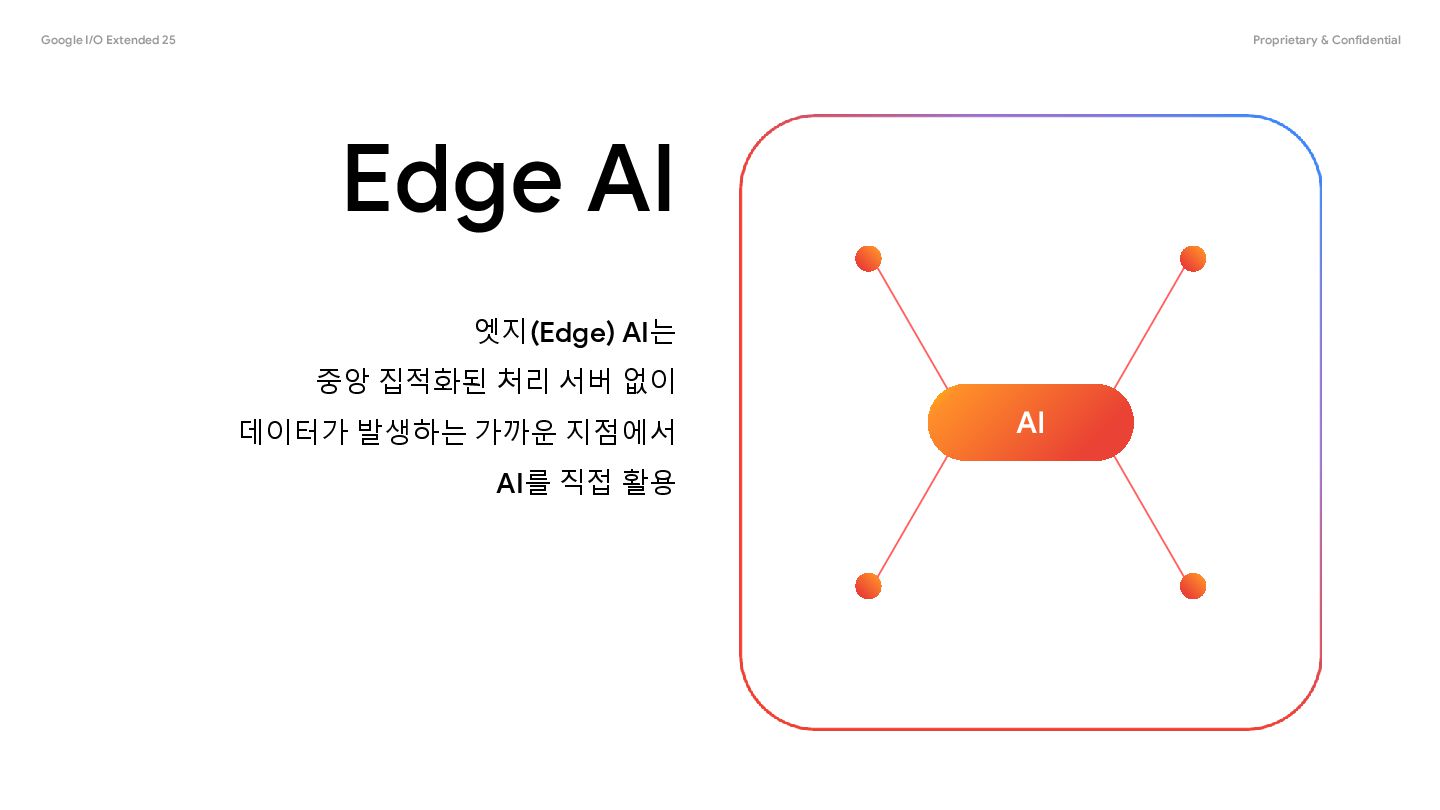
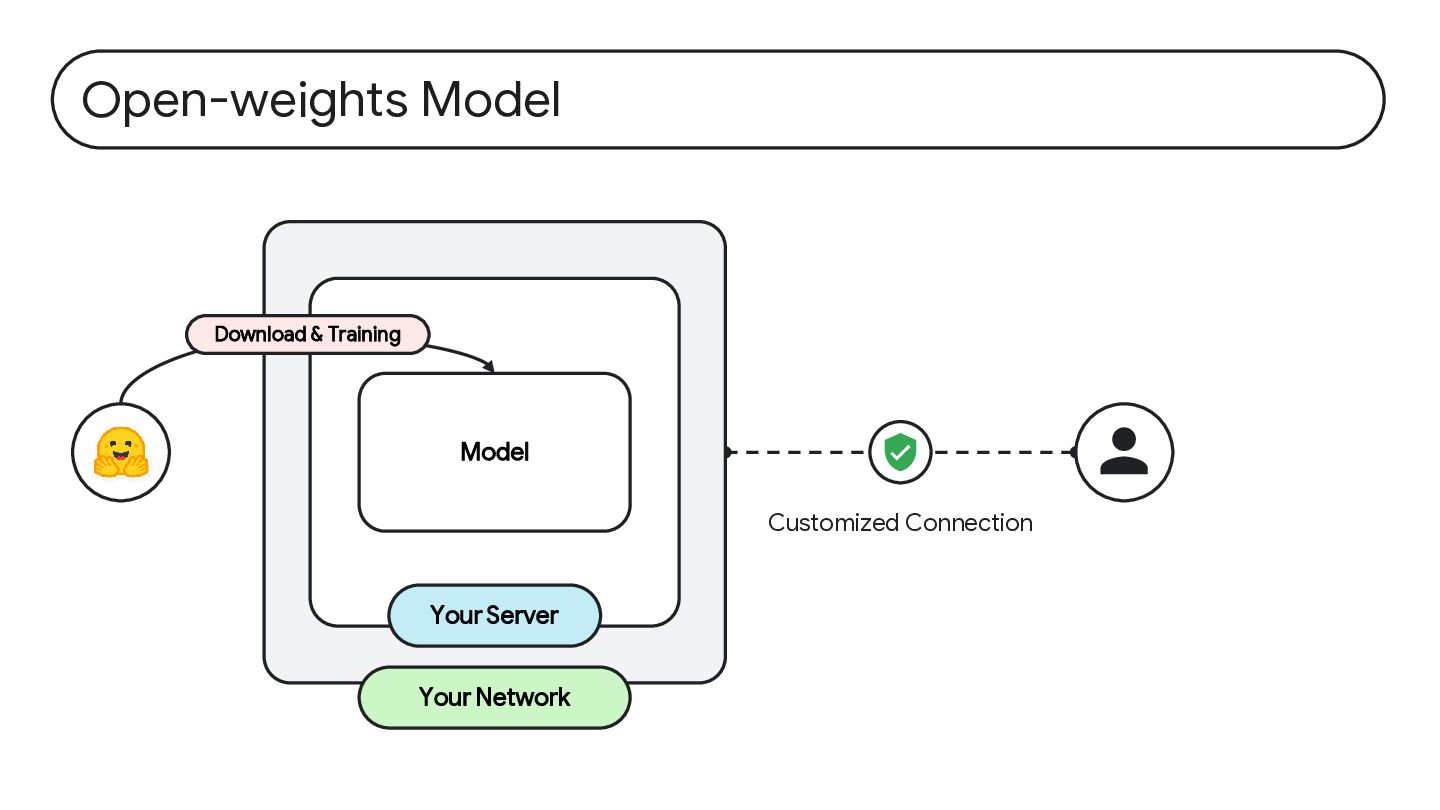
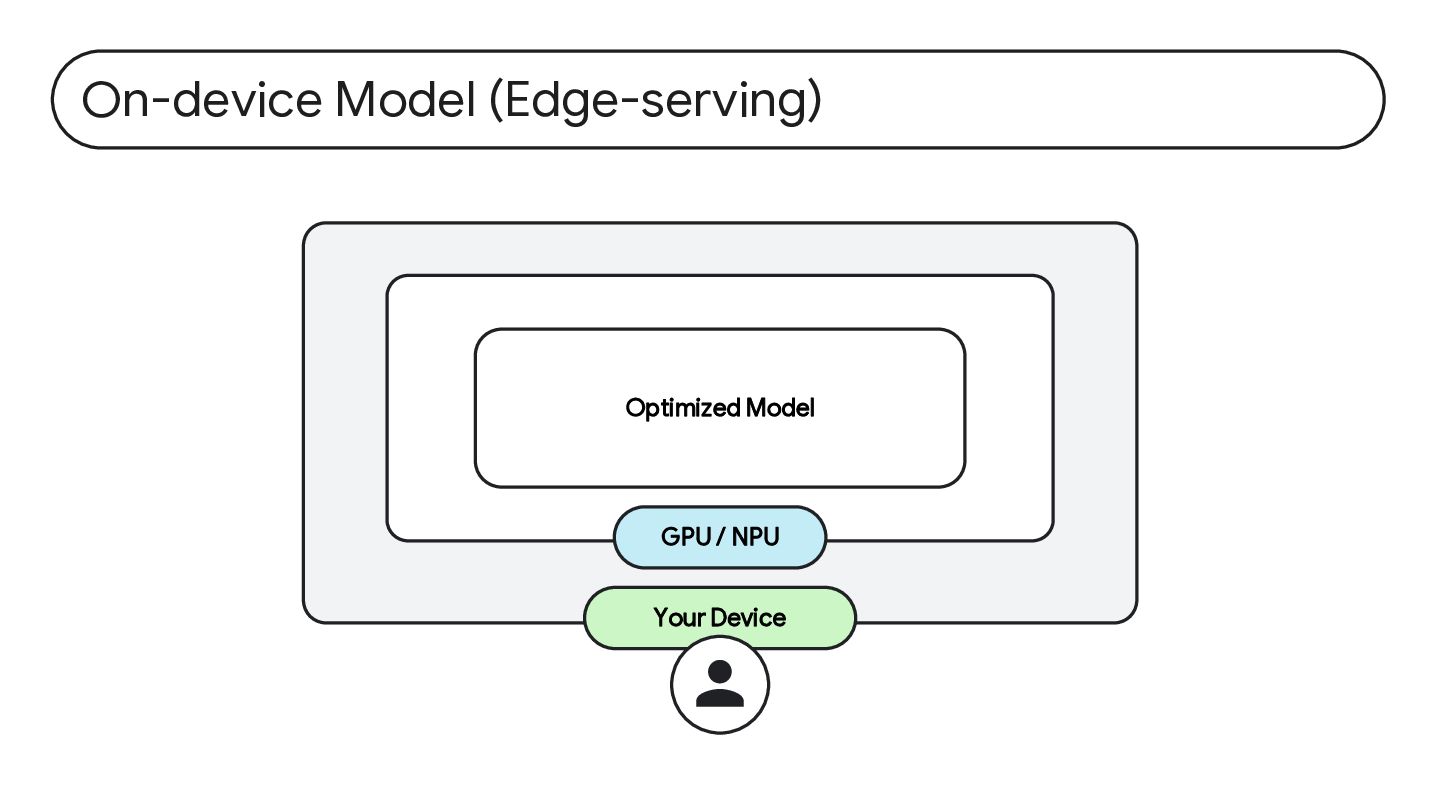
저비용 예측 가능한 비용 활용 및 컴퓨팅 효율화된 AI 모델을 사용으로 인한 비용 효율화 개인정보 보호 데이터가 발생한 지점 외에 데이터 전파가 일어나지 않 으므로 개인정보를 보호할 수 있음 투명성 가중치가 공개된 모델 활용 으로 인해 모델의 특성을 투명하게 확인할 수 있으며 , 필요에 따라 최신 미세조 정 및 정렬(Align) 기능 활 용 가능
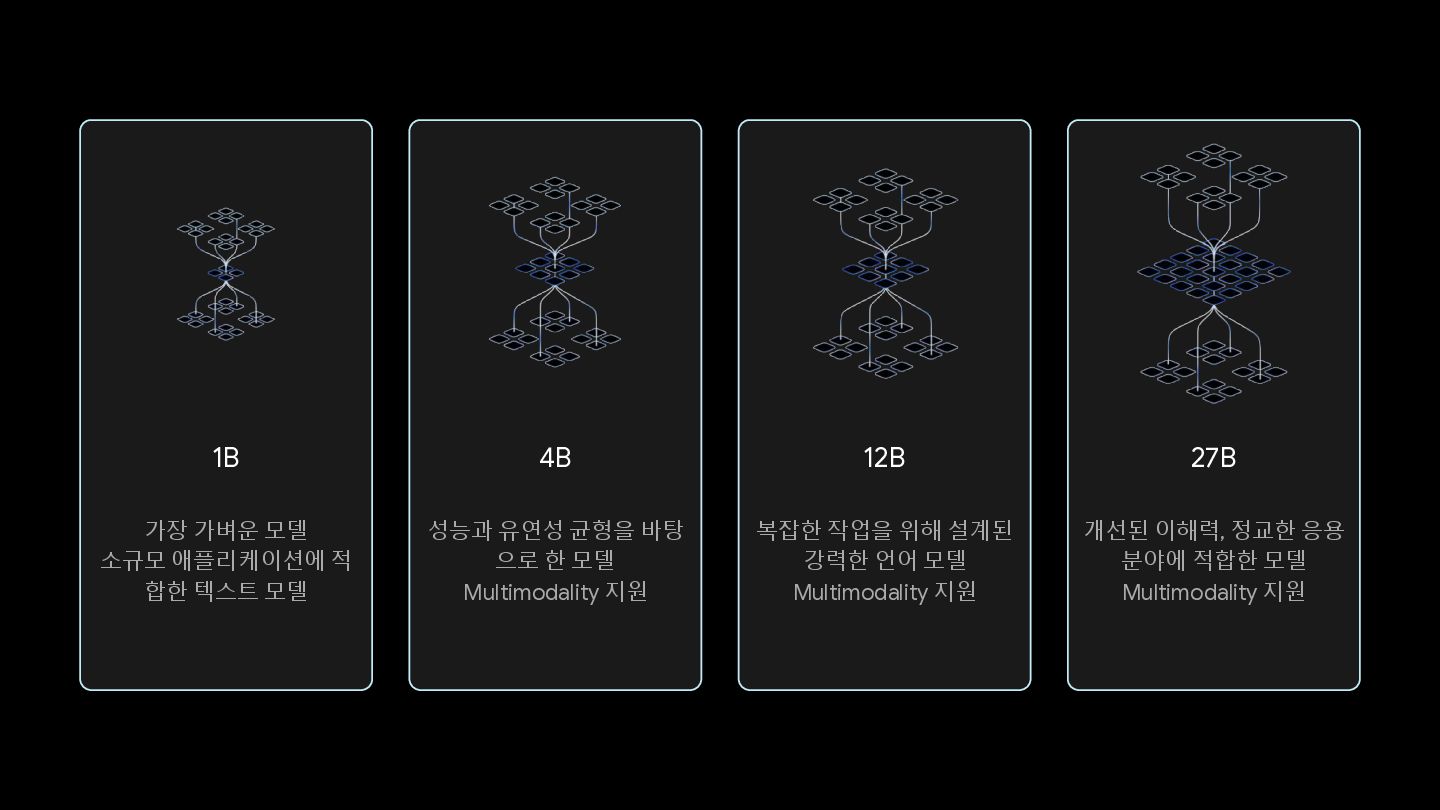
12B 7.55GB Video source: Google Deepmind https://deepmind.google/discover/blog/gemma-scope-helping-the-safety-community-shed-light-on-the-inner-workings-of-language-models/ 27B 27.05GB (int8)
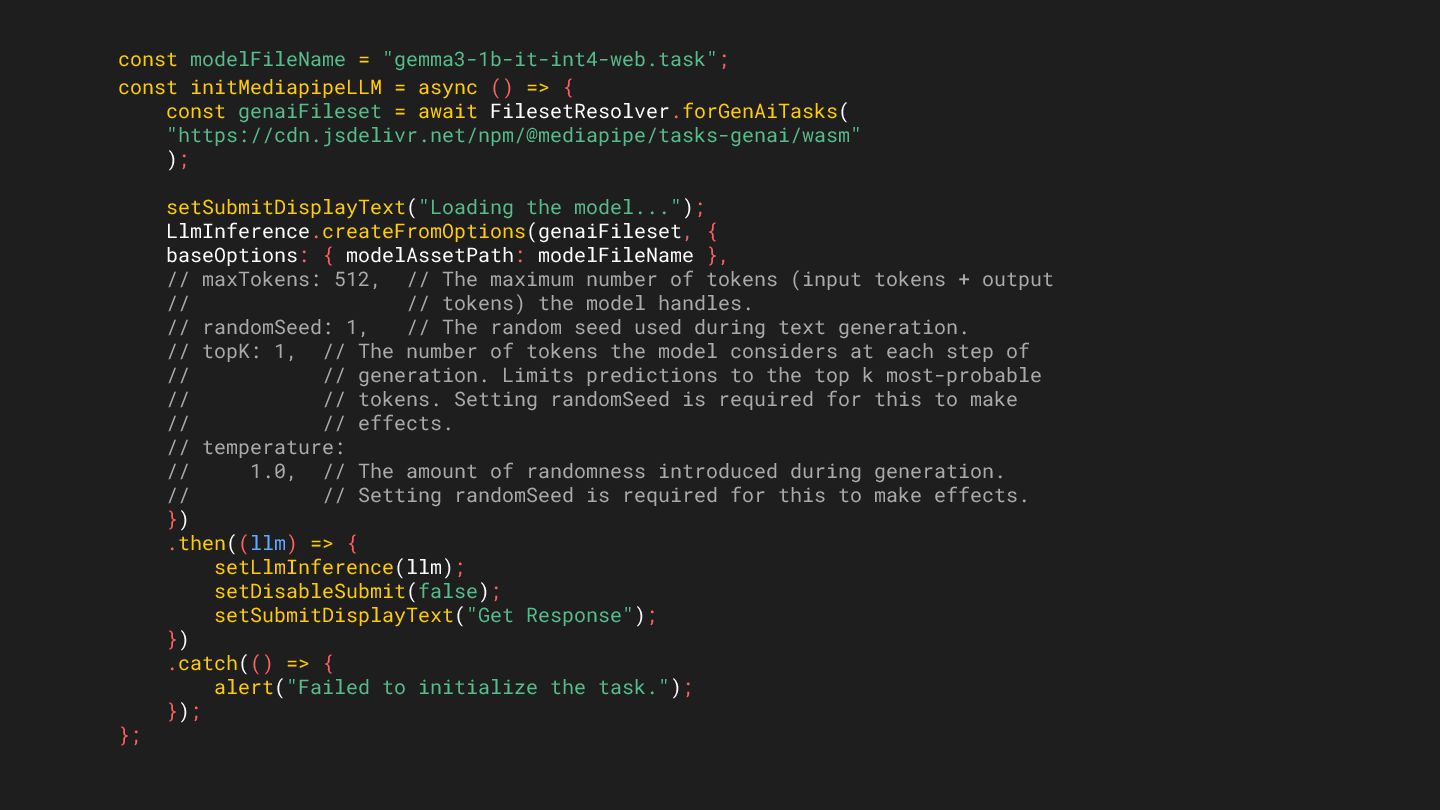
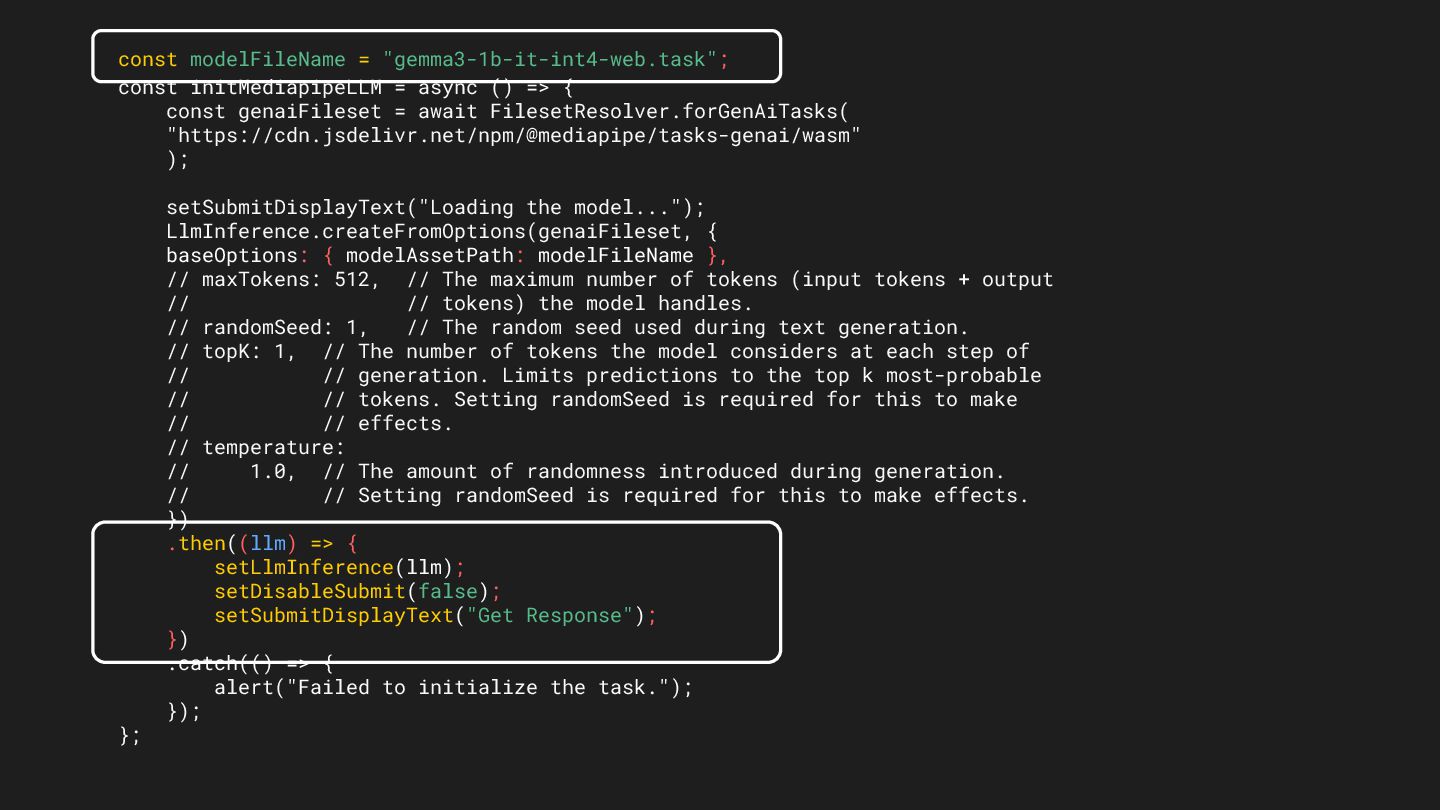
{ const genaiFileset = await FilesetResolver.forGenAiTasks( "https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai/wasm" ); setSubmitDisplayText("Loading the model..."); LlmInference.createFromOptions(genaiFileset, { baseOptions: { modelAssetPath: modelFileName }, // maxTokens: 512, // The maximum number of tokens (input tokens + output // // tokens) the model handles. // randomSeed: 1, // The random seed used during text generation. // topK: 1, // The number of tokens the model considers at each step of // // generation. Limits predictions to the top k most-probable // // tokens. Setting randomSeed is required for this to make // // effects. // temperature: // 1.0, // The amount of randomness introduced during generation. // // Setting randomSeed is required for this to make effects. }) .then((llm) => { setLlmInference(llm); setDisableSubmit(false); setSubmitDisplayText("Get Response"); }) .catch(() => { alert("Failed to initialize the task."); }); };
{ const genaiFileset = await FilesetResolver.forGenAiTasks( "https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai/wasm" ); setSubmitDisplayText("Loading the model..."); LlmInference.createFromOptions(genaiFileset, { baseOptions: { modelAssetPath: modelFileName }, // maxTokens: 512, // The maximum number of tokens (input tokens + output // // tokens) the model handles. // randomSeed: 1, // The random seed used during text generation. // topK: 1, // The number of tokens the model considers at each step of // // generation. Limits predictions to the top k most-probable // // tokens. Setting randomSeed is required for this to make // // effects. // temperature: // 1.0, // The amount of randomness introduced during generation. // // Setting randomSeed is required for this to make effects. }) .then((llm) => { setLlmInference(llm); setDisableSubmit(false); setSubmitDisplayText("Get Response"); }) .catch(() => { alert("Failed to initialize the task."); }); };
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
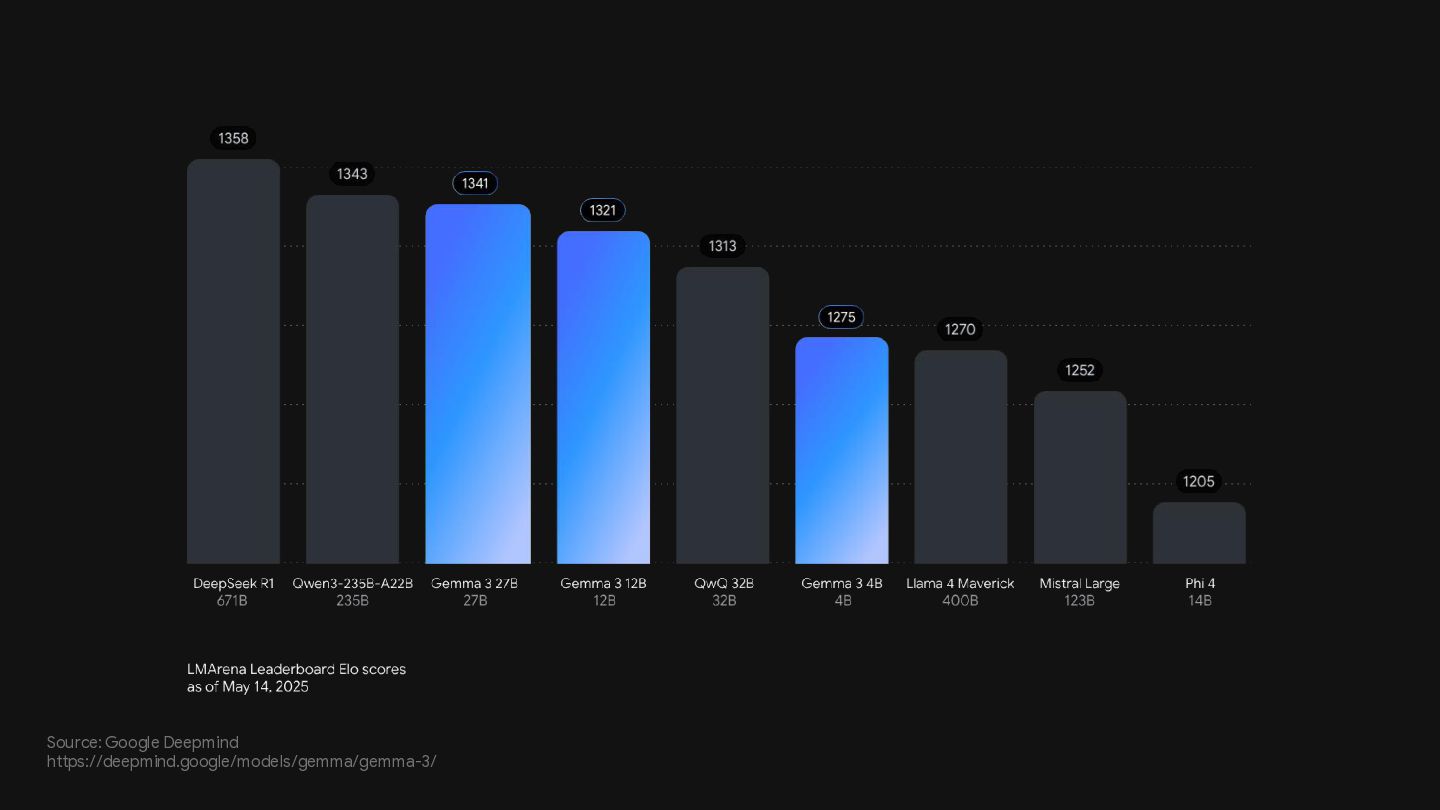{kind=link}
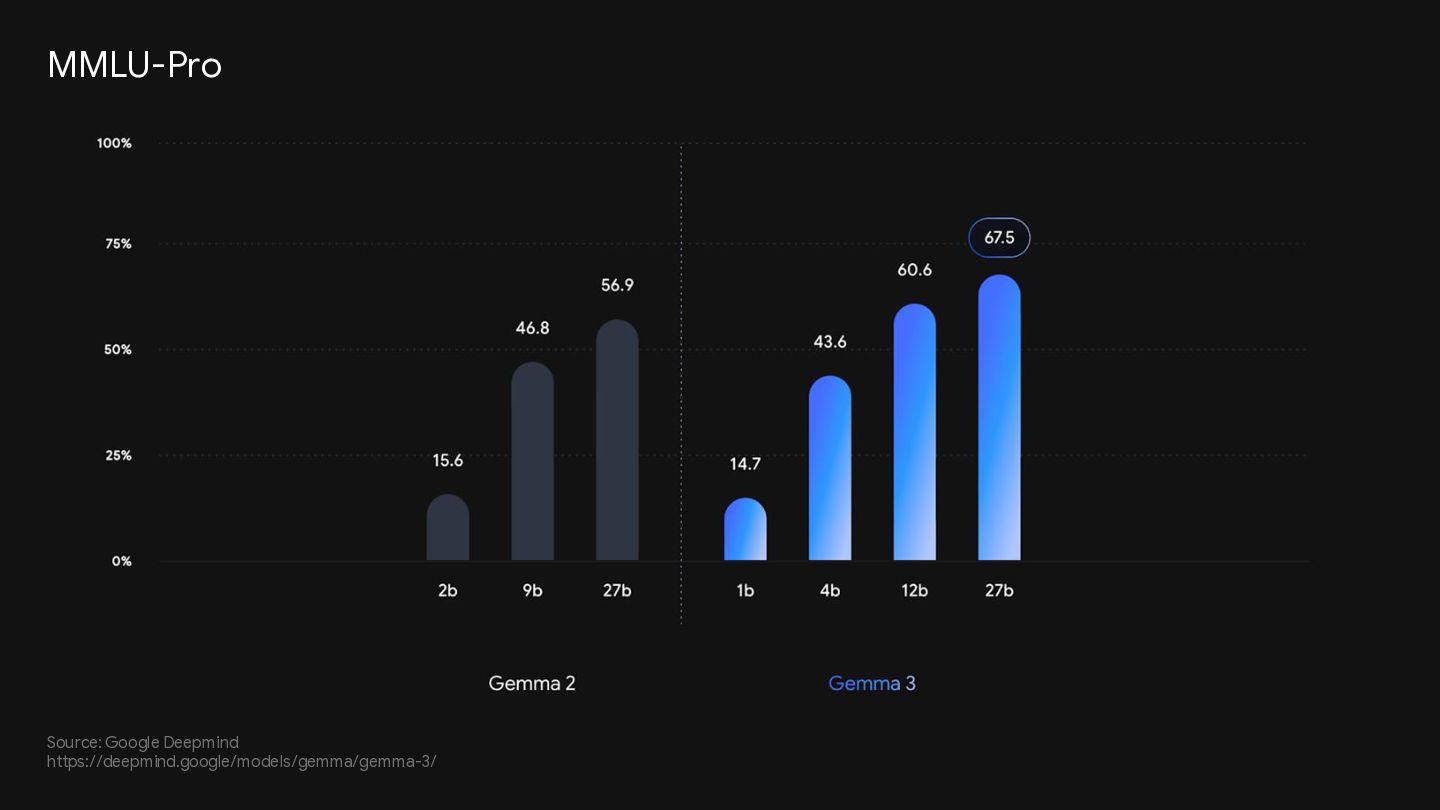{kind=link}
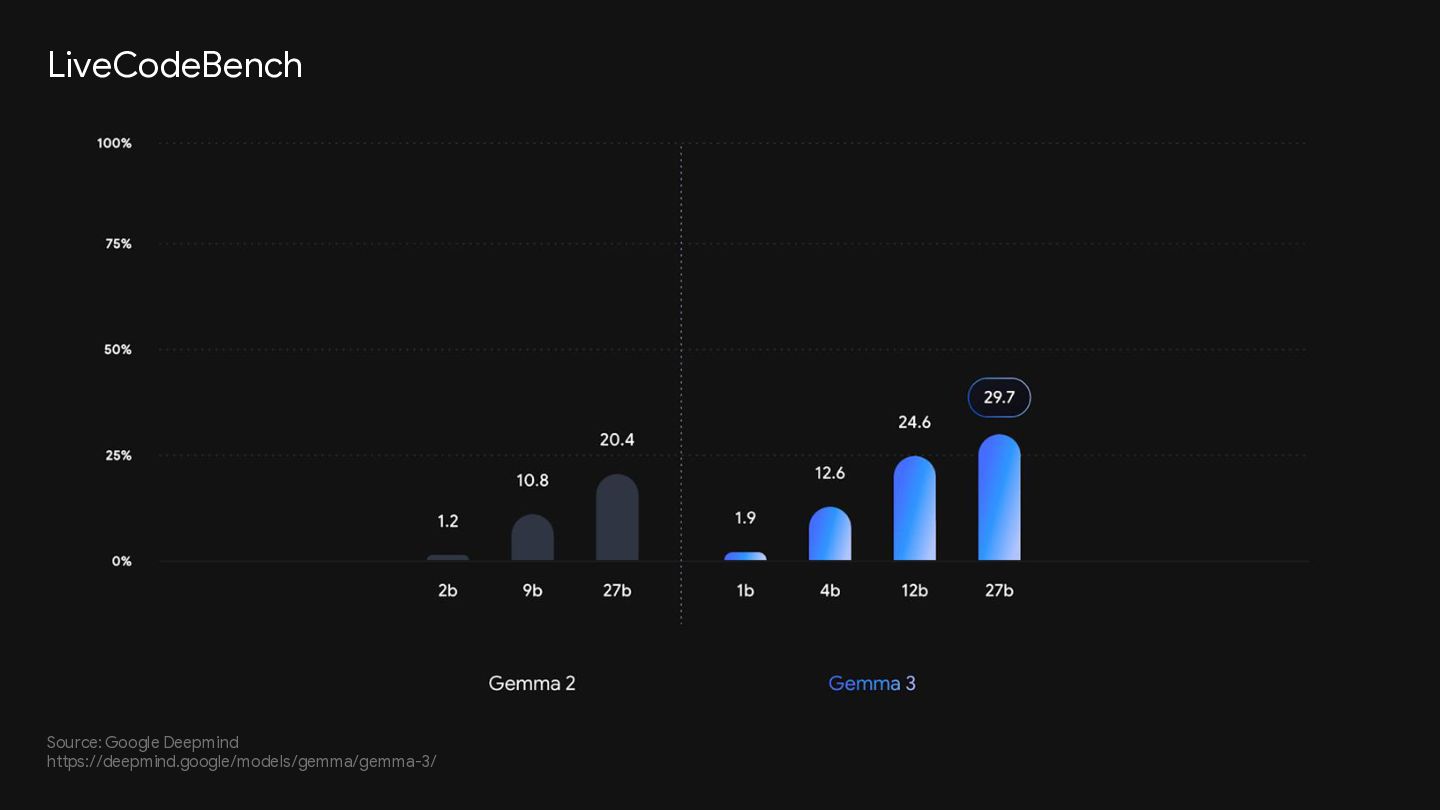{kind=link}
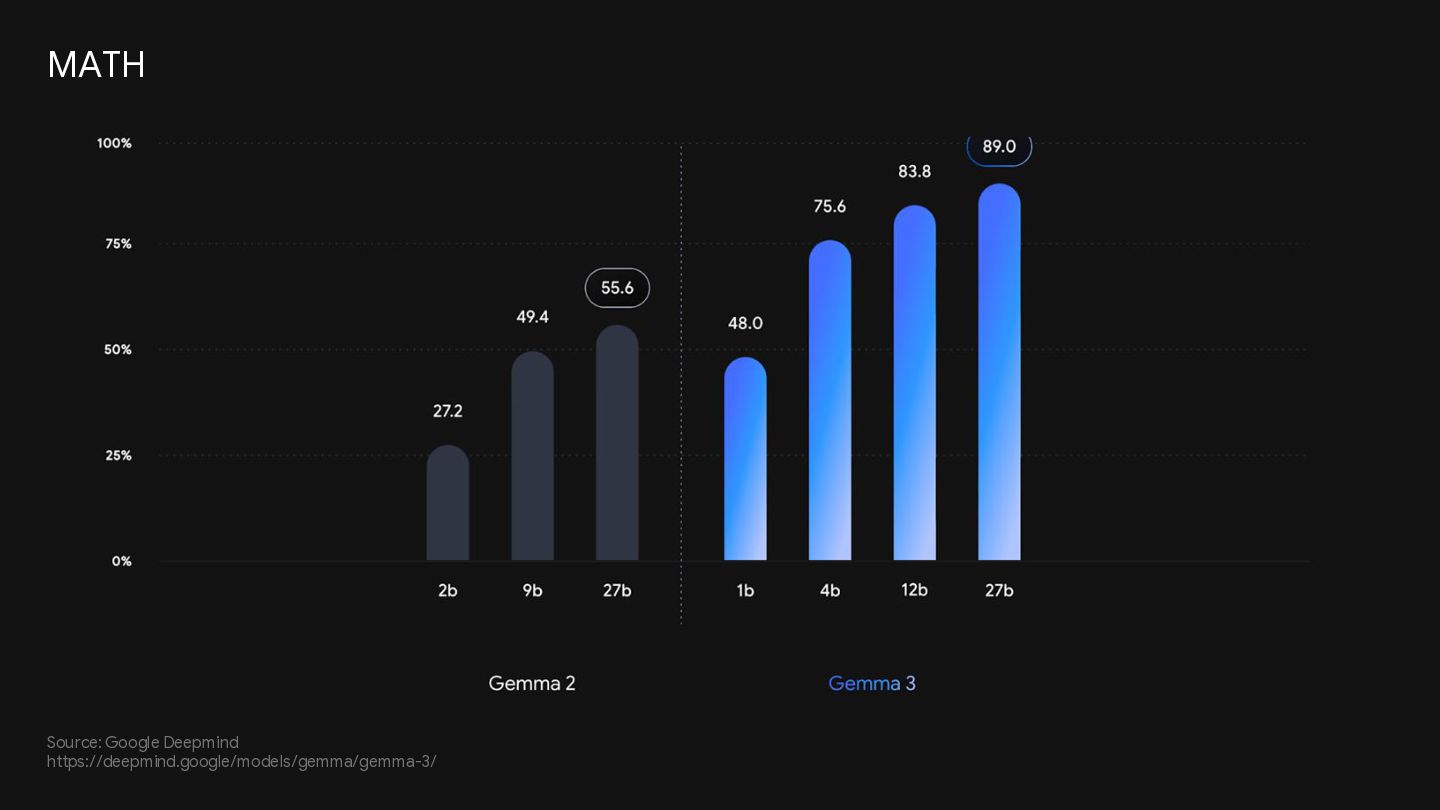{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}