Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[JSAI23] Switching Head–Tail Funnel UNITER: Mu...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
May 31, 2023
Technology
930
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[JSAI23] Switching Head–Tail Funnel UNITER: Multimodal Instruction Comprehension for Object Manipulation Tasks
Semantic Machine Intelligence Lab., Keio Univ.
PRO
May 31, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
85
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
99
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
300
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
190
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
480
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.6k
穢れた技術選定について
watany
20
6.2k
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
310
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
180
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
300
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
2
590
OPENLOGI Company Profile for engineer
hr01
1
75k
発表と総括 / Presentations and Summary
ks91
PRO
0
210
Jitera Company Deck
jitera
0
520
Featured
See All Featured
Claude Code のすすめ
schroneko
67
230k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
520
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
420
Designing for Timeless Needs
cassininazir
1
400
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Un-Boring Meetings
codingconduct
0
350
How STYLIGHT went responsive
nonsquared
100
6.2k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Transcript
慶應義塾大学 是方諒介,神原元就,吉田悠,石川慎太朗, 川崎陽祐,髙橋正樹,杉浦孔明 Switching Head-Tail Funnel UNITERによる 対象物体および配置目標に関する 指示文理解と物体操作
背景:生活支援ロボットに自然言語で指示できると便利 - 2 - World Robot Summit (WRS) [Okada+, AR19]
▪ 高齢化が進行する現代社会 ▪ 日常生活における介助支援需要の高まり ▪ 生活支援ロボット ▪ 被介助者を物理的に支援可能 ▪ 在宅介助者不足解消に期待 りんごを キッチンに 運んで
問題設定:Dual Referring Expression Comprehension with fetch-and-carry (DREC-fc) ▪ 物体検出により抽出した各領域から, および
を特定 ▪ そのうえで,把持・配置動作を実行 ▪ 入力 ① 指示文 ② 対象物体候補が写る画像 ③ 配置目標候補が写る画像 ▪ 出力 ▪ 対象物体候補および配置目標候補が, ともに指示文のGround Truthに一致する確率 “Move the on the left side of the plate to the empty .” 対象物体 配置目標 bottle chair - 3 -
関連研究: Vision-and-Language + Roboticsに関する多様なタスク - 4 - タスク 手法・データセット 概要
VLN ALFRED [Shridhar+, CVPR20] 自然言語の指示文に対応する模範動作 から構成されるデータセット ObjNav OMT [Fukushima+, ICRA22] Object-Scene Memoryを用いて, シーケンス中の物体に注目 MLU-FI TdU [Ishikawa+, RA-L21] 物体操作指示理解分野に,UNITER [Chen+, ECCV20] 型注意機構を導入 ALFRED OMT
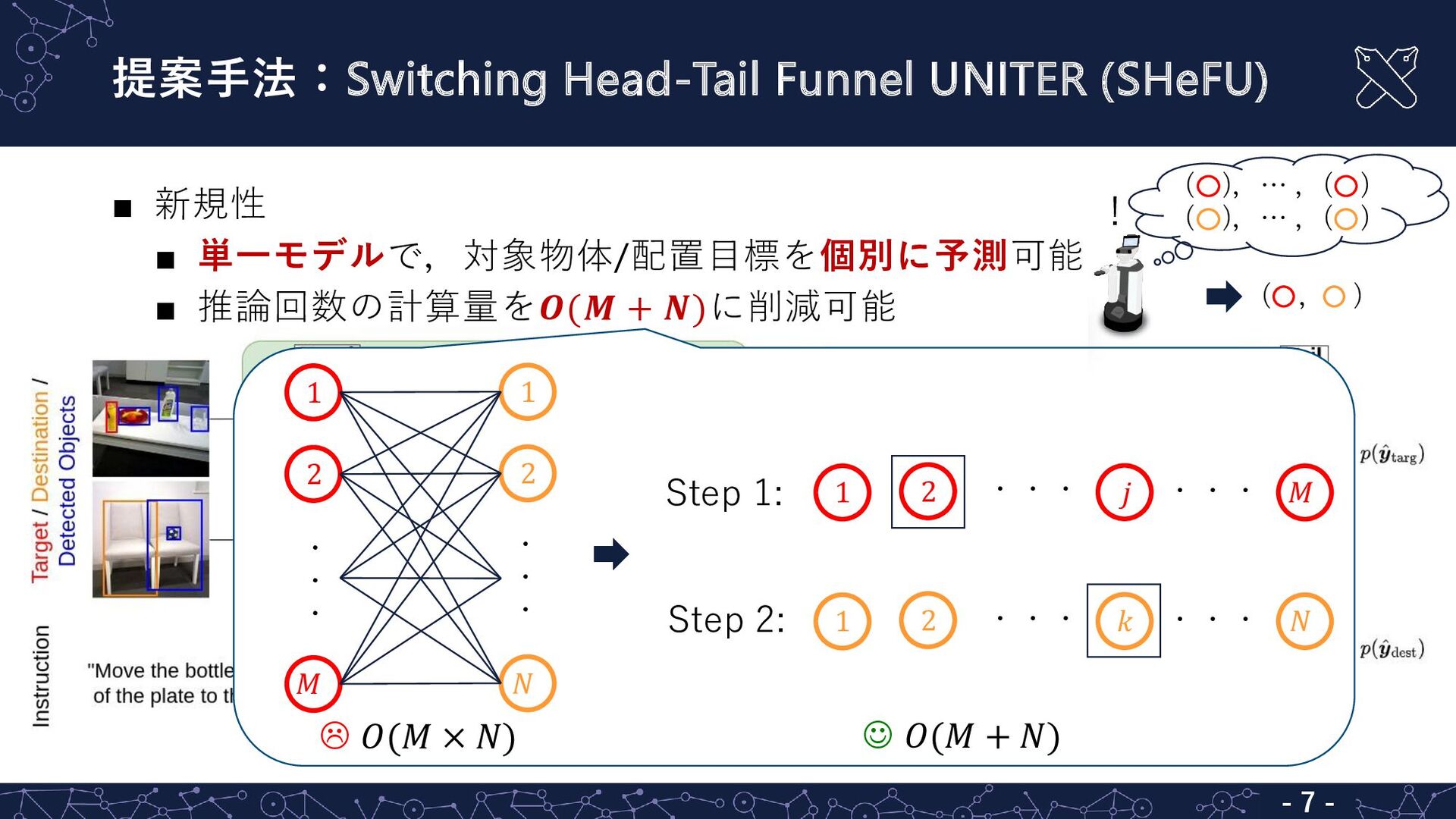
TdUの課題: 要する推論回数が膨大で,リアルタイム性において非実用的 ▪ 目標:指示文に対する最尤のペア(対象物体,配置目標)を探索 推論回数の計算量が 𝑶(𝑴 × 𝑵) 例:𝑀
= 𝑁 = 100,1回の推論時間を4 × 10−3秒と仮定 判断に40秒必要 𝑴:対象物体候補数 𝑵:配置目標候補数 ( , ) … ( , ) ? - 5 - 屋内環境
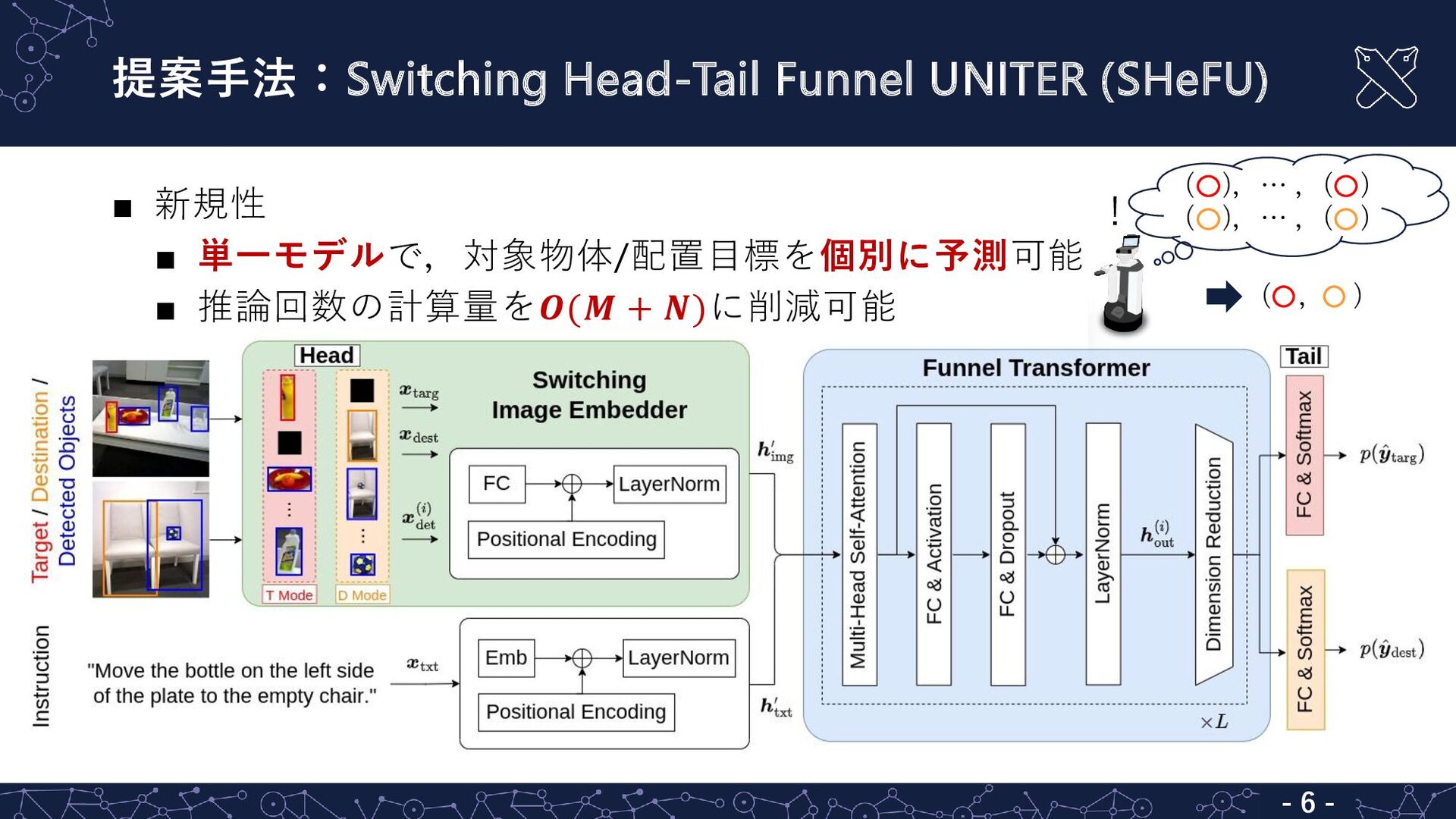
提案手法:Switching Head-Tail Funnel UNITER (SHeFU) - 6 - ▪ 新規性
▪ 単一モデルで,対象物体/配置目標を個別に予測可能 ▪ 推論回数の計算量を𝑶(𝑴 + 𝑵)に削減可能 ( , ) ( ),… ,( ) ( ),… ,( ) !
提案手法:Switching Head-Tail Funnel UNITER (SHeFU) - 7 - 1 1
2 𝑁 2 𝑀 ・ ・ ・ ・ ・ ・ 1 2 𝑗 ・ ・ ・ 𝑀 ・ ・ ・ 1 2 𝑘 ・ ・ ・ 𝑁 ・ ・ ・ Step 1: Step 2: ☺ 𝑂(𝑀 + 𝑁) 𝑂(𝑀 × 𝑁) ▪ 新規性 ▪ 単一モデルで,対象物体/配置目標を個別に予測可能 ▪ 推論回数の計算量を𝑶(𝑴 + 𝑵)に削減可能 ( , ) ( ),… ,( ) ( ),… ,( ) !
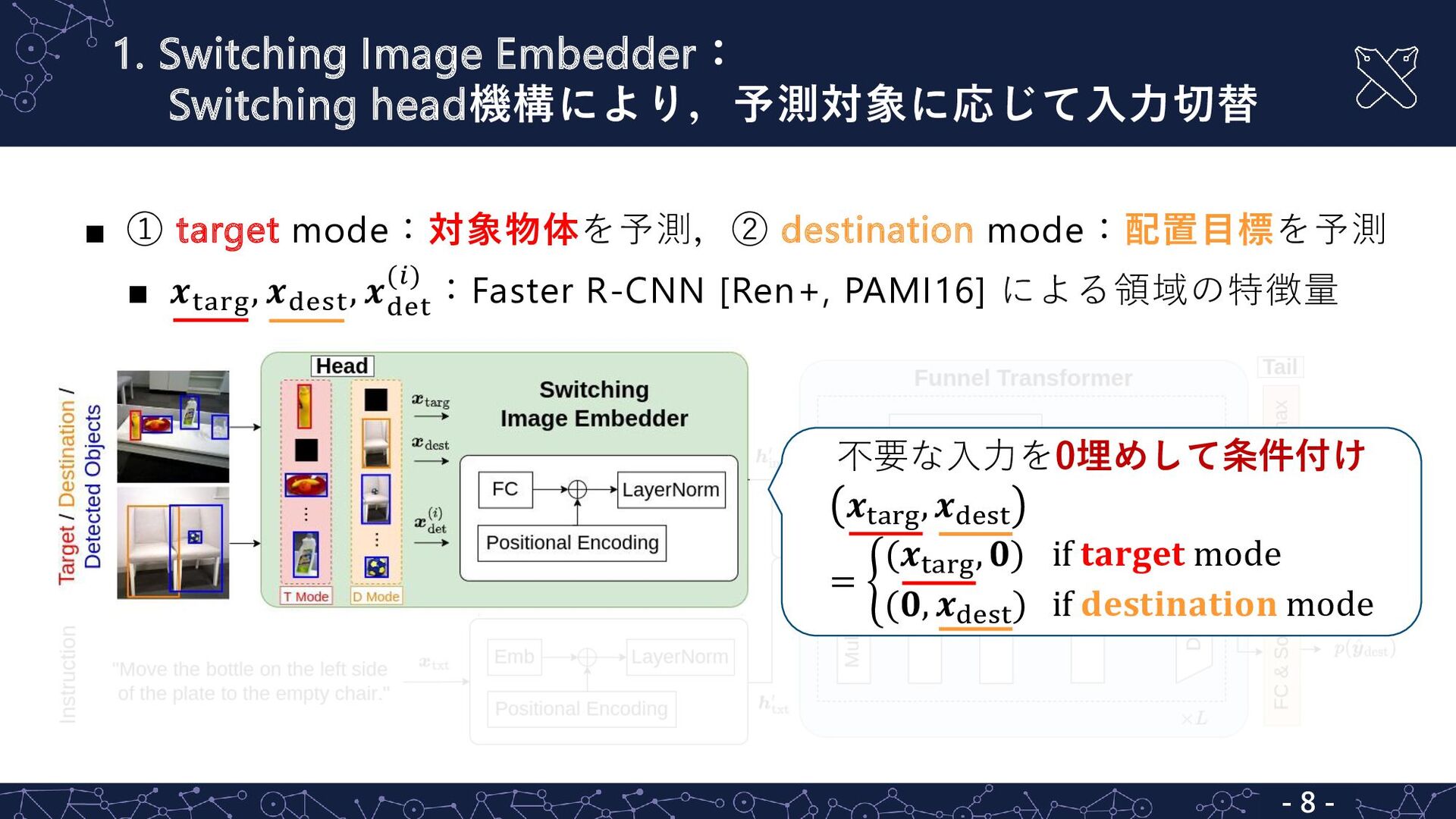
▪ ① target mode:対象物体を予測,② destination mode:配置目標を予測 ▪ 𝒙targ , 𝒙dest
, 𝒙 det (𝑖) :Faster R-CNN [Ren+, PAMI16] による領域の特徴量 1. Switching Image Embedder: Switching head機構により,予測対象に応じて入力切替 不要な入力を0埋めして条件付け 𝒙targ , 𝒙dest = ቊ (𝒙targ , 𝟎) if 𝐭𝐚𝐫𝐠𝐞𝐭 mode (𝟎, 𝒙dest ) if 𝐝𝐞𝐬𝐭𝐢𝐧𝐚𝐭𝐢𝐨𝐧 mode - 8 -
2. Funnel Transformer: self-attentionの後,Switching tail機構によりモードに応じて確率を出力 ▪ Funnel Transformer [Dai+, NeurIPS20]
を𝐿層反復 ▪ target modeでは𝑝(ෝ 𝒚targ ),destination modeでは𝑝(ෝ 𝒚dest )を予測確率と解釈 ▪ 単一モデルでマルチタスク学習 ℒ = 𝜆targ ℒCE 𝑦targ , 𝑝 ො 𝑦targ + 𝜆dest ℒCE 𝑦dest , 𝑝 ො 𝑦dest 𝜆⋅ :ハイパーパラメータ ℒCE :交差エントロピー誤差 - 9 -
実験設定:”ALFRED-fc” データセットを収集し,性能を評価 ▪ ALFRED [Shridhar+, CVPR20] ▪ 物体操作を含むVision-and-Language Navigationの標準データセット ▪
ALFRED-fc (fetch and carry):DREC-fcタスクのための新規データセット ☺ ALFREDから,物体把持直前/配置直後の画像を収集 ☺ 配置後の物体を0埋めしてマスク 把持中の物体で 視野が遮蔽 配置後の物体が写る 配置動作の例 - 10 -
定量的結果:ベースライン手法を上回る性能を達成 ▪ 対象物体/配置目標を同時に予測するベースライン手法に合わせて評価 ▪ 正解ラベル(真偽値): 𝑦 = 𝑦targ ∩ 𝑦dest
▪ 予測ラベル(真偽値): ො 𝑦 = ො 𝑦targ ∩ ො 𝑦dest ✓ ベースライン手法を精度で上回る ✓ Switching head/tail機構はともに有効 手法 Accuracy [%] extended TdU [Ishikawa+, RA-L21] 79.4 ± 2.76 提案手法 (W/o Switching head機構) 76.9 ± 2.91 提案手法 (W/o Switching tail機構) 78.4 ± 2.05 提案手法 (SHeFU) 83.1 ± 2.00 +3.7 - 11 -
定性的結果:正例に対する成功例 ▪ 指示文:”Move the soap from the shelves to the
metal rack .” ☺ 対象物体候補 / 配置目標候補が, ともにGround Truthに一致すると正しく予測 - 12 -
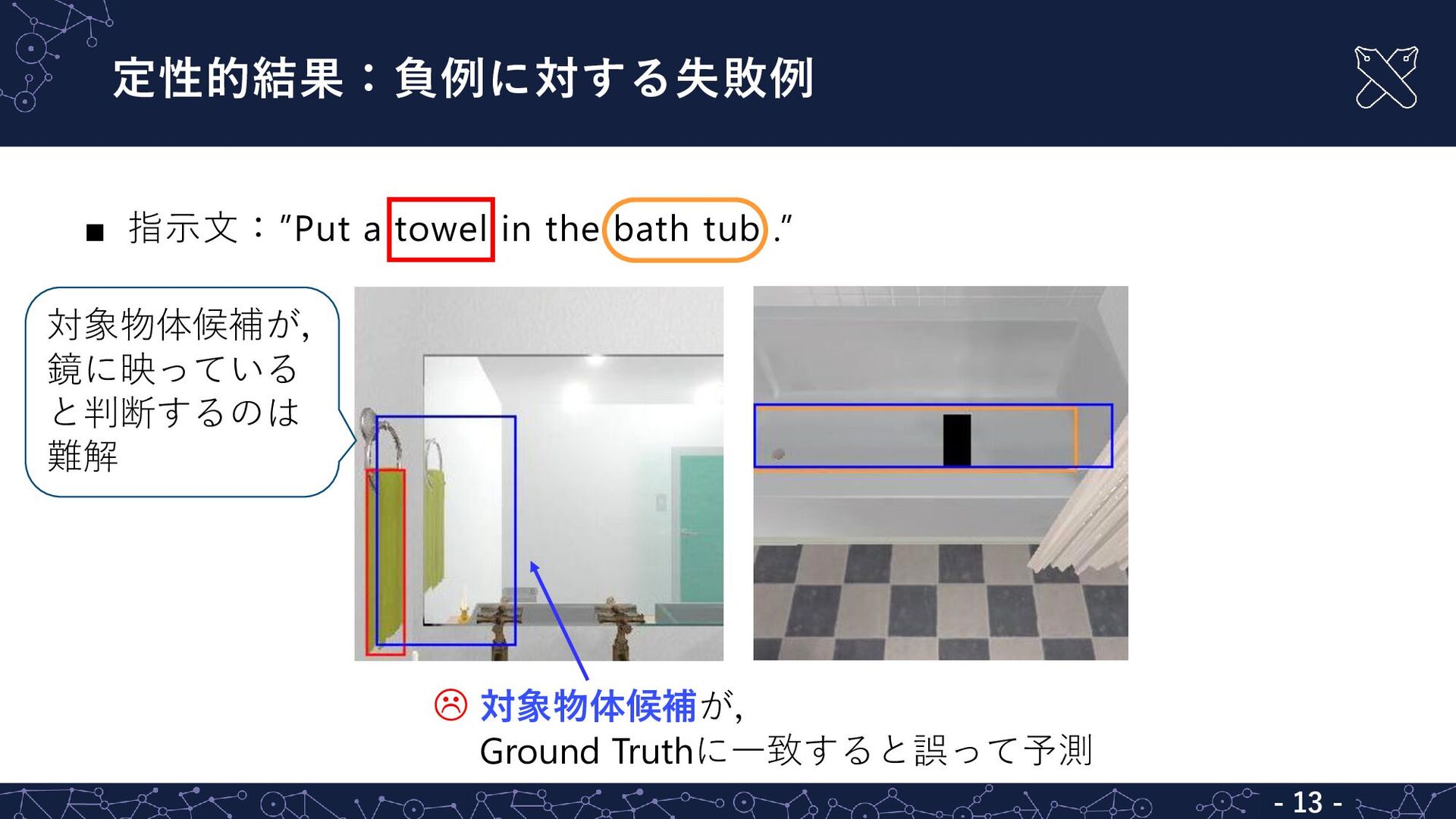
定性的結果:負例に対する失敗例 - 13 - ▪ 指示文:”Put a towel in the
bath tub .” 対象物体候補が, Ground Truthに一致すると誤って予測 対象物体候補が, 鏡に映っている と判断するのは 難解
実験設定(実機):言語理解 + 把持・配置動作 - 14 - 8x 家具を複数視点から撮影するwaypoint(16個)を巡回 ▪ 環境:WRS
2020 Partner Robot Challenge/Real Spaceの標準環境に準拠 ▪ 実機:Human Support Robot (HSR) [Yamamoto+, ROBOMECH J.19] ▪ 物体:YCB Object [Calli+, RAM15] ▪ 評価指標:言語理解精度,タスク成功率(把持・配置)
実機動作:移動・把持・配置動作はヒューリスティック - 15 - ▪ 移動 ▪ 把持 ▪ 配置
RGB / Depth / ハンドカメラ ハンドカメラ rviz rviz rviz 8x 1.5x 1.5x
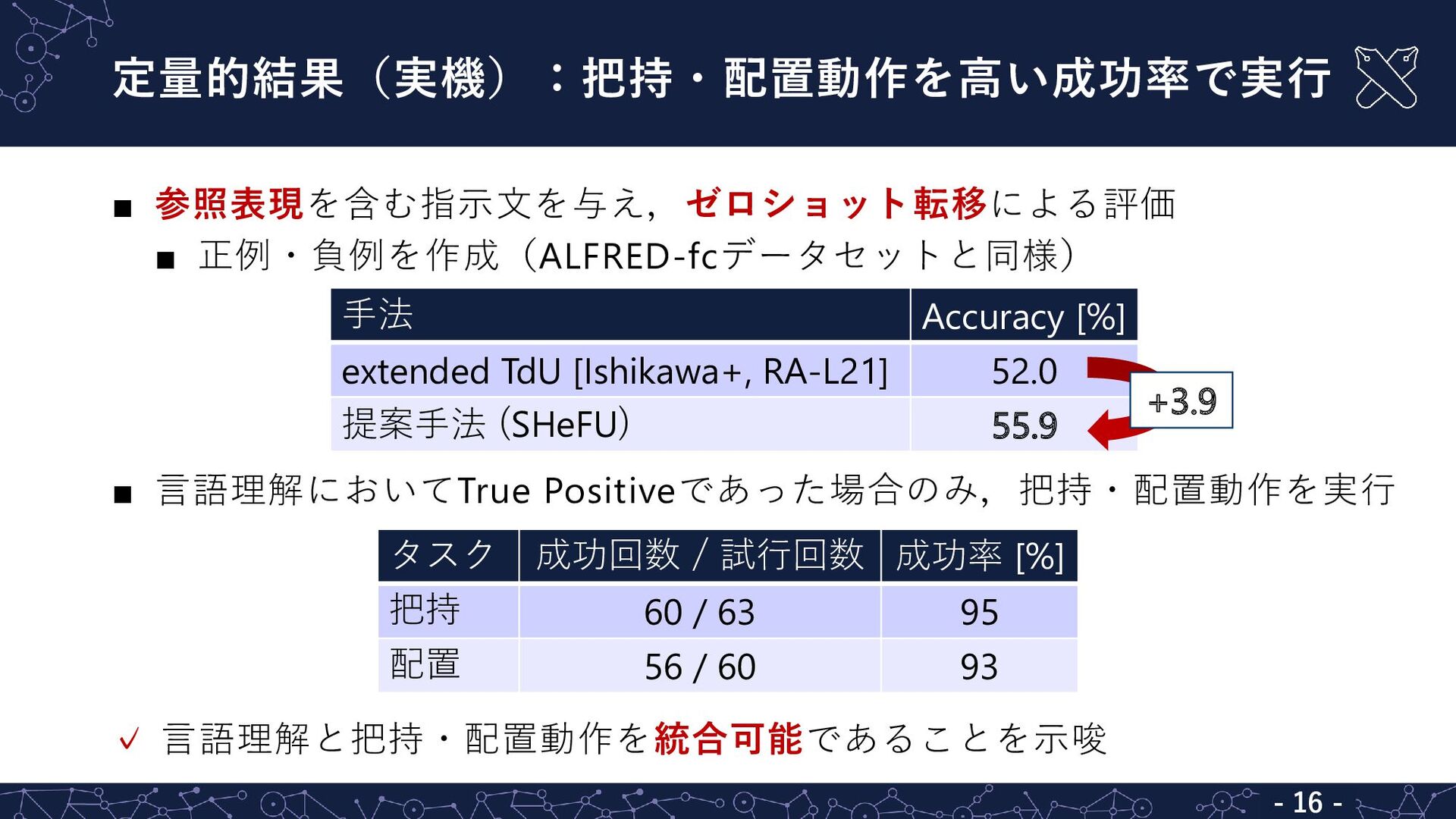
定量的結果(実機):把持・配置動作を高い成功率で実行 - 16 - ▪ 参照表現を含む指示文を与え,ゼロショット転移による評価 ▪ 正例・負例を作成(ALFRED-fcデータセットと同様) ▪ 言語理解においてTrue
Positiveであった場合のみ,把持・配置動作を実行 ✓ 言語理解と把持・配置動作を統合可能であることを示唆 手法 Accuracy [%] extended TdU [Ishikawa+, RA-L21] 52.0 提案手法 (SHeFU) 55.9 タスク 成功回数 / 試行回数 成功率 [%] 把持 60 / 63 95 配置 56 / 60 93 +3.9
定性的結果(実機):成功例 - 17 - 4x ▪ 指示文:”Put the red chips
can on the white table with the soccer ball on it.” 対象物体 / 対象物体候補 配置目標 / 配置目標候補 ☺ 言語理解,把持, および配置の一連動作を正確に実行
まとめ - 18 - ▪ 背景 ✓ 生活支援ロボットに対して 自然言語で指示できると便利 ▪
提案 ✓ Switching head-tail機構の導入により, 単一モデルで対象物体および配置目標 を個別に予測 ▪ 結果 ✓ シミュレーション環境・実機環境において, ベースライン手法を言語理解精度で上回った ✓ 言語理解と把持・配置動作実行を統合可能 4x
Appendix
関連タスク - 20 - ▪ Referring Expression Comprehension ▪ Referring
Expression Segmentation ▪ Visual Question Answering ▪ Embodied Question Answering ▪ Vision-and-Language Navigation ▪ Object Goal Navigation ▪ Embodied Instruction Following ▪ Multimodal Language Understanding for Fetching Instructions
Funnel Transformer [Dai+, NeurIPS20] - 21 - ▪ transformer [Vaswani+,
NeurIPS17] の計算コストを削減 ▪ シーケンスの長さを徐々に圧縮
ALFRED-fcに関する統計情報 - 22 - サンプル数(訓練:検証:テスト) 画像 指示文 語彙サイズ 平均文長 5748
(4420 : 642 : 686) 1099 3452 646 8.4
ハイパーパラメータ設定 - 23 - 最適化関数 Adam (𝛽1 = 0.9, 𝛽2
= 0.999) 学習率 8 × 10−5 ステップ数 20000 バッチサイズ 8 ドロップアウト 0.1 タスクの重み係数 𝜆targ = 1.0, 𝜆dest = 1.0
Ablation条件 - 24 - ▪ W/o Switching head機構 ▪ 各モードで𝒙targ
と𝒙dest を同一の値にする ▪ W/o Switching tail機構 ▪ 単一モデルで対象物体および配置目標に関するシングルタスク学習 𝒙targ , 𝒙dest = ቊ (𝒙targ , 𝒙targ ) if target mode (𝒙dest , 𝒙dest ) if destination mode
混同行列:ALFRED-fc - 25 - 予測ラベル Positive Negative 正解ラベル Positive 453
233 Negative 24 662
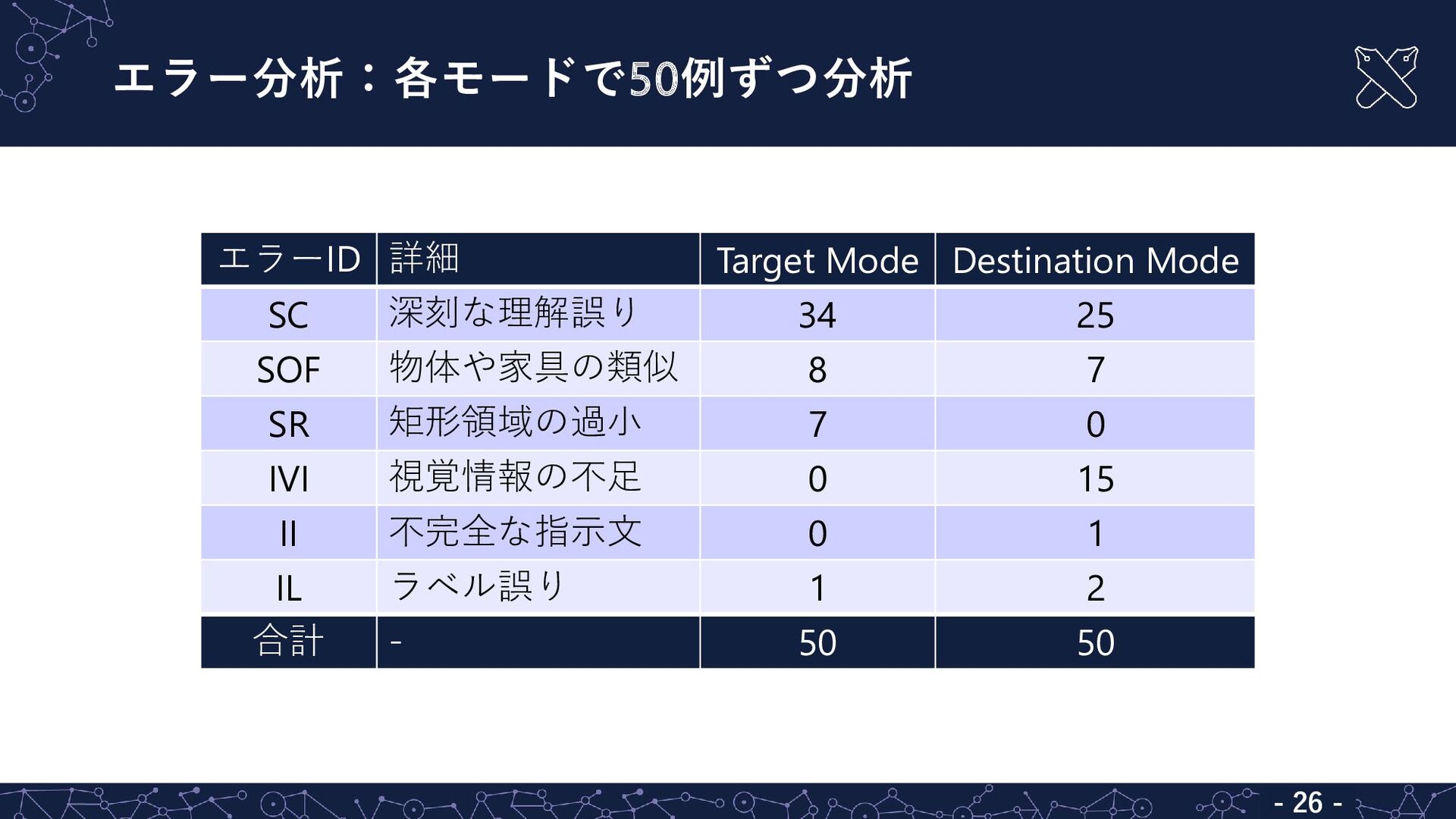
エラー分析:各モードで50例ずつ分析 - 26 - エラーID 詳細 Target Mode Destination Mode
SC 深刻な理解誤り 34 25 SOF 物体や家具の類似 8 7 SR 矩形領域の過小 7 0 IVI 視覚情報の不足 0 15 II 不完全な指示文 0 1 IL ラベル誤り 1 2 合計 - 50 50
実機:Human Support Robot [Yamamoto+, ROBOMECH J.19] - 27 - https://global.toyota/jp/download/8725215
▪ HSR:トヨタ自動車製の生活支援ロボット ▪ 頭部搭載のAsus Xtion Proカメラを使用
定性的結果(実機):把持・配置動作における失敗例 - 28 - ▪ 把持失敗例 ▪ 配置失敗例 点群が前面に集中
1.5x 柔らかい素材の家具は不安定 1.5x
{kind=link}
![背景:生活支援ロボットに自然言語で指示できると便利 - 2 - World Robot Summit (WRS) [Okada+, AR19]](https://files.speakerdeck.com/presentations/dff7ec3987044fb5a3fe84537d8d4284/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2. Funnel Transformer: self-attentionの後,Switching tail機構によりモードに応じて確率を出力 ▪ Funnel Transformer [Dai+, NeurIPS20]](https://files.speakerdeck.com/presentations/dff7ec3987044fb5a3fe84537d8d4284/slide_8.jpg){kind=link}
![実験設定:”ALFRED-fc” データセットを収集し,性能を評価 ▪ ALFRED [Shridhar+, CVPR20] ▪ 物体操作を含むVision-and-Language Navigationの標準データセット ▪](https://files.speakerdeck.com/presentations/dff7ec3987044fb5a3fe84537d8d4284/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Funnel Transformer [Dai+, NeurIPS20] - 21 - ▪ transformer [Vaswani+,](https://files.speakerdeck.com/presentations/dff7ec3987044fb5a3fe84537d8d4284/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実機:Human Support Robot [Yamamoto+, ROBOMECH J.19] - 27 - https://global.toyota/jp/download/8725215](https://files.speakerdeck.com/presentations/dff7ec3987044fb5a3fe84537d8d4284/slide_26.jpg){kind=link}
{kind=link}