Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[RSJ25] Multilingual Scene Text-Aware Multimoda...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 01, 2025
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[RSJ25] Multilingual Scene Text-Aware Multimodal Retrieval for Everyday Objects Based on Deep State Space Models
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 01, 2025
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Network Firewallやっていき!
news_it_enj
0
260
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
770
GoでCコンパイラを作った話
repunit
0
150
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
930
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
280
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
620
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
Featured
See All Featured
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
Crafting Experiences
bethany
1
230
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Optimizing for Happiness
mojombo
378
71k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
370
Transcript
慶應義塾大学 西牧宙輝,八島大地,戸倉健登,杉浦孔明 多言語シーンテキストを考慮した 深層状態空間モデルに基づく実世界検索エンジン
Motivation: 実世界検索エンジンをショッピングモール規模に適用したい - 2 - 実世界検索エンジン [Yashima+, RA-L25], [Kaneda+, RA-L24]:自然言語に基づき,物体を検索
屋内 ドバイモール 万博の一部 カテゴリ数 RT-1 [Brohan+, RSS23],π0 [Black+, RSS25] 300~ 2,000~ 50,000~ 検索可 操作可 適用不可
手法 概要 NLMap [Chen+, ICRA23] 構築したシーン表現に基づく物体検索 Embodied-RAG [Xie+, 24] 階層的なメモリ構造に基づく階層的探索
RelaX-Former [Yashima+, RA-L25] 自由形式の指示文に基づく物体検索・操作 関連研究: 検索ベースの物体操作手法は1つの店舗規模ですら適用が困難 - 3 - RelaX-Former Embodied-RAG 多様なカテゴリ の物体に対応 できない
なぜ難しいのか? - 4 - ◼ カテゴリ数が多い ◼ 1画像内の物体数が多い ⇔ シーンテキストを利用すれば
解決できるはず 英語 アラビア語 フランス語 https://dubainotorisetsu.com/wp-content/uploads/2024/09/472882200_616937954348236_4867730316808105745_n.jpg, https://i1.wp.com/shunpost.com/wp-content/uploads/2019/04/LaysChina-190420_003.jpg, https://www.nongshim.co.jp/wp-content/uploads/2024/09/sub3-1.jpg, https://m.media-amazon.com/images/I/61pvgGGaJ2L._UF894,1000_QL80_.jpg, https://www.instacart.com/image-server/1864x1864/www.instacart.com/assets/domains/product-image/file/large_75a80d77-183d-47b9-9898-38da5a697be0.jpg 英語 中国語 英語 韓国語 日本語 英語 スペイン語 英語 ドイツ語 多言語
なぜ難しいのか? - 5 - ◼ カテゴリ数が多い ◼ 1画像内の物体数が多い ⇔ シーンテキストを利用すれば
解決できるはず 英語 アラビア語 フランス語 https://dubainotorisetsu.com/wp-content/uploads/2024/09/472882200_616937954348236_4867730316808105745_n.jpg, https://i1.wp.com/shunpost.com/wp-content/uploads/2019/04/LaysChina-190420_003.jpg, https://www.nongshim.co.jp/wp-content/uploads/2024/09/sub3-1.jpg, https://m.media-amazon.com/images/I/61pvgGGaJ2L._UF894,1000_QL80_.jpg, https://www.instacart.com/image-server/1864x1864/www.instacart.com/assets/domains/product-image/file/large_75a80d77-183d-47b9-9898-38da5a697be0.jpg 英語 中国語 英語 韓国語 日本語 英語 スペイン語 英語 ドイツ語 多言語
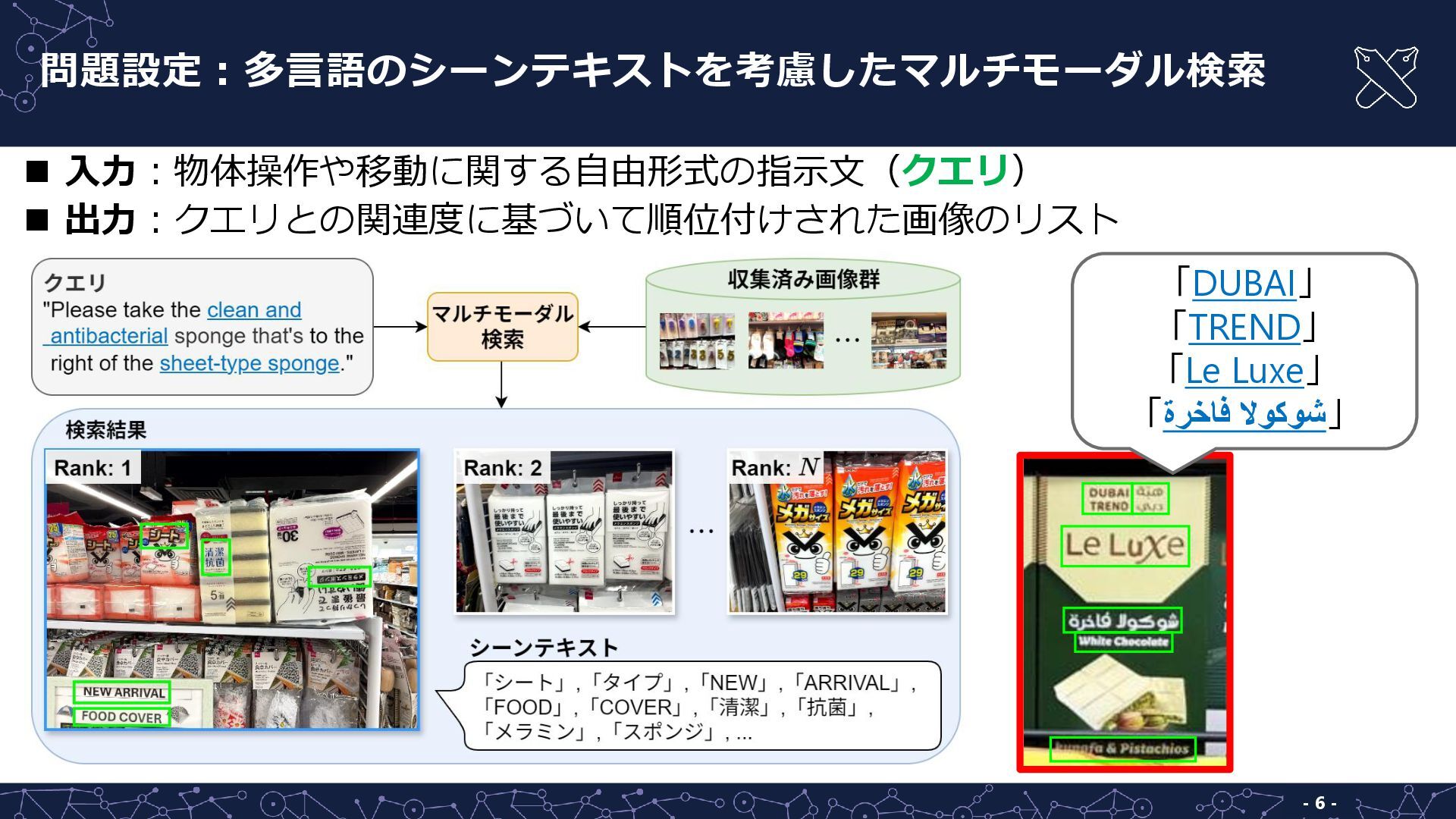
問題設定:多言語のシーンテキストを考慮したマルチモーダル検索 - 6 - ◼ 入力:物体操作や移動に関する自由形式の指示文(クエリ) ◼ 出力:クエリとの関連度に基づいて順位付けされた画像のリスト 「DUBAI」 「TREND」
「Le Luxe」 「ةرخاف الوكوش」
- 7 - 多言語のシーンテキストを視覚言語モデルは扱えない 「ةنيهج」 「بيلح」 https://omiyagemylove.com/wp-content/uploads/2024/06/import/blog_import_66504b7bdd661.jpg, https://img.danawa.com/prod_img/500000/840/719/img/2719840_1.jpg, https://m.media-amazon.com/images/I/411Y41QziVL.jpg
これらの文字から情報を得られない 「퐁퐁」 「キュキュット」 「除菌」
- 8 - シーンテキストには固有名詞が含まれるため翻訳だけでは不十分 「ةنيهج」 ⇒ Juhayna 「بيلح」 ⇒ milk
https://omiyagemylove.com/wp-content/uploads/2024/06/import/blog_import_66504b7bdd661.jpg, https://img.danawa.com/prod_img/500000/840/719/img/2719840_1.jpg, https://m.media-amazon.com/images/I/411Y41QziVL.jpg 固有名詞を翻訳 ⇒ 不適切な埋め込み 「퐁퐁」 ⇒ Pongpong 「キュキュット」 ⇒ Kyu Kyu Tto 「除菌」 ⇒ antibacterial
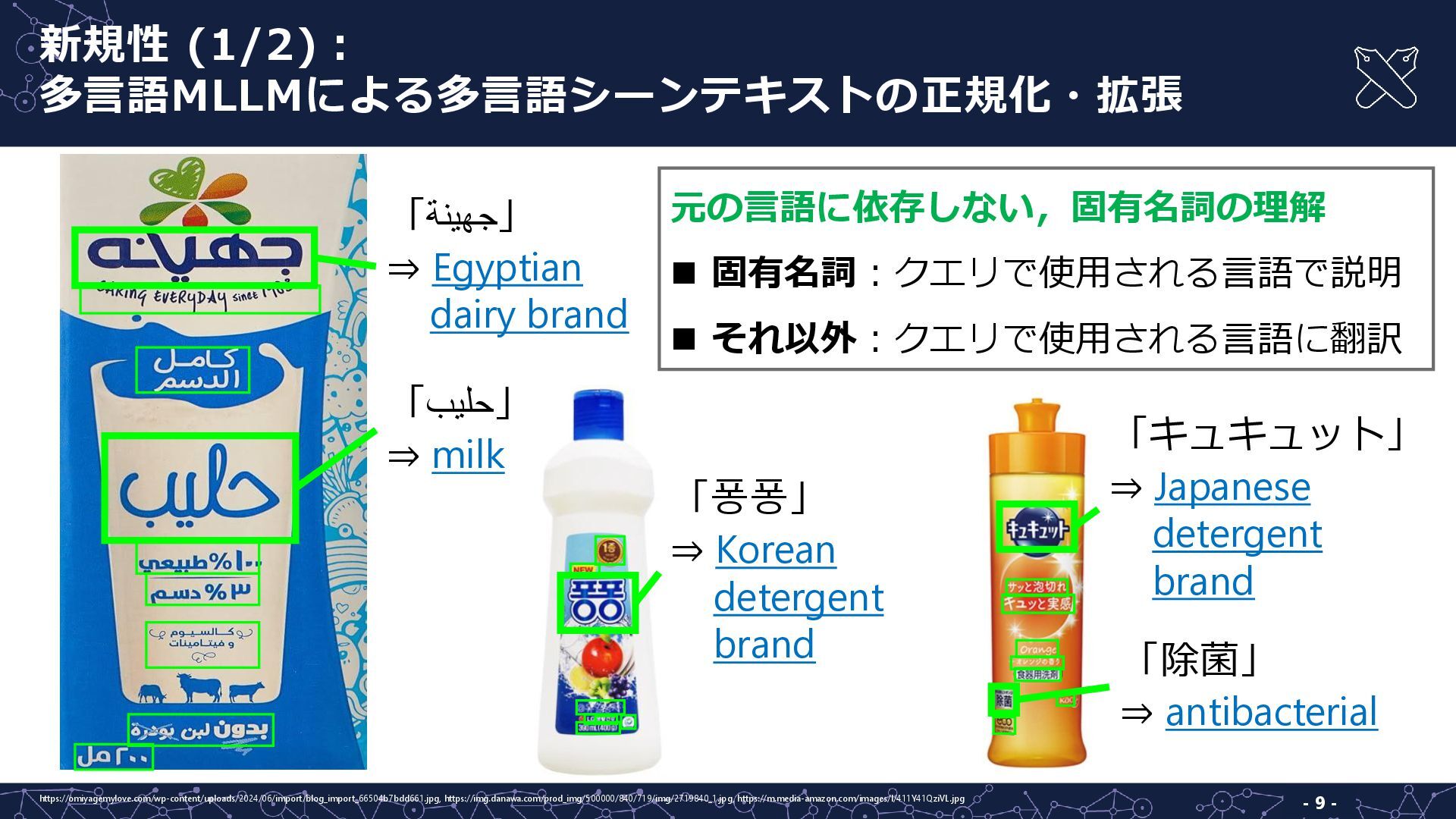
- 9 - 新規性 (1/2): 多言語MLLMによる多言語シーンテキストの正規化・拡張 「ةنيهج」 ⇒ Egyptian dairy
brand 「بيلح」 ⇒ milk https://omiyagemylove.com/wp-content/uploads/2024/06/import/blog_import_66504b7bdd661.jpg, https://img.danawa.com/prod_img/500000/840/719/img/2719840_1.jpg, https://m.media-amazon.com/images/I/411Y41QziVL.jpg 「퐁퐁」 ⇒ Korean detergent brand 「キュキュット」 ⇒ Japanese detergent brand 「除菌」 ⇒ antibacterial 元の言語に依存しない,固有名詞の理解 ◼ 固有名詞:クエリで使用される言語で説明 ◼ それ以外:クエリで使用される言語に翻訳
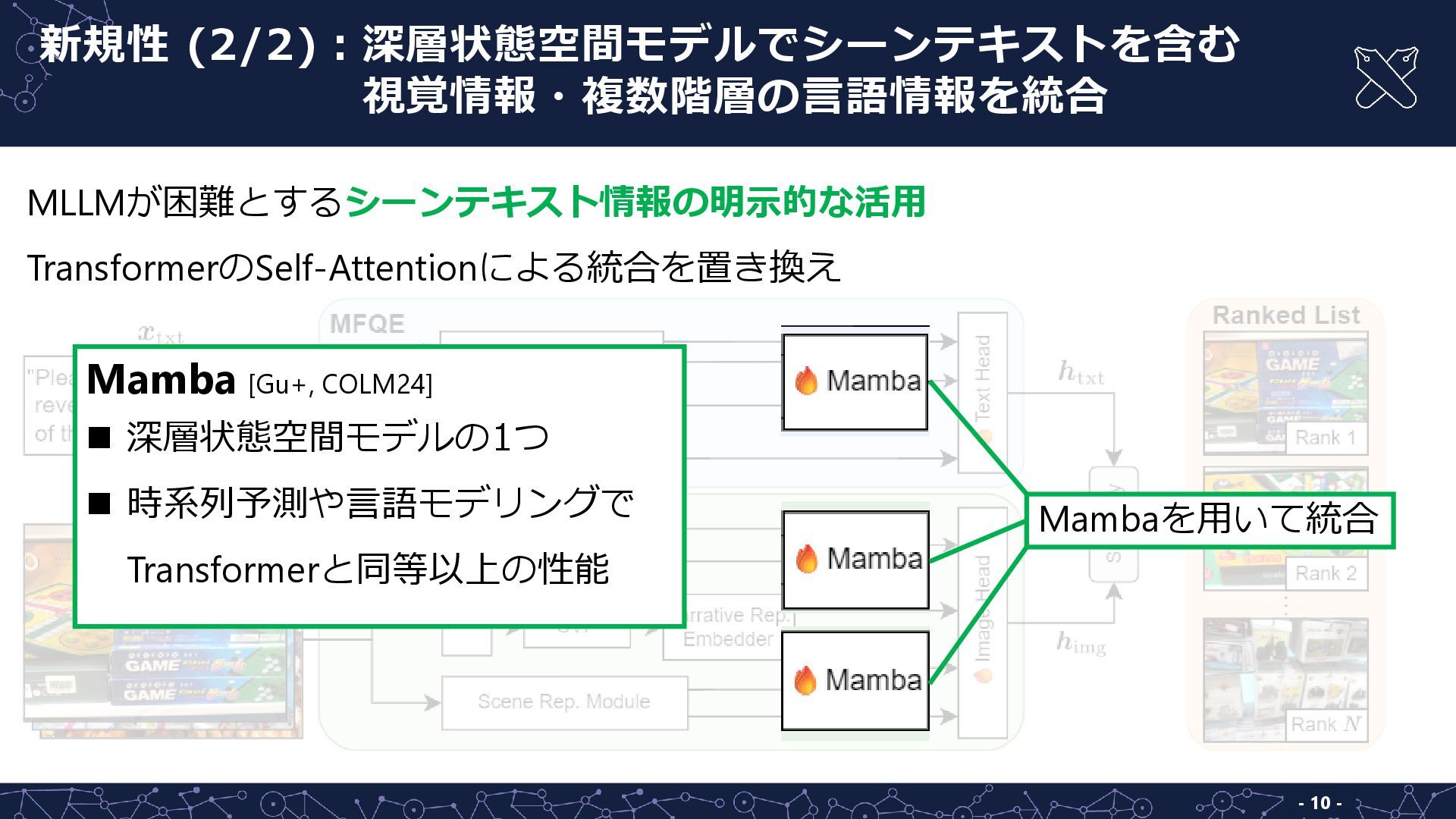
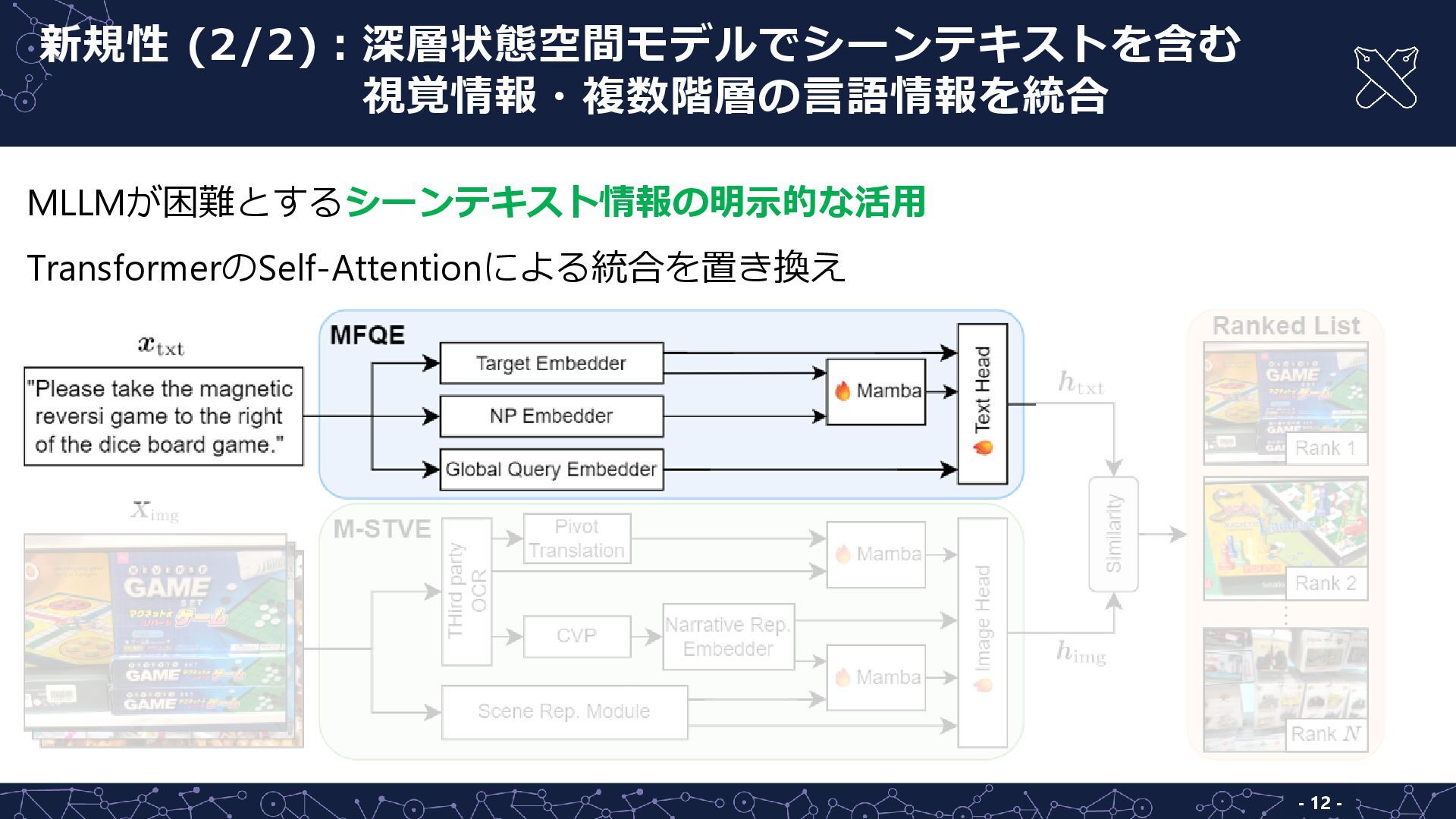
- 10 - 新規性 (2/2):深層状態空間モデルでシーンテキストを含む 新規性 (2/2):視覚情報・複数階層の言語情報を統合 MLLMが困難とするシーンテキスト情報の明示的な活用 TransformerのSelf-Attentionによる統合を置き換え Mamba
[Gu+, COLM24] ◼ 深層状態空間モデルの1つ ◼ 時系列予測や言語モデリングで Transformerと同等以上の性能 Mambaを用いて統合
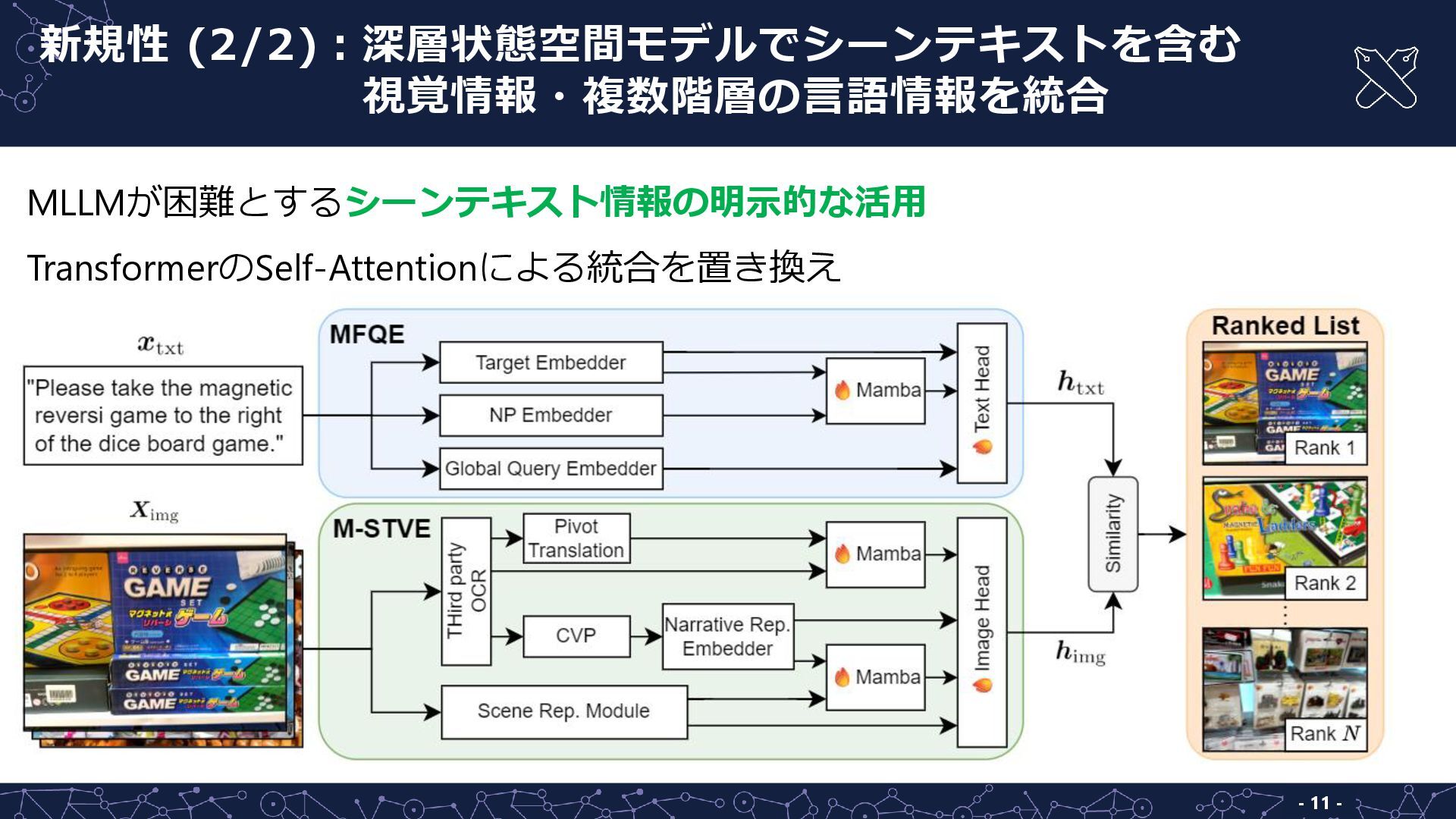
- 11 - MLLMが困難とするシーンテキスト情報の明示的な活用 TransformerのSelf-Attentionによる統合を置き換え 新規性 (2/2):深層状態空間モデルでシーンテキストを含む 新規性 (2/2):視覚情報・複数階層の言語情報を統合
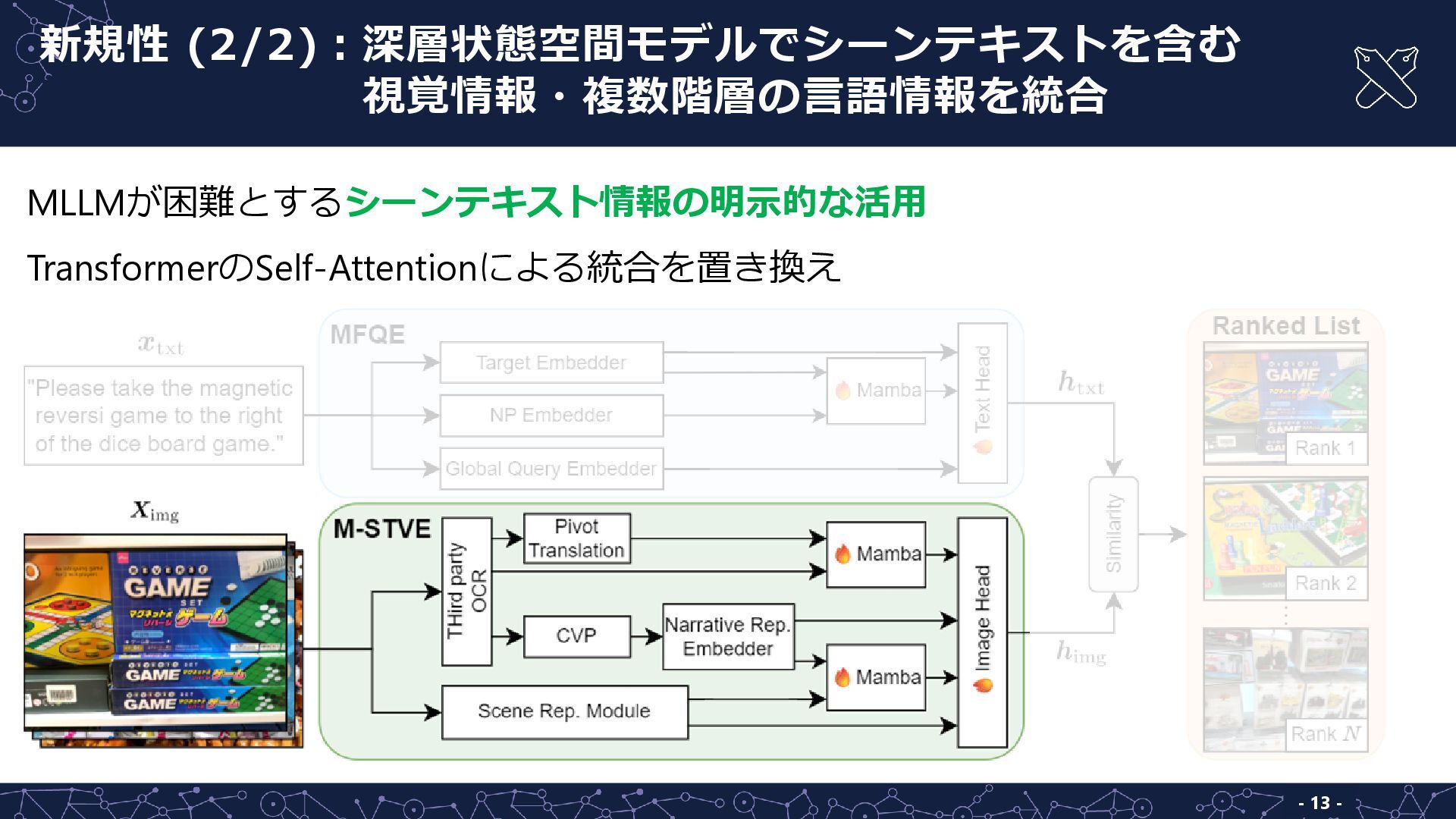
- 12 - MLLMが困難とするシーンテキスト情報の明示的な活用 TransformerのSelf-Attentionによる統合を置き換え 新規性 (2/2):深層状態空間モデルでシーンテキストを含む 新規性 (2/2):視覚情報・複数階層の言語情報を統合
- 13 - MLLMが困難とするシーンテキスト情報の明示的な活用 TransformerのSelf-Attentionによる統合を置き換え 新規性 (2/2):深層状態空間モデルでシーンテキストを含む 新規性 (2/2):視覚情報・複数階層の言語情報を統合
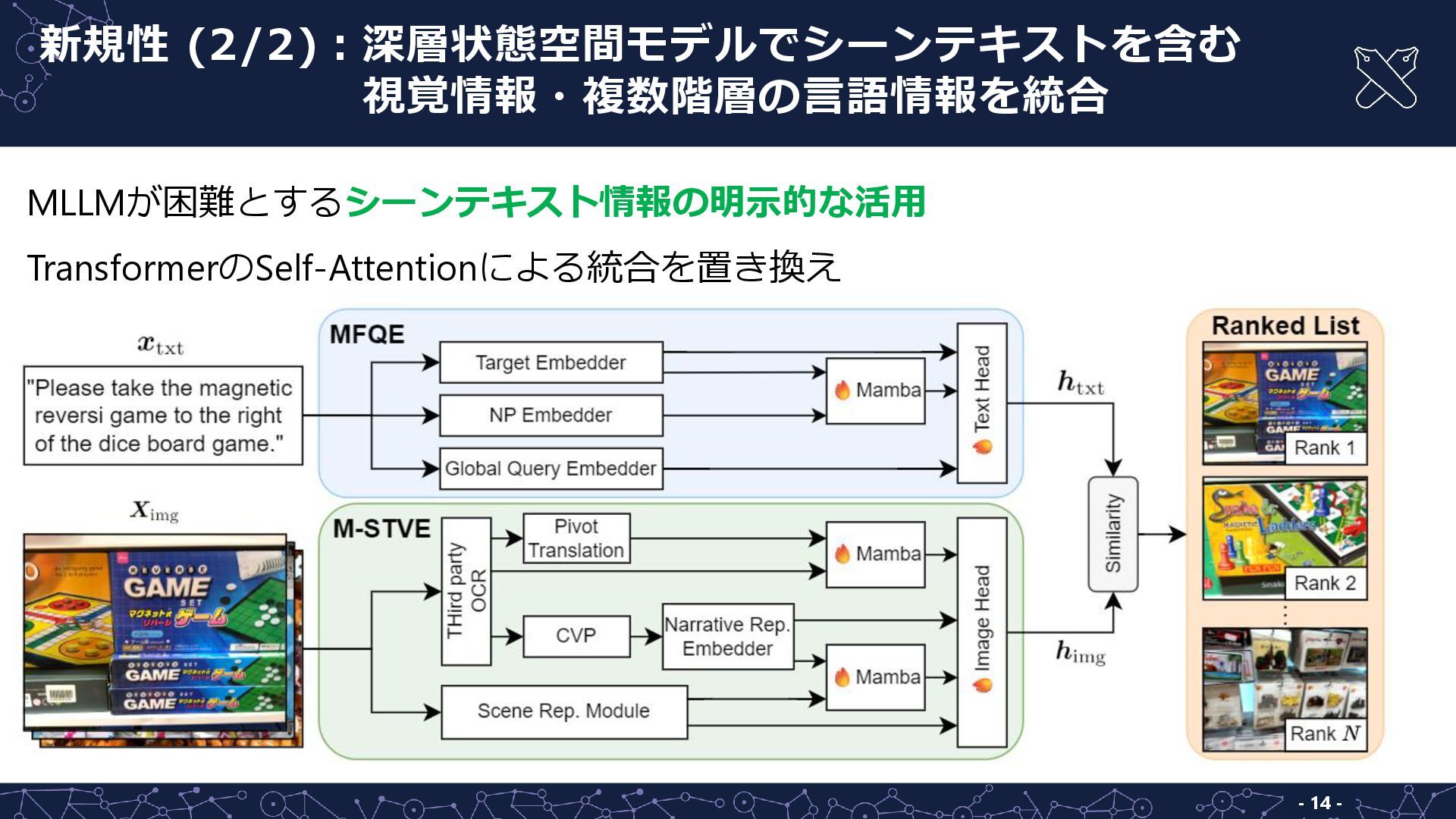
- 14 - MLLMが困難とするシーンテキスト情報の明示的な活用 TransformerのSelf-Attentionによる統合を置き換え 新規性 (2/2):深層状態空間モデルでシーンテキストを含む 新規性 (2/2):視覚情報・複数階層の言語情報を統合
実験設定: 多言語のシーンテキストを含むマルチモーダル検索ベンチマークを構築 - 15 - ◼ 多言語のシーンテキストを含む画像とそれらを考慮したクエリで構成 ◼ 107名のアノテータ ◼
580画像,2994クエリ ◼ ドバイモール (世界最大級の ショッピングモール) の店舗で画像を収集 MP3D [Chang+, 3DV17], HM3D [Ramakrishnan+, NeurIPS21] シーンテキストを含まない画像群 GoGetIt, TextCaps-test [戸倉+, MIRU25] 英語のシーンテキストのみを考慮したクエリ
定量的結果 (1/2):標準的な評価指標でベースライン手法を上回った - 16 - [%] 手法 M-STAR GoGetIt (Instruction)
GoGetIt (RefText) TextCaps-test R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ 提案手法 62.3 83.1 84.0 89.8 82.8 88.8 86.8 92.5 BLIP2 [Li+, ICML23] 54.9 71.5 - - - - 76.8 86.3 BEiT-3 [Wang+, CVPR23] 44.6 61.0 67.0 77.2 77.3 84.2 82.5 89.5 SigLIP2 [Tschannen+, 25] 61.0 77.8 67.8 75.9 70.4 80.3 78.5 85.5 STARE [戸倉+, MIRU25] 58.2 76.9 78.7 86.8 79.7 86.7 81.5 87.6
[%] 手法 M-STAR GoGetIt (Instruction) GoGetIt (RefText) TextCaps-test R@5↑ R@10↑
R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ 提案手法 62.3 83.1 84.0 89.8 82.8 88.8 86.8 92.5 BLIP2 [Li+, ICML23] 54.9 71.5 - - - - 76.8 86.3 BEiT-3 [Wang+, CVPR23] 44.6 61.0 67.0 77.2 77.3 84.2 82.5 89.5 SigLIP2 [Tschannen+, 25] 61.0 77.8 67.8 75.9 70.4 80.3 78.5 85.5 STARE [戸倉+, MIRU25] 58.2 76.9 78.7 86.8 79.7 86.7 81.5 87.6 - 17 - +5.3 +3.0 +2.1 +3.0 定量的結果 (2/2):標準的な評価指標でベースライン手法を上回った
- 18 - 定性的結果 (1/2): 日本語のシーンテキスト「消臭ビーズ」も考慮して順位付け “Please get the pink
aroma product with deodorant beads surrounding it.”
- 19 - 定性的結果 (1/2): 日本語のシーンテキスト「消臭ビーズ」も考慮して順位付け “Please get the pink
aroma product with deodorant beads surrounding it.”
- 20 - 定性的結果 (1/2): 日本語のシーンテキスト「消臭ビーズ」も考慮して順位付け “Please get the pink
aroma product with deodorant beads surrounding it.”
- 21 - 定性的結果 (1/2): 日本語のシーンテキスト「消臭ビーズ」も考慮して順位付け “Please get the pink
aroma product with deodorant beads surrounding it.”
- 22 - 定性的結果 (2/2):複数のシーンテキストを考慮して順位付け “Please bring me the purple
Lavender bottle on the right side of white thieves bottle.”
- 23 - 定性的結果 (2/2):複数のシーンテキストを考慮して順位付け “Please bring me the purple
Lavender bottle on the right side of white thieves bottle.”
- 24 - 背景 ◼ 多言語のシーンテキストを考慮したマルチモーダル検索 新規性 ◼ 多言語のシーンテキストを正規化・拡張し,視覚情報との関係をモデル化 ◼
深層状態空間モデルでシーンテキストを含む視覚情報・複数階層の言語情報を統合 結果 ◼ すべてのベンチマークにおいて ベースライン手法を上回る まとめ
Appendix 25
- 26 - 損失関数:類似画像に対して頑健な損失関数の設定 Dual Relaxed Contrastive (DRC) loss [Yashima+,
RA-L25]を使用 ◼ MLLMを用いて類似画像にUnlabeled Positiveを付与 ◼ Unlabeled Positiveを考慮し,対照性を緩和する損失関数 :Unlabeled Positiveペアの添字集合
- 27 - ベンチマーク:マルチモーダル検索用のベンチマーク 物体操作や移動に関する自由形式の指示文および画像から構成 ◼ GoGetIt,TextCaps-test [戸倉+, MIRU25] ◼
RefText [Bu+, TMM23] ,TextCaps [Sidorov+, ECCV20] の画像に対して指示文を付与 ◼ クエリは英語のシーンテキストを考慮して付与 ◼ LTRRIE [Kaneda+, RA-L24] ◼ 屋内環境を対象 ◼ シーンテキストを含まない画像群が検索対象 クエリ:“Pass me a yellow TOBLERONE in front of the orange Apricots.” GoGetIt
- 28 - 評価指標:マルチモーダル検索設定において標準的 ◼ Recall@K :クエリ数 :𝑖番目のクエリに対する正解画像群 :𝑖番目のクエリに対する検索結果のうち,上位𝐾枚の画像群
Ablation Study: 多言語シーンテキストの正規化・拡張が性能向上に寄与 - 29 - 手法 [%] M-STAR GoGetIt
(Instruction) GoGetIt (RefText) TextCaps-test R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ 提案手法 62.3 83.1 84.0 89.8 82.8 88.8 86.8 92.5 w/o Pivot Translation 55.7 77.8 80.5 85.9 79.1 87.1 83.2 88.9 ◼ すべてのベンチマークにおいてシーンテキストの正規化・拡張が性能向上に寄与 ◼ 特に多言語のシーンテキストを考慮したM-STARベンチマークで性能向上が顕著
Ablation Study:Mambaを用いた統合が性能向上に寄与 - 30 - 手法 [%] M-STAR GoGetIt (Instruction)
GoGetIt (RefText) TextCaps-test R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ R@5↑ R@10↑ 提案手法 62.3 83.1 84.0 89.8 82.8 88.8 86.8 92.5 w/ Transformer 59.1 79.1 80.2 86.7 79.8 87.7 83.3 90.0 ◼ Mambaによる特徴量の統合部分をTransformerに置き換えて実験 ◼ すべてのベンチマークにおいて,Mambaによる統合が性能向上に寄与
- 31 - 定性的結果 (失敗例): 「Botanical」をシーンテキストととらえられずに順位付け “Please bring me the
frame that says Botanical, located on the far left of the shelf.”
- 32 - 定性的結果 (失敗例): 「Botanical」をシーンテキストととらえられずに順位付け “Please bring me the
frame that says Botanical, located on the far left of the shelf.” 「BOTA」と「NICAL」に分かれて検出 ⇒ クエリ中の「Botanical」と対応付けられず 「BOTA」 「NICAL」
{kind=link}
![Motivation: 実世界検索エンジンをショッピングモール規模に適用したい - 2 - 実世界検索エンジン [Yashima+, RA-L25], [Kaneda+, RA-L24]:自然言語に基づき,物体を検索](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_1.jpg){kind=link}
![手法 概要 NLMap [Chen+, ICRA23] 構築したシーン表現に基づく物体検索 Embodied-RAG [Xie+, 24] 階層的なメモリ構造に基づく階層的探索](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量的結果 (1/2):標準的な評価指標でベースライン手法を上回った - 16 - [%] 手法 M-STAR GoGetIt (Instruction)](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_15.jpg){kind=link}
![[%] 手法 M-STAR GoGetIt (Instruction) GoGetIt (RefText) TextCaps-test R@5↑ R@10↑](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- 27 - ベンチマーク:マルチモーダル検索用のベンチマーク 物体操作や移動に関する自由形式の指示文および画像から構成 ◼ GoGetIt,TextCaps-test [戸倉+, MIRU25] ◼](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_26.jpg){kind=link}
{kind=link}
![Ablation Study: 多言語シーンテキストの正規化・拡張が性能向上に寄与 - 29 - 手法 [%] M-STAR GoGetIt](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_28.jpg){kind=link}
![Ablation Study:Mambaを用いた統合が性能向上に寄与 - 30 - 手法 [%] M-STAR GoGetIt (Instruction)](https://files.speakerdeck.com/presentations/46b963f6dc154d4b9b1d7af9060db8bd/slide_29.jpg){kind=link}
{kind=link}
{kind=link}