Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
システムとの会話から生まれる先手のDevOps
Search
KAKEHASHI
PRO
April 15, 2025
Technology
1.1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
システムとの会話から生まれる先手のDevOps
DevOpsDays Tokyo 2025
https://www.devopsdaystokyo.org/
での登壇資料です
KAKEHASHI
PRO
April 15, 2025
More Decks by KAKEHASHI
See All by KAKEHASHI
「軸足」は 固定しなくていい - 熱量と強みで描く、しなやかなキャリアの形
kakehashi
PRO
1
320
Sync と Async ─ useSyncExternalStore を使う者の岐路
kakehashi
PRO
1
570
React Compiler導入の効果と運用の工夫
kakehashi
PRO
3
470
変化の激しい時代をゴキゲンに生き抜くために 〜ストレスマネジメントのススメ〜
kakehashi
PRO
5
2.5k
「SaaSの次の時代」に重要性を増すステークホルダーマネジメントの要諦 ~解像度を圧倒的に高めPdMの価値を最大化させる方法~
kakehashi
PRO
3
5k
プロダクトを育てるように生成AIによる開発プロセスを育てよう
kakehashi
PRO
2
2.1k
チームのモメンタムに投資せよ! 不確実性と共存しながら勢いを生み出す3つの実践
kakehashi
PRO
1
400
FAXが現役の業界でマルチモーダルAIプロダクトを作る
kakehashi
PRO
1
330
EMからVPoEを経てCTOへ:マネジメントキャリアパスにおける葛藤と成長
kakehashi
PRO
9
4k
Other Decks in Technology
See All in Technology
LiDAR SLAMの実装とセンサ融合 ~Lie群からContinuous-Time LIOまで~
naokiakai
1
830
Why is RC4 still being used?
tamaiyutaro
0
270
開発組織のAI活用レベルを可視化する「エンジニア版AI番付」の取り組み
fuzzy31u
0
100
NDIAS CTF 2026 問題解説会資料
bata_24
0
160
きのこカンファレンス2026_肩書きを外したとき私は誰か
yamasatimi
1
120
AIに障害切り分けを全部やってもらった。 。 。 。
estie
0
330
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
130
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
100
4人目のSREはAgent
tanimuyk
0
360
5分でわかるDuckDB Quack
chanyou0311
4
290
知見・人・API・DB・予算 ─ ナイナイ尽くしだった人事データ整備 with dbt、5年間の学び
ken6377
1
130
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.3k
Featured
See All Featured
RailsConf 2023
tenderlove
30
1.5k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
250
30 Presentation Tips
portentint
PRO
1
340
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Evolving SEO for Evolving Search Engines
ryanjones
0
230
Done Done
chrislema
186
16k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
The Limits of Empathy - UXLibs8
cassininazir
1
380
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
860
Designing Powerful Visuals for Engaging Learning
tmiket
1
430
YesSQL, Process and Tooling at Scale
rocio
174
15k
Transcript
©KAKEHASHI inc. システムとの会話から生まれる先手のDevOps 2025年4月15日 松本 明紘 DevOpsDays Tokyo 2025
©KAKEHASHI inc. 株式会社 カケハシ(2023年2月〜) • AI在庫管理、医薬品のSCM関連の新規事業 • バックエンドに軸足を置くテックリード もっち(X: @mottyzzz)
松本 明紘 2 自己紹介 https://speakerdeck.com/kakehashi
Mission 日本の医療体験を、 しなやかに。 カケハシは、調剤薬局DXを入り口に 日本の医療システムの再構築を目指す ヘルステックスタートアップ
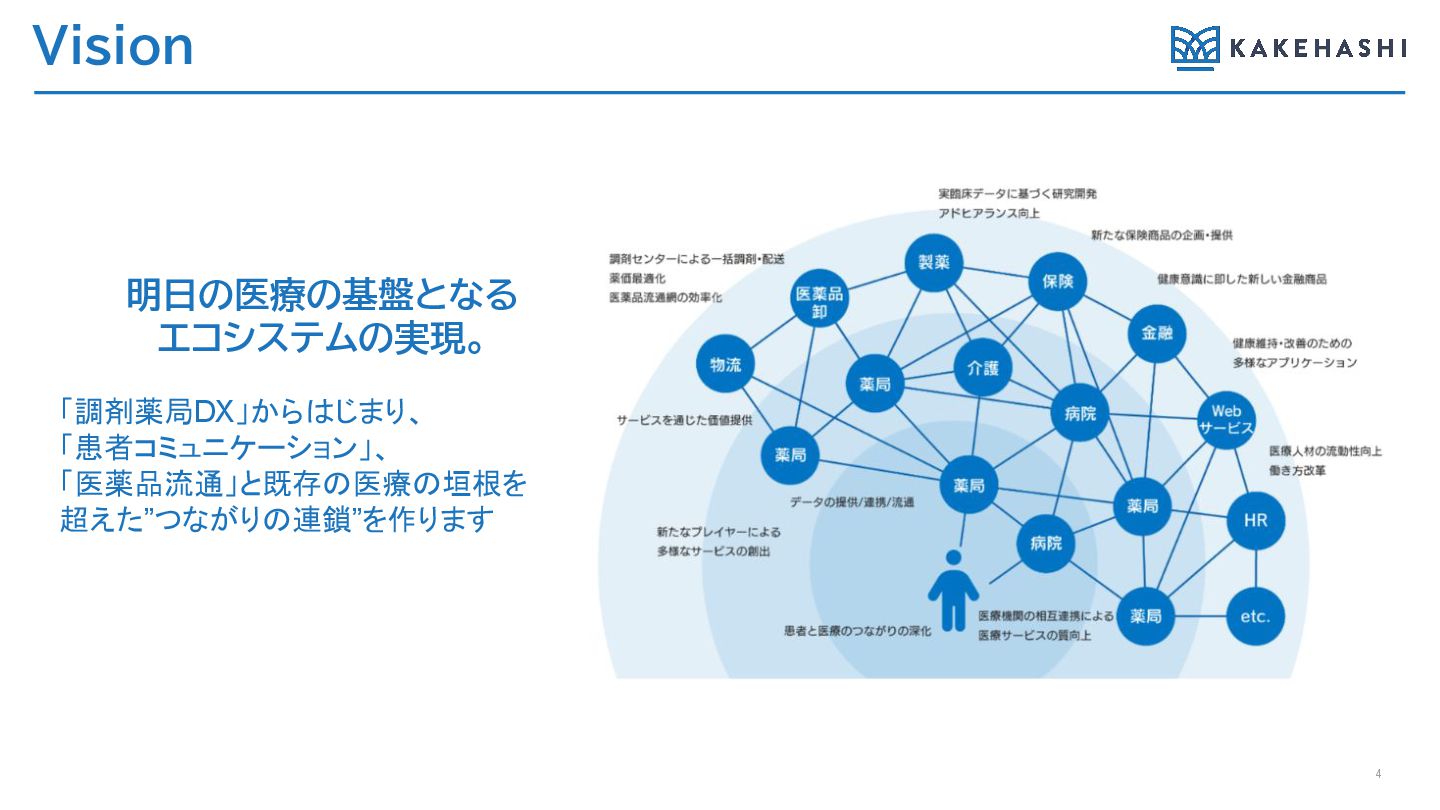
Vision 明日の医療の基盤となる エコシステムの実現。 「調剤薬局DX」からはじまり、 「患者コミュニケーション」、 「医薬品流通」と既存の医療の垣根を 超えた”つながりの連鎖”を作ります 4
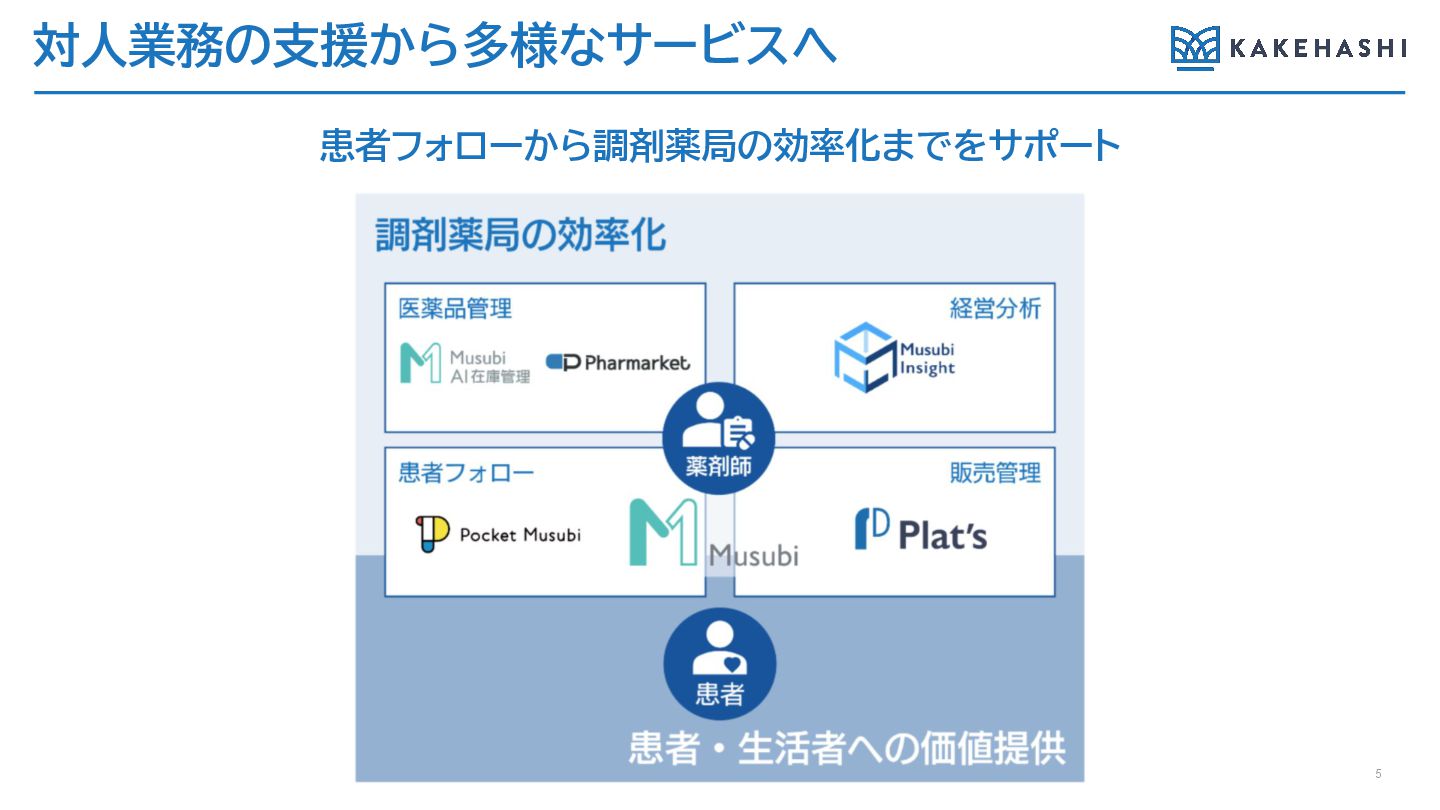
対人業務の支援から多様なサービスへ 患者フォローから調剤薬局の効率化までをサポート 5
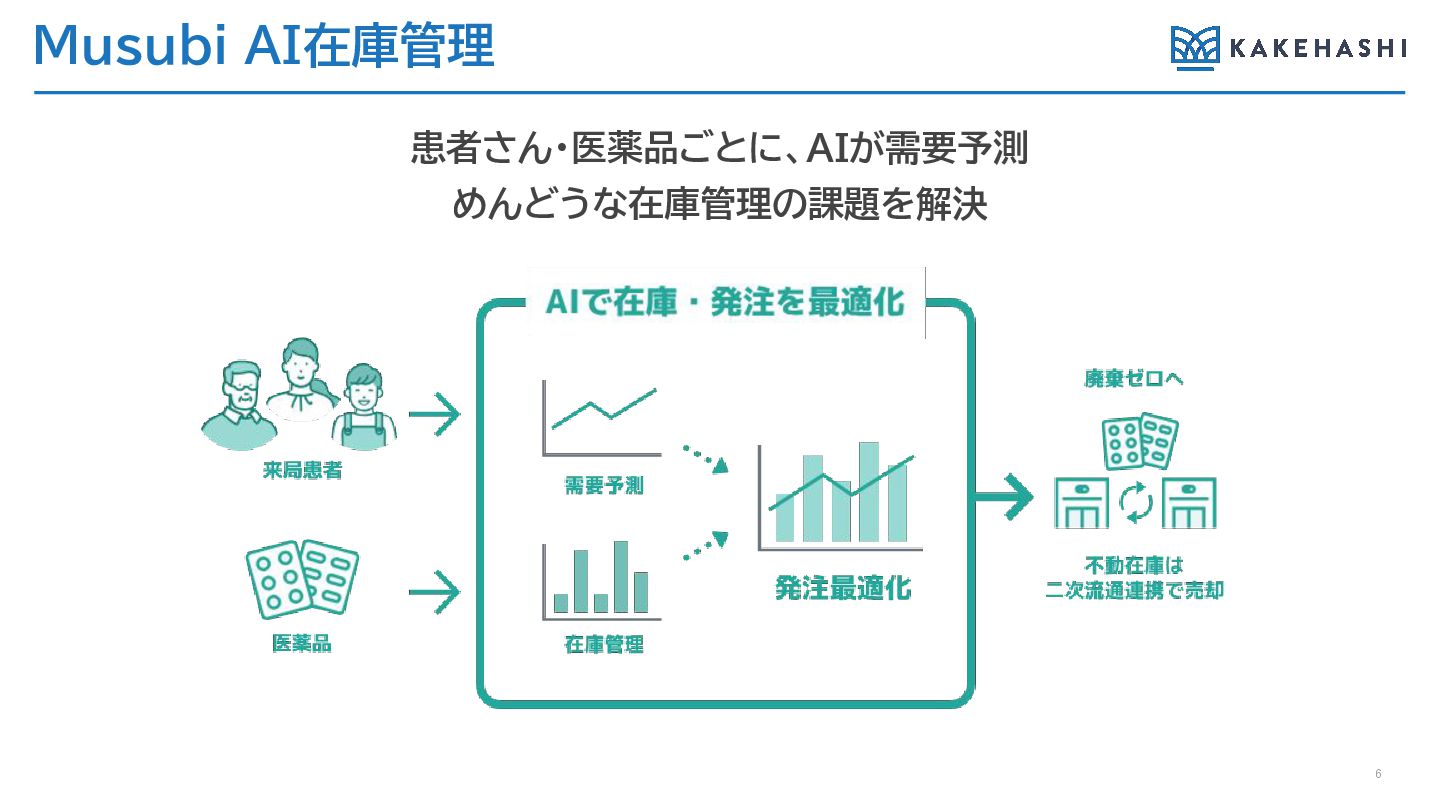
Musubi AI在庫管理 6 患者さん・医薬品ごとに、AIが需要予測 めんどうな在庫管理の課題を解決
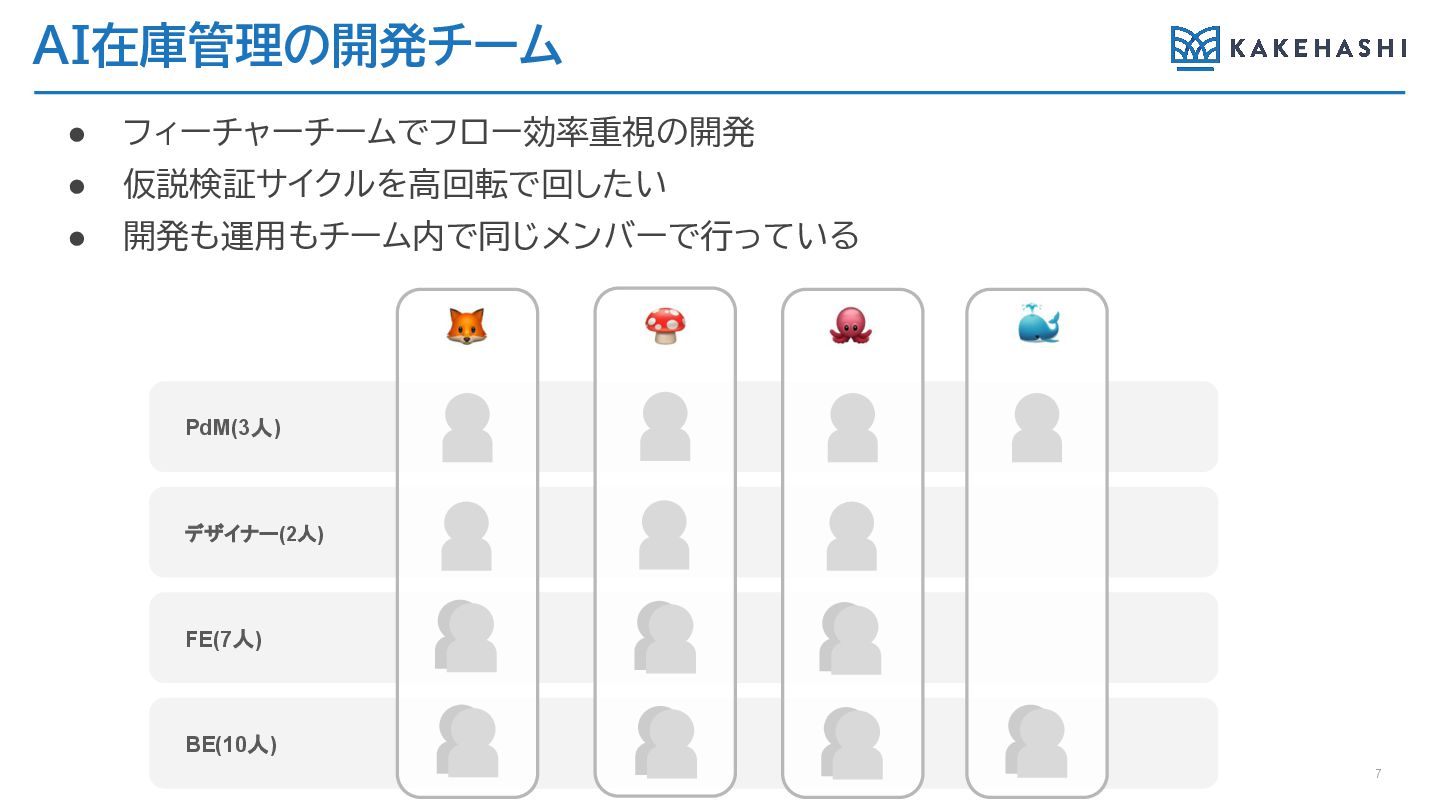
AI在庫管理の開発チーム • フィーチャーチームでフロー効率重視の開発 • 仮説検証サイクルを高回転で回したい • 開発も運用もチーム内で同じメンバーで行っている PdM(3人) デザイナー(2人) FE(7人)
BE(10人) 7
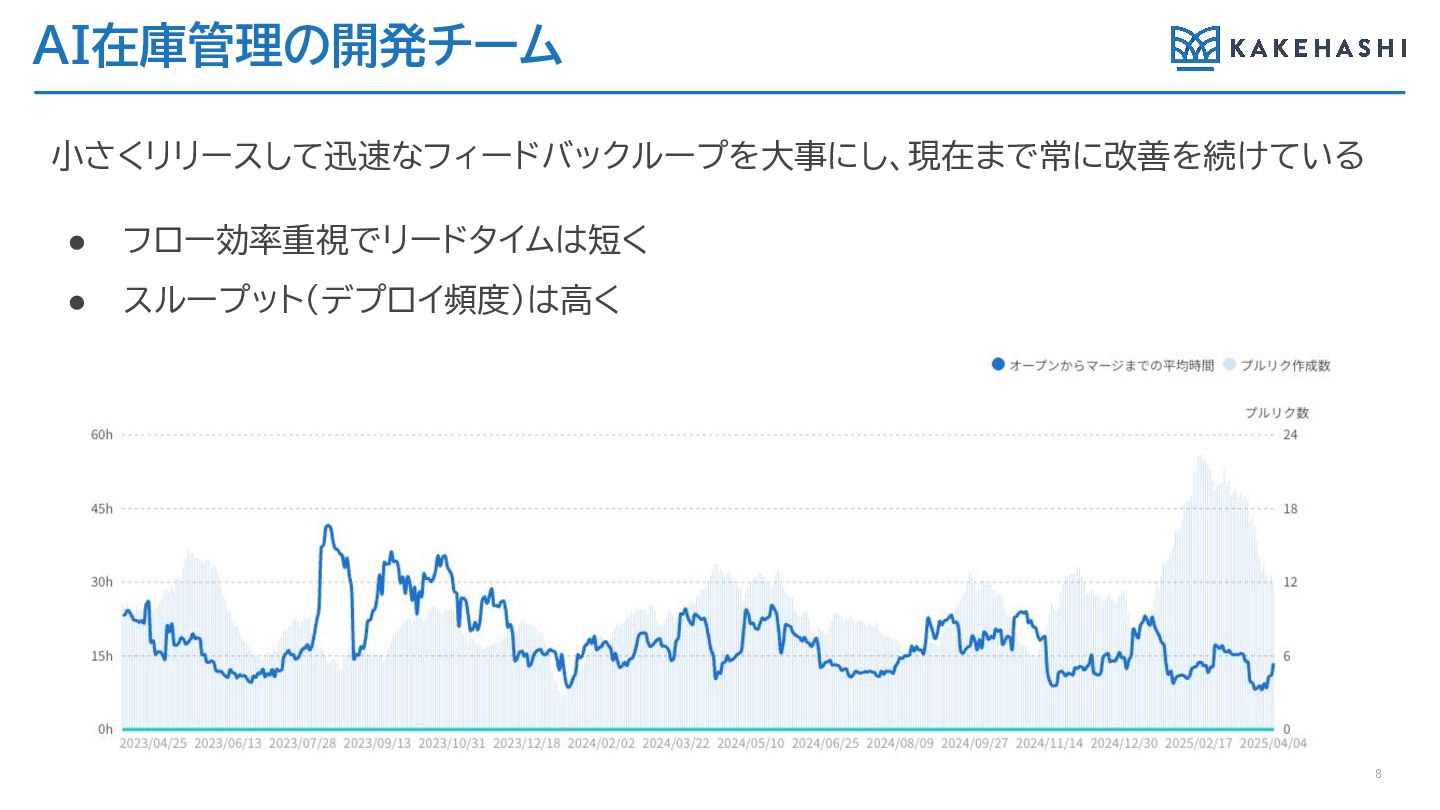
AI在庫管理の開発チーム 小さくリリースして迅速なフィードバックループを大事にし、現在まで常に改善を続けている • フロー効率重視でリードタイムは短く • スループット(デプロイ頻度)は高く 8
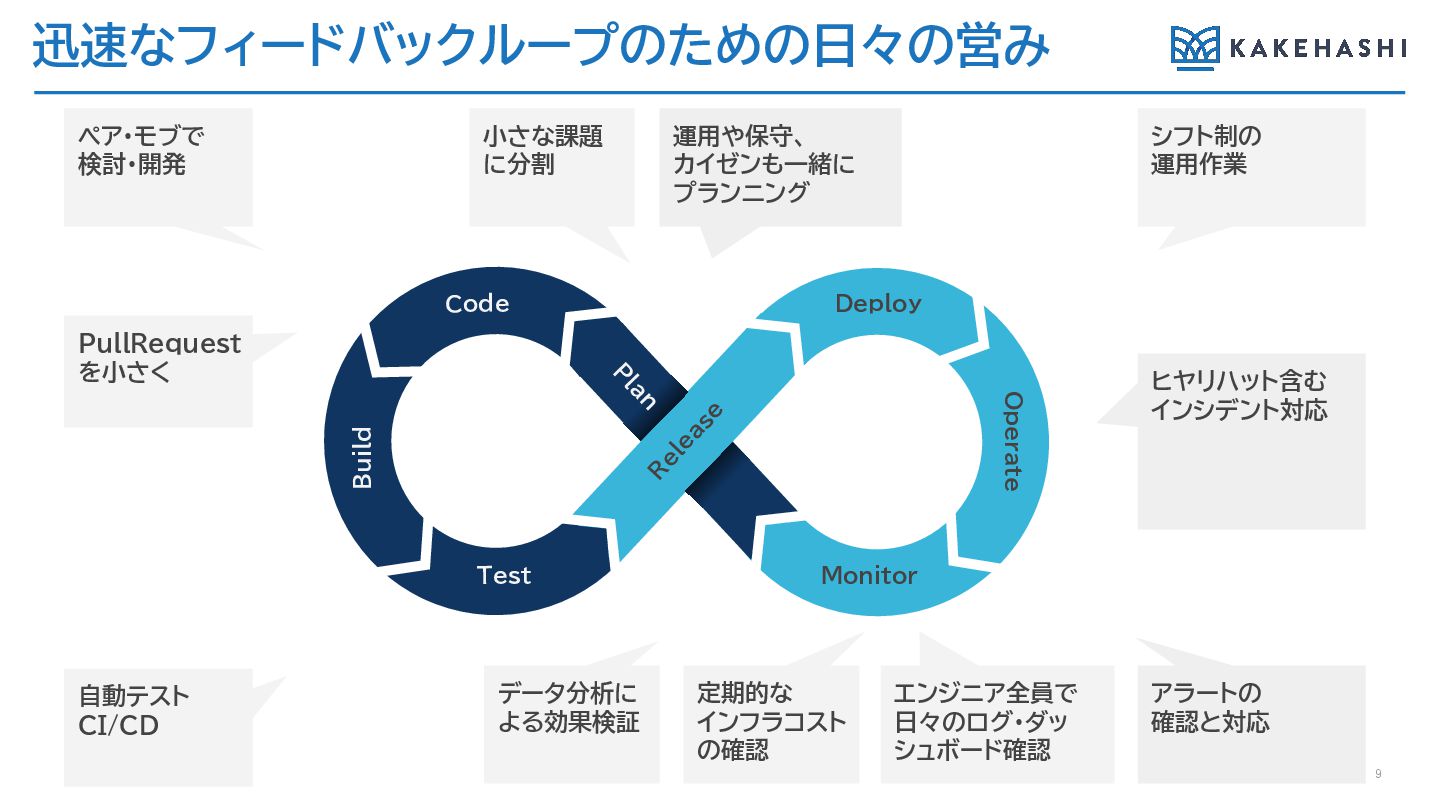
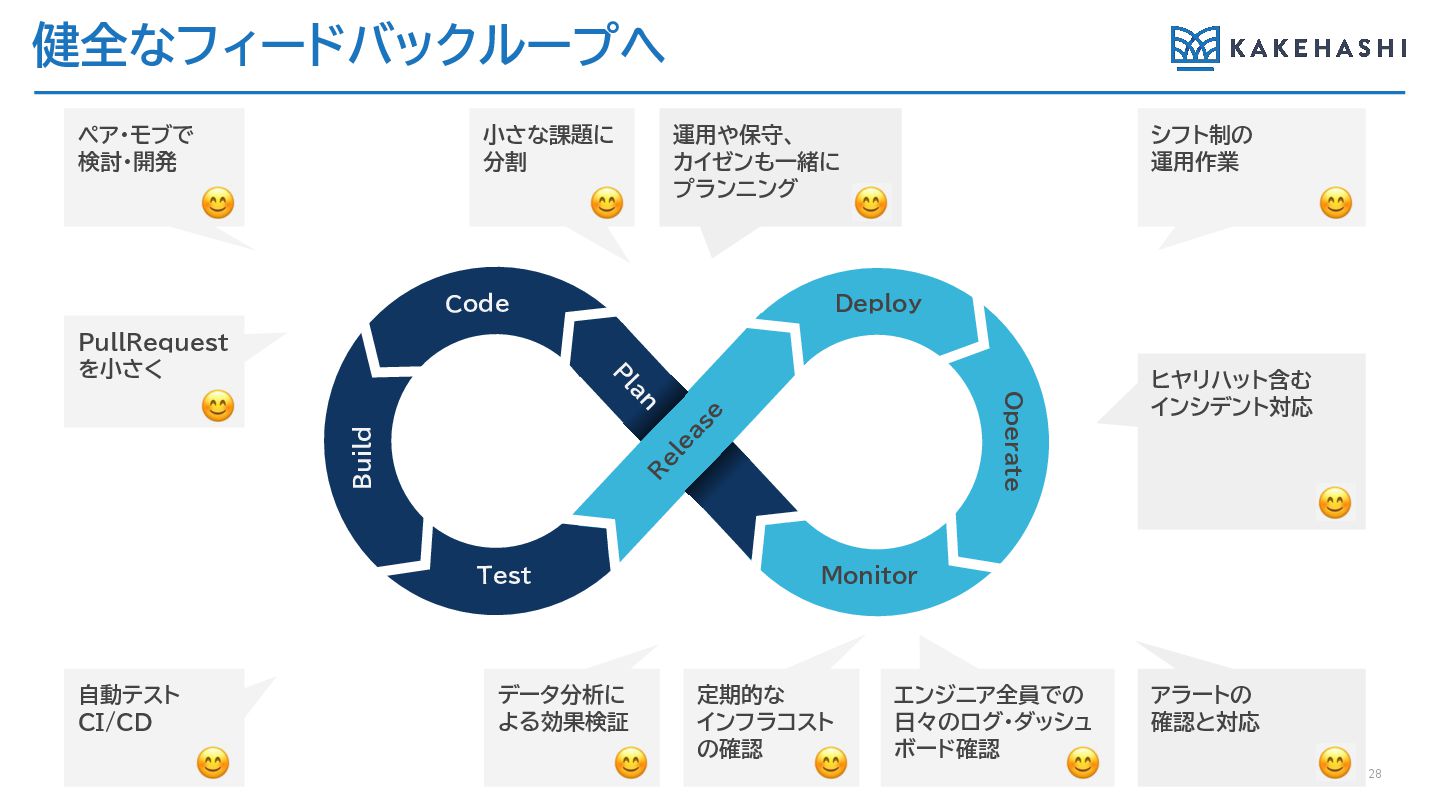
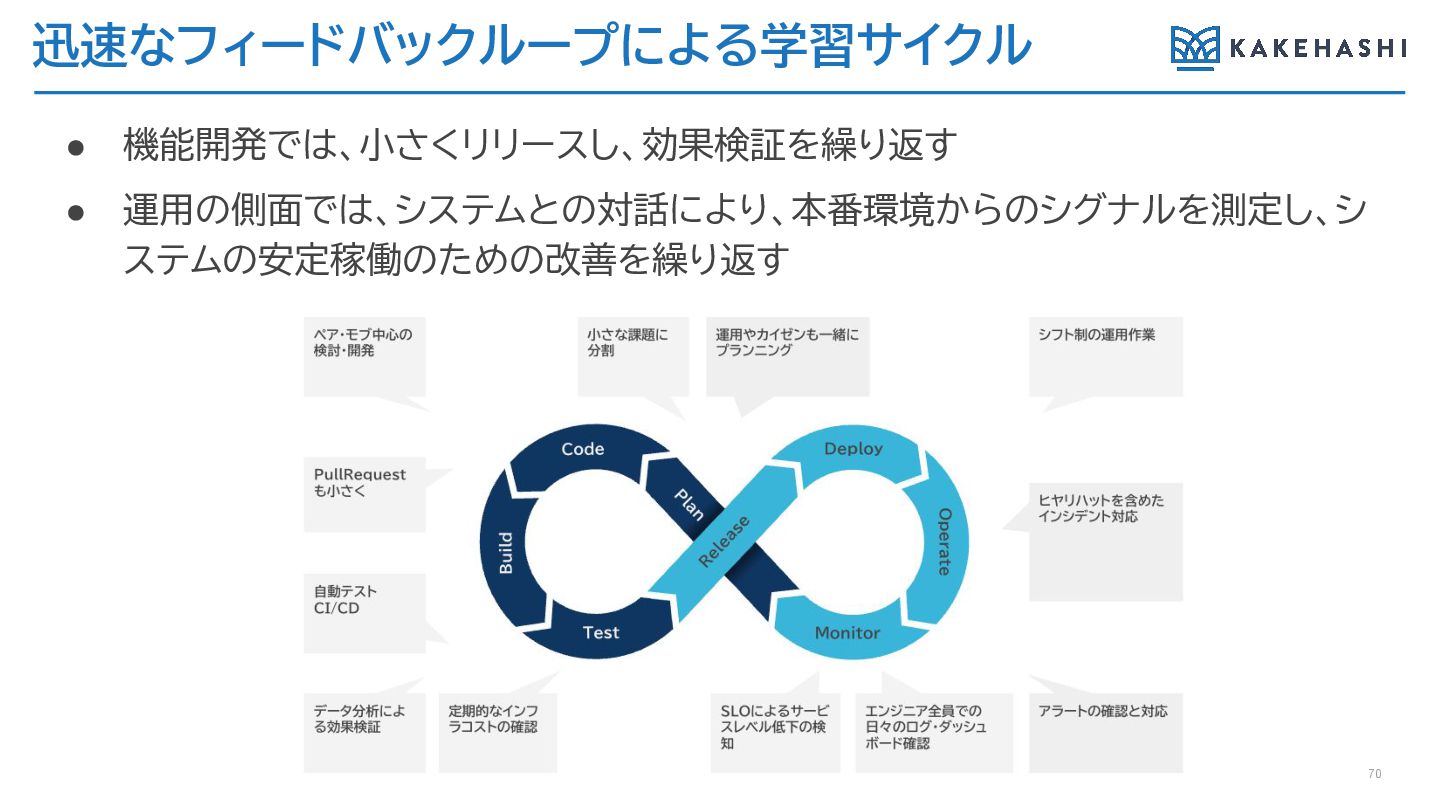
迅速なフィードバックループのための日々の営み 9 PullRequest を小さく 小さな課題 に分割 エンジニア全員で 日々のログ・ダッ シュボード確認 運用や保守、
カイゼンも一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
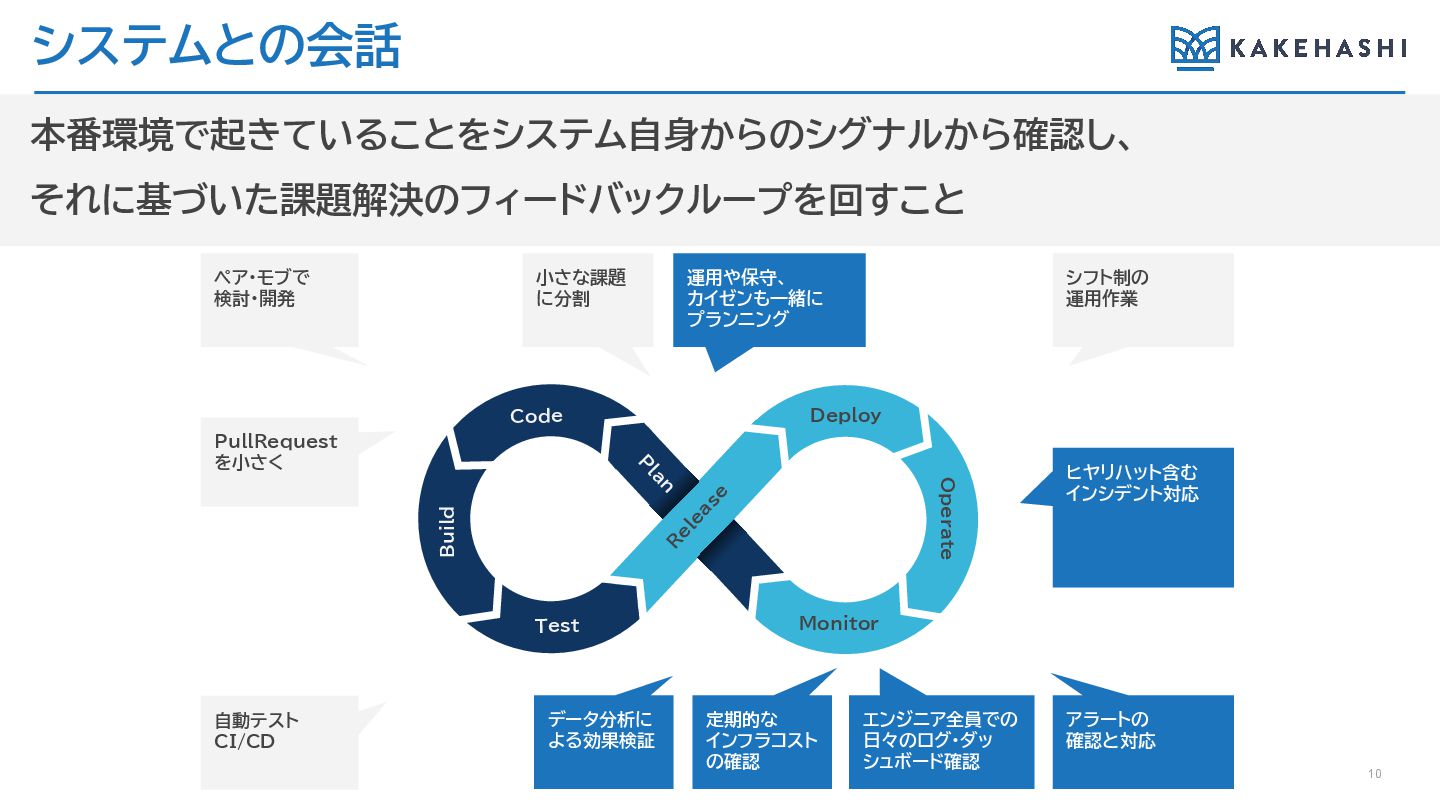
システムとの会話 10 本番環境で起きていることをシステム自身からのシグナルから確認し、 それに基づいた課題解決のフィードバックループを回すこと PullRequest を小さく 小さな課題 に分割 エンジニア全員での 日々のログ・ダッ
シュボード確認 運用や保守、 カイゼンも一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
プロダクトのフェーズが 変わってきた
2024年初旬 大手法人様への導入が決定 開発プロジェクトを開始
導入に向けてさまざまなワーキンググループが発足 • 導入推進 ◦ 既存の在庫管理システムからAI在庫管理への移行にあたりデータ移行の仕組みづくり ◦ 顧客の本部組織と連携して、各店舗の移行をスムーズに進めるためのプラン策定 • サポート体制の見直し •
障害対応フローの見直し ◦ 顧客への障害時のエスカレーション方針の確認 ◦ 障害レベル、障害フローの再定義 • 大手法人向け新規機能開発 ◦ 本部組織向けの機能 ◦ これまでは運用でカバーしていたものを機能化 • 既存ユーザー向けの機能エンハンス ◦ 大手法人向けの開発に注力はするが、対応がゼロにはできない 13
総力戦!!!
やるぞ!!!
しかしこのとき AI在庫管理のチームは 課題を抱えていた
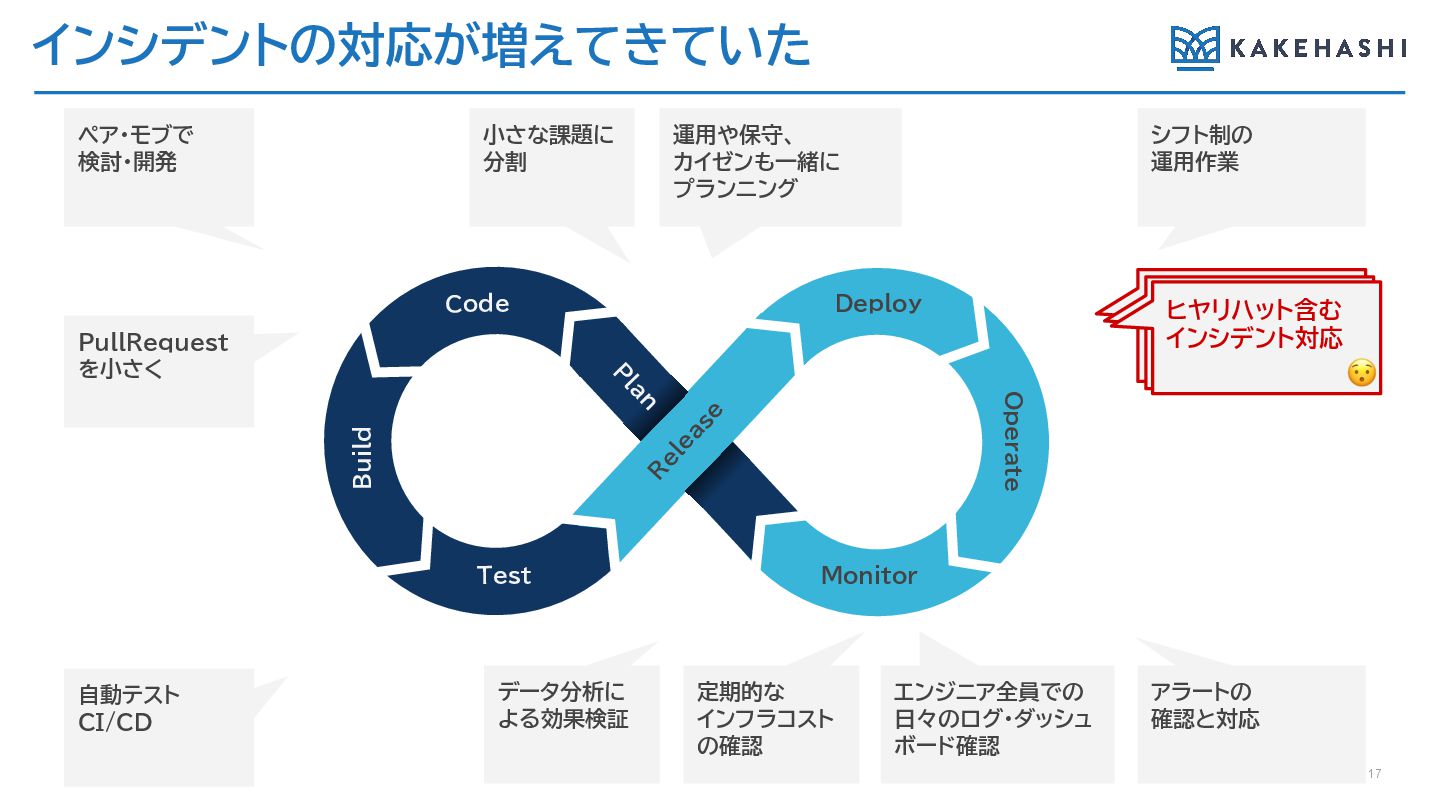
インシデントの対応が増えてきていた 17 PullRequest を小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 運用や保守、
カイゼンも一緒に プランニング ヒヤリハットを含めた インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 ヒヤリハットを含めた インシデント対応 ヒヤリハット含む インシデント対応 Deploy Monitor R elease Code Test Operate P lan Build
AI在庫管理のインシデント対応 18 AI在庫管理で定義するインシデントとは https://speakerdeck.com/kakehashi/more-incident-reports
インシデントから成長できるチームを目指している 19 https://speakerdeck.com/kakehashi/more-incident-reports
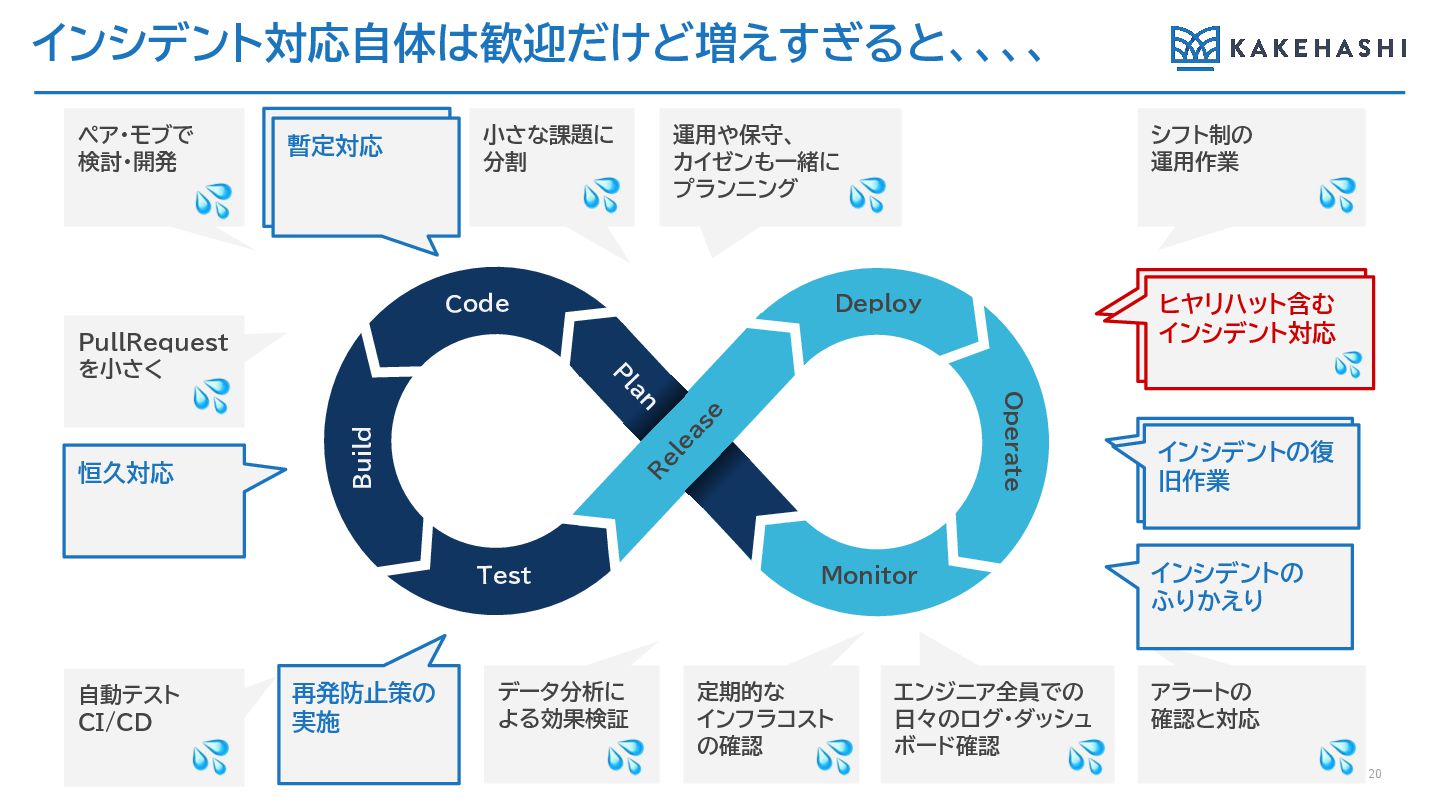
インシデント対応自体は歓迎だけど増えすぎると、、、、 20 PullRequest を小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 運用や保守、
カイゼンも一緒に プランニング ヒヤリハットを含めた インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 ヒヤリハット含む インシデント対応 インシデントの復旧作 業 インシデントの復 旧作業 インシデントの ふりかえり 暫定対応 恒久対応 再発防止策の 実施 暫定対応 Deploy Monitor R elease Code Test Operate P lan Build
Deploy Monitor R elease Code Test Operate P lan Build
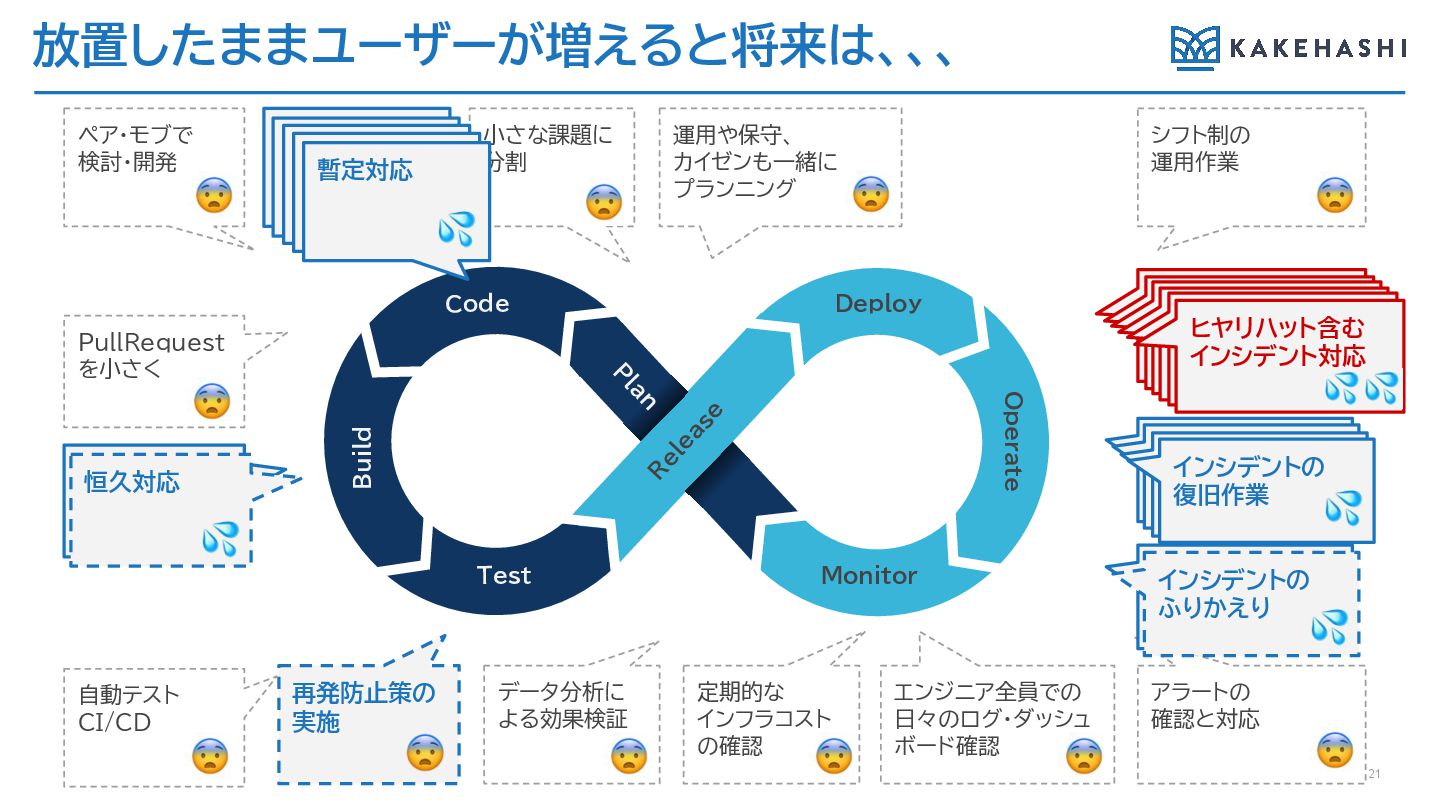
放置したままユーザーが増えると将来は、、、 21 PullRequest を小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 運用や保守、 カイゼンも一緒に プランニング ヒヤリハットを含めた インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 ヒヤリハットを含めた インシデント対応 ヒヤリハットを含めた インシデント対応 ヒヤリハットを含めた インシデント対応 ヒヤリハットを含めた インシデント対応 ヒヤリハット含む インシデント対応 インシデントの復旧作 業 インシデントの復旧作 業 インシデントの復旧作 業 インシデントの 復旧作業 インシデントの ふりかえり インシデントの ふりかえり 暫定対応 恒久対応 再発防止策の 実施 暫定対応 暫定対応 暫定対応 暫定対応 恒久対応
品質・信頼性向上のワーキンググループが発足 • 導入推進 ◦ 既存の在庫管理システムからAI在庫管理への移行にあたりデータ移行の仕組みづくり ◦ 顧客の本部組織と連携して、各店舗の移行をスムーズに進めるためのプラン策定 • サポート体制の見直し •
障害対応フローの見直し ◦ 顧客への障害時のエスカレーション方針の確認 ◦ 障害レベル、障害フローの再定義 • 大手法人向け新規機能開発 ◦ 本部組織向けの機能 ◦ これまでは運用でカバーしていたものを機能化 • 既存ユーザー向けの機能エンハンス ◦ 大手法人向けの開発に注力はするが、対応がゼロにはできない • 品質向上・信頼性向上 ← New ◦ 大手法人導入後に大きな問題につながるようなインシデントの防止 ◦ よく発生しているインシデントの発生箇所・原因箇所の見直し 22
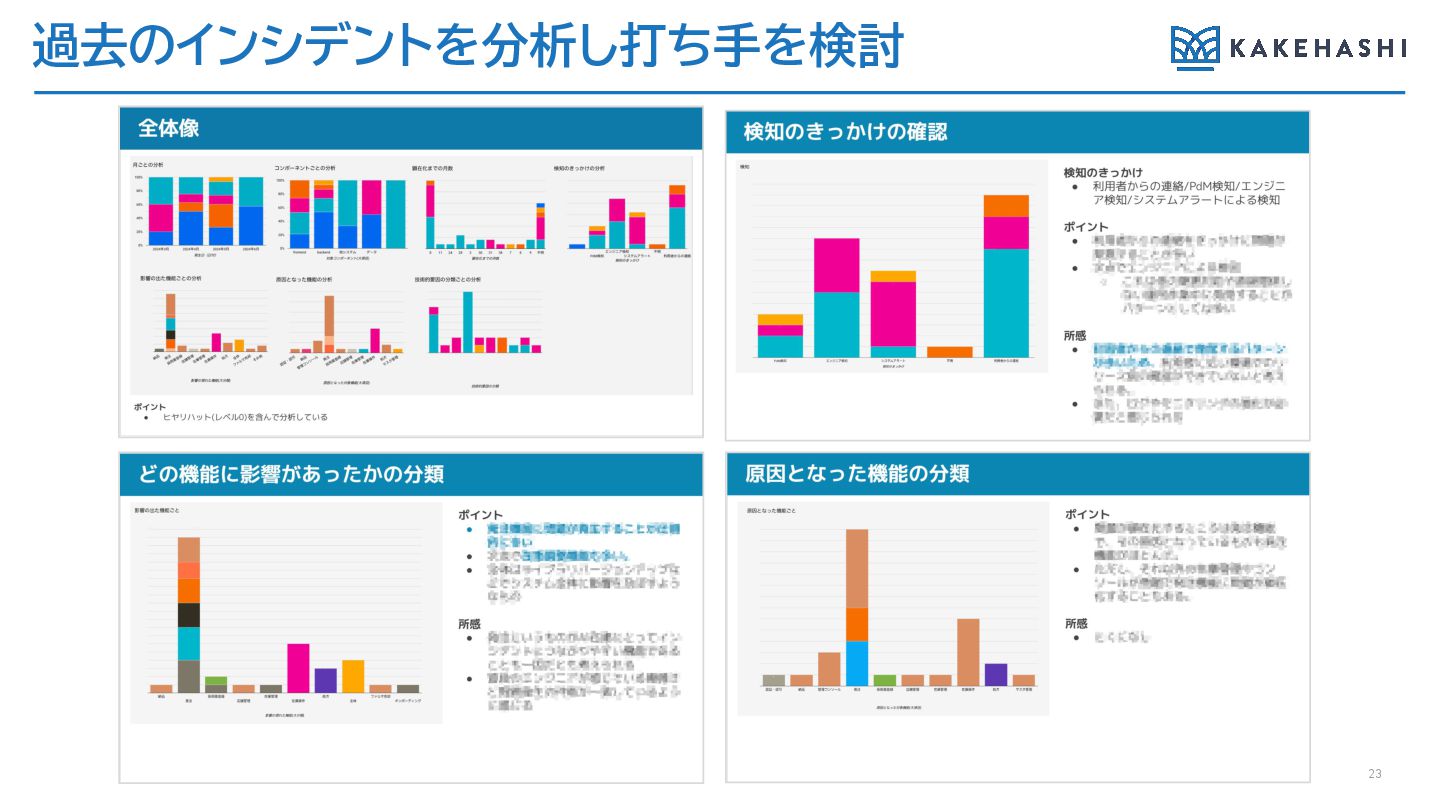
過去のインシデントを分析し打ち手を検討 23
どのような観点での分析をしたか # 観点 説明 使い方 1 障害レベル レベル0〜レベル5の障害レベル 発生数に対しての打ち手か、大きな障害への打ち手か、ど ちらへの打ち手が効果があるかの確認
2 発生月 いつに発生したインシデントか 何かの体制変更などのイベント、大きな機能開発など発生 につながった要素がありそうかの確認 3 対象コンポーネント backend/frontend/外部システ ム連携/データ コンポーネント、サブコンポーネントごとに見直しが必要な コンポーネントの特定 4 作り込み顕在化まで の月数 作り込み日から発生日までの月数 リリースしてすぐの検知が多ければテスト方法やリリース プロセスの見直し。過去に作り込んだ問題が多い場合は、 開発時の既存仕様の確認方法の見直し 5 検知のきっかけ システム検知、エンジニア検知、 PdM/CS検知、ユーザー検知 モニタリング、アラートの強化が必要か 6 現象が発生した機能 発注、在庫管理、処方などの機能 見直しが必要な機能の特定 7 原因となった機能 発注、在庫管理、処方などの機能 原因と現象発生の機能が異なる場合は、機能やシステム の依存関係が複雑になっている可能性がある 8 技術的要因の区分 状態管理不正、計算ロジック不正、ラ イブラリアップデート 偏りが見られる場合は、全体への類似見直しを検討する 24
リスクアセスメントを行い優先度を決定 25
対応を進めた結果 26 • インシデントの発生頻度を1/3にすることができた • 重大な顧客影響にしないために、問題の検知から薬局の業務開始までにリカバ リーをしていたような夜間のインシデント対応を無くすことができた
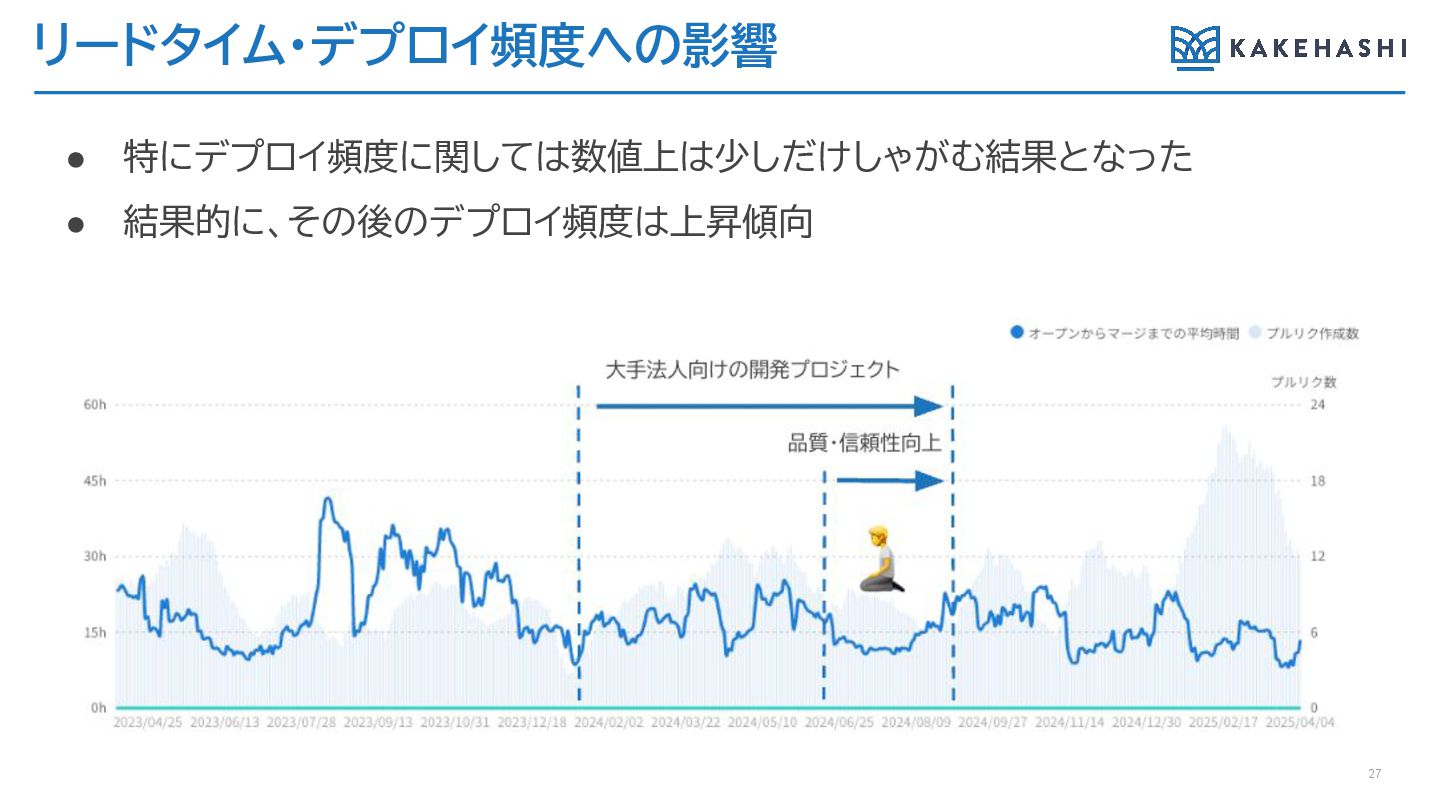
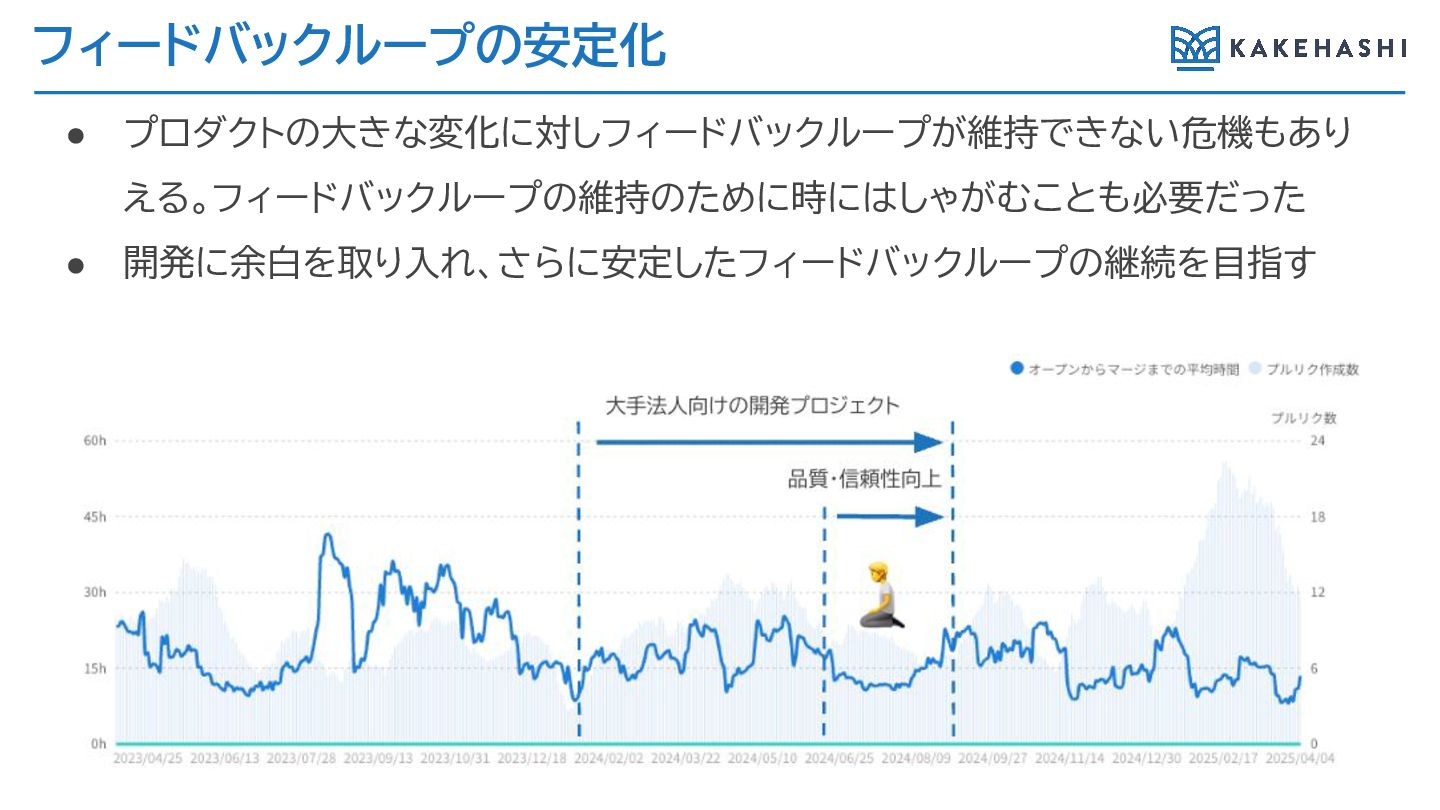
リードタイム・デプロイ頻度への影響 • 特にデプロイ頻度に関しては数値上は少しだけしゃがむ結果となった • 結果的に、その後のデプロイ頻度は上昇傾向 27
健全なフィードバックループへ 28 PullRequest を小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 運用や保守、
カイゼンも一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
大手法人への導入を 無事に終えることができた
先手を打てた部分もあるが、 大手法人様への導入を進める中で 初めて気づけたものもあった
インフラコストが 急上昇!!?
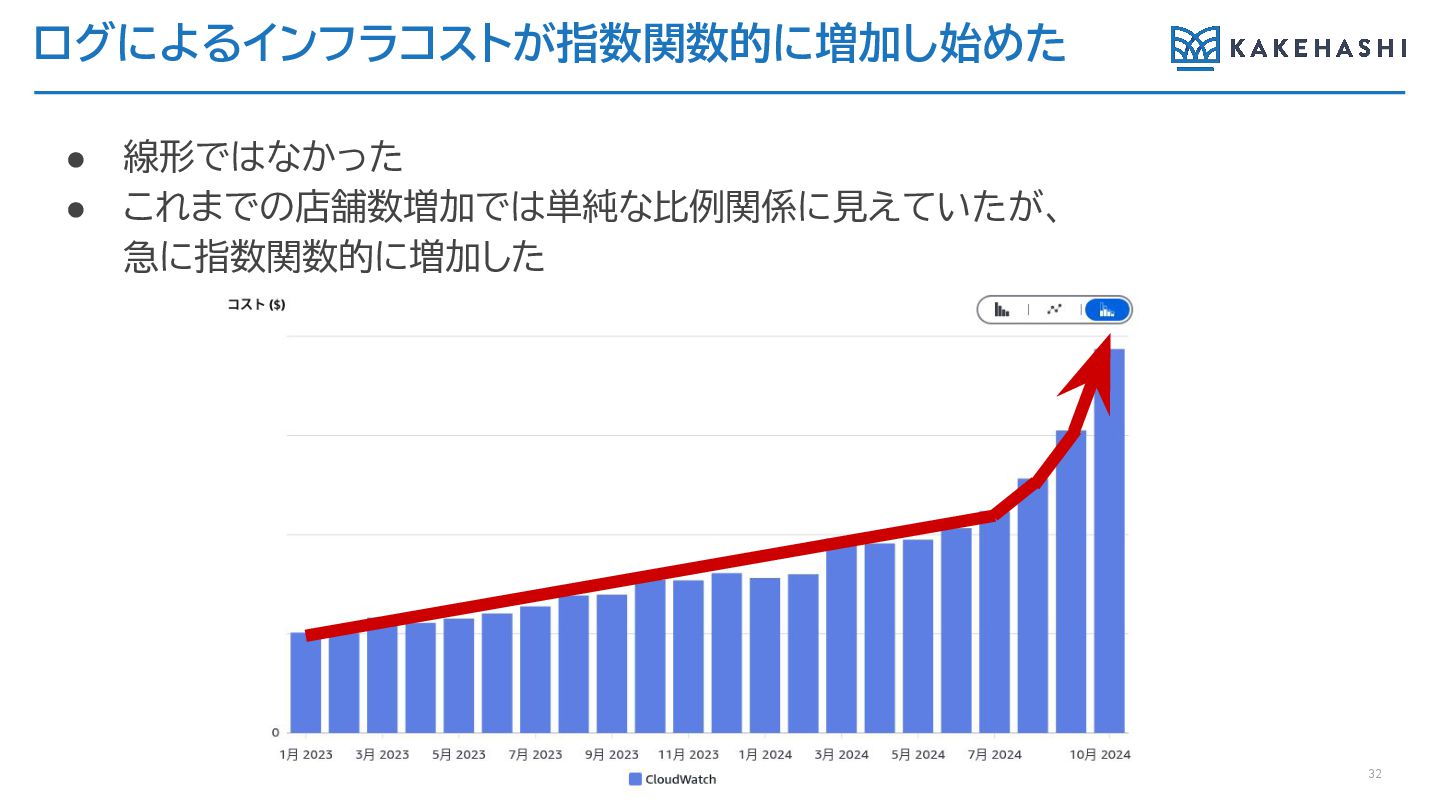
ログによるインフラコストが指数関数的に増加し始めた • 線形ではなかった • これまでの店舗数増加では単純な比例関係に見えていたが、 急に指数関数的に増加した 32
見直しを実施したログ • AWSのインフラが出力するシステムログの削減 ◦ Infoレベルの情報はトラブルシュートでもほぼ使っていなかったため、 出力ログレベルをWarnレベルに変更し、ログの書き込み量を削減 • アプリケーションで出力していた一部のInfoログの停止 ◦ なんとなくの安心感のために出力し、
使っていなかったアプリケーションのログを出力しないように変更 • 内部処理のトラブルシュートためのトレース情報の保管期間の見直し ◦ トレース情報は過去に渡って確認することがなかったため、保管の期間を見直し ◦ CloudWatch LogsとDatadogの両方に保管していたトレース情報をDatadogのみに変更 33
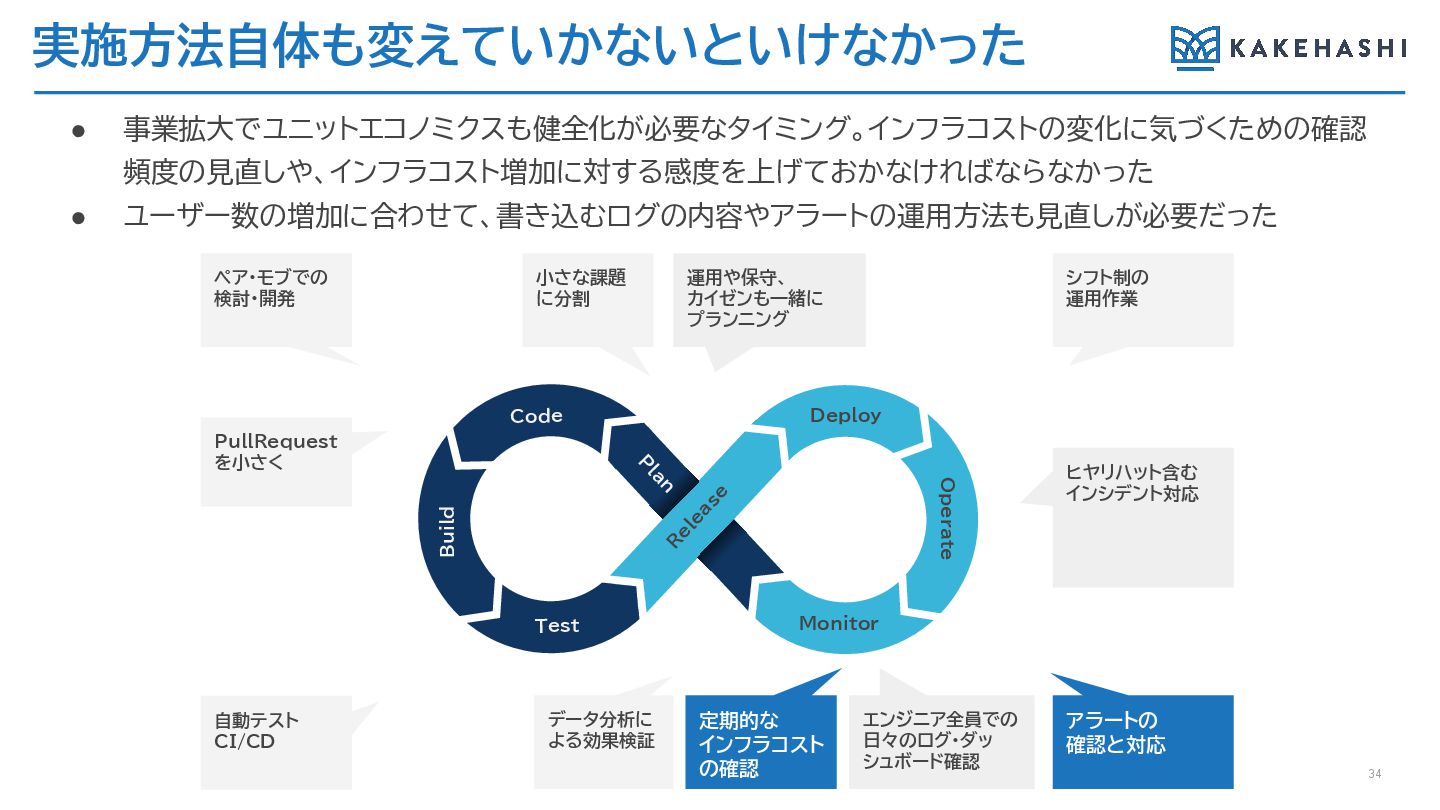
実施方法自体も変えていかないといけなかった 34 • 事業拡大でユニットエコノミクスも健全化が必要なタイミング。インフラコストの変化に気づくための確認 頻度の見直しや、インフラコスト増加に対する感度を上げておかなければならなかった • ユーザー数の増加に合わせて、書き込むログの内容やアラートの運用方法も見直しが必要だった PullRequest を小さく 小さな課題
に分割 エンジニア全員での 日々のログ・ダッ シュボード確認 運用や保守、 カイゼンも一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブでの 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
DB負荷が2倍に
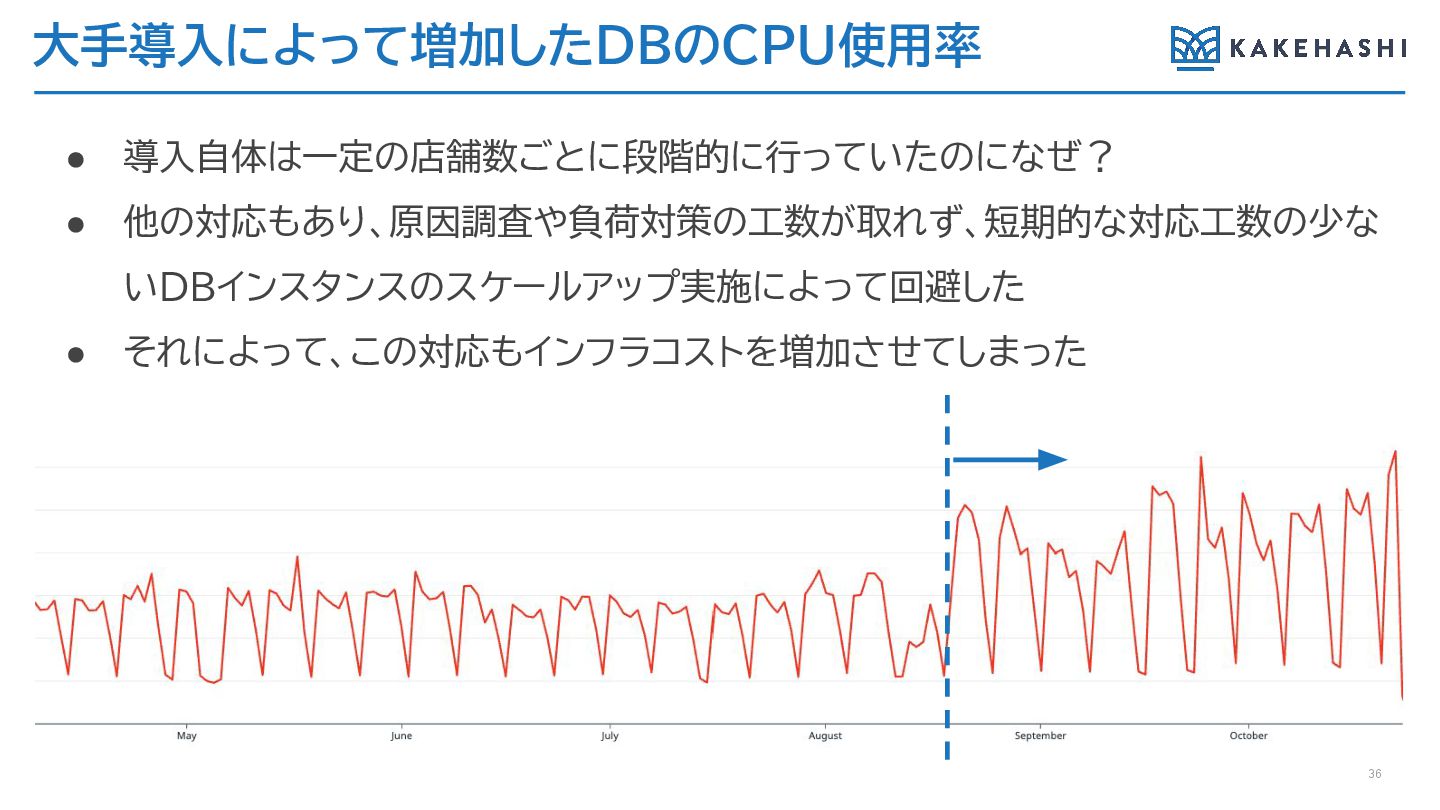
大手導入によって増加したDBのCPU使用率 36 • 導入自体は一定の店舗数ごとに段階的に行っていたのになぜ? • 他の対応もあり、原因調査や負荷対策の工数が取れず、短期的な対応工数の少な いDBインスタンスのスケールアップ実施によって回避した • それによって、この対応もインフラコストを増加させてしまった
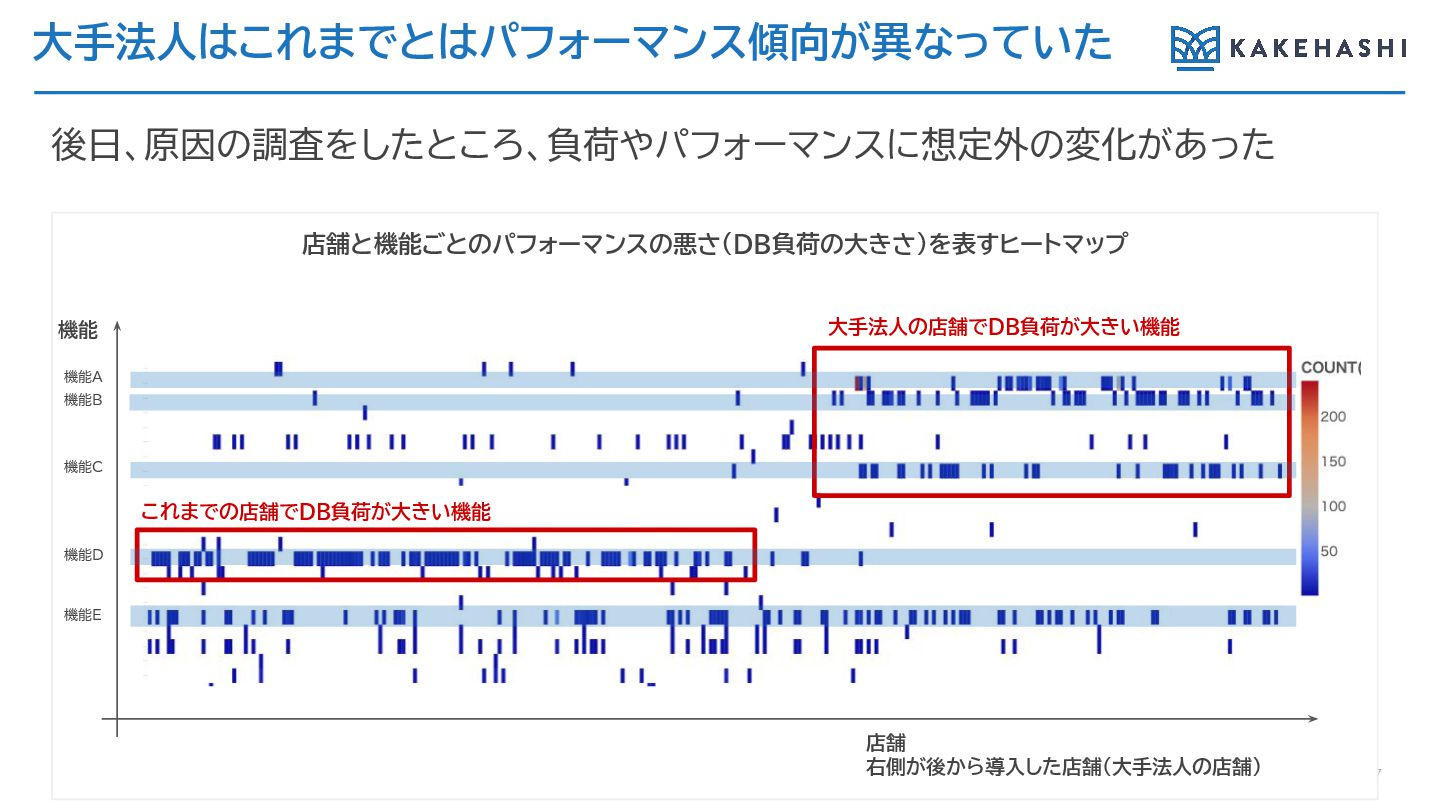
大手法人はこれまでとはパフォーマンス傾向が異なっていた 37 これまでの店舗でDB負荷が大きい機能 店舗と機能ごとのパフォーマンスの悪さ(DB負荷の大きさ)を表すヒートマップ 機能A 大手法人の店舗でDB負荷が大きい機能 店舗 右側が後から導入した店舗(大手法人の店舗) 後日、原因の調査をしたところ、負荷やパフォーマンスに想定外の変化があった 機能B
機能C 機能D 機能E 機能
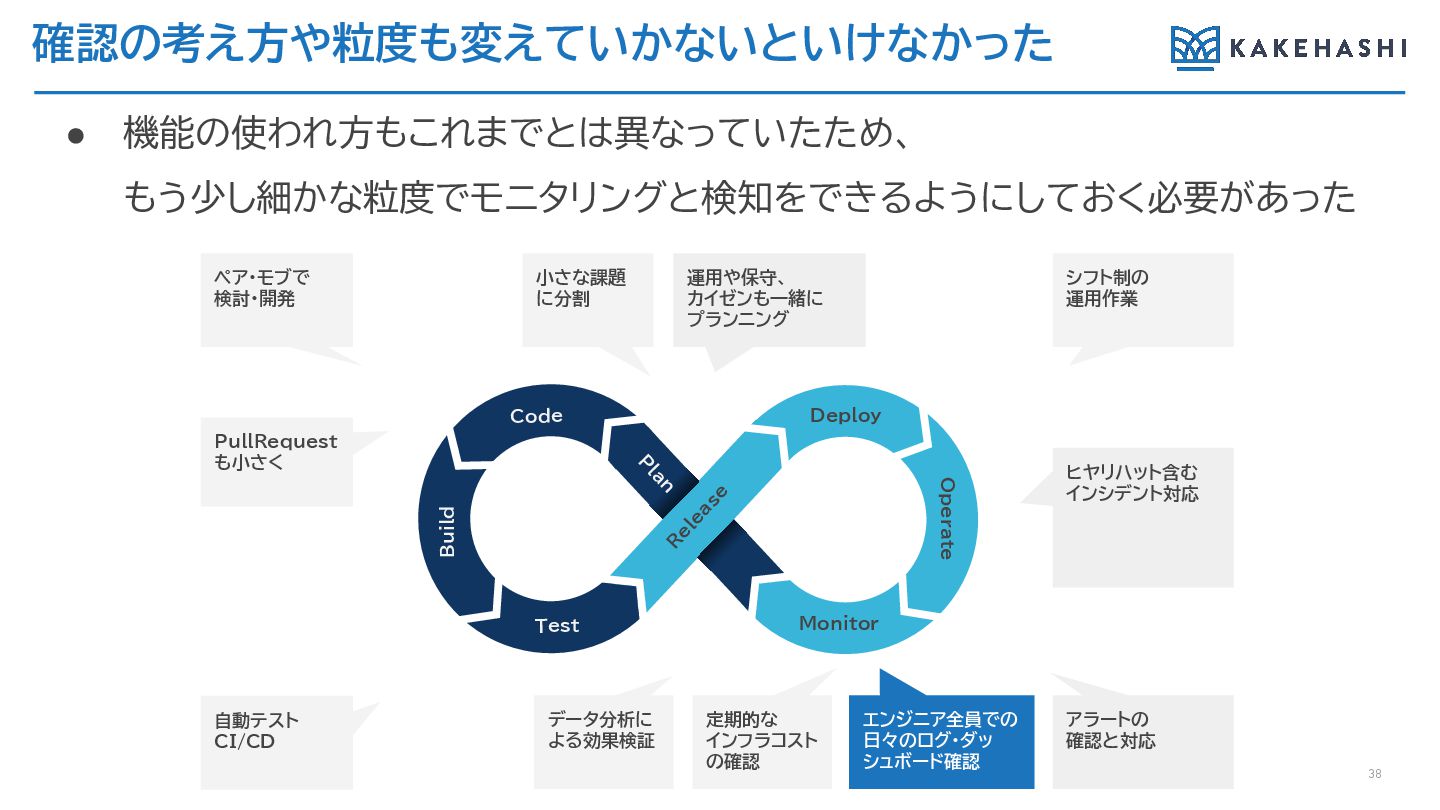
確認の考え方や粒度も変えていかないといけなかった 38 • 機能の使われ方もこれまでとは異なっていたため、 もう少し細かな粒度でモニタリングと検知をできるようにしておく必要があった PullRequest も小さく 小さな課題 に分割 エンジニア全員での
日々のログ・ダッ シュボード確認 運用や保守、 カイゼンも一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
それ以外にも色んな考え方を変化させていく必要がある これまで 拡大期(大手法人導入〜) 一度に導入される店舗数 数店舗〜数十店舗 数百店舗 機能性と品質 AI在庫管理のコア機能であるおすすめ発注 など、魅力的品質が求められてきた 魅力的品質はもちろん、資産管理としての在庫管理と
しても使われるため、当たり前品質も求められるよう になった 導入時のデータ投入 1店舗ずつなど進められた 同時に複数店舗の大量のデータ投入が必要になり、 データ投入時のシステム負荷が無視できない パフォーマンスとスケーラ ビリティ 除々に遅くなるなど変化が緩く、システム 全体の日々のモニタリングで十分に対処で きていた 導入店舗が急に増える、かつ、機能の使われ方も変 わったため、急なパフォーマンス変化が見られた。これ までよりも細かいモニタリングの粒度が必要だった モニタリングとアラート 日々のモニタリングで、対応が必要な場合 も十分に対処できていた システム規模が大きくなりこれまでのモニタリング粒 度では変化を把握できない アラート数も増え、対処が間に合わなくなる 運用 エンジニアの手動での運用でも十分に対応 できていた 店舗数が増えたことで日々の運用にかかる時間も増 えてきた インフラコスト PMFを優先し、ある程度無視できた 1店舗あたりのコストの健全性も事業継続のために重 要になってきた 39
開発のためのフィードバックループ だけじゃなく 日々の運用もフィードバックループの中 で改善できるようになりたい
やることはたくさん!
チーム全体で 変化に余裕を持って対応できる 習慣を作りたい
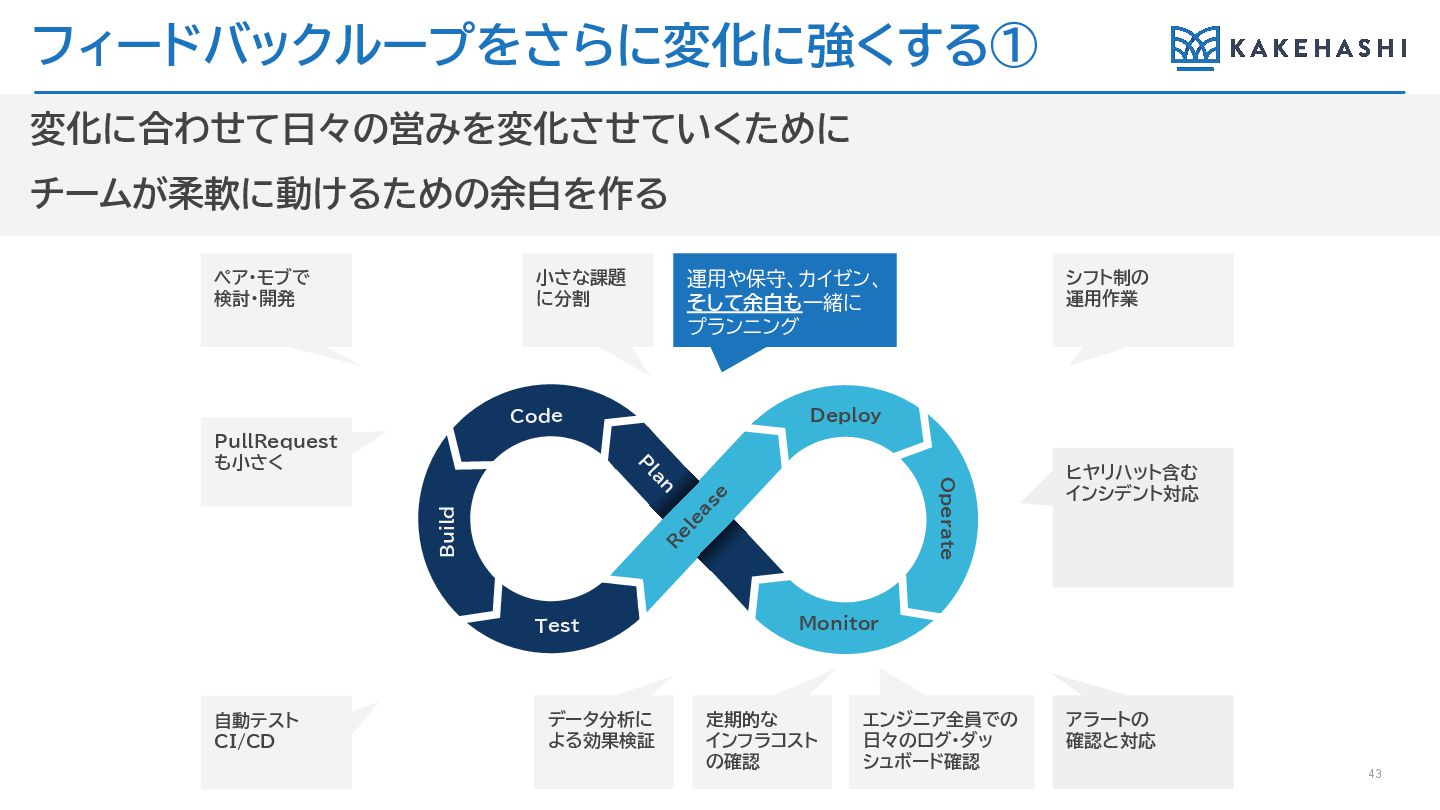
フィードバックループをさらに変化に強くする① 43 変化に合わせて日々の営みを変化させていくために チームが柔軟に動けるための余白を作る PullRequest も小さく 小さな課題 に分割 エンジニア全員での 日々のログ・ダッ
シュボード確認 運用や保守、カイゼン、 そして余白も一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
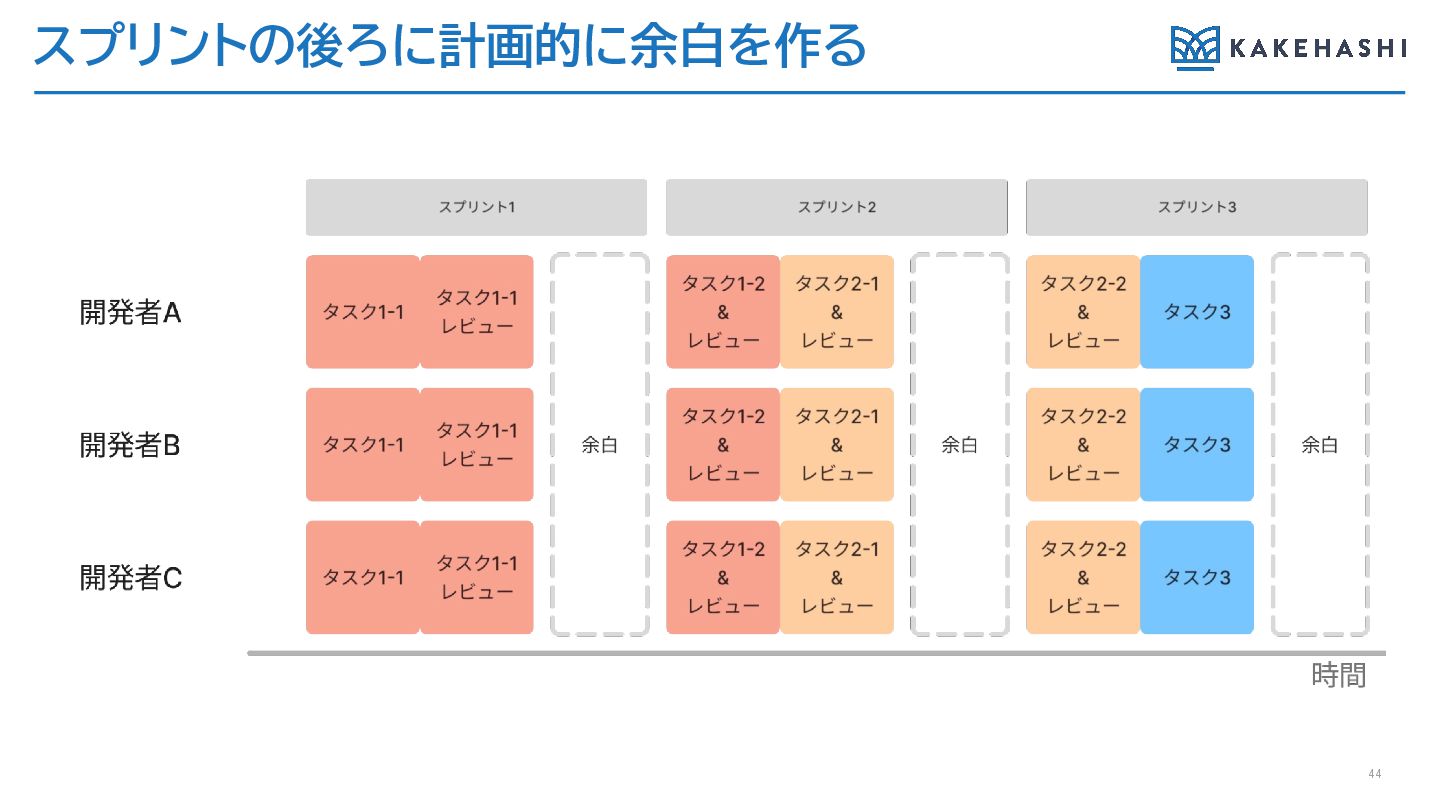
スプリントの後ろに計画的に余白を作る 44
スプリントの後ろに計画的に余白を作る 下記のようなワーキングアグリーメントで実際に取り組んでいる • 1週間スプリントの5日目はロードマップの開発は行わない • プランニング時点で1週間の最初の3日で完了するくらいの 余裕をもった計画にする • 想定より早くそのスプリントの開発が完了しとしても、 次の開発項目を始めない
45
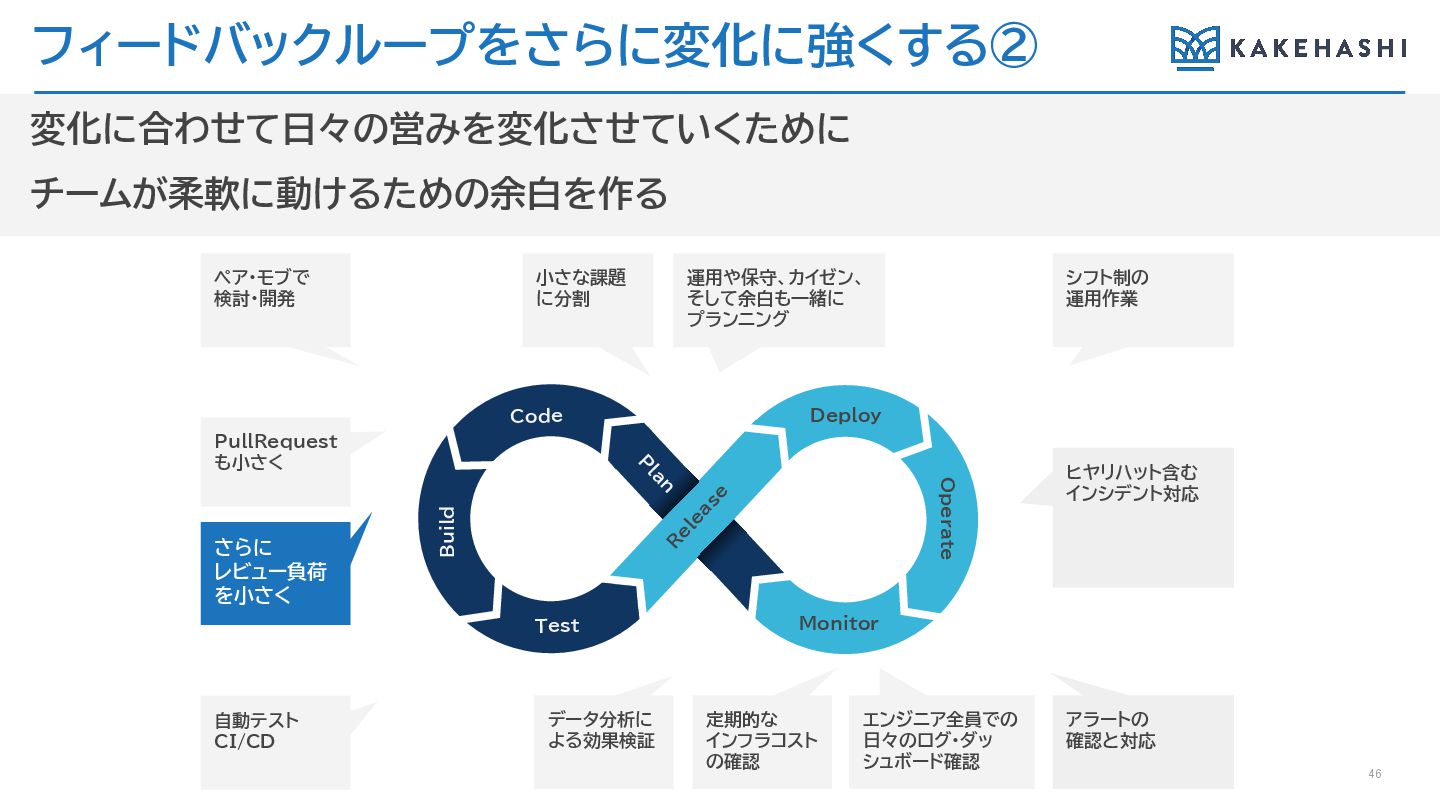
フィードバックループをさらに変化に強くする② 46 変化に合わせて日々の営みを変化させていくために チームが柔軟に動けるための余白を作る PullRequest も小さく 小さな課題 に分割 エンジニア全員での 日々のログ・ダッ
シュボード確認 運用や保守、カイゼン、 そして余白も一緒に プランニング ヒヤリハット含む インシデント対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析に よる効果検証 定期的な インフラコスト の確認 アラートの 確認と対応 さらに レビュー負荷 を小さく Deploy Monitor R elease Code Test Operate P lan Build
Tidy First? チームに信頼があり、盤石な文化があれば、整頓には レビューは不要だ 整頓はレビューしなくてもよいというレベルの安全と 信頼に到達するには、何ヶ月もかかる。練習しよう。 実験しよう。みんなでエラーをレビューしよう。 https://www.oreilly.co.jp/books/9784814400911/ “ ”
47
実際にこんなルールで取り組みを開始しました 1. PullRequestタイトルのプレフィックスを [Tidy] とつける 2. 変更内容が単一である (複数の変更をひとつのPullRequestに含めない) 3. 修正箇所のテストが存在し、テストが通っている
(コメントのみの修正等は除く) 4. アプリケーションの挙動は変わっていないこと 5. 可逆的である (不具合が発生した場合は、このPullRequestをRevertするだけでよい) 6. 不具合が発生するリスクが低い自信を持てている (PullRequest 作成者の自己申告でよい) レビュー負荷軽減のため、レビューなしマージの取り組みを開始した 48
気持ちにも余裕が出てきた
問題が起きそうなときに 日々の営み自体をアップデートする 習慣ができてきた
さらに先手を打てるようにするために 取り組み始めたこと
SLOを導入することで チーム全体が 何を達成すべきかを明確にする
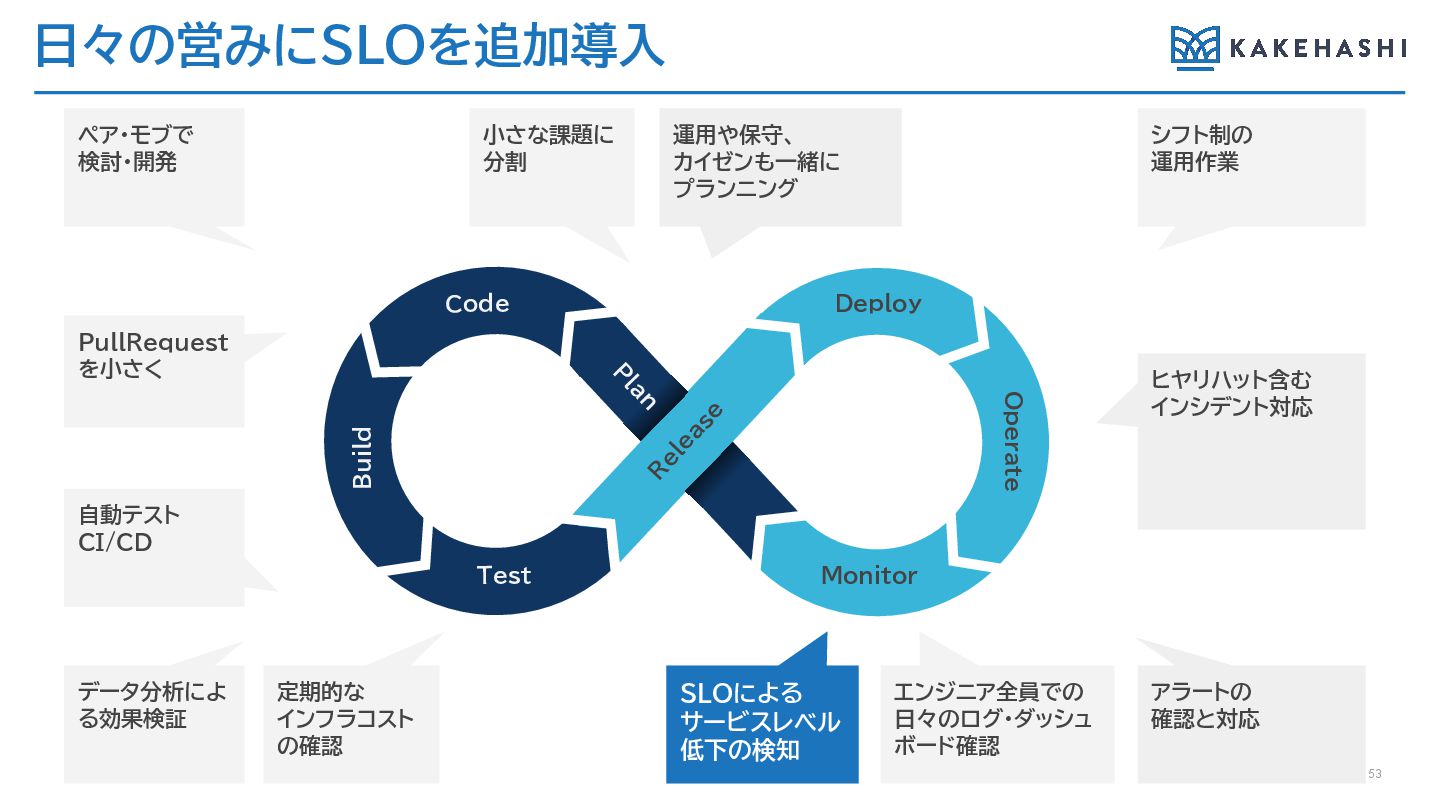
日々の営みにSLOを追加導入 53 PullRequest を小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 ペア・モブで
検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析によ る効果検証 定期的な インフラコスト の確認 SLOによる サービスレベル 低下の検知 運用や保守、 カイゼンも一緒に プランニング ヒヤリハット含む インシデント対応 アラートの 確認と対応 Deploy Monitor R elease Code Test Operate P lan Build
AI在庫管理においてのSLO設定のねらい • AI在庫管理のチームは、開発・運用・QAが分かれていないため、本来リリース時 のガードレールが設定されるようなところに明確なガードレールがない • そのため何らかのサービスレベル低下の検知後、エンジニアが対応の必要性を判 断しており、その中でもその特定のサービスに詳しいメンバーが直感的な判断を 行っている • SLOを設定することで、エンジニア以外を含めたチーム全体がシステムの安定運
用のために対応の優先順位を判断できるようにする 54
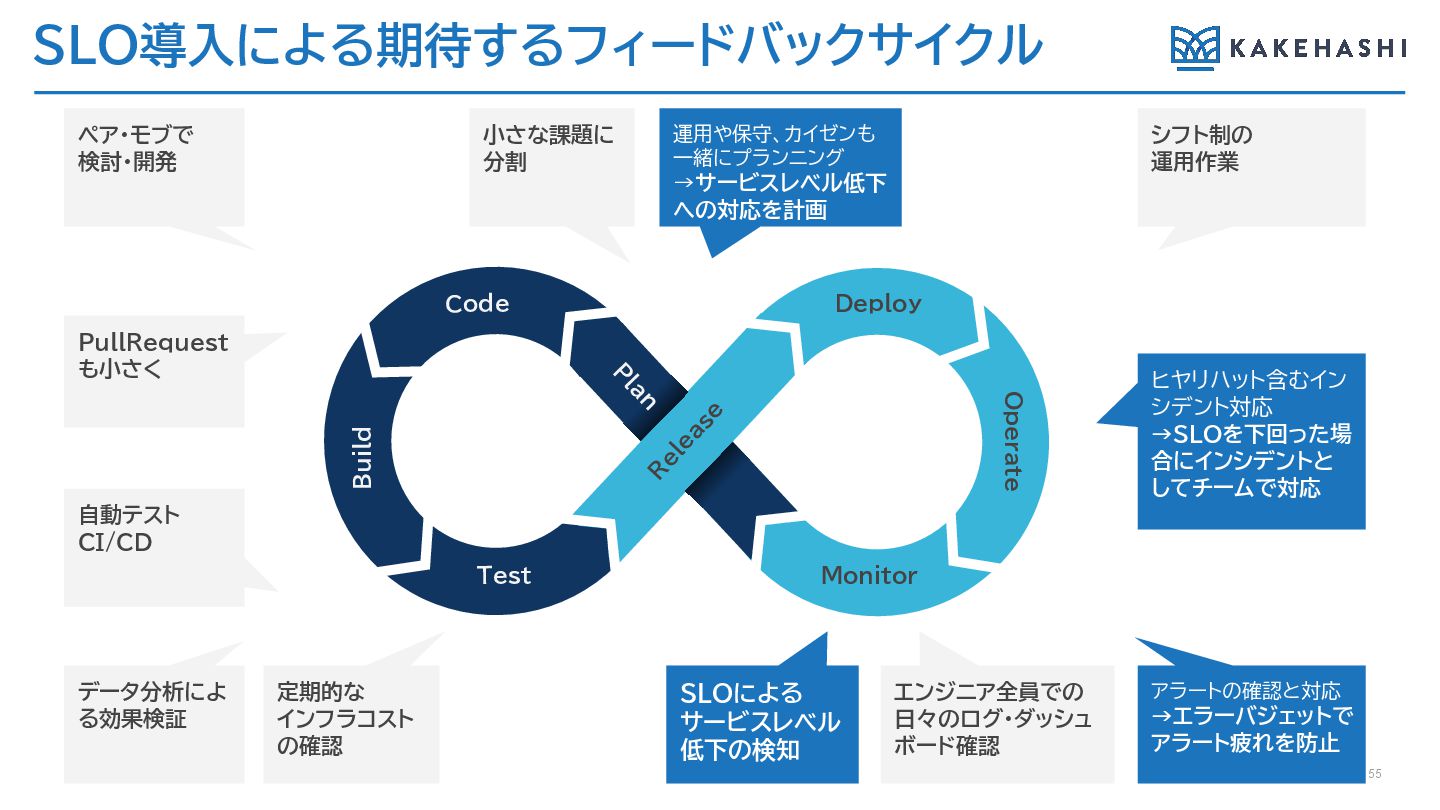
SLO導入による期待するフィードバックサイクル 55 PullRequest も小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 運用や保守、カイゼンも
一緒にプランニング →サービスレベル低下 への対応を計画 ヒヤリハット含むイン シデント対応 →SLOを下回った場 合にインシデントと してチームで対応 ペア・モブで 検討・開発 シフト制の 運用作業 自動テスト CI/CD データ分析によ る効果検証 定期的な インフラコスト の確認 SLOによる サービスレベル 低下の検知 アラートの確認と対応 →エラーバジェットで アラート疲れを防止 Deploy Monitor R elease Code Test Operate P lan Build
さらなる大手法人導入に向けて想定される課題 56 観点 想定される課題感 指標 可用性 特になし。 マネージドサービス中心に使用していること、24/365のシステムでは ない ー
レイテン シー データ量増加に伴って一部のAPIにパフォーマンス の劣化の可能性 • APIごとのレイテンシー • APIごとのタイムアウト数 スケール 性 将来のスケールアウトが必要なタイミングの予測が 困難。 また、顧客数増加に対しての妥当な負荷増加なの か、不当な実装での負荷増加なのかの把握が難しい • 店舗数増加との関係値 • 店舗単位の負荷、リソース使 用量 データの 納期 データ量増加に伴って、バッチ処理が店舗の業務開 始に間に合わなくなる • 完了時間 データ品 質 使用傾向の異なる顧客が増え、AIの出力結果の品 質(精度)が下がる • 出力結果の制約に異常検知率 • 入力値や結果の分布変化値
さらなる大手法人導入に向けて想定される課題 57 観点 想定される課題感 指標 可用性 特になし。 マネージドサービス中心に使用していること、24/365のシステムでは ない ー
レイテン シー データ量増加に伴って一部のAPIにパフォーマンス の劣化の可能性 • APIごとのレイテンシー • APIごとのタイムアウト数 スケール 性 将来のスケールアウトが必要なタイミングの予測が 困難。 また、顧客数増加に対しての妥当な負荷増加なの か、不当な実装での負荷増加なのかの把握が難しい • 店舗数増加との関係値 • 店舗単位の負荷、リソース使 用量 データの 納期 データ量増加に伴って、バッチ処理が店舗の業務開 始に間に合わなくなる • 完了時間 データ品 質 使用傾向の異なる顧客が増え、AIの出力結果の品 質(精度)が下がる • 出力結果の制約に異常検知率 • 入力値や結果の分布変化値 SLOとして設定 オブザーバビリティ強化
SLO導入初期の考え方 • レイテンシーはユーザー体験の悪化に大きく影響を与える分かりやすい指標 • エンジニア以外を巻き込んだ運用になるため、まずはシンプルな少ない指標と目 標でSLMの実践をスタートさせたい ◦ 運用が軌道に乗ってから他の指標の追加を検討する • 他の課題に関してはサービスレベルというよりはシステム内部の把握のための指
標であるため、まずはオブザーバビリティの強化として扱う 58 APIごとに、30日間のローリングウィンドウで、 • 99%tile(APIによっては95%tile) 値のレイテンシーが今のベースライン+α以下 • タイムアウト数が今のベースライン+α以下
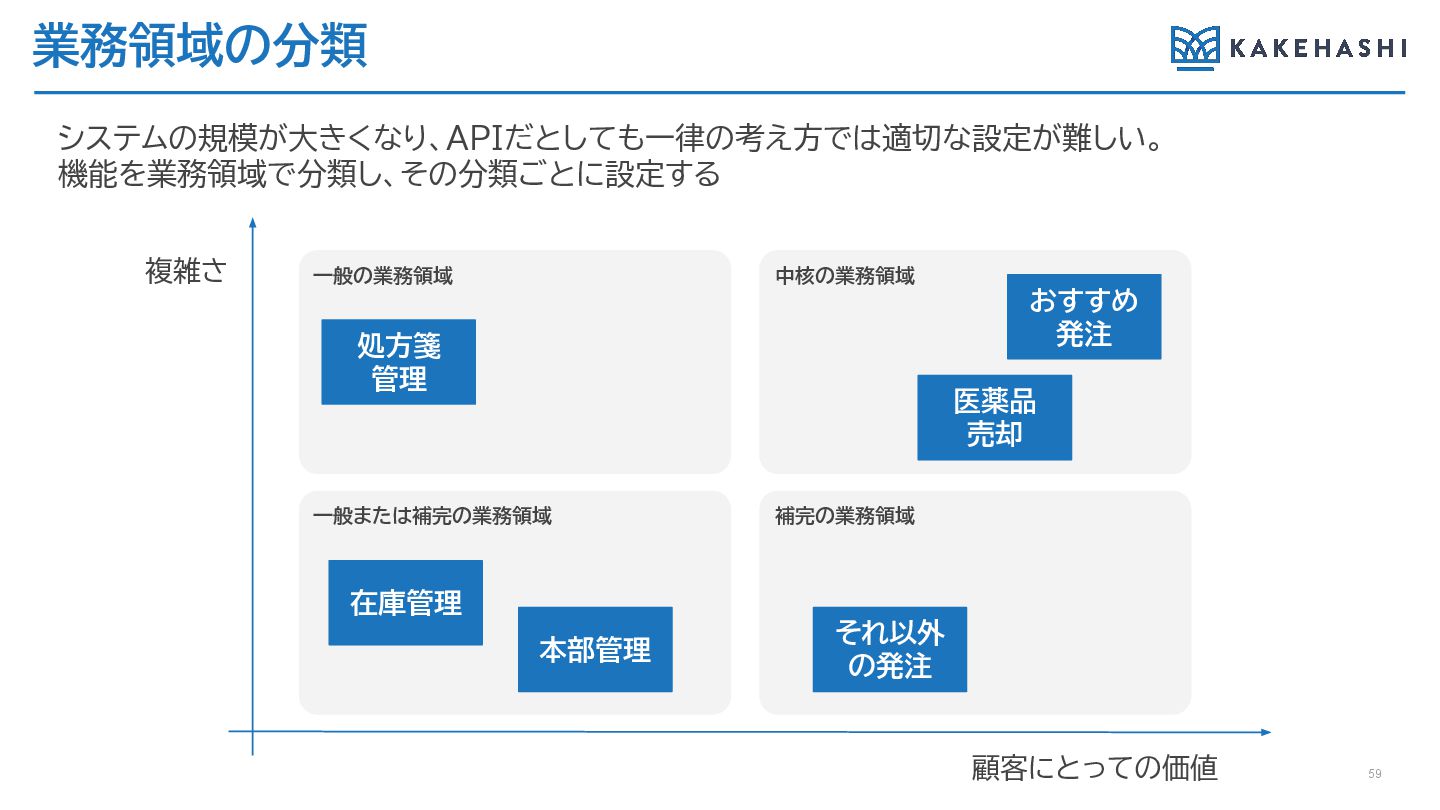
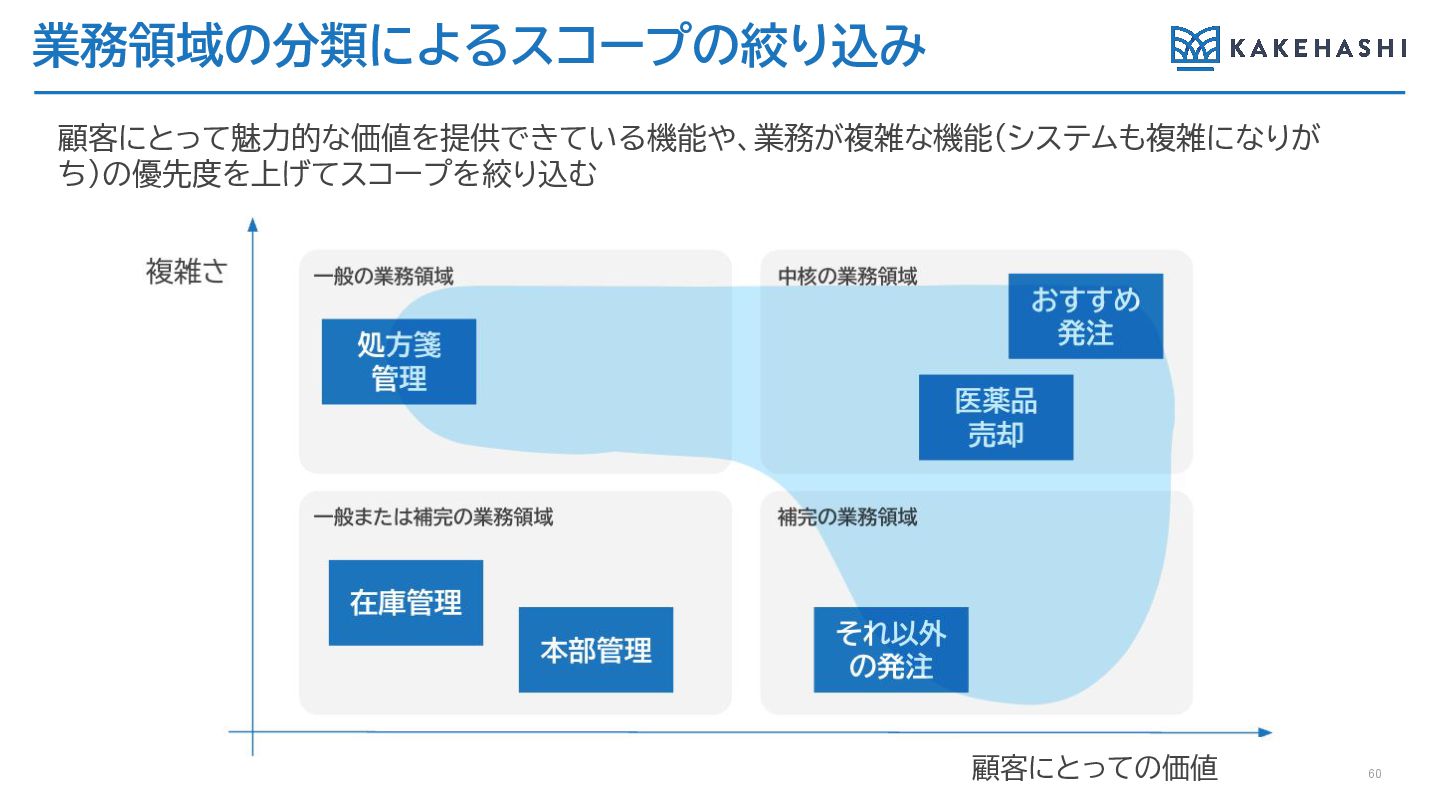
業務領域の分類 おすすめ 発注 医薬品 売却 在庫管理 それ以外 の発注 複雑さ 顧客にとっての価値
処方箋 管理 本部管理 中核の業務領域 補完の業務領域 一般の業務領域 一般または補完の業務領域 システムの規模が大きくなり、APIだとしても一律の考え方では適切な設定が難しい。 機能を業務領域で分類し、その分類ごとに設定する 59
業務領域の分類によるスコープの絞り込み 顧客にとって魅力的な価値を提供できている機能や、業務が複雑な機能(システムも複雑になりが ち)の優先度を上げてスコープを絞り込む 60 顧客にとっての価値
ここまでは これまでより悪化してないかという システムを守るための目標値
それだけで良い?
チーム全員が主体的に システムを良くしていけるように
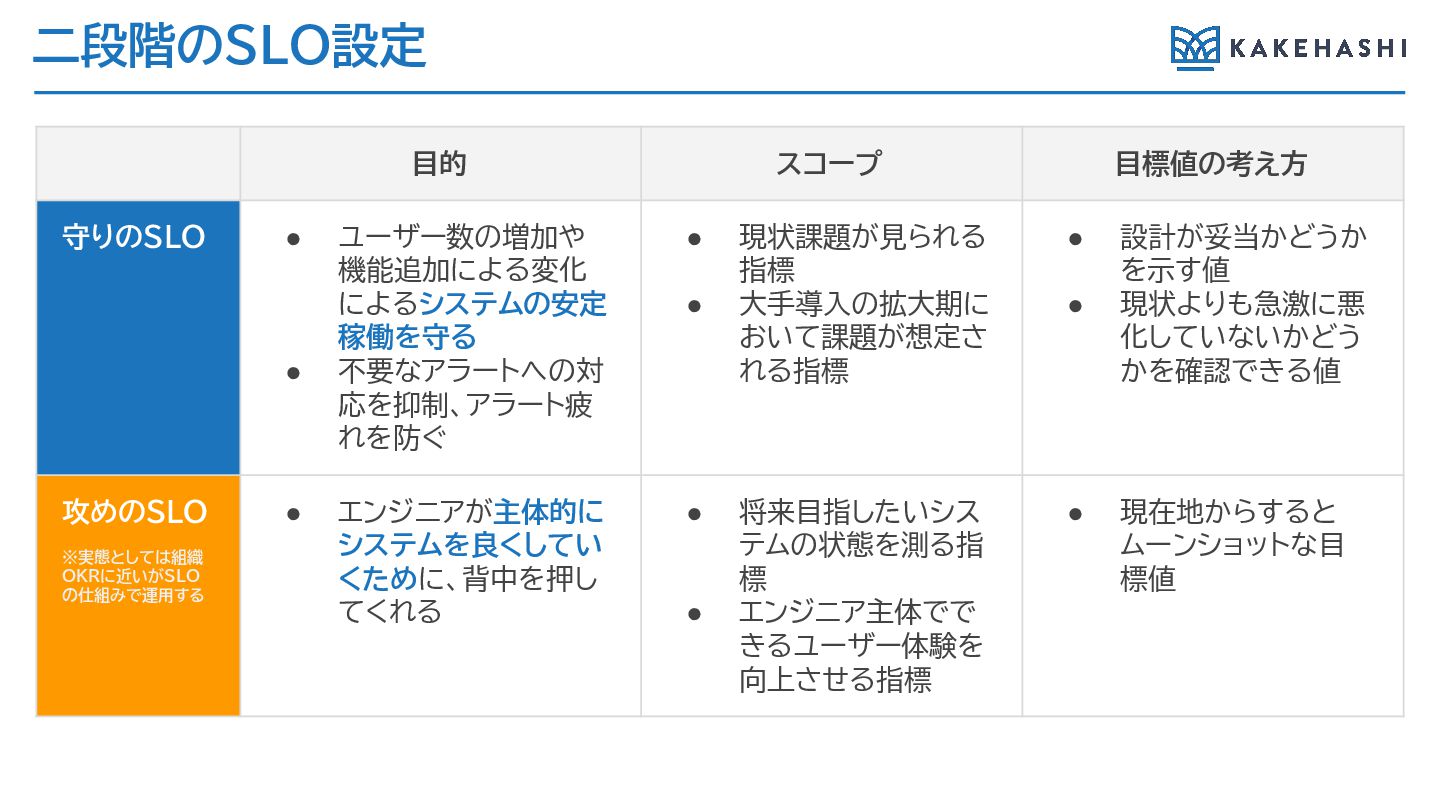
二段階のSLO設定 目的 スコープ 目標値の考え方 守りのSLO • ユーザー数の増加や 機能追加による変化 によるシステムの安定 稼働を守る
• 不要なアラートへの対 応を抑制、アラート疲 れを防ぐ • 現状課題が見られる 指標 • 大手導入の拡大期に おいて課題が想定さ れる指標 • 設計が妥当かどうか を示す値 • 現状よりも急激に悪 化していないかどう かを確認できる値 攻めのSLO ※実態としては組織 OKRに近いがSLO の仕組みで運用する • エンジニアが主体的に システムを良くしてい くために、背中を押し てくれる • 将来目指したいシス テムの状態を測る指 標 • エンジニア主体でで きるユーザー体験を 向上させる指標 • 現在地からすると ムーンショットな目 標値
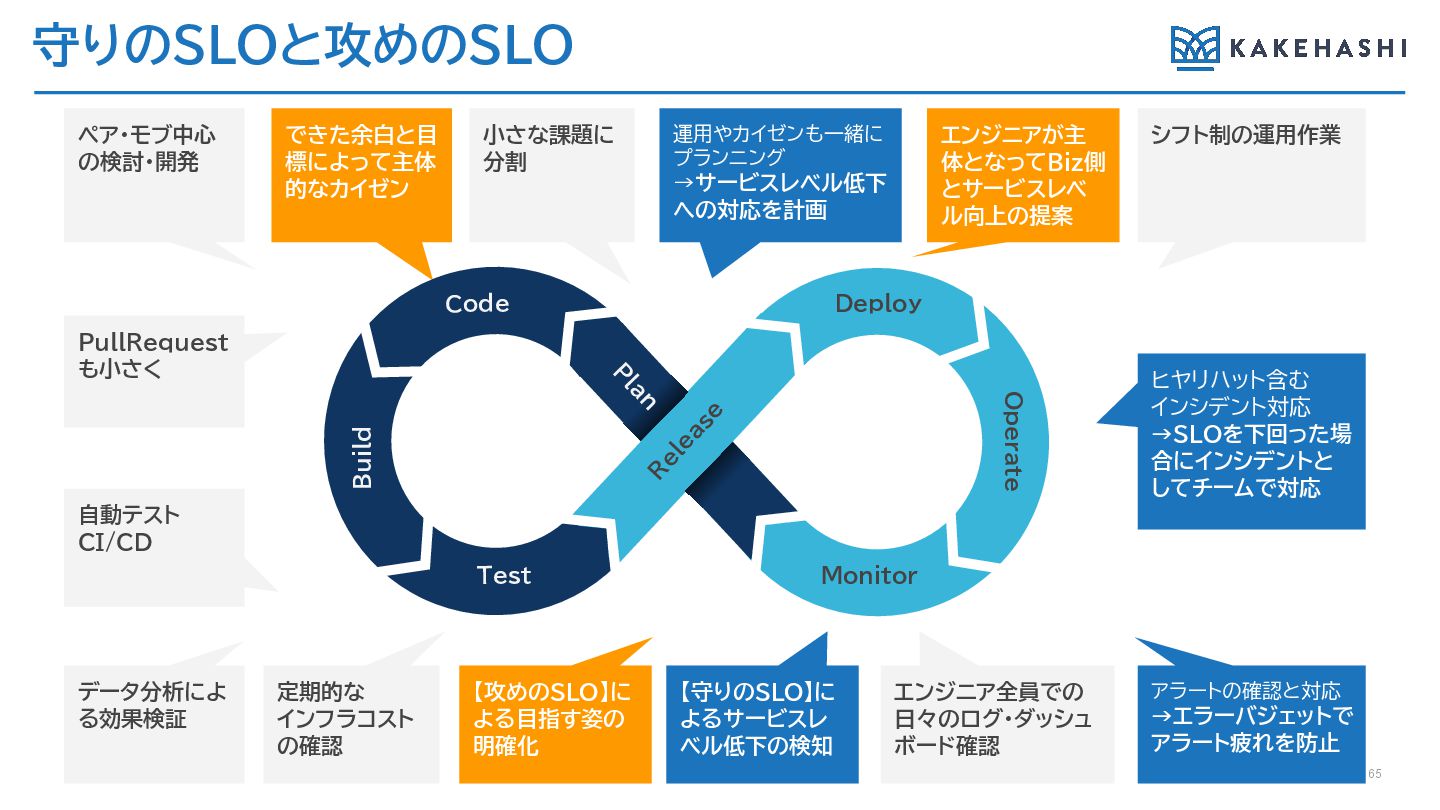
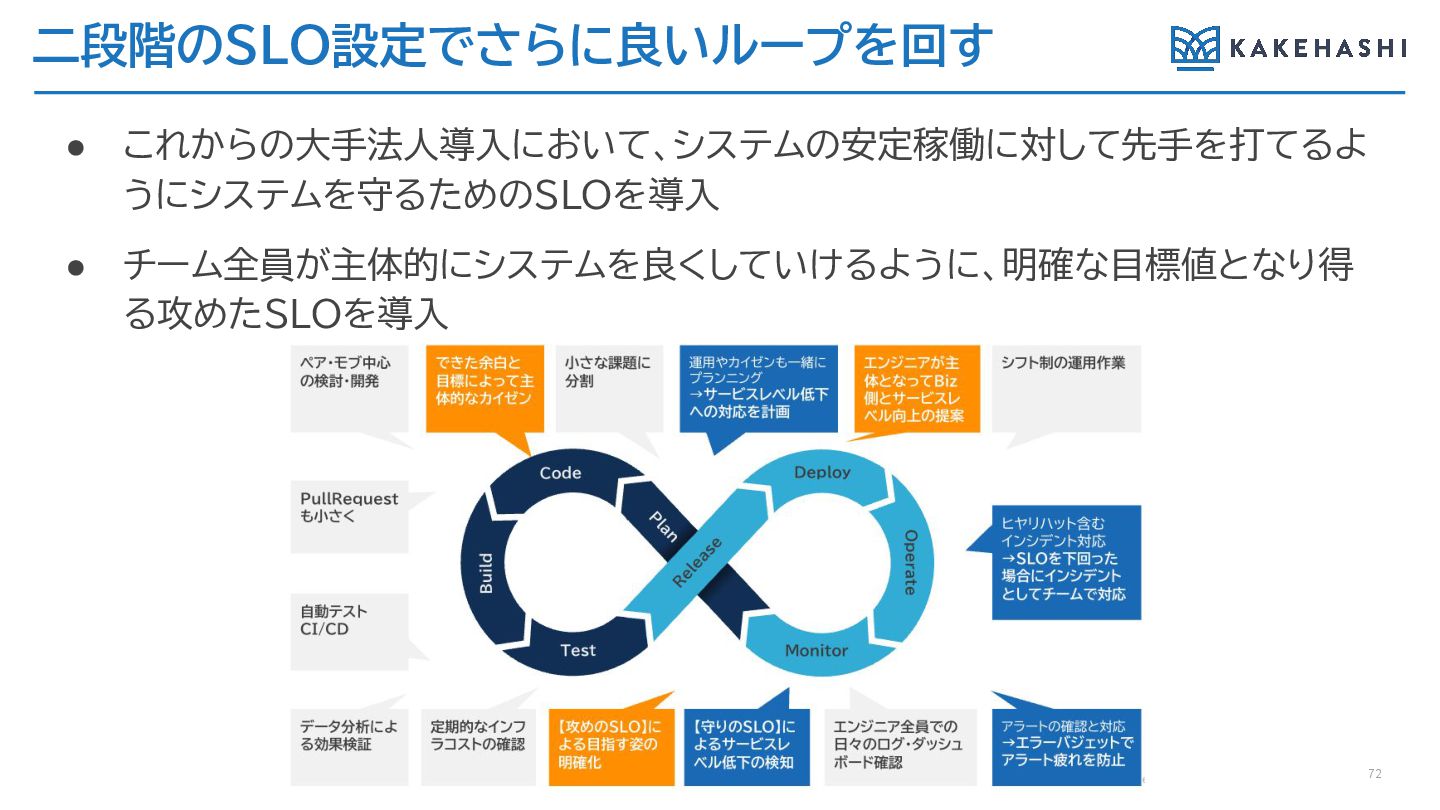
守りのSLOと攻めのSLO 65 PullRequest も小さく 小さな課題に 分割 エンジニア全員での 日々のログ・ダッシュ ボード確認 運用やカイゼンも一緒に
プランニング →サービスレベル低下 への対応を計画 ヒヤリハット含む インシデント対応 →SLOを下回った場 合にインシデントと してチームで対応 ペア・モブ中心 の検討・開発 シフト制の運用作業 自動テスト CI/CD データ分析によ る効果検証 定期的な インフラコスト の確認 【守りのSLO】に よるサービスレ ベル低下の検知 【攻めのSLO】に よる目指す姿の 明確化 できた余白と目 標によって主体 的なカイゼン エンジニアが主 体となってBiz側 とサービスレベ ル向上の提案 アラートの確認と対応 →エラーバジェットで アラート疲れを防止 Deploy Monitor R elease Code Test Operate P lan Build
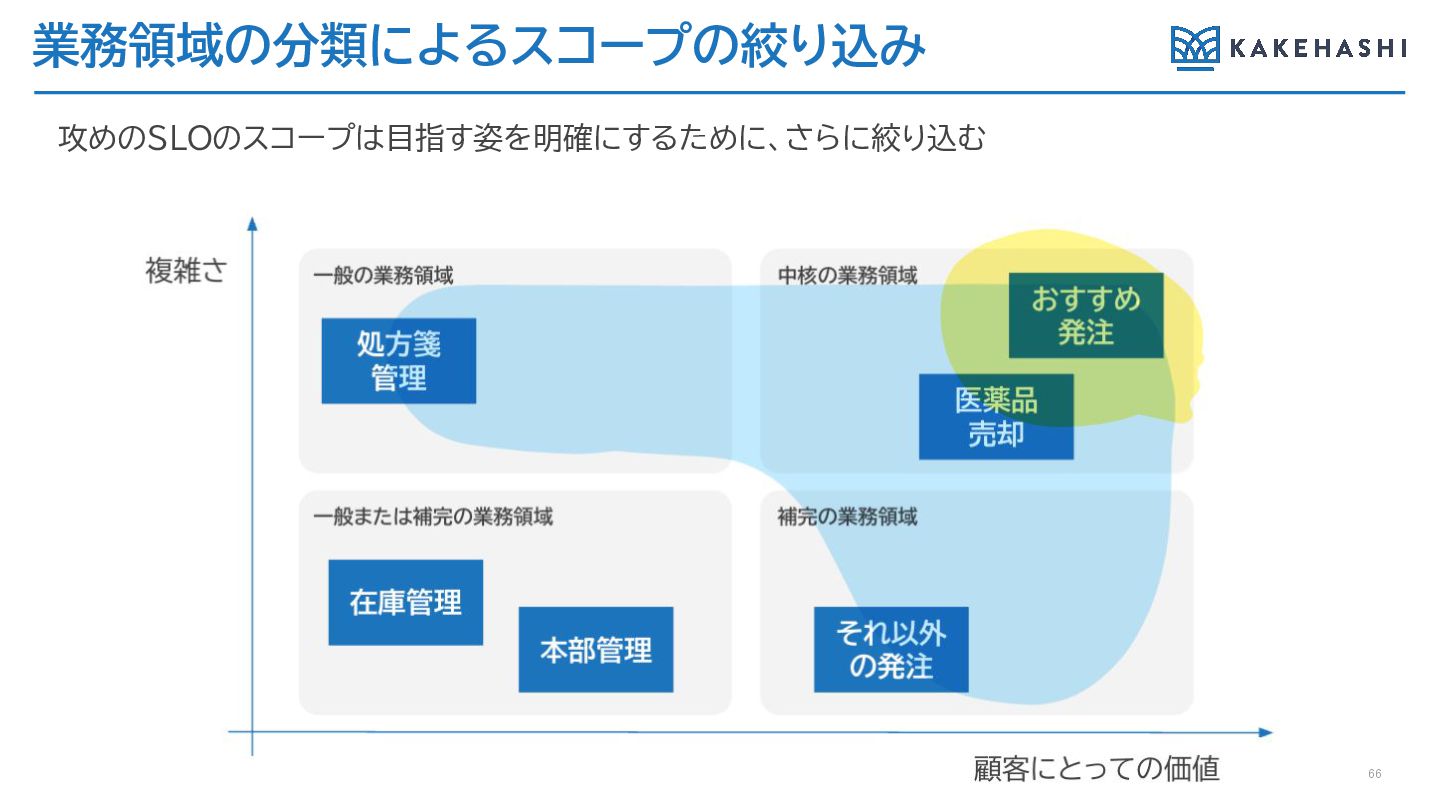
業務領域の分類によるスコープの絞り込み 攻めのSLOのスコープは目指す姿を明確にするために、さらに絞り込む 66
攻めのSLO設定の具体例(数値は仮決め状態) 67 • 中核の業務領域のAPIの99%tile値のレイテンシーを500ms以下 • 中核の業務領域のAPIのタイムアウト数をゼロ • AI在庫管理の魅力的な機能をさらに魅力的にするための指標設定 • 中核の業務領域の機能の一つである、AIによるおすすめ発注は、すべてのロール
のメンバーが関わる機能であるため、誰一人無関係ではいられない機能
まだ始めたばかりですが、 SLOの導入によって さらにより良いフィードバックループを 回せるように取り組んでいきます
おわりに
迅速なフィードバックループによる学習サイクル 70 • 機能開発では、小さくリリースし、効果検証を繰り返す • 運用の側面では、システムとの対話により、本番環境からのシグナルを測定し、シ ステムの安定稼働のための改善を繰り返す
フィードバックループの安定化 • プロダクトの大きな変化に対しフィードバックループが維持できない危機もあり える。フィードバックループの維持のために時にはしゃがむことも必要だった • 開発に余白を取り入れ、さらに安定したフィードバックループの継続を目指す 71
二段階のSLO設定でさらに良いループを回す 72 • これからの大手法人導入において、システムの安定稼働に対して先手を打てるよ うにシステムを守るためのSLOを導入 • チーム全員が主体的にシステムを良くしていけるように、明確な目標値となり得 る攻めたSLOを導入
仕事に追われている状況だからこそ 先手を取れるように 一歩踏み出してみませんか
ありがとうございました!!!!!! 74 カケハシの技術に関連する情報を 発信しています! 𝕏 @kakehashi_dev 是非フォローもお願いします!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実際にこんなルールで取り組みを開始しました 1. PullRequestタイトルのプレフィックスを [Tidy] とつける 2. 変更内容が単一である (複数の変更をひとつのPullRequestに含めない) 3. 修正箇所のテストが存在し、テストが通っている](https://files.speakerdeck.com/presentations/63b6606cd8fd4a4c8ae36b4c3cb04158/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}