !45 •使⽤用者編號1~10中對商品編號1~10 的評價有 3 以上的有哪些?依 照 rating 進⾏行行排序 (⼤大到⼩小)
•結果格式如下 • User 1 評價 Item 1 為 5 • u.data.csv (http://files.imaclouds.com/dataset/u.data.csv)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![執⾏行行指令 !22 $ spark-submit --class <package> --master local[2] <jar path>](https://files.speakerdeck.com/presentations/d1137b131429434abd62a736862ec3d2/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}