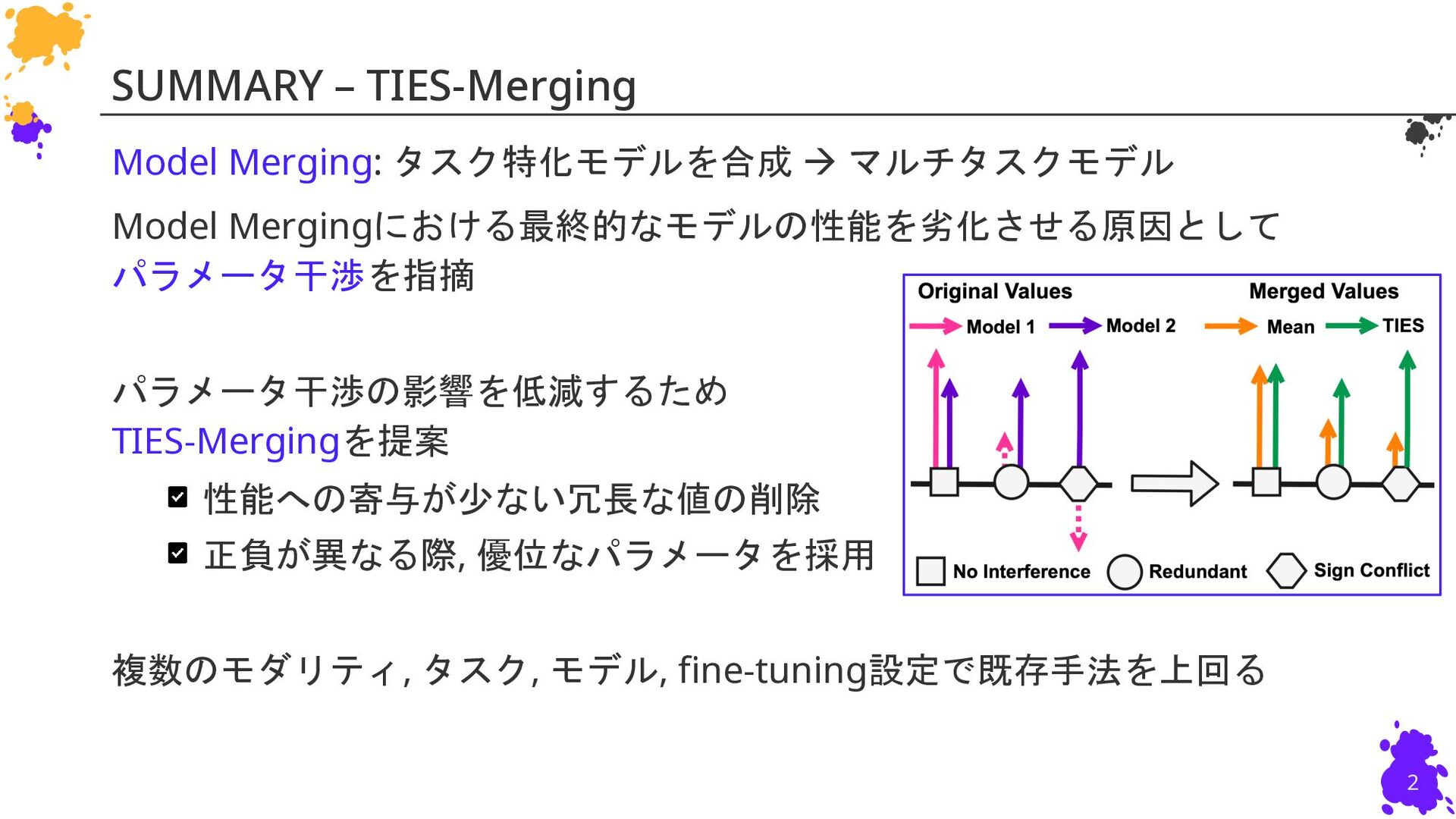
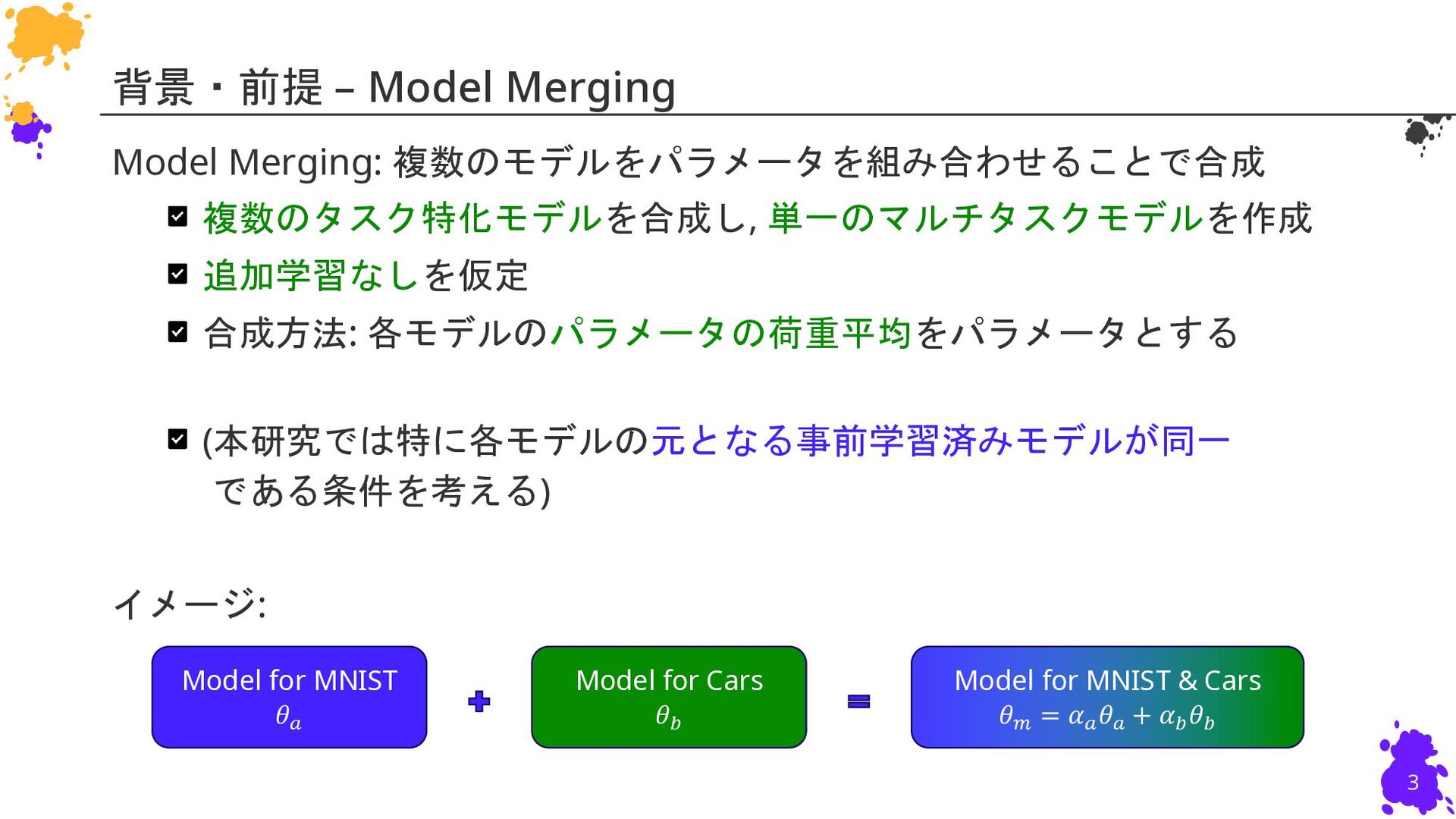
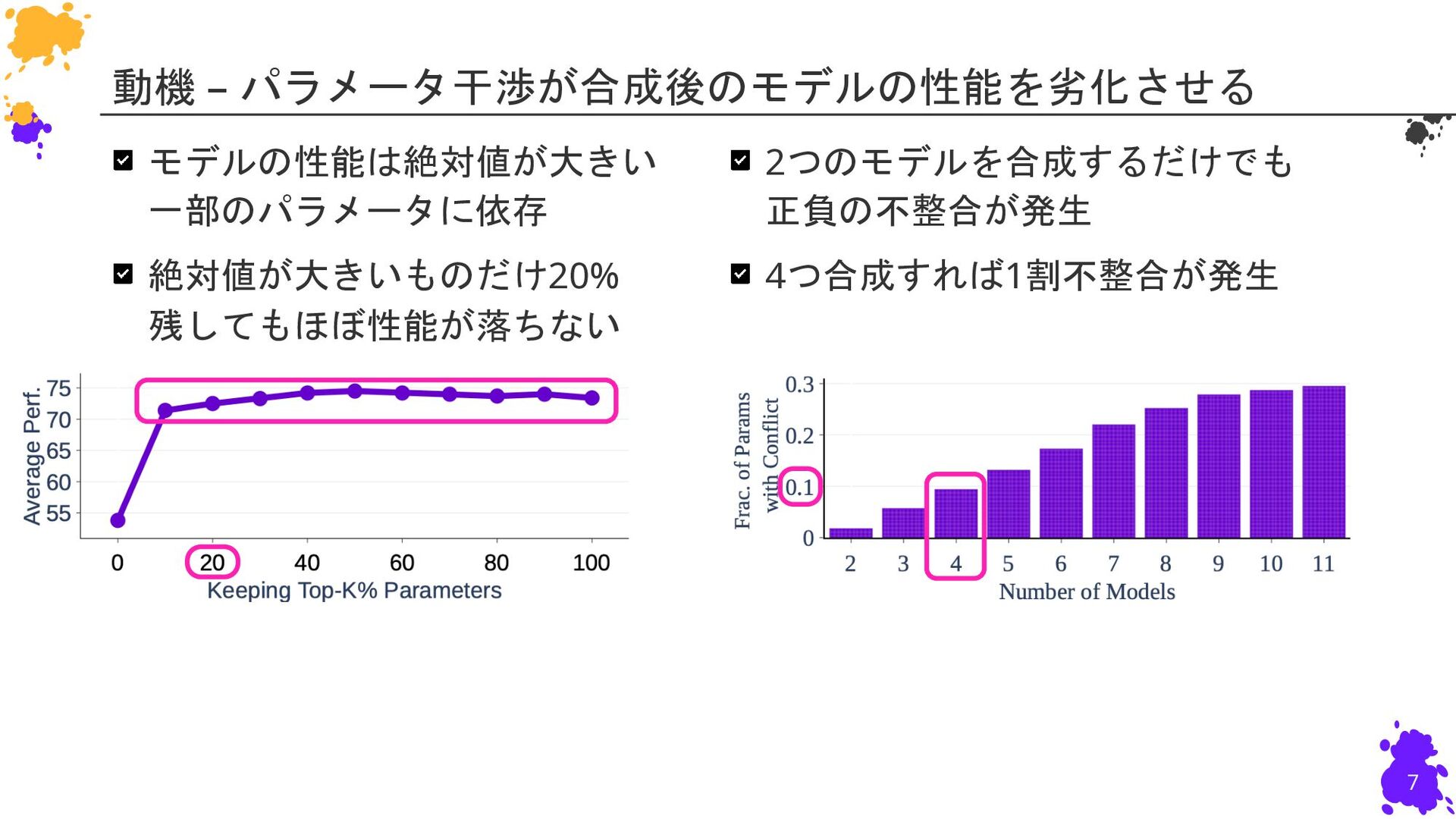
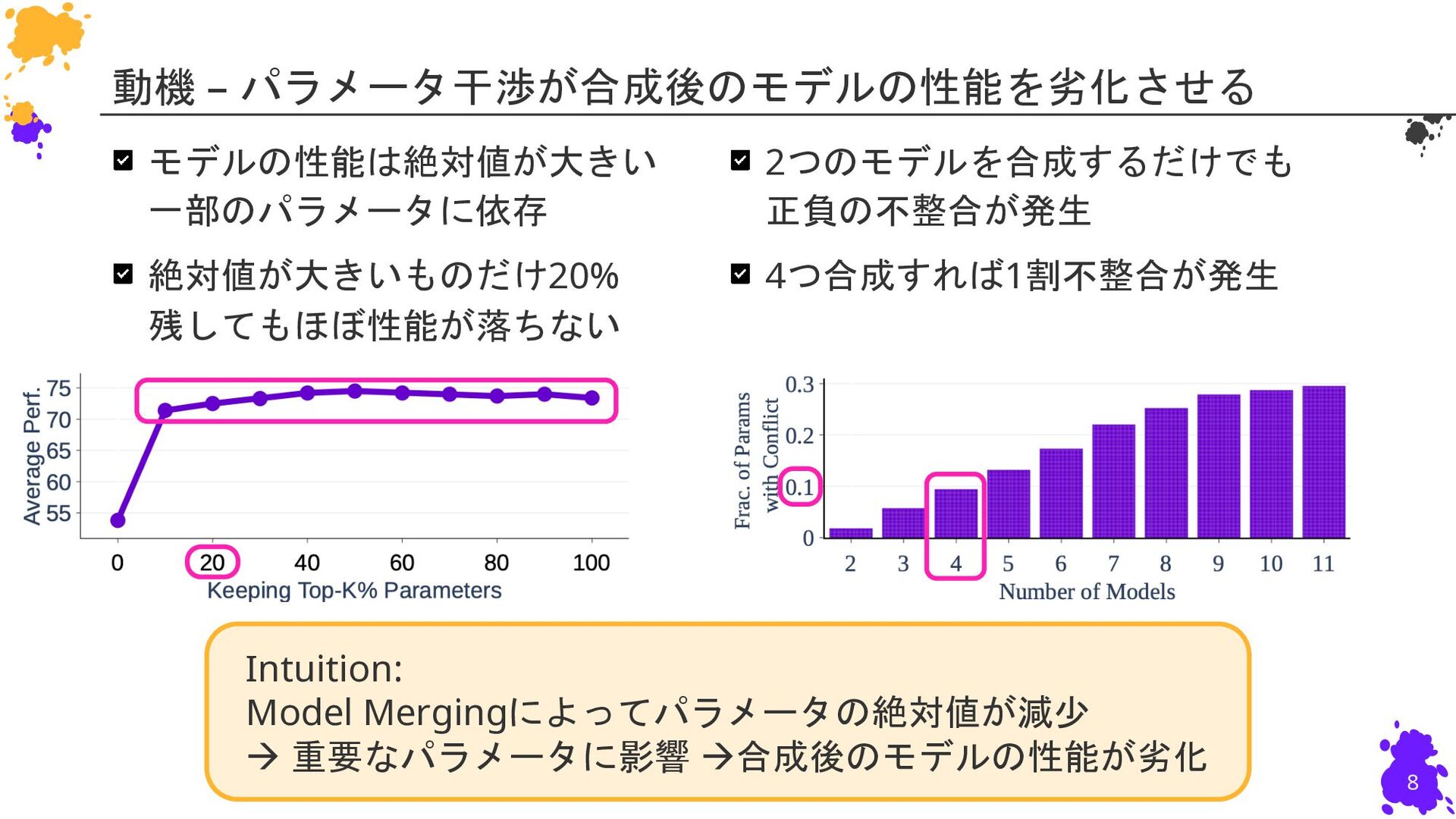
Leshem Choshen2,3, Colin Raffel1, Mohit Bansal1 1: University of North Carolina at Chapel Hill 2: IBM Research 3: MIT 慶應義塾大学 杉浦孔明研究室 小槻誠太郎 P. Yadav, D. Tam, L. Choshen, C. Raffel, and M. Bansal, “TIES-Merging: Resolving Interference When Merging Models,” in NeurIPS, 2023. NeurIPS23 (Poster)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 関連研究 – 複数の合成方法が提案されている 概要 RegMean [Jin+, ICLR’23] マルチタスクモデル内の線形層の出力をタスク特化 モデル内の線形層の出力に近づける線形回帰を解き,](https://files.speakerdeck.com/presentations/fc8aecdd464544d0a597ef634832e7b7/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
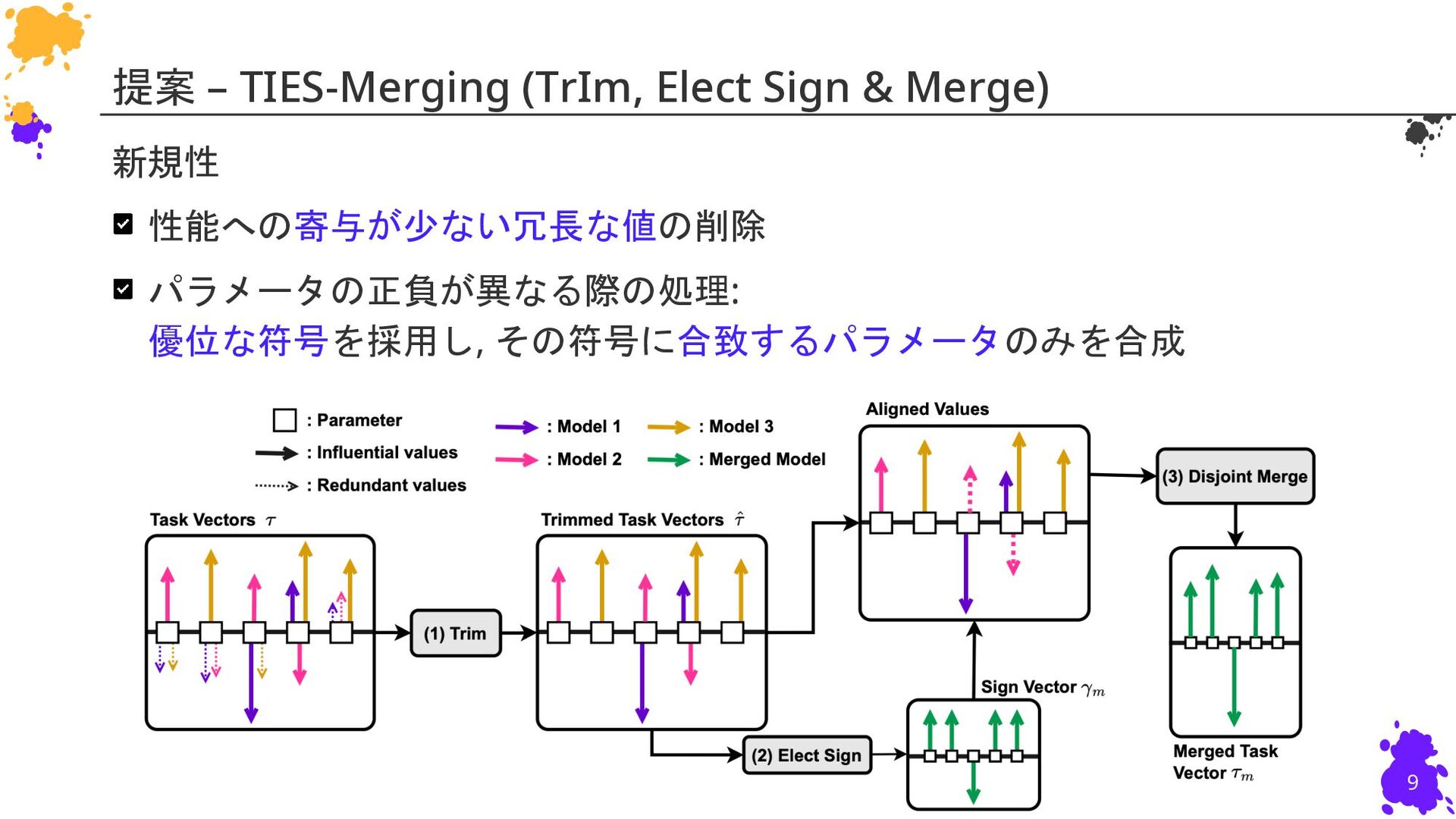{kind=link}
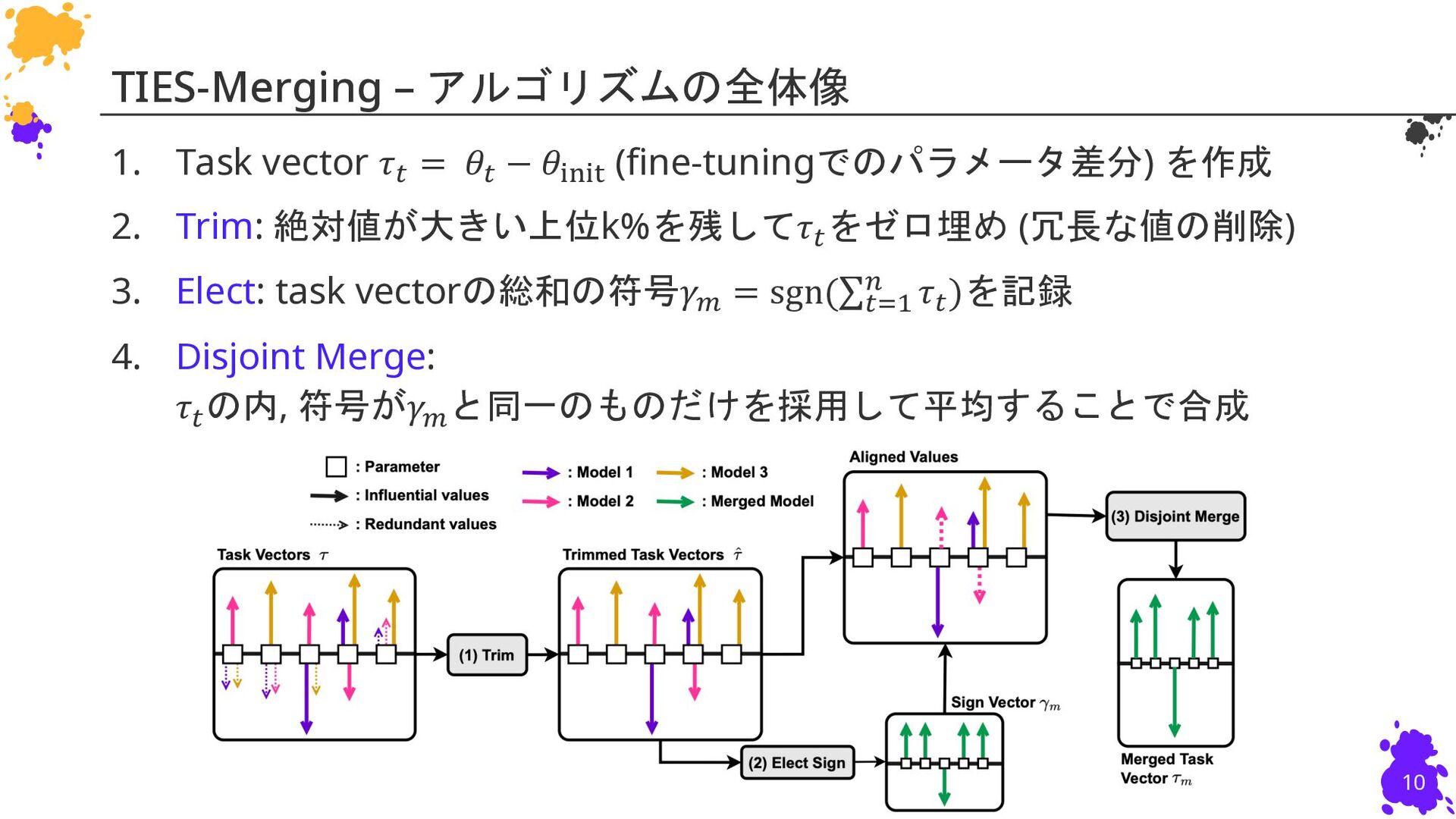{kind=link}
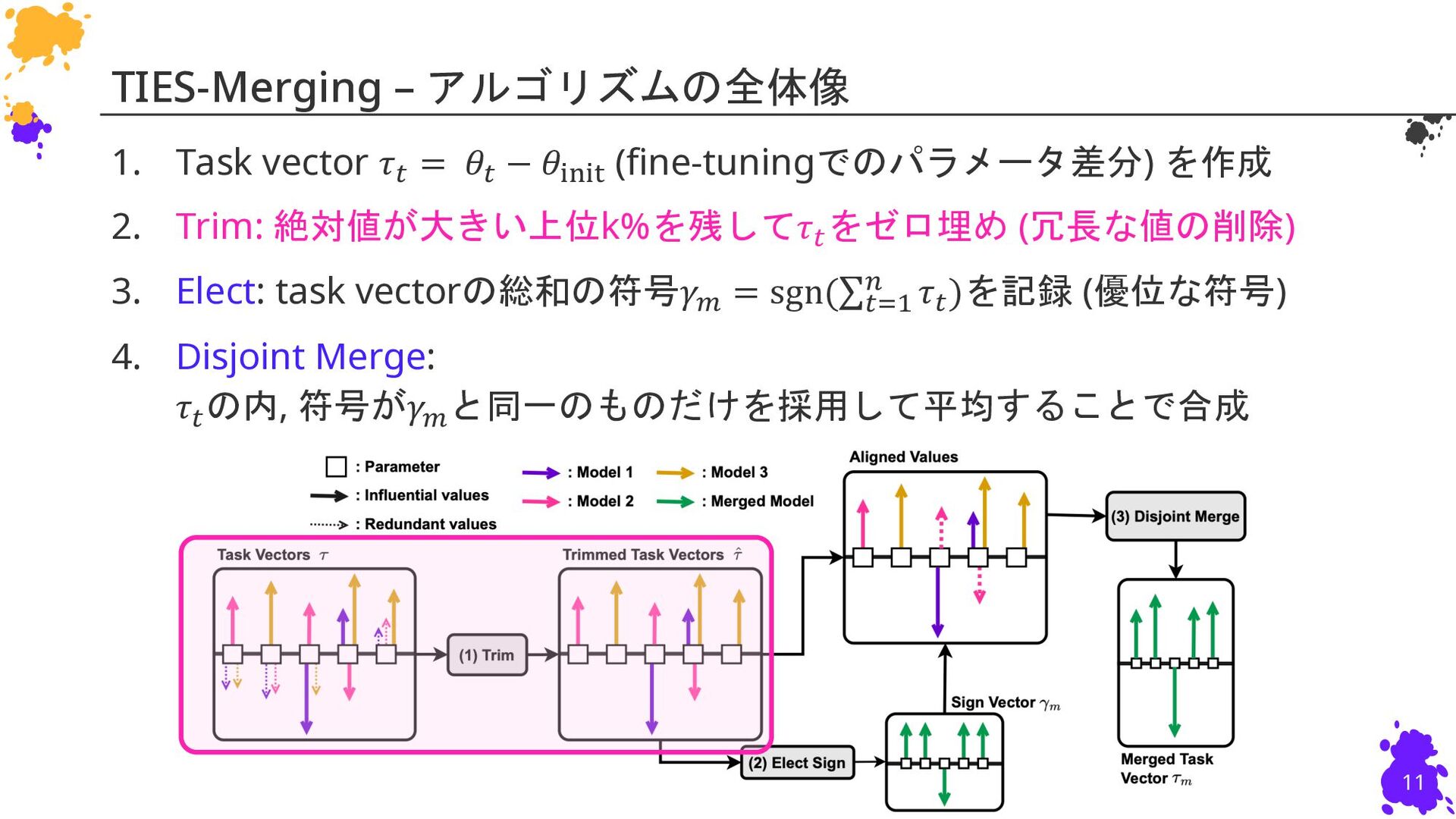{kind=link}
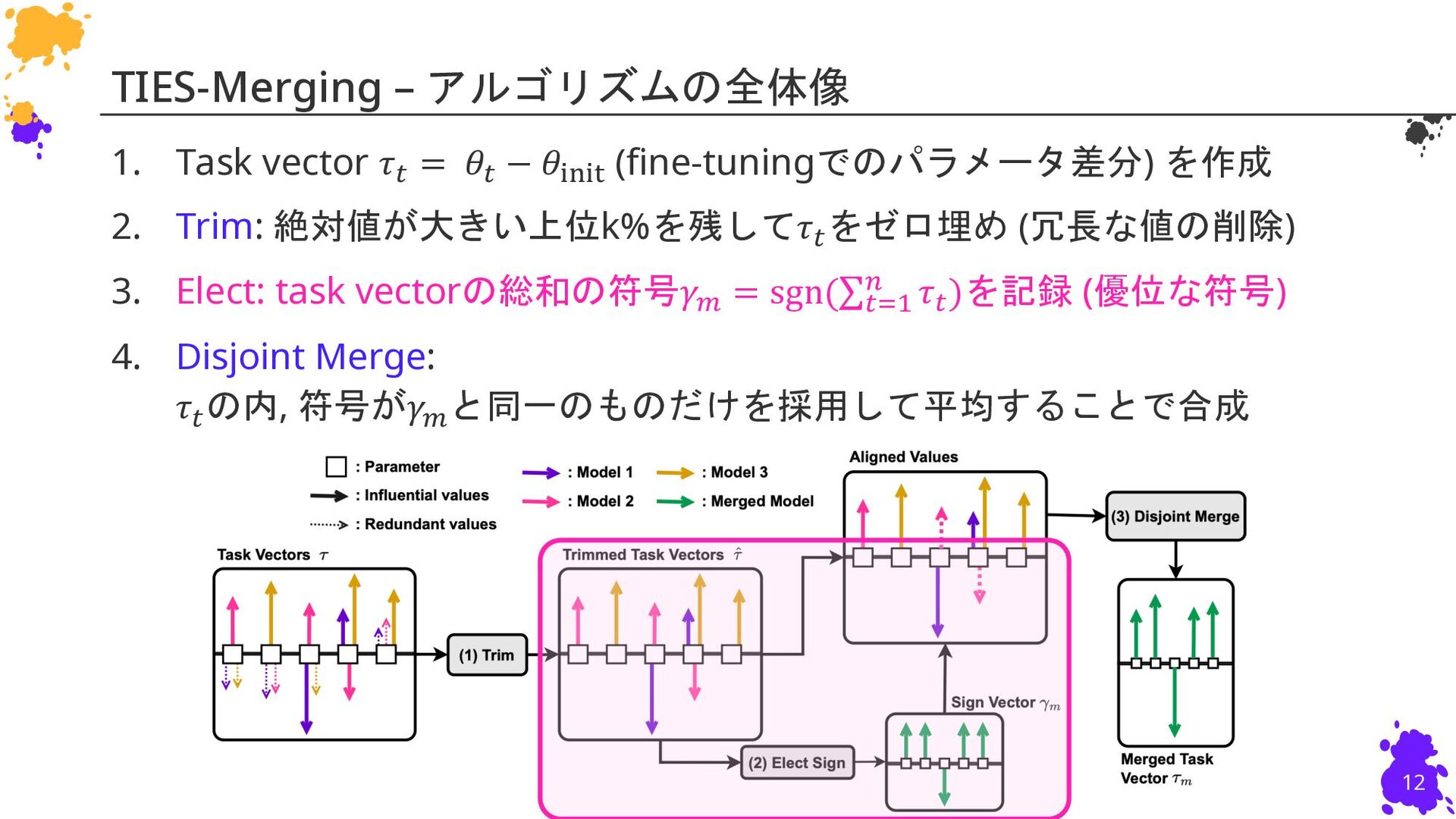{kind=link}
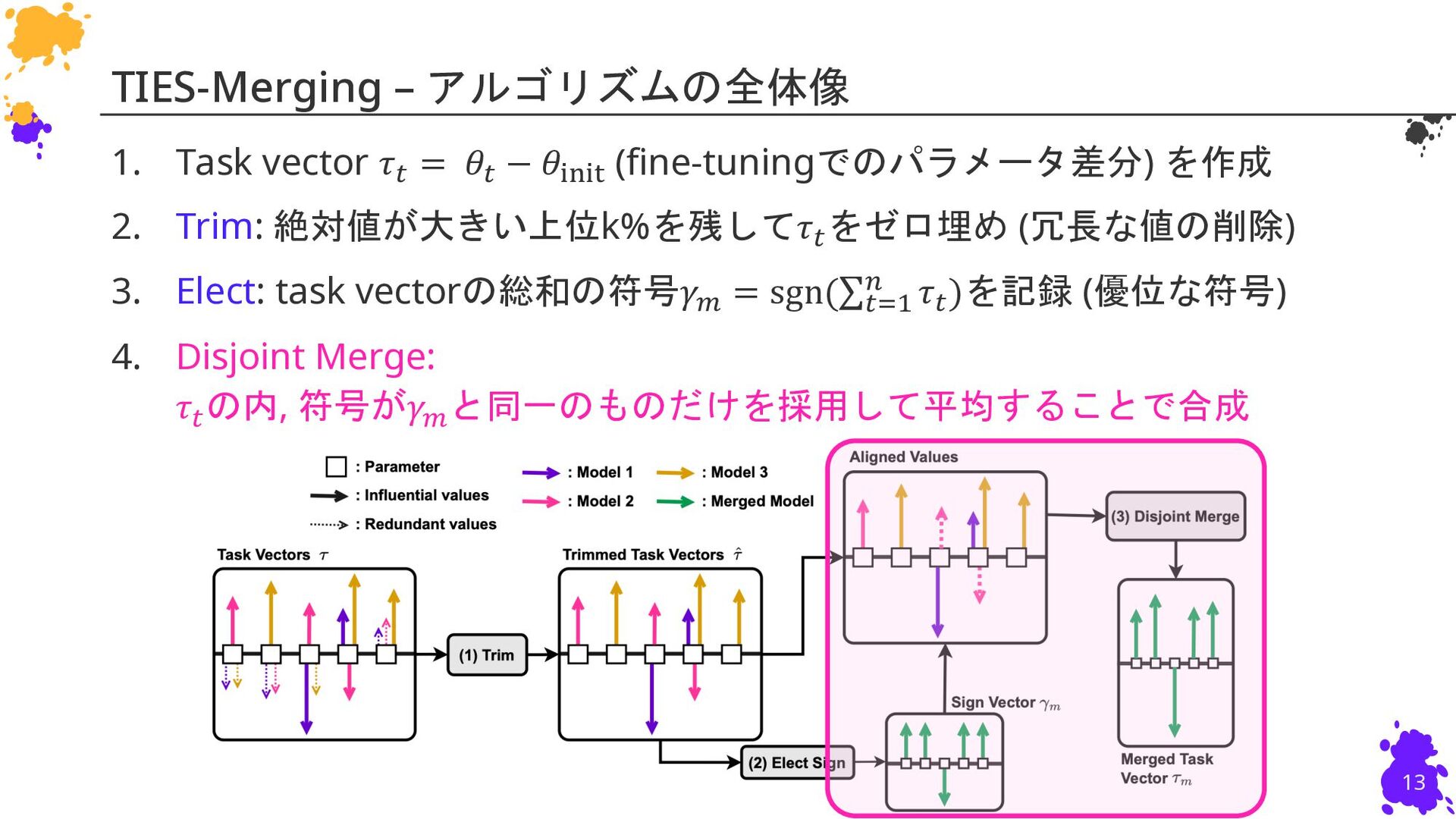{kind=link}
{kind=link}
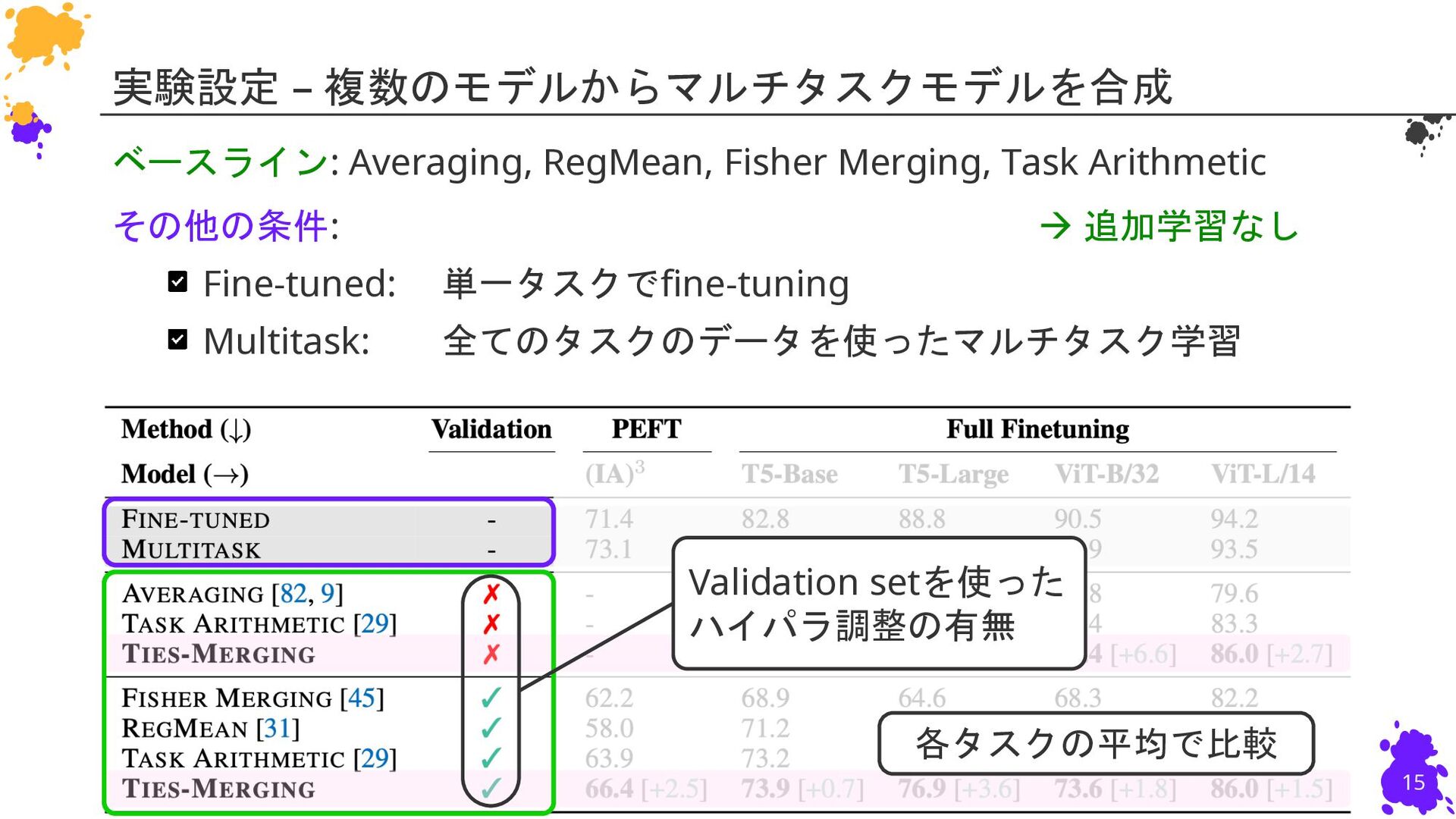{kind=link}
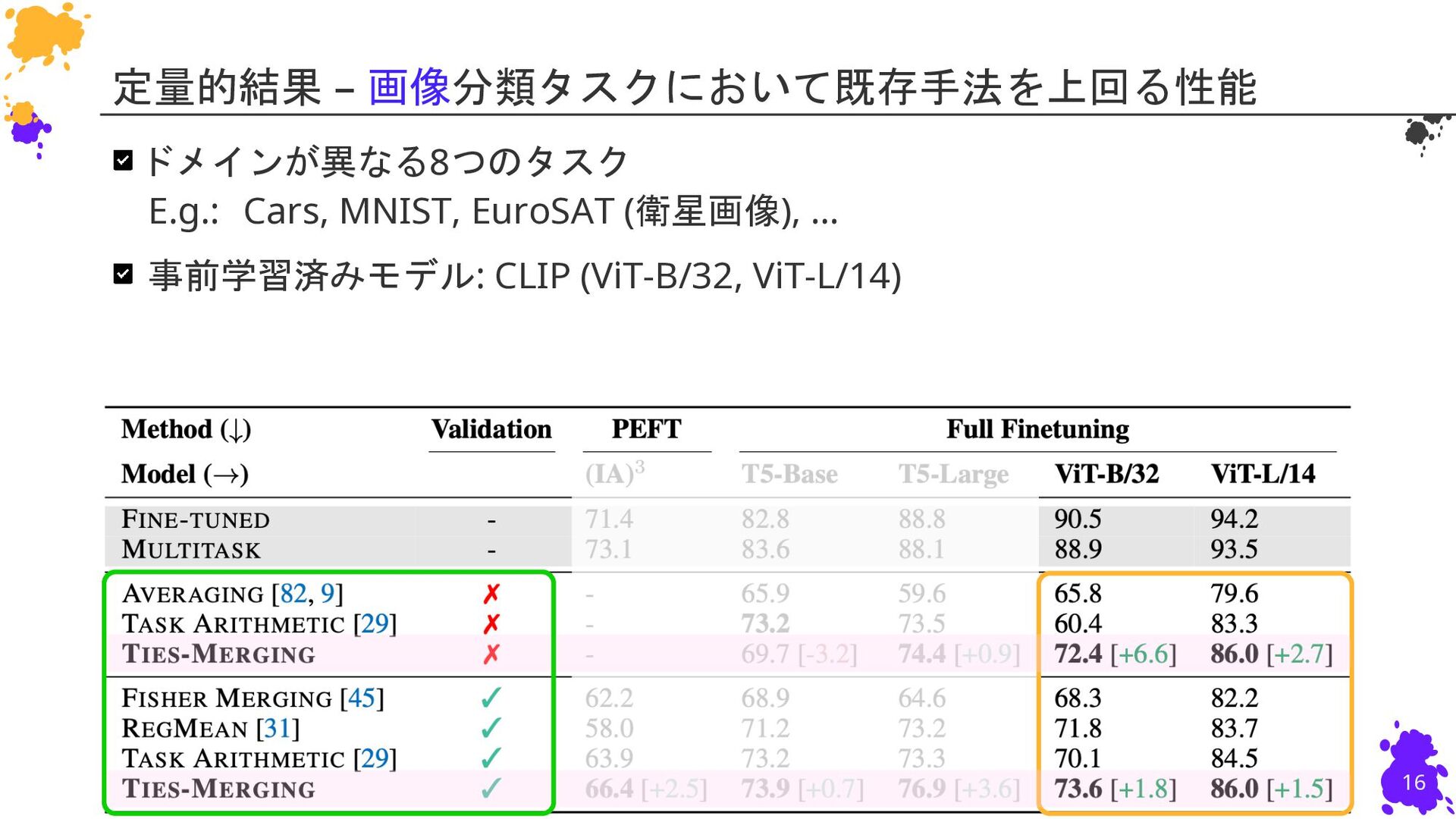{kind=link}
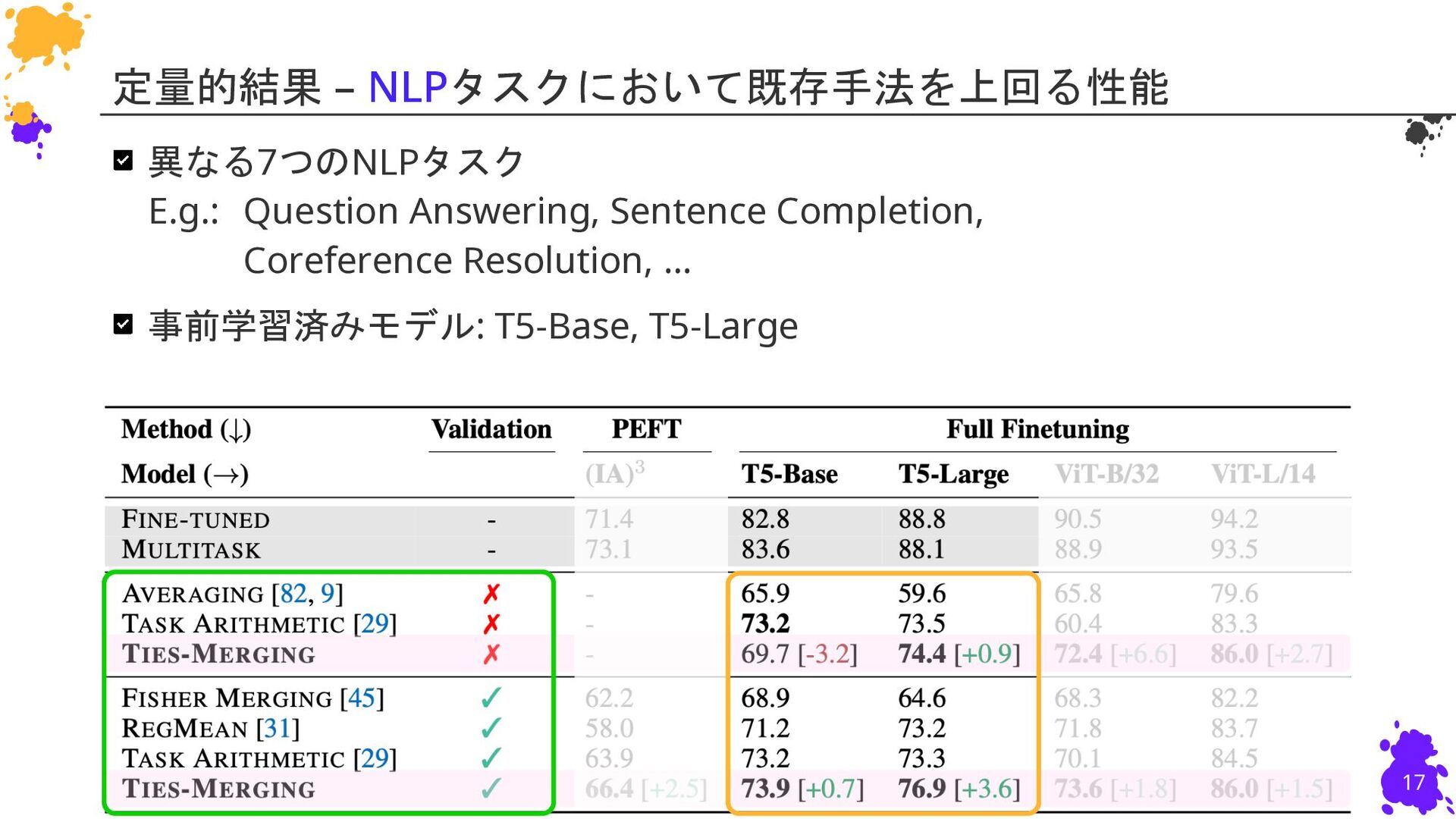{kind=link}
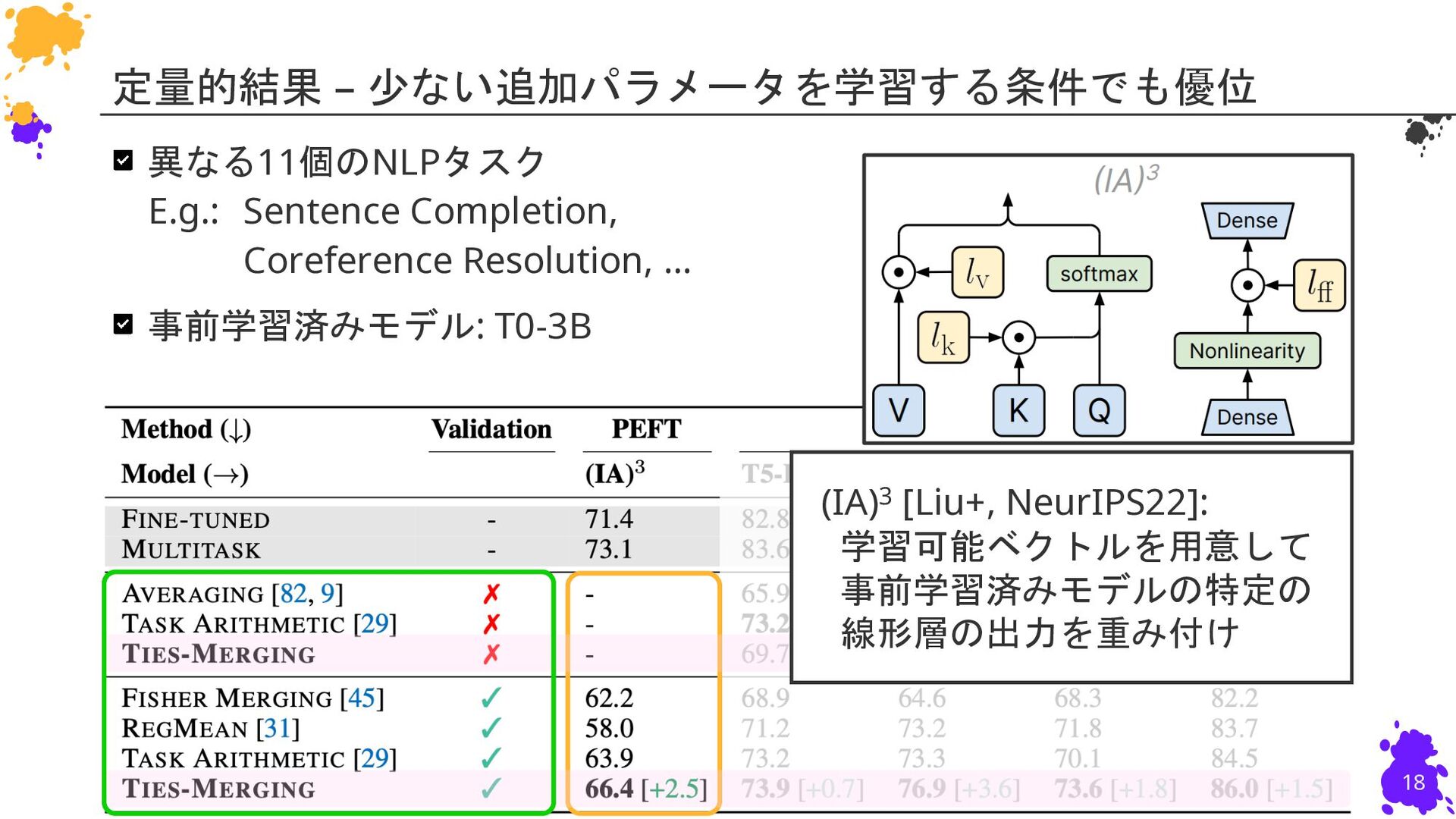{kind=link}
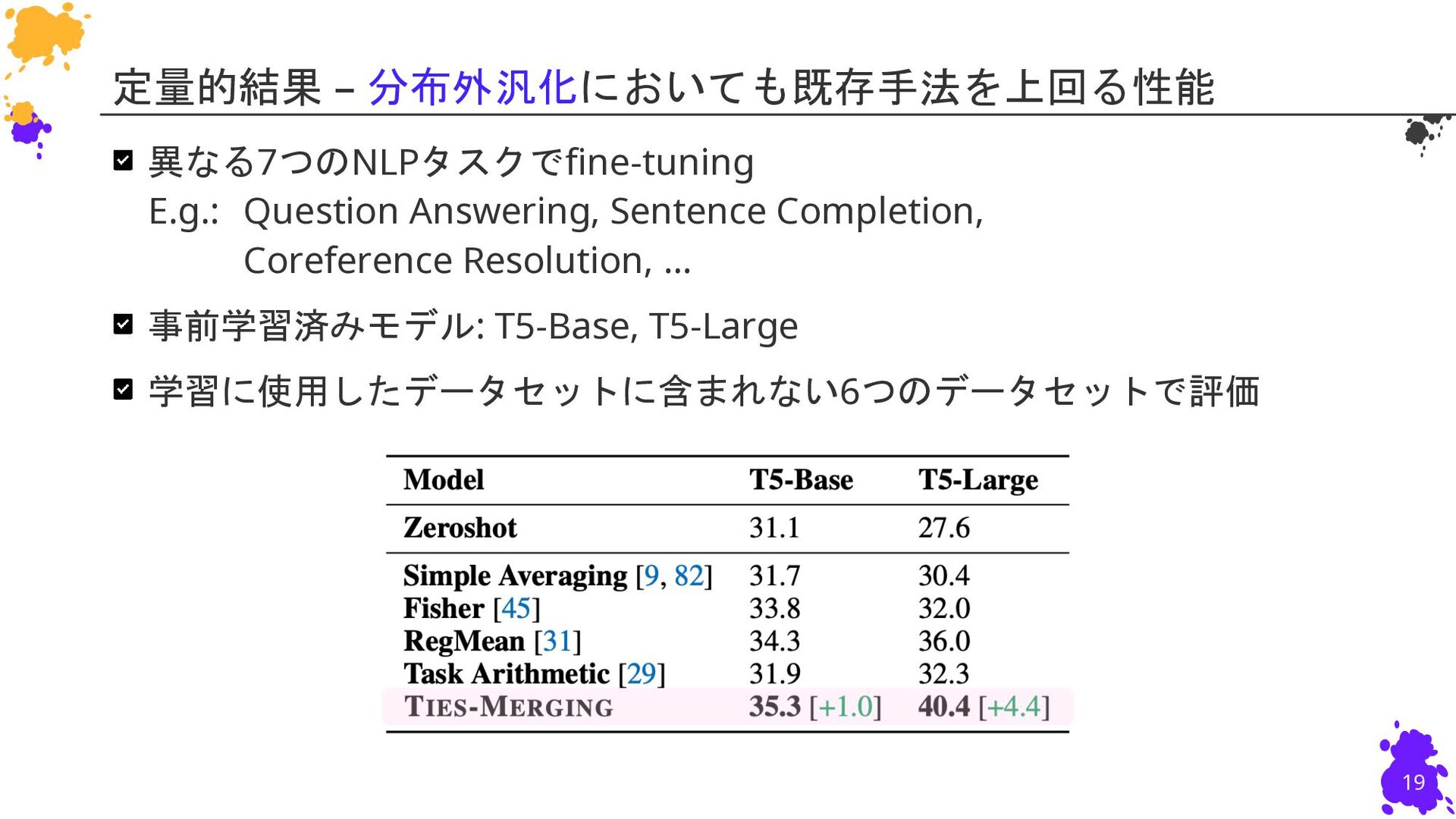{kind=link}
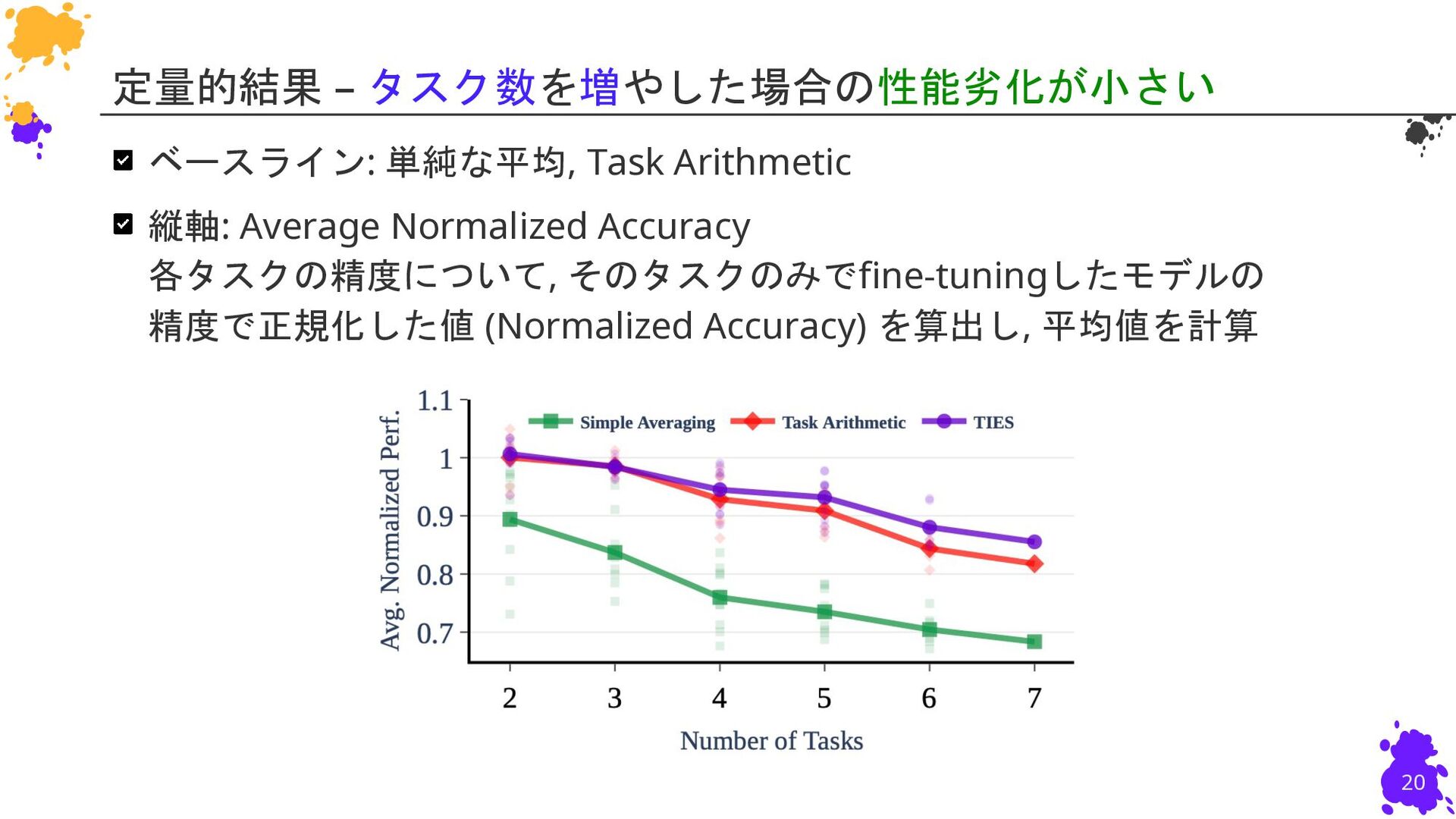{kind=link}
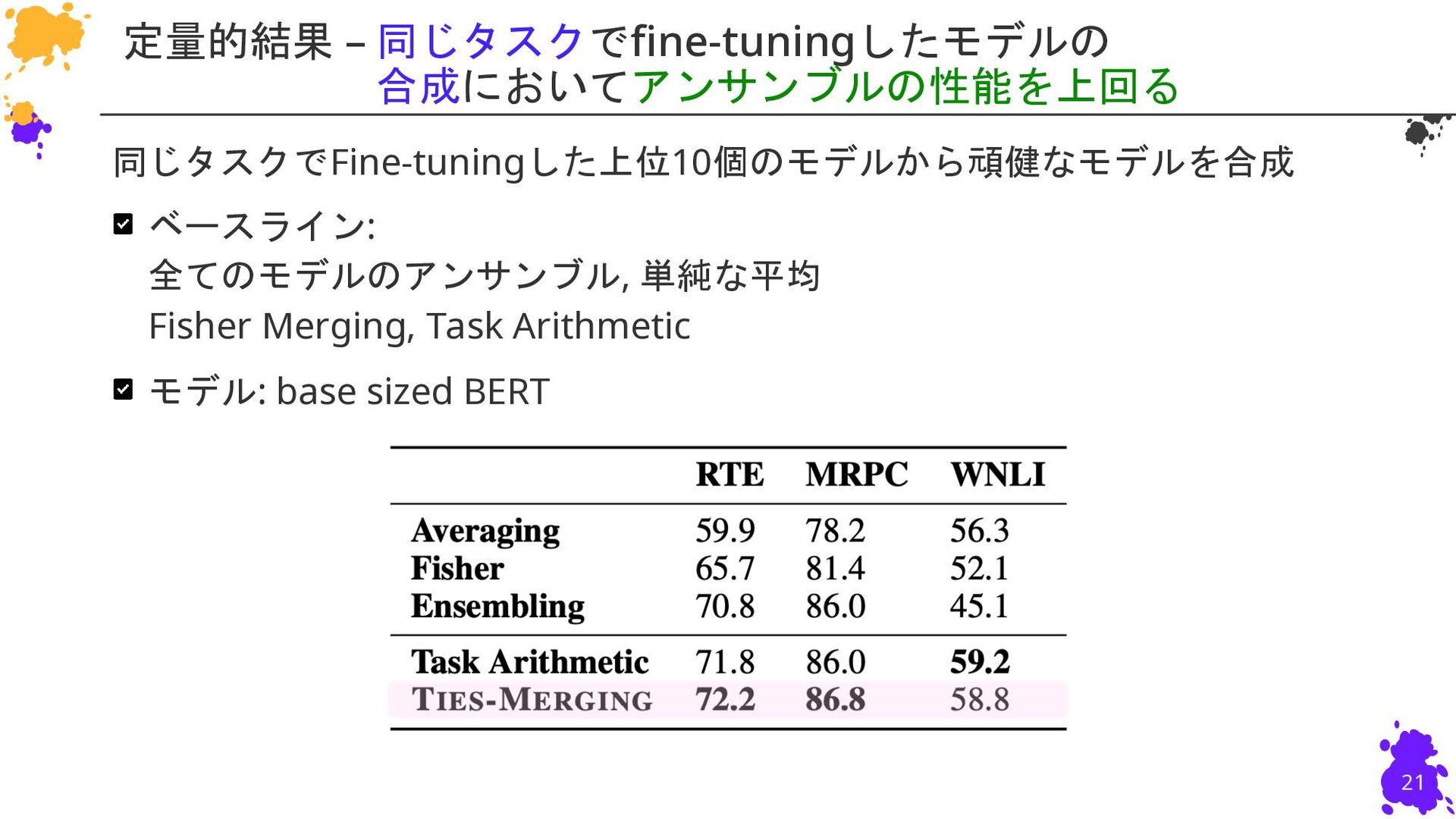{kind=link}
{kind=link}
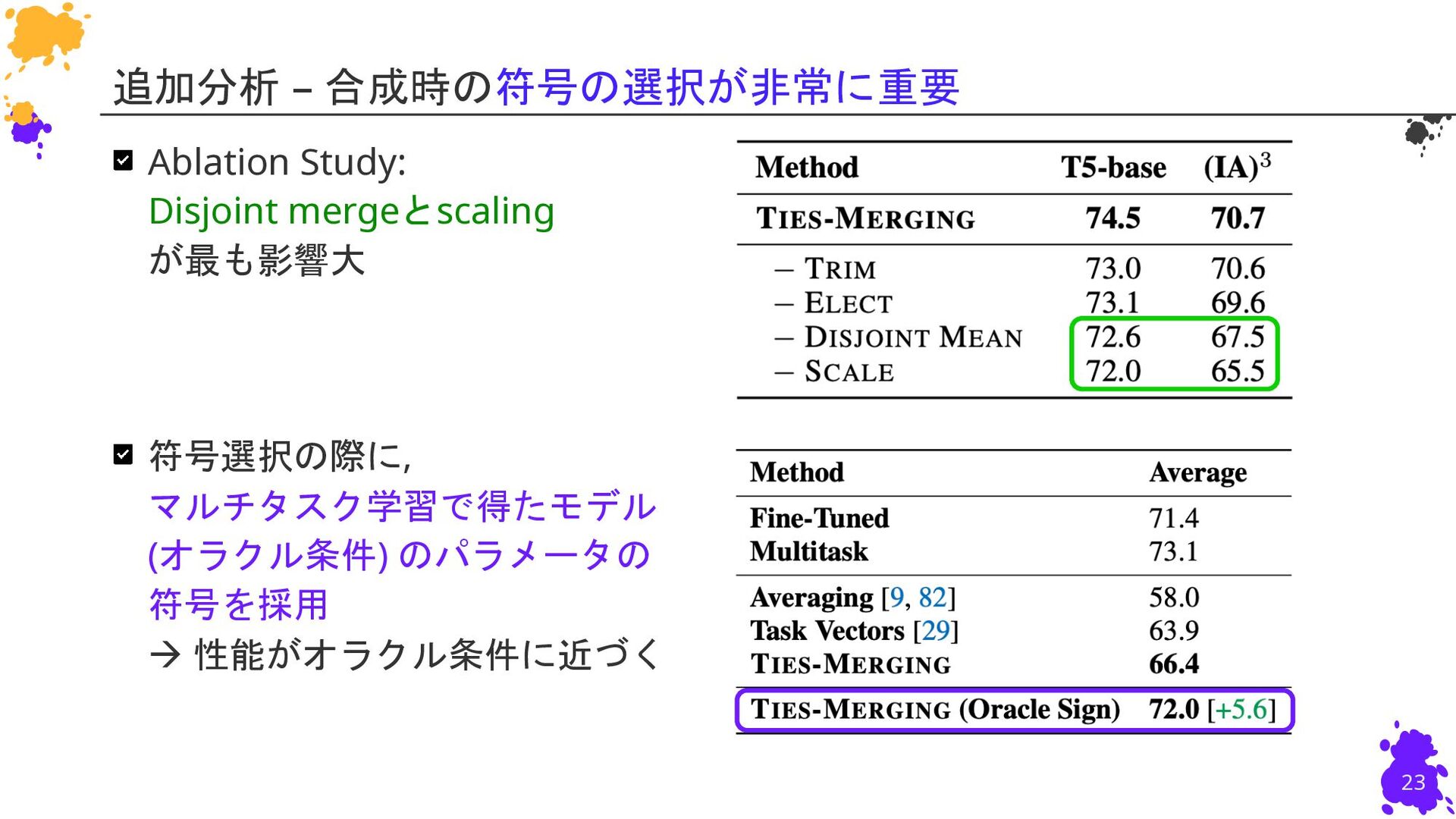{kind=link}
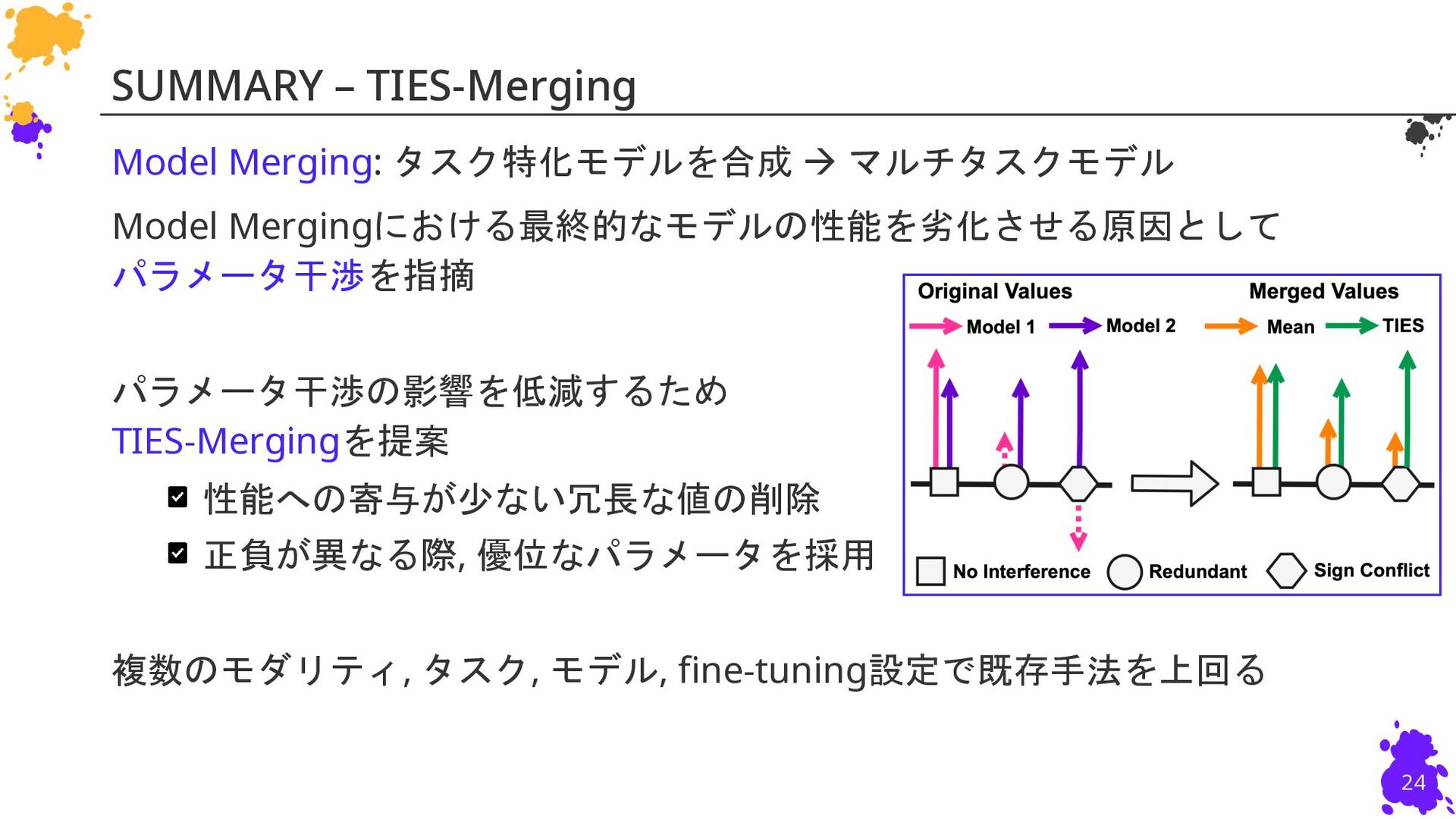{kind=link}
{kind=link}
{kind=link}
{kind=link}