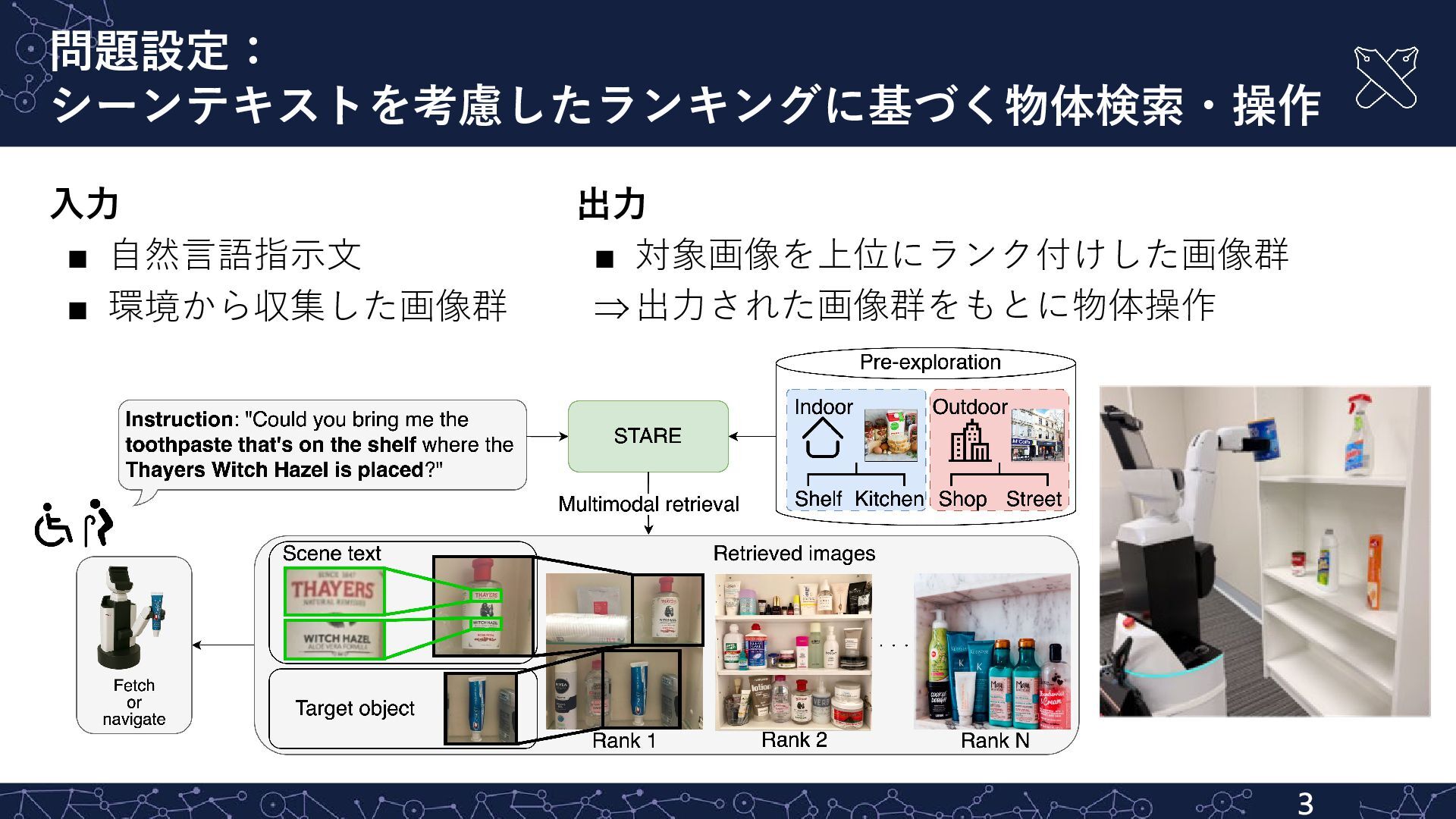
公共空間での物体検索 ▪ 例:ショッピングモール ▪ シーンテキストの利用により,物体を明確に指定可能 ×10 “Can you pass me the remote control next to the towel?” ×10 “Move the coke.” ×8 画像内の物体に記載された文字情報 ▪ Banana Nut Crunch, Post, Selects, …
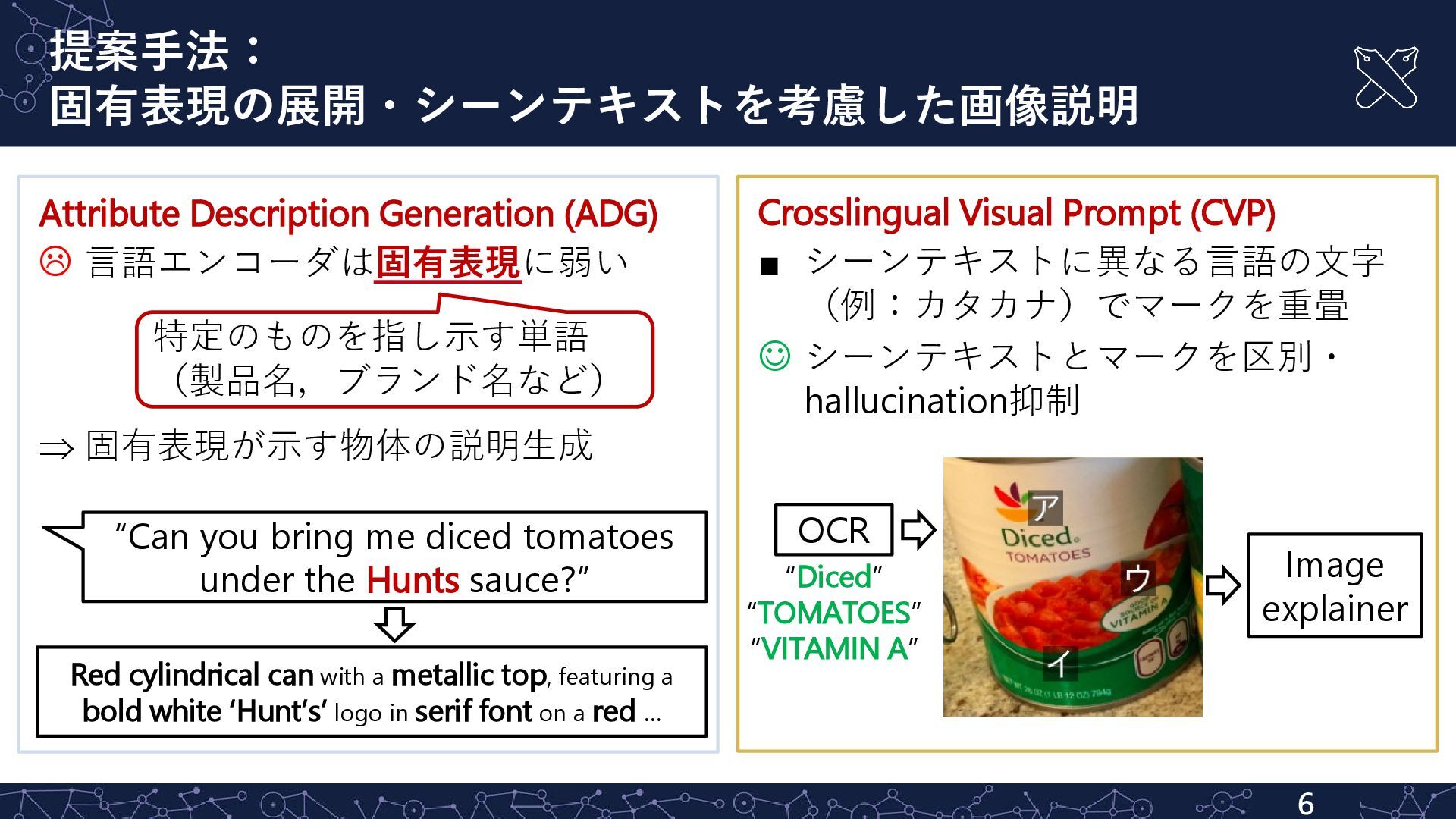
固有表現が示す物体の説明生成 Crosslingual Visual Prompt (CVP) ▪ シーンテキストに異なる言語の文字 (例:カタカナ)でマークを重畳 シーンテキストとマークを区別・ hallucination抑制 Image explainer OCR “Diced” “TOMATOES” “VITAMIN A” “Can you bring me diced tomatoes under the Hunts sauce?” Red cylindrical can with a metallic top, featuring a bold white ‘Hunt’s’ logo in serif font on a red … 特定のものを指し示す単語 (製品名,ブランド名など)
“Vanilla Soymilk” ⇒ シーンテキストを含むデータセットに動作を記述した自然言語指示文を付与 “Grab the bottle "DAWN" on the bottom-left corner. There is yellow rubber glove to the right of it.” “Please grab the jar of kimchi that is on the top shelf, second from the left.”
{kind=link}
![背景:自然言語指示による実世界での物体検索・操作 2 自然言語指示を扱うロボティクス手法 ▪ π0 ,[Goko+, CoRL24] ▪ 生活支援ロボットによる物体操作 ▪](https://files.speakerdeck.com/presentations/c3c8b450f7094d1cb35e77b582e87774/slide_1.jpg){kind=link}
{kind=link}
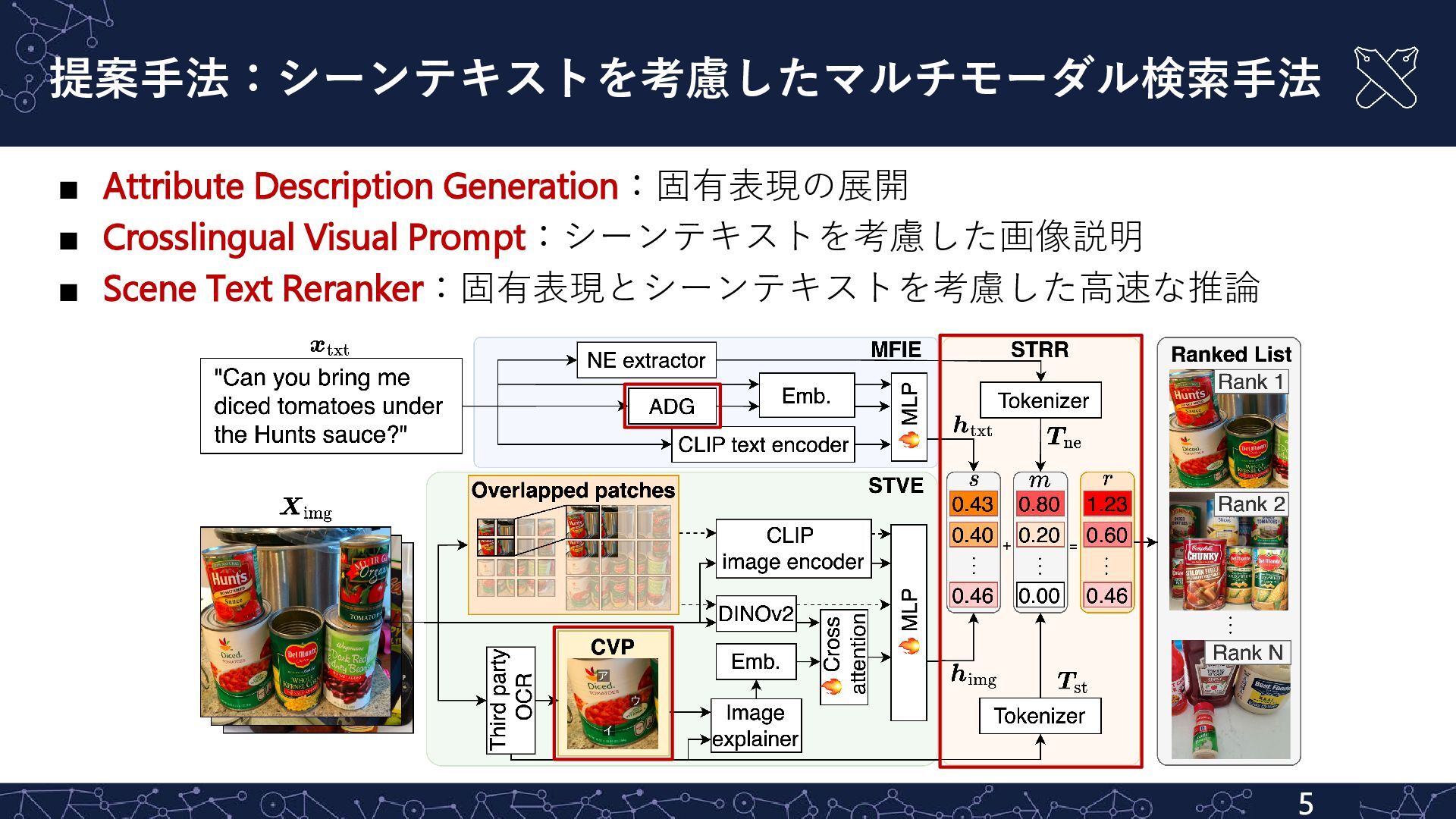
![関連研究:シーンテキストの活用が不十分 4 手法 概要 CLIP [Radford+, ICML21] BEiT-3 [Wang+, CVPR23]](https://files.speakerdeck.com/presentations/c3c8b450f7094d1cb35e77b582e87774/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量的結果: シーンテキストの有無を問わずベースライン手法を上回った [%] 手法 GoGetIt (RefText) GoGetIt (Instruction) TextCaps-test LTRRIE](https://files.speakerdeck.com/presentations/c3c8b450f7094d1cb35e77b582e87774/slide_8.jpg){kind=link}
{kind=link}
![実機実験-設定:物体検索・操作へのゼロショット転移 11 ▪ 物体:YCB [Calli+, RAM15] (10種類)+ラベル付き日常物体(13種類) ▪ 試行回数:100エピソード ▪](https://files.speakerdeck.com/presentations/c3c8b450f7094d1cb35e77b582e87774/slide_10.jpg){kind=link}
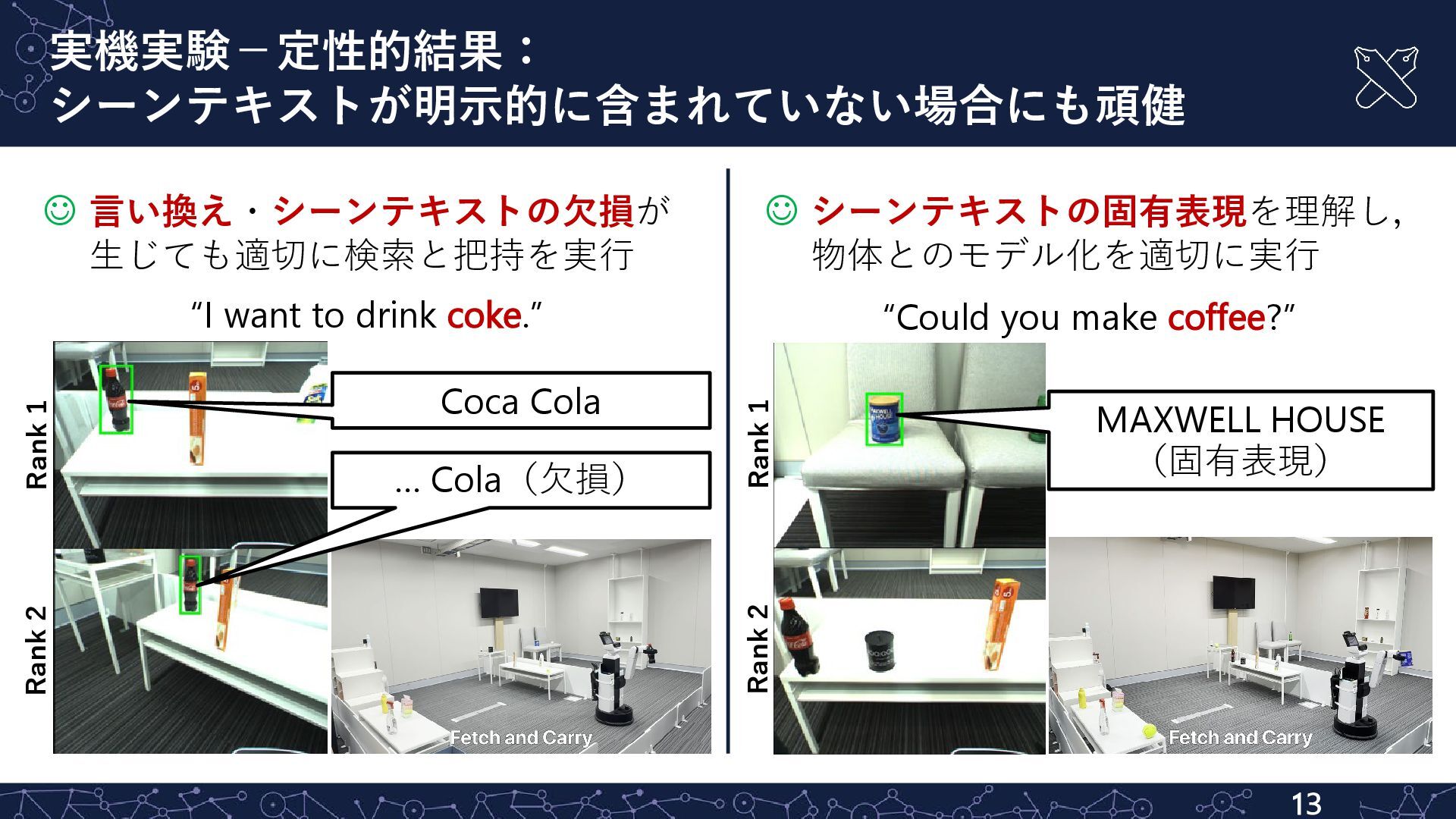
![実機実験-定量・定性的結果: ベースライン⼿法を上回るゼロショット転移性能 手法 [%] R@5↑ SR↑ 提案手法 88 80 CLIP](https://files.speakerdeck.com/presentations/c3c8b450f7094d1cb35e77b582e87774/slide_11.jpg){kind=link}
{kind=link}
{kind=link}