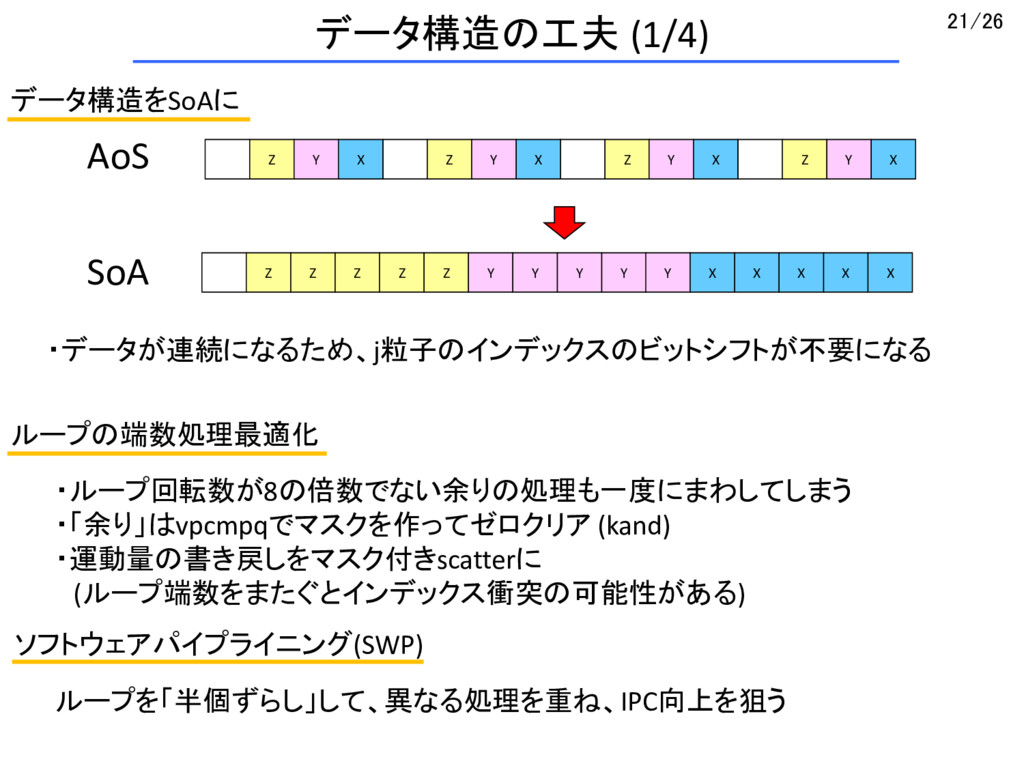
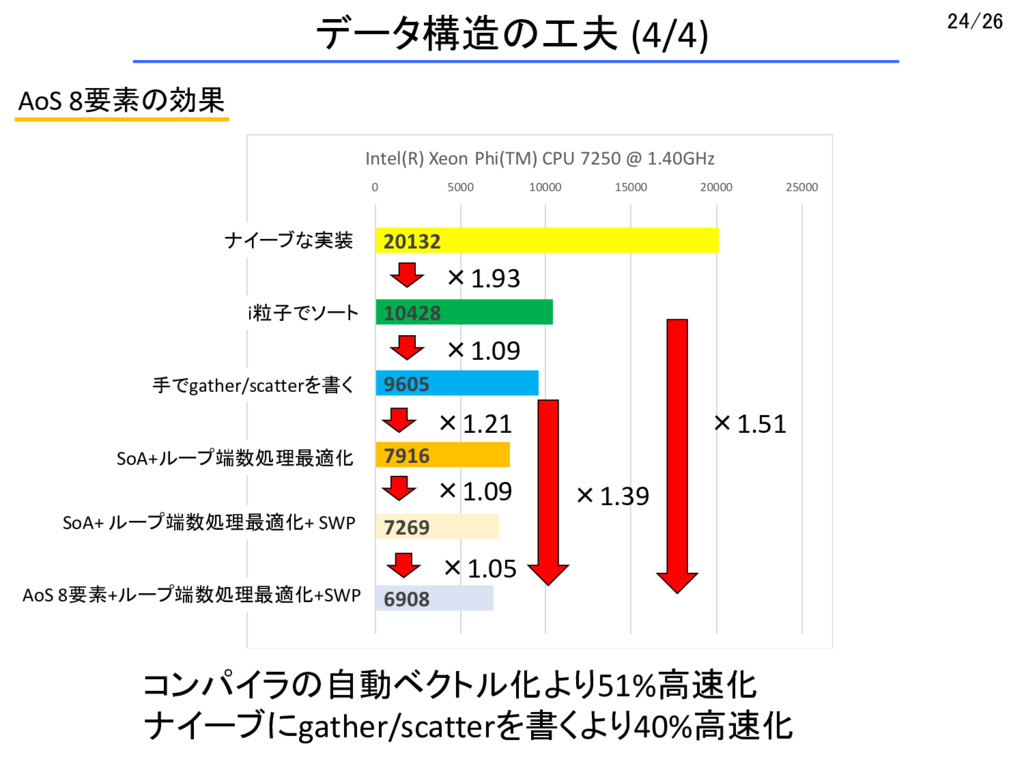
X Z Y X Z Y X SoA Z Z Z Z Z Y Y Y Y Y X X X X X ループの端数処理最適化 ・ループ回転数が8の倍数でない余りの処理も一度にまわしてしまう ・「余り」はvpcmpqでマスクを作ってゼロクリア (kand) ・運動量の書き戻しをマスク付きscatterに (ループ端数をまたぐとインデックス衝突の可能性がある) ソフトウェアパイプライニング(SWP) ループを「半個ずらし」して、異なる処理を重ね、IPC向上を狙う ・データが連続になるため、j粒子のインデックスのビットシフトが不要になる
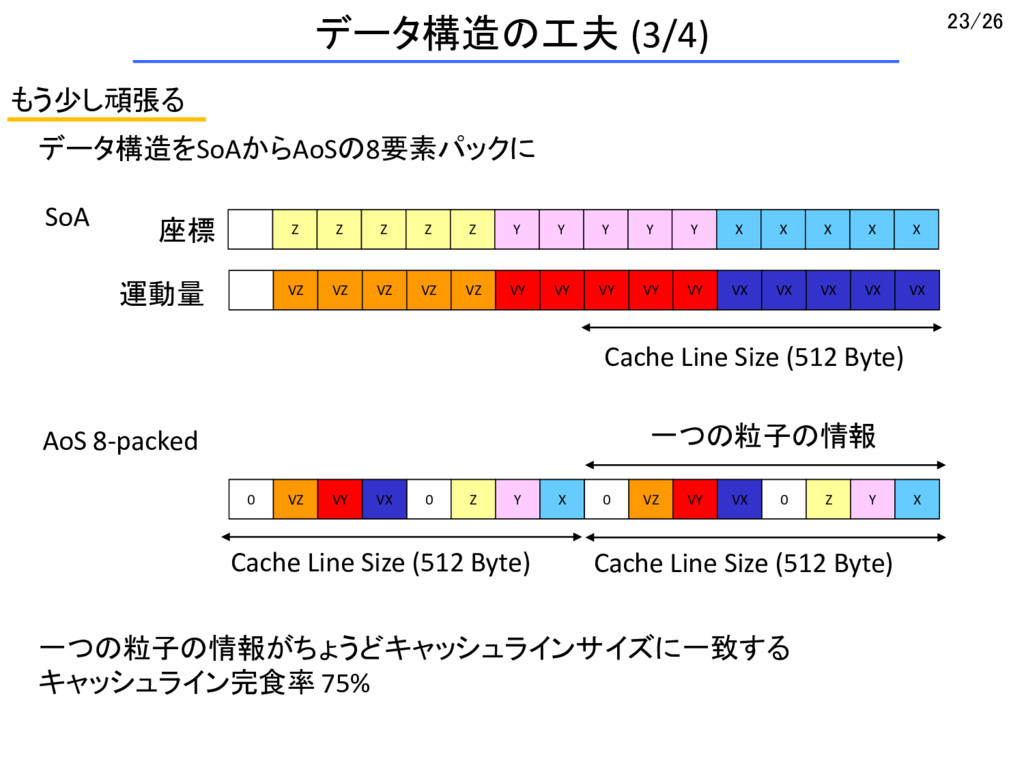
Y Y Y Y X X X X X SoA VZ VZ VZ VZ VZ VY VY VY VY VY VX VX VX VX VX 座標 運動量 Cache Line Size (512 Byte) AoS 8-packed 0 VZ VY VX 0 Z Y X 0 VZ VY VX 0 Z Y X 一つの粒子の情報 Cache Line Size (512 Byte) Cache Line Size (512 Byte) データ構造をSoAからAoSの8要素パックに 一つの粒子の情報がちょうどキャッシュラインサイズに一致する キャッシュライン完食率 75%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
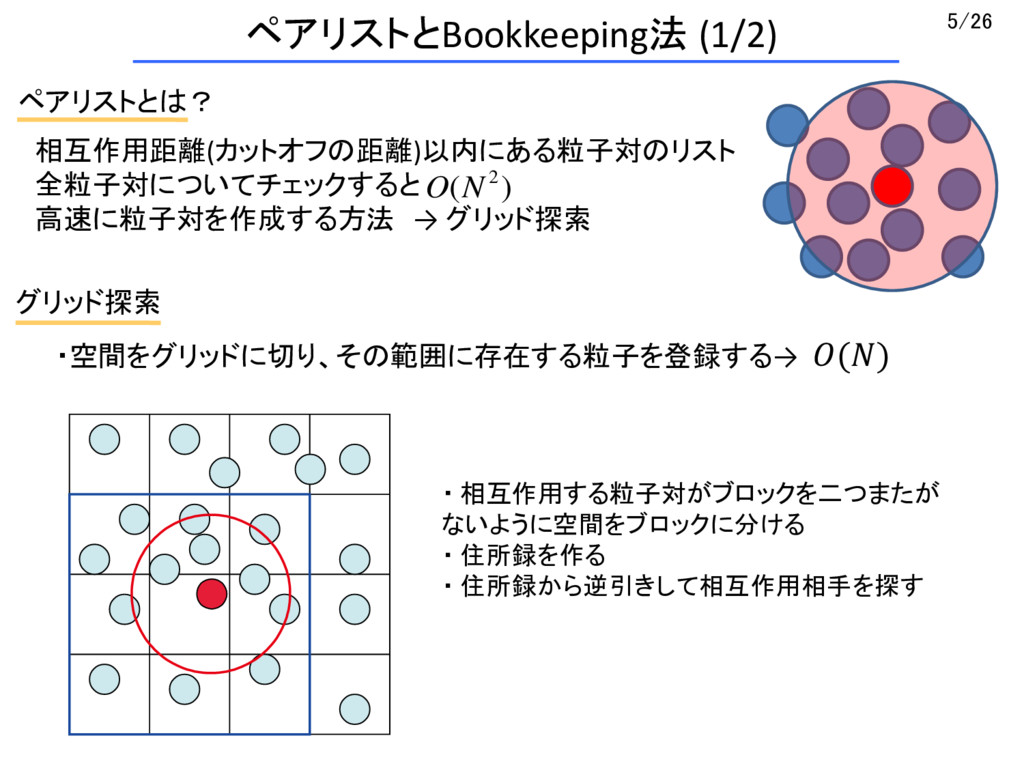{kind=link}
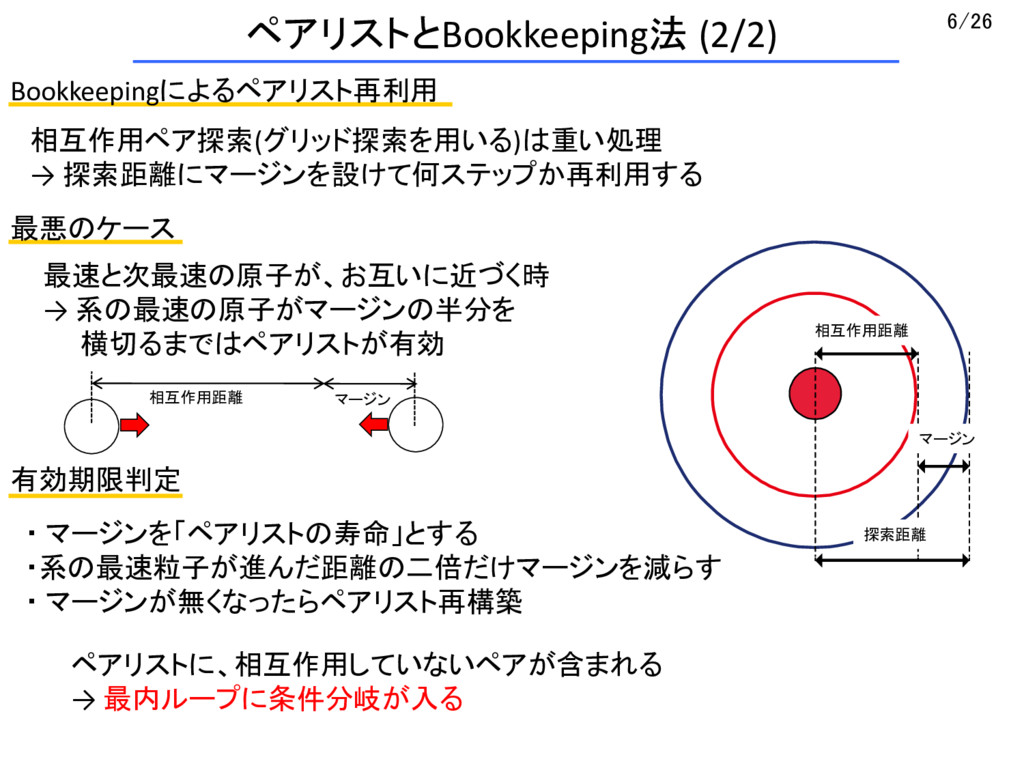{kind=link}
{kind=link}
{kind=link}
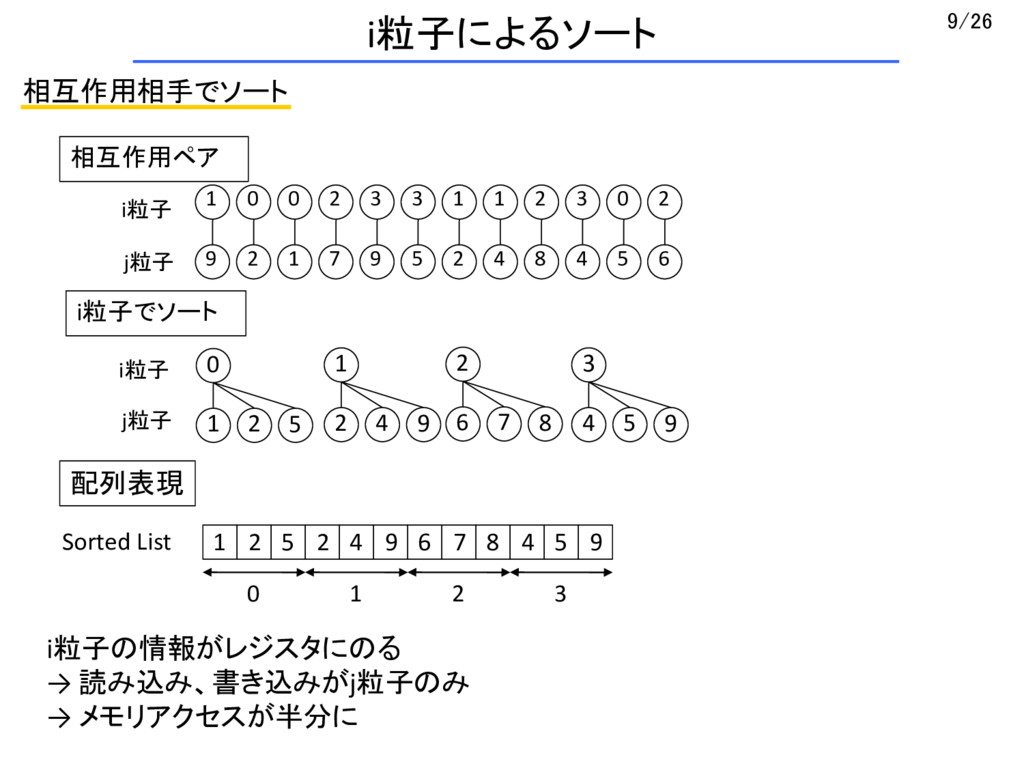{kind=link}
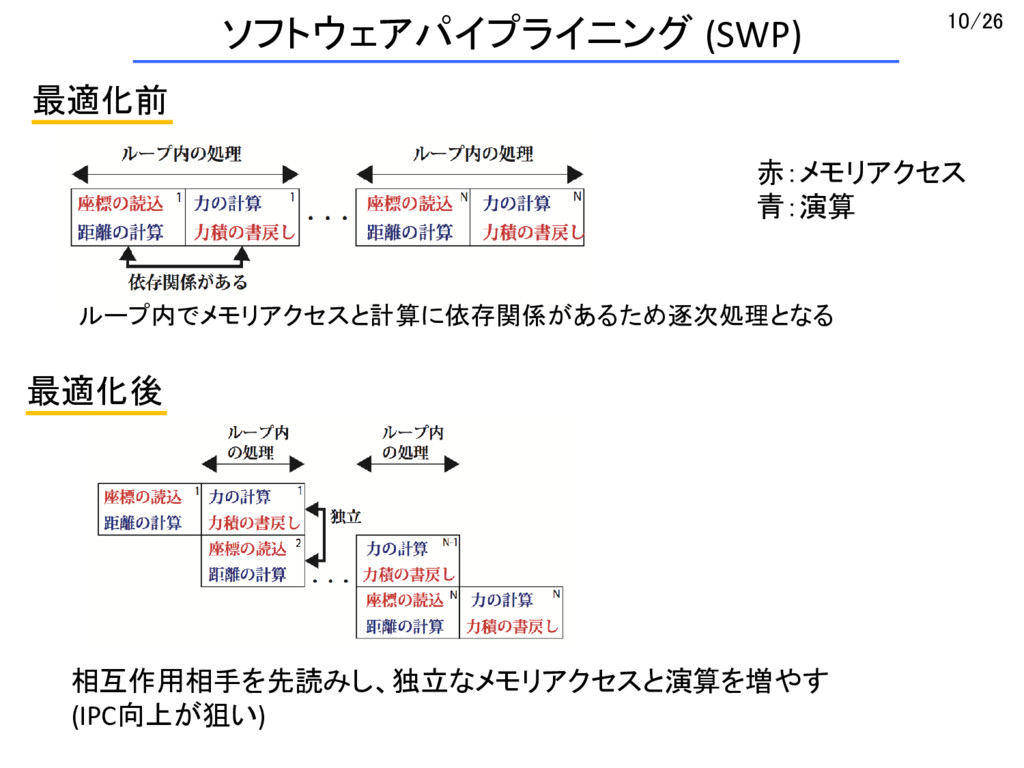{kind=link}
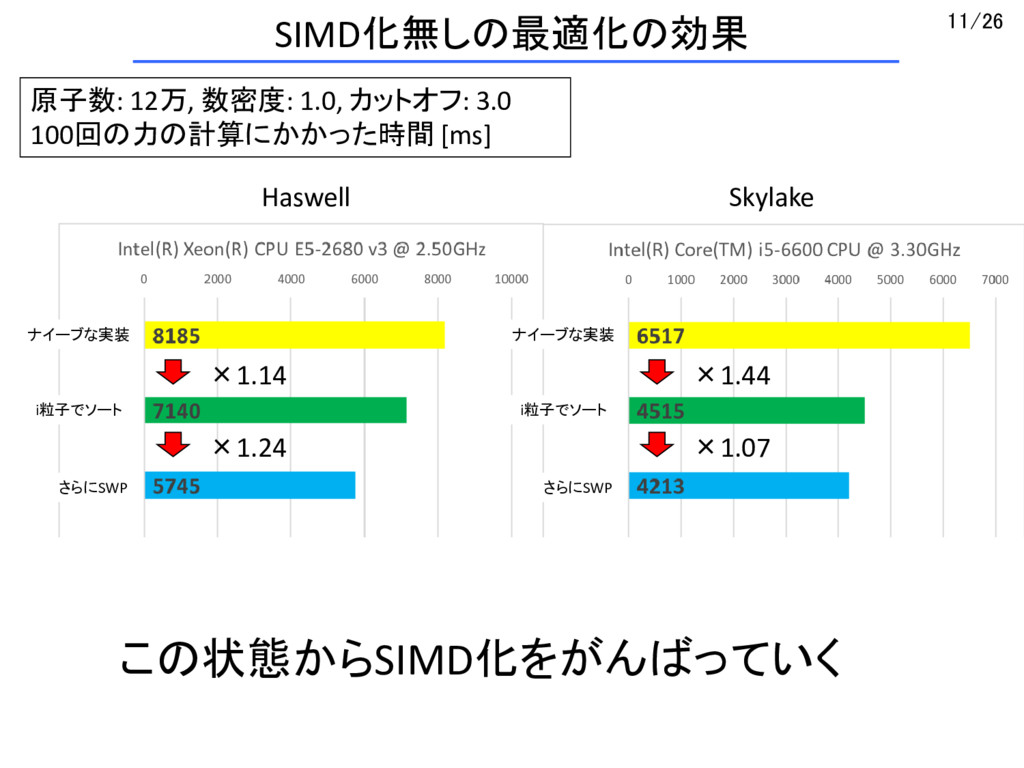{kind=link}
{kind=link}
![13/26 AVX2を用いたSIMD化 (2/5) パディング付きAoS データを粒子数*4成分の二次元配列で宣言 double q[N][4], p[N][4]; Z Y](https://files.speakerdeck.com/presentations/f89a56e81ccc40f29c240eb43ef746d8/slide_12.jpg){kind=link}
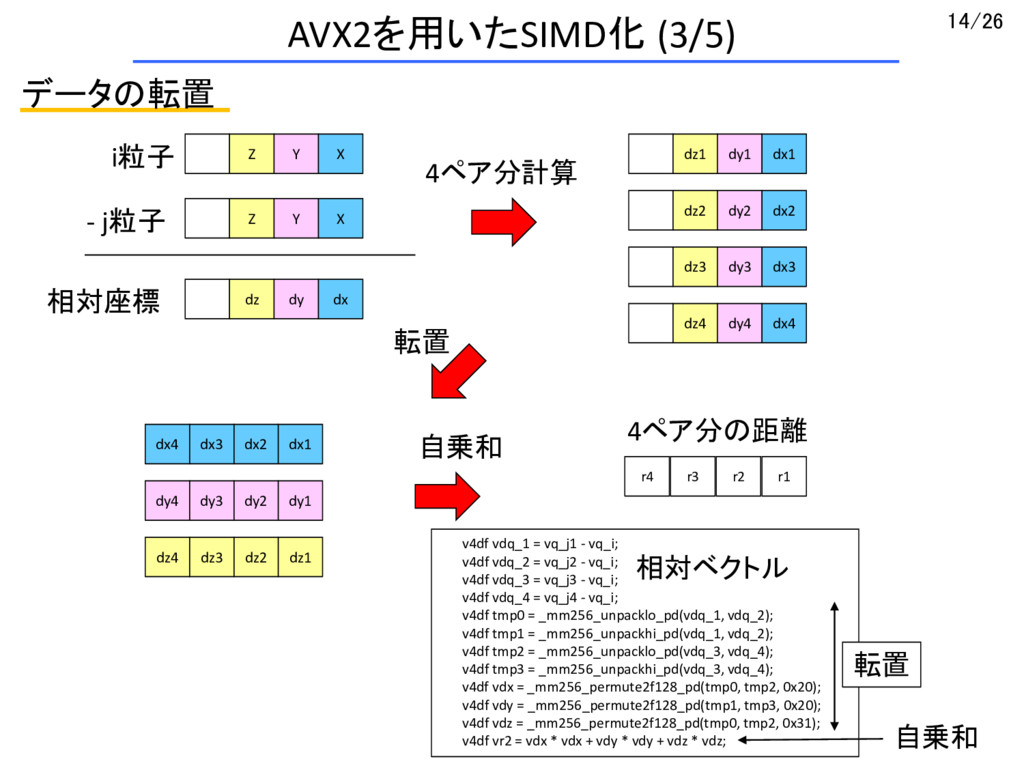{kind=link}
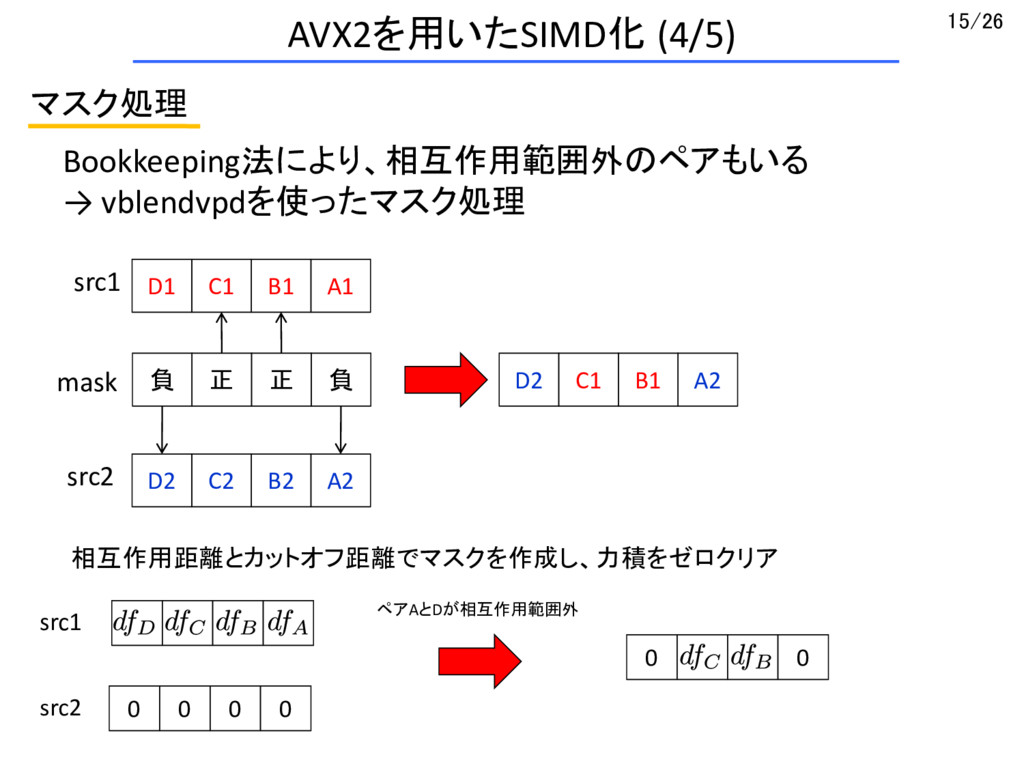{kind=link}
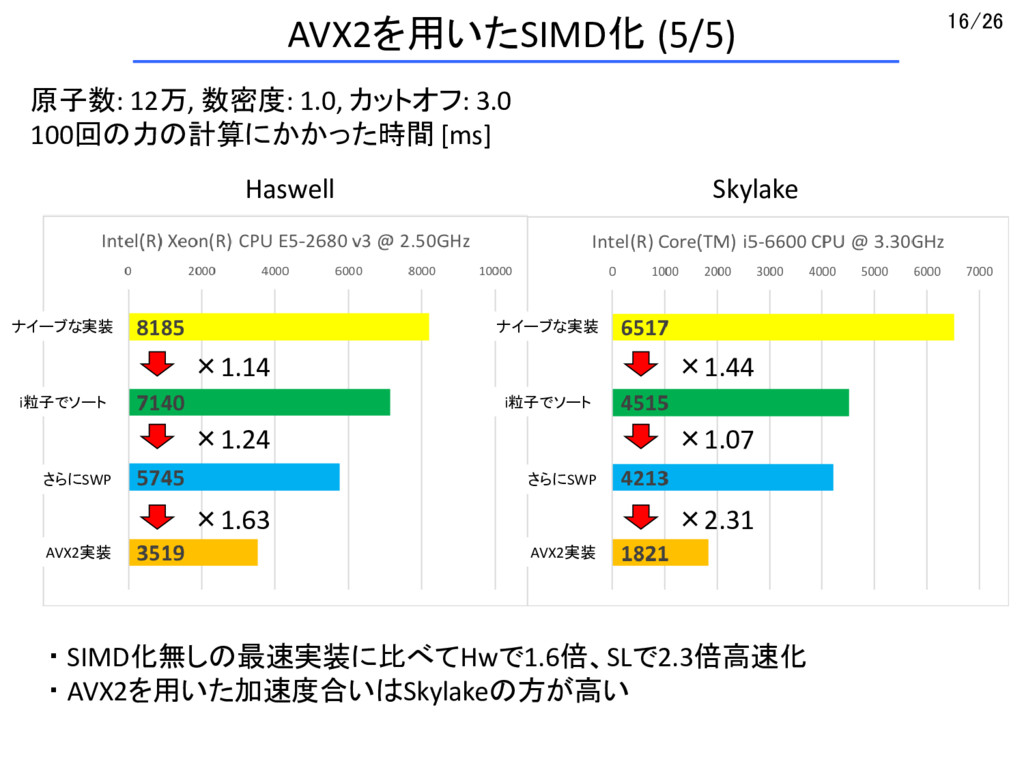{kind=link}
{kind=link}
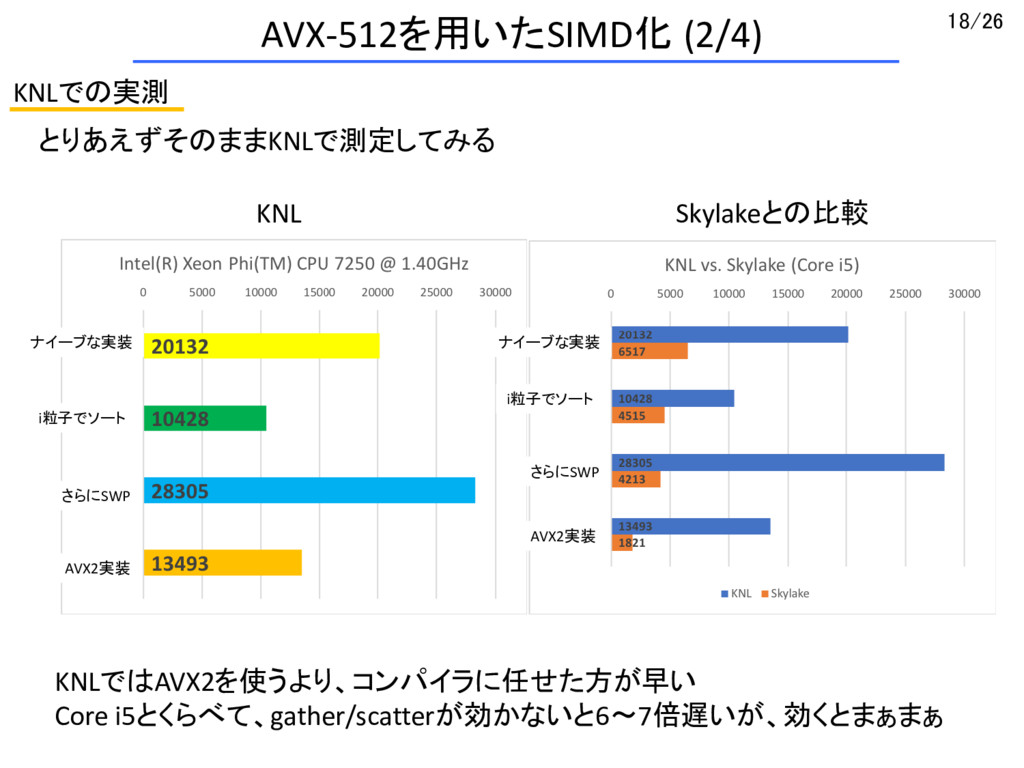{kind=link}
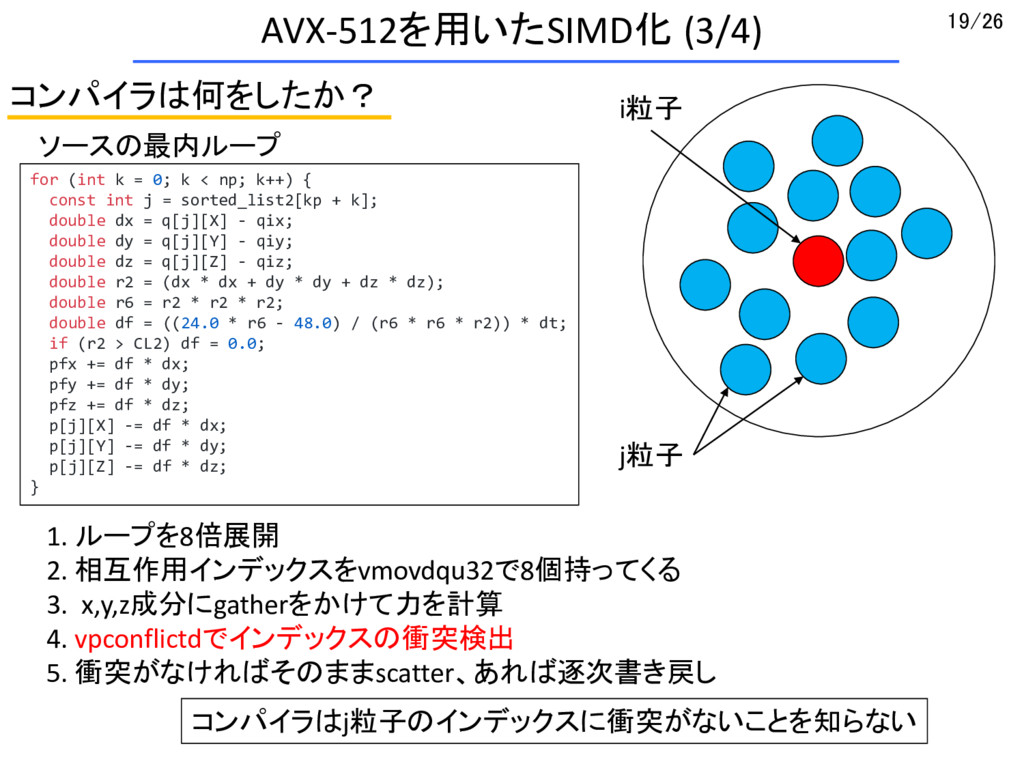{kind=link}
{kind=link}
{kind=link}
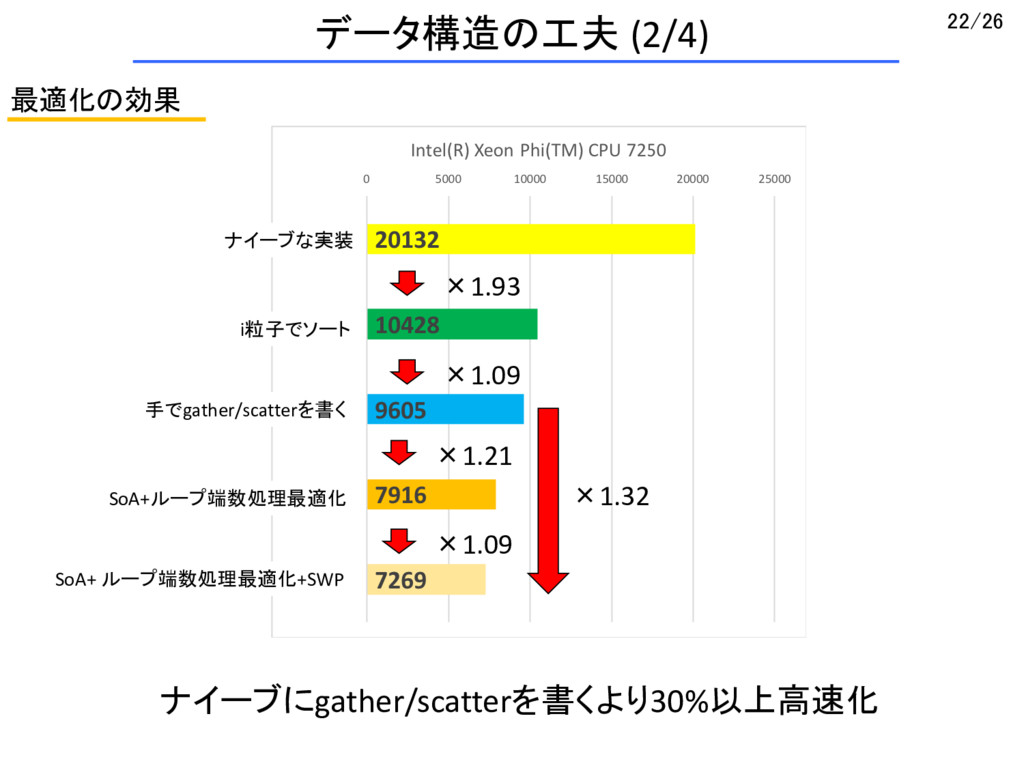{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}