Are you addicted to slow application performance? Are you ready to make a change? :)
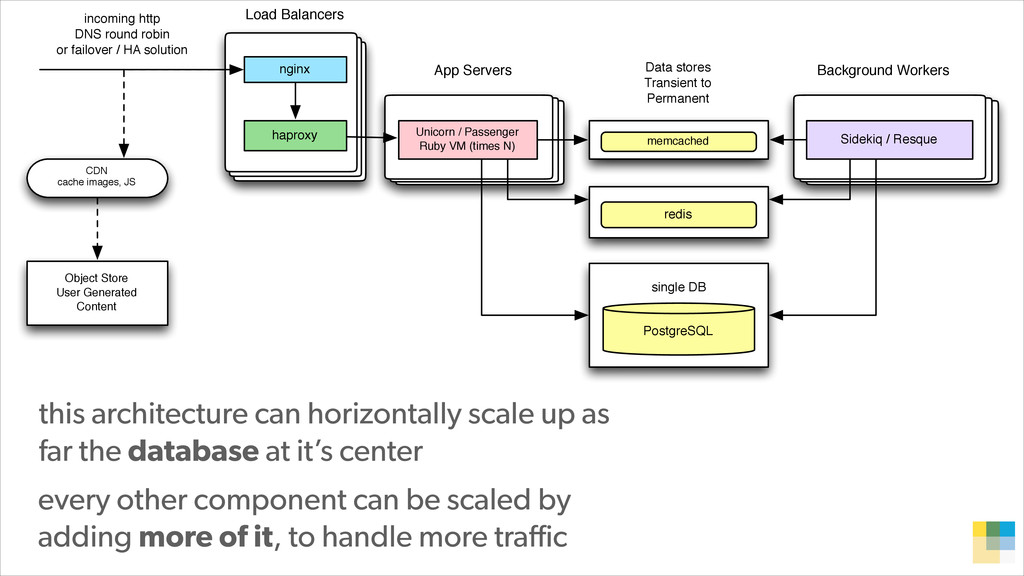
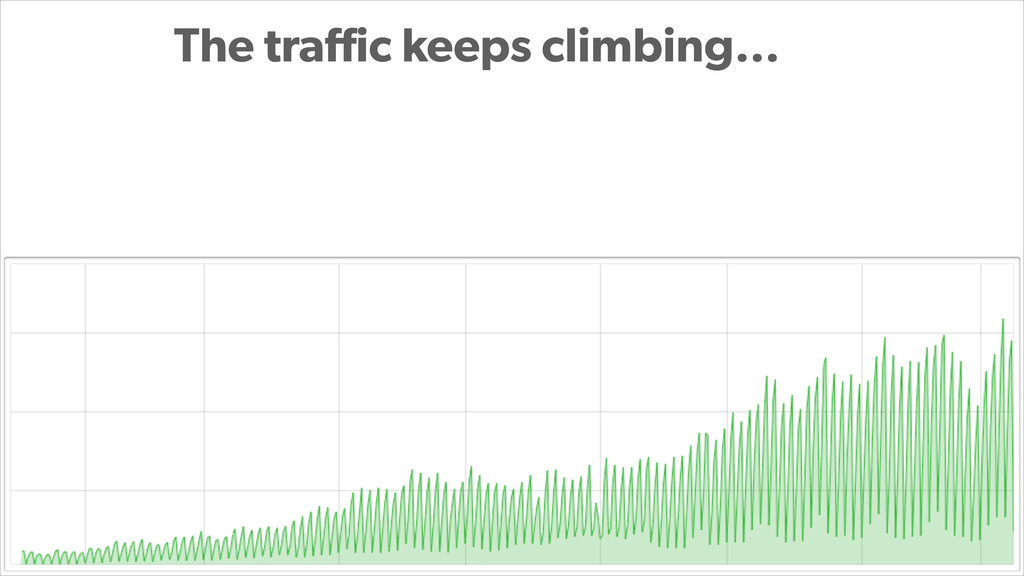
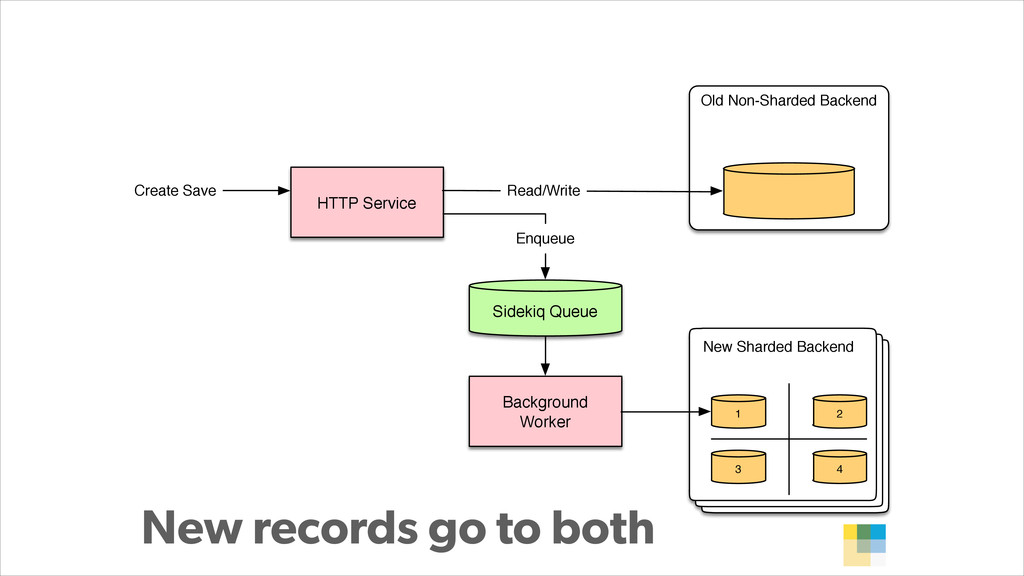
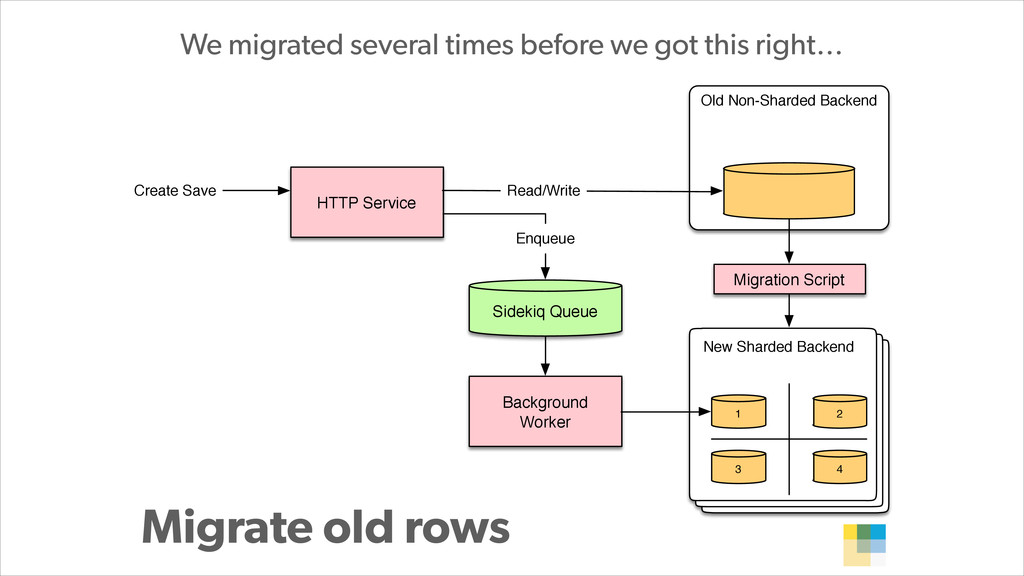
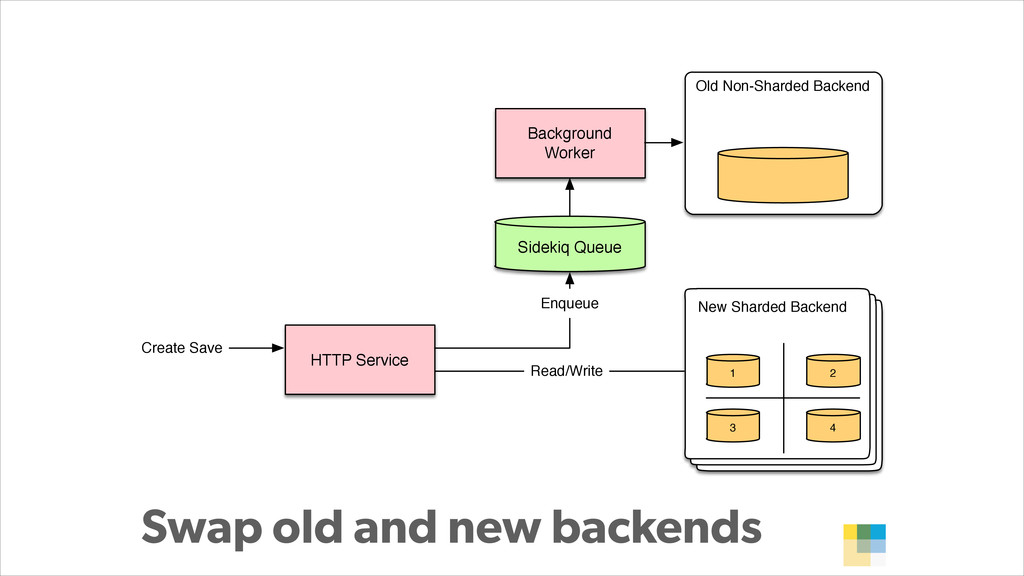
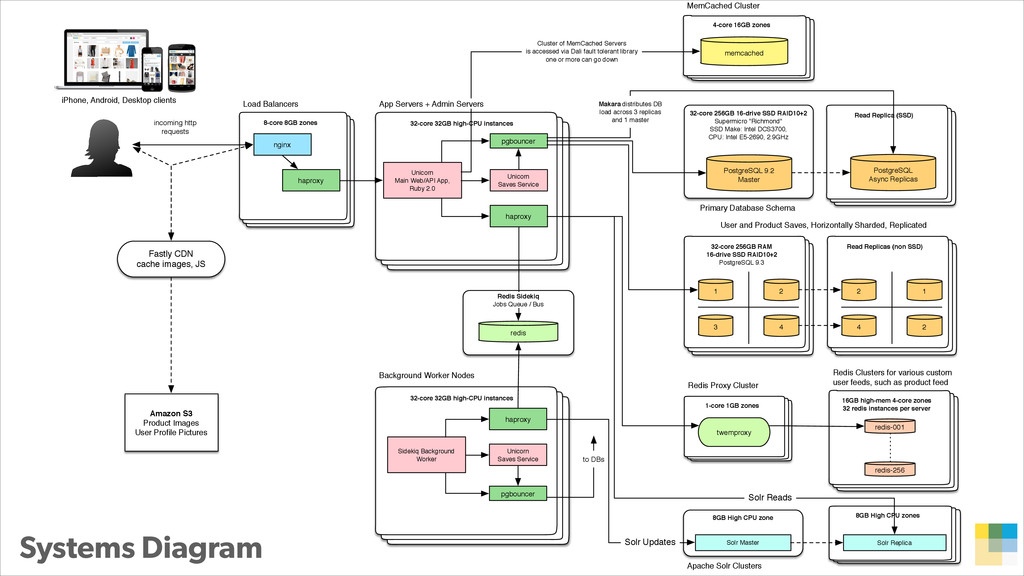
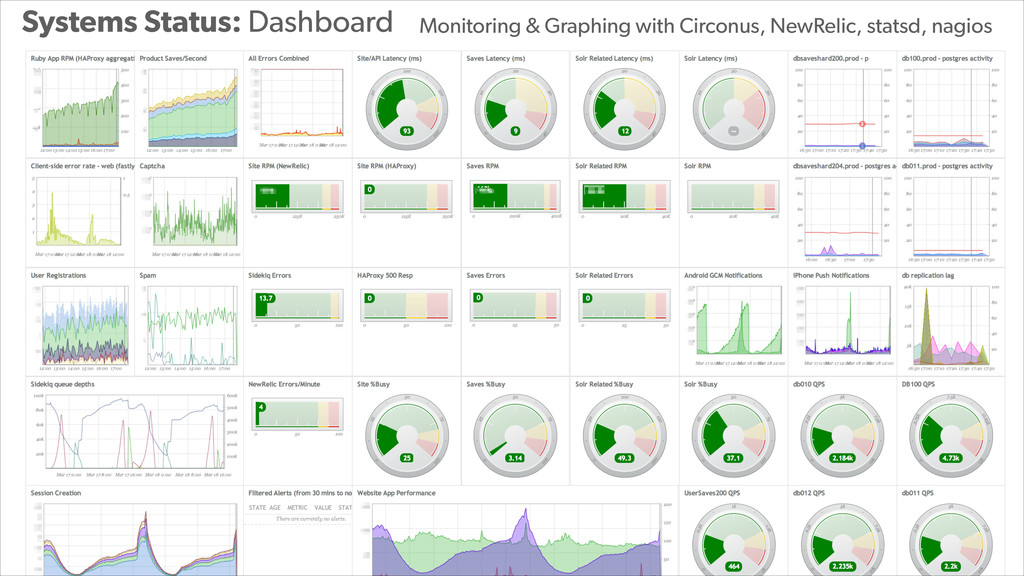
In this presentation, Konstantin Gredeskoul tells the story of how Wanelo grew their application to serve 3K requests/seconds in just a few months, while keeping latency low, and tackling each new growth challenge that came their way. He breaks down their story into a 12-step program for scaling applications atop PostgreSQL. The talk will cover topics ranging from traditional slow query optimization, vertical and horizontal sharding with PostgreSQL, serializing and buffering frequent writes, as well as using services to abstract scalability concerns.
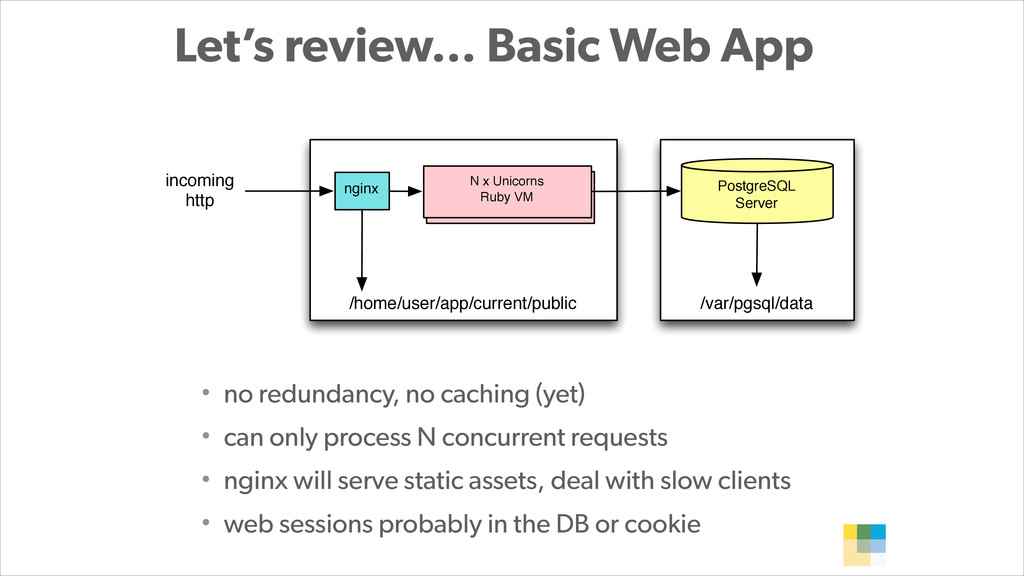
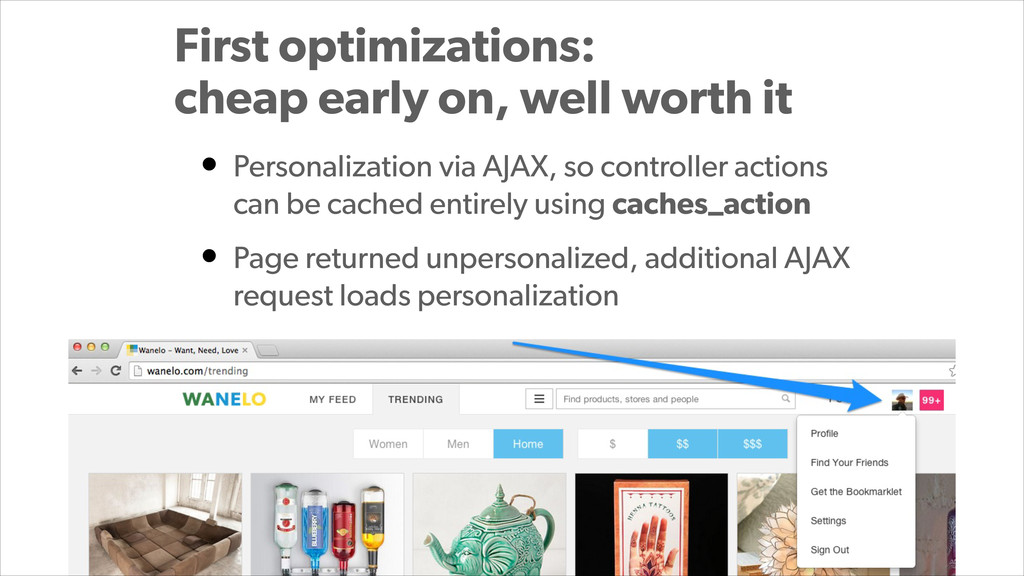
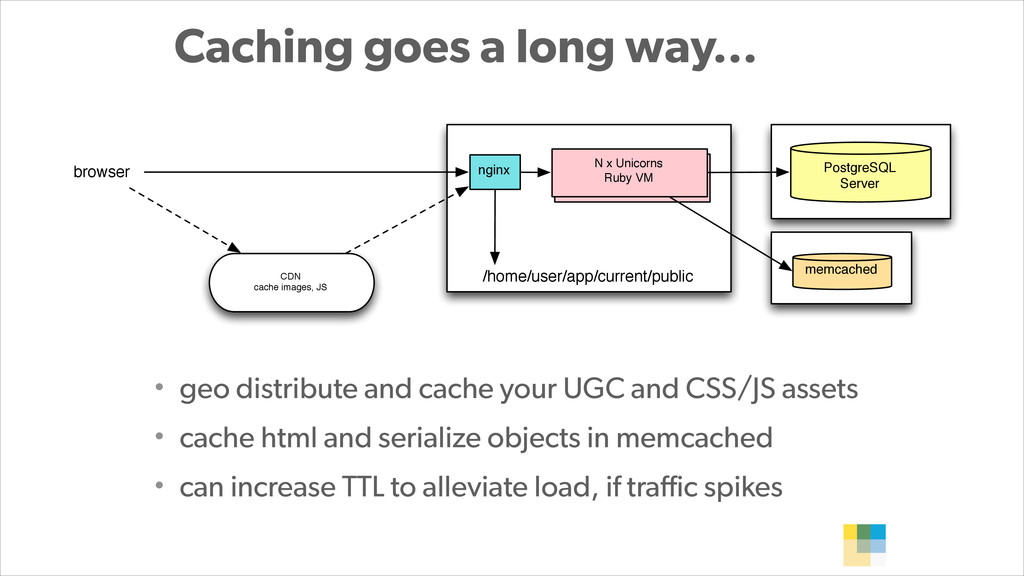
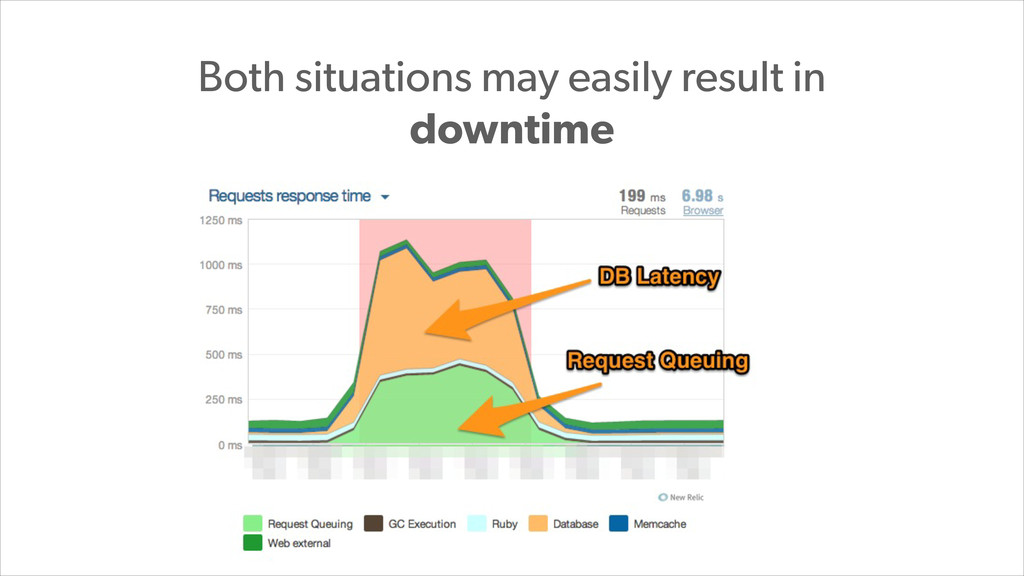
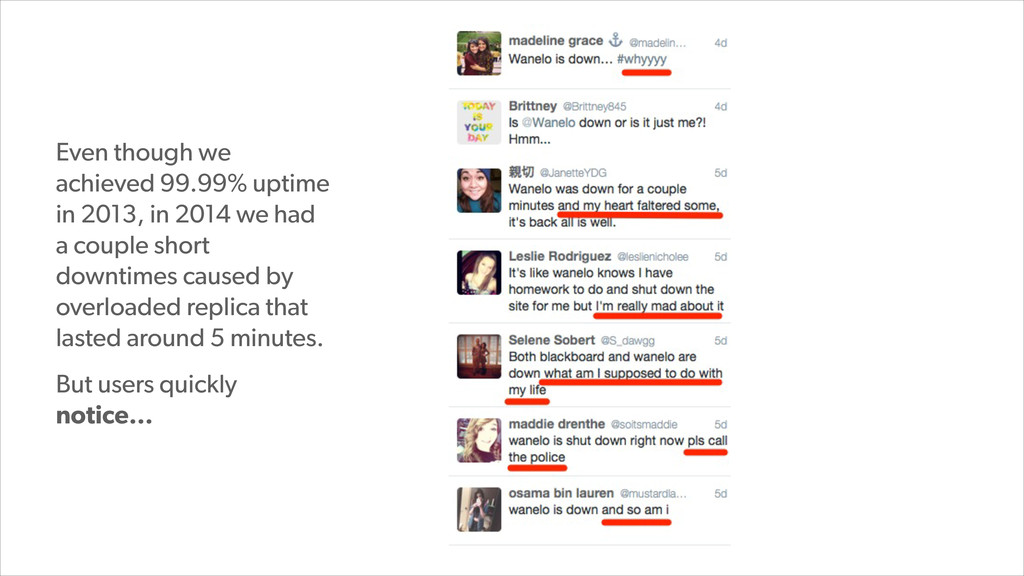
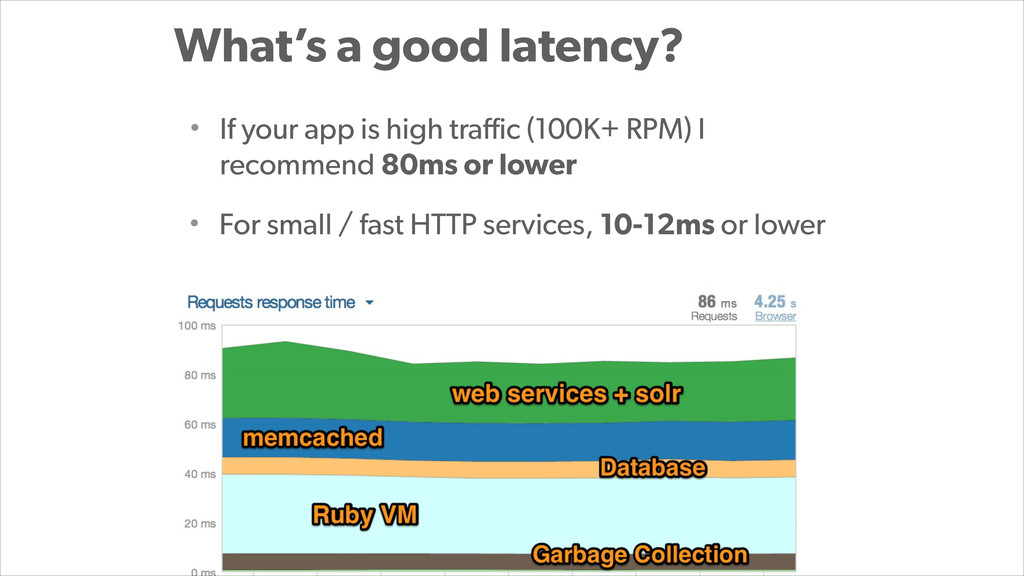
With PostgreSQL 9.2 and 9.3 as the primary data store and Joyent Public Cloud as their hosting environment, the team at Wanelo keeps optimizing the application stack over and over again using an iterative approach, to keep the latency low, uptime high, and users happy :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}