Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
慶應義塾大学 機械学習基礎13 強化学習の基礎
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
April 17, 2023
Technology
1.7k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
慶應義塾大学 機械学習基礎13 強化学習の基礎
Semantic Machine Intelligence Lab., Keio Univ.
PRO
April 17, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
61
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
73
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
110
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
90
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
LiDAR SLAMの実装とセンサ融合 ~Lie群からContinuous-Time LIOまで~
naokiakai
1
1k
デジタル・デザイン構想 by Sayaka Ishizuka
y150saya
0
200
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
170
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
310
はじめてのWDM
miyukichi_ospf
1
120
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Baseline対応のDOMの型定義を作った
uhyo
3
720
AI Driven AI Governance
pict3
0
250
Claude Codeとハーネスについて考えてみる
oikon48
18
8.8k
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
420
“ID沼入口” - 基本とセキュリティから始める、考え続けるためのID管理技術勉強会 告知&イントロ
ritou
0
440
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
670
Featured
See All Featured
Color Theory Basics | Prateek | Gurzu
gurzu
0
380
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Mind Mapping
helmedeiros
PRO
1
280
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Visualization
eitanlees
152
17k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
The Spectacular Lies of Maps
axbom
PRO
1
850
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
260
Transcript
情報工学科 教授 杉浦孔明
[email protected]
慶應義塾大学理工学部 機械学習基礎 第13回 強化学習の基礎
強化学習の基礎 - - 4
強化学習(reinforcement learning)の概要 - - 5 ▪ 1980年代:Suttonらによる研究 ▪ バックギャモンへの強化学習の適用[Tesauro, 1992]
▪ 2017年:深層強化学習を用いたAlphaGoが囲碁チャンピオンを破る https://deepmind.com/alphago-china
強化学習とは - - 6 強化学習 ▪ 環境と相互作用しながら報酬をもとに 行動を学習する枠組み 強化学習の応用例 ▪
囲碁将棋等のゲームAI ▪ ロボットの単純動作の獲得 ▪ 教師あり学習と組み合わせた利用 ▪ ChatGPTの一部であるInstructGPT で利用
強化学習の設定 - - 7 ▪ エージェント ▪ 行動(action)を学習する主体 ▪ 方策(policy)に従って行動を選択
▪ 環境(environment) ▪ エージェントが行動を加える対象 ▪ 状態(state)と報酬(reward)をエー ジェントに返す -1 -20 -1 -1 +10
強化学習の流れ グリッドワールドの例 - - 8 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 状態:左上
強化学習の流れ グリッドワールドの例 - - 9 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 1. 決定論的方策(例:100%の確率で下) 2. 確率論的方策(例:50%の確率でランダ ムに右 or 下を選択)
強化学習の流れ グリッドワールドの例 - - 10 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 1. 決定論的方策(例:100%の確率で下) 2. 確率論的方策(例:50%の確率でランダ ムに右 or 下を選択) 確率論的方策のみを考える
強化学習の流れ グリッドワールドの例 - - 11 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10
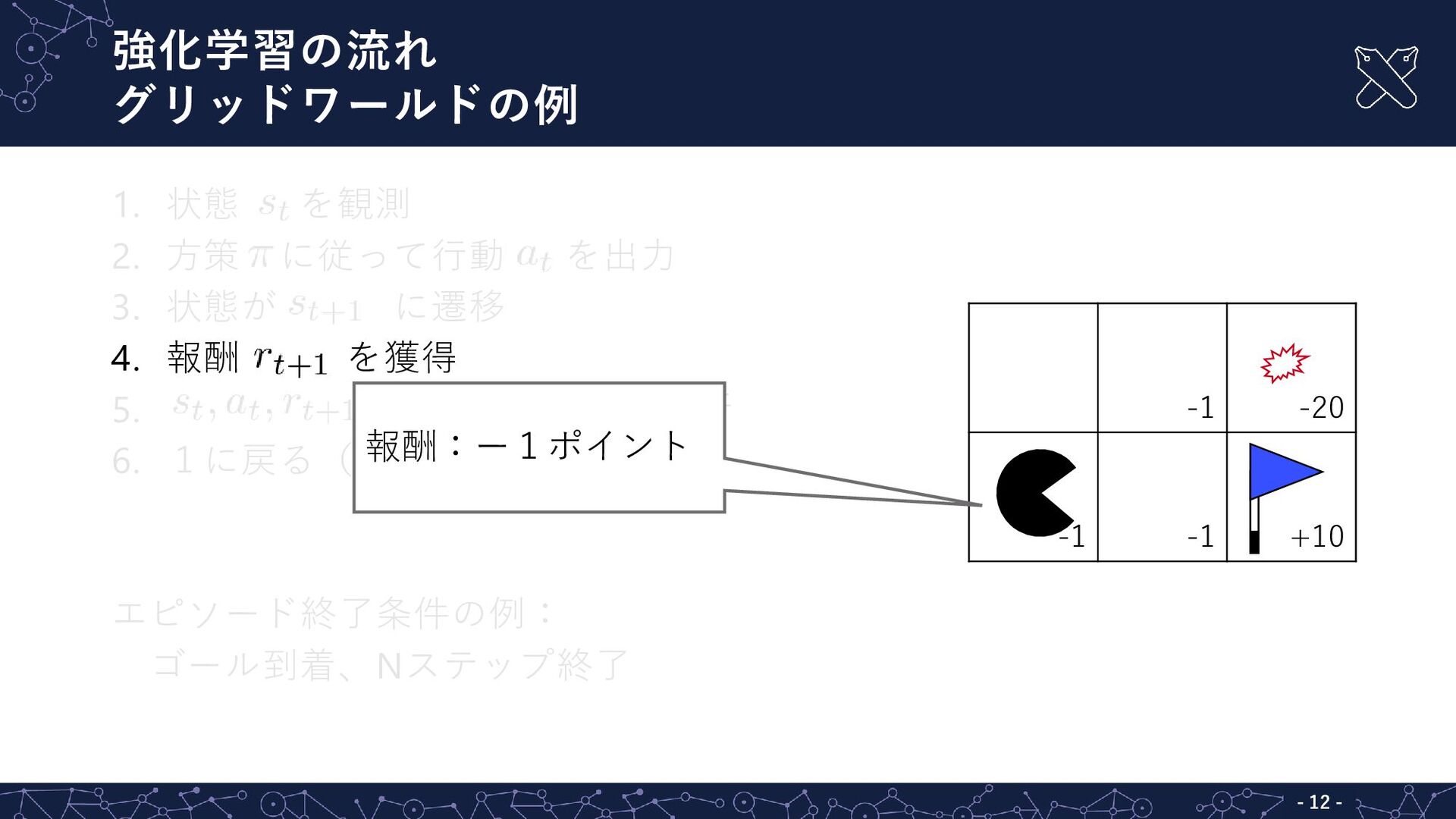
強化学習の流れ グリッドワールドの例 - - 12 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 報酬:ー1ポイント
強化学習の流れ グリッドワールドの例 - - 13 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 左上から下に進んだら、 -1ポイントだった
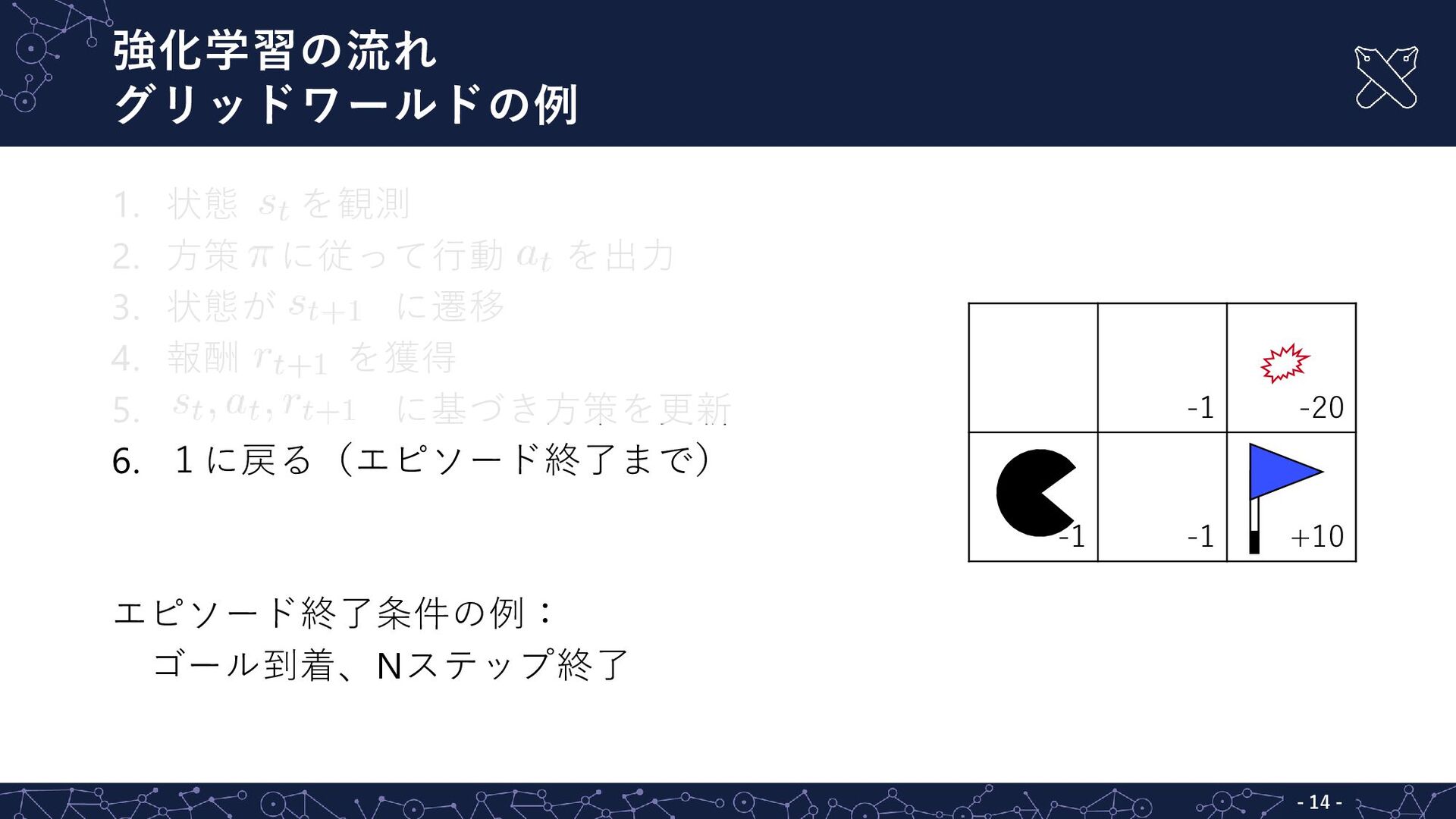
強化学習の流れ グリッドワールドの例 - - 14 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10
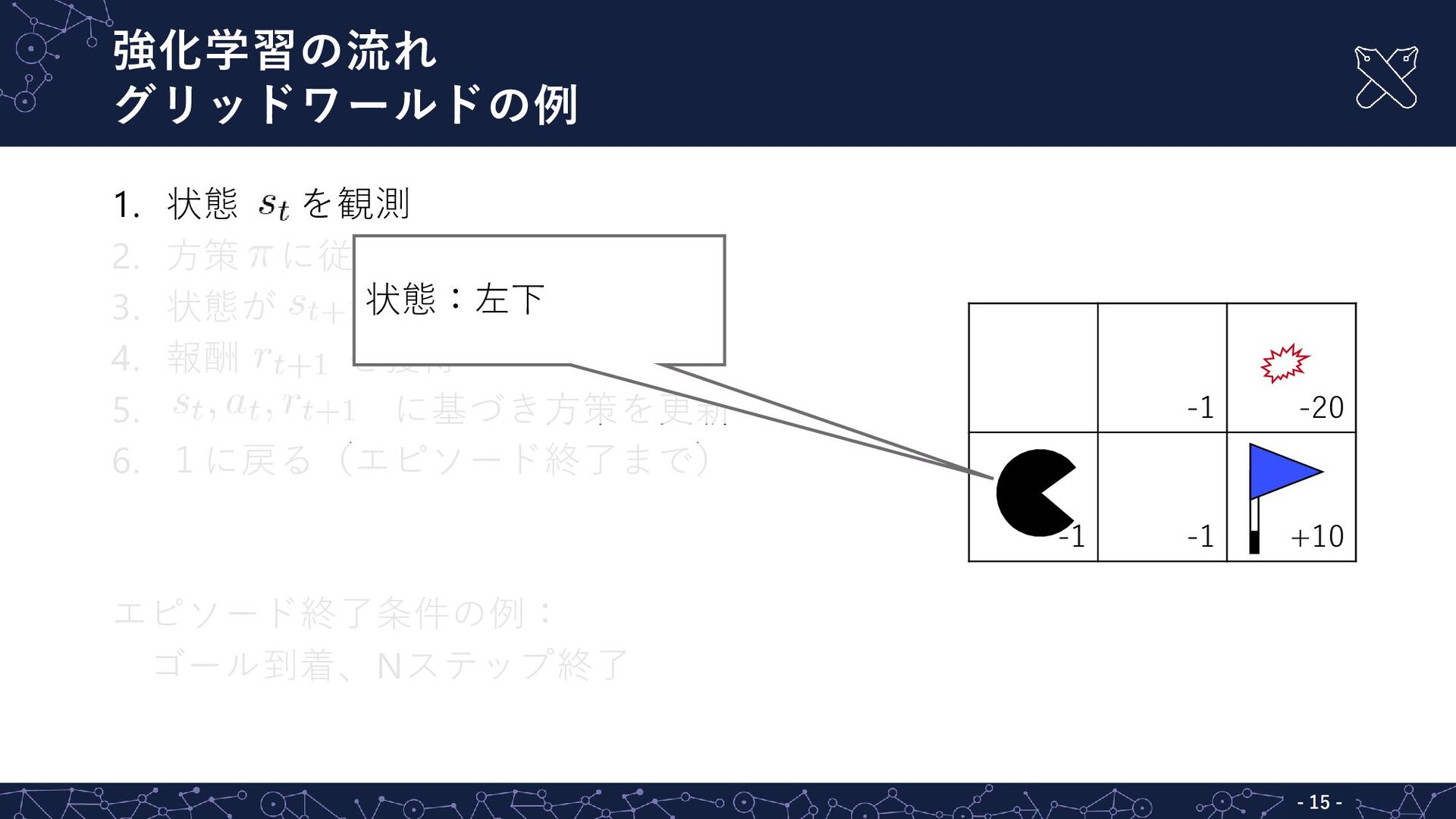
強化学習の流れ グリッドワールドの例 - - 15 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 状態:左下
強化学習の流れ グリッドワールドの例 - - 16 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 1. 決定論的方策(例:100%の確率で下) 2. 確率論的方策(例:50%の確率でランダ ムに右 or 下を選択)
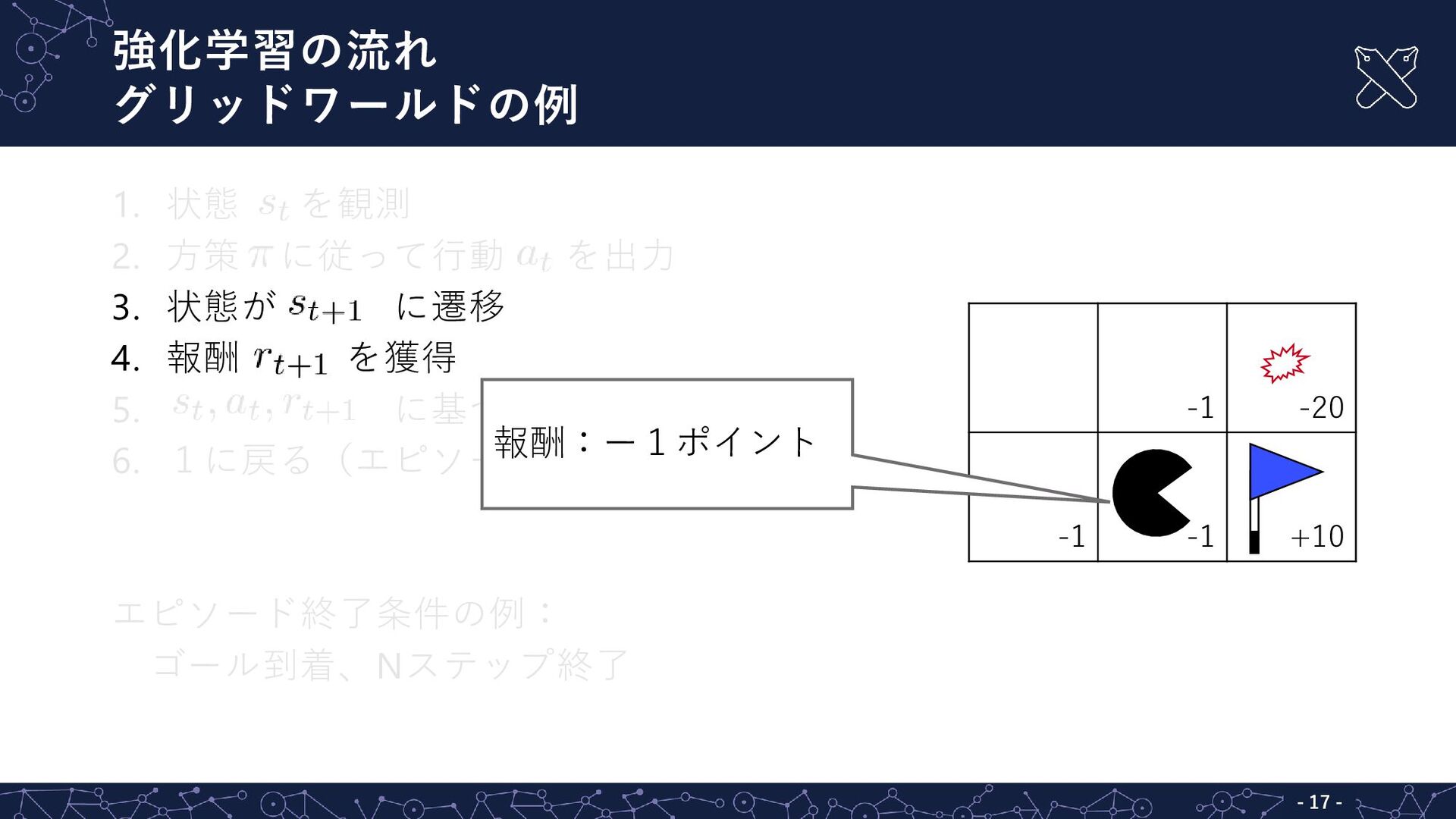
強化学習の流れ グリッドワールドの例 - - 17 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 報酬:ー1ポイント
強化学習の流れ グリッドワールドの例 - - 18 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 左下から右に進んだら、 -1ポイントだった
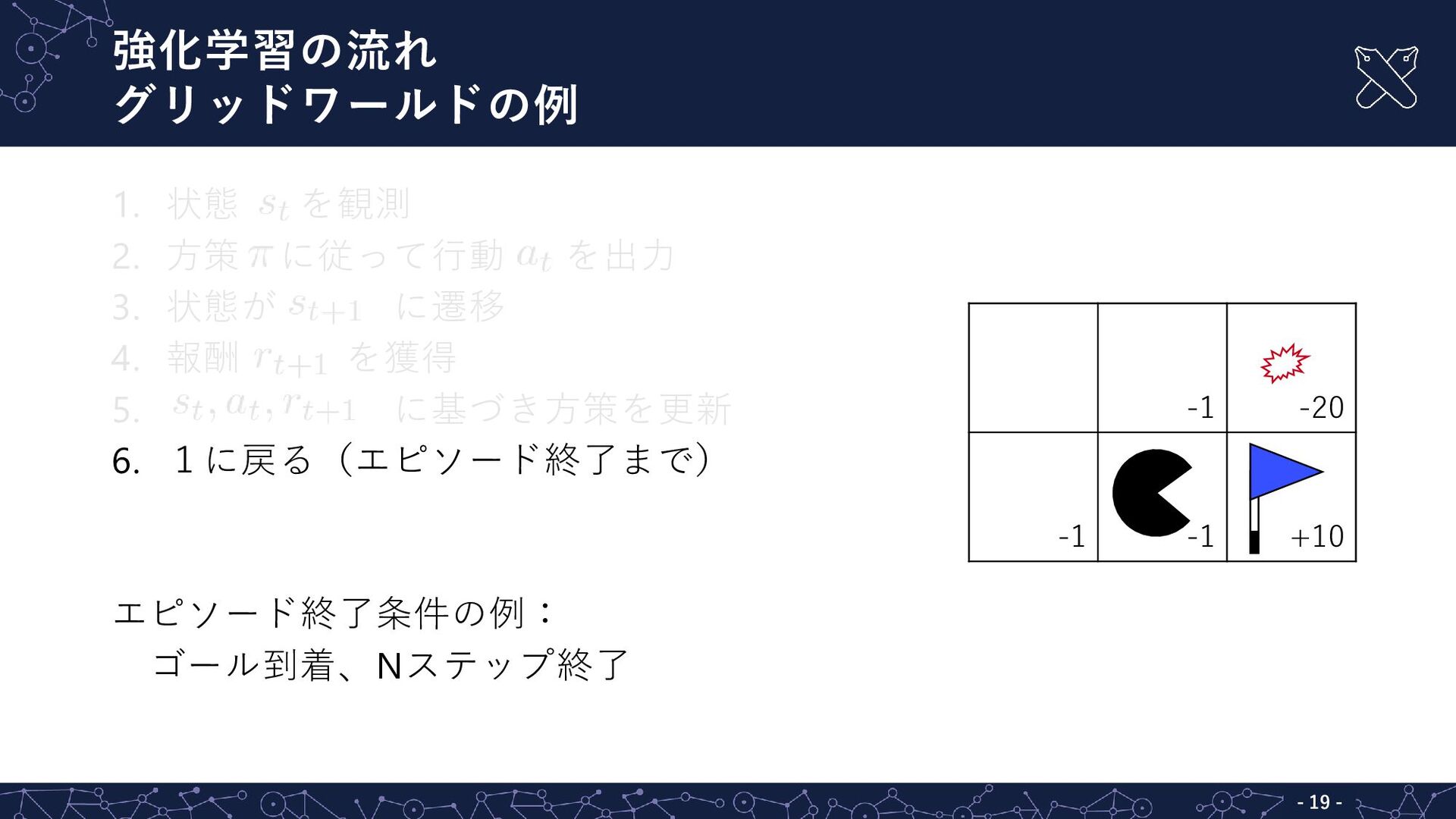
強化学習の流れ グリッドワールドの例 - - 19 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10
強化学習の流れ グリッドワールドの例 - - 20 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 状態:中下
強化学習の流れ グリッドワールドの例 - - 21 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 1. 決定論的方策(例:100%の確率で下) 2. 確率論的方策(例:50%の確率でランダ ムに右 or 下を選択)
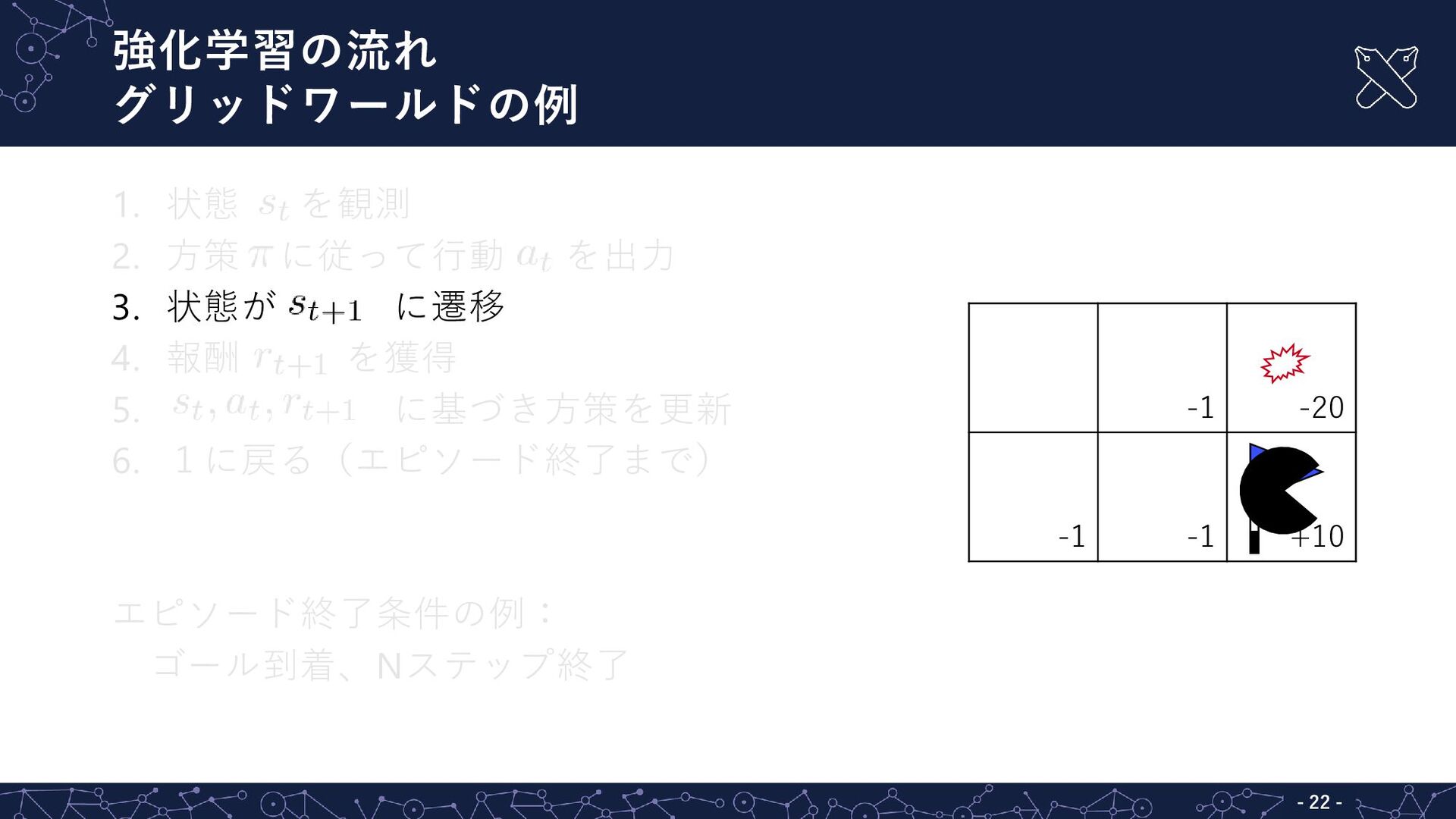
強化学習の流れ グリッドワールドの例 - - 22 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10
強化学習の流れ グリッドワールドの例 - - 23 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 中下から右に進んだら、 +10ポイントだった
強化学習の流れ グリッドワールドの例 - - 24 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 エピソード終了
強化学習の流れ グリッドワールドの例 - - 25 1. 状態 を観測(2エピソード目) 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 状態:左上
強化学習の流れ グリッドワールドの例 - - 26 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 1エピソード目では下に進んだら-1の 報酬だった →右に進む確率が上昇
強化学習の流れ グリッドワールドの例 - - 27 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10 報酬:ー1ポイント
強化学習の流れ グリッドワールドの例 - - 28 1. 状態 を観測 2. 方策
に従って行動 を出力 3. 状態が に遷移 4. 報酬 を獲得 5. に基づき方策を更新 6. 1に戻る(エピソード終了まで) エピソード終了条件の例: ゴール到着、Nステップ終了 -1 -20 -1 -1 +10
強化学習の目的は収益を最大化する方策を得ること - - 29 ▪ 収益(return)=報酬の割引総和 ▪ 割引率(discount rate) (
): 遠い未来ほど減衰させ、 無限和が発散しないようにする ▪ 注意 ▪ 収益は単純な報酬の総和ではないし、次時刻の報酬のみでもない
マルコフ決定過程として問題をモデル化する - - 30 ▪ マルコフ決定過程(Markov Decision Process, MDP)を用いて時間発 展を記述
(有限) (1次の)マルコフ性: を決めるのは時刻 時点での情報のみであり、 以 前の履歴は一切関係しない 影響しないと仮定する 例:将棋で次の盤面は現在の盤面と指し手のみで決定可能(※千日手は例外)
強化学習の定式化: 収益の最大化を考えるために以下を用いて定式化する - - 31 ▪ 状態遷移(state transition):各状態間の遷移を記述 ▪ 報酬:報酬
r が得られる分布 ▪ 方策:ある状態においてどの行動を取るか
強化学習の定式化: 状態遷移確率 - - 32 ▪ エージェントが状態sにおいて行動aをとったときに、次の状態s’に遷 移する確率 ▪ 方策πに従う場合の状態遷移確率
方策 添字のtで時刻tにおける変数を表している s’は「左上」等を表す 当たり前のことを数式化
強化学習の定式化: 報酬 - - 33 ▪ 報酬 r は以下の条件付き確率分布から生成されるものとする ↑「状態sにいて行動aをとってs’に遷移したら報酬rが得られた」
▪ 時刻t+1で得られる報酬の条件付き期待値
状態価値関数 - - 34 ▪ 状態価値関数(state value function):状態における収益の期待値 ある状態がどれだけ良いのかを表す
最良の方策が満たすべき方程式 - - 35 ▪ 最適方策(optimal policy) ▪ 期待収益を最大化する方策 ▪
強化学習の目的=最適方策(に近い方策)を探索 ▪ ベルマン最適方程式(Bellman optimality equation) ▪ 最適方策が見つかったとして、その方策が満たすべき性質を表す 行動1 行動2 状態1 0.9 0.1 状態2 0.5 0.5
ベルマン最適方程式に関するよくある疑問 - - 36 ▪ Q.ベルマン最適方程式を導出した後どうなるか? ▪ 「とはいえ、この前提(後述)が満たされないので異なるアプロー チ(強化学習の各手法)をとる」 ▪
Q.では、なぜベルマン最適方程式を考えるのか? ▪ 前提が満たされている問題(強化学習を使う必要はない)と、そう でない問題に分ける ▪ 強化学習手法はベルマン方程式に基づくものが多いので、統一的に 理解できる ▪ Q. ベルマン最適方程式の導出は当たり前のように見えるが? ▪ その通り。仰々しく感じる人も多い
最適方策は状態価値関数を最大化するはず - - 37 ▪ 状態価値関数 :状態sにおける方策πのもとでの期待収益 ▪ 状態価値関数の最大化 ▪
では はどのように得られるか? ←全パターンについて期待収益を計算すれば 当然最大値 が見つかるという意味 自体に似ているので 再帰的に定義できそう →遷移先s’を考えよう
状態価値関数を再帰的に求めたい - - 38 自体に似ているので 再帰的に定義できそう →遷移先s’を考えよう
状態価値関数を再帰的に求めたい 第1項 - - 39 自体に似ているので 再帰的に定義できそう →遷移先s’を考えよう 状態sで行動a を取る確率
報酬 状態s・行動a→遷移先s’ への遷移確率
状態価値関数を再帰的に求めたい 第2項 - - 40 自体に似ているので 再帰的に定義できそう →遷移先s’を考えよう 遷移先の状態価値 状態sで行動a
を取る確率 状態s・行動a→遷移先s’ への遷移確率
状態価値に関するベルマン方程式(Bellman equation) - - 41 遷移先の状態価値
行動価値関数とは - - 42 ▪ 行動価値関数(action-value function) ▪ 状態sにおいて行動aを選択したときの期待収益 ▪
最適方策は行動価値関数を最大化するはず ▪ ↔状態sの期待収益は状態価値関数 ▪ 状態価値関数と同様(=再帰的)に、行動価値関数のベルマン方程式 を導出できる ▪ 付録参照
ベルマン最適方程式 [Bellman, 1957] - - 43 最適状態価値関数 最適行動価値関数 Q学習(後述)では下線 部が利用されている
最適方策をベルマン最適方程式から導ける場合とは - - 48 ▪ 遷移確率 ▪ 期待報酬 が与えられる 最適方策がベルマン最適方程式か
ら直接求まる 動的計画法(強化学習以前の手 法)で十分 以降では、これらが未知である場合を考える 強化学習の仮定→ 環境の情報が未知であること
価値ベースと方策ベース 価値ベース(value-based methods) 行動価値関数 を学習し,その値に基づき行動を選択 特徴:学習速度が速い / 間接的
/ 行動空間が連続だと使えない アルゴリズム:Sarsa / Q学習 / … 方策ベース(policy-based methods) 方策関数 を学習し,その方策から行動を選択 特徴:学習速度が遅い / 価値関数を経由せず直接的 / 行動空間が連続でも使える アルゴリズム:Vanilla policy gradient / REINFORCE / … Actor-critic Actor(方策関数)とcritic(価値関数)の両方を学習 - - 49
価値関数の推定 ベルマン方程式から価値関数を求めるためには? 状態遷移確率が必要 一般的に未知 状態遷移確率を陽に使わずに試行錯誤的な経験によって価値関数を求める (TD学習:temporal
difference learning) TD学習の方法 Sarsa 行動価値関数のベルマン方程式に基づく学習法 Q学習 最適行動価値関数のベルマン最適方程式に基づく学習法 - - 50
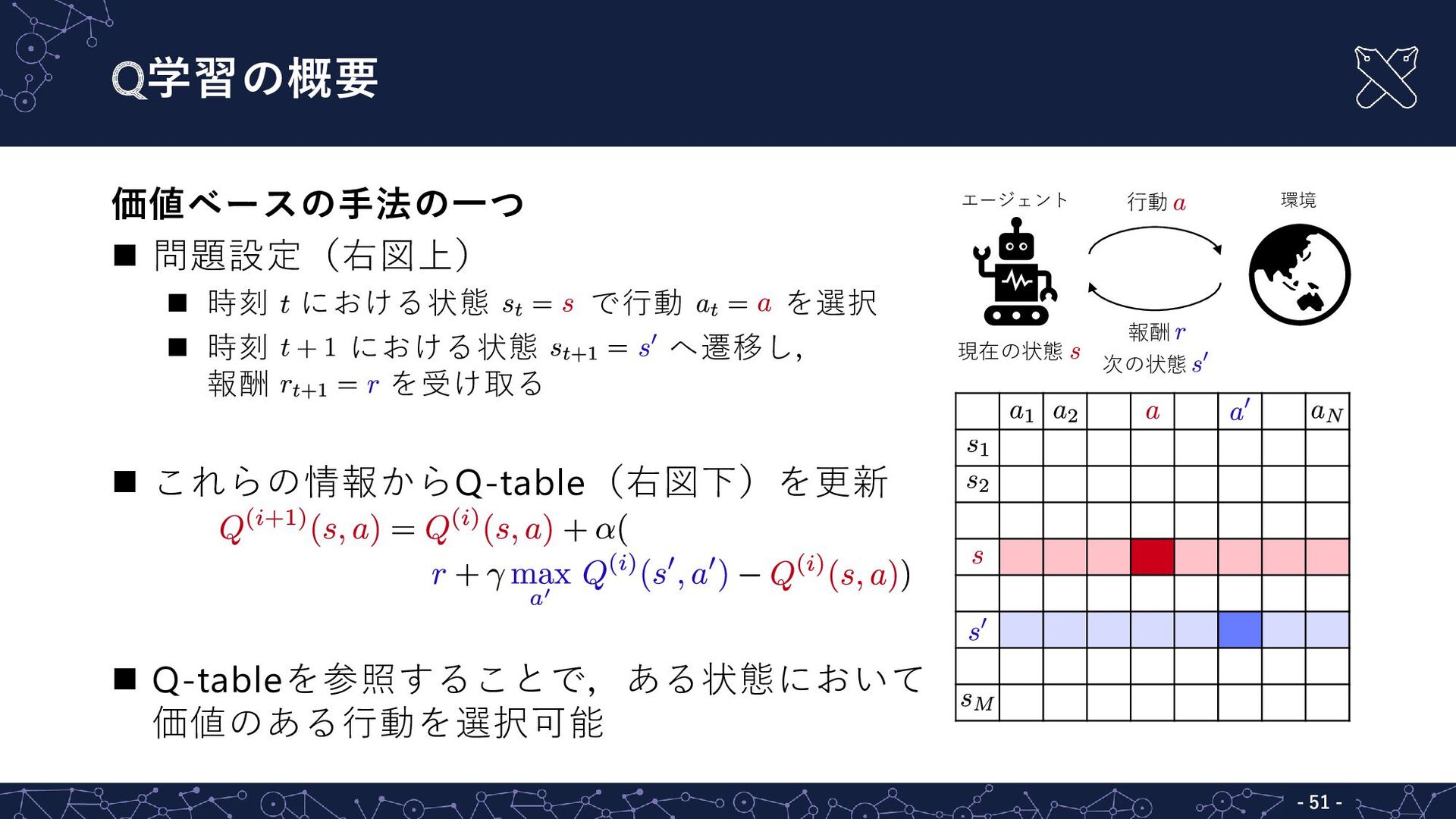
Q学習の概要 価値ベースの手法の一つ 問題設定(右図上) 時刻 における状態 で行動 を選択
時刻 における状態 へ遷移し, 報酬 を受け取る これらの情報からQ-table(右図下)を更新 Q-tableを参照することで,ある状態において 価値のある行動を選択可能 - - 51 行動 報酬 現在の状態 次の状態 エージェント 環境
Q学習の方法 行動価値関数に対するベルマン最適方程式(再掲) 再帰計算の導入によって期待値計算が不要 状態遷移確率 や報酬関数 を知っている必要がある
試行錯誤的な経験によって価値関数を求める Q値の更新式: :時刻 において 回目の更新がされている行動価値 :状態 における行動価値の最大値 は が最大となる行動で,実際の行動 は自由に選択可能 Temporal Difference Error(TD誤差)を小さくする - - 52
Q学習における行動の選択(方策) 利用と探索のトレードオフ(exploitation-exploration trade-off) グリーディ(貪欲)法(greedy method) 探索が起こらない
ランダム法(random method) あらゆる行動を等確率で選択 行動価値が更新されても効果的な知識利用ができない ε-グリーディ法(ε-greedy method) 確率 でランダム法,確率 でグリーディ法に基づき行動を選択 - - 53
Q学習とSarsa 行動価値の更新式の違い Q学習(方策オフ型:off-policy) は が最大となる行動 Sarsa(方策オン型:on-policy)
は実際に選択する行動 - - 54 https://qiita.com/triwave33/items/cae48e492769852aa9f1
を初期化 for to do を観測 repeat で方策(ε-グリーディ法)に従って を選択して行動 環境から と
を観測 行動価値の更新式に従って を更新 , とする until ゴールに到達 / 終了条件に到達 end for Q学習の流れ - - 55
方策勾配法(policy-gradient Method) 方策ベースの手法の一つ 方策をパラメータ付けられた関数でモデル化 長期間の報酬の期待値 を最大化するように を更新する
勾配上昇法 方策勾配の推定法 REINFORCE [Williams 1992] 自然方策勾配法 - - 56
方策勾配定理とREINFORCE 方策勾配定理 長期間の報酬の期待値の勾配を行動価値関数を用いて表す パラメータ更新を方策勾配法で解くことが可能 状態 ,行動 に関する期待値計算
は方策に基づき行動をして得られた サンプルを利用してモンテカルロ近似で求める REINFORCE REward Increment = Nonnegative Factor × Offset Reinforcement × Characteristic Eligibility 方策勾配定理の行動価値関数を(即時)報酬で代用する手法 - - 57
強化学習と他分野との関連 ▪ 最適制御理論(1950s-) ▪ 評価関数を最大化する制御則を求める問題 ▪ 動的計画法(1940s-) ▪ 評価関数を最大化する経路決定問題 ▪
システム同定(1970-) ▪ 確率システムのパラメータ推定 ▪ 能動学習(1920s-) ▪ アルゴリズムが訓練サンプルを選択できる機械学習問題 ▪ 強化学習の探索部分に相当 Copy right © Keio
深層強化学習 - - 59
深層強化学習 価値関数や方策関数をニューラルネットワークで表現 Deep Q-network (DQN) [Mnih+ 2013, Mnih+ 2015]
CNNを用いてゲームの画像情報から 行動価値関数を学習 この後簡単に説明 AlphaGo [Silver+ 2016] CNNを用いて碁の盤面から 方策 / 状態価値関数を学習 モンテカルロ木探索 - - 60
Q-tableとDQN Q-table 有限個の状態に おける行動価値を保持 - - 61 st 行動価値
状態 DQN 画像情報(状態 )から行動価値を予測
DQNの入出力 入力 ゲームの連続する4フレーム分の画像(状態) 行動パターン 9×2 = 18個 操縦ハンドル(動かさない
/ 上下左右斜め) 9個 トリガボタン(押す / 押さない) 2個 出力 18個の行動パターンに対応する行動価値 - - 62 ……
DQNのネットワーク構造 入力層 84×84×4の白黒画像 連続する4フレーム 隠れ層 3層の畳み込み層
2層の全結合層 出力層 18次元の 5000万フレーム 1ヶ月の学習 - - 63
DQNにおける工夫 経験リプレイ(experience replay)を用いたミニバッチ学習 事前にプレイして取得した経験 からランダムに選択 データの偏りを防ぎ学習の安定化を実現 標的ネットワーク(target network)を用いた教師データの生成
一定期間標的ネットワークのパラメータを固定 TD誤差が安定し学習の安定化を実現 Reward clippingを用いた報酬のスケール 報酬 を の範囲にクリップ 勾配が理不尽に大きくなることを防ぎ学習の安定化を実現 - - 64
DQNによる「Breakout」のプレイ - - 65
強化学習アルゴリズム全体像 - - 66 https://pbs.twimg.com/media/EheX1UXVgAQdOpP?format=jpg&name=large
本講義全体の参考図書 - - 67 ▪ ★機械学習スタートアップシリーズ これならわかる深層学習入門 瀧雅人著 講談 社(本講義では、異なる表記を用いることがあるので注意)
▪ ★Dive into Deep Learning (https://d2l.ai/) ▪ 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) 岡谷貴之著 講談社 ▪ ディープラーニングを支える技術 岡野原大輔著 技術評論社 ▪ 画像認識 (機械学習プロフェッショナルシリーズ) 原田達也著 講談社 ▪ 深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ) 坪井祐太、 海野裕也、鈴木潤 著、講談社 ▪ IT Text 自然言語処理の基礎 岡﨑直観、荒瀬由紀、鈴木潤、鶴岡慶雅、宮尾祐介 著、オーム社 ▪ 東京大学工学教程 情報工学 機械学習 中川 裕志著、東京大学工学教程編纂委員会 編 丸善出版 ▪ パターン認識と機械学習 上・下 C.M. ビショップ著 丸善出版
参考文献 - - 68 1. 強化学習,Richard Sutton, Andrew Barto著,森北出版 2.
ゼロから作る Deep Learning 4 ―強化学習編,斎藤康毅著,オライ リージャパン 3. Tesauro, G. (1992). Practical issues in temporal difference learning. Machine learning, 8(3), 257-277.
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第13回 強化学習の基礎](https://files.speakerdeck.com/presentations/c1005ea94a894b339defdf4bcde7d45b/slide_0.jpg){kind=link}
{kind=link}
![強化学習(reinforcement learning)の概要 - - 5 ▪ 1980年代:Suttonらによる研究 ▪ バックギャモンへの強化学習の適用[Tesauro, 1992]](https://files.speakerdeck.com/presentations/c1005ea94a894b339defdf4bcde7d45b/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ベルマン最適方程式 [Bellman, 1957] - - 43 最適状態価値関数 最適行動価値関数 Q学習(後述)では下線 部が利用されている](https://files.speakerdeck.com/presentations/c1005ea94a894b339defdf4bcde7d45b/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![深層強化学習 価値関数や方策関数をニューラルネットワークで表現 Deep Q-network (DQN) [Mnih+ 2013, Mnih+ 2015]](https://files.speakerdeck.com/presentations/c1005ea94a894b339defdf4bcde7d45b/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}