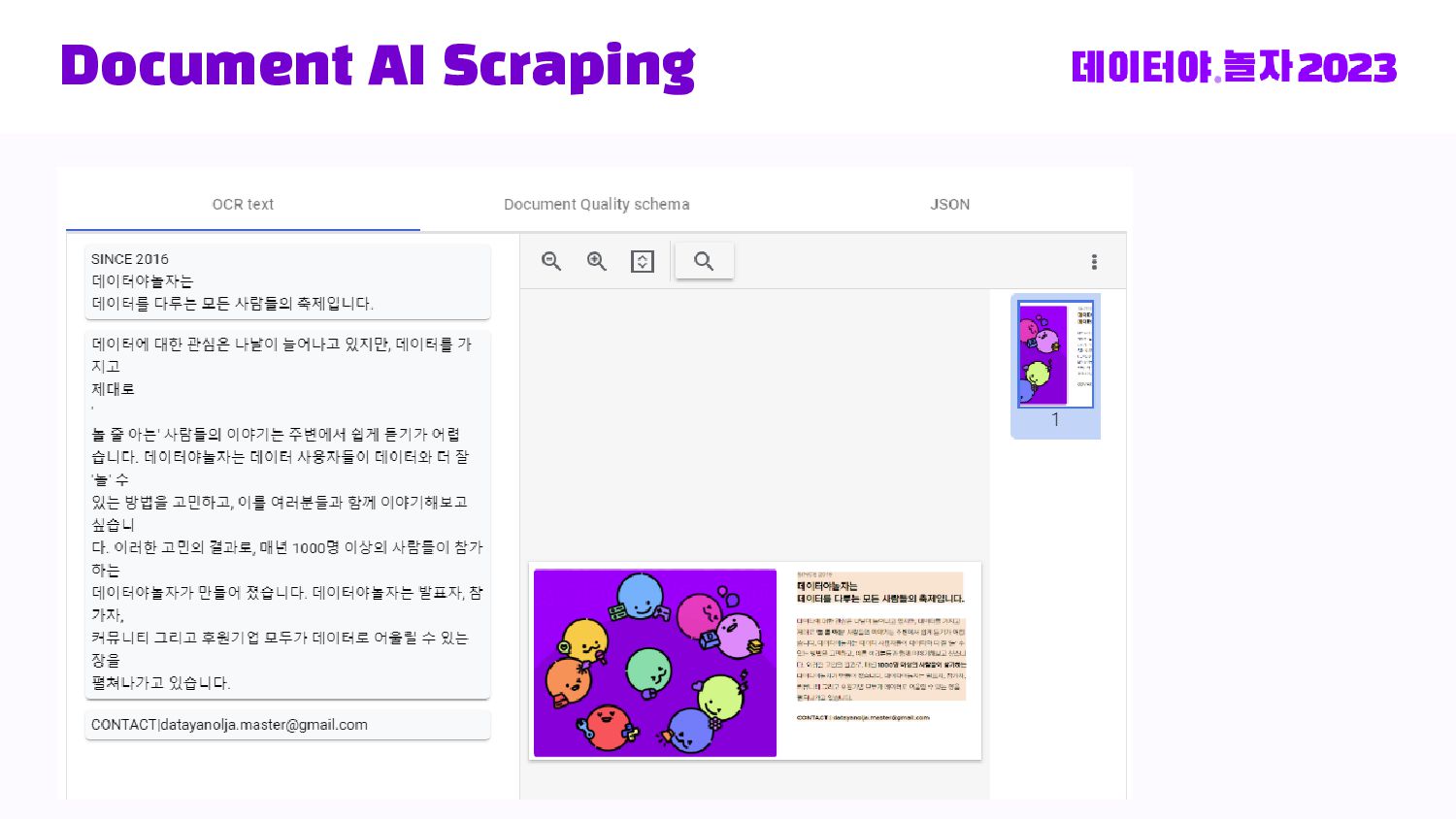
Llama2 + LoRA Fine-tuning을 데이터브릭스 데이터 전처리 부터 하나하나 경험하는 발표 자료입니다.
10월 14일, 데이터야놀자에서,
"LLMOps를 위한 거대한 데이터 연못 만들기" 주제로 발표된 주제로.
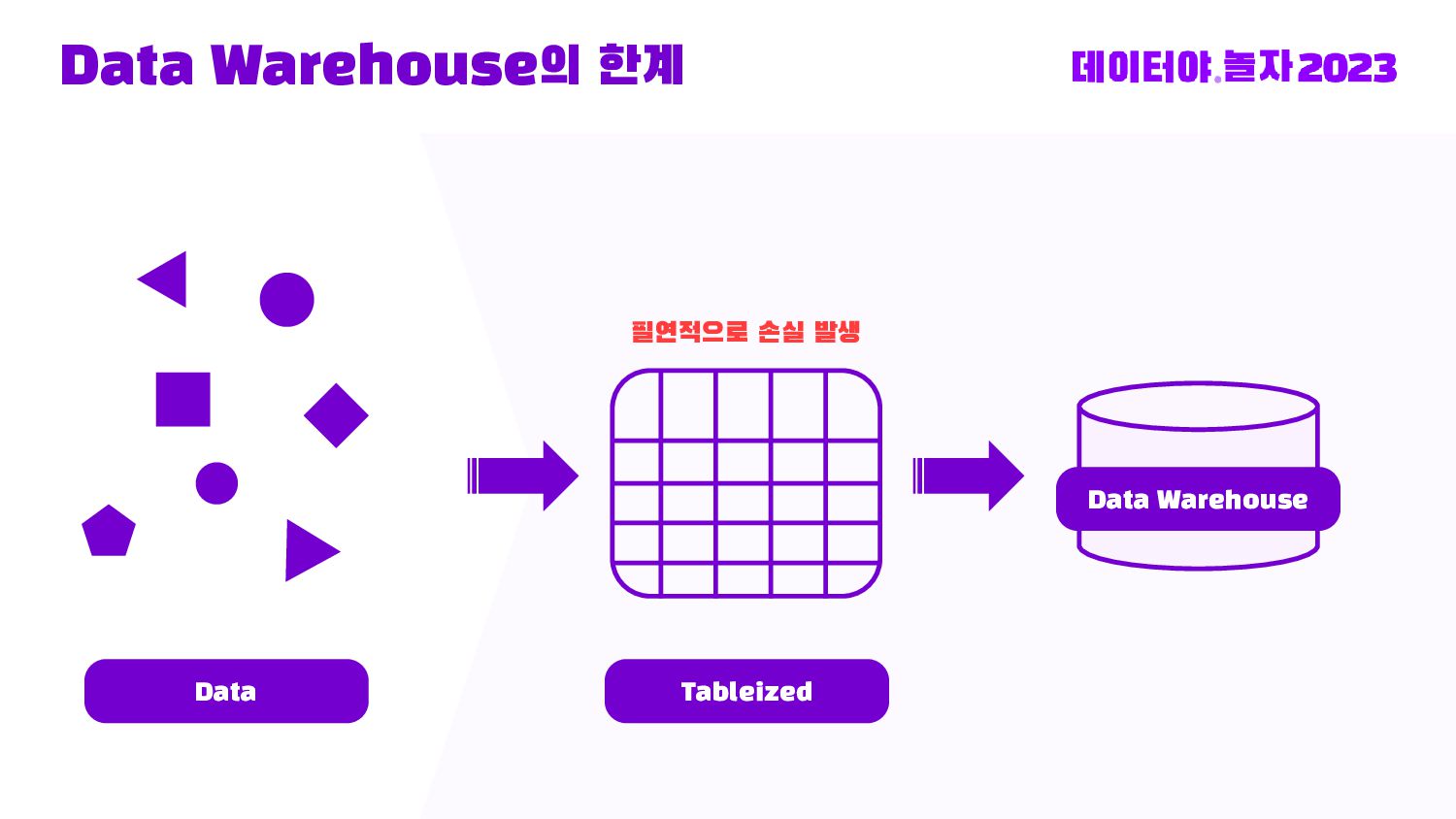
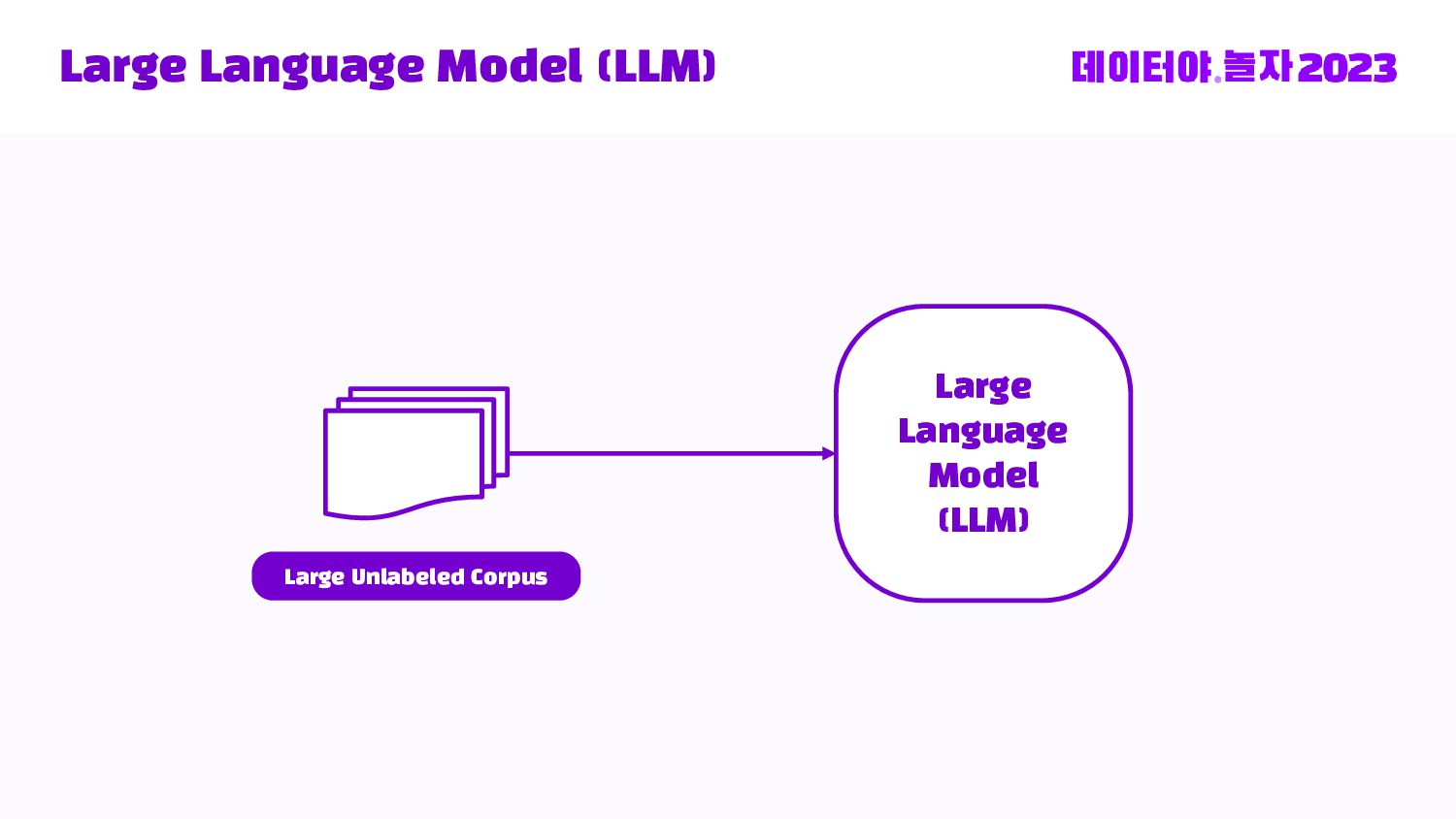
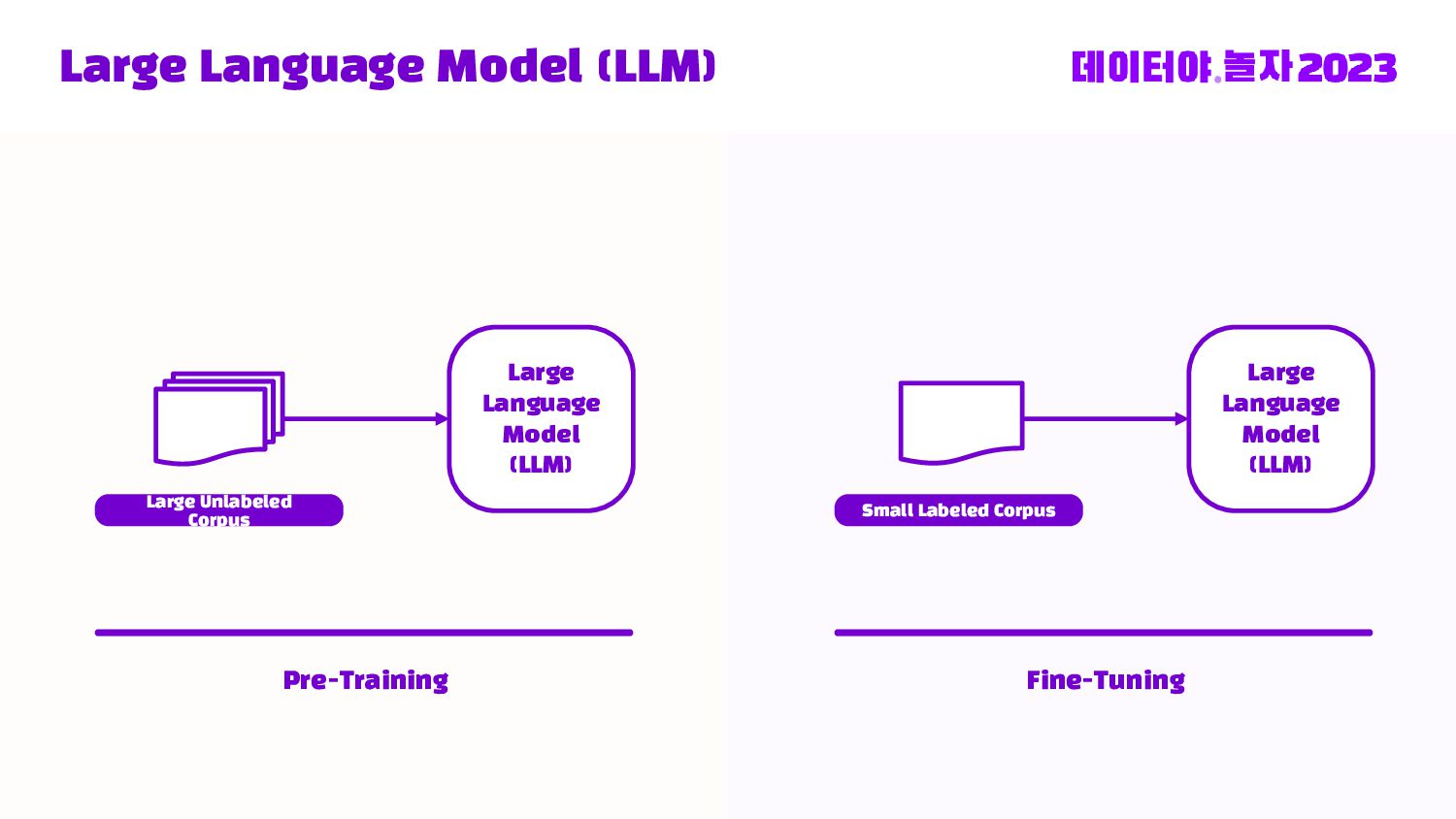
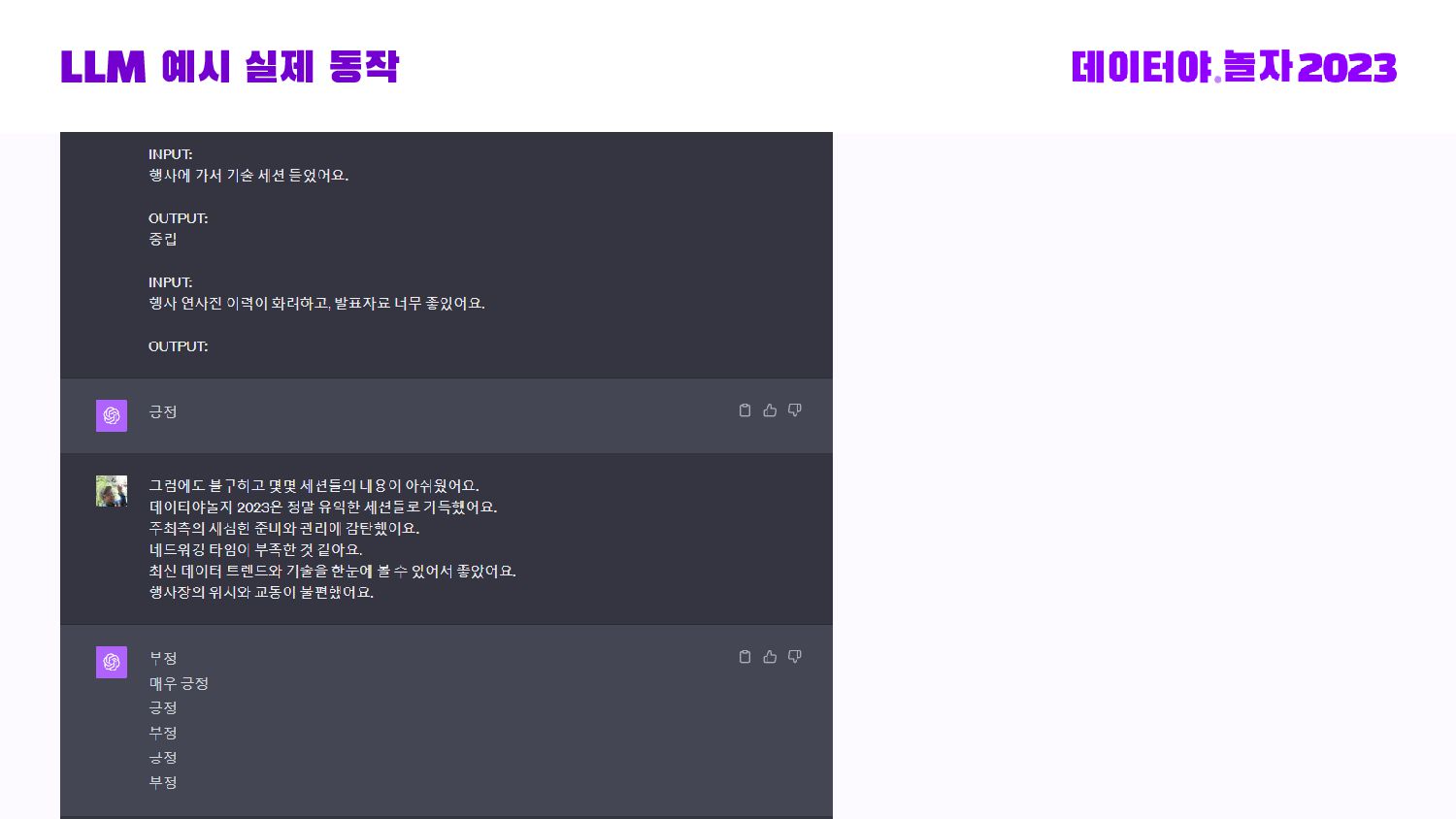
Databricks Medallion 아키텍처로 부터 Bronze -> Silver -> Gold 데이터 스파크 전처리부터, 허깅페이스 데이터셋 등록, Llama2 + LoRA로 직접 Fine-tuning 및 LLM 인퍼런스를 Transformers Pipeline으로 돌리는 End-to-end 내용을 다룹니다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
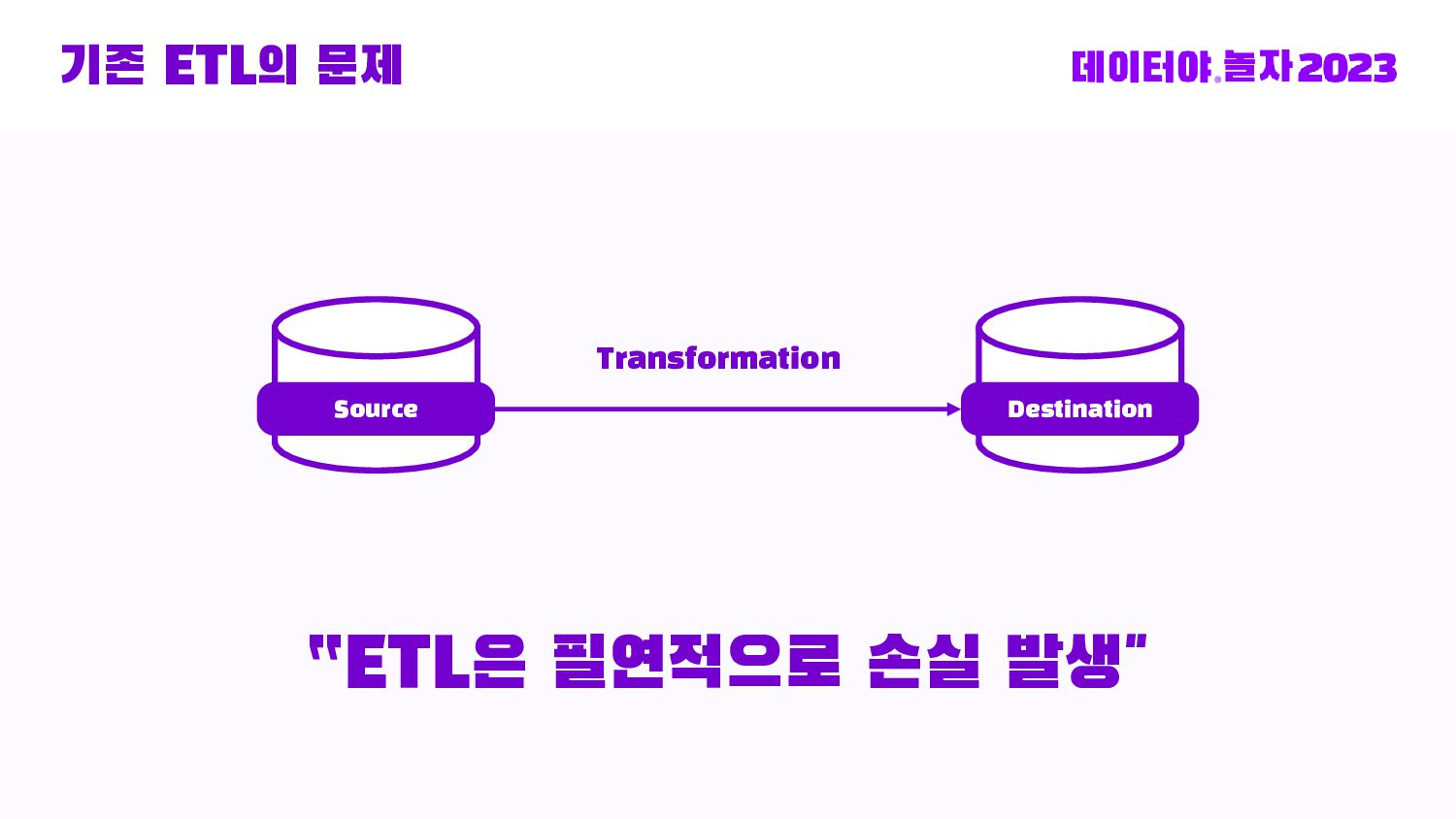{kind=link}
{kind=link}
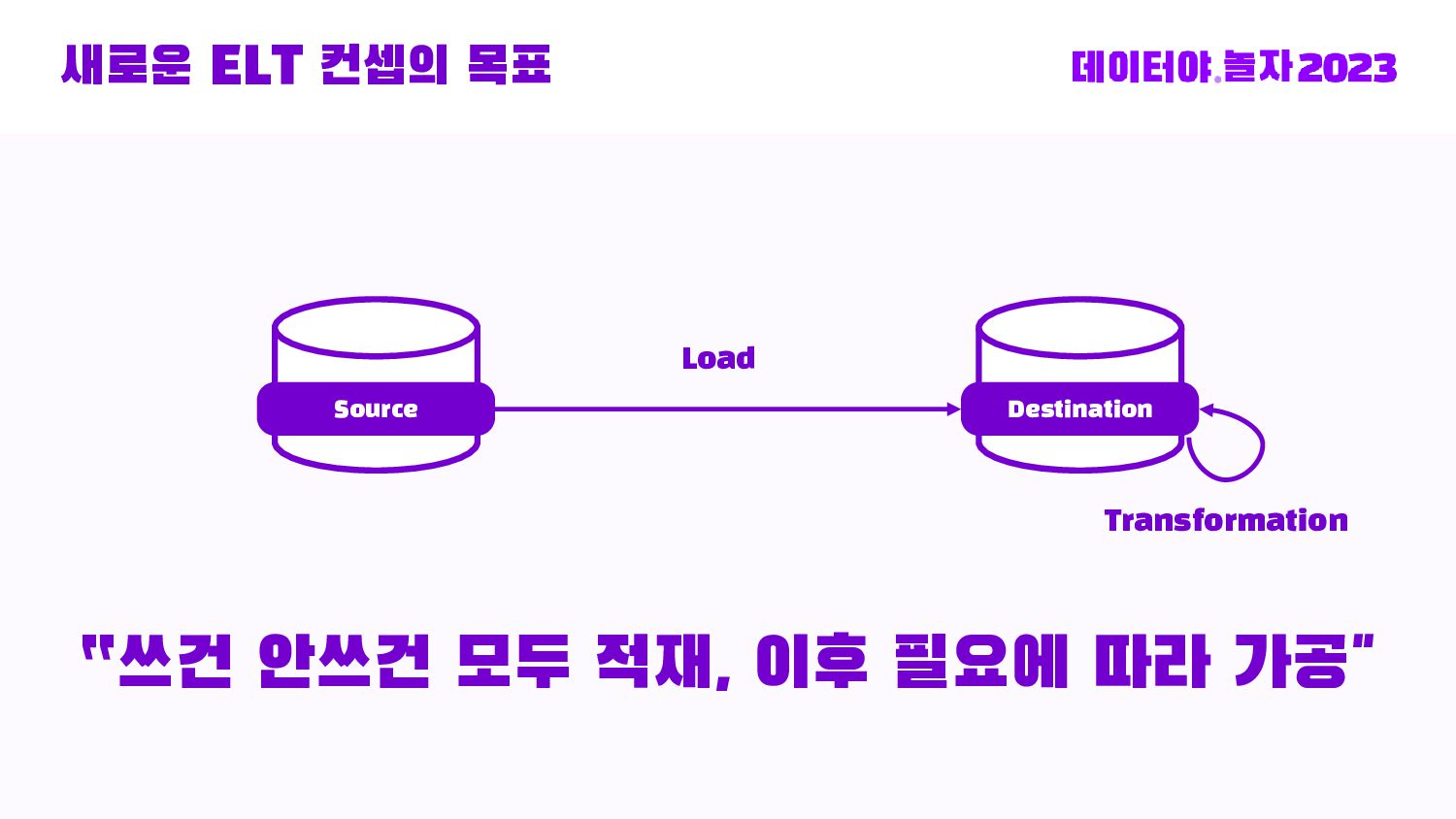{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Demonstration]](https://files.speakerdeck.com/presentations/adf23877c3124f1abdfde1e82d453587/slide_25.jpg){kind=link}
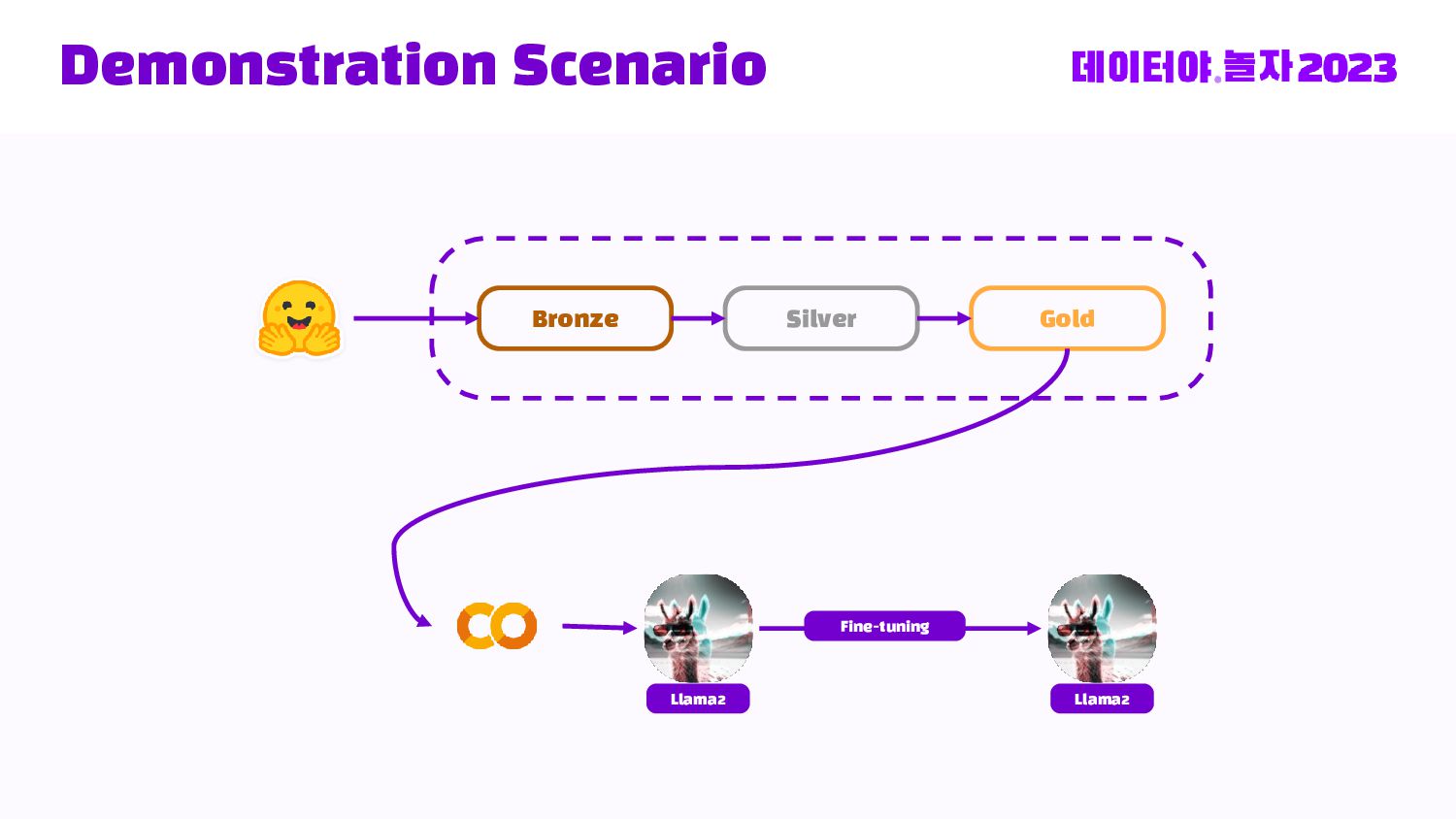{kind=link}
![Bronze df = dataset["train"].to_pandas() df = pd.concat([df.drop(['preference-suggestion'], axis=1), df['preference- suggestion'].apply(pd.Series)],](https://files.speakerdeck.com/presentations/adf23877c3124f1abdfde1e82d453587/slide_27.jpg){kind=link}
{kind=link}
![Gold df = silver_df gold_df = df.select(concat( lit("[REQ]"), df['request'], lit("[/REQ]"),](https://files.speakerdeck.com/presentations/adf23877c3124f1abdfde1e82d453587/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Output [{'generated_text': "<s>[REQ]I want to send money, how long will](https://files.speakerdeck.com/presentations/adf23877c3124f1abdfde1e82d453587/slide_36.jpg){kind=link}
{kind=link}
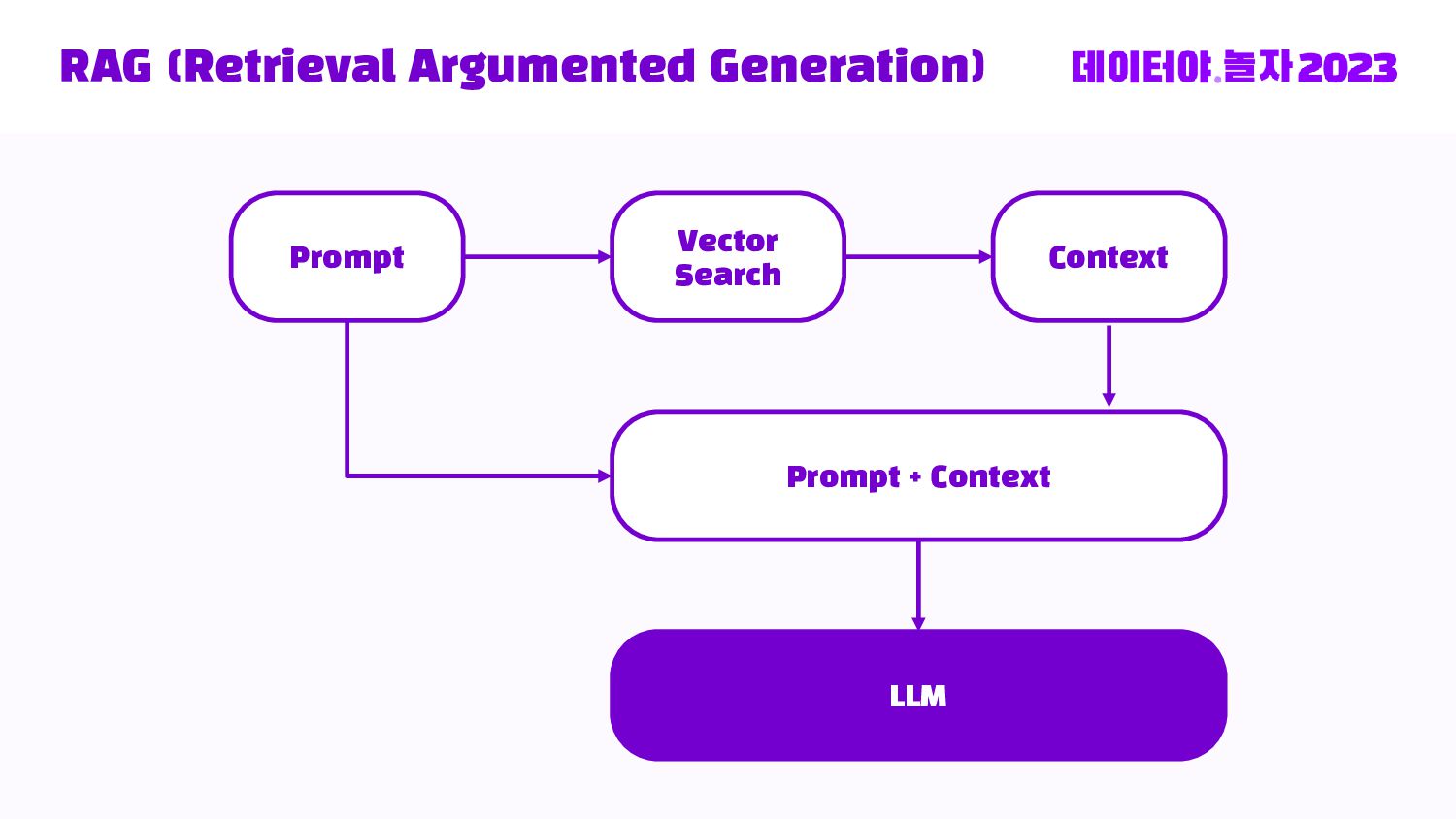{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Spark NLP #1 document_assembler = DocumentAssembler().setInputCol("text").setOutputCol("document") tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("tokens") normalizer](https://files.speakerdeck.com/presentations/adf23877c3124f1abdfde1e82d453587/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected]](https://files.speakerdeck.com/presentations/adf23877c3124f1abdfde1e82d453587/slide_46.jpg){kind=link}
{kind=link}