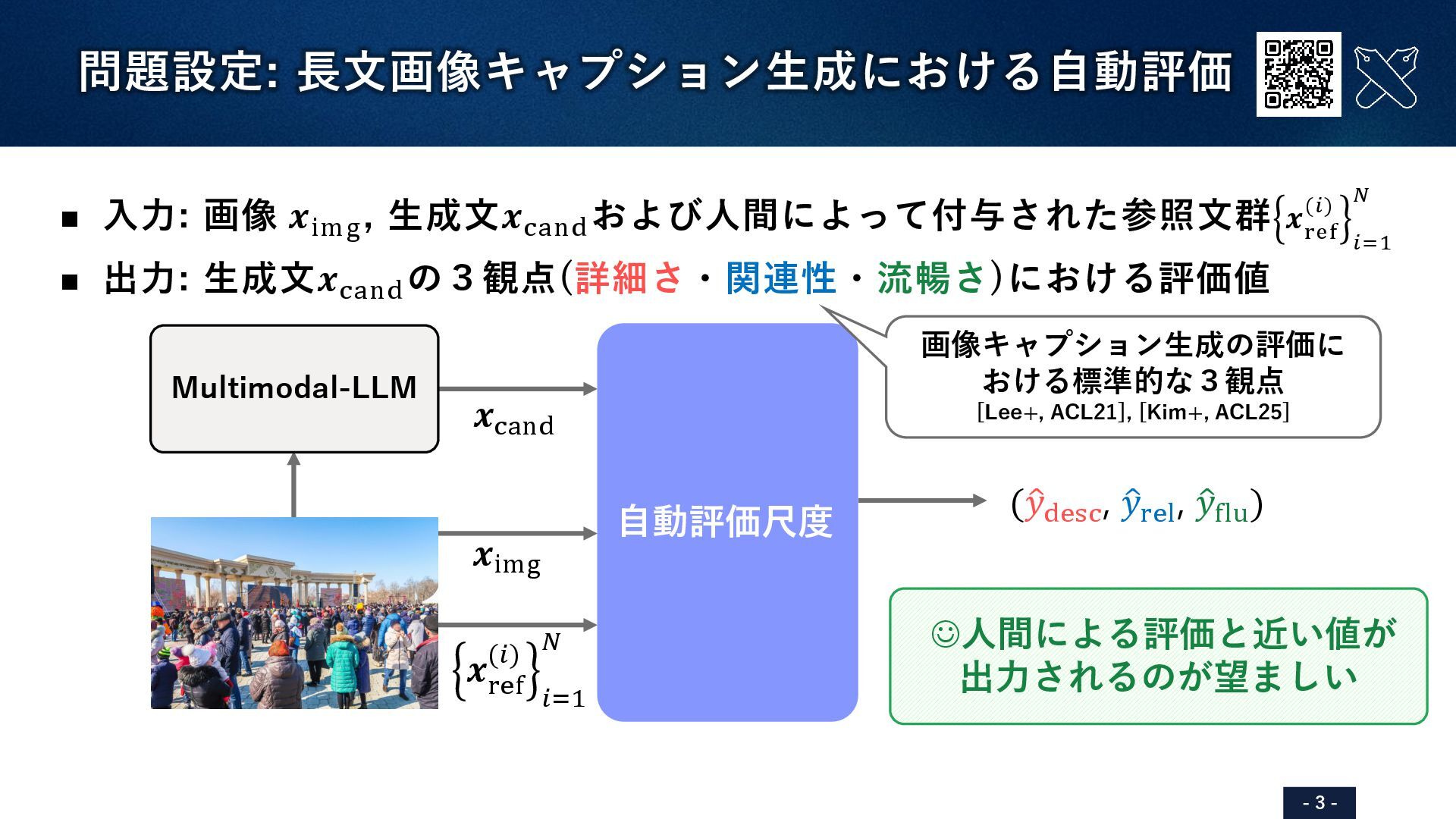
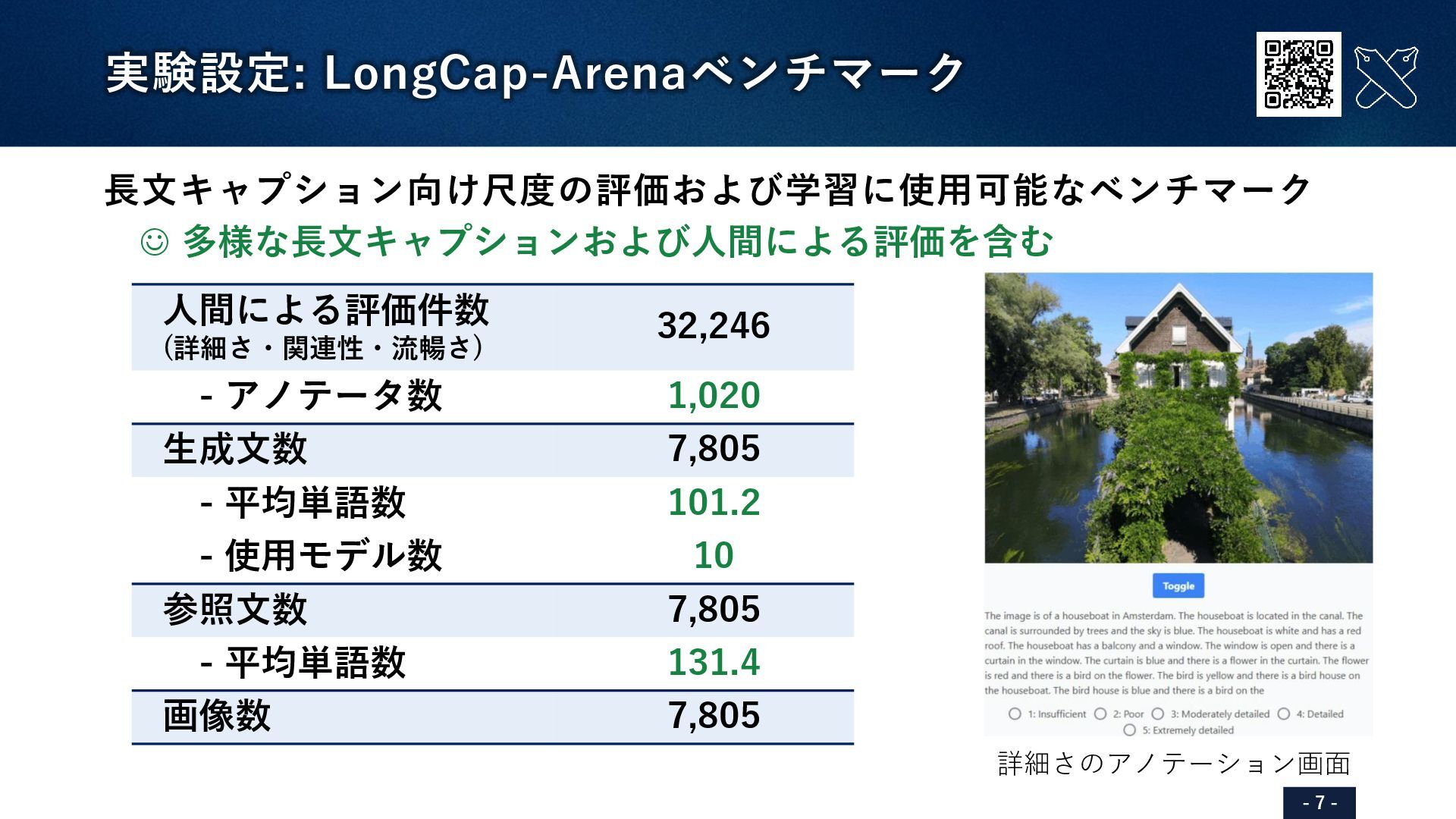
75/100 100/100 VELA (Ours) 70/100 59/100 91/100 人間による評価 75/100 50/100 100/100 InstructBLIP[Dai+, NeurIPS23]による生成文: “In the image, a large white and blue airplane is taking off from a grassy field. The plane is in the process of ascending into the sky, with its wheels still on the ground. There are several trees visible in the background, providing a natural setting for the airplane's takeoff. In addition to the main airplane, there are two smaller airplanes present in the scene...” ハルシネーションを含む&詳細さに欠ける ※評価値を0~100に正規化した値
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![尺度 TestA [𝝉𝒄] ↑ TestB [𝝉𝒄] ↑ 推論時間 [ms]↓ 詳細さ](https://files.speakerdeck.com/presentations/b48162d05a92475a9cbe7b0d985c90be/slide_7.jpg){kind=link}
![尺度 TestA [𝝉𝒄] ↑ TestB [𝝉𝒄] ↑ 推論時間 [ms]↓ 詳細さ](https://files.speakerdeck.com/presentations/b48162d05a92475a9cbe7b0d985c90be/slide_8.jpg){kind=link}
{kind=link}
{kind=link}