Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[RSJ25] LILAC: Language‑Conditioned Object‑Cent...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 02, 2025
Technology
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[RSJ25] LILAC: Language‑Conditioned Object‑Centric Optical Flow for Open‑Loop Trajectory Generation
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 02, 2025
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
880
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
260
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
950
VPCセキュリティ対応の最新事情
nagisa53
1
240
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
24
10k
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
190
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
420
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
350
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
300
Featured
See All Featured
YesSQL, Process and Tooling at Scale
rocio
174
15k
Agile that works and the tools we love
rasmusluckow
331
22k
Rails Girls Zürich Keynote
gr2m
96
14k
Code Review Best Practice
trishagee
74
20k
Practical Orchestrator
shlominoach
191
11k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
370
Mobile First: as difficult as doing things right
swwweet
225
10k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Un-Boring Meetings
codingconduct
0
350
Six Lessons from altMBA
skipperchong
29
4.3k
Transcript
神原元就1, 妹尾幸樹1, 鶏内朋也2, 王亜楠2, 杉浦孔明1 物体中心オプティカルフローによる 言語条件付きOpen-Loop軌道生成 1慶應義塾大学 2KDDI総合研究所
Motivation: VLAを少量のロボットデータで訓練したい - 1 - 課題:既存VLAは大量のロボットデータでfine-tuning 5-100 h/task [Black+, RSS25]
[Kim+, CoRL24] ~150 demos/task [Bjorck+, 25] ~3 h/task 本研究:ロボットデータをembodiment学習のみに用いることで省データ ☺ 実験では~20 demos/taskのみ使用 ロボットデータでactionとembodimentを学習する
関連研究: 省データ化への取り組み - 2 - 手法 概要 Track2Act [Bharadhwaj+, ECCV24]
• 1段階目でFlowを生成、2段階目でアームの軌道に変換 • 言語指示は扱わない Im2Flow2Act [Xu+, CoRL24] • 言語指示に基づくflowベース軌道生成 • flowについても各タスクにfittingさせないと性能が不十分 Phantom [Lepert+, CoRL25] • 人間の動作動画のみで訓練 Track2Act Phantom
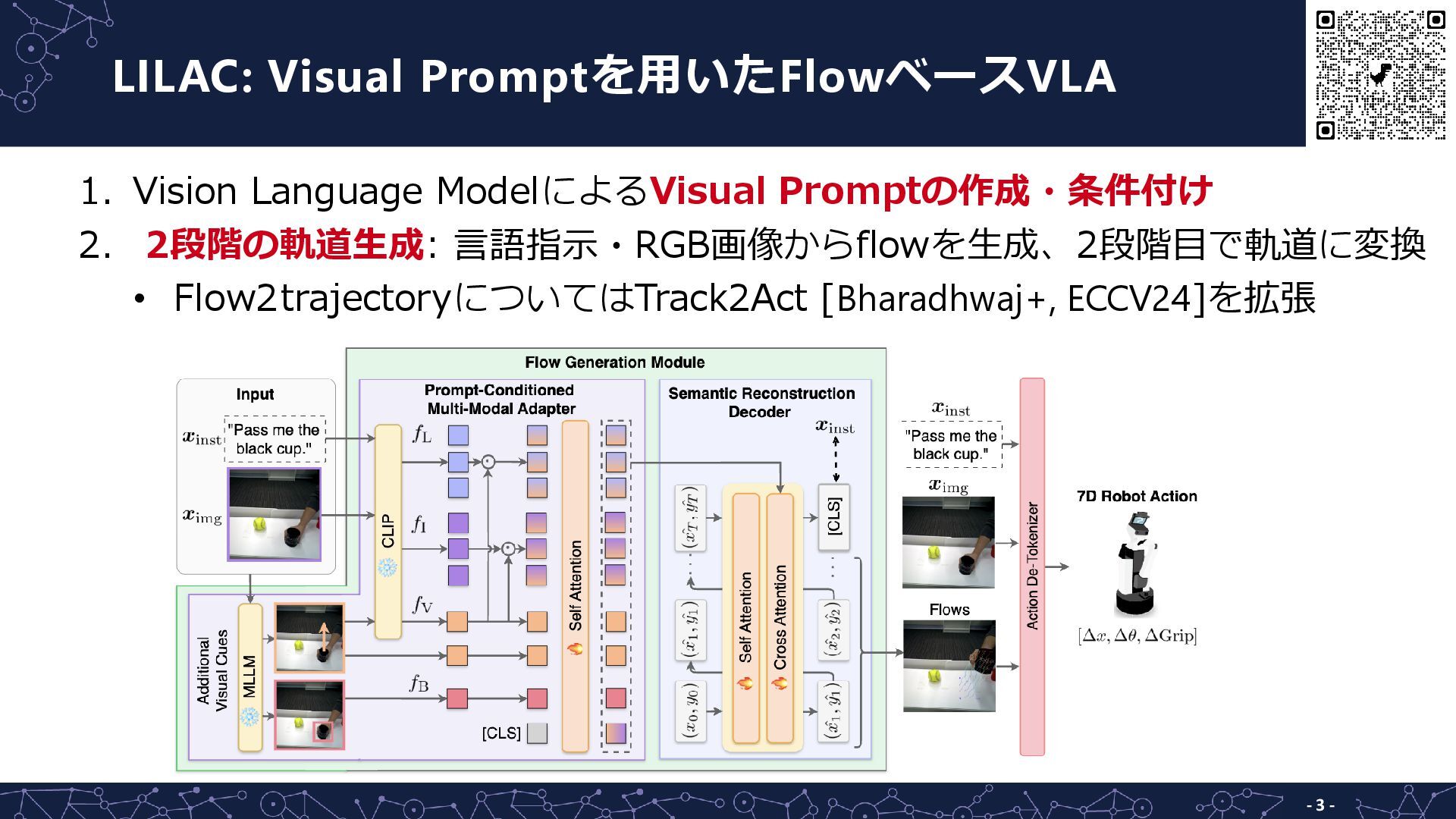
LILAC: Visual Promptを用いたFlowベースVLA - 3 - 1. Vision Language ModelによるVisual
Promptの作成・条件付け 2. 2段階の軌道生成: 言語指示・RGB画像からflowを生成、2段階目で軌道に変換 • Flow2trajectoryについてはTrack2Act [Bharadhwaj+, ECCV24]を拡張
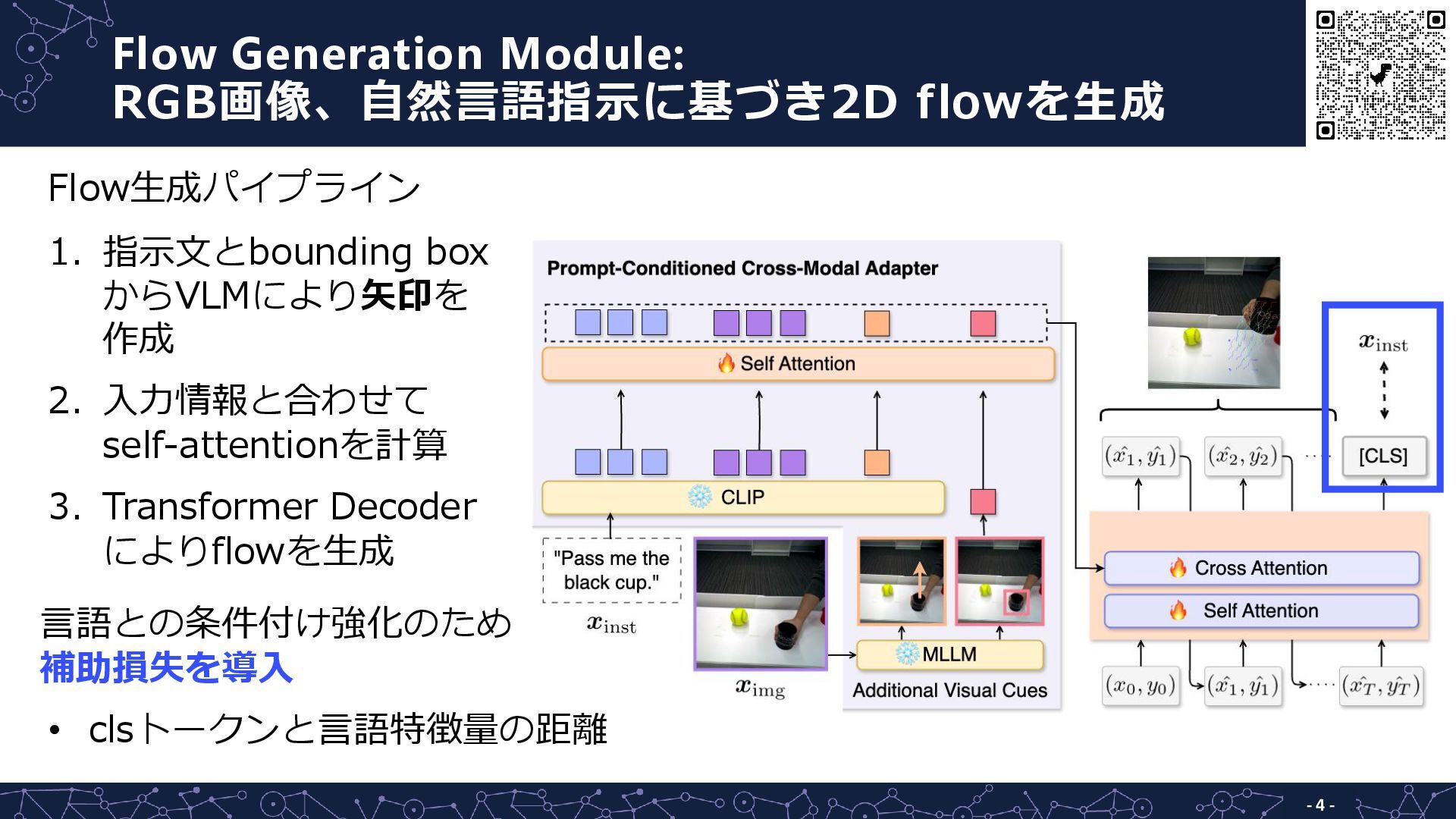
Flow Generation Module: RGB画像、自然言語指示に基づき2D flowを生成 - 4 - 1. 指示文とbounding
box からVLMにより矢印を 作成 2. 入力情報と合わせて self-attentionを計算 3. Transformer Decoder によりflowを生成 言語との条件付け強化のため 補助損失を導入 Flow生成パイプライン • clsトークンと言語特徴量の距離
Visual Prompt Generation: 2D flow生成における補助的な情報の生成 - 5 - Could you
take the coke. Multimodal LLM Visual prompt Bounding box “Place brown chip bag into middle drawer.” “Unfold the fabric from the bottom right to the top left.” 画像と言語から直接flowを生成することは困難 粗なaction表現として矢印を利用、モデルへ入力
実験設定: Robot Flow Benchmark - 6 - • 2D flow生成用のベンチマークを新しく構築
• Fractal, Bridge v2データセットに基づく • 計50,382エピソード Fractalサブセット Bridge v2サブセット “Move sponge near blue chip bag.” “Put spatula on plate sink.” ロボットによる物体操作のためのflowベンチマークはほとんど提案されていない 構築パイプライン 1. VLM (Qwen-2.5-VL-3B)で対象 物体のbounding boxを特定 2. CoTracker3によりflowを生成 3. 動画をNステップにクリップ CoTracker3 [Karaev+, 24]
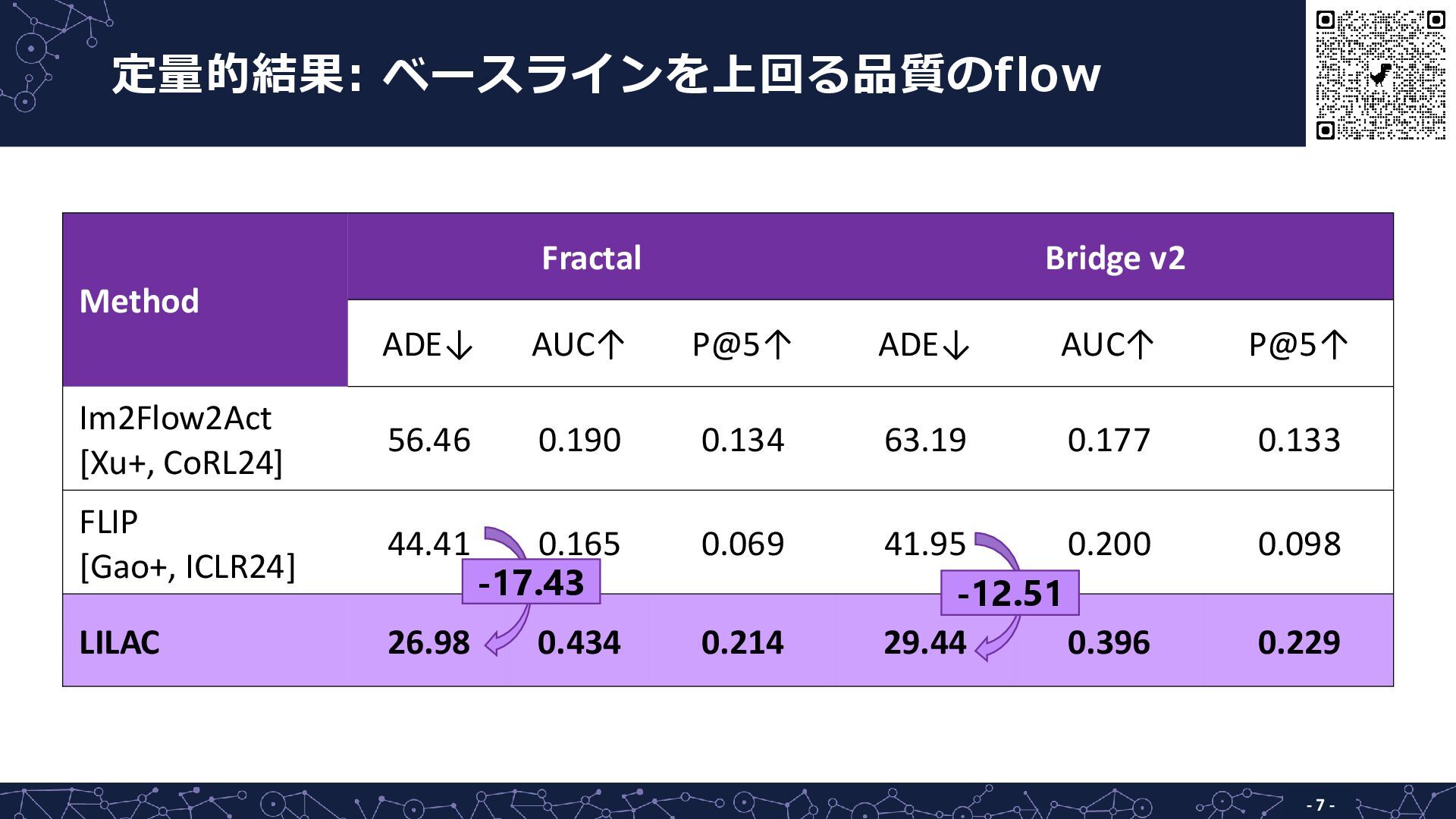
定量的結果: ベースラインを上回る品質のflow - 7 - Method Fractal Bridge v2 ADE↓
AUC↑ P@5↑ ADE↓ AUC↑ P@5↑ Im2Flow2Act [Xu+, CoRL24] 56.46 0.190 0.134 63.19 0.177 0.133 FLIP [Gao+, ICLR24] 44.41 0.165 0.069 41.95 0.200 0.098 LILAC 26.98 0.434 0.214 29.44 0.396 0.229 -17.43 -12.51
定性的結果: 指示文で指定された動作・物体を理解 - 8 - “Take the yellow block to
put it on top of the tower.” “Move water bottle near green jalapeno chip bag.” LILAC FLIP FLIP LILAC ☺ Chip bagの方向へflowを生成 ☺ 持ち上げる方向へ適切に生成
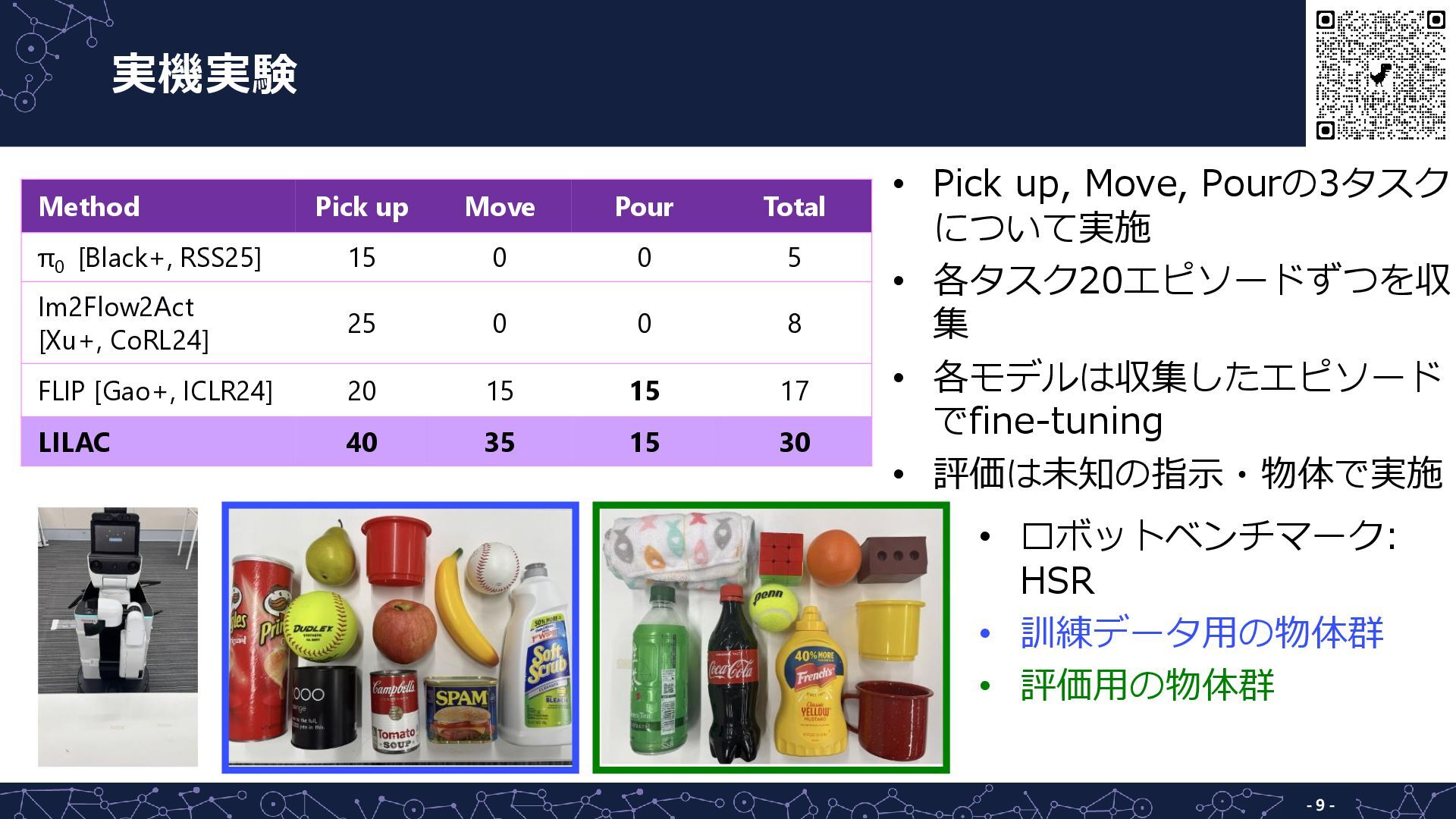
実機実験 - 9 - • Pick up, Move, Pourの3タスク について実施
• 各タスク20エピソードずつを収 集 • 各モデルは収集したエピソード でfine-tuning • 評価は未知の指示・物体で実施 • ロボットベンチマーク: HSR • 訓練データ用の物体群 • 評価用の物体群 Method Pick up Move Pour Total π0 [Black+, RSS25] 15 0 0 5 Im2Flow2Act [Xu+, CoRL24] 25 0 0 8 FLIP [Gao+, ICLR24] 20 15 15 17 LILAC 40 35 15 30
定性的結果: 未知物体に対しても動作生成に成功 - 10 - Could you take the coke.
Pick the yellow bottle. Pour yellow bottle into the red mug. Place the cup near the orange
まとめ - 11 - • Fine-tuningにおいて、少量のロボットデータで訓練ができれば省コスト • 物体中心のflowを生成、flowをアームの起動に変換するflow-based VLAであ るLILACを提案
• Visual promptをflow生成の補助と して用いることで品質を向上 • Flow生成だけでなく、実機におけ る軌道生成においてもベースライ ンを上回る性能を達成
{kind=link}
![Motivation: VLAを少量のロボットデータで訓練したい - 1 - 課題:既存VLAは大量のロボットデータでfine-tuning 5-100 h/task [Black+, RSS25]](https://files.speakerdeck.com/presentations/39533d251c304e0ead3e011bc6ac94c3/slide_1.jpg){kind=link}
![関連研究: 省データ化への取り組み - 2 - 手法 概要 Track2Act [Bharadhwaj+, ECCV24]](https://files.speakerdeck.com/presentations/39533d251c304e0ead3e011bc6ac94c3/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}