Park Jongin Lim Younghan Jeon Jin Young Choi ASRI, Dept. of Electrical and Computer Engineering, Seoul National University ICCV 2021 Seulki Park, Jongin Lim, Younghan Jeon, and Jin Young Choi. "Influence-Balanced Loss for Imbalanced Visual Classification." In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
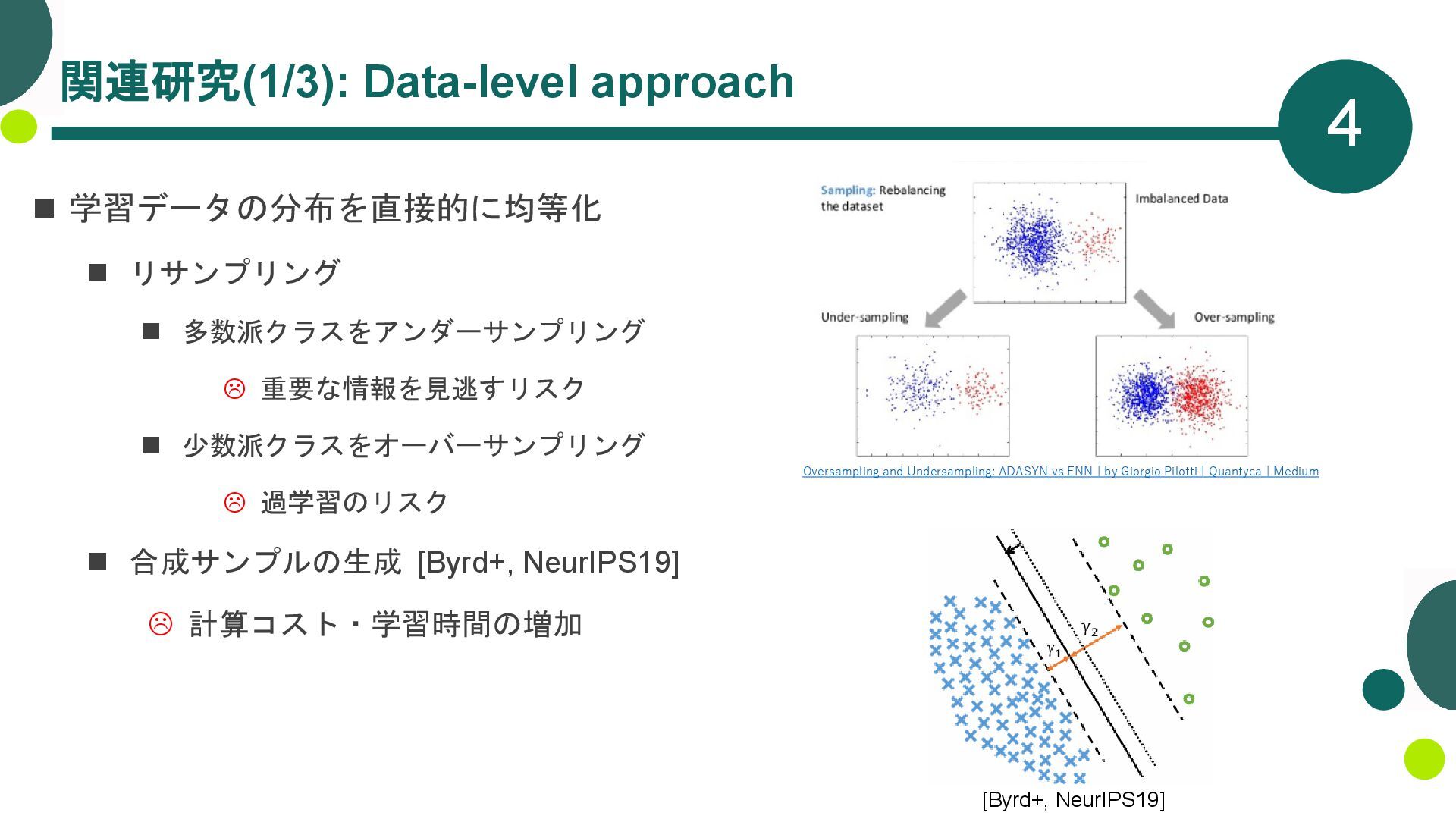
重要な情報を見逃すリスク ◼ 少数派クラスをオーバーサンプリング 過学習のリスク ◼ 合成サンプルの生成 [Byrd+, NeurIPS19] 計算コスト・学習時間の増加 Oversampling and Undersampling: ADASYN vs ENN | by Giorgio Pilotti | Quantyca | Medium [Byrd+, NeurIPS19]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![6 関連研究(3/3): Meta-learning approach ◼ 学習過程自体そのものを学習する ◼ 重み関数のメタ最適化 [Shu+, NeurIPS19]](https://files.speakerdeck.com/presentations/8f7793ecd79f4b178993338a0e71bed3/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
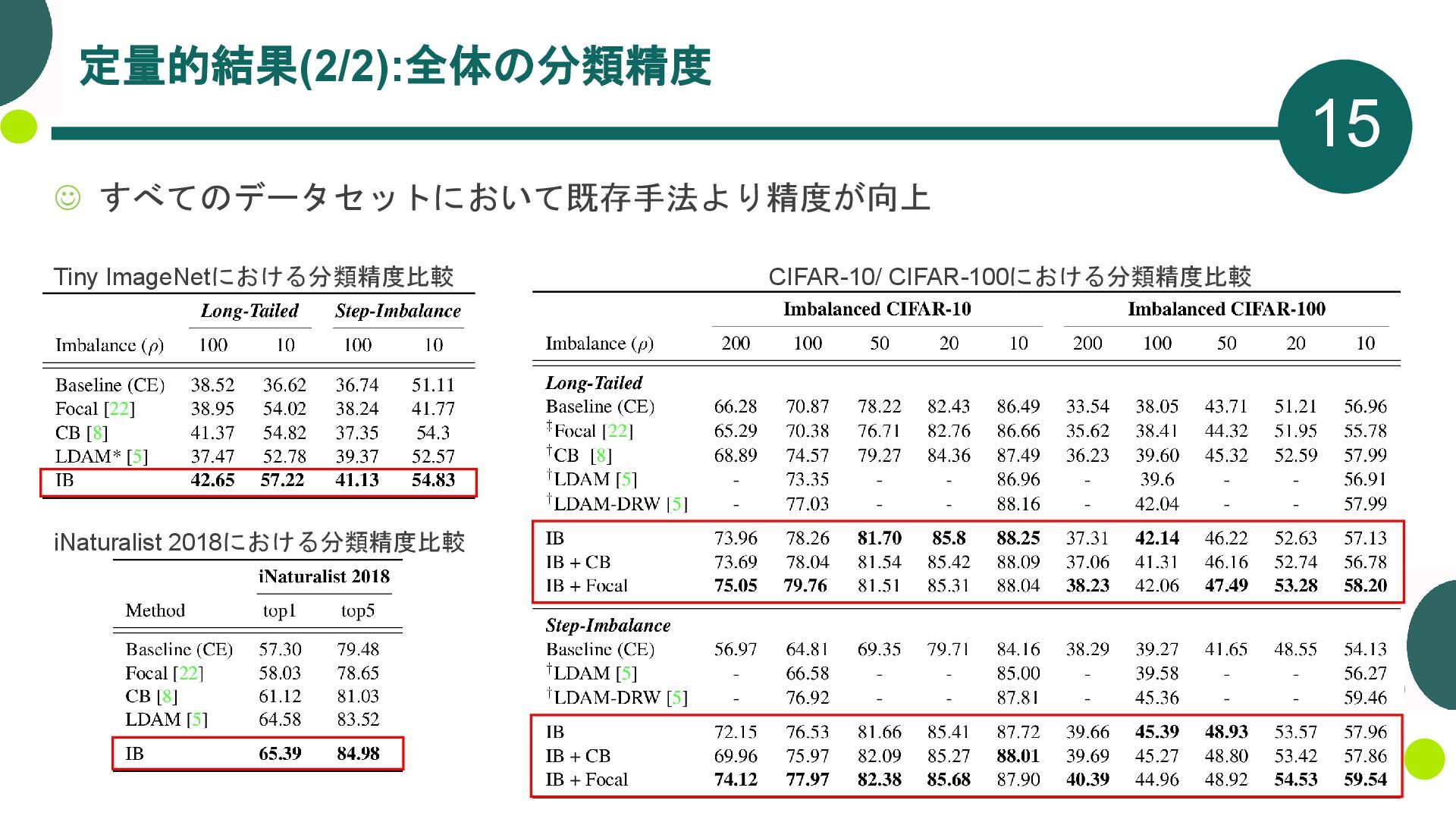{kind=link}
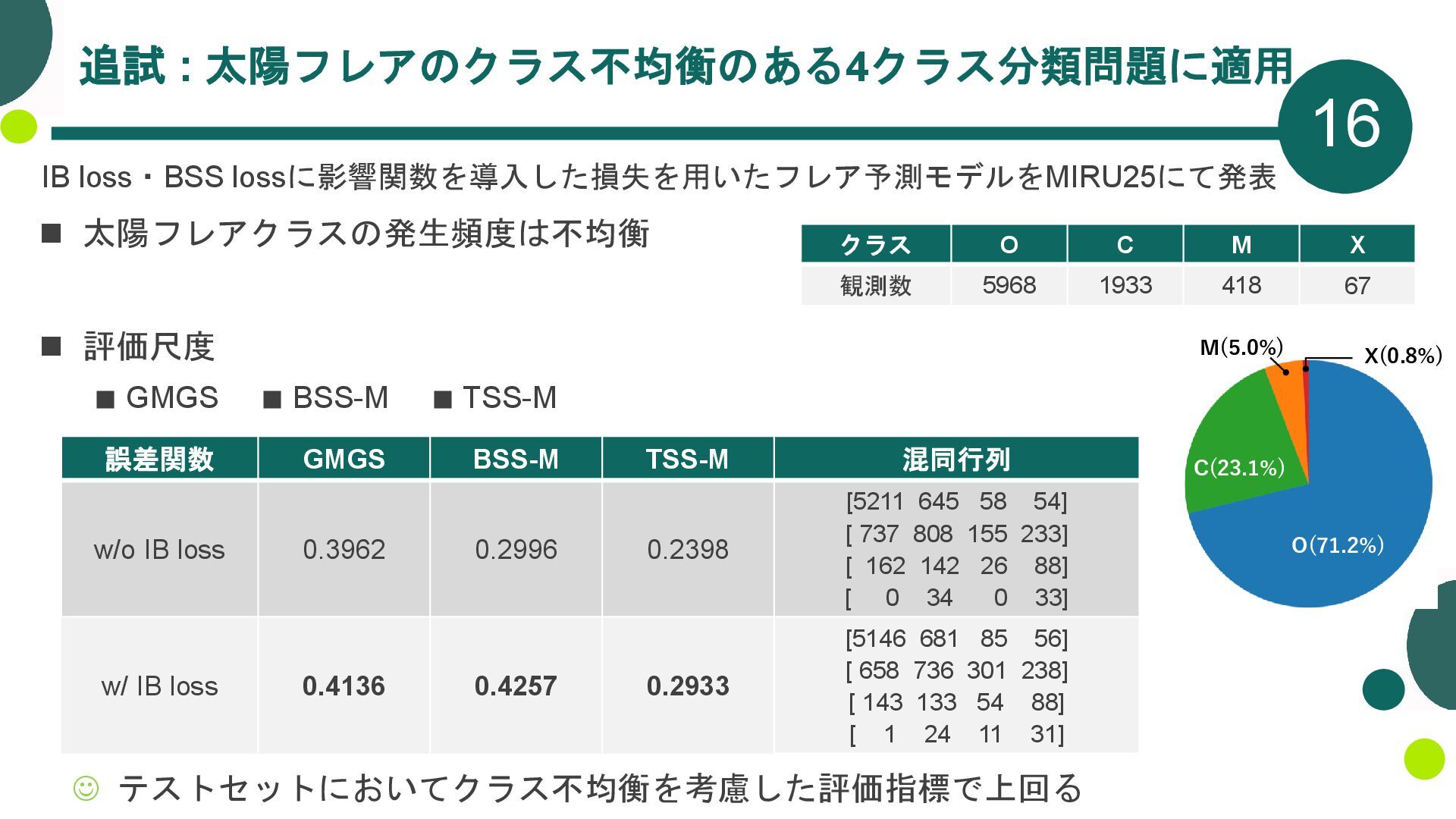{kind=link}
{kind=link}
{kind=link}
{kind=link}