2Carnegie Mellon University Steering Your Generalists: Improving Robotic Foundation Models via Value Guidance 杉浦孔明研究室 妹尾 幸樹 CoRL24 Nakamoto, M., Mees, O., Kumar, A., & Levine, S. “Steering Your Generalists: Improving Robotic Foundation Models via Value Guidance”. In 8th Annual Conference on Robot Learning, 2024.
{kind=link}
{kind=link}
{kind=link}
![関連研究︓価値関数に基づく⾏動選択はVLAモデルで未活⽤ 4 ⼿法 特徴 Cobbe et al. [Cobbe+, 21] 数学の問題に対してVerifierモデルを学習し、LLMからの複数の出⼒](https://files.speakerdeck.com/presentations/09e2d57ad37748d3817b08ac78733402/slide_3.jpg){kind=link}
{kind=link}
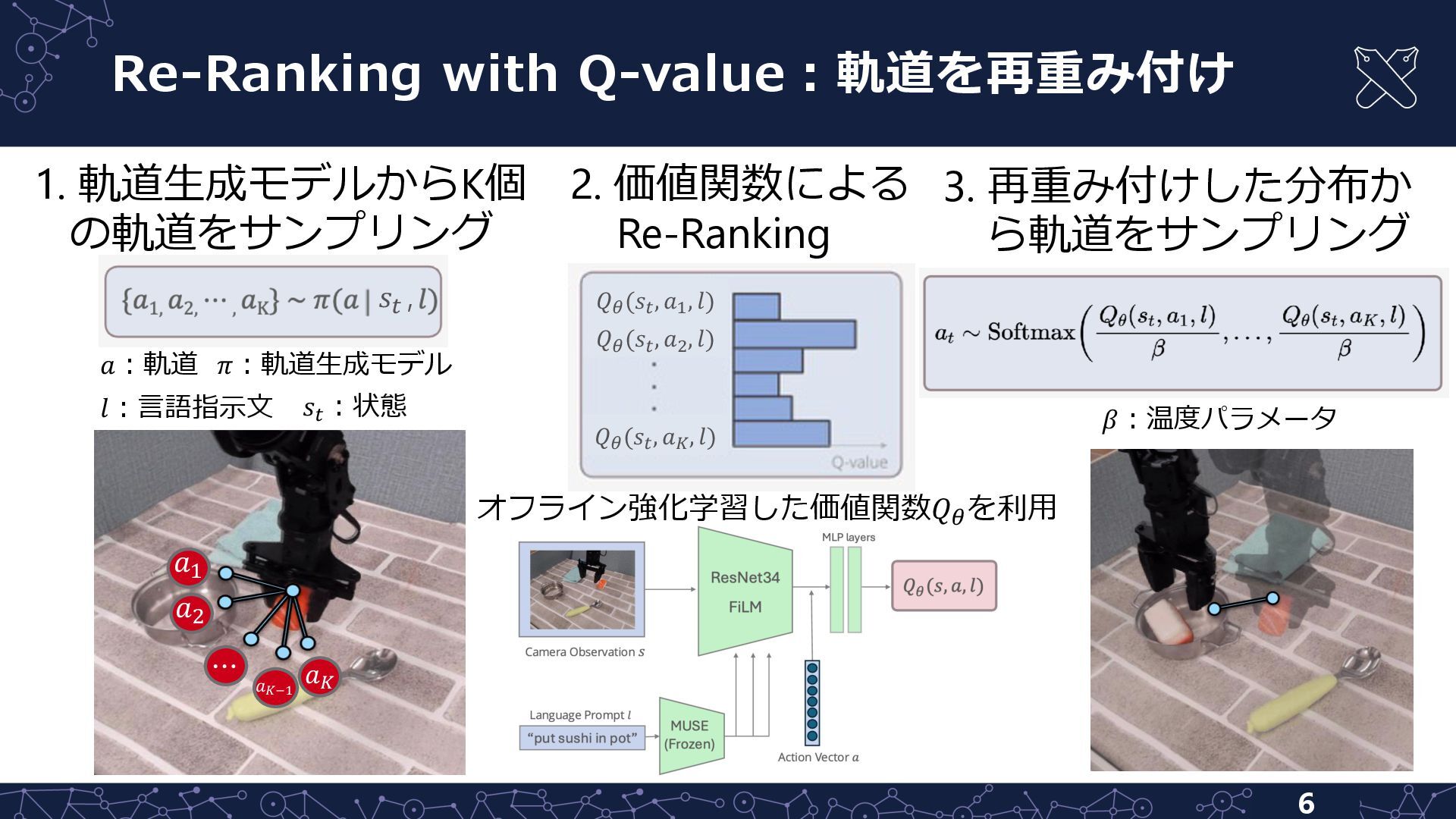{kind=link}
![損失関数 7 ▪ 強化学習⼿法としてCal-QL [Nakamoto+, NeurIPS23]を採⽤ ▪ 第1項(Calibrated conservative regularizer︓保守的正則化項)](https://files.speakerdeck.com/presentations/09e2d57ad37748d3817b08ac78733402/slide_6.jpg){kind=link}
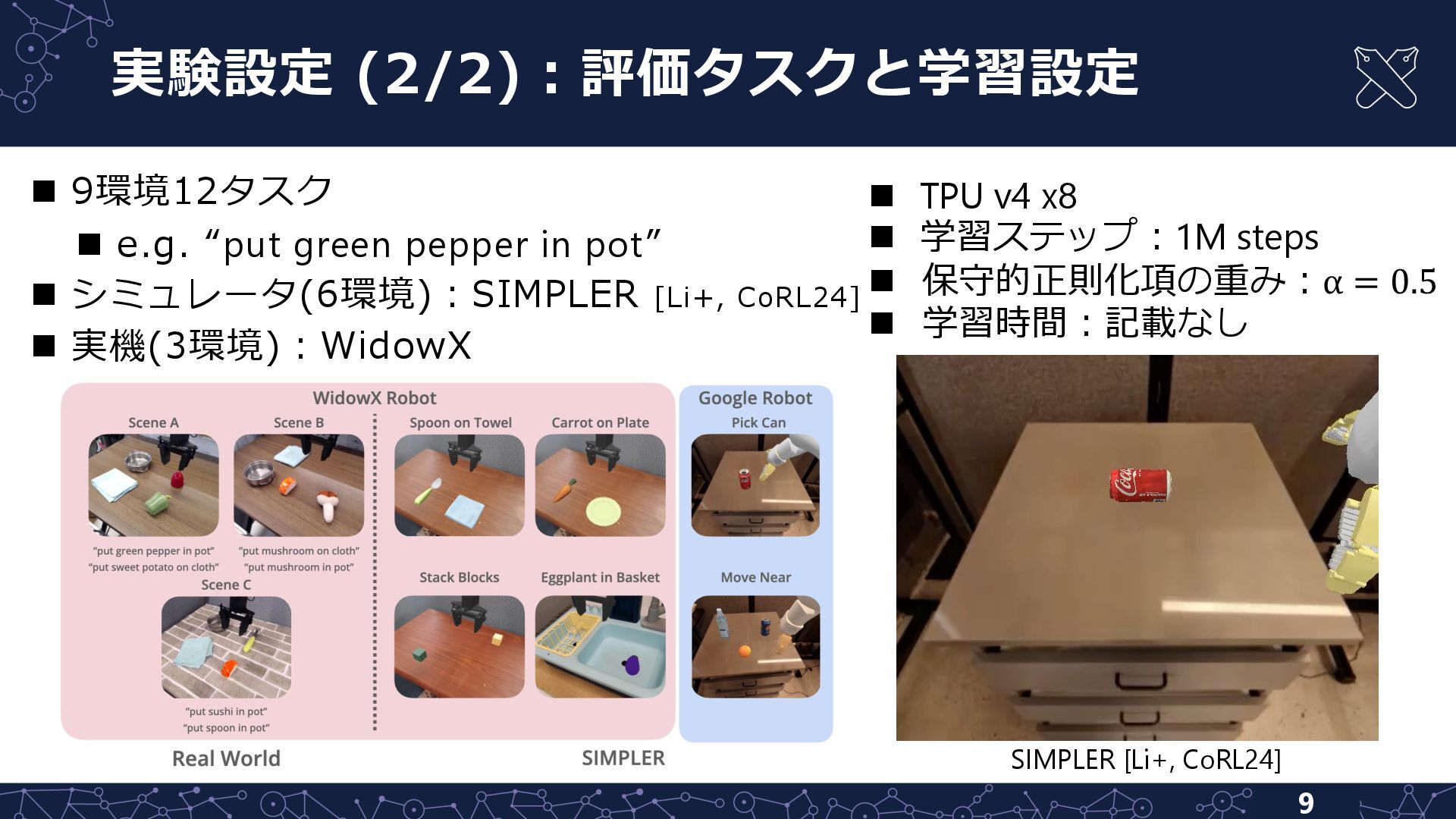
![実験設定 (1/2)︓訓練データセット 8 Fractal [Brohan, RSS23] n Google Robot n](https://files.speakerdeck.com/presentations/09e2d57ad37748d3817b08ac78733402/slide_7.jpg){kind=link}
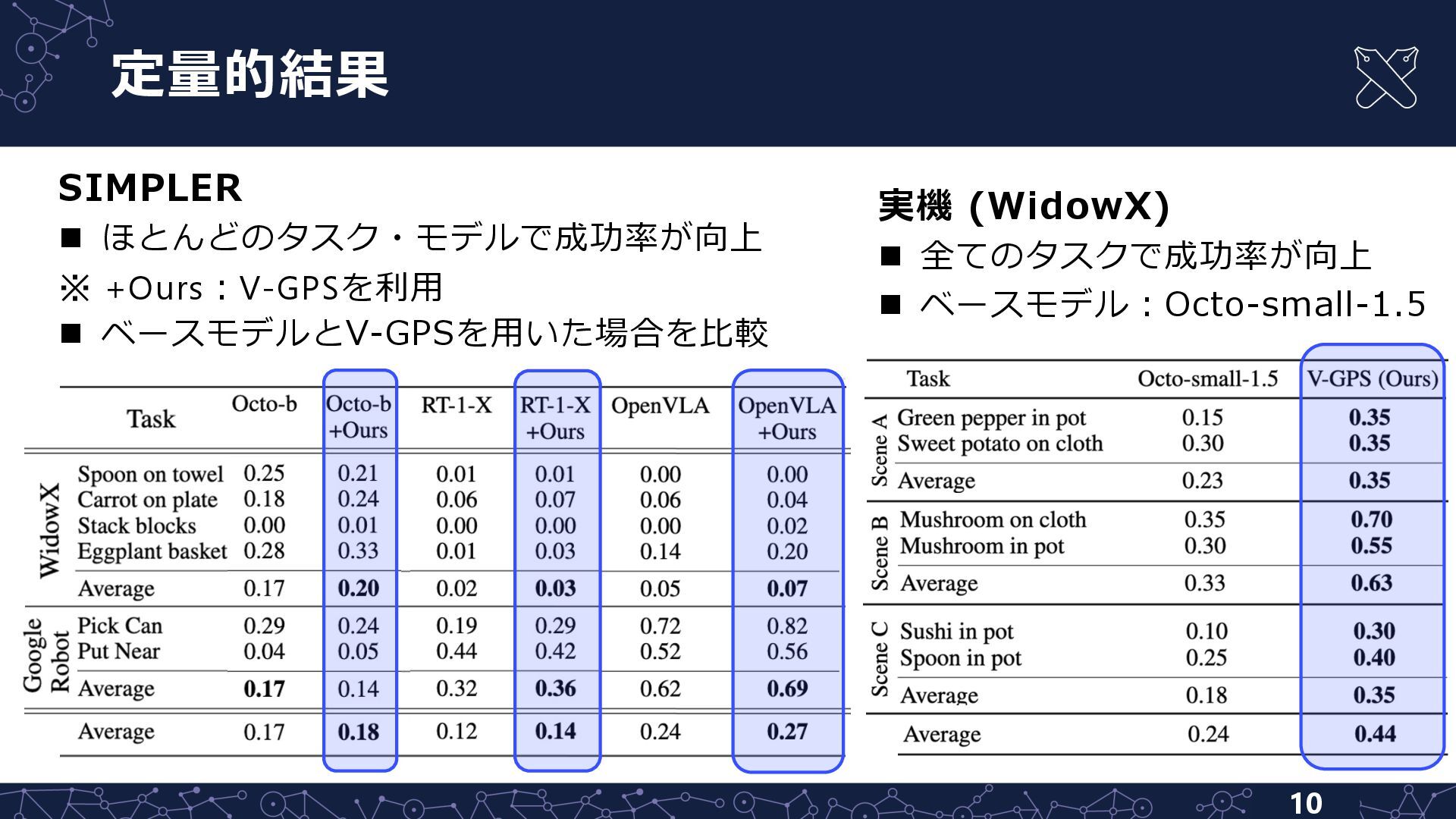
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
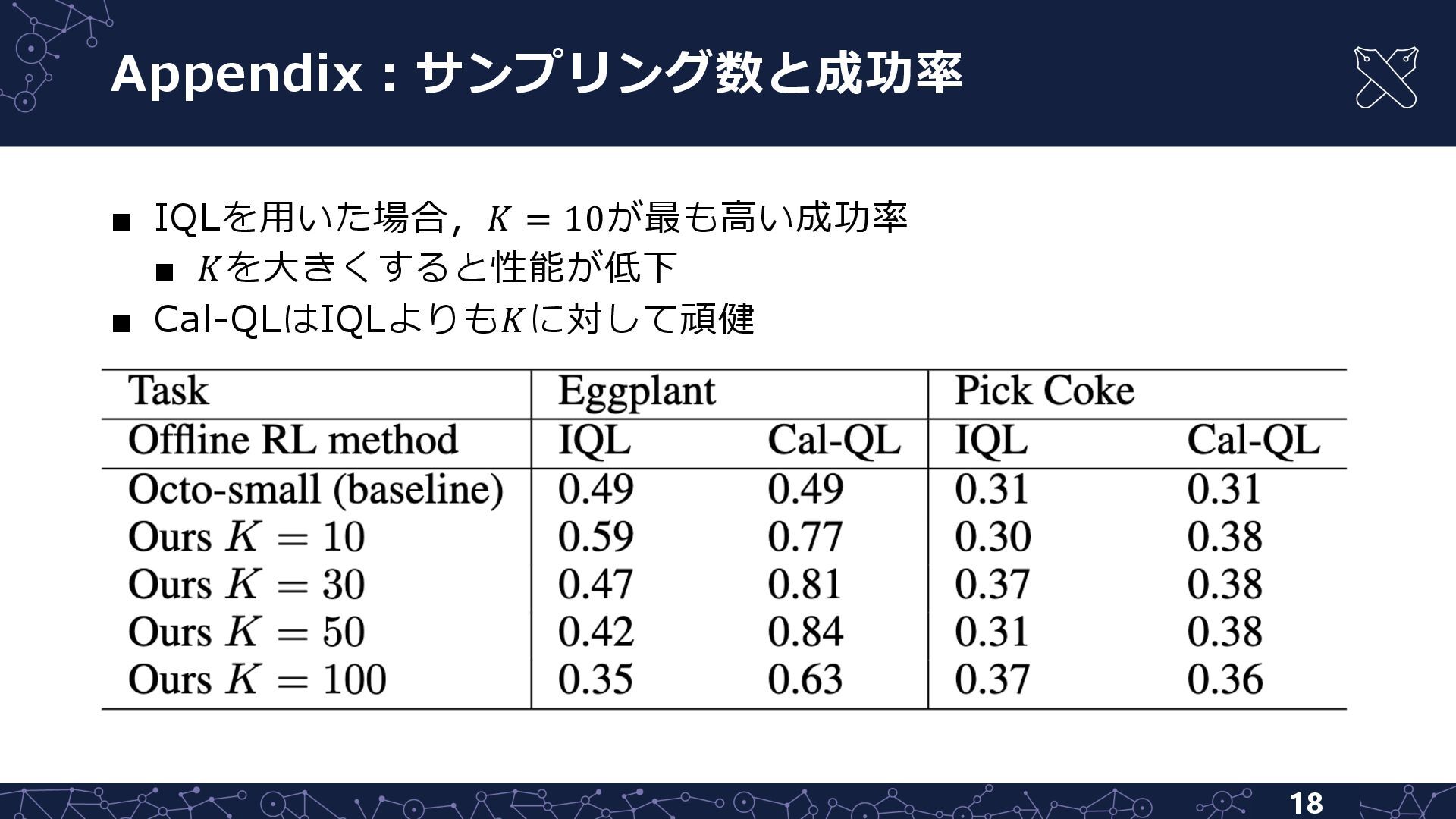
![Appendix︓あらゆるオフライン強化学習⼿法を使⽤可能 14 IQL [Kostrikov, NeurIPS21]を使⽤した場合もベースモデルの成功率が向上 𝑠︓状態 𝒟︓データセット 𝑄$ % ︓遅延したQ関数](https://files.speakerdeck.com/presentations/09e2d57ad37748d3817b08ac78733402/slide_13.jpg){kind=link}
![Appendix︓fine-tuningよりも効果的 15 ▪ ⼤規模VLAモデルのfine-tuningは困難 L closed-source (e.g. RT-1 [Brohan, RSS23]は⼀部のみ公開)](https://files.speakerdeck.com/presentations/09e2d57ad37748d3817b08ac78733402/slide_14.jpg){kind=link}
{kind=link}
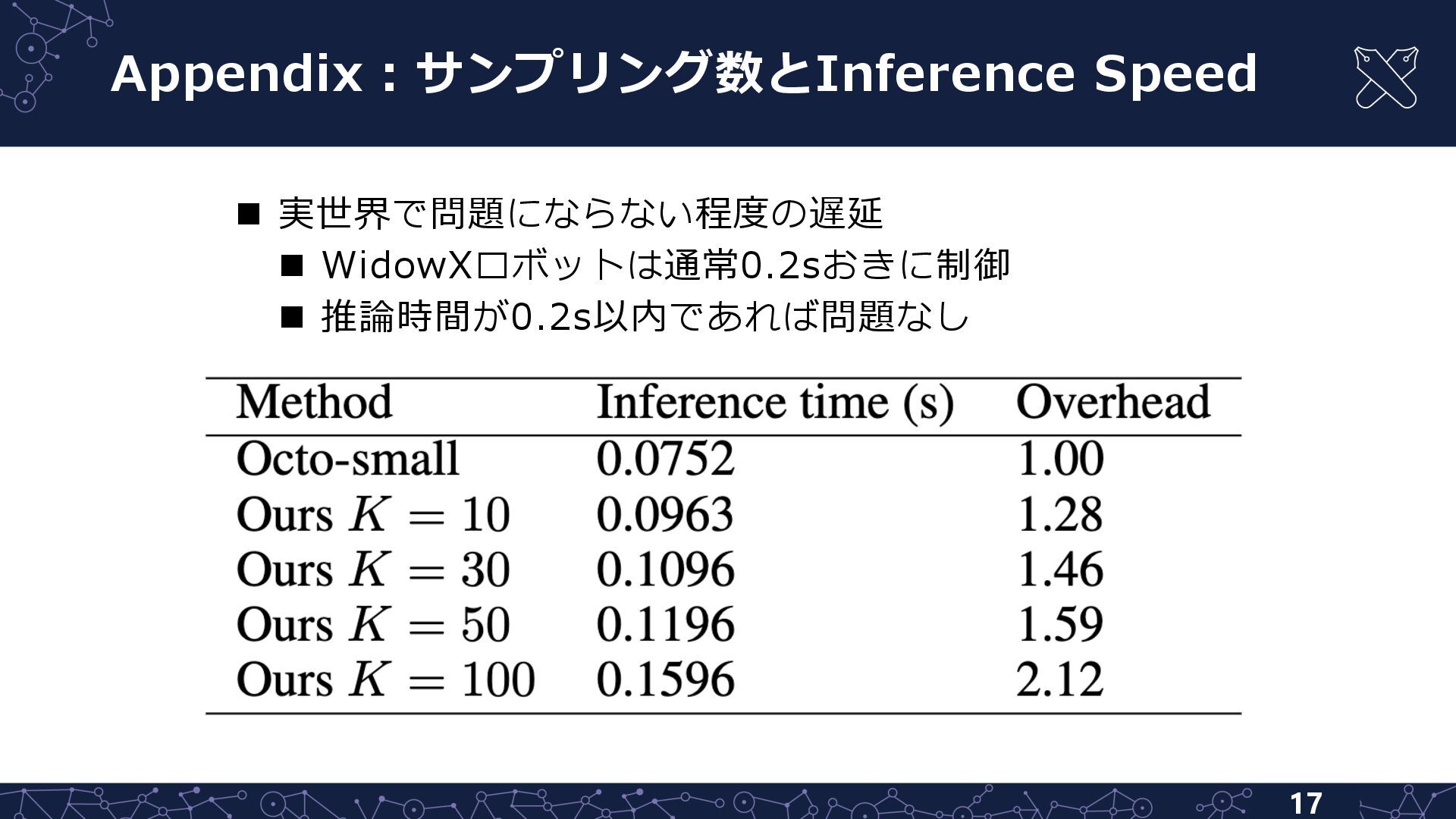{kind=link}
{kind=link}