Zhu*, Myong Chol Jung*, Jesse Clark* *marqo.ai WWW2025 慶應義塾大学 杉浦孔明研究室 木暮緋南 Tianyu Zhu, et al. "Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking." Companion Proceedings of the ACM on Web Conference 2025.
クエリ・ドキュメントの生成 ① Amazonの分類ツリーから Fashion / Homewareカテゴリを抽出 ② GPT-4で約12万件の検索クエリを生成 ③ ②のクエリで、Google Shoppingを検索、 ドキュメントを収集 ④ 商品名・画像・ランキング位置を含む ドキュメントを作成 ① ② ③ ④ uランキングスコア • Google Shoppingのランキング位置 を利用 • 𝑠 = 101 − 𝑟𝑎𝑛𝑘
{kind=link}
{kind=link}
![関連研究:既存の対照学習手法はランキング情報を考慮していない 03 分野 手法 概要 対照学習手法 SimCLR [Chen+, PmLR20] データ拡張による画像ペアを利用した対照学習](https://files.speakerdeck.com/presentations/e6f7b73b9ecd4a1e921a90fb2e3944c3/slide_2.jpg){kind=link}
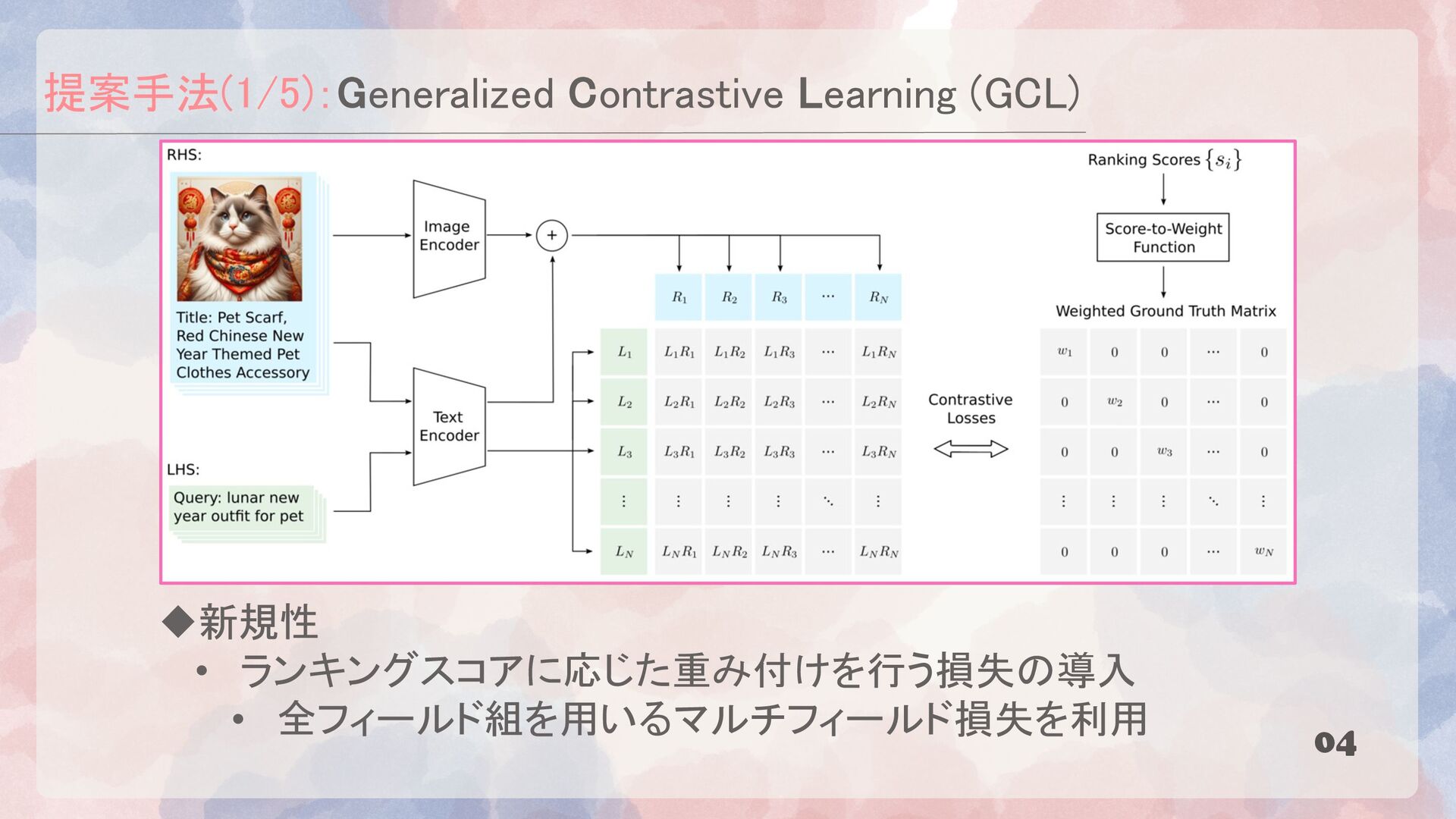{kind=link}
{kind=link}
{kind=link}
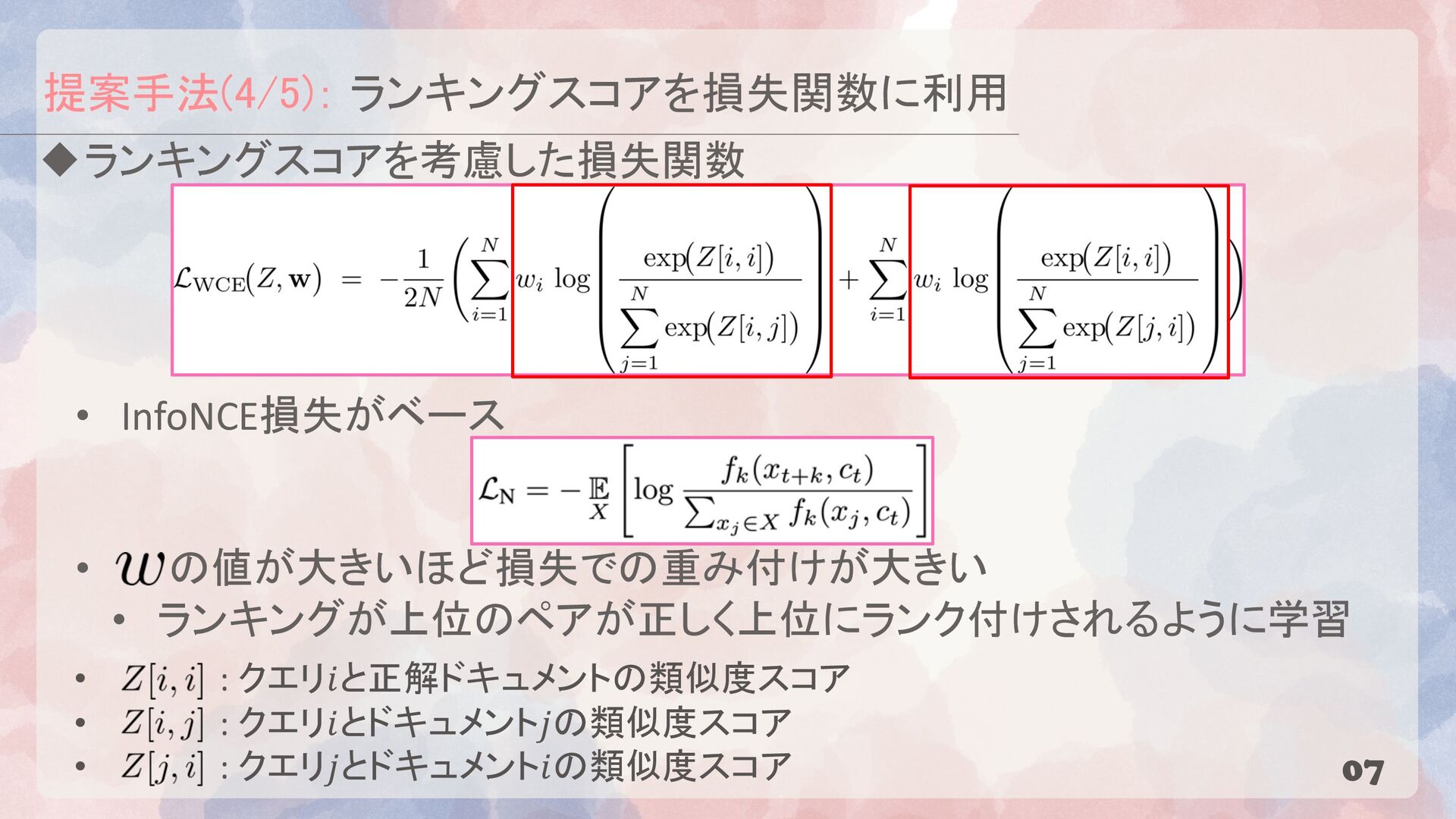{kind=link}
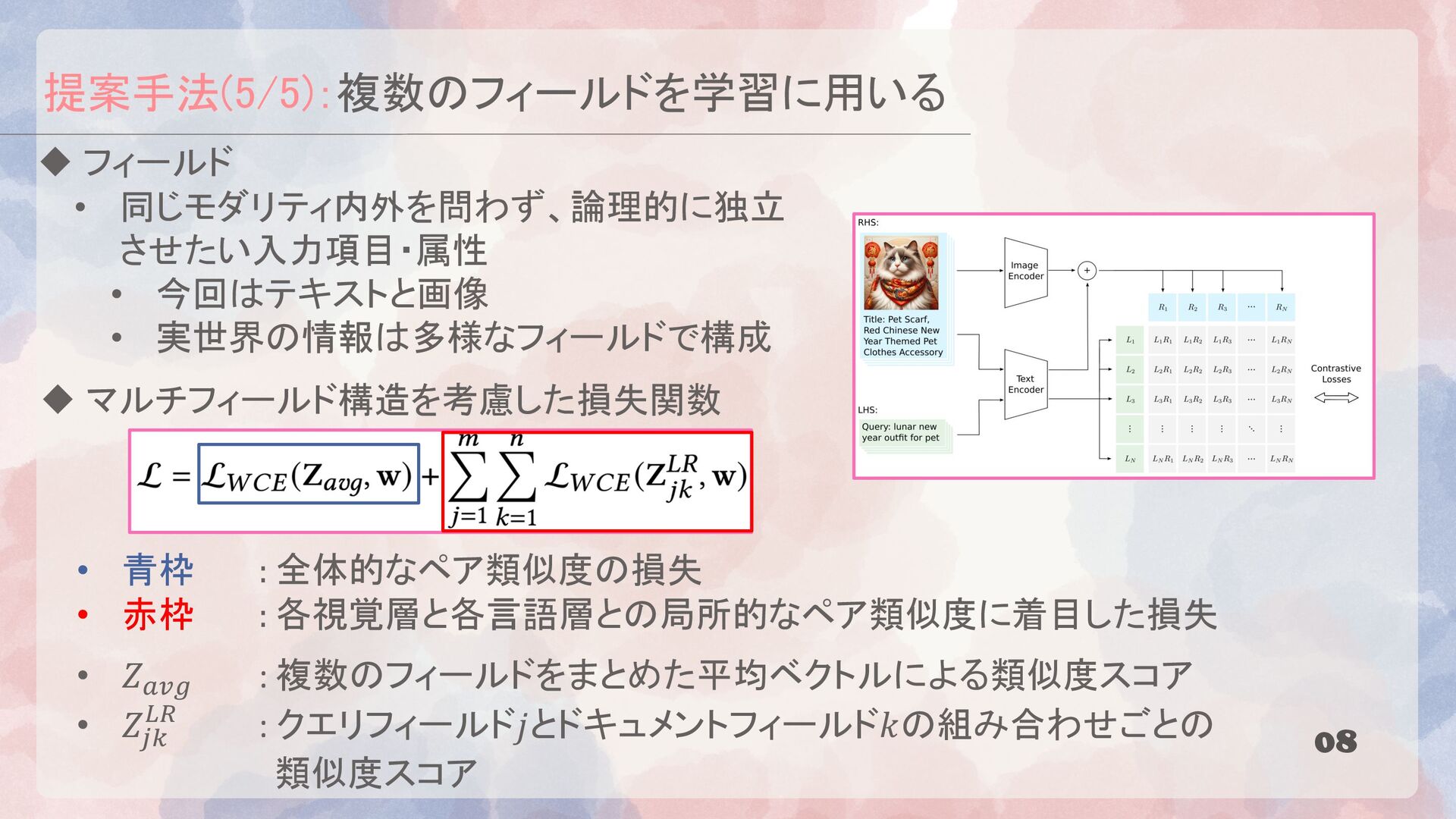{kind=link}
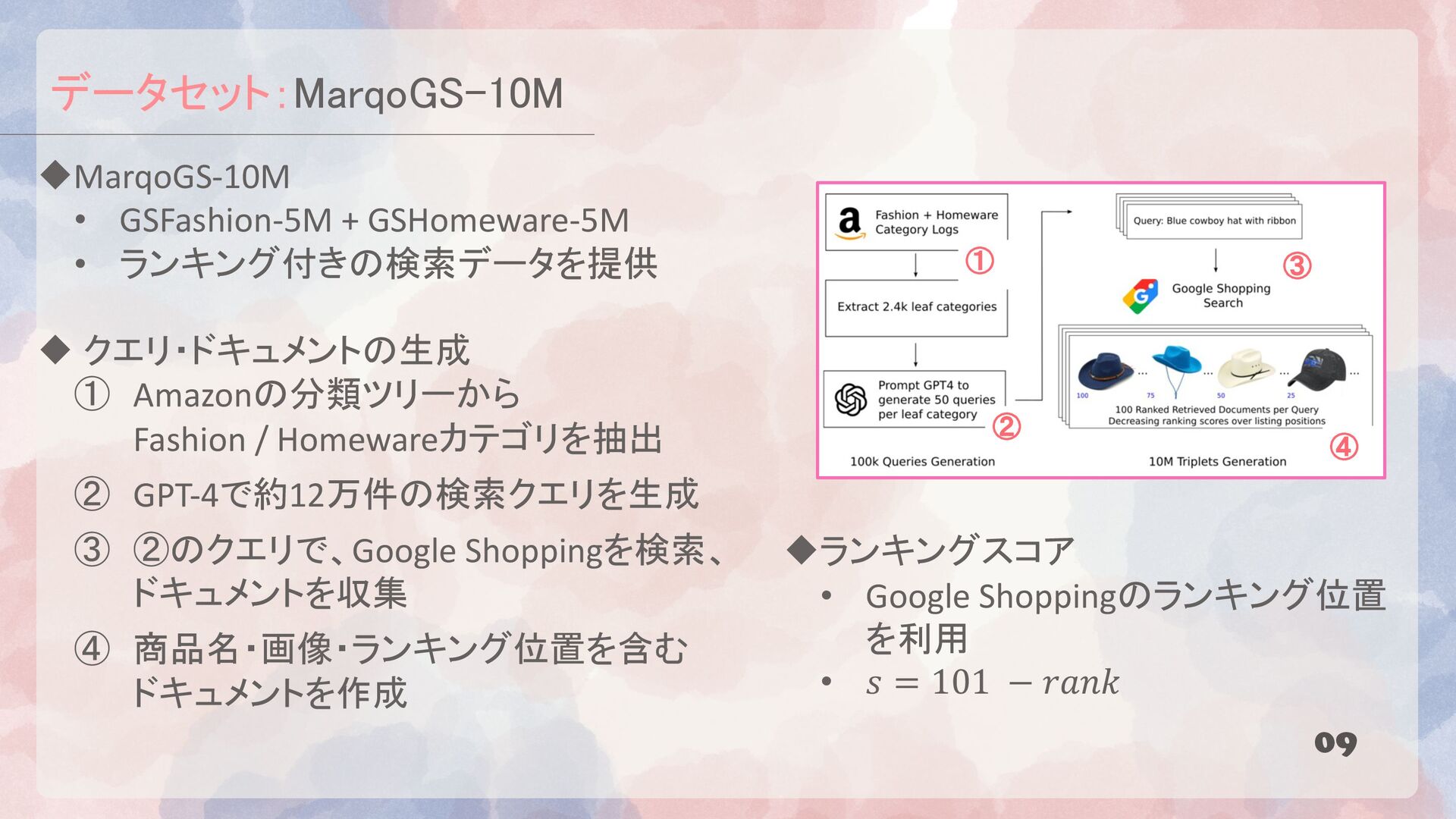{kind=link}
{kind=link}
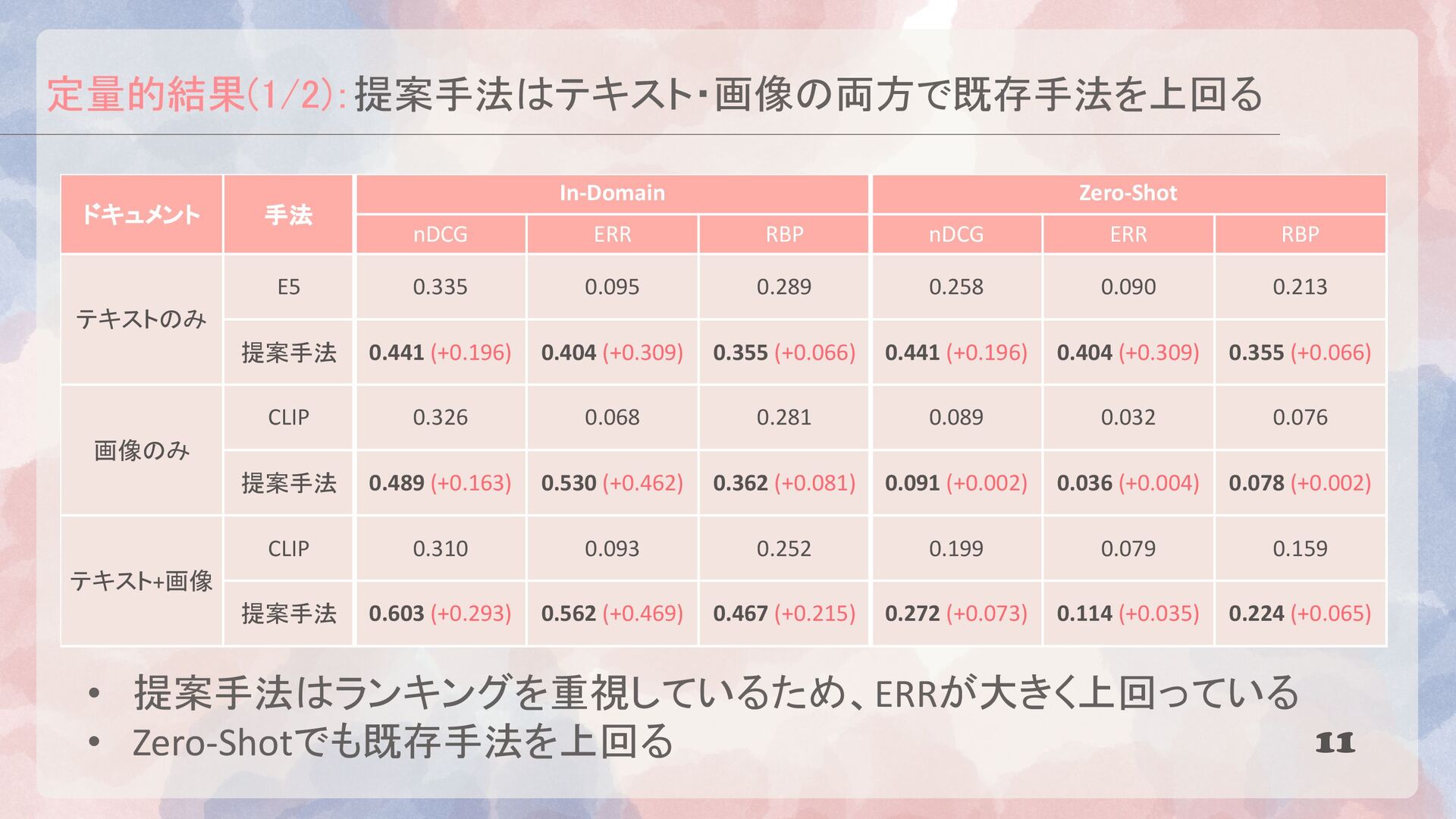{kind=link}
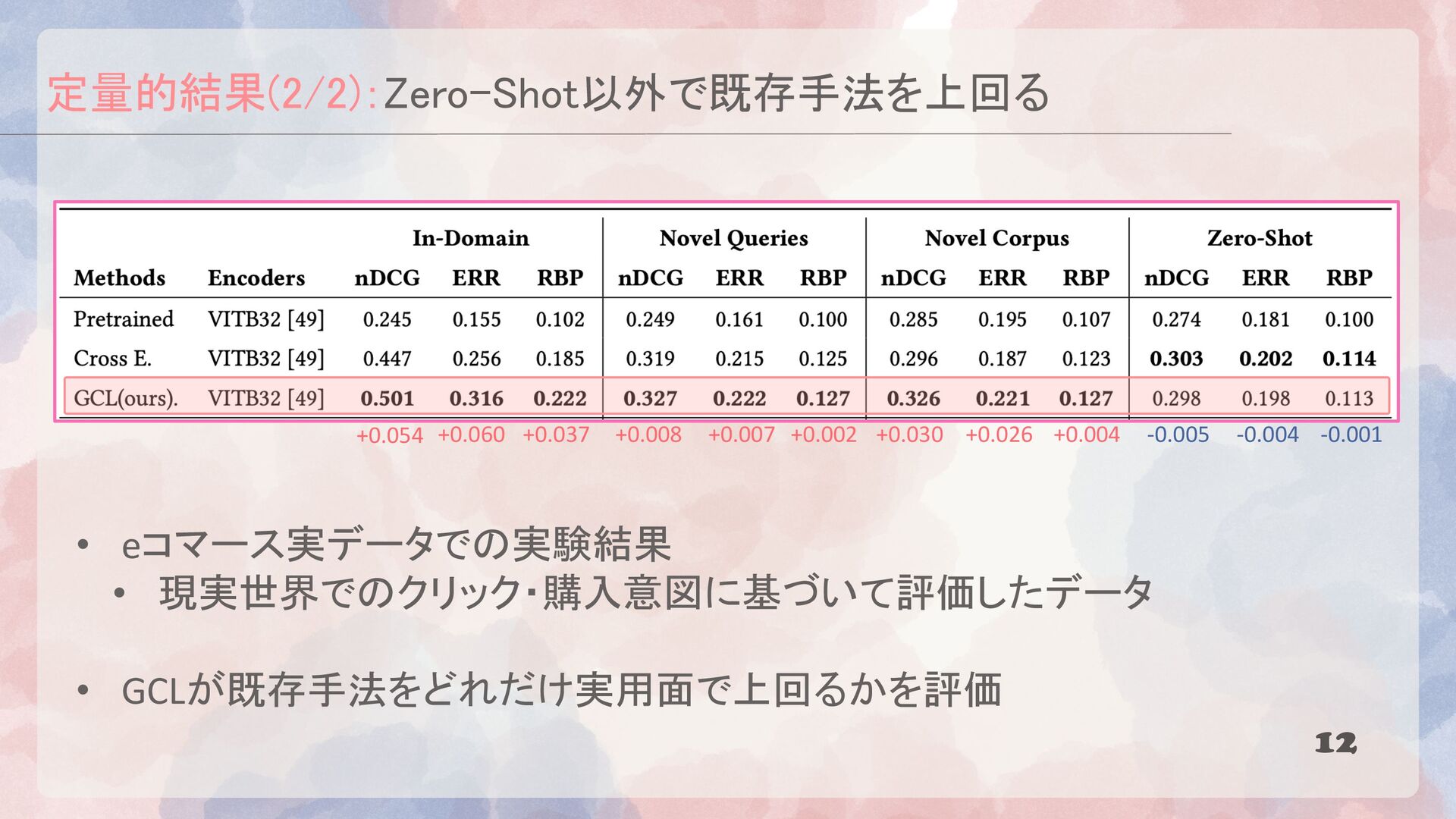{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
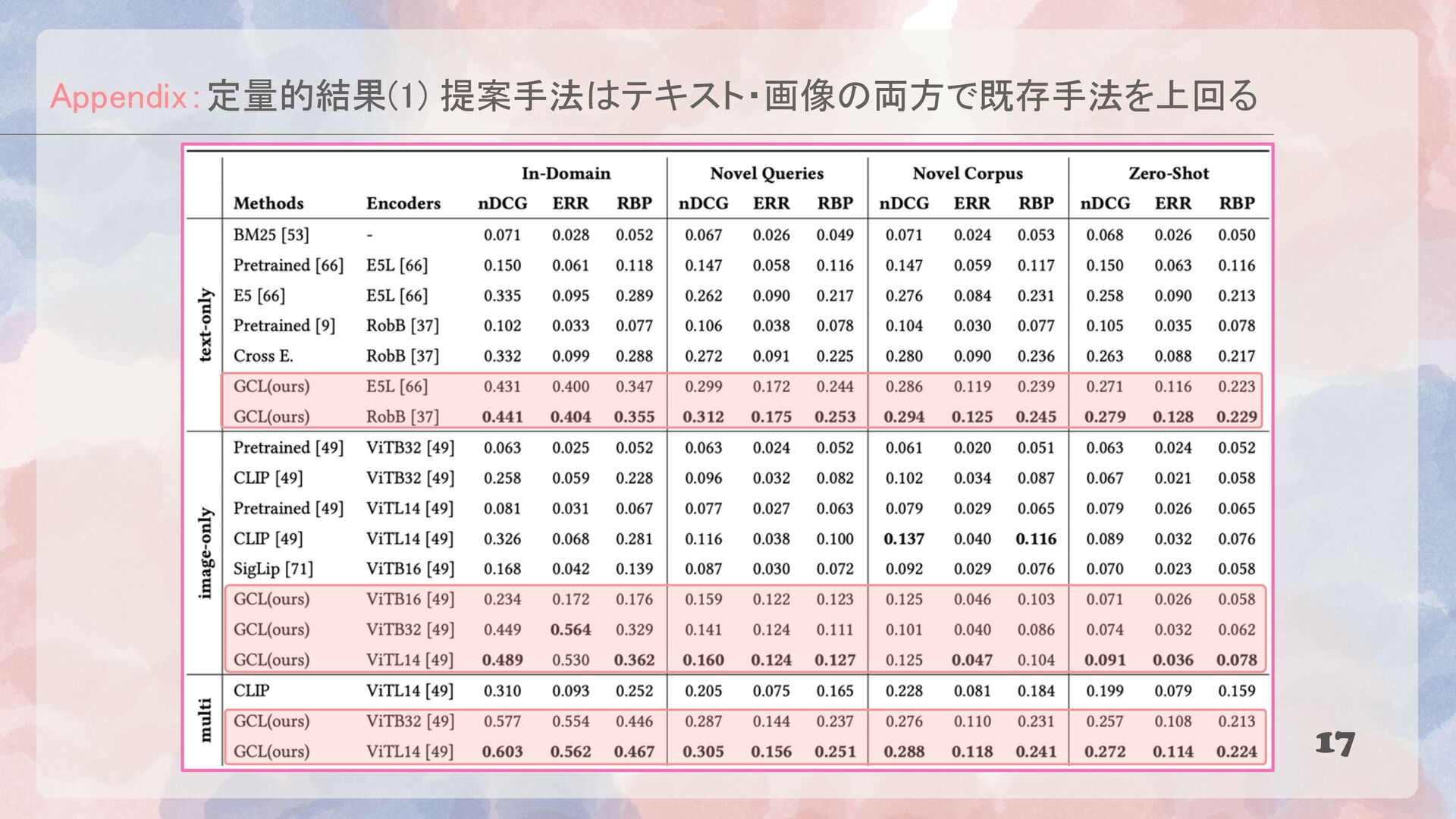{kind=link}
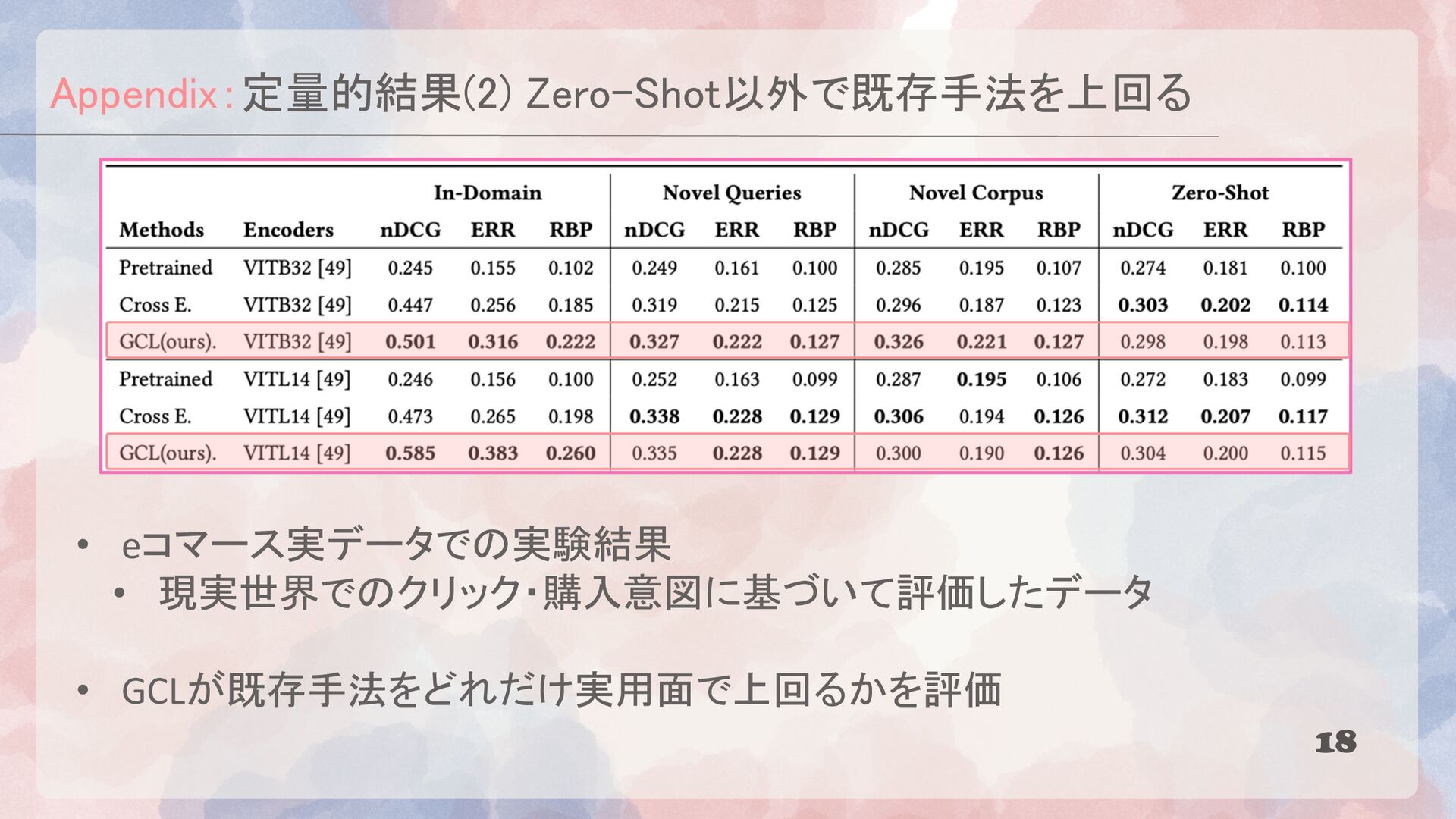{kind=link}
{kind=link}
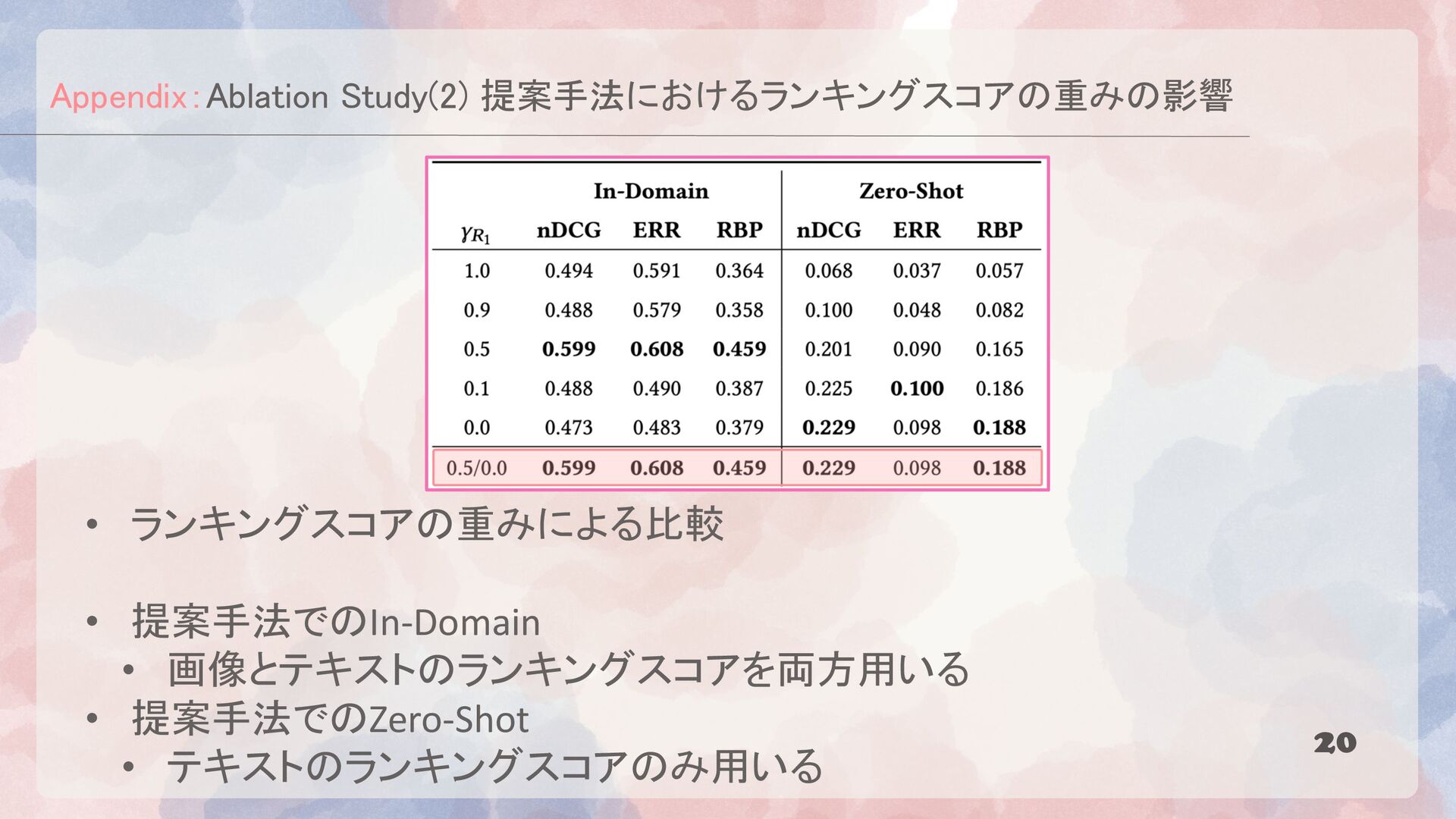{kind=link}
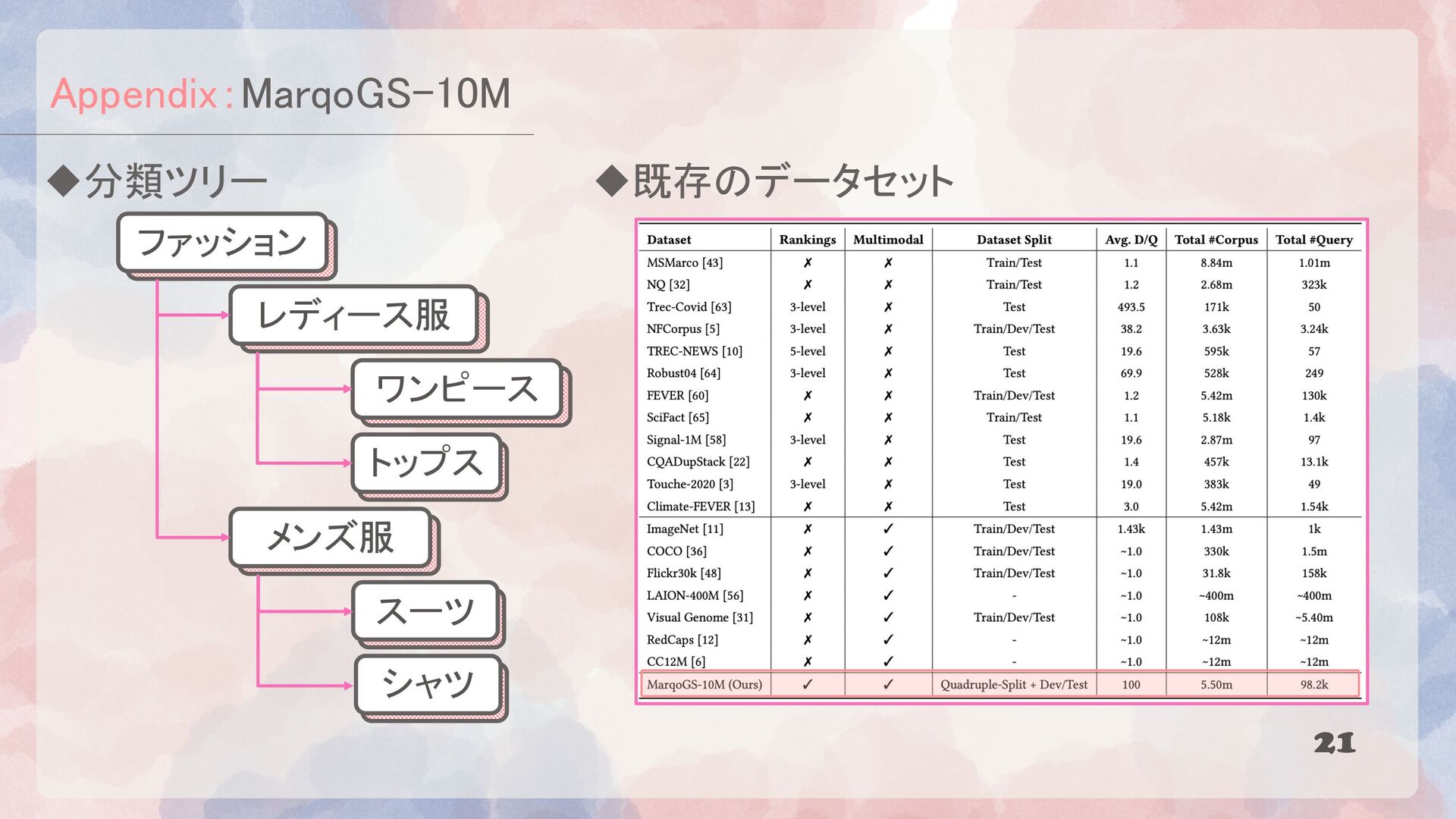{kind=link}
{kind=link}