Slow queries can be a common challenge when working with PostgreSQL, and understanding how to identify and resolve performance bottlenecks is key to maintaining a high-performing database.
In this talk, we'll dive into practical examples that demonstrate how to diagnose performance bottlenecks using tools like EXPLAIN and optimize queries effectively. Using relatable and actionable scenarios, we'll walk through common causes of slow queries, how to analyze execution plans, and practical steps for improvement, such as optimizing indexes and rewriting queries. We'll also explore the impact of statistics and planner decisions—key factors in understanding why PostgreSQL chooses a particular execution plan.
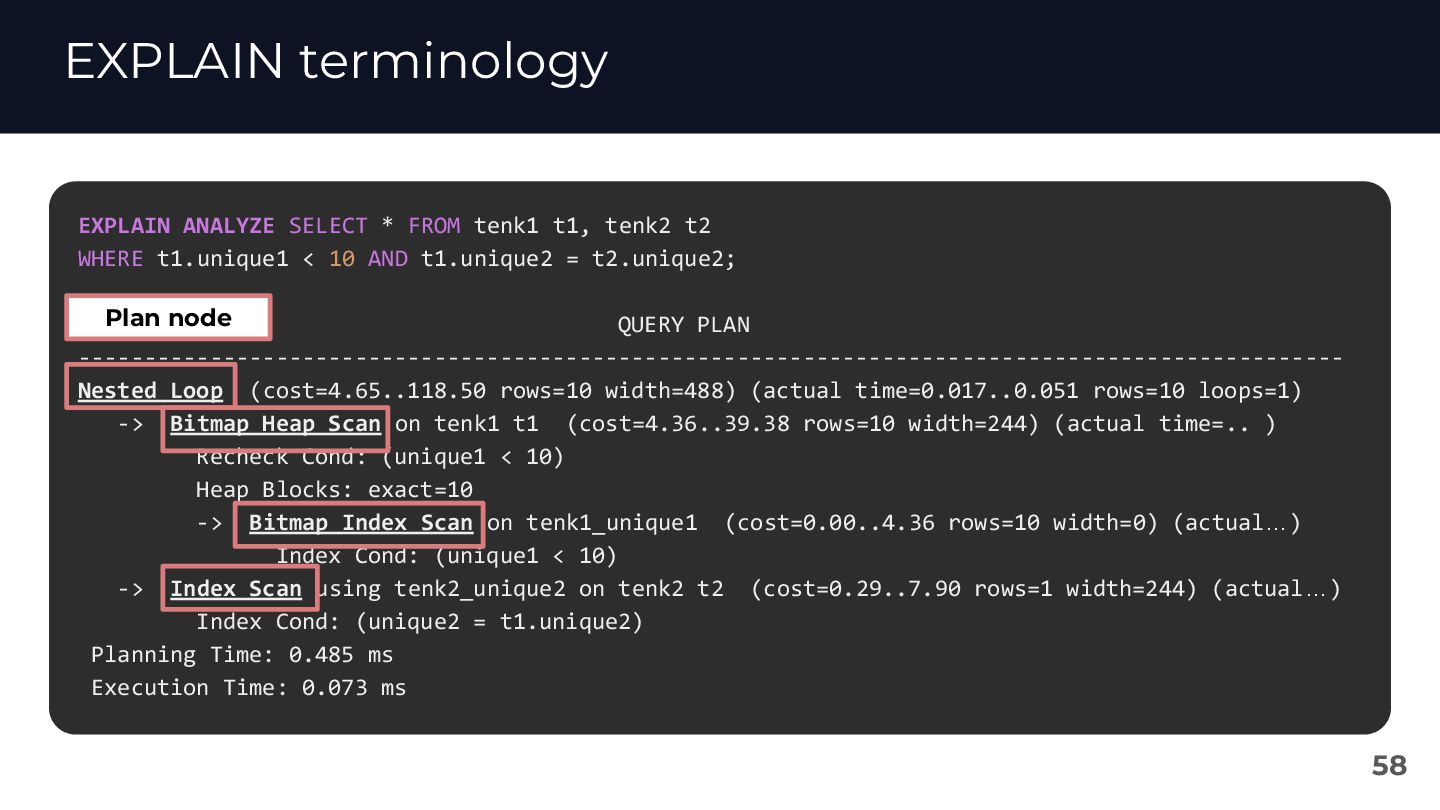
This session is designed for those who are familiar with the basics of reading EXPLAIN plans and want to expand their skills by applying them to practical scenarios.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
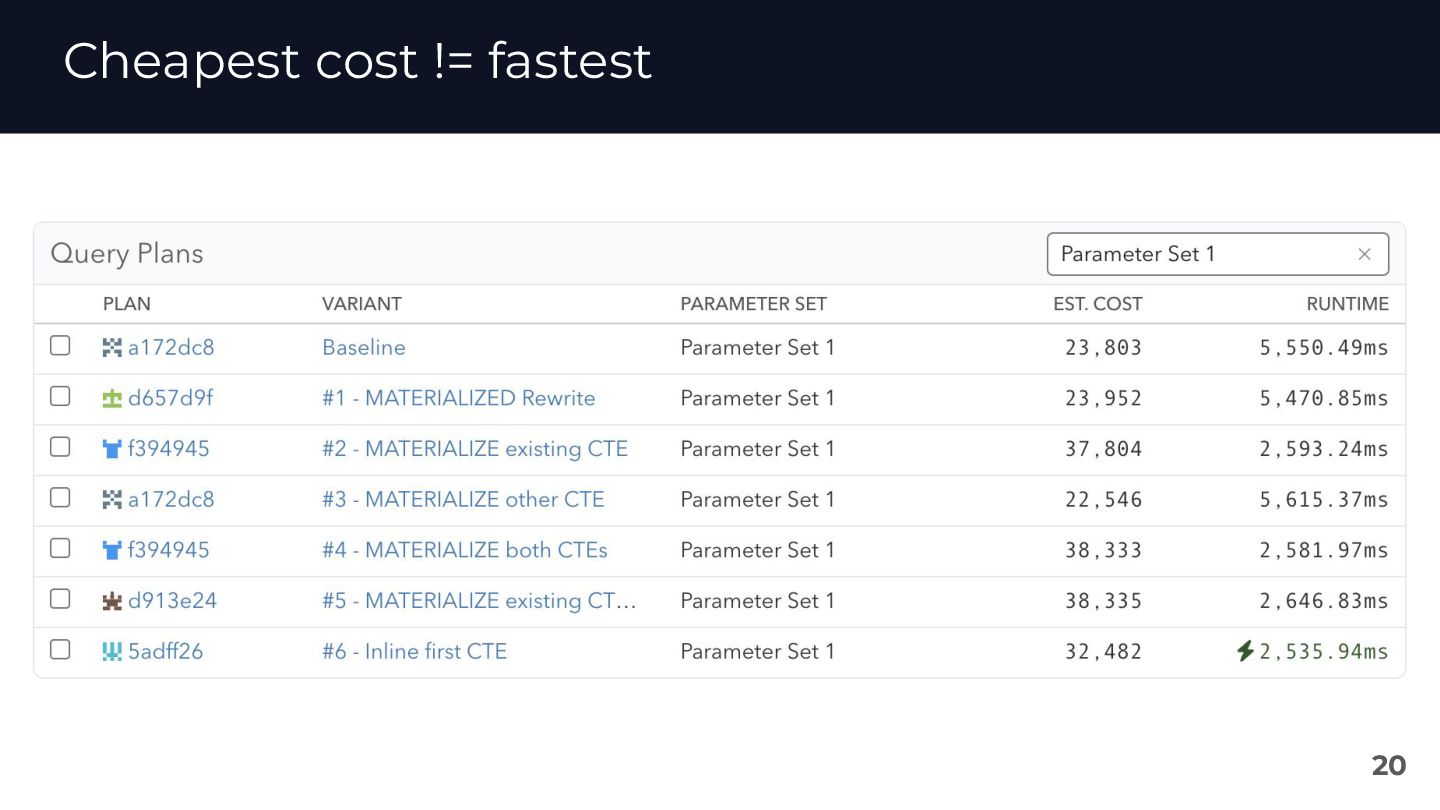{kind=link}
{kind=link}
{kind=link}
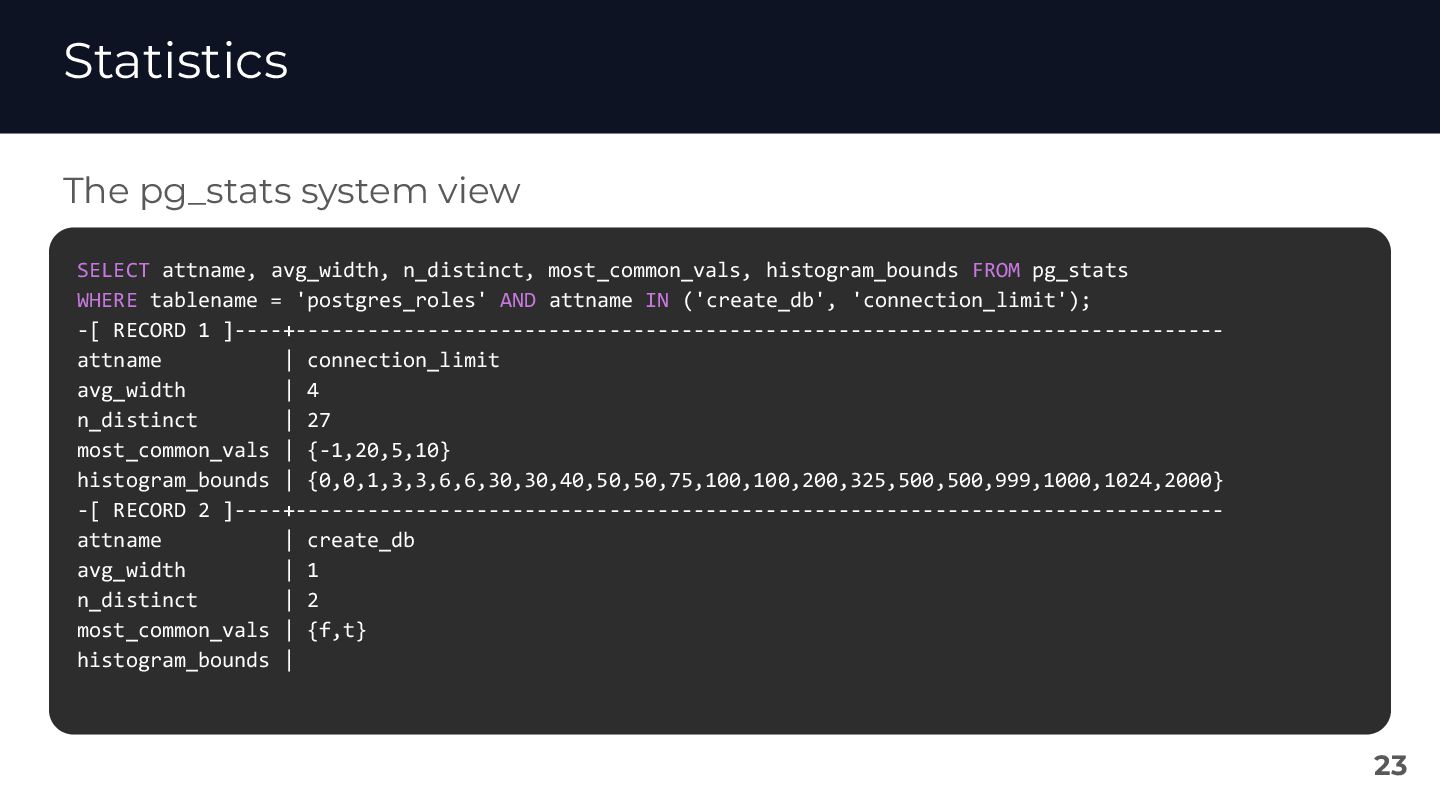{kind=link}
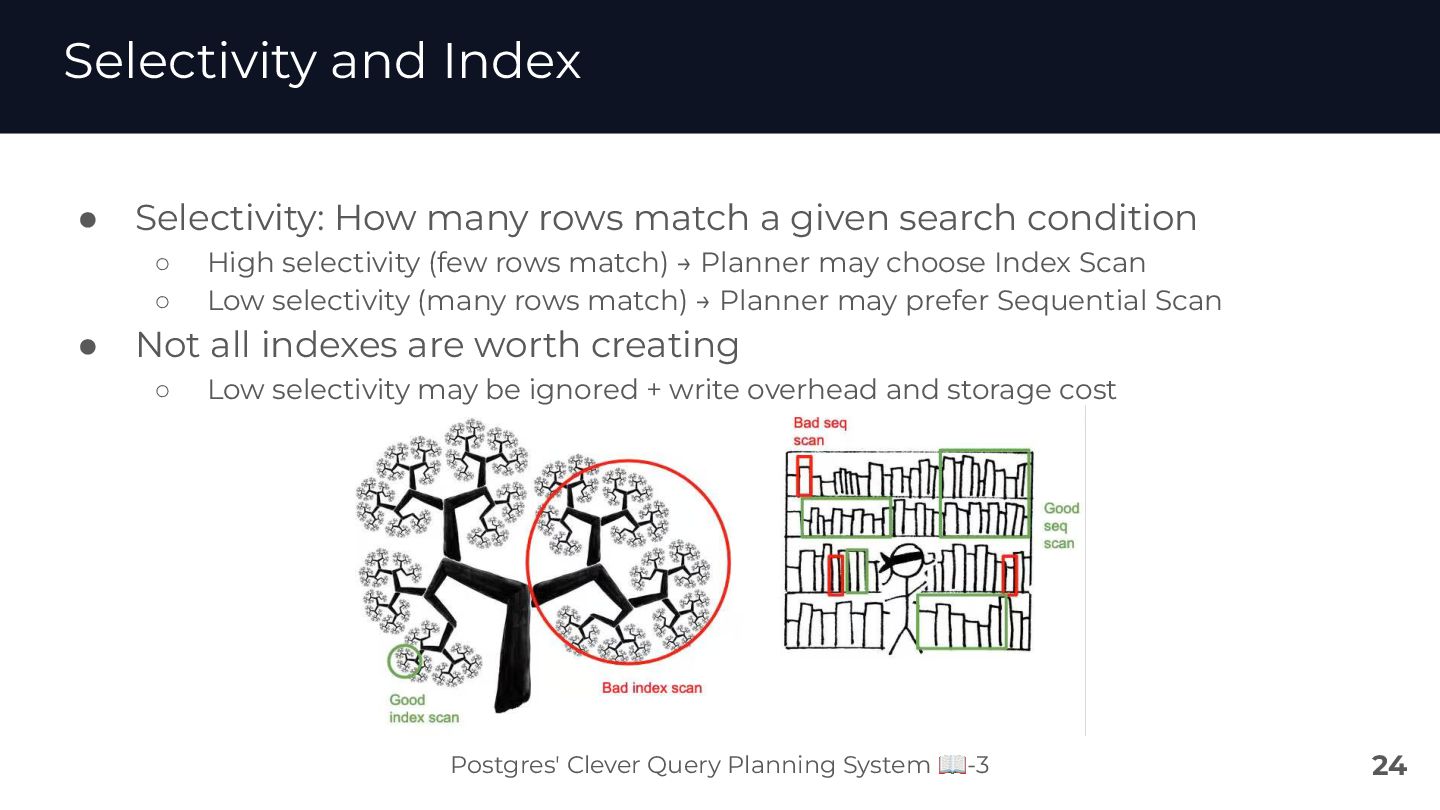{kind=link}
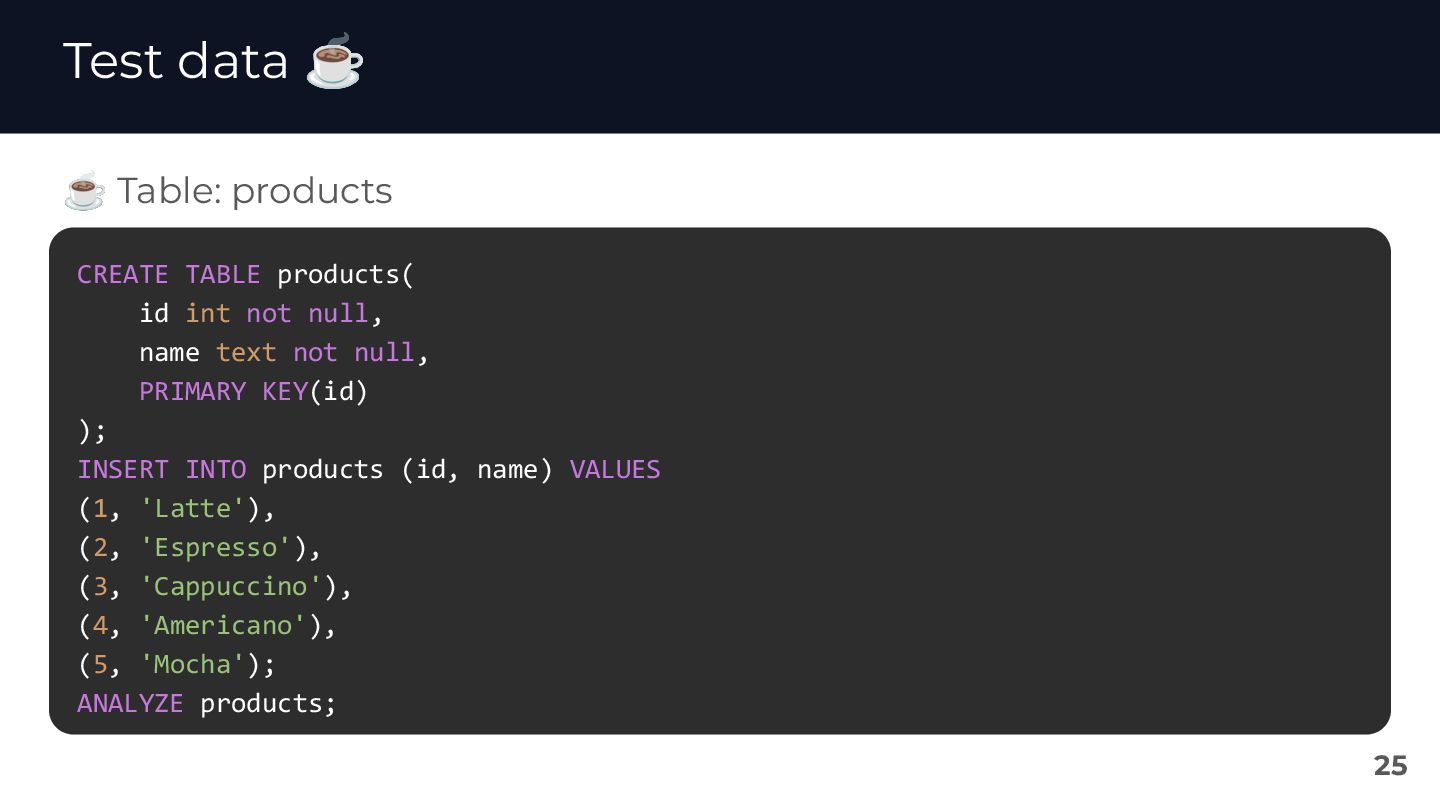{kind=link}
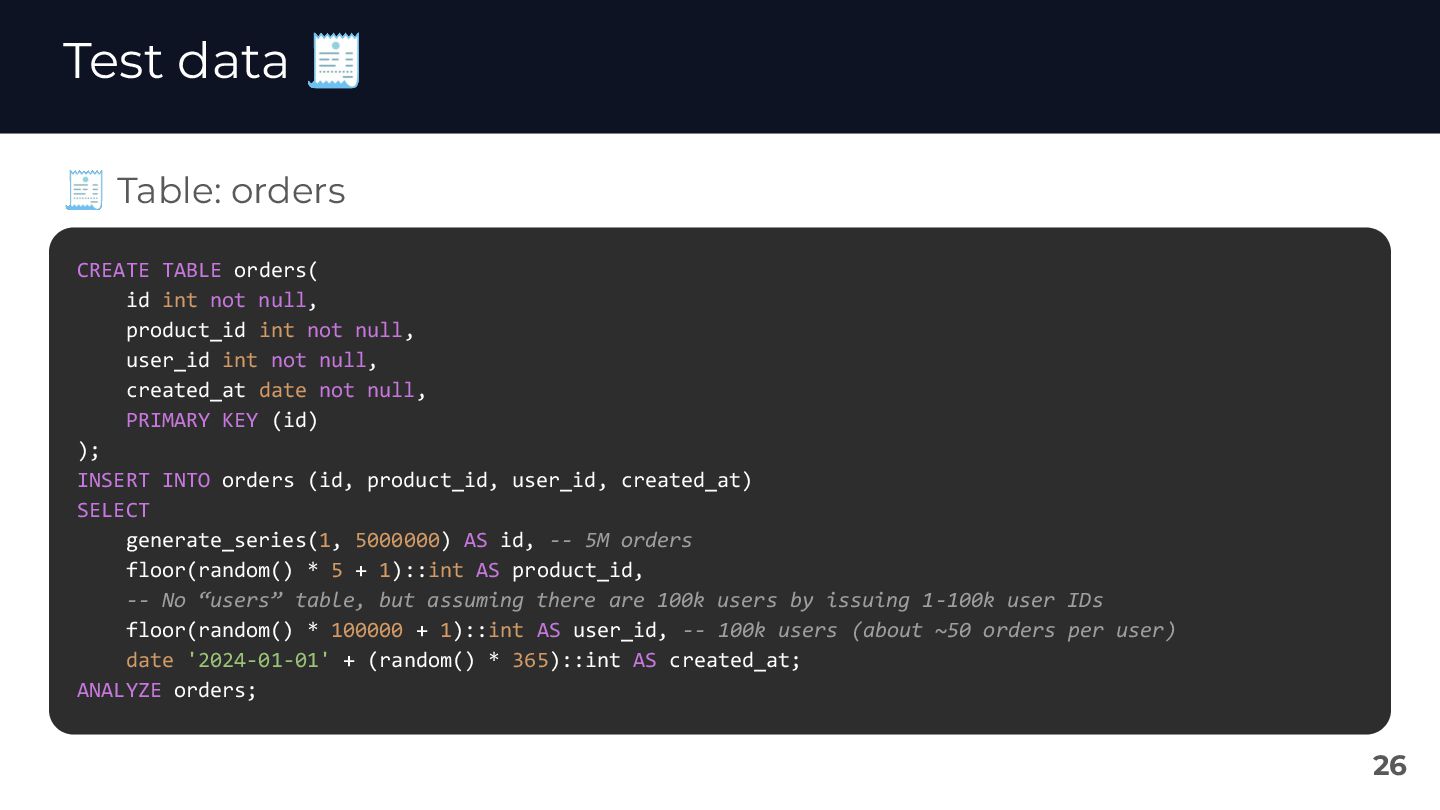{kind=link}
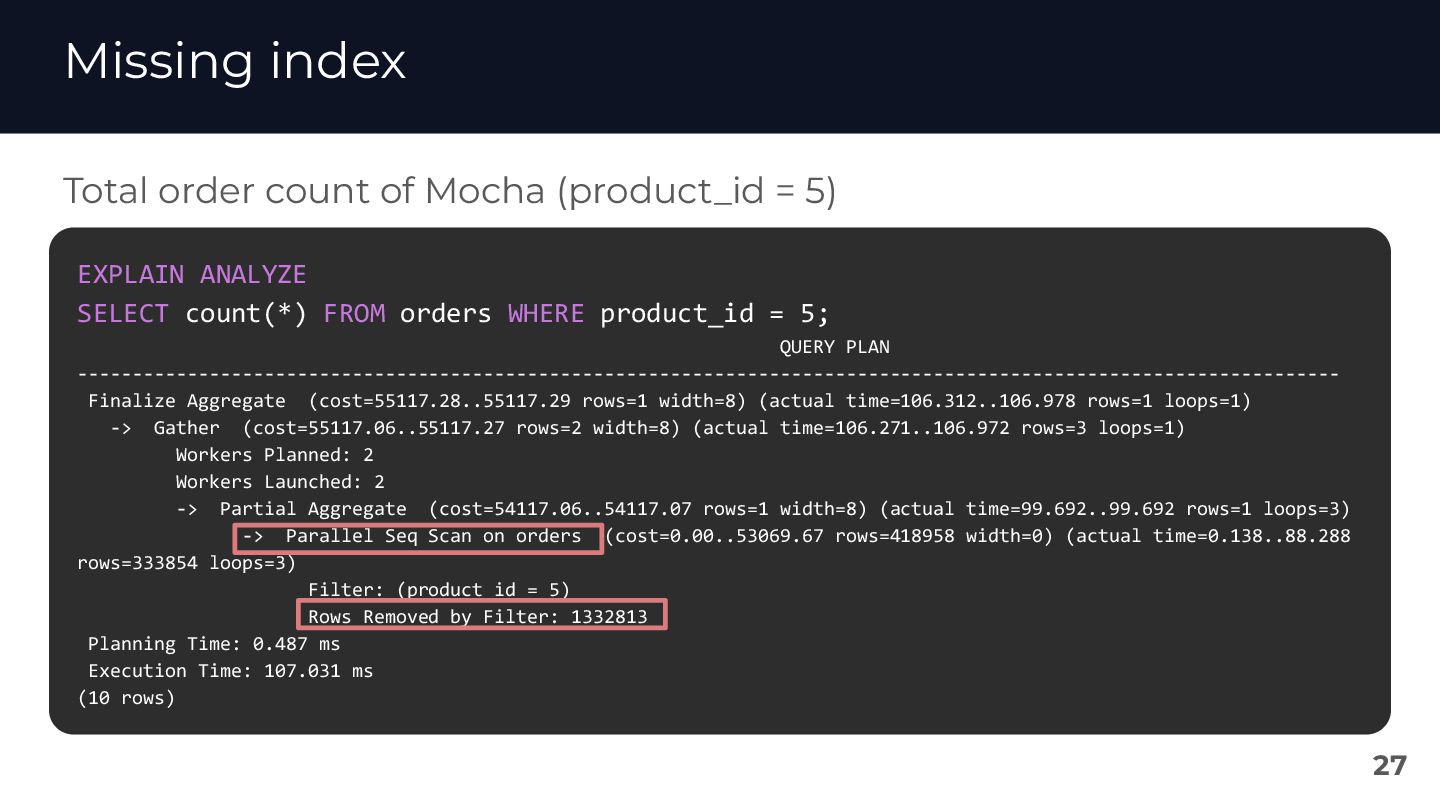{kind=link}
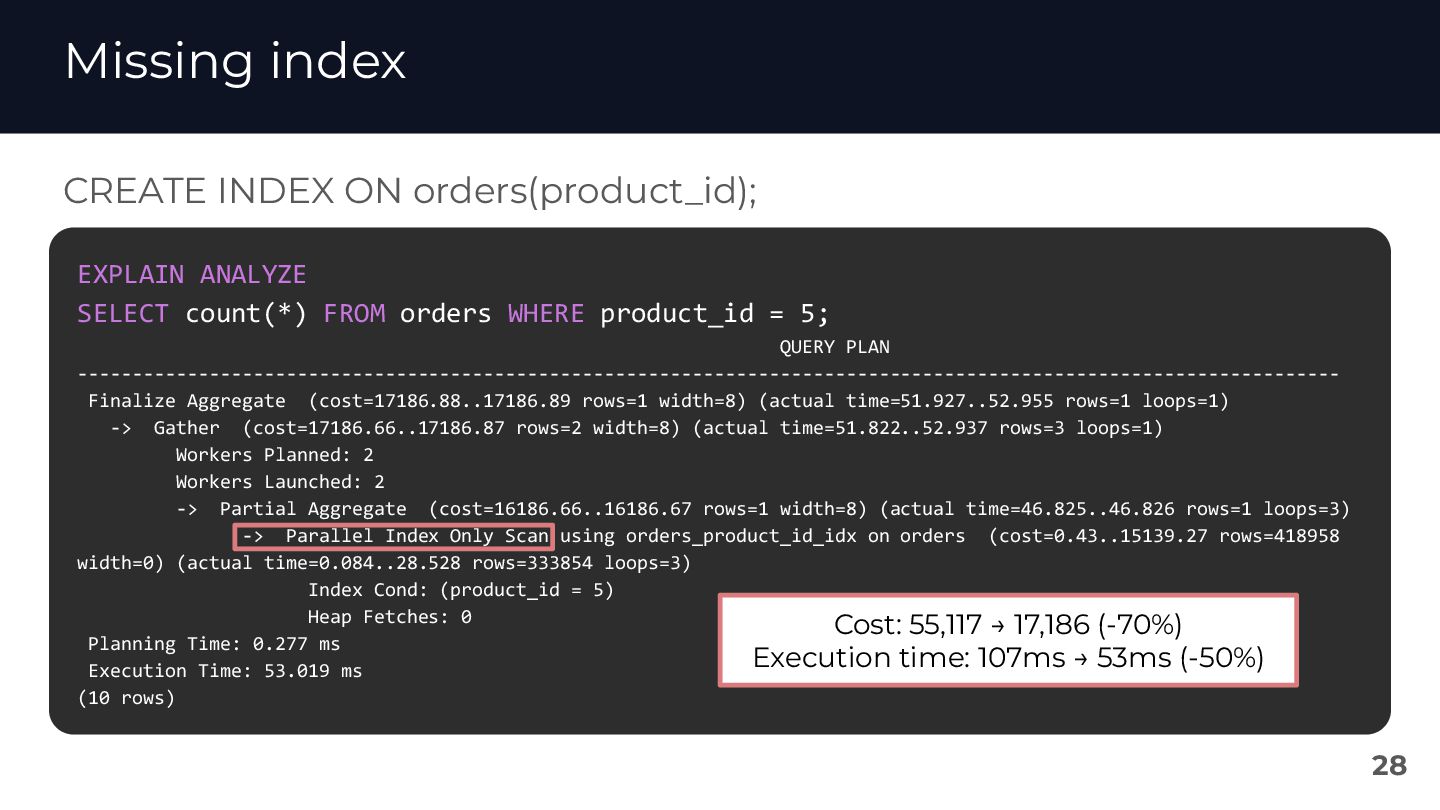{kind=link}
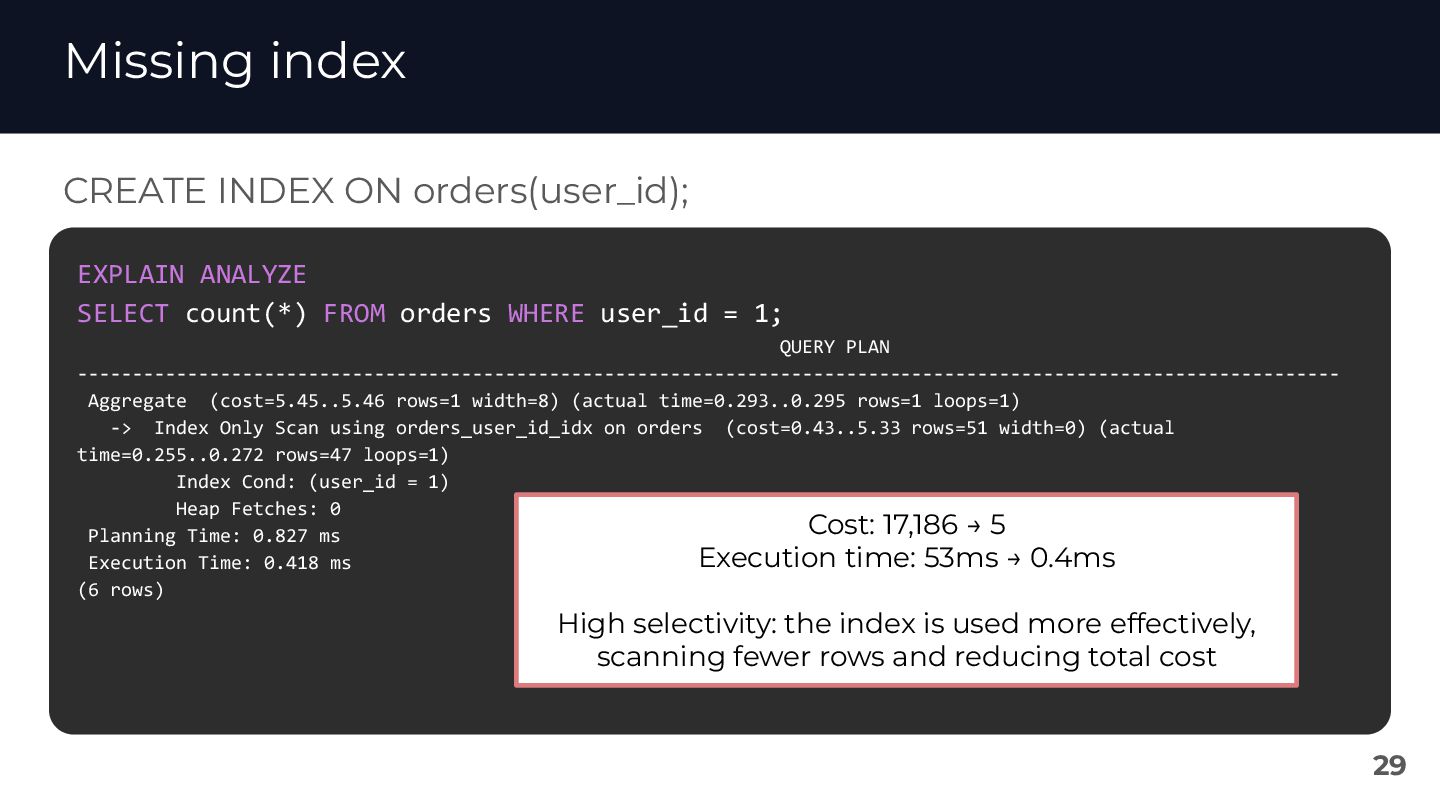{kind=link}
{kind=link}
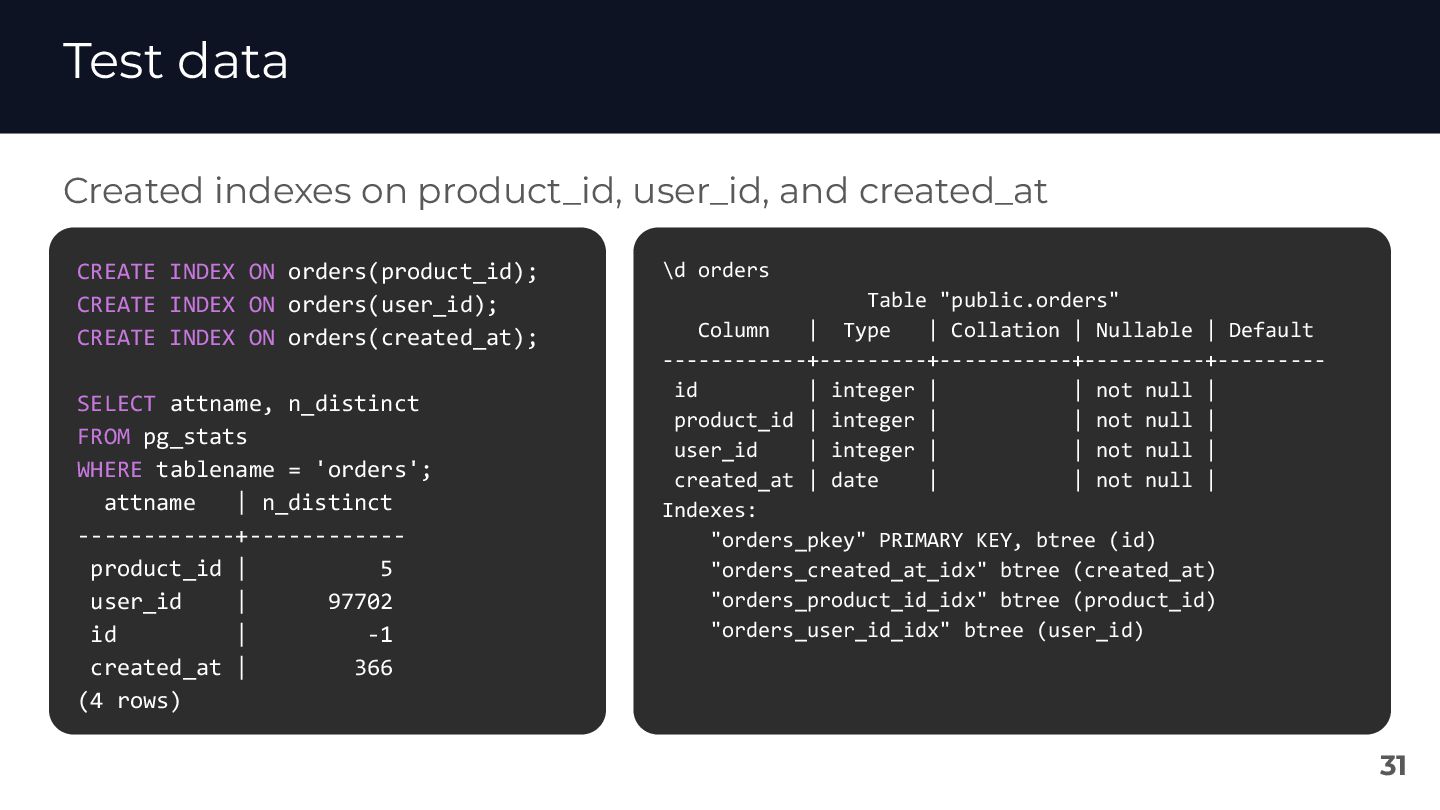{kind=link}
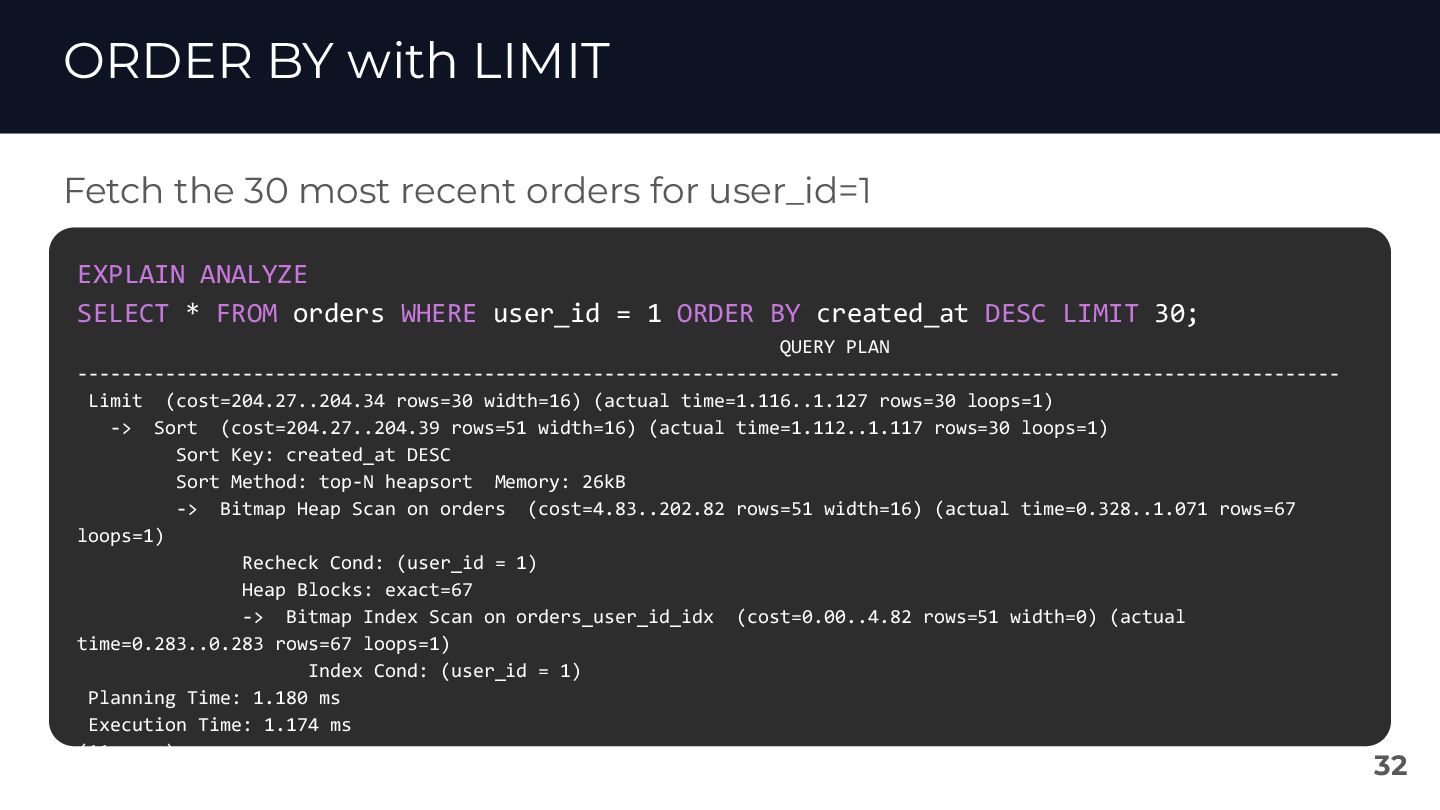{kind=link}
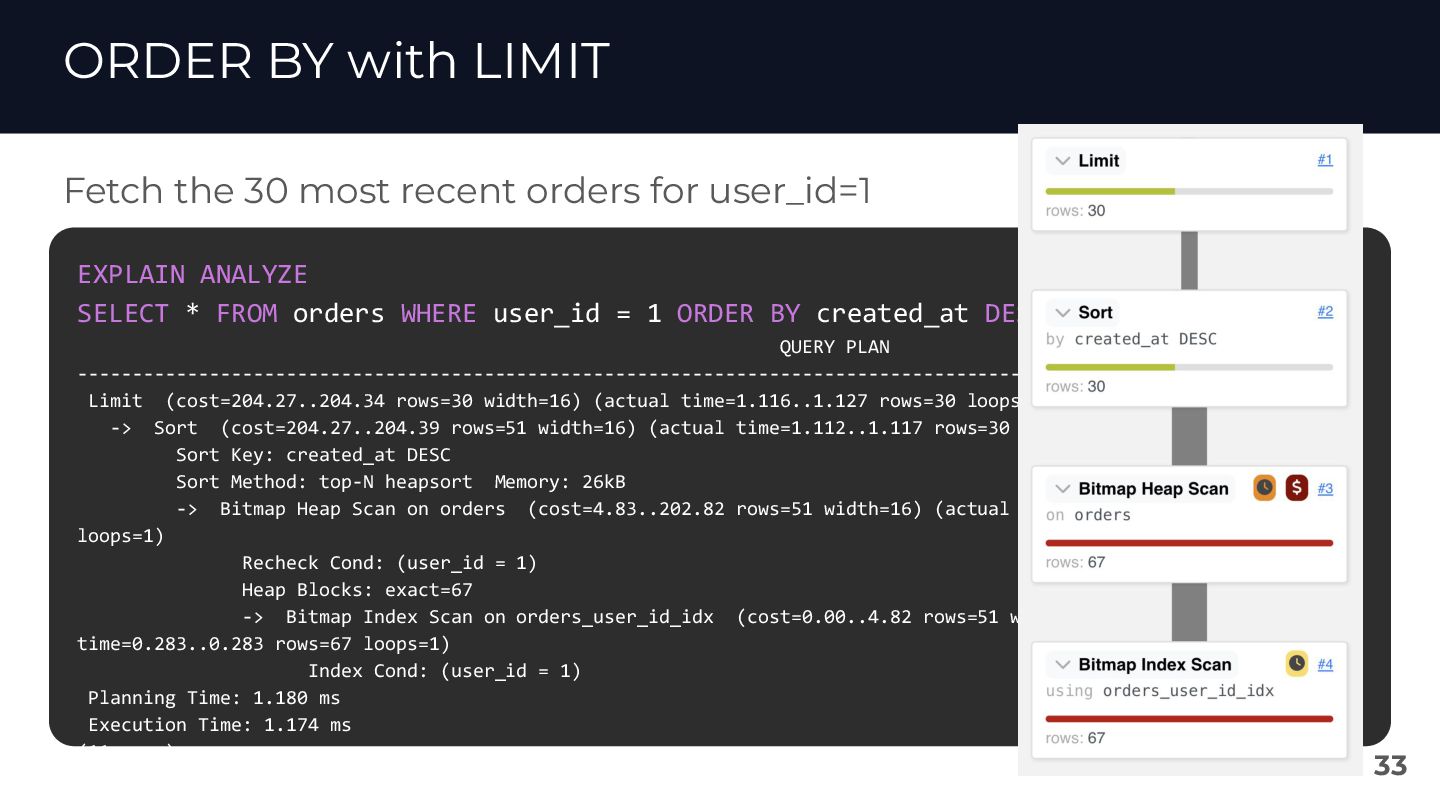{kind=link}
{kind=link}
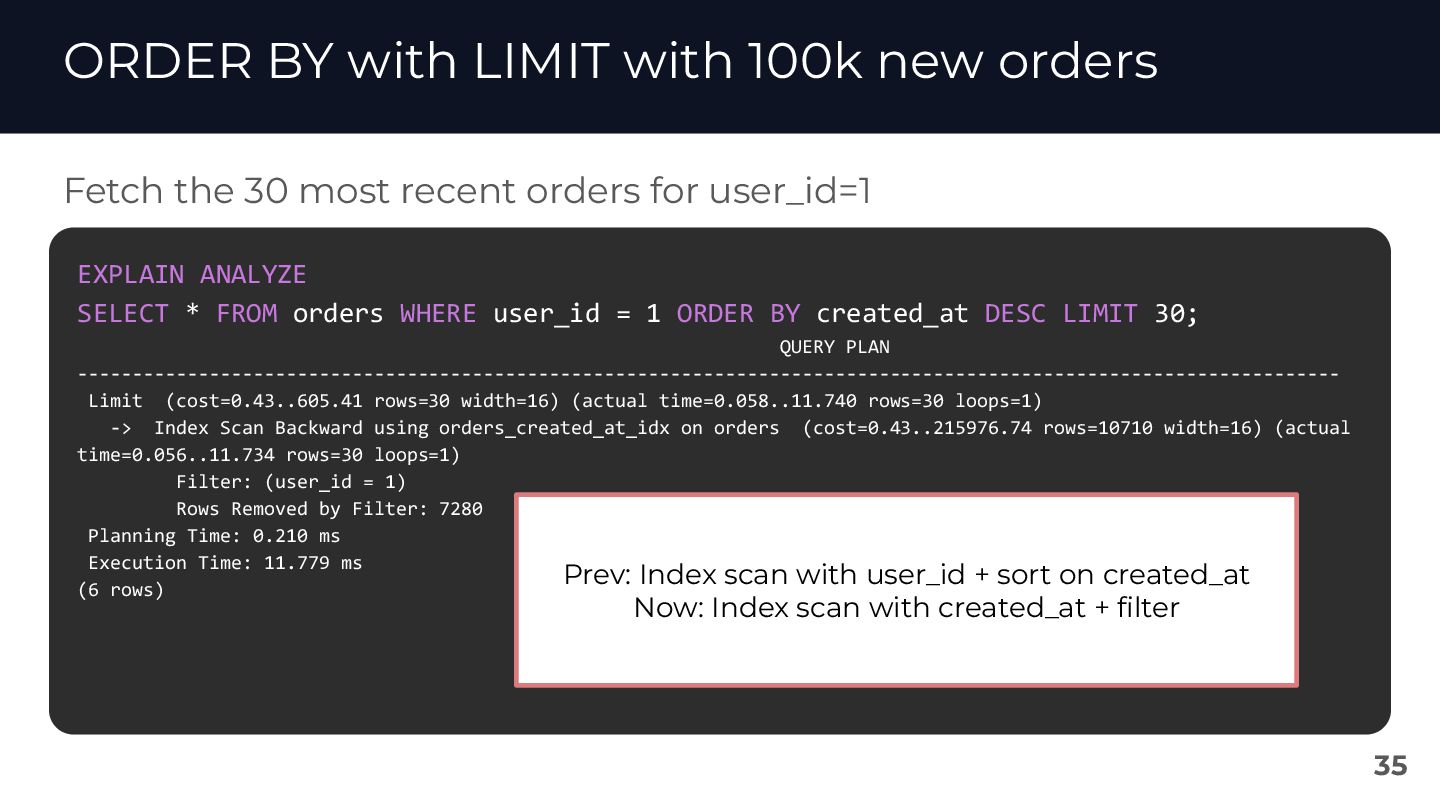{kind=link}
{kind=link}
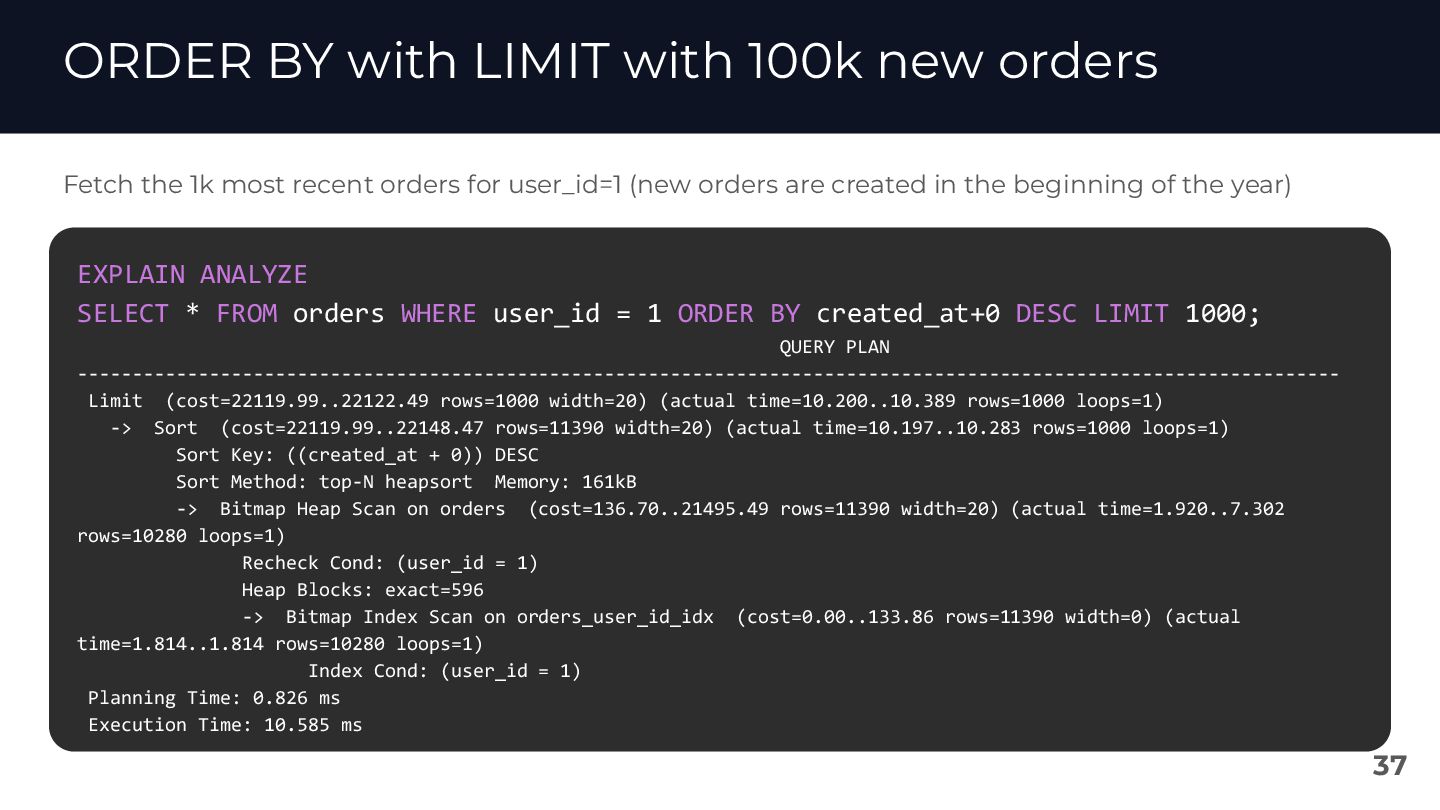{kind=link}
{kind=link}
{kind=link}
{kind=link}
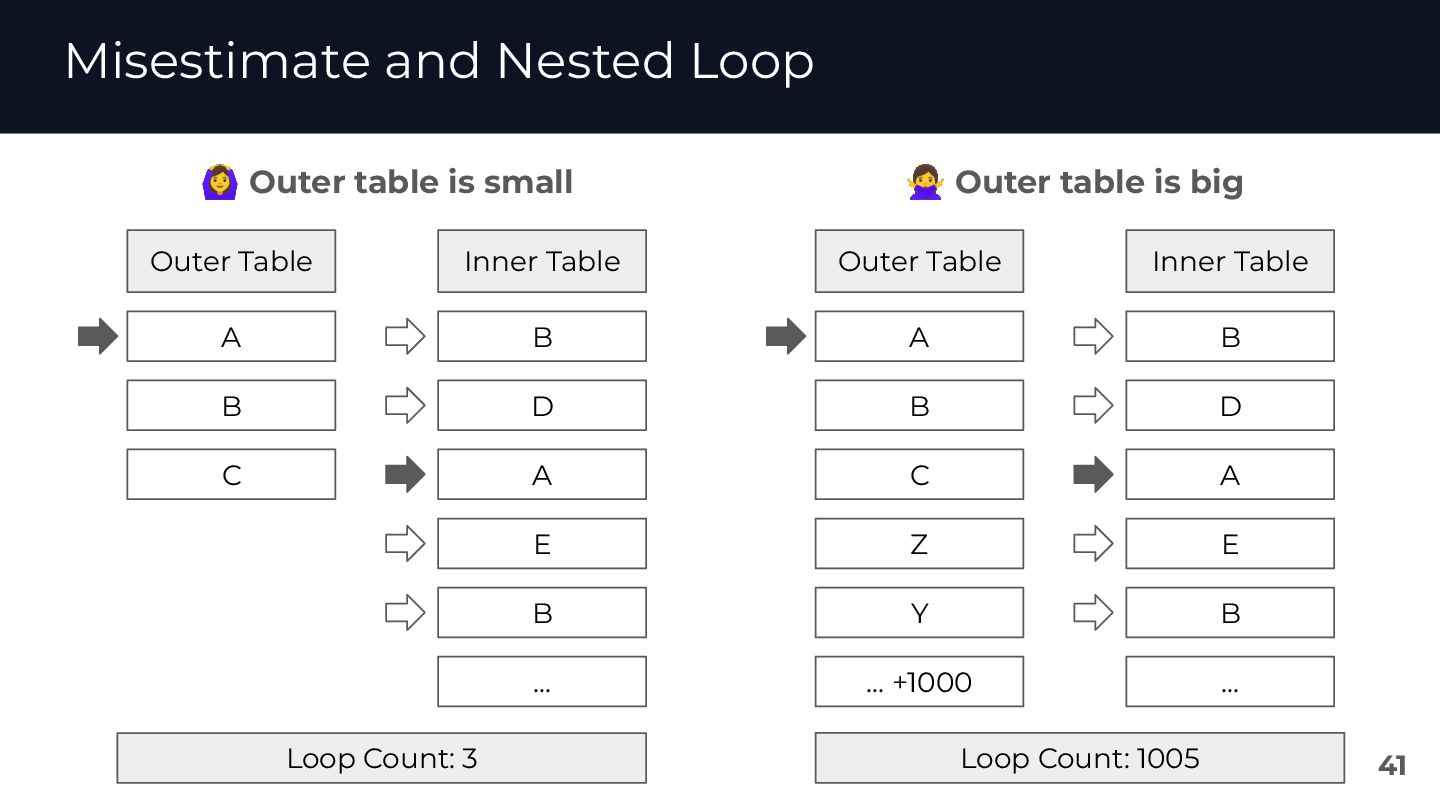{kind=link}
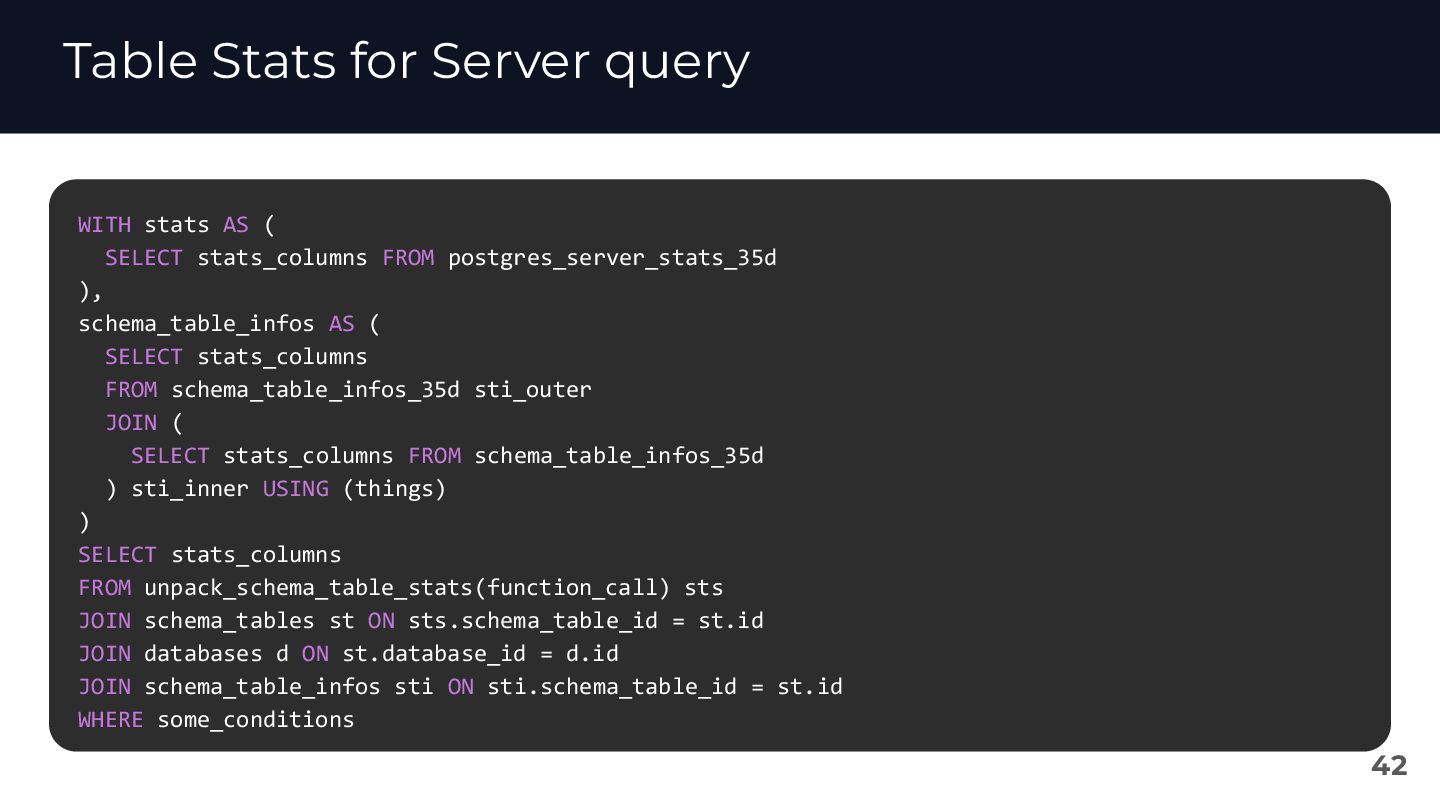{kind=link}
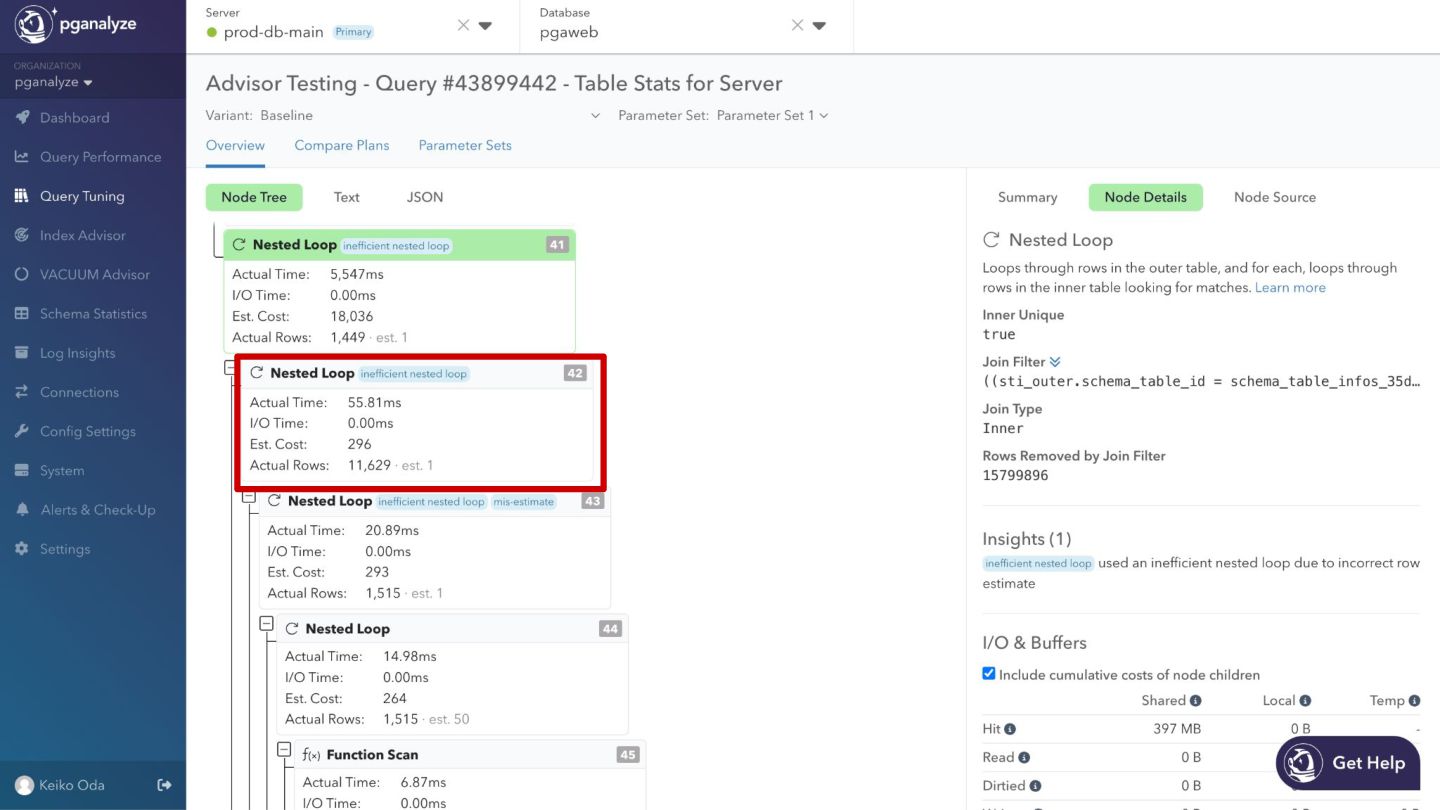{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}