Research engineer at Naver Clova Former Software engineer at IGAWorks Former Software engineer at 심심이 https://www.facebook.com/han.sungmin/ https://github.com/KennethanCeyer https://www.linkedin.com/in/sungmin-han-768419133/ [email protected]
0 for _ in range(10000000): sum_value += x return sum_value if __name__ == "__main__": with ThreadPoolExecutor(max_workers=10) as executor: res = executor.map(calc, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(list(res)) def calc(x: int) -> int: sum_value = 0 for _ in range(10000000): sum_value += x return sum_value if __name__ == "__main__": res = map(calc, [1, 2, 3]) print(list(res)) Thread: 4,116ms Single core: 1,208ms
Access & Update Variable - CPU Bound Function Call - Sys call - GC - Disk Read & Write - Network Communication - DB Connect & Requests - Audio Play - Sleep (In case of AsyncIO)
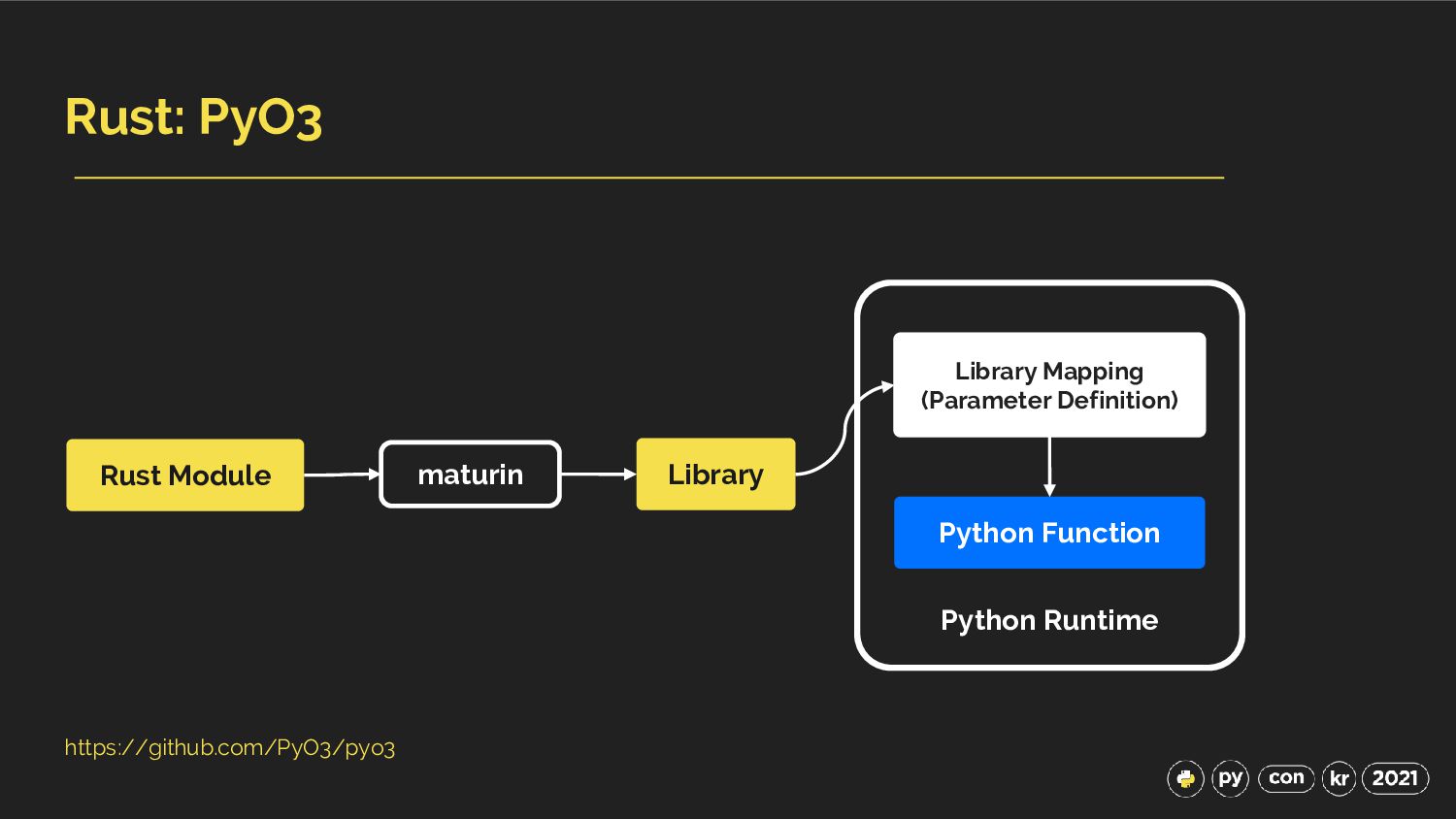
edition = "2018" [lib] name = "string_sum" # "cdylib" is necessary to produce a shared library for Python to import from. # # Downstream Rust code (including code in `bin/`, `examples/`, and `tests/`) will not be able # to `use string_sum;` unless the "rlib" or "lib" crate type is also included, e.g.: # crate-type = ["cdylib", "rlib"] crate-type = ["cdylib"] [dependencies.pyo3] version = "0.14.1" features = ["extension-module"] Cargo.toml
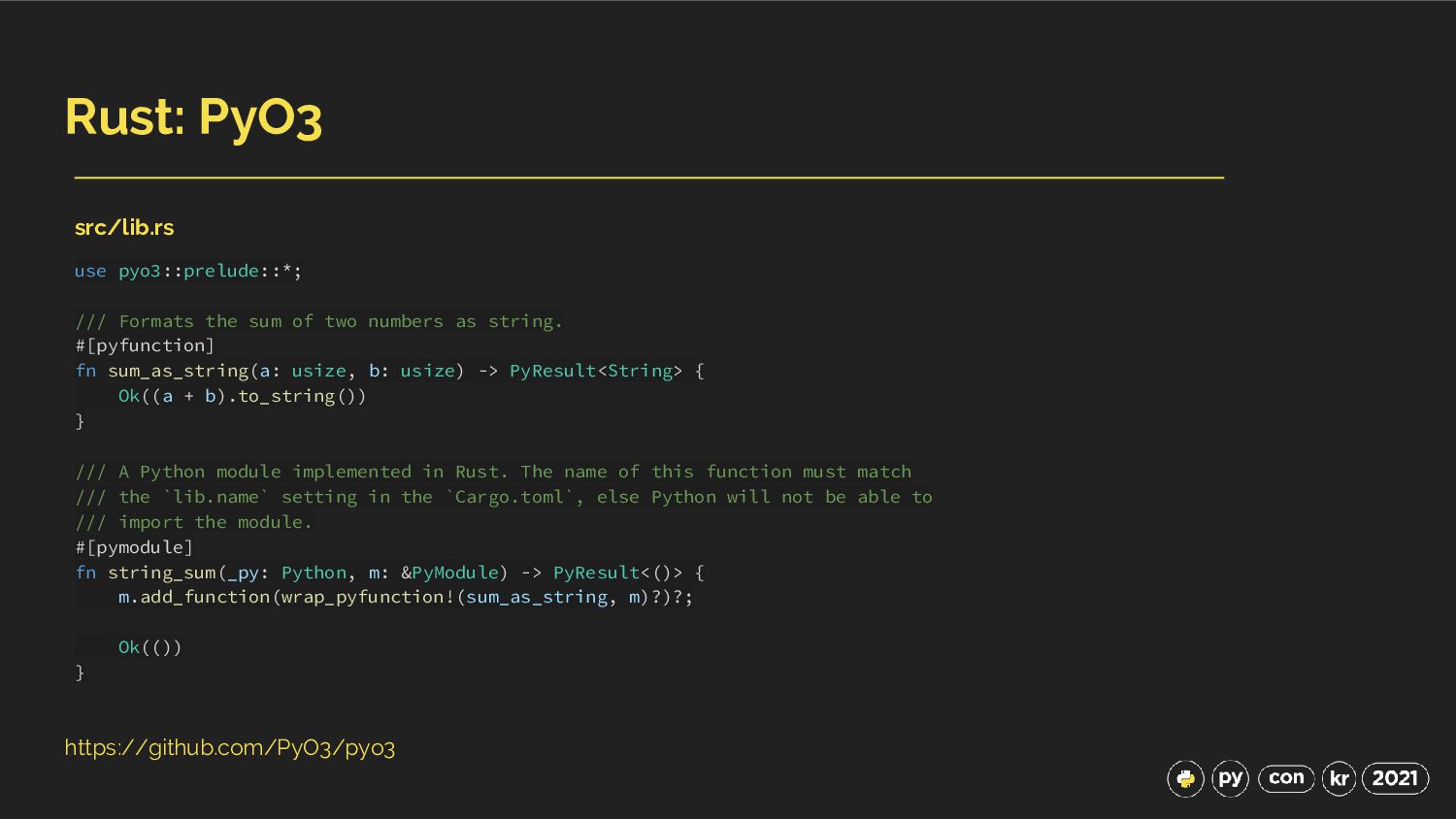
two numbers as string. #[pyfunction] fn sum_as_string(a: usize, b: usize) -> PyResult<String> { Ok((a + b).to_string()) } /// A Python module implemented in Rust. The name of this function must match /// the `lib.name` setting in the `Cargo.toml`, else Python will not be able to /// import the module. #[pymodule] fn string_sum(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(sum_as_string, m)?)?; Ok(()) } src/lib.rs
+ 4 8 + CPU Tick CPU Tick CPU Tick CPU Tick 6 8 10 12 Single Instruction Single Data Stream (SISD) 1 5 3 7 4 8 2 6 CPU Tick Single Instruction Multiple Data Stream (SIMD) + 6 8 10 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
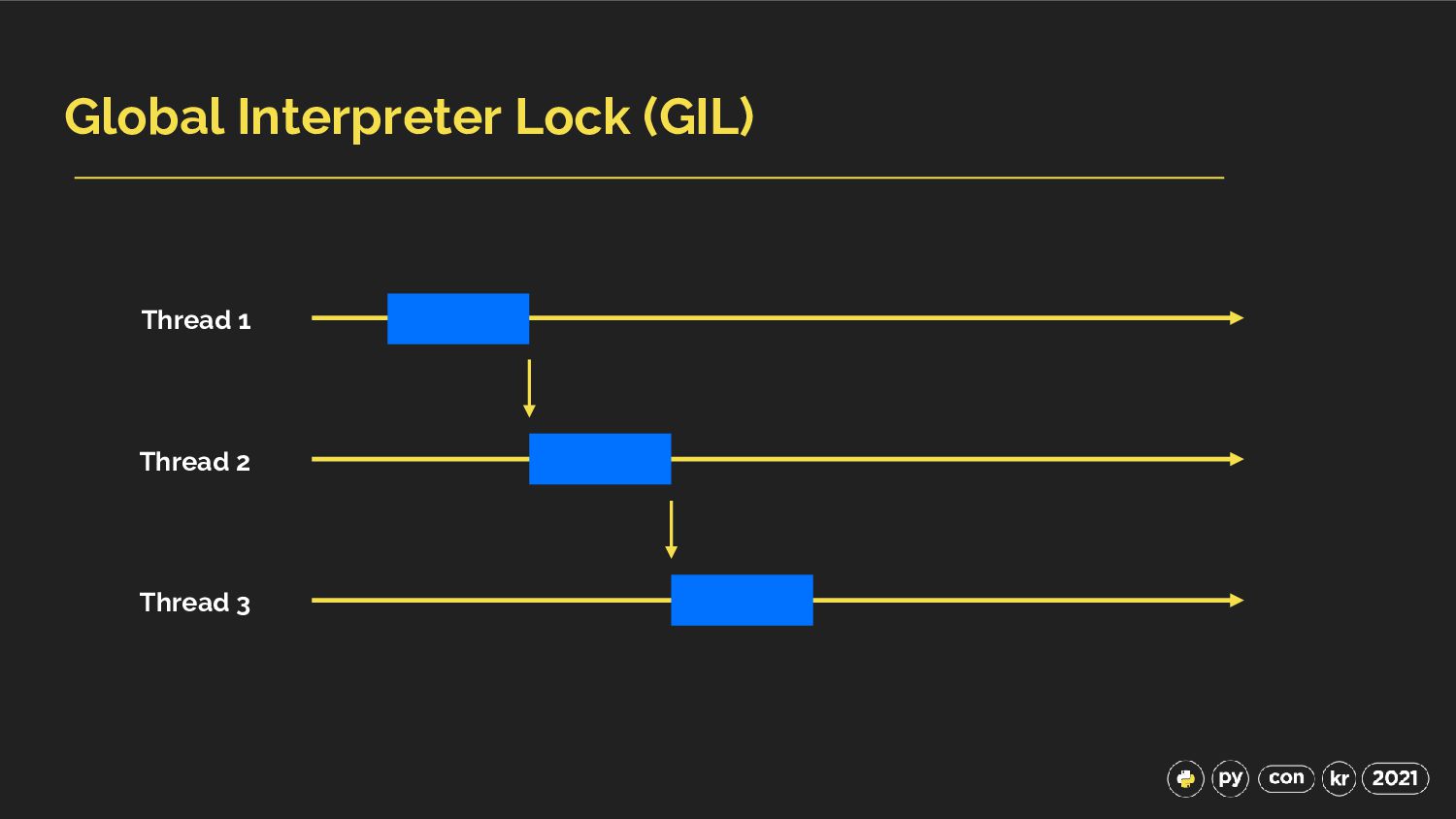{kind=link}
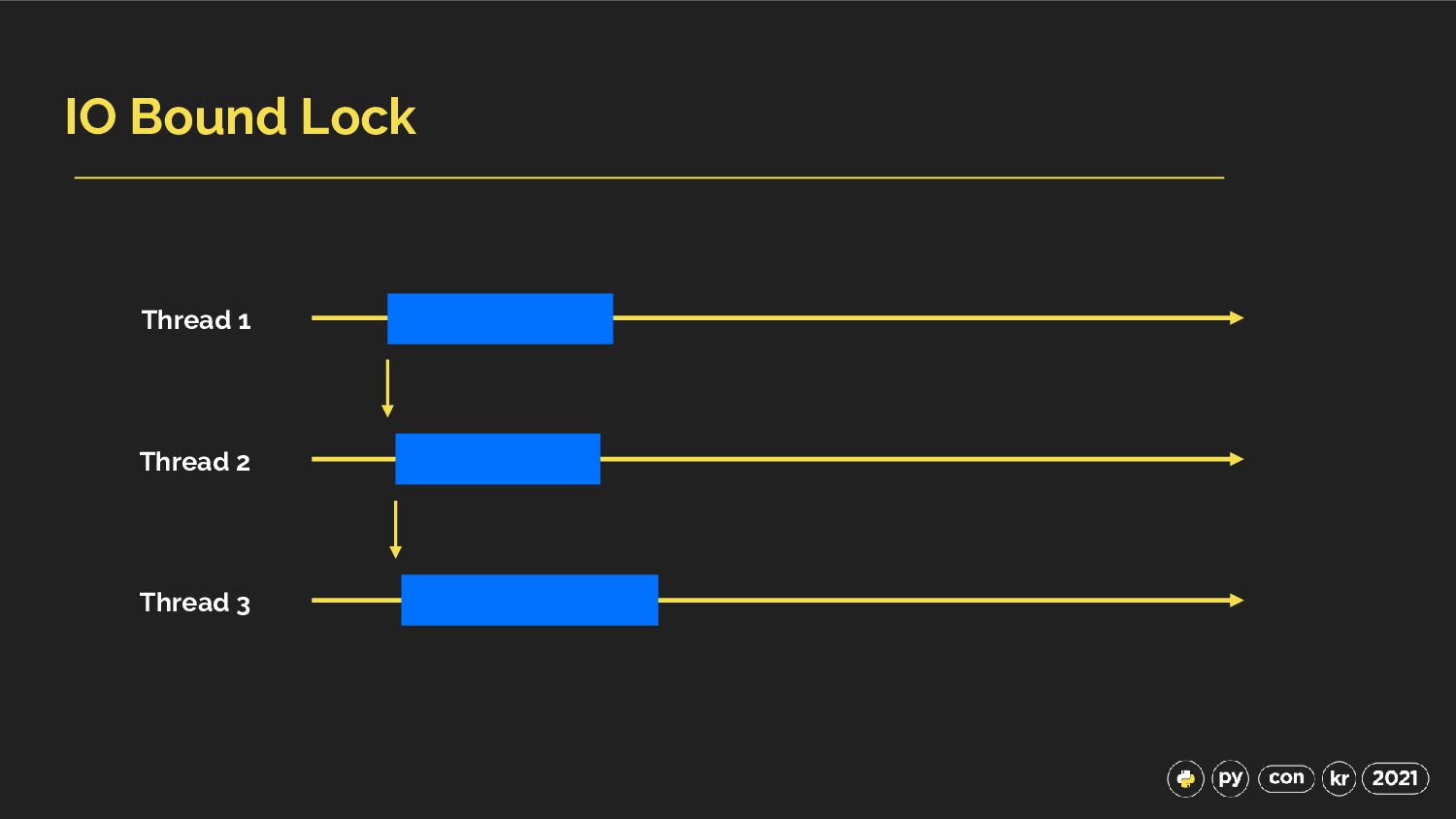
![Thread in Python with IO Bound Requests URLS: List[str] =](https://files.speakerdeck.com/presentations/1cf2001189f14b5f917a509af5cbc566/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Native Python STD def mean(nums: List[float]) -> float: return sum(nums)](https://files.speakerdeck.com/presentations/1cf2001189f14b5f917a509af5cbc566/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
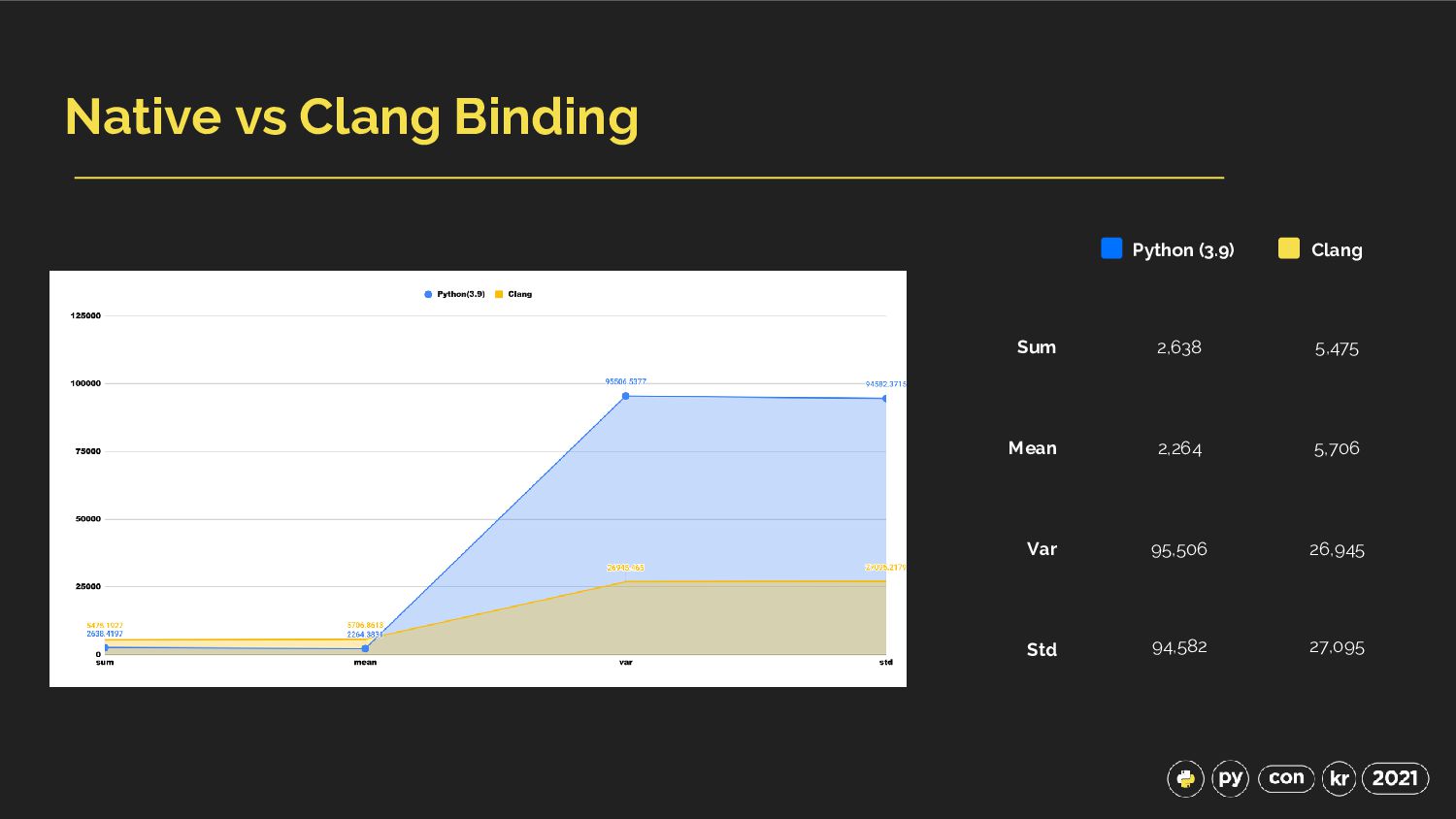{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Rust: PyO3 https://github.com/PyO3/pyo3 [package] name = "string-sum" version = "0.1.0"](https://files.speakerdeck.com/presentations/1cf2001189f14b5f917a509af5cbc566/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
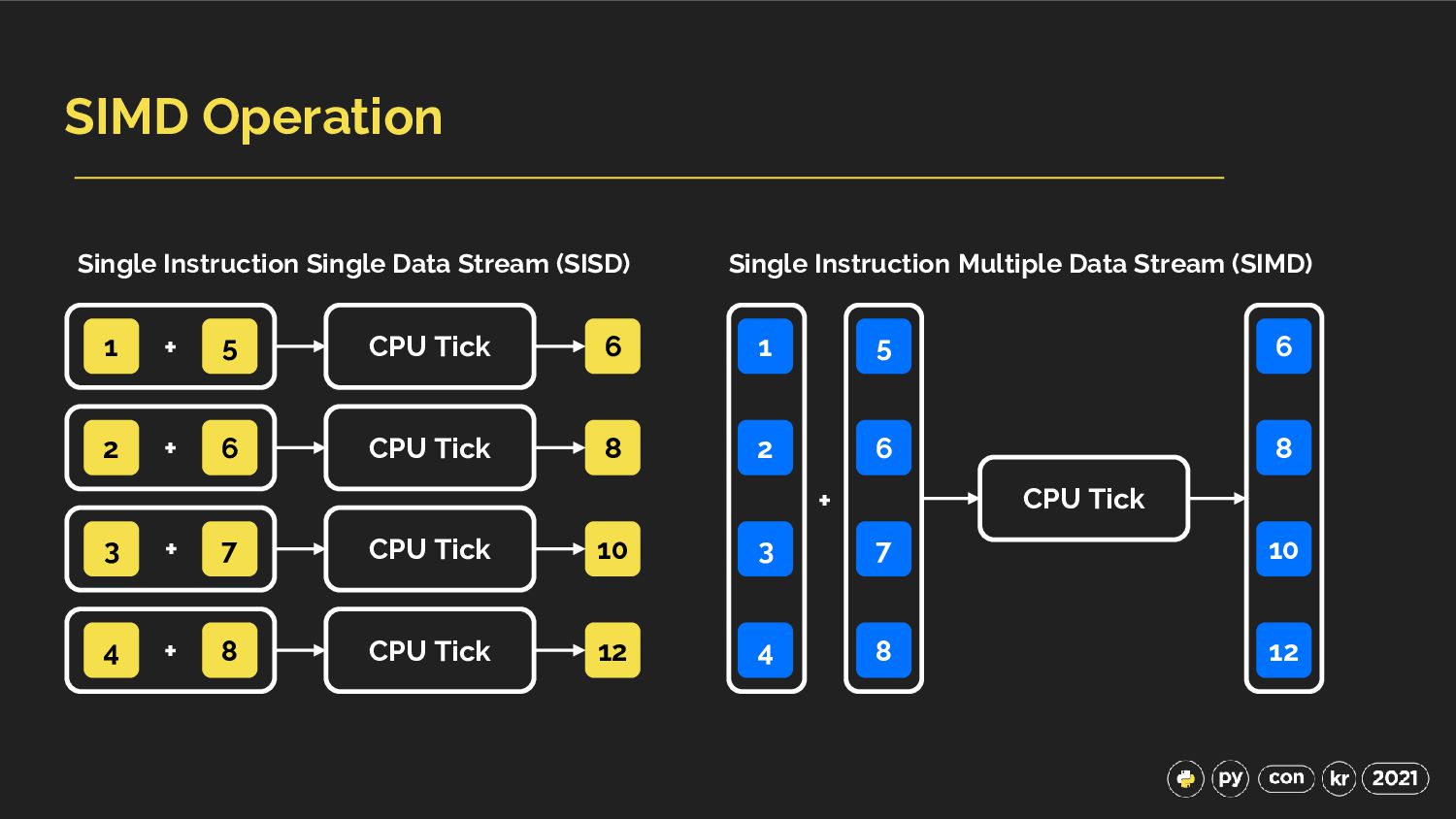{kind=link}
![SSE3 in Cython cdef void sample(): cdef double[4] operand1 cdef](https://files.speakerdeck.com/presentations/1cf2001189f14b5f917a509af5cbc566/slide_27.jpg){kind=link}
{kind=link}
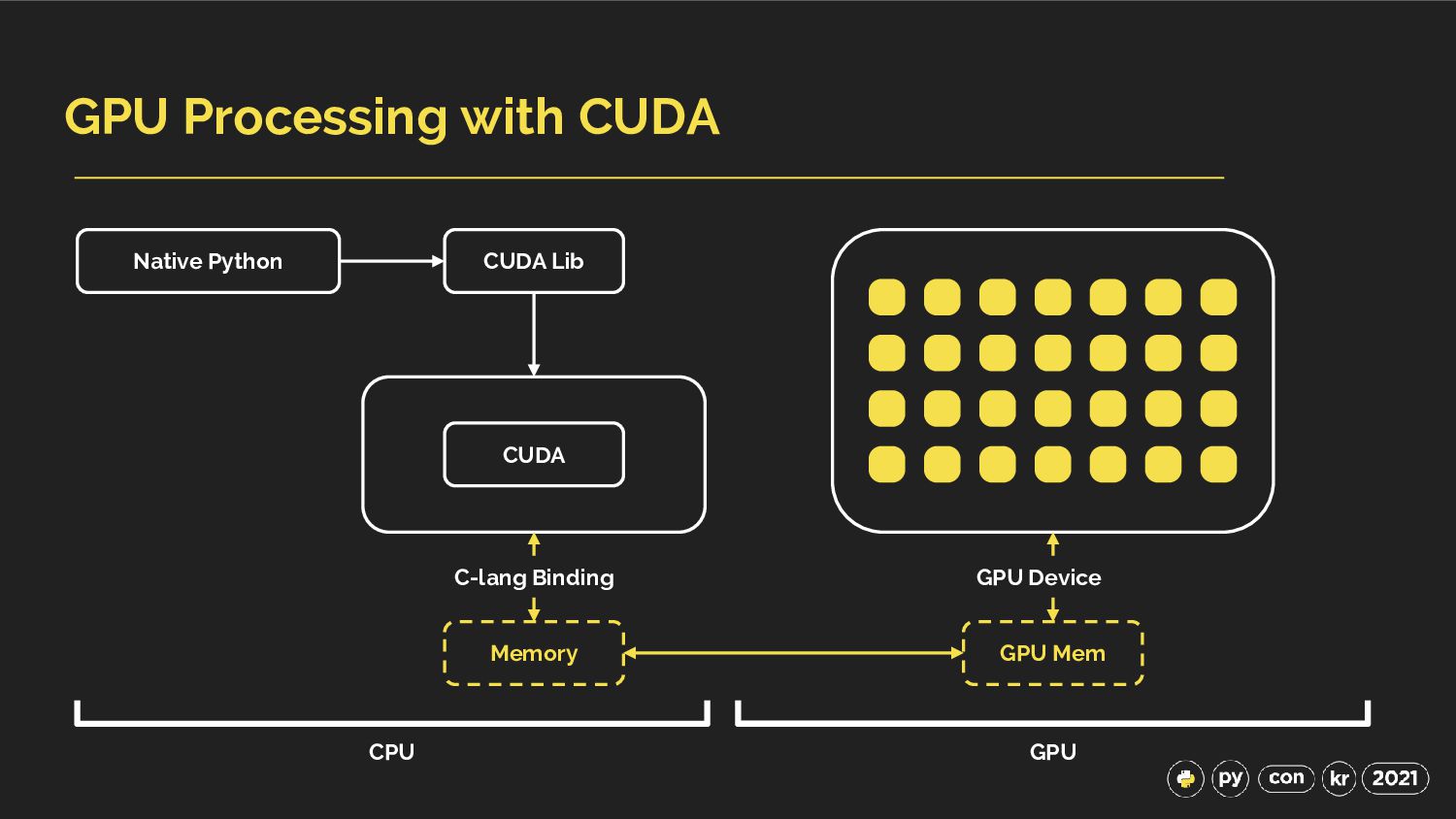{kind=link}
{kind=link}
{kind=link}
{kind=link}
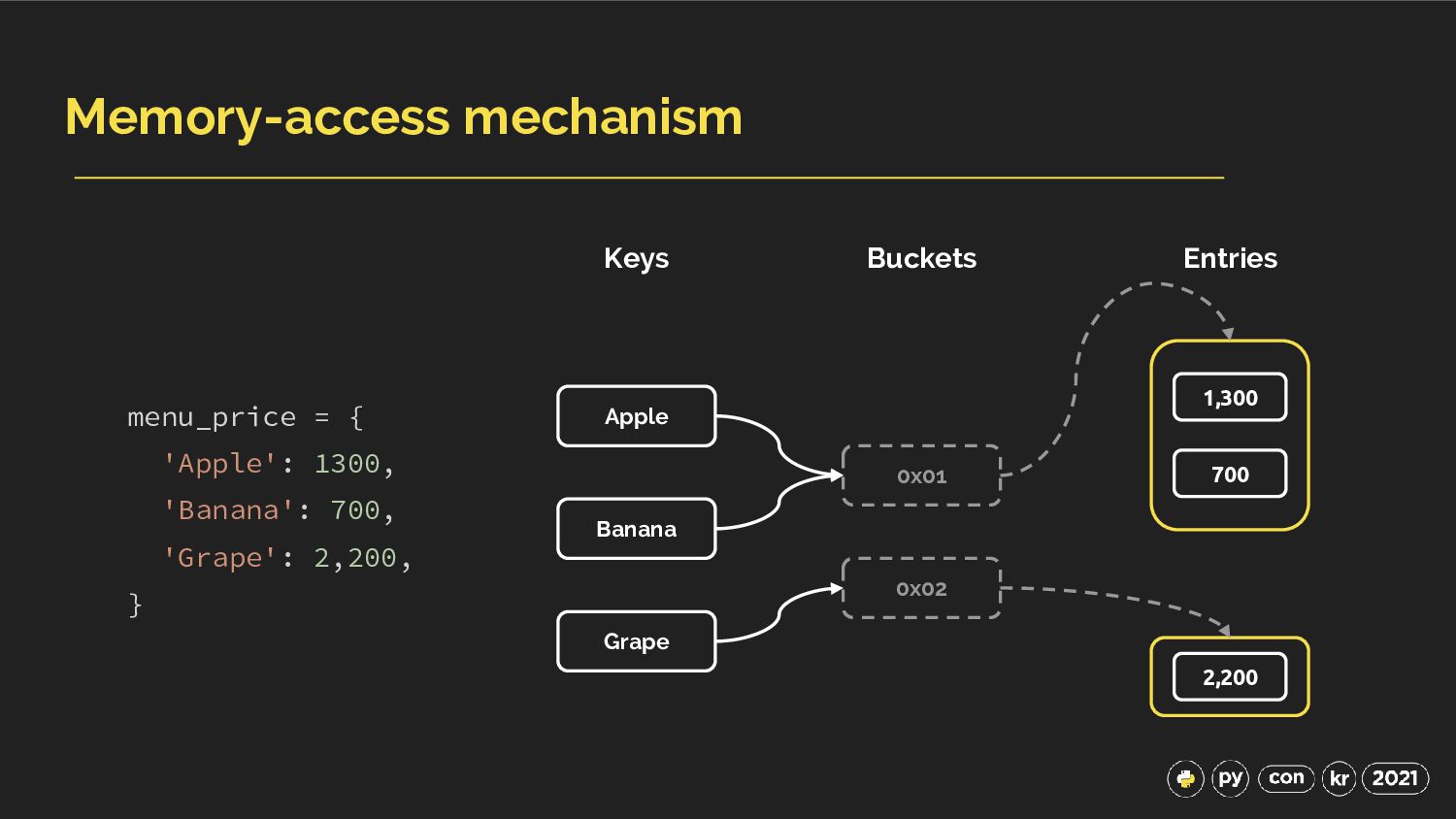{kind=link}
{kind=link}
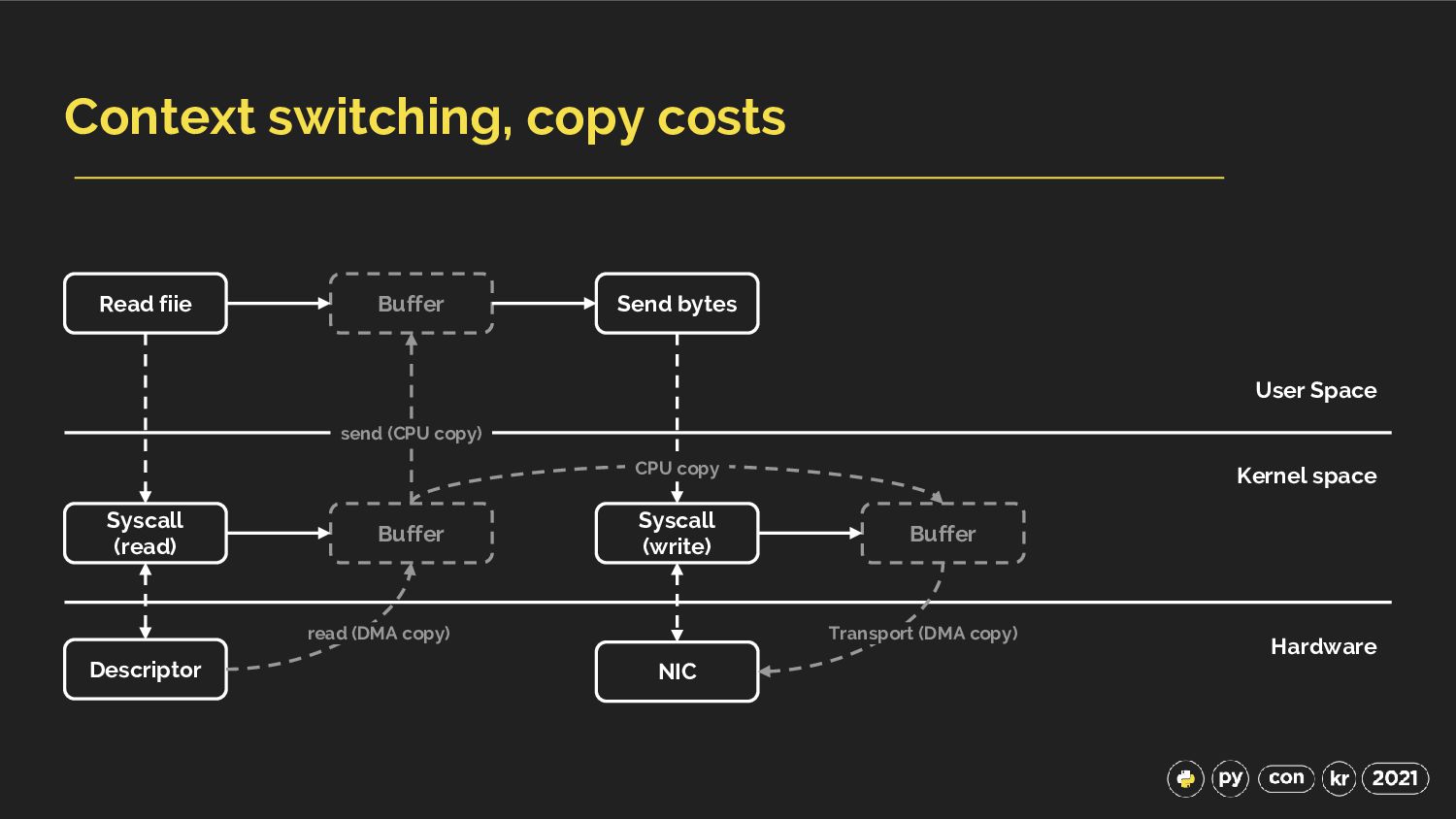{kind=link}
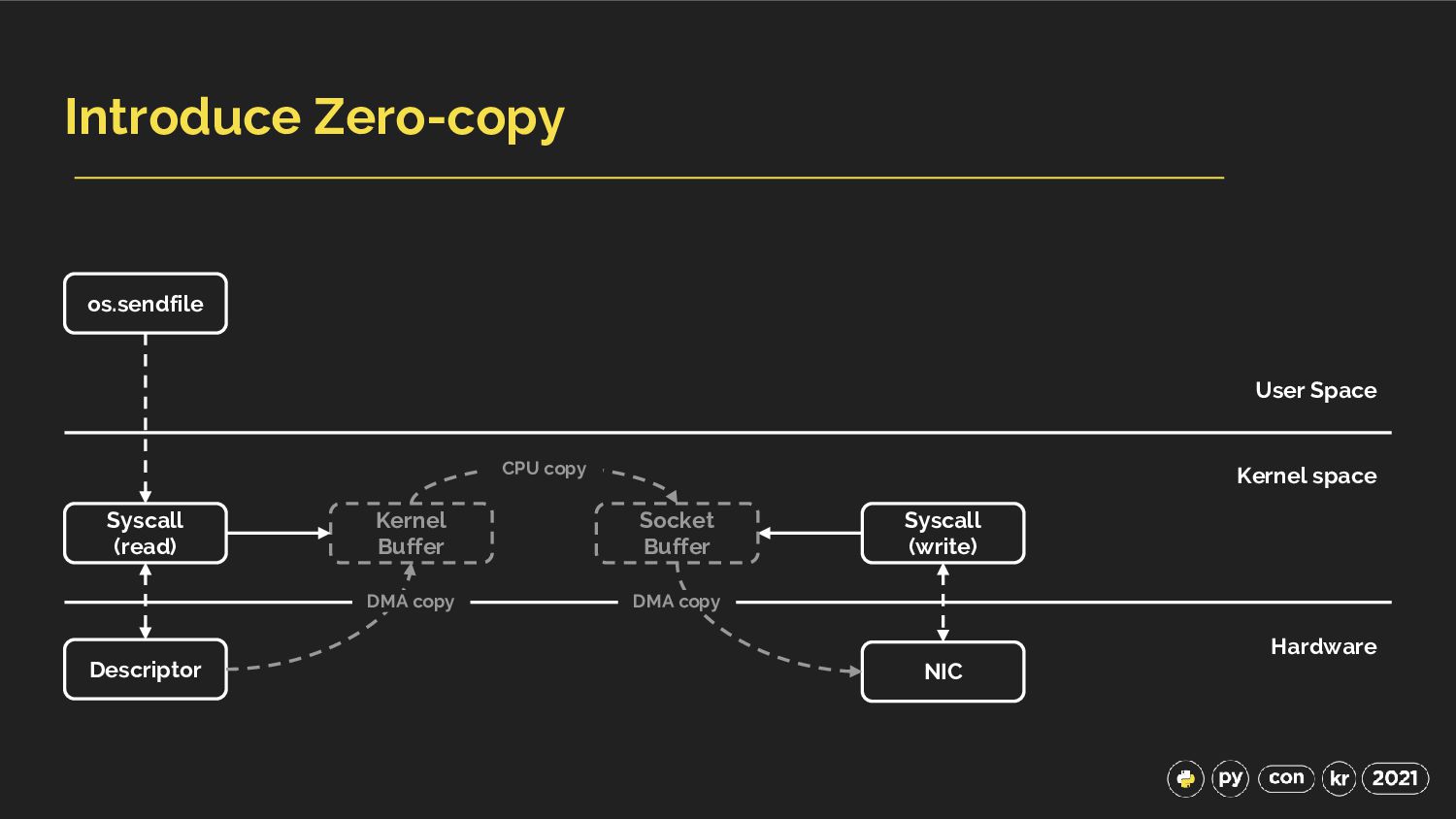{kind=link}
{kind=link}
{kind=link}
{kind=link}
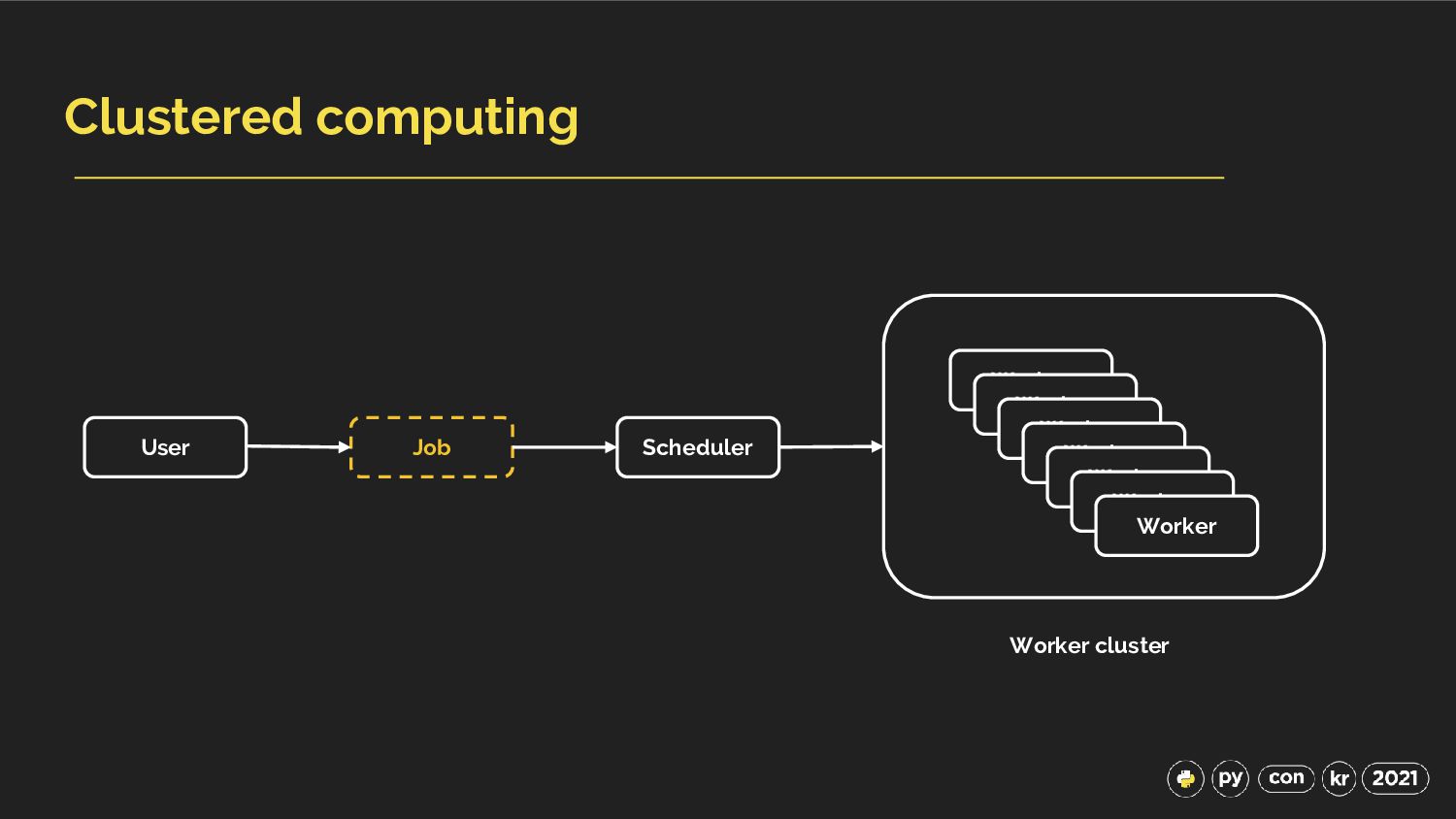{kind=link}
{kind=link}
{kind=link}