OpenStackやKubernetesといったソフトウェアの登場によって、近年ではユーザが、サーバ等の物理インフラを気にすることなく、簡単にVMやコンテナをデプロイできるようになっています。
一方で、インフラ自体の動作・構成は複雑化・隠蔽されているため、トラブルが発生した際の原因特定などが困難になっていることも事実です。
本セッションでは、OpenStackを題材として、実際のトラブルシュートでの経験を元に、クラウドインフラにおけるトラブルシュート時の考え方やTipsをご紹介します。
Cloud Operator Days Tokyo 2020 講演資料です。https://cloudopsdays.com/archive/2020/program/
@masayukig さんと共同の講演です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
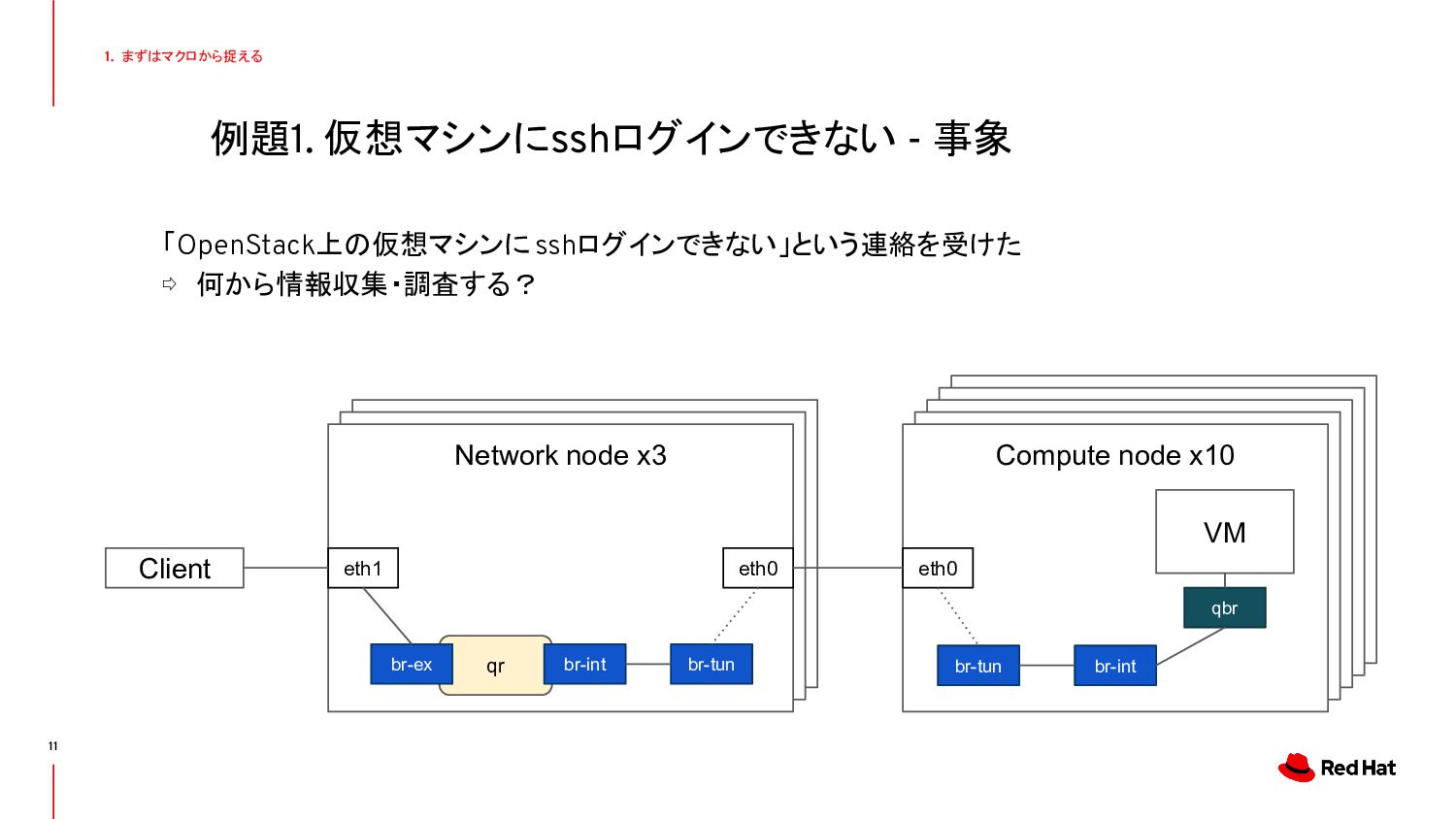{kind=link}
{kind=link}
{kind=link}
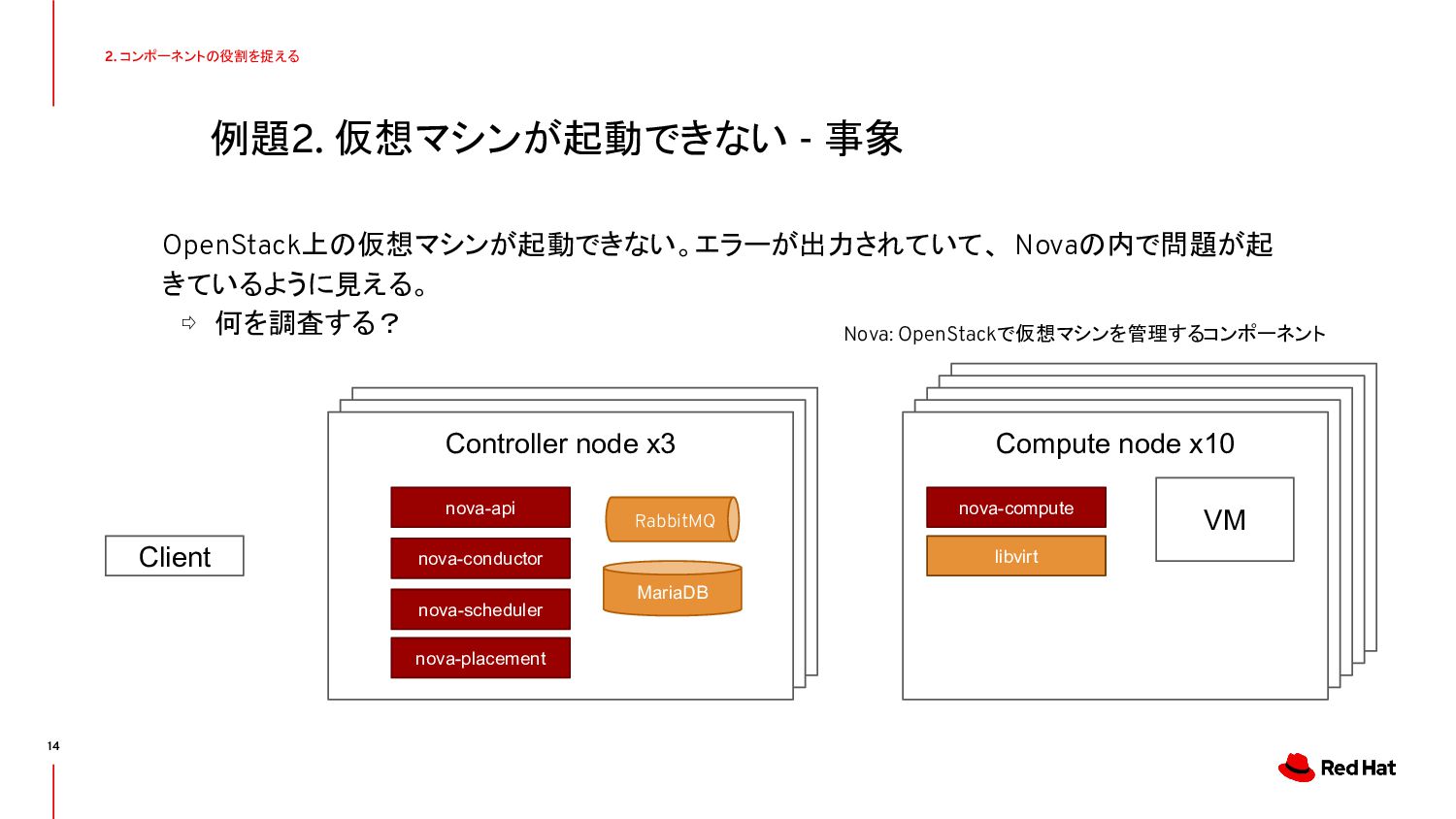{kind=link}
{kind=link}
{kind=link}
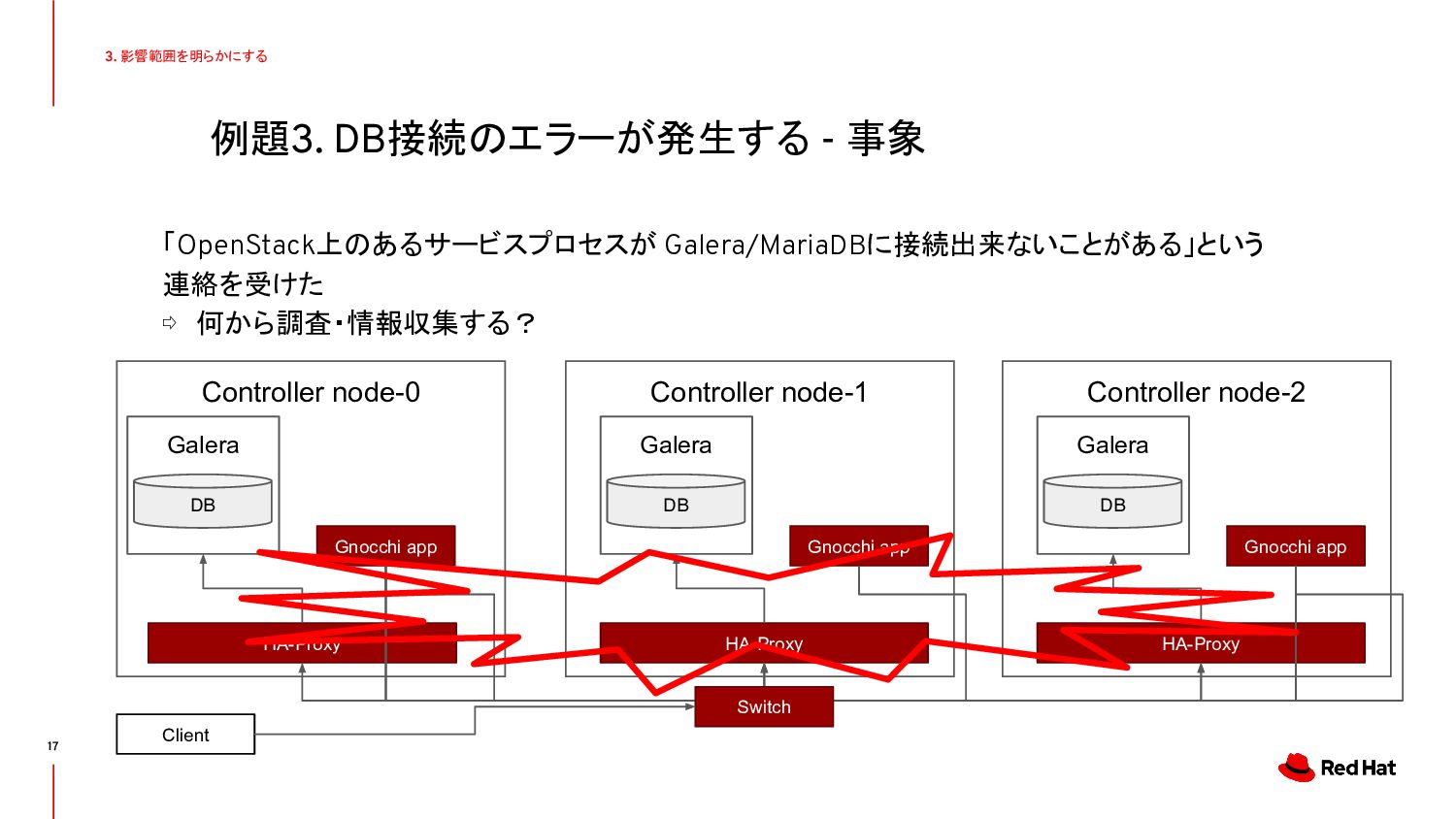{kind=link}
{kind=link}
{kind=link}
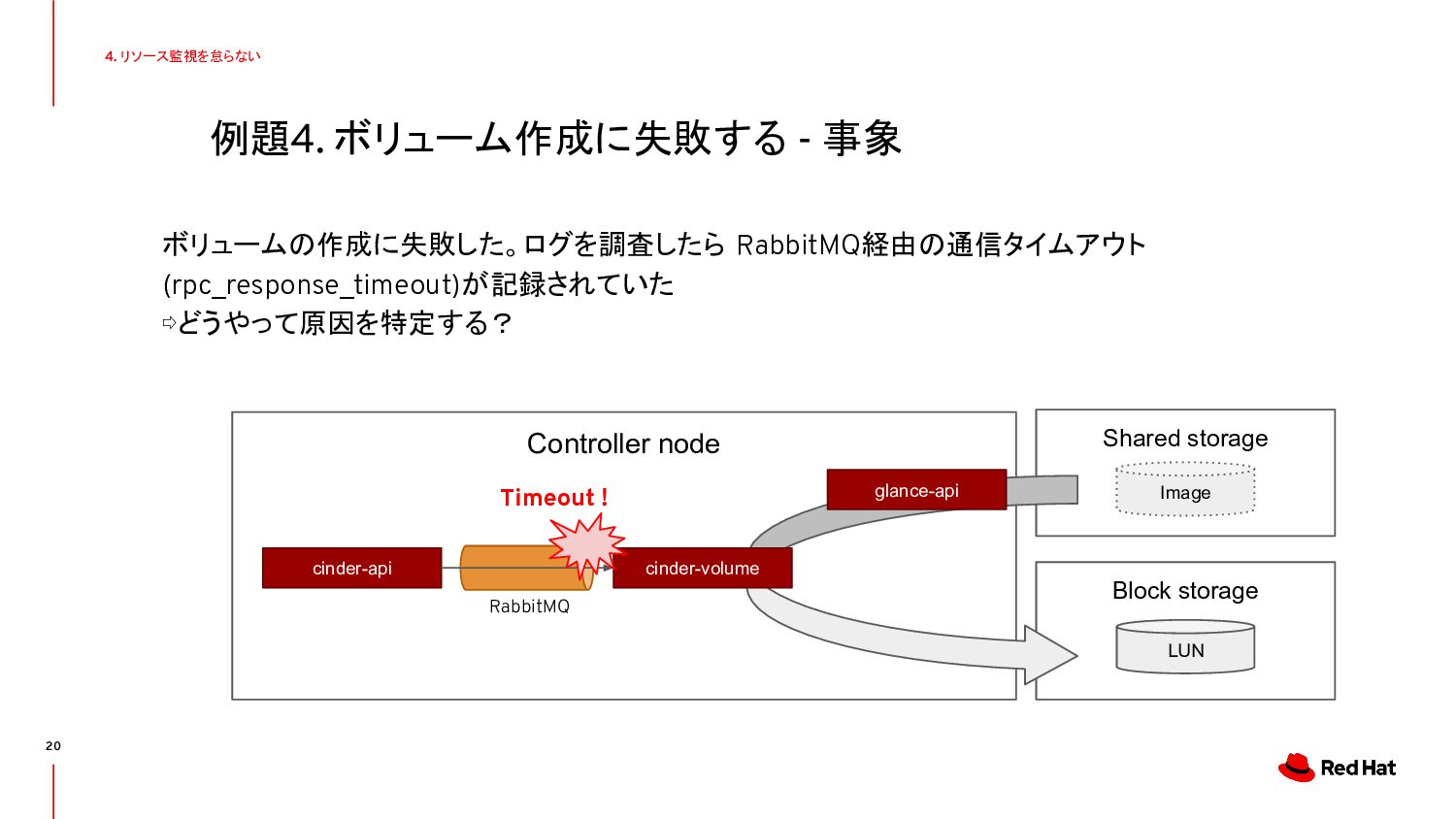{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}