Corp. All rights reserved. Redistribution or public display is not permitted without written permission from Kakao. Kakao Hadoop Platform (KHP) 국성표 elixir.kook 카카오 if(kakao)2022
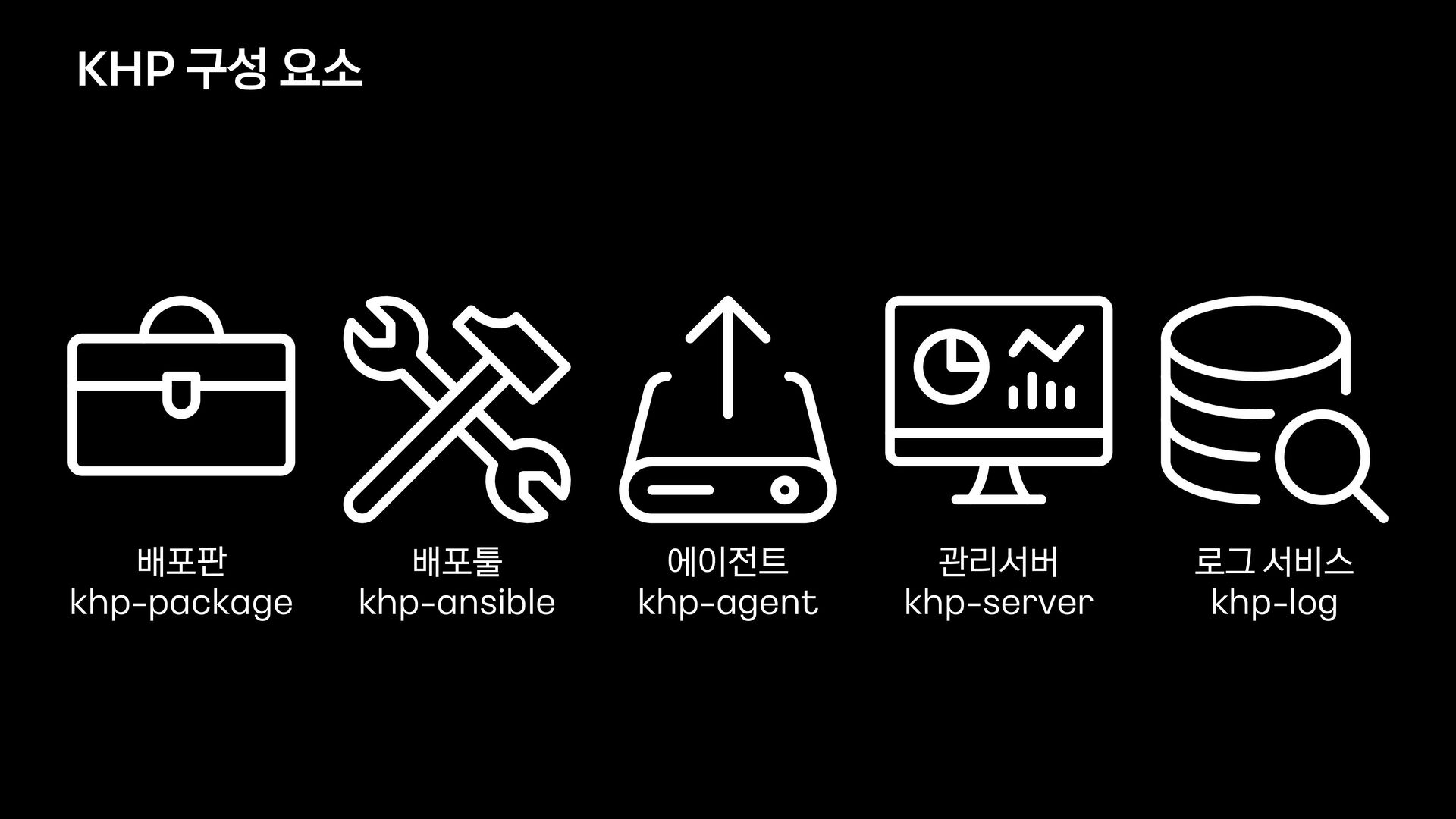
2020.11 ~ 2021.02 투입인력 10명 - - 관리도구 (khp - ansible, agent, server) 기능 개발 완료 고도화 고도화 하둡 배포판 최소한의 운영 안정적인 운영을 위한 하둡 패치 Impala, Sentry 대체 위한 하둡 컴포넌트 기능 검증/추가 배포판에 포함된 컴포넌트 Hadoop, HBase, Hive, Spark, … +Oozie, Tez, Anaconda + Presto, Ranger 클러스터 이전 클러스터 성격에 따라 이관 목표를 세우고 이행 KHP 개발 마일스톤
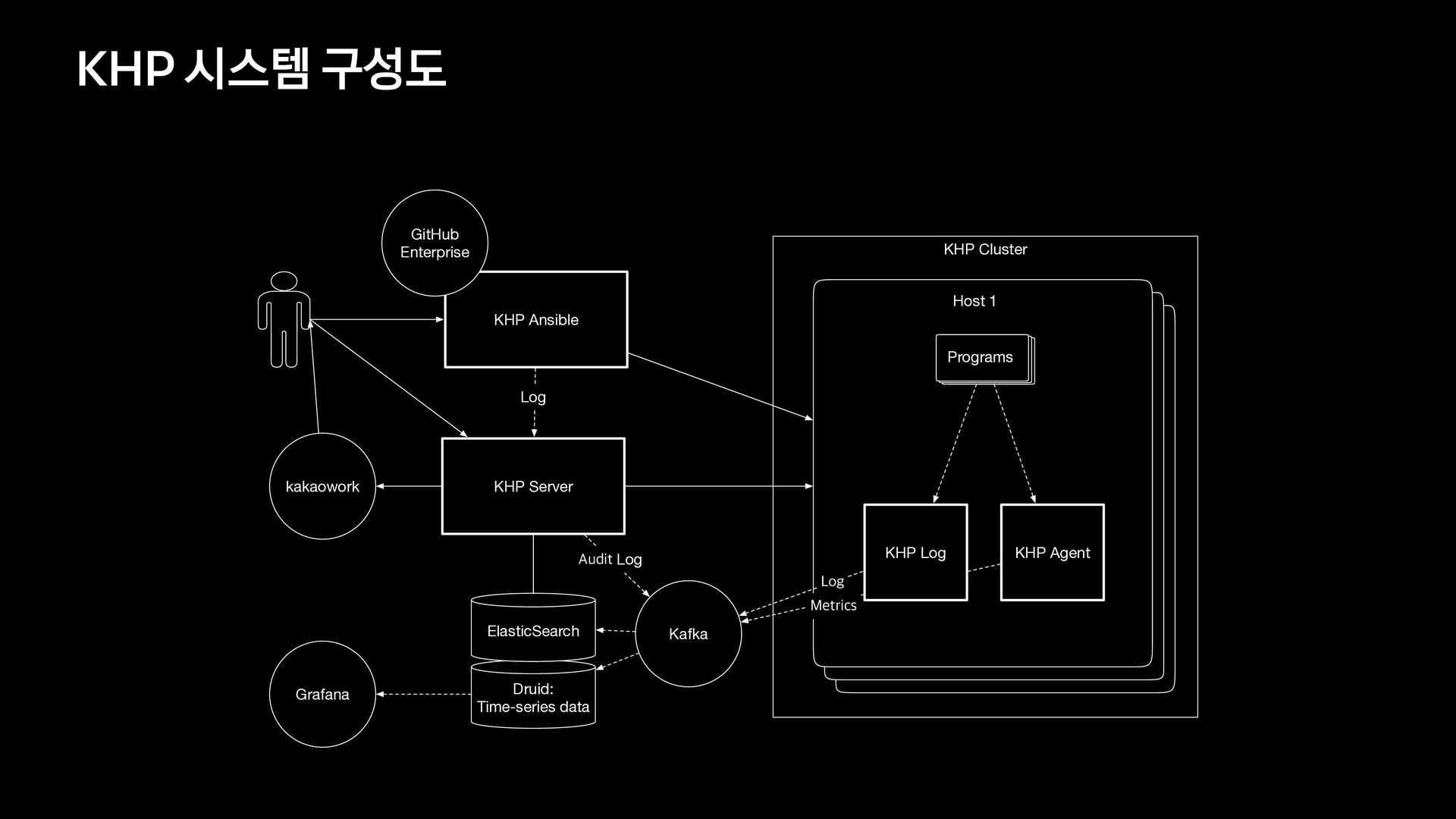
툴로서, 프로비저닝, 구성 관리, 애플리케이션 배포, 오케스트레이션, 기타 여러 가지 수동 IT 프로세스를 자동화합니다. - IaC (Infrastructure as Code) - Playbook (.yaml) - Inventory (.ini) 배포툴 (khp - ansible)
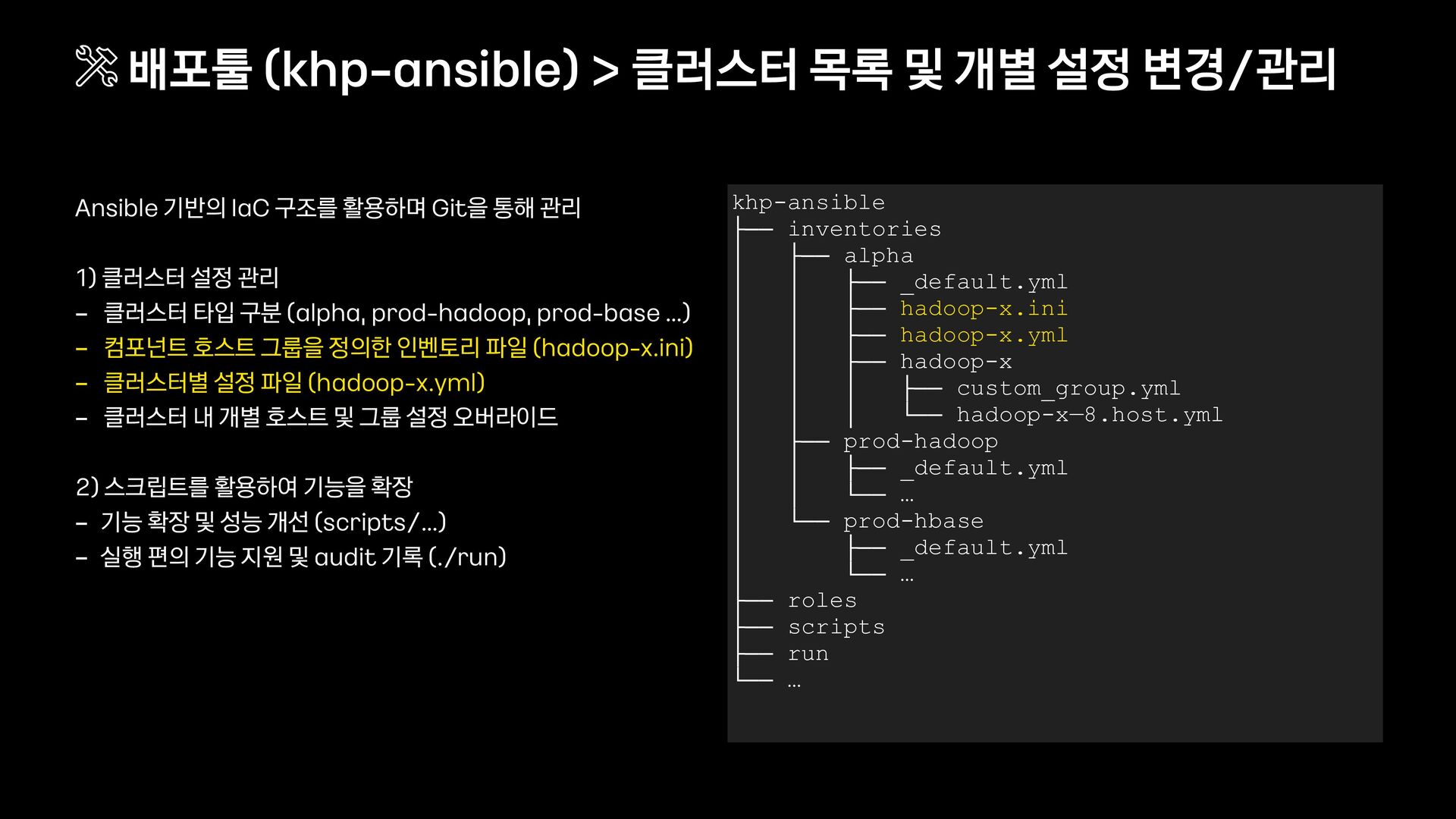
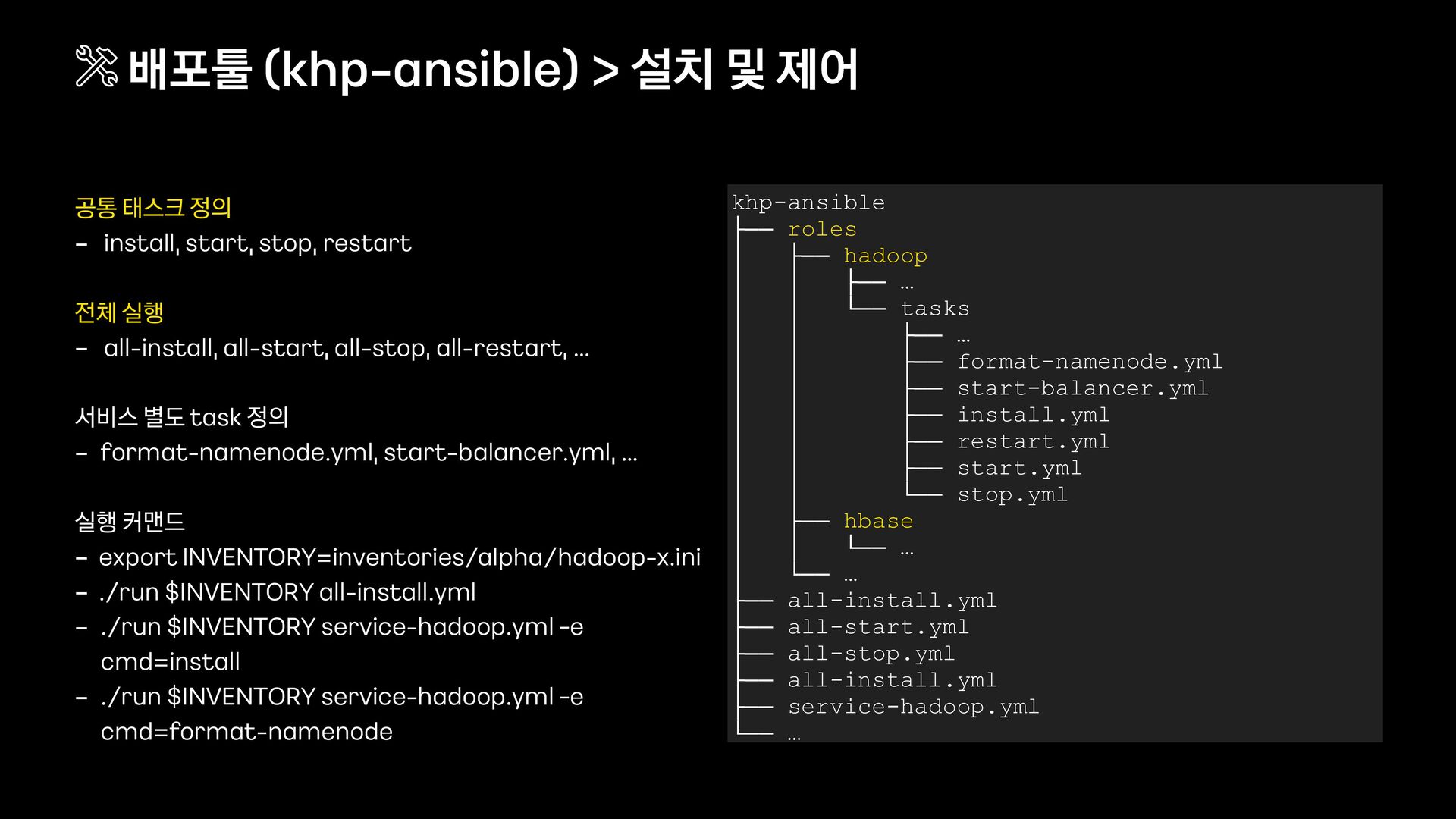
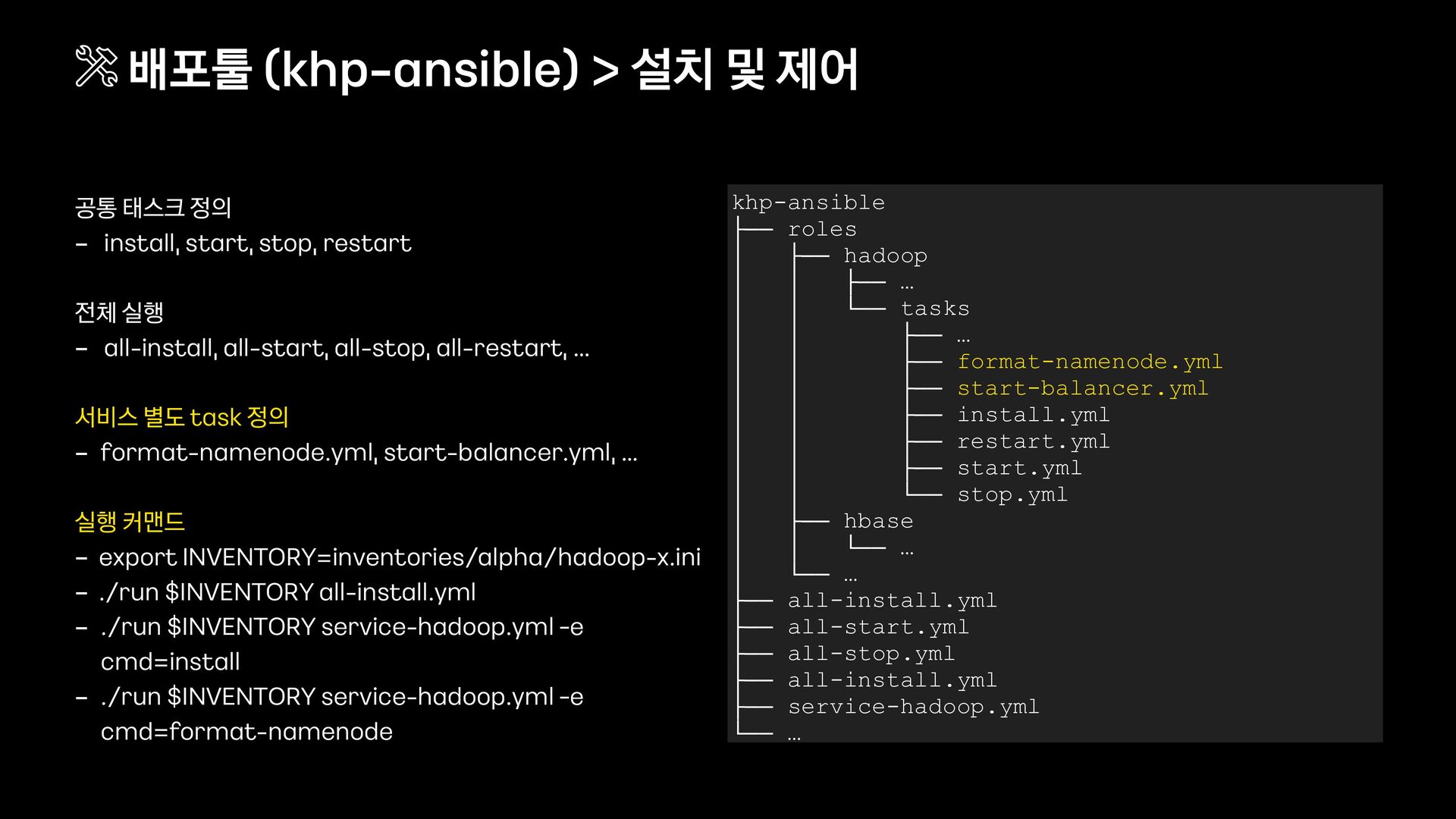
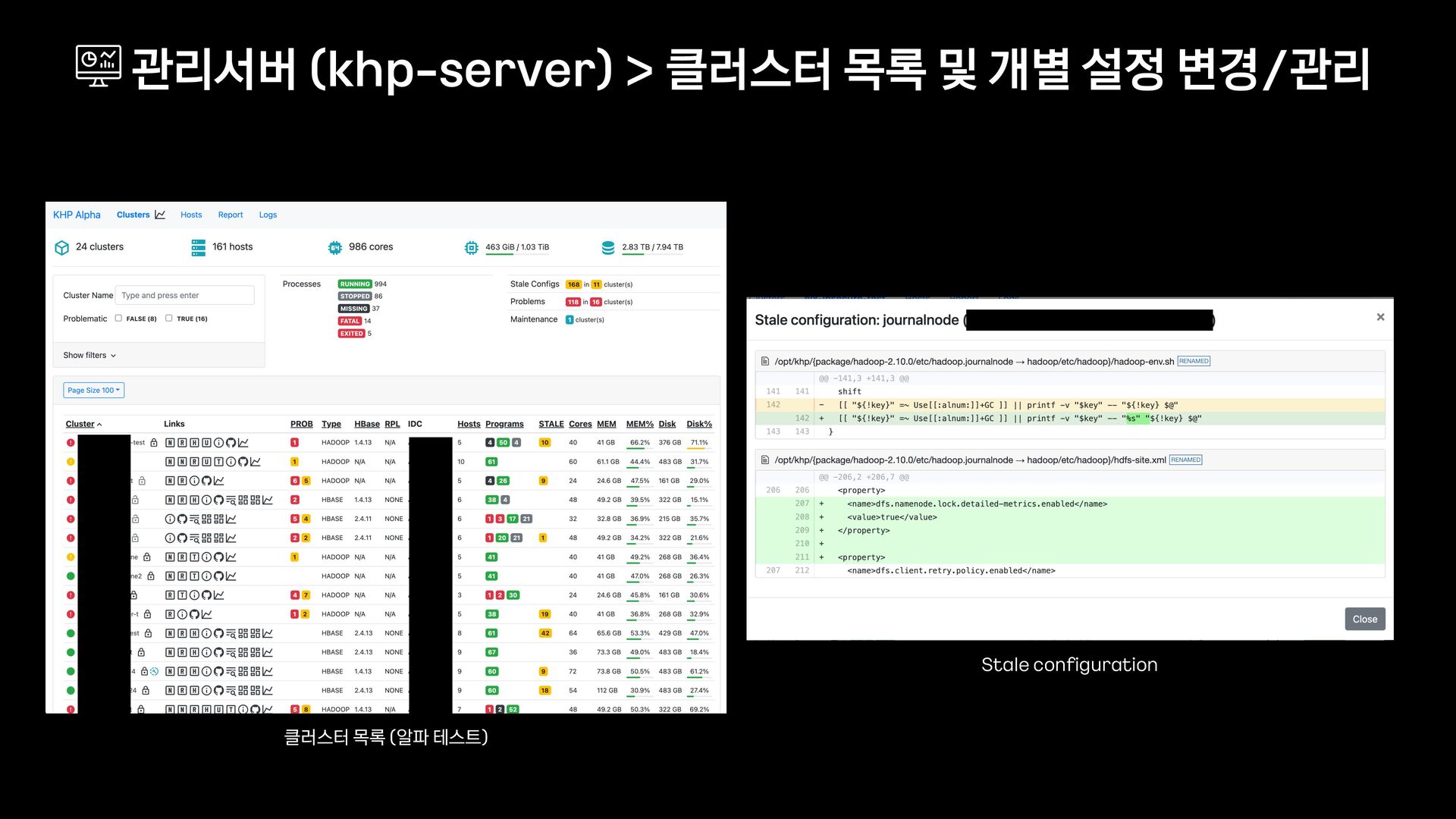
설정 관리 - 클러스터 타입 구분 (alpha, prod - hadoop, prod - base …) - 컴포넌트 호스트 그룹을 정의한 인벤토리 파일 (hadoop - x.ini) - 클러스터별 설정 파일 (hadoop - x.yml) - 클러스터 내 개별 호스트 및 그룹 설정 오버라이드 2) 스크립트를 활용하여 기능을 확장 - 기능 확장 및 성능 개선 (scripts/…) - 실행 편의 기능 지원 및 audit 기록 (./run) 배포툴 (khp - ansible) > 클러스터 목록 및 개별 설정 변경/관리 khp-ansible ├── inventories │ ├── alpha │ │ ├── _default.yml │ │ ├── hadoop-x.ini │ │ ├── hadoop-x.yml │ │ ├── hadoop-x │ │ │ ├── custom_group.yml │ │ │ └── hadoop-x—8.host.yml │ ├── prod-hadoop │ │ ├── _default.yml │ │ └── … │ └── prod-hbase │ ├── _default.yml │ └── … ├── roles ├── scripts ├── run └── …
설정 관리 - 클러스터 타입 구분 (alpha, prod - hadoop, prod - base …) - 컴포넌트 호스트 그룹을 정의한 인벤토리 파일 (hadoop - x.ini) - 클러스터별 설정 파일 (hadoop - x.yml) - 클러스터 내 개별 호스트 및 그룹 설정 오버라이드 2) 스크립트를 활용하여 기능을 확장 - 기능 확장 및 성능 개선 (scripts/…) - 실행 편의 기능 지원 및 audit 기록 (./run) 배포툴 (khp - ansible) > 클러스터 목록 및 개별 설정 변경/관리 khp-ansible ├── inventories │ ├── alpha │ │ ├── _default.yml │ │ ├── hadoop-x.ini │ │ ├── hadoop-x.yml │ │ ├── hadoop-x │ │ │ ├── custom_group.yml │ │ │ └── hadoop-x—8.host.yml │ ├── prod-hadoop │ │ ├── _default.yml │ │ └── … │ └── prod-hbase │ ├── _default.yml │ └── … ├── roles ├── scripts ├── run └── …
설정 관리 - 클러스터 타입 구분 (alpha, prod - hadoop, prod - base …) - 컴포넌트 호스트 그룹을 정의한 인벤토리 파일 (hadoop - x.ini) - 클러스터별 설정 파일 (hadoop - x.yml) - 클러스터 내 개별 호스트 및 그룹 설정 오버라이드 2) 스크립트를 활용하여 기능을 확장 - 기능 확장 및 성능 개선 (scripts/…) - 실행 편의 기능 지원 및 audit 기록 (./run) 배포툴 (khp - ansible) > 클러스터 목록 및 개별 설정 변경/관리 khp-ansible ├── inventories │ ├── alpha │ │ ├── _default.yml │ │ ├── hadoop-x.ini │ │ ├── hadoop-x.yml │ │ ├── hadoop-x │ │ │ ├── custom_group.yml │ │ │ └── hadoop-x—8.host.yml │ ├── prod-hadoop │ │ ├── _default.yml │ │ └── … │ └── prod-hbase │ ├── _default.yml │ └── … ├── roles ├── scripts ├── run └── …
설정 관리 - 클러스터 타입 구분 (alpha, prod - hadoop, prod - base …) - 컴포넌트 호스트 그룹을 정의한 인벤토리 파일 (hadoop - x.ini) - 클러스터별 설정 파일 (hadoop - x.yml) - 클러스터 내 개별 호스트 및 그룹 설정 오버라이드 2) 스크립트를 활용하여 기능을 확장 - 기능 확장 및 성능 개선 (scripts/…) - 실행 편의 기능 지원 및 audit 기록 (./run) 배포툴 (khp - ansible) > 클러스터 목록 및 개별 설정 변경/관리 khp-ansible ├── inventories │ ├── alpha │ │ ├── _default.yml │ │ ├── hadoop-x.ini │ │ ├── hadoop-x.yml │ │ ├── hadoop-x │ │ │ ├── custom_group.yml │ │ │ └── hadoop-x—8.host.yml │ ├── prod-hadoop │ │ ├── _default.yml │ │ └── … │ └── prod-hbase │ ├── _default.yml │ └── … ├── roles ├── scripts │ └── … ├── run └── …
- 재시작 필요 - 주로 패치 버전 적용 목적 ex) hadoop_url을 변경 후 install 한다면 - 변경 전: hadoop_url: http:/ /khp - fi leserver/hadoop-2.10.0-khp-20220307.tar.gz - 변경 후: hadoop_url: http:/ /khp - fi leserver/hadoop-2.10.0-khp-20210809.tar.gz 링크 변경 - 변경 전: /opt/khp/hadoop -> /opt/khp/package/hadoop-2.10.0-khp-20220307 - 변경 후: /opt/khp/hadoop -> /opt/khp/package/hadoop-2.10.0-khp-20210809 배포툴 (khp - ansible) > 업그레이드
- 재시작 필요 - 주로 패치 버전 적용 목적 ex) hadoop_url을 변경 후 install 한다면 - 변경 전: hadoop_url: http:/ /khp - fi leserver/hadoop-2.10.0-khp-20220307.tar.gz - 변경 후: hadoop_url: http:/ /khp - fi leserver/hadoop-2.10.0-khp-20210809.tar.gz 링크 변경 - 변경 전: /opt/khp/hadoop -> /opt/khp/package/hadoop-2.10.0-khp-20220307 - 변경 후: /opt/khp/hadoop -> /opt/khp/package/hadoop-2.10.0-khp-20210809 배포툴 (khp - ansible) > 업그레이드
설치 2) 기존 클러스터로부터 데이터 복제 또는 이동 3) 기존 클러스터로부터 실행 중인 그리고 실행될 잡 이동 4) 데이터 및 잡 이관 완료 후 기존 클러스터 삭제 특징 - 새로운 클러스터 구성 시 컴포넌트 버전 선택이 상대적으로 자유롭다 - 사용자가 직접 작업 이관을 처리해야 한다 - 대규모 마이그레이션 작업 시 시스템 리소스 외에도 네트워크 대역폭에 대한 관리가 필요하다 - 이관이 이뤄짐에 따라 기존 클러스터 정리와 신규 클러스터 확대를 병행한다 단계적 이관
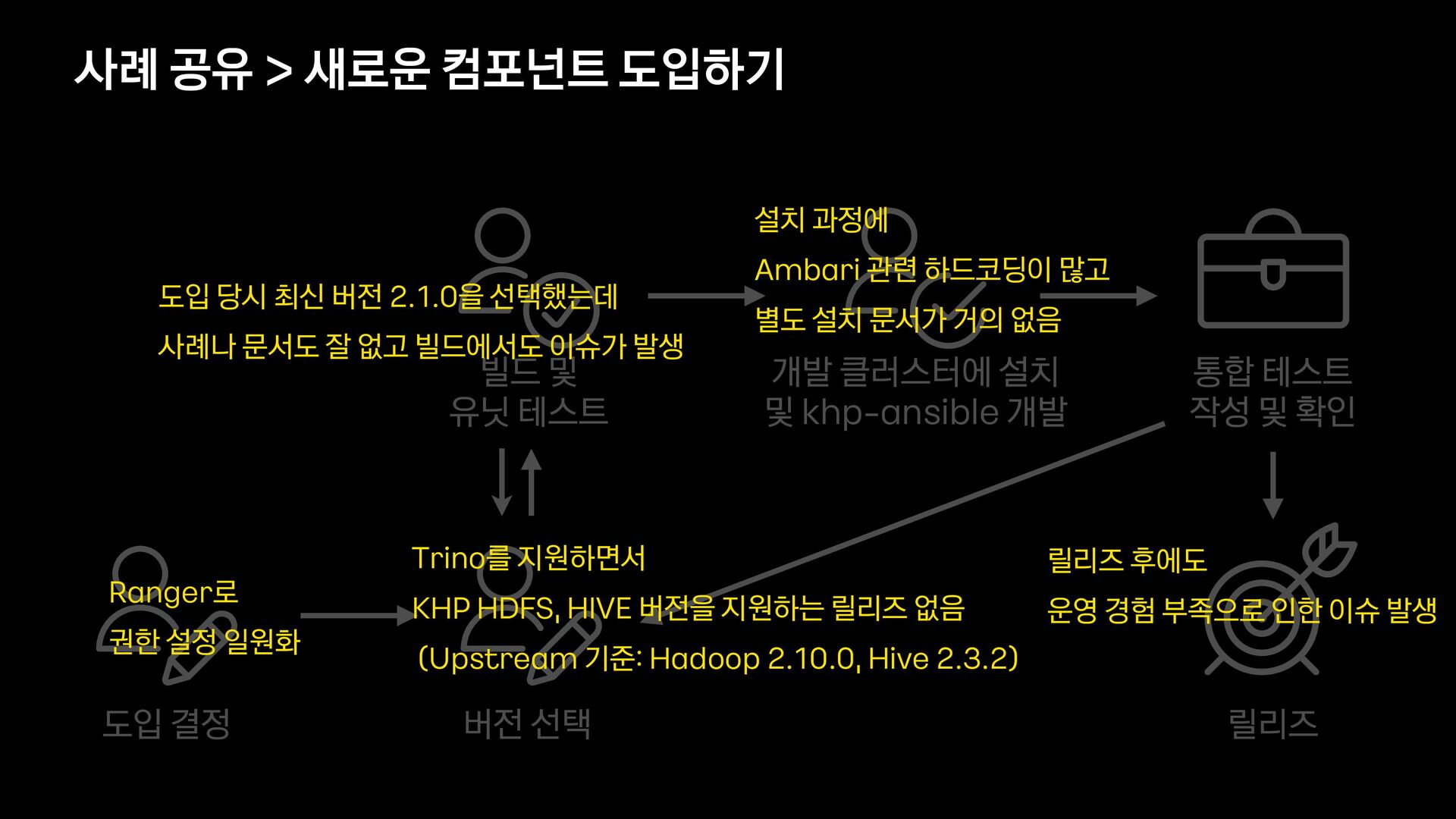
HIVE 버전을 지원하는 릴리즈 없음 (Upstream 기준: Hadoop 2.10.0, Hive 2.3.2) 설치 과정에 Ambari 관련 하드코딩이 많고 별도 설치 문서가 거의 없음 도입 당시 최신 버전 2.1.0을 선택했는데 사례나 문서도 잘 없고 빌드에서도 이슈가 발생 릴리즈 후에도 운영 경험 부족으로 인한 이슈 발생 Ranger로 권한 설정 일원화
없다면 run_once로 설정 - 플레이북 실행 시 —limit과 —tag 옵션을 최대한 활용 - 오래 걸리는 일부 task들을 외부 process로 실행 - 실행 환경으로 Linux docker 활용 - 대상 호스트가 수백에서 수천까지 늘어나며 macOS Kerberos 관련 GSSCred 프로세스가 CPU를 많이 사용하면서 느려지며 connection timemout 발생 - AWX를 통한 작업 서버 병렬화 고려 사례 공유 > 대규모 클러스터 대상 Ansible 성능 이슈
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}